[논문] Self-supervised learning for medical image classification: a systematic review and implementation guidelines
논문
Title: Self-supervised learning for medical image classification: a systematic review and implementation guidelines
Journal: 2023 npj Digital Medicine
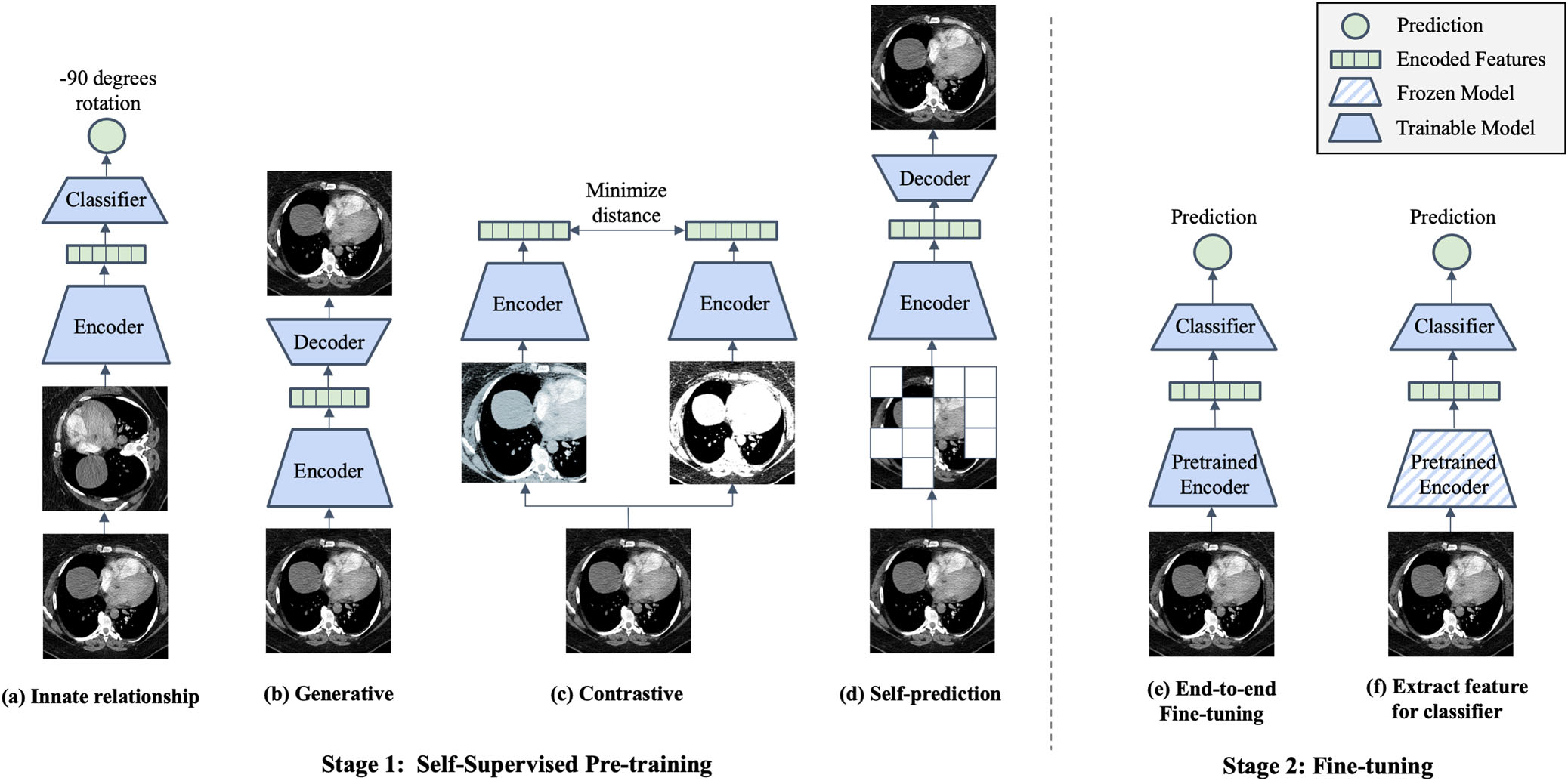
1) Pre-training
1. Innate relationship
Innate relationship SSL은 모델을 레이블링 없이 hand-crafted task에 대해 pre-training 해서 → 데이터의 internal structure를 학습한다. Task에 맞는 classification/regression loss를 최소화하며 최적화한다. Innate relationship pre-training으로 학습하는 visual feature는 hand-crafted task에는 효과적일지 몰라도, downstream task에서는 제한적이다. 예시로는 rotation, jigsaw puzzle, image patch relative position prediction이 있다.
