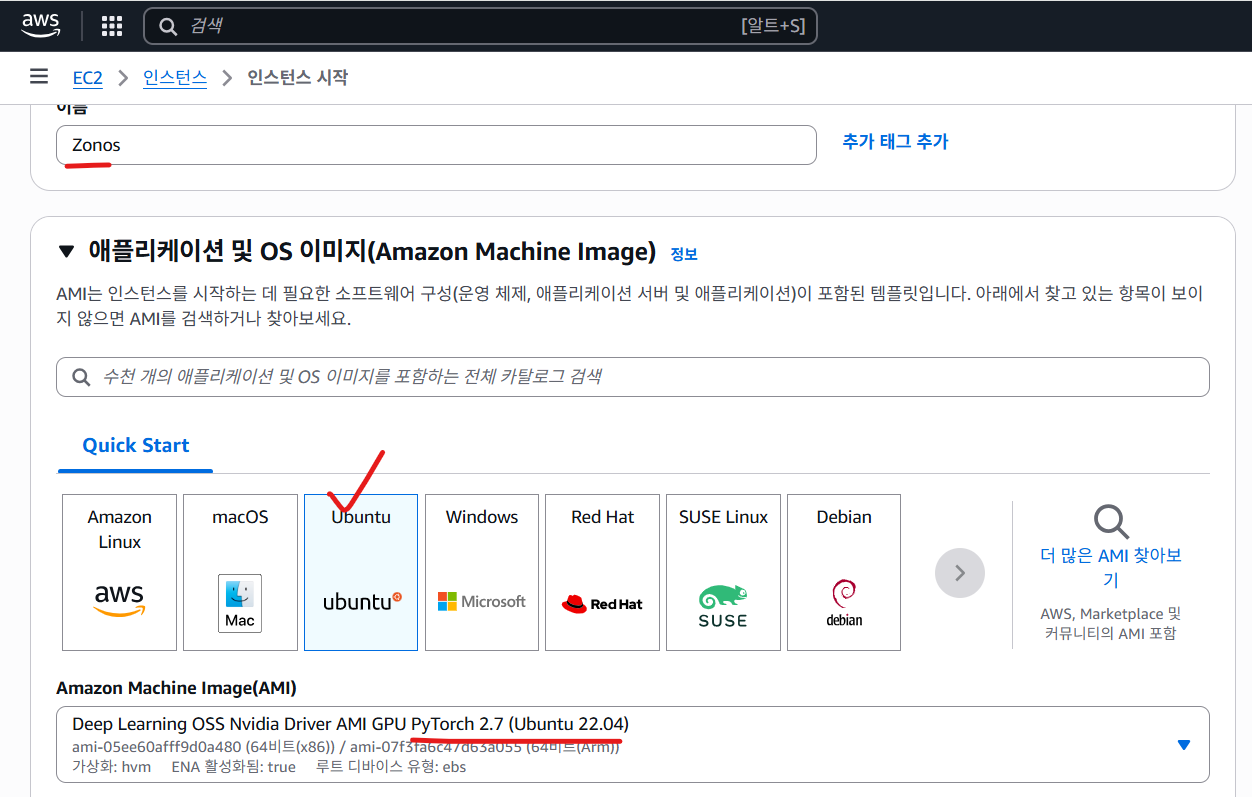
Zonos TTS 서버 구축기: AWS GPU 인스턴스부터 Django 연동, 성능 개선(V1→V2)
AI 면접 서비스에 고품질 한국어 TTS를 붙이기 위해 Zonos 모델을 GPU 인스턴스에서 구동하고,
Django API로 질문 음성을 생성해 S3에 업로드하는 흐름을 정리.
구축 중 겪은 스토리지 용량 이슈(300GiB 권장), 성능 병목, 코드 수정 포인트를 중심으로 기록.
