프로젝트에서 사용자에게 실제 면접을 경험 시키기 위해 텍스트를 음성으로 변환
시키는 기술이 필요하다고 생각했다. 사람처럼 자연스럽게 음성이 나가고 지연시간도
최대한 짧은 기술이 필요하다고 판단했다.
TTS(Text-to-Speech)에도 다양한 기술들이 존재한다. TTS 기술을 찾아보던중
한가지 뉴스를 발견하였다. 한국에서 만든 신기술이 있다는것이였다.
"Nari labs Dia" 를 포함한 다양한 기술을 알아보고 비교후 선택하기로했다.
https://www.hankyung.com/article/2025050537461

TTS(Text-to-Speech) 란?
- 텍스트 데이터를 사람 목소리처럼 읽어주는 기술
- 사람이 읽는 것처럼 발음·억양·속도·감정을 합성해서 음성 파일을 생성함
TTS 기술 정리
| 기술 | 장점 | 단점 | AI 면접 서비스 적합성 |
|---|---|---|---|
| AWS Polly | - 다양한 언어·성별 지원 - 속도/톤 조절 가능 - AWS 서비스와 손쉬운 연동(S3, ECS 등) | - 감정 표현 제한적 - 최신 Neural TTS보다 자연스러움 떨어짐 | ✅ 높음: AWS 인프라 내에서 통합 운영 가능, 지연 시간 최소화 |
| Google Cloud TTS | - WaveNet 기반 자연스러운 발음 - 다양한 감정/억양 지원 | - 한국어 감정 표현 다소 제한 - Google Cloud 환경 의존 | ⚪ 중간: 품질은 좋지만 AWS 환경과 직접 연동 시 관리 포인트 증가 |
| Zonos / ElevenLabs | - 최신 AI 음성 합성으로 매우 자연스러움 - 감정·톤·발음 조절 세밀 - 사용자 몰입감 높음 | - 비용 상대적으로 높음 - 외부 API 호출 → 지연 발생 가능 | ✅ 높음(품질 기준): 몰입감 높은 면접 환경 가능, 다만 네트워크 지연 고려 필요 |
| Nari Labs | - 한국어 특화, 감정·억양 표현 우수 - 빠른 응답 속도 - 국내 환경 최적화 | - 글로벌 언어 지원 제한 - 해외 API 대비 기능 다양성 부족 | ✅ 높음(한국어 면접 기준): 자연스러운 발음과 감정 표현 가능, 국내 서버로 지연 최소화 |
- 기본적인 정리를 했지만 실제로 구축해보고 테스트를 해봐야 정확히 알수있을것이라고 생각했다.
- Google TTS 는 제외 시켰다. 왜냐하면 동시관리는 그럴수있지만 우리는 AWS 에서 운영을 하기로 했기때문에 AWS에 집중하여 완성도를 높이고싶었다.
AWS Polly 테스트
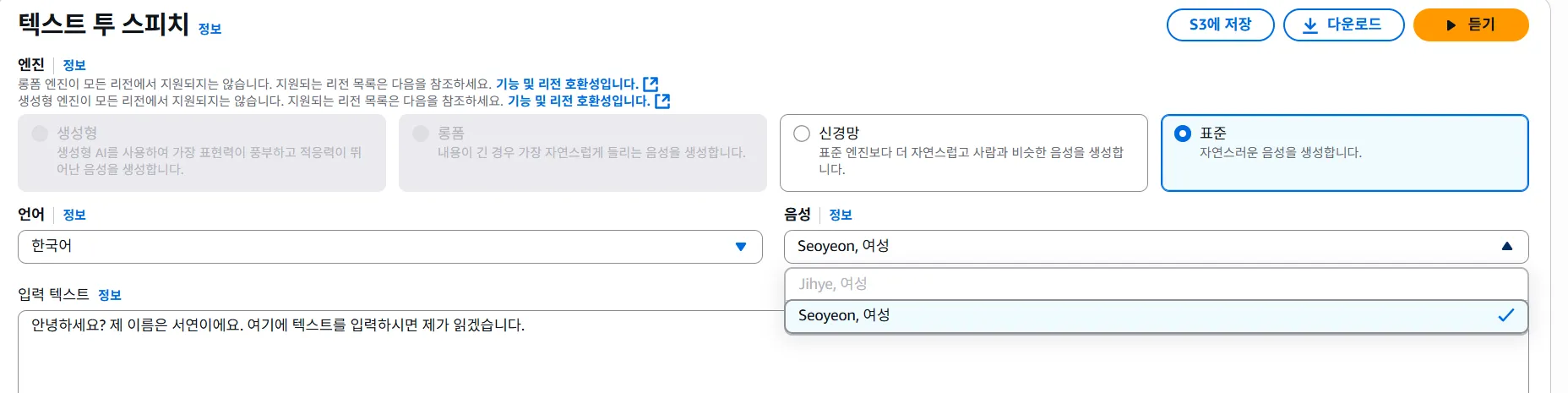
- 현재 Polly는 Seoyeon이라는 여성의 음성만이 가능한것을 확인했다.