Results
- 연구들에 사용된 innate relationship pretext tasks: Rotation prediction, Horizontal flip prediction, Reordering shuffled slices, Patch order prediction
- 두 개의 innate relationship pretext task (→ Slice order prediction, Geometric tranformation prediction)를 동시에 학습해봤더니 weight-sharing Siamese network가 두 개의 pre-training objective들을 합침으로써 싱글 모델보다 좋은 퍼포먼스를 냈다.
- 의료영상의 특징에 맞게 임상적으로 유의미한 pretext task를 정의하여 실험했다.
- 연구 1) gaze(시선)-point regression을 해서 → 초음파 비디오 프레임에서 초음파 검사자의 시선을 예측했다.
- 연구 2) 심초음파 영상의 시간적, 공간적 일관성을 사용해서 → 심장의 고유한 주기적 패턴과 밀접한 상관관계가 있는 심초음파의 특징을 만들었다.
- 결과적으로는 10개의 연구 중에서 supervised pre-training을 한 결과와 innate relationship pre-training을 한 결과를 비교했을 때, 8개의 연구에서 SSL이 더 높은 퍼포먼스를 보였다.
- 임상적으로 유의하게 정의한 pretext task를 썼을 때가 transformation 기반의 pretext task를 썼을 때보다 훨씬 더 높은 퍼포먼스를 보였다.
2. Generative
Generative SSL은 학습 데이터의 분포를 학습해서 → 입력을 reconstruction 하거나 새로운 synthetic data를 생성한다. 명시적인 레이블 없이 주어진 데이터만으로도 자동으로 latent representation을 학습할 수 있는게 장점이다. AE, VAE, GAN이 발전하면서 주목받았는데, AE는 인코더가 입력을 latent representation으로 변환하면 디코더가 다시 원래 이미지로 재구성한다. 최근에는 GAN을 SSL에 사용하기 시작해서 이전 연구들보다 좋은 성능을 보였다. 예시로는 GAN이 있다.
Results
- 연구 1) 병리이미지에 대해 입력 이미지와 함께 가지고 있던 image caption을 가지고 image captioning을 하는 pretext task를 정의했다. 이미지 인코딩에는 ResNet18을 썼고, representation은 trasnformer에 입력되어 image-captioning에 사용됐다. 이후에는 유방암 분류를 비롯한 여러 downstream task에 fine-tuning할 수 있었다. ⇒ Image + Image caption
- 연구 2) 뇌 fMRI 스캔의 연속된 chronology를 사용해서 pretext task를 정의했다. Pre-training 할 때 두 개의 모델을 사용했는데, 뇌의 passive image를 줬을 때 오토인코더로 뇌의 active fMRI 이미지를 생성하고, LSTM으로 다음 이미지를 예측하도록 하는 pretext task를 정의했다. 이후에는 학습된 representation을 가지고 fine-tuning할 때 PTSD를 예측하는 classifier를 학습했다.
3. Contrastive
Contrastive SSL은 이미지에 가하는 transformation 으로 인한 변형은 semantic meaning을 변질시키지는 않는다는 가정을 기반으로 한다. 따라서 같은 이미지로부터 augmentation해서 생성한 이미지들은 positive pair, 나머지는 negative pair라고 부른다. Contrastive model은 latent space에서 positive pair와의 거리는 가깝게, negative pair와의 거리는 멀게 만들며 최적화한다. 이때 사용하는 arbitrary distance metric은 contrastive loss에 함께 고려하여 사용한다. Similarity measure로는 contrastive learning에서 대부분 cosine distance를 사용하는데, scale-invariant하며 노이즈에 덜 민감하다는 장점이 있기 때문이다. 예시로는 SimCLR, MoCo, BYOL, SimSiam, DINO가 있다.