인프라 준비: AWS GPU 인스턴스 생성
핵심 체크리스트
- GPU 지원 이미지/드라이버:
nvidia-smi가 동작해야 함 - 스토리지(EBS): 최소 300GiB 권장 (모델/의존성/캐시 다운로드 공간 부족 이슈 방지)
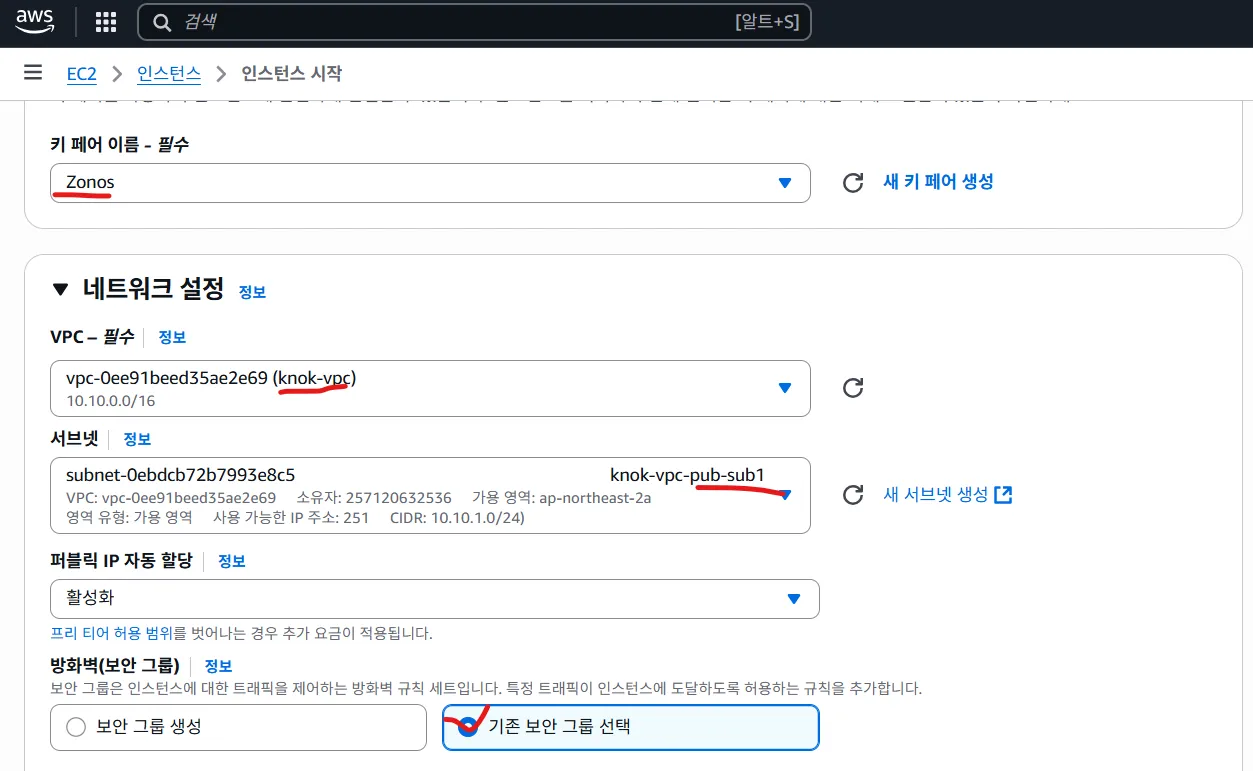
- 보안 그룹: 초기 테스트는