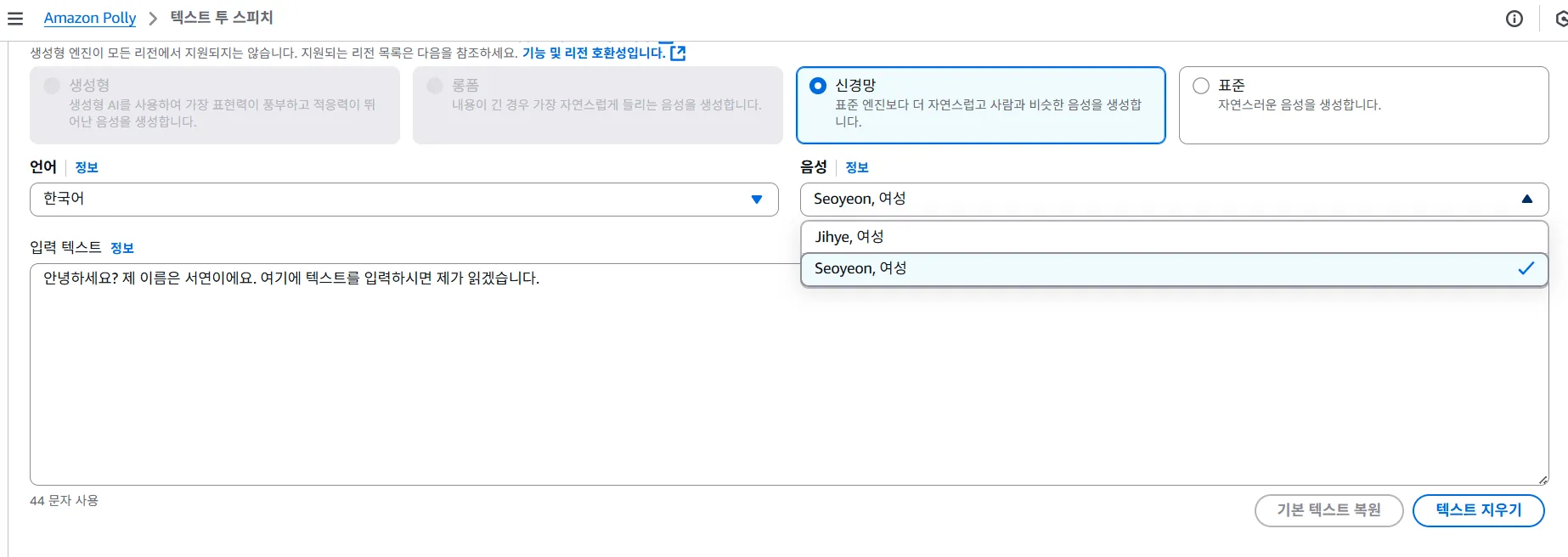
- NTTS(Neural Text-to-Speech) 에서는, Jihye도 선택이 가능하지만, 남성은 선택이 안됨
AWS Polly 를 제외한 이유
1. 음성 자연스러움 부족
- Neural TTS가 도입되었지만 최신 모델(Zonos, ElevenLabs)에 비해
감정·억양 표현이 단조로움. 면접관처럼 사람스러운 몰입감을 주기 어려움.
