[논문] Self-Supervised Learning of Echocardiogram Videos Enables Data-Efficient Clinical Diagnosis
논문
목록 보기
3/5
Title: Self-Supervised Learning of Echocardiogram Videos Enables Data-Efficient Clinical Diagnosis
Journal: 2022 ICML
Github: https://github.com/cards-yale/echo-ssl-aortic-stenosis
Abstract
SSL의 흐름
- (1) 처음에는 Transfer learning + Supervised pretraining task.
- (2) 나중에는 In-domain representation learning (Model initialization에 사용) + Supervised finetuning
- 퍼포먼스 면에서는 (2) > (1)
Objectives
- Echo videos에서 SSL해서 representation learning하고, downstream task에 finetuning 하겠다.
- 이런 SSL이 비디오 포맷으로 된 메디컬 영상에 대해서는 적용된 바가 없기 떄문에 novelty가 있다.
Downstream task
- Aortic stenosis (AS, 대동맥 협착) 진단.
- AS는 대동맥 판막 부위가 좁아지면서 발생하는 심장질환.
- 종류로는 판막 협착, 판막 아래 부분 협착, 판막 윗부분 협착 등이 있다.
Performance
- 학습데이터의 1%에 대해서만 finetuning을 했음에도 불구하고 (2) > (1)의 성능을 보였다.
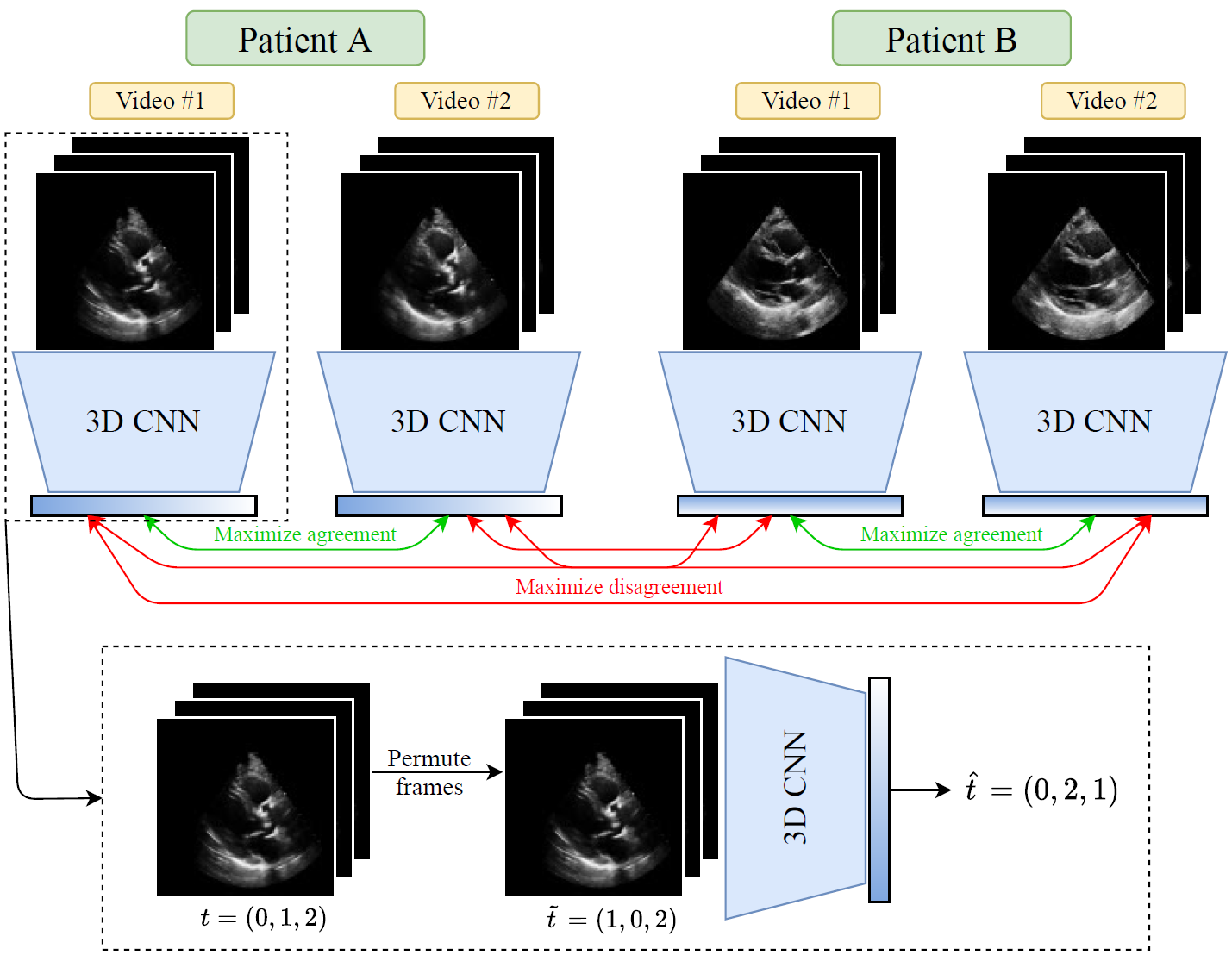
논문에서 제안하는 echo videos에서의 SSL 방법
프레임워크는 2가지로 구성된다:
- Contrastive learning objective.
- Frame re-ordering task.
- 같은 환자에서 서로 다른 video들로 positive pair를 구성하여 contrastive loss를 구한다.
- Frame re-ordering pretext task는 echo에서 프레임 순서를 바꿔놓고 classifier가 원래 순서를 맞추도록 학습시킨다.
1. Introduction
Background
- AS screening은 보통 심초음파 중에서도 도플러 영상을 활용한다.
- 근데 시중에 나와있는 handheld 심초음파 기기들은 대체로 도플러 이미징을 지원하지 않는다. 그렇기 때문에 AS 진단이 불가하다.
- 그래서 논문은 도플러 이미징을 사용하지 않고 2D 심초음파 영상으로부터 severe AS를 자동 진단할 수 있는 방법을 제안한다.
- 이전 연구들 중 딥러닝으로 AS를 진단하는 연구가 없었던 건 아니지만, 모두 큰 레이블링 데이터셋을 가지고 학습한 모델이다.
- 따라서 논문은 → 심초음파 영상에 SSL을 적용해서 데이터 효율적인 방법으로 representations를 학습하고, 이걸 강력한 모델 initialization으로 사용해서 작은 레이블링 데이터셋에서 downstream finetuning 했다.
Related works
- 이전에도 메디컬 영상에 SSL을 잘 적용한 연구는 많았지만 대부분 2D 데이터에 대한 연구였다.
- 최근에 3D 메디컬 이미지에 대해 SSL을 적용한 연구도 있기는 한데, 심초음파가 아니라 CT와 MRI 였다.
| CT와 MRI | Echo |
|---|---|
| 3번째 차원이 spatial | 3번째 차원이 temporal |
| 고해상도의 모달리티 | 매우 저해상도의 noisy한 모달리티 |
| 영상 획득 방법이 표준화 되어있다 | 촬영자의 숙련도에 영향을 크게 받는다 |
| SSL에서 중요한 데이터 augmentation에 적합하다 | 위 2개 이유 때문에 작은 transformation에도 굉장히 민감하다 |
Contribution
SSL을 심초음파 영상에 적용할 때 고려해야 하는 점
- 초음파는 noisy한 모달리티기 때문에 heavy한 데이터 augmentation에 취약하다.
- 심초음파는 시간 정보를 많이 담고 있는데 contrastive learning에서는 이 정보를 사용하지 않는다.
1번을 해결하기 위해서 “Multi-instance” contrastive learning을 제안한다.
- 서로 다른 view의 video를 positive pair로 만든다. 이때, 한 환자의 서로 다른 view를 가진 video들은 같은 특징을 가진다고 가정하는 것이다.
- 좋은 점 (1): Challenging positive pair를 생성하게 된다.
- 좋은 점 (2): 심초음파에다가 aggressive한 augmentation을 해서 인위적으로 두 개의 서로 다른 view를 만들 필요가 없다.
2번을 해결하기 위해서 “Fram re-ordering” pretext task를 제안한다.
- 프레임을 무작위로 섞은 후에 모델이 원래 프레임 순서대로 맞출 수 있도록 학습시킨다.
- 좋은 점 (1): 모델에 시간적 일관성을 부여해서 downstream task를 수행할 때 유리하다.
- 좋은 점 (2): 보다 설명 가능한 시각적 해석을 가능하게 한다.
2. Materials
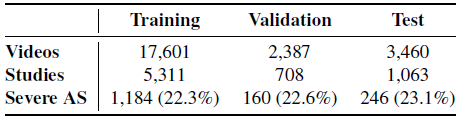
Dataset
- Severe AS detection
- Binary classification task → Positive class: Severe AS, Negative class: 나머지 AS 및 normal 환자.
- 괄호 안 숫자 = severe AS 비율
- Train 75%, Validation 10%, Test 15%
Preprocessing
- 10,000개의 스터디에서 severe AS는 50배 오버샘플링해서 추출
- 자동으로 view classifiation하는 알고리즘 써서 PLAX echo들만 획득
- PLAX echo들은 convex hull 알고리즘으로 가장 큰 컨투어를 찾음으로써 마스킹 작업을 해서 deidentification을 했다.
- 112 x 112로 다운 샘플링
3. Methods
SimCLR
- 논문에서 echo 영상에다 처음 시도한 SSL 방법
- Echo로부터 video 클립을 랜덤 샘플링
- 각 프레임에다가 temporally consistent한 spatial augmentation 수행해서 → 2개의 view를 만든다.
- 그런데 echo 영상 특성상 noisy한 nature를 가지기 때문에 유의미한 signal을 없애지 않으려면 augmentation 정도에 제한이 걸릴 수 밖에 없다.
- 따라서 augmentation은 다음 세 가지만 사용하였다: random zero-padding (모든 방향으로 8픽셀, prob 1), random horizontal flip (prob 0.5), random rotation (degree -10~10, prob 0.5)
MI-SimCLR
- 풀네임 “Multi-Instance” SimCLR
- Positive pair를 만들 때, 한 환자 내에서 독립적인 PLAX videos로부터 서로 다른 조합들을 만들어서 구성한다. → Echo에 aggressive한 augmentation을 안해도 된다는 장점.
- 이때, 한 환자의 echo에는 여러 PLAX videos가 있다고 가정한다. (그리고 실제로 그러함)
- 여기서의 가설은, 한 환자의 서로 다른 PLAX videos는 공통되는 underlying feature들을 가지고 있다.
- 결론적으로는, SimCLR보다 echo 영상 특성에 더 맞춰진 방법이다.
MI-SimCLR+FO
- 풀네임 “Multi-Instance” SimCLR with “Frame re-Ordering”
- SimCLR, MI-SimCLR은 echo의 temporal content를 고려하지 않는다. 그런데 이 방법에서는 pretext task로 시간 정보를 고려할 수 있다.
- Pretext task: 각 echo video의 프레임을 무작위로 섞어서 모델이 원래대로 순서를 맞출 수 있게 학습시킨다.
- Echo video가 K 프레임을 가진다면, K!-classification 문제로 고려된다. → ?
- 이런 pretraining을 하면 모델은 temporal coherence에 대해서도 학습이 가능하다. → 메디컬 비디오 도메인에 good.
Experimental setup
Initializations
- 5가지 initialization 비교: Random, Kinetics-400, SimCLR, MI-SimCLR, and MI-SimCLR+FO
- 3D ResNet18 초기화 → Severe AS 분류 목적의 finetuning
- Binary CE loss 사용, AUROC로 test set에 대해 퍼포먼스 측정
Finetune
- 학습 데이터셋의 비율마다 비교: 1%, 5%, 10%, 25%, 50%, 75%, 100%
- 적은 양의 데이터를 학습할 때 각각의 initialization이 어떻게 수행되는지 알기 위해서 이렇게 세팅한다.
4. Results
Fine-tuning Experiments
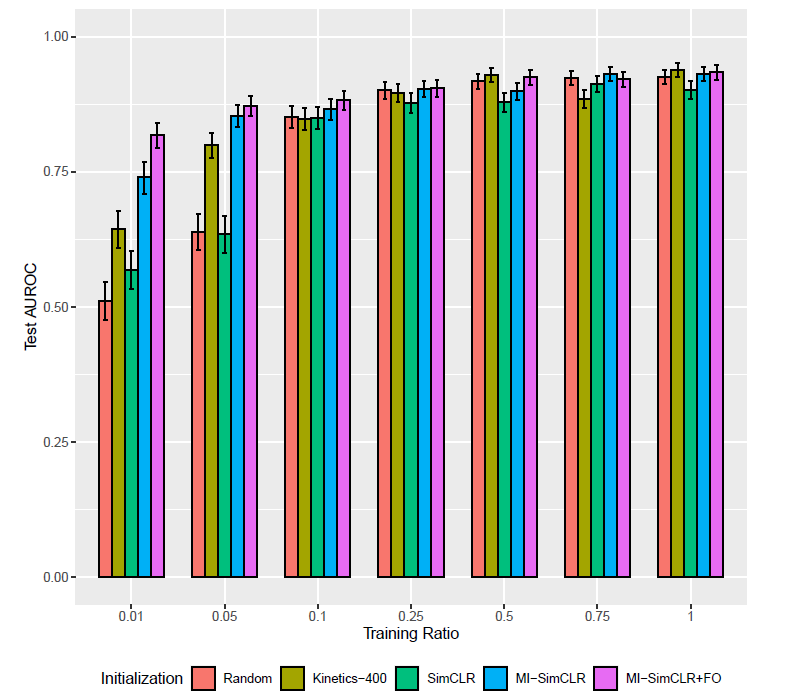
- 10% 이하의 학습 데이터셋을 사용한 경우 multi-instance 계열의 SSL 방법이 다른 방법들보다 좋았다.
- 무엇보다 이 세팅에서 SimCLR을 단독으로 사용한 경우 퍼포먼스가 상당히 안좋았는데에 반해, multi-instance 계열은 상위 성적을 내었다.
- 즉, 동일 환자에 대해 서로 다른 videos를 사용해서 positive pair를 구성하는 것이 → echo에서 효과적인 representation learning을 할 수 있는 방법이었다.
- 그리고 MI-SimCLR+FO가 대부분의 실험에서 MI-SimCLR보다 좋은 퍼포먼스를 냈다. → Frame re-ordering task의 효과.
Interpretability Analysis
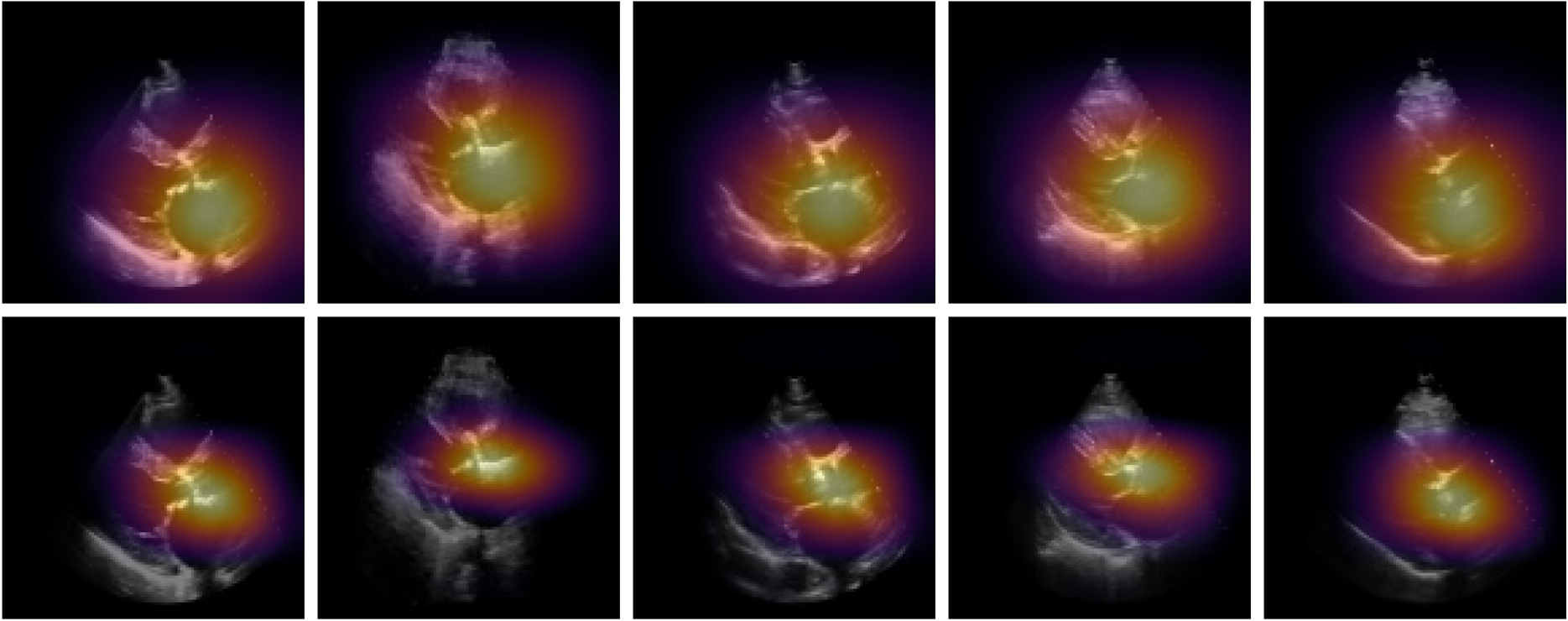
- 1행: Kinetics-400-pretrained model의 saliency maps
- 2행: MI-SimCLR+FO model의 saliency maps
- 각 video의 첫 번째 프레임만 열마다 시각화 한 것. → 가장 confident한 5개의 AS predictions를 시각화 한 것이다.
- Saliency map은 Grad-CAM을 사용해서 얻었다.
기존 transfer learning 모델과 논문의 SSL 모델을 비교했을 때, severe AS를 예측하기 위해서:
- 둘 다 LA의 aortic valve를 집중적으로 본다.
- 그런데, 논문 모델 중 MI-SimCLR+FO이 더 일관적으로 국소화된 영역을 본다.
Conclusion
- Novel self-supervised learning method for echocardiogram videos를 제안한다.
- 아주 적은 양의 데이터만으로도 finetuning해서 severe AS를 예측할 수 있다.
- 논문 모델 중 MI-SimCLR+FO는 심초음파 영상이 가지고 있는 challege들에 대한 보완책을 제시한다.
- 메디컬 videos에 SSL을 적용한 최초의 paper이다.

바오바오바오바오바오
유익한 글이었습니다.