0.0.0.0/0로 열어도 되지만, 운영 전 필히 축소 - SSH 접속: 키 페어 확인, 고정 IP(Elastic IP) 고려
GPU 생성
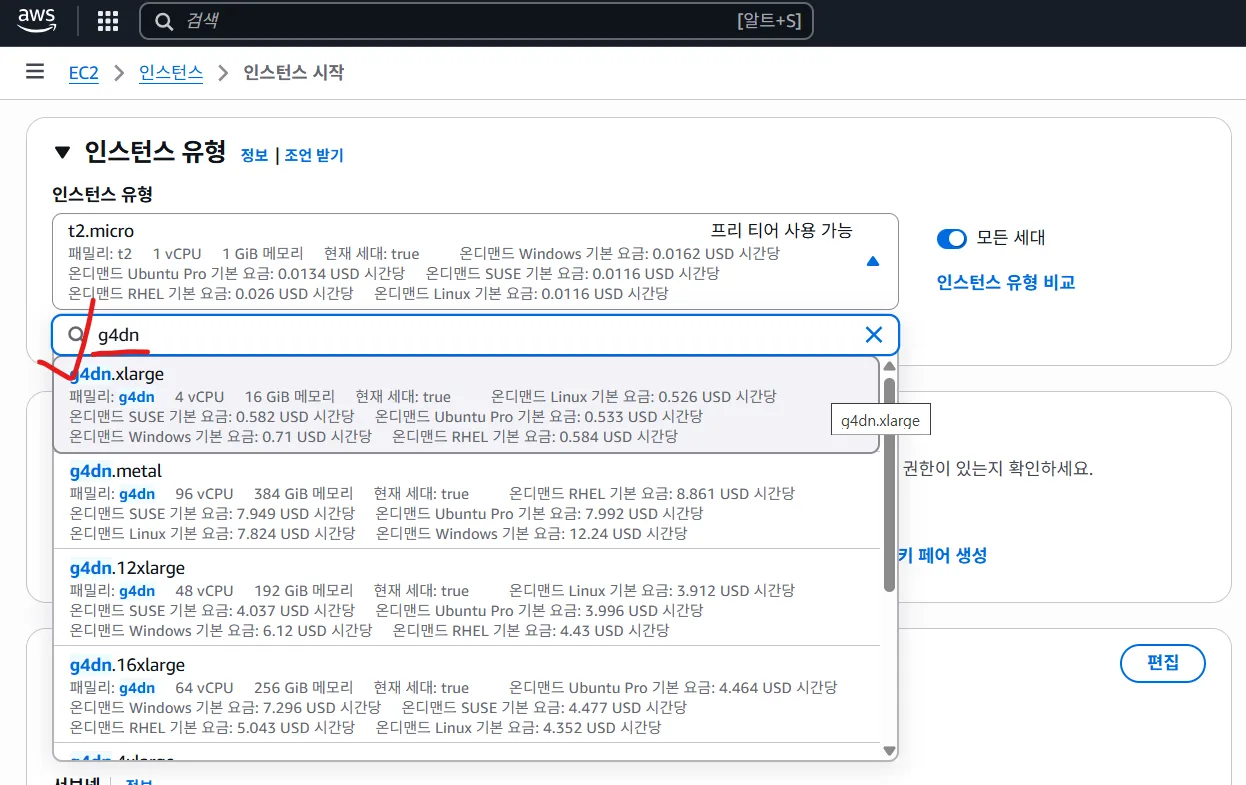
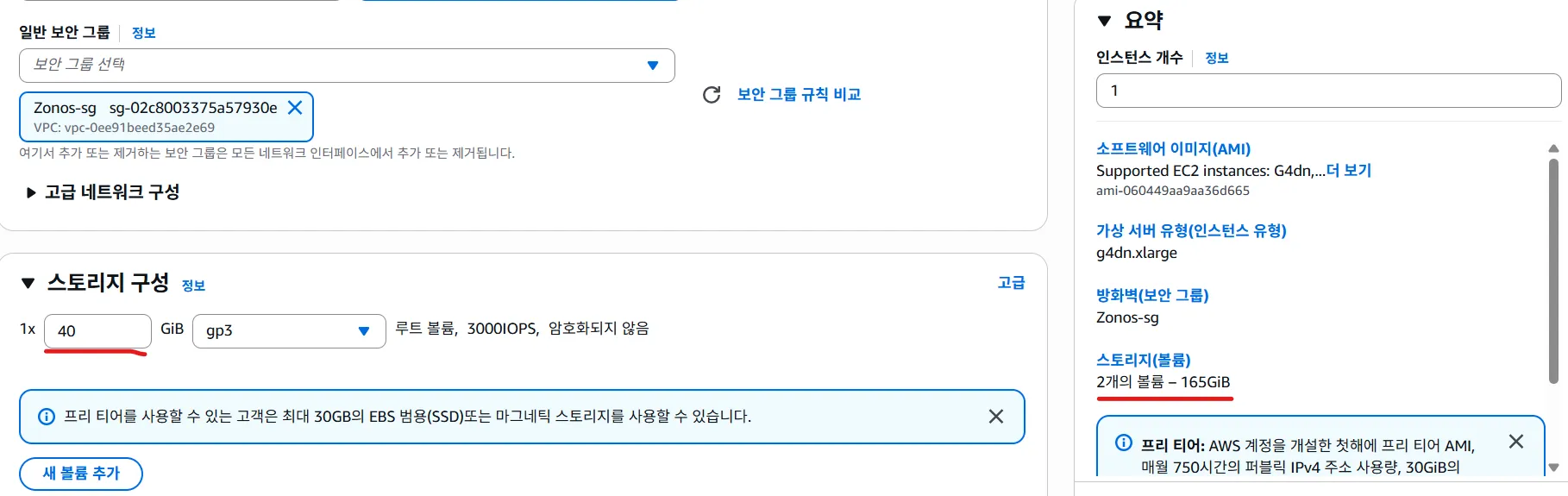
(300GIB로 변경해야 함.)