2. 목소리 다양성 제한
- 현재 한국어 기준 여성 목소리만 제공. 남성/다양한 톤의 목소리가 필요
한 면접 환경 재현이 힘듦.
3. 감정·억양 제어 한계
- 질문의 뉘앙스(친절, 엄격, 빠른 템포 등)를 세밀하게 조절하기 어려움.
면접 특유의 긴장감·자연스러움 구현에 제약.Nari Labs 테스트
- 테스트 목적
- 한국어 지원이 가능한지 확인 여부
- 텍스트를 넣었을 때 TTS가 가능한지 여부
- 이를 음성파일로 생성할 수 있는지 여부
- CPU 버전으로도 가능한지 여부
- 컨테이너(서버)로 실행해야하지만, API같은 호출로 TTS가 가능한지 여부
오픈소스 설치
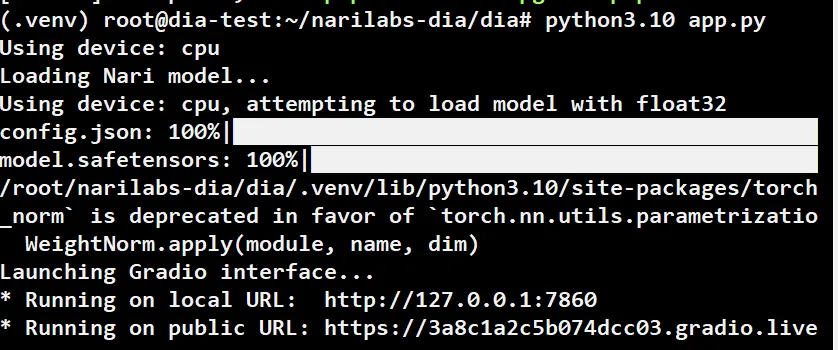
→ 이렇게 로딩이 완료되면 local에서 접속할 수 있는 URL과 외부에서도 접근할 수 있는 URL이 제공됨.
→ 우선적으로 외부에서 접근할 수 있는 URL을 통해서 테스트.
Gradio 웹에 접속해서 테스트
→ 이 방법은 Gradio UI에서 모델을 호출하고 음성파일을 생성하는 과정이 너무 크고 복잡해서 작업시간이 CPU로는 감당이 안됨.
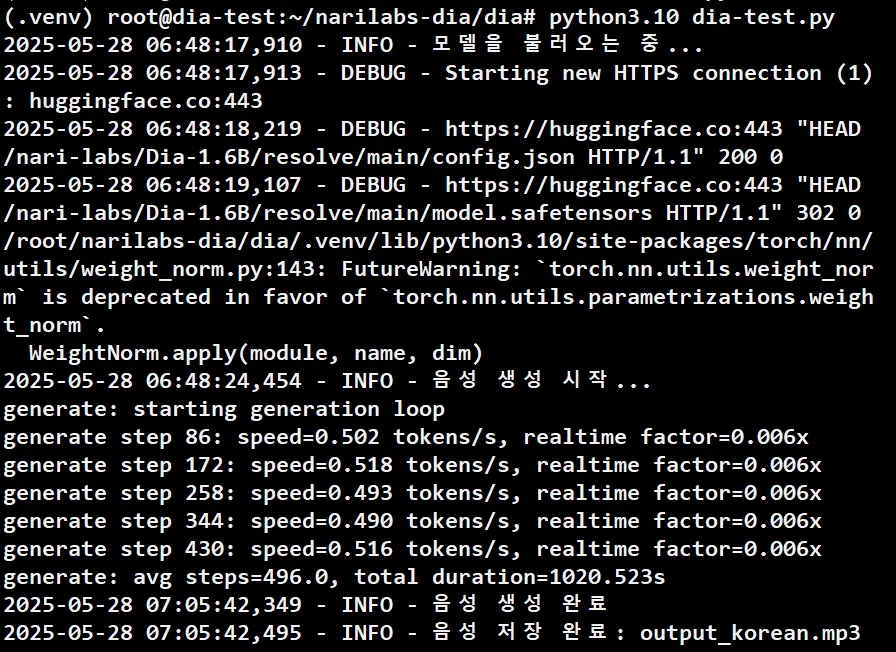
DIA 모델 호출 영어 테스트 결과
- 총 소요 시간 : 1020.523s ( 약 17분 )
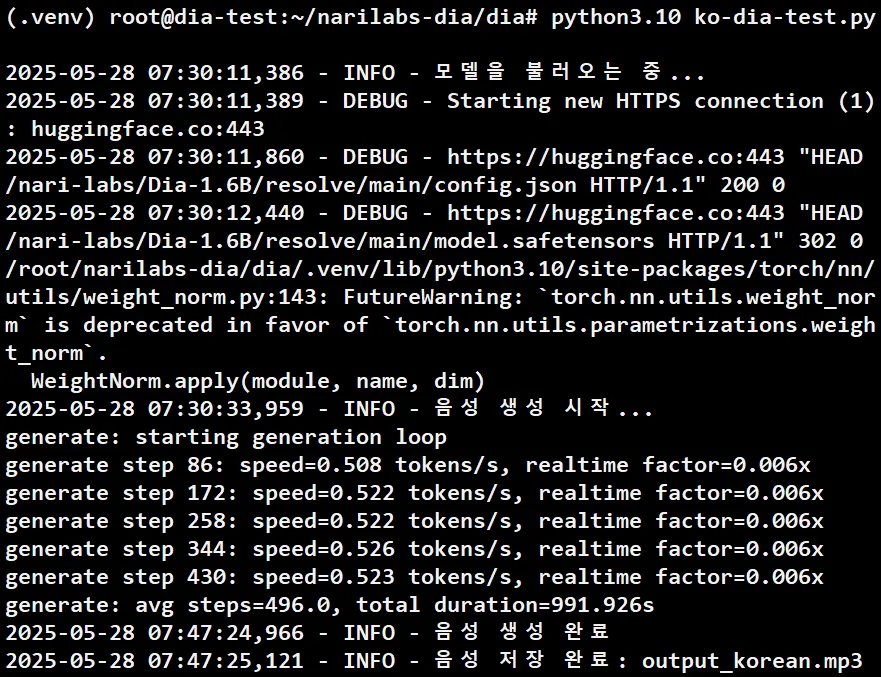
DIA 모델 호출 한국어 테스트 결과
- 총 소요시간 : 991.926s (약 16분 30초)
→ 한국어는 현재 인식을 하지 못하는 것 같음. 한국어에 대한 문제를 해결하는 방안 모색 필요.
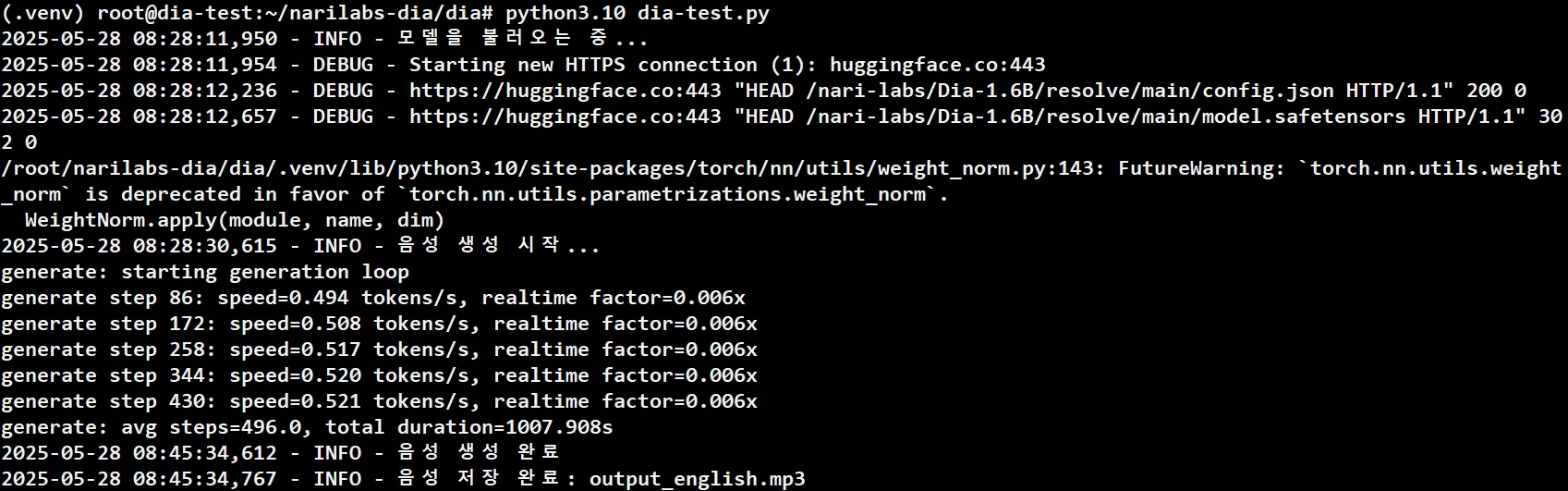
DIA 모델 호출 영어 + 웃음 테스트 결과
- 총 소요시간 : 1007.908 (약 16분 47초)
제외한 이유
- DIA 모델을 호출해서 텍스트-음성 변환을 사용해봄
- Gradio UI를 통해서도 가능하지만, API 형식으로 호출하는 방식을 사용할 것 같기 때문에 서버 형식으로 진행해봄.
- CPU환경에서 진행해서 속도가 매우 느림. 그리고 짧은 입력(오디오 5초 미만)은 자연스럽지 않게 들림. → 공식 Github 에도 나와있음.
- 영어는 음성 변환을 성공적이지만, 한국어는 인식자체를 못하고 있는 상황 → 아직 다국어는 미지원
- 비언어적 표현 태그를 사용했을 때 어느정도 잘 적용되는 것을 확인해봄.
Zonos 테스트
→ Gradio UI를 통해서 TTS 테스트
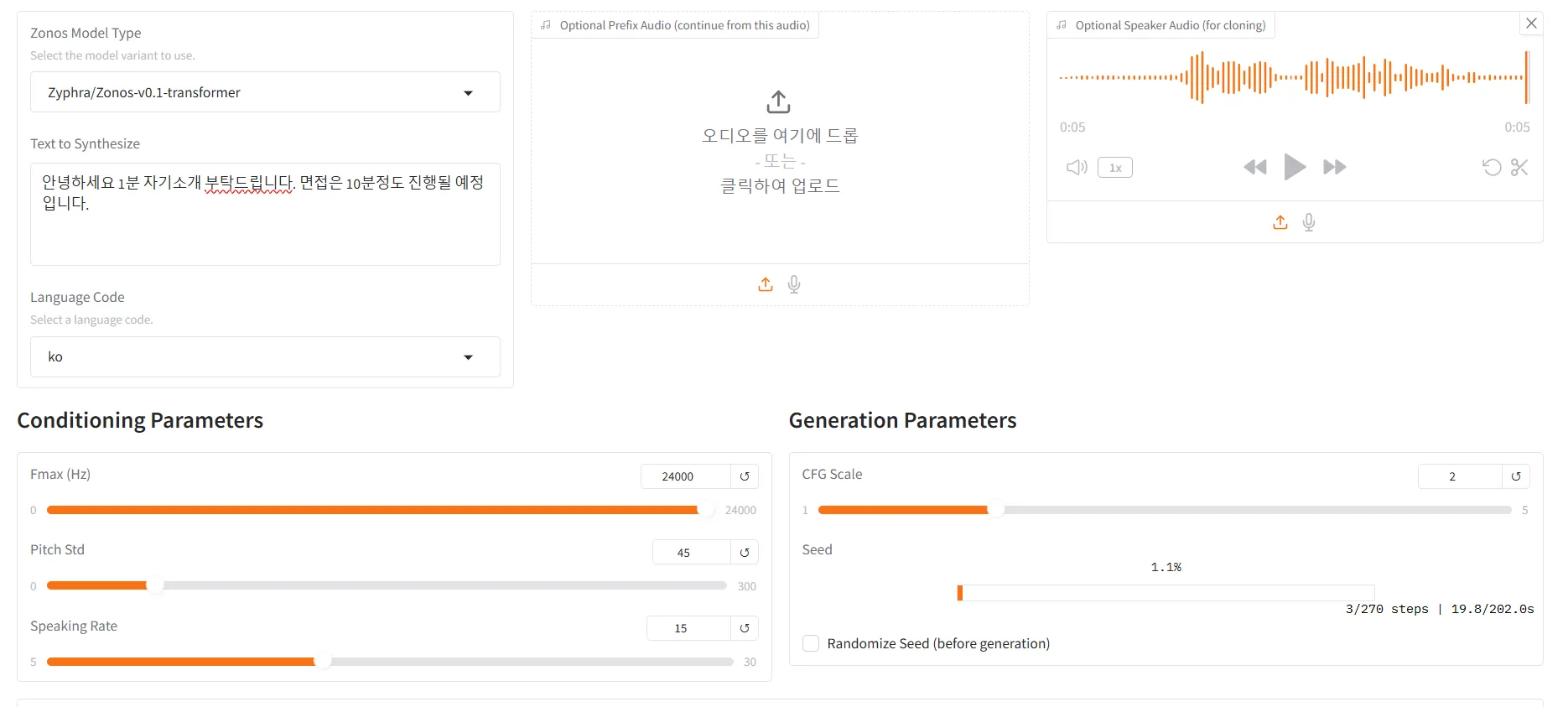
zonos 에 대해서
ZONOS는20만 시간 이상의 다국어 음성 데이터를 학습하여 다양한 언어와
감정을 표현할 수 있는 TTS 모델입니다.
사용자는 자신의 음성을 복제하거나, 텍스트에 감정을 부여하여 더욱 생동감 있는
음성을 생성할 수 있습니다. 이러한 기능은 개인화된 음성 비서,
오디오북 제작, 게임 캐릭터 음성 등 다양한 분야에서 활용될 수 있습니다.- 오픈 소스 기반 텍스트 음성 변환(TTS) 모델
- 자연스러운 TTS 모델을 사용하고자 함에 있어서 비용이 드는 Elevenlabs, Clover 등 보다 오픈 소스 기반 모델을 채택하고자 함.
- 제로샷 TTS 및 음성 복제
- 추가적인 학습 없이도 결과를 추론할 수 있는 제로샷이 가능한 모델이며, 30~40초 분량의 원본 음성 파일로 음성을 복제할 수 있는 보이스 클로닝 기능도 존재.
- 다국어 지원
- 영어,일본어,중국어,프랑스어, 독일어 등 여러 언어를 자연스러운 발음으로 지원. 가장 중요한 한국어를 지원하고 있고 다른 오픈소스 모델들과 비교했을 때 가장 자연스러운 품질을 제공하고 있다고 생각.
- 고급 제어 기능
- 말하는 속도, 음높이, 오디오 품질, 감정 표현 등을 세밀하게 조절할 수 있다는 장점. 행복, 슬픔, 분노, 두려움, 싫음, 등 세밀하게 조정 가능하고, 테스트는 안해보았지만 텍스트 입력에 오디오 프리픽스를 추가하여 화자의 특성을 강화하고, 속삭임과 같은 특별한 음성 효과를 구현할 수 있고 지역별 억양 적용도 가능하다고 합니다.
- 로컬 환경 지원
- 다른 모델들 보다 VRAM을 6GB 이상이면 로컬 환경에서도 손쉽게 구현가능. 현재 CPU도 돌렸을 때 기준으로 2분~3분 정도 소요 되는 것을 확인. GPU를 사용한다면 빠르게 구성 가능할 것이라고 생각함.
최종결론
"Zonos"를 선택하여 프로젝트를 진행하기로 하였다.
이유는
1.음성변환이 자유롭다.
2. 비용이 발생하지않는다.
3. 고급 제어가 가능하여 사용자에게 자연스러운 음성을 전달가능하다.
4. 다국어 지원
5. 음성 생성 속도 또만 2~3분 안에 나온다.
(생성속도를 더 빠르게 할수있는 방안으로 생각한뒤 적용하면 될것같다.)
꿈나무🌳