- Simple Framework for Contrastive Learning (SimCLR) → 적은 레이블링 데이터만으로도 supervised 모델들보다 좋은 성능을 냈지만, 좋은 성능을 위해서는 매우 큰 배치사이즈가 필요한데, 이는 충분한 수의 negative sample을 얻기 위해서이다.
- Momentum Contrast (MoCo) → 기존의 negative sample 확보 문제를 해결하기 위해 이 샘플들을 보관할 수 있는 momentum encoded queue를 제안했다.
Results
- 현재까지 의료 쪽에서 상당 수의 SSL 연구는 contrastive learning을 기반으로 했다. 그 중 가장 많이 사용된 모델은 SimCLR, MoCo, BYOL이다.
- 의료 도메인 prior를 활용해서 의료영상에 특화된 positive pair를 만드는 방법을 개발한 연구도 있다.
- 연구 1) 병리이미지에서 어떤 패치의 주변 패치들은 모두 비슷하기 때문에 pre-clustering으로 비슷하지 않은 패치를 찾을 수 있다. 이렇게 해서 비슷한 패치들끼리 positive pair를 구성한 것 같다. ⇒ Patch + Neighbor patch
- 연구 2) X-ray 영상과 거기에 대응되는 리포트를 매칭시키는 멀티모달 contrastive learning을 제안했다 (→ global image-sentence matching, local attention-based region-phrase matching). 이렇게 해서 이미지로부터의 representation과 text로부터의 representation을 positive pair로 구성했다. ⇒ Image + Clinical report
- 연구 3) 같은 이미지로부터 얻은 라디오믹스 feature와 딥러닝 feature로 positive pair를 구성했다. 추가로, 패치들 간 공간적 정보를 이용해서 tumor 영역에 근접한 패치들은 positive pair로, 멀리 있는 패치들은 negative pair로 구성했다. ⇒ Radiomics feature + Deep feature
- 연구 3) 환자의 메타데이터 (아마도 다이콤 정보)를 사용해서 positive pair를 구성했다. ⇒ Image + Meta data
4. Self-prediction
Self-prediction SSL은 입력 이미지의 일부를 무작위로 masking하거나 augmenting해서 → 나머지 멀쩡한 부분들을 가지고 원래 입력을 재구성한다. 원래 NLP 분야에서 SOTA인 Maksed Language Model (MLM) 으로 pre-training 하던게 비전으로 넘어와서 발전한 메소드이다. 비전에서의 시작은 NLP에서처럼 이미지의 패치를 랜덤하게 마스킹하거나 증강해서 CNN이 사라진 부분들을 재구성하게 하는거였다. 최근에는 ViT가 등장하면서 트랜스포머 기반의 방법이 많이 나왔고, ViT와 self-prediction pre-training objective를 결합한 메소드들이 여럿 등장해서 SOTA를 달성했다. Generative SSL처럼 reconstruction loss로 최적화하지만 둘의 다른 점은, self-prediction은 이미지의 일부에 변형을 가하고 변형되지 않은 나머지를 가지고 다시 일부를 재구성하지만, generative는 전체에 변형을 가하고 전체 이미지를 재구성한다. 예시로는 BERT Pre-Training of Image Transformers (BEiT), Masked Autoencoders (MAE)가 있다.
Results
- 이미지의 랜덤 패치에만 shuffling이 적용된다는 점에서 local-pixel shuffling도 self-prediction의 범주로 포함하였다.
- 연구 1) Local-pixel shuffling된 초음파 이미지를 U-Net을 인코더로 써서 복원하는 pretext task를 정의했다. 그리고 인코더의 출력과 임상적 특징 (나이, 성별, 종양 크기)와 결합해서 downstrean task에 사용했다.
- 연구 2) 세 개의 이미지 복원 task인 local-pixel shuffling, 프레임 내에서 pixel shuffling, 랜덤 픽셀들로 비디오 전체를 덮는 것을 pretext task로 정의했다.. 인코더와 디코더로는 U-Net 계열을 사용했다.
- 연구 3) 단일 CT 슬라이스 내에서 일부 작은 패치들을 바뀐 이미지를 복원하는 pretext task를 정의했다.
- 연구 4) rs-fMRI의 ROI pair에 대해 functional connectivity matrix를 만들어서 행렬의 행과 열을 랜덤으로 마스킹하고 복원하는 pretext task를 정의했다.
5. Combined approaches
Contrastive + Generative: 주로 contrastive learning과 generative learning을 섞는다. 그 중에서도 대부분의 연구가 contrastive model이랑 합칠 때 generative model로 오토인코더를 쓴다.
Contrastive + Innate Relationship: Contrasive learning과 innate relationship을 합친 연구도 있다. 사용된 innate relationship task로는 augmentation prediction, patch positioning, rotation prediction, ultrasound video to speech correspondence prediction이 있다.
Generative + Self-prediction: conditional GAN을 사용한 연구. 여기서 colorization, inpainting (→ self-prediction), super-resolution (→ generative)이 제너레이터 네트워크의 task로 사용되었다. 사용되는 task에 self-prediction과 generative 메소드가 모두 포함되어 있기 때문에 conditional GAN이 combined approach로 포함되었다.
Generative + Innate Relationship + Self-prediction: 세 가지 기법을 섞은 연구. 오토인코더를 학습시켜서 출력된 latent representation을 바탕으로 비슷한 외향의 인스턴스끼리 그룹화 한다. 그리고 이미지 패치를 랜덤으로 크롭해서 각 크롭된 패치에 pseudo label을 부여한다. 크롭된 패치들은 랜덤으로 뒤섞이고 복원을 위한 오토인코더가 pseudo label classification objective와 함께 학습된다.
Discussion
- 결론적으로 가장 많이 적용되고 비교되는 메소드는 SimCLR → AutoEncoder → MoCo 순이었다.
- 의료영상 classification에 있어서 자연 이미지에서 pre-train한 SSL 모델은 supervised pre-train한 모델보다 성능이 높다. 그리고 in-domain의 의료영상들로 SSL pre-training을 하면 성능이 가장 좋았다.
- Generic하고 large-scale의 supervised pre-trained model (BigTransfer 같은 모델)을 사용하면 domain-specific한 task에도 잘 작동함은 물론, 궁극적으로는 여러 의료 모달리티 이미징에도 좋은 퍼포먼스를 보일 수 있다.
- 여러 SSL 기법들을 결합해서 얻은 representation은 여러 의료 모달리티 이미징에서도 좋은 퍼포먼스를 보인다.
- 레이어 수가 더 늘어나거나 모델 전체가 fine-tuning되면 더 좋은 퍼포먼스를 보인다. 예를 들어, linear probing (extracted features + linear model)의 경우에는 MoCo > MAE 였지만, fine-tuning 레이어를 늘리자 MAE > MoCo 였다.
- Earlier 레이어에서 얻은 representation이 downstream classification task에 더 적합한 경우도 있다.
- SSL pre-training 데이터와 downstream task 데이터 사이의 domain shift 차이도 성능(→ linear separability를 말함)에 영향을 주는 요소이다.
- 결론적으로는 의료영상에 대해서는 end-to-end fine-tuning이 더 나은 퍼포머스를 보임을 확인했다. 그러나 end-to-end로 fine-tuning했을 때와 later layer들만 fine-tuning을 했을 때 어떤게 더 나은 퍼포먼스를 보이는지는 알 수 없다.
2) Fine-tuning
SSL은 task에 구애받지 않으며, 하나의 SSL pre-trained model이 있다면 그 모델로 classification, segmentation, object detection처럼 다양한 downstream task로 fine-tuning할 수 있다.
| Fine-tuning strategy | End-to-end | Extract feature for classifier |
|---|---|---|
| Pre-trained Encoder | Unfrozen→ Trainable | Frozen |
| Classifier | Unfrozen→ Trainable | Unfrozen→ Trainable |
End-to-end
인코더와 classifier의 모든 가중치가 unfrozen 상태이기 때문에 fine-tuning하면 supervised learning을 통해 최적화 될 수 있다.
Feature extraction
인코더의 가중치는 frozen되어 downstream classifier의 feature extractor로 사용되어 classifier는 trainable하다. 기존 연구들에서는 주로 trainable한 linear classifier (= linear probing)를 사용했지만, SVM과 K-NN처럼 어떠한 유형의 classifier나 구조도 사용될 수 있다.
[출처] Huang, SC., Pareek, A., Jensen, M. et al. Self-supervised learning for medical image classification: a systematic review and implementation guidelines. npj Digit. Med. 6, 74 (2023).

좋은 정보 감사합니다