첫 시도
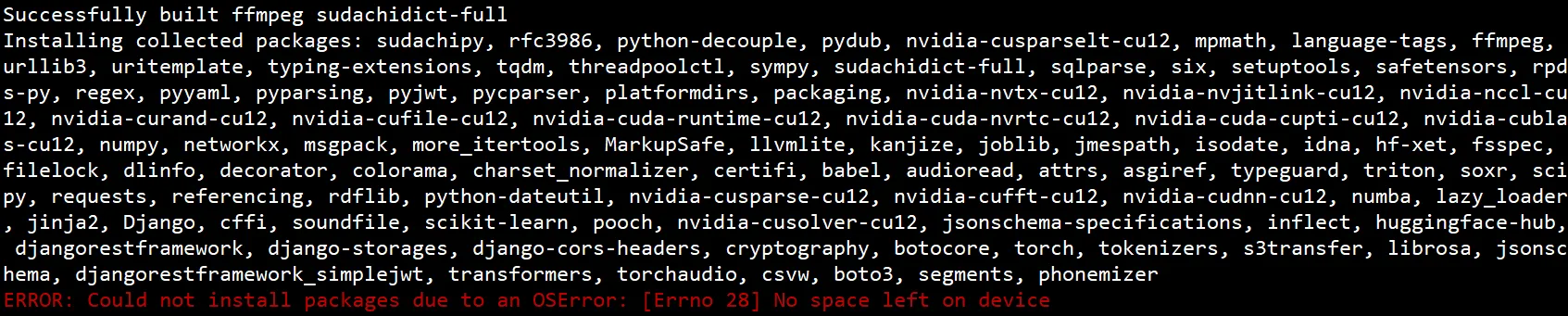
EBS 기본 용량(예: 165GiB)으로 진행했다가 패키지/모델 다운로드 중 용량 부족으로 실패 → 300GiB로 재생성하여 해결.
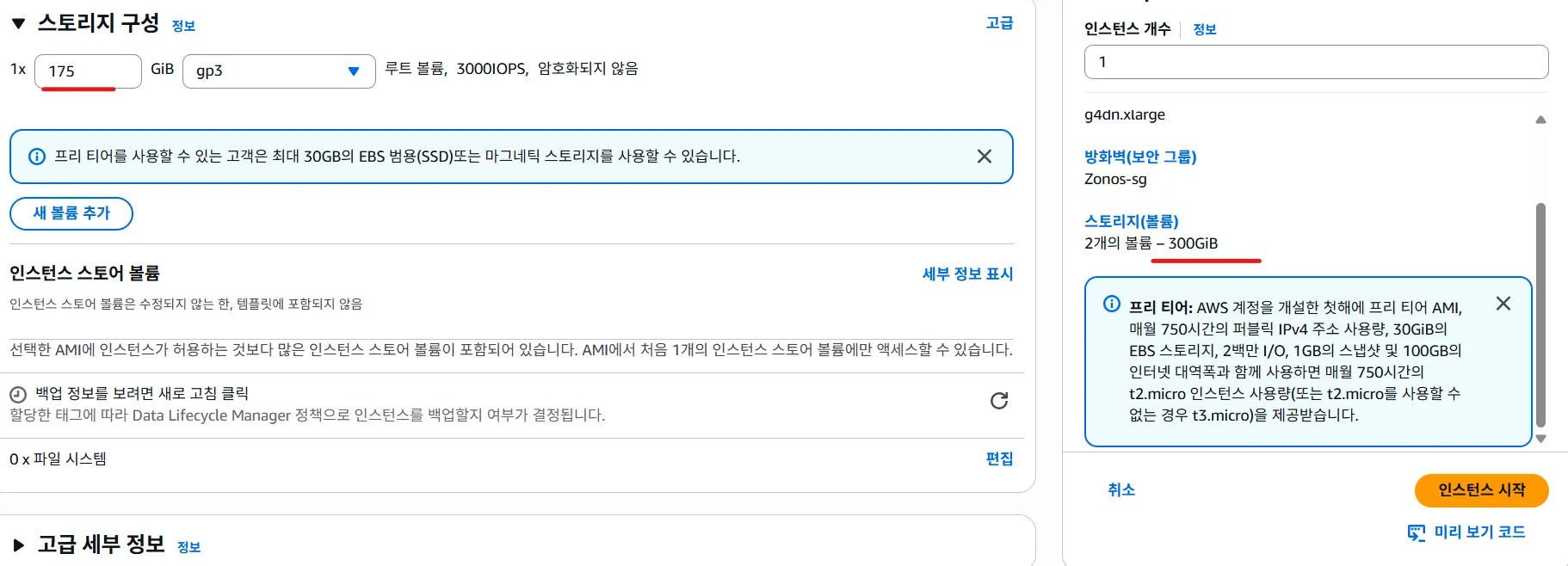 -> 용량을 300GIB로 늘려서 다시 시도
-> 용량을 300GIB로 늘려서 다시 시도
SSH 접속
ssh -i <YOUR_KEY>.pem ubuntu@<PUBLIC_IP>
사전 로딩한 모델 파일 전송
scp -i C:\Users\USER\Desktop\Key\knok-vpc\Zonos.pem -r C:\Users\USER\Desktop\model ubuntu@3.38.247.242:/home/ubuntu→ 내 로컬에 있는 model 파일을 GPU 인스턴스에 전송.

# in GPU instance
sudo -imv /home/ubuntu/model/ ~# pwd : /root
ls# result
root@ip-10-10-1-108:~# ls
model snap Zonos 모델 테스트
- espeak-ng 다운로드를 위한 명령어
apt update -y && apt install -y espeak-ngZonos 서버 동작을 위한 git clone 및 의존성 패키지 설치
git clone https://github.com/AIKNOK/Zonos-TTS.git
python -m venv venv
source venv/bin/activate
cd Zonos-TTS
vi .env
#################
# 파일 내용 입력 #
#################
pip install -r requirements.txt
which nvidia-smiGPU 여부 확인하는 명령어
# result
((venv) ) root@ip-10-10-1-108:~/Zonos-TTS# which nvidia-smi
/usr/bin/nvidia-smi- 설치가 되어있으면 위와 같이 나와야함.
nvidia-smi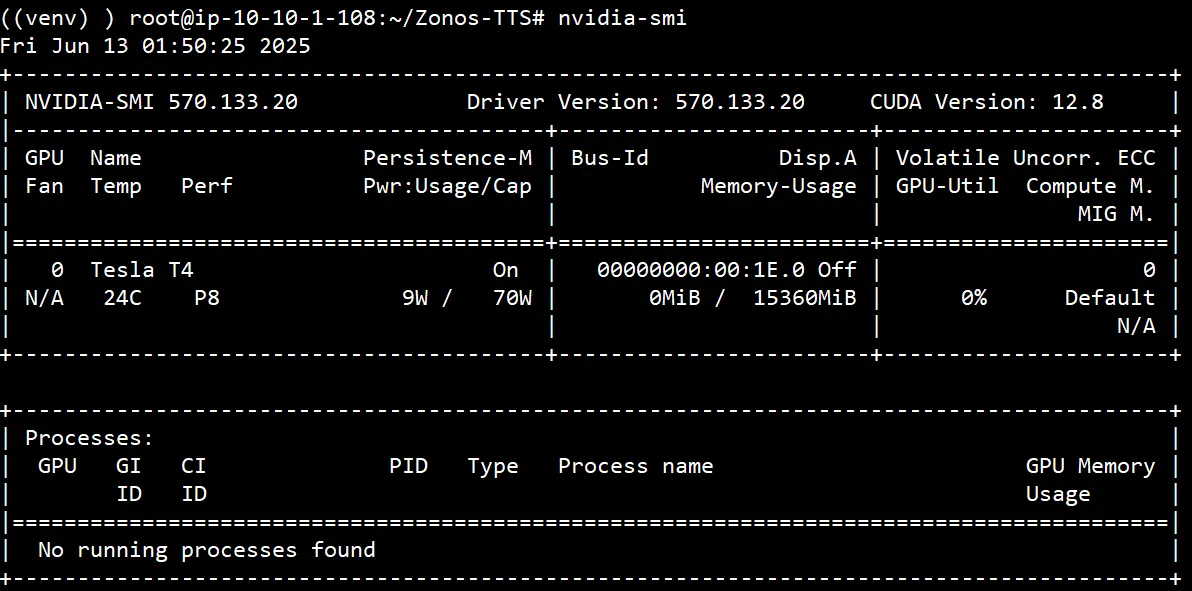 → 이렇게 GPU의 현재 존재 여부 및 사용 여부를 확인할 수 있음.
→ 이렇게 GPU의 현재 존재 여부 및 사용 여부를 확인할 수 있음.
python manage.py runserver 0.0.0.0:8002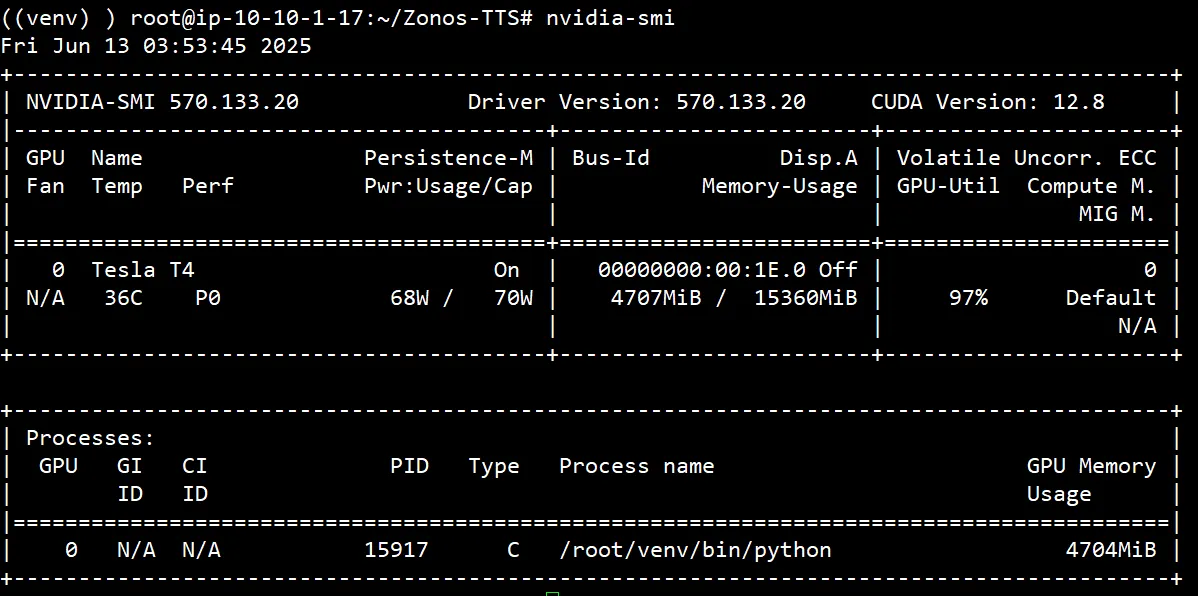
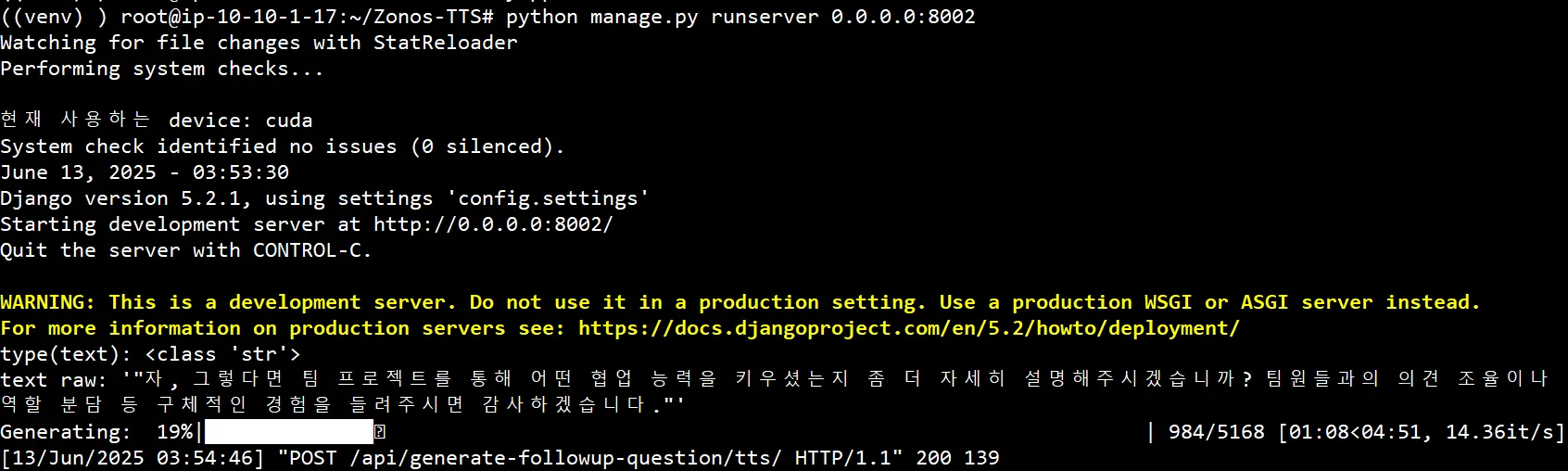
(시간이 너무 오래걸림..)
코드 수정사항
views.py
# Create your views here.
from rest_framework.decorators import api_view
from rest_framework.response import Response
from rest_framework.permissions import IsAuthenticated
from rest_framework.decorators import api_view, permission_classes
from datetime import datetime
import tempfile
import boto3
import torchaudio
import torch
import os
import io
import hmac
import hashlib
import base64
from zonos.model import Zonos
from zonos.conditioning import make_cond_dict
from zonos.utils import DEFAULT_DEVICE as device
from django.conf import settings
# from .models import Resume
from django.http import JsonResponse
# Create your views here.
# Zonos TTS 모델 로딩(로컬에서 1회만 실행할 수 있게 변경)
model = Zonos.from_pretrained("/root/model/models--Zyphra--Zonos-v0.1-transformer", device=device)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"현재 사용하는 device: {device}")
@api_view(['POST'])
@permission_classes([IsAuthenticated])
# @permission_classes([AllowAny]) # 인증 없이 Postman에서 테스트 가능
def generate_followup_question(request):
text = request.data.get('text')
question_number = request.data.get('question_number')
user = request.user
print("type(text):", type(text))
print("text raw:", repr(text))
if not text:
return Response({'error': 'text field is required'}, status=400)
try:
#torch._dynamo.reset()
#torch._dynamo.config.suppress_errors = True
#torch._dynamo.disable()
# 임시 음성 파일 로딩 (스피커 임베딩을 위한 샘플 음성)
# 실제 환경에서는 사용자의 음성을 업로드받거나 기본값 지정
audio_path = os.path.join(settings.BASE_DIR, "cloning_sample.wav")
speaker_wav, sampling_rate = torchaudio.load(audio_path)
speaker = model.make_speaker_embedding(speaker_wav, sampling_rate)
# 텍스트와 스피커 임베딩으로 conditioning 구성
cond_dict = make_cond_dict(
text=text,
speaker=speaker,
language="ko",
emotion=[0.15, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.8],
speaking_rate=23.0,
pitch_std=20.0,
)
conditioning = model.prepare_conditioning(cond_dict)
conditioning = conditioning.to(device)
# Zonