실제 면접을 가면 어떤 난이도의 질문이 들어올지 아무도 모른다. 그래서 난이도 조정으로 다양한 측면에서 연습이 가능하도록 하면 좋겠다고 생각을 하였다. 이렇게 난이도를 조정할수있다면 사용자 입장에서는 다양하게 연습이 가능하다고 판단했다.
목표
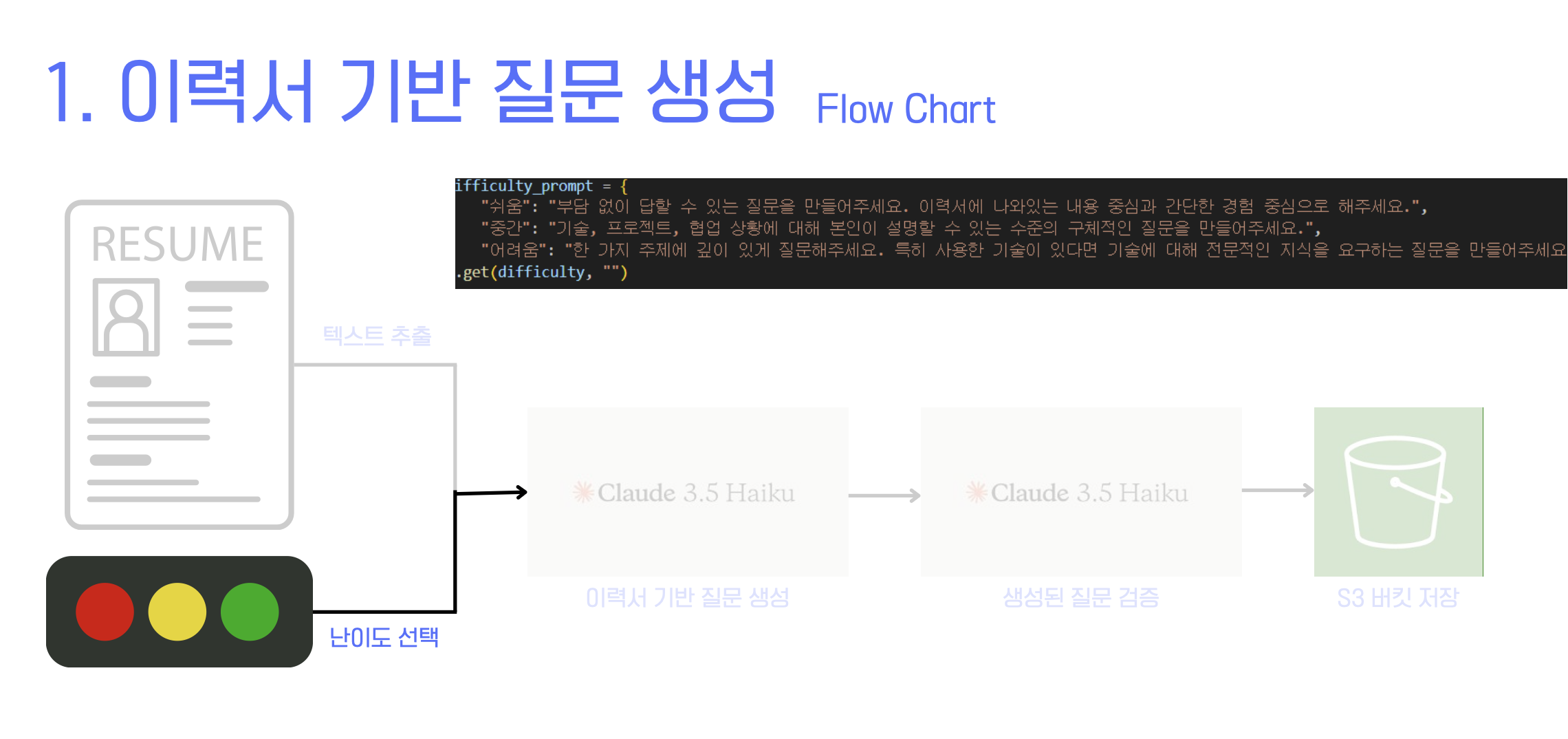
Bedrock(Claude 3 Haiku)을 이용해 이력서(PDF)를 읽고,
사용자가 고른 난이도(쉬움/중간/어려움)에 맞춰 질문 3개를 생성한 뒤
S3 버킷에질문1.txt… 형태로 저장하는 API 구현기.
전체 흐름
flowchart LR
A[사용자: 난이도 선택] --> B[API: /generate_resume_questions]
B --> C[S3: resumes/{user}/ 최신 PDF 조회]
C --> D[PDF Text 추출(PyPDF2)]
D --> E[Claude 3 Haiku: 1차 생성]
E --> F[Claude 3 Haiku: 2차 검증/정제]
F --> G[질문 3개 + 고정질문 합치기]
G --> H[S3: resume-questions/ 질문N.txt 저장]
H --> I[응답 반환(최종 질문 목록)]난이도별 지침 + 생성 프롬프트
difficulty_prompt = {
"쉬움": "부담 없이 답할 수 있는 질문을 만들어주세요. 자기소개, 간단한 경험 중심.",
"중간": "기술/프로젝트/협업에 대해 구체적으로 설명하도록 유도해 주세요.",
"어려움": "하나의 주제를 깊게 파고드는 질문. 한 문장에 여러 질문 금지."
}.get(difficulty, "")- LLM 모델에 어떻게 프롬프트를 작성하면 좋을지 생각을 했다. 위의 내용처럼 조건을 설정하면 난이도가 다르게 나왔다.
실무 팁(성능/비용/안정성)
비용/지연: Bedrock 호출 2회(생성→검증). 지연이 문제라면 검증을 키워드 필터 + 얕은 LLM으로 대체하는 하이브리드 고려.
PDF 품질: 추출 텍스트 품질이 저하되면 Tesseract OCR 등으로 보완.
레이트 리밋: 사용자별 난이도 변경 호출 빈도에 제한(예: 1분 1회).
로그: difficulty, raw_questions, verified_questions을 로그로 남겨 프롬프트 튜닝에 활용.
S3 권한: 버킷을 프라이빗으로 두고, 클라이언트에는 프리사인 URL만 전달.
에러 처리: PDF 없음(404), Bedrock 장애(5xx) 분리 처리 + 재시도/폴백.
내가 느낀 점
LLM이 생성하는 질문은 생각보다 자연스럽지만, 항상 이력서와 직접적인 관련이 있는 것은 아니었다.
난이도 프롬프트를 조금만 바꿔도 질문 톤이 크게 달라지는 걸 보며, 프롬프트 엔지니어링의 중요성을 다시 느꼈다.
주의해야 할 점
출력 형식 제어가 생각보다 어렵다. 번호를 붙이지 말라고 했는데도 가끔 붙여서 나오기도 했고,
줄바꿈 규칙을 어길 때도 있었다 → 따라서 검증 단계가 반드시 필요하다.
PDF 품질(스캔본 vs 텍스트 PDF)에 따라 Claude가 읽어낸 텍스트 정확도가 달라지므로, 전처리/추출 과정도 중요하다.
S3 저장 시 UTF-8 인코딩을 꼭 지정해야 한글이 깨지지 않는다.
깨달은 점
한 번의 LLM 호출만으로는 서비스 품질을 담보할 수 없다. → 생성(1차) + 검증(2차) 단계를 넣는 게 안정적이다.
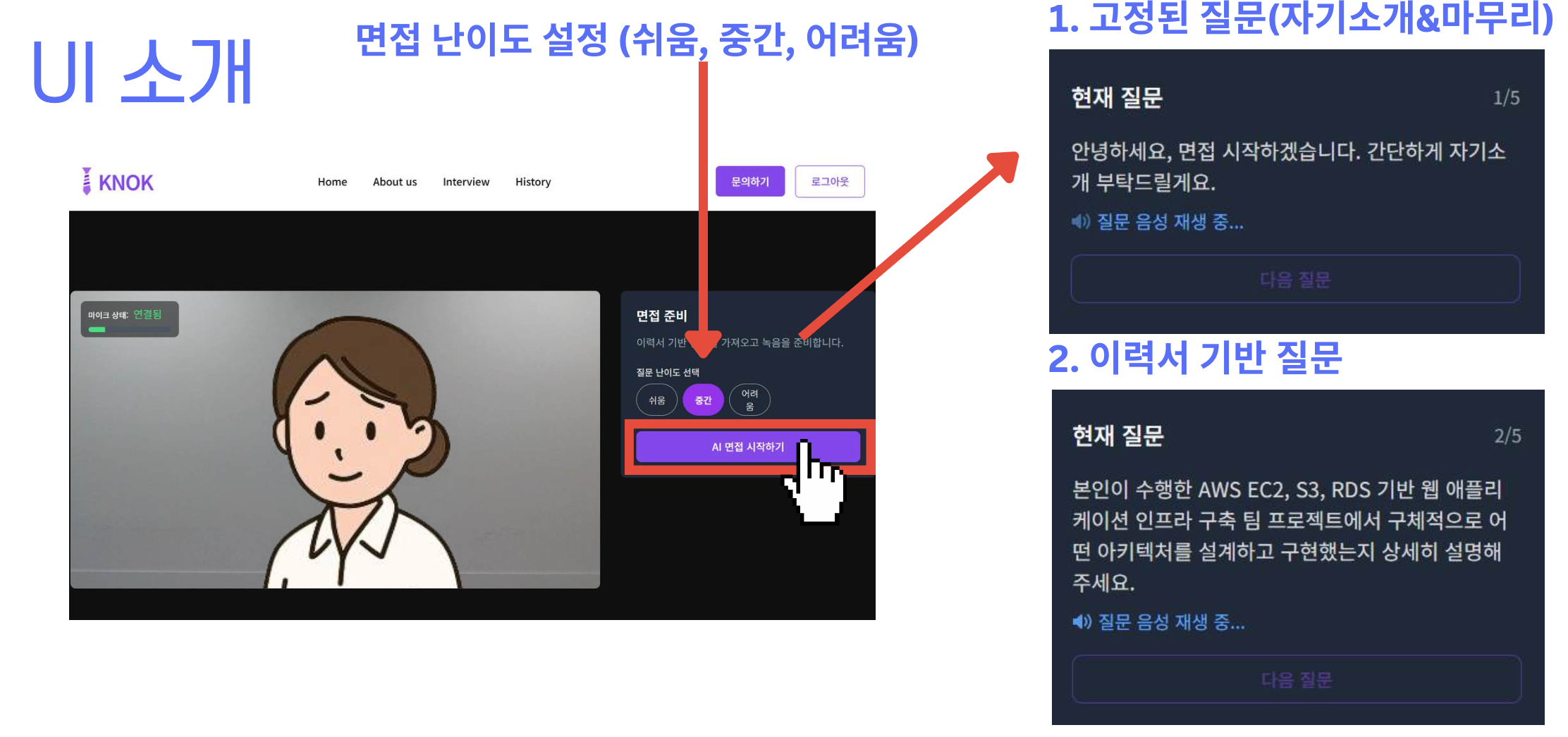
사용자가 직접 난이도를 선택할 수 있게 하면, 면접 경험의 개인화가 훨씬 강화된다.
단순히 기술 구현이 아니라, “면접자가 어떻게 느낄까?”를 고려하는 게 결국 서비스 성공의 핵심이라는 걸 깨달았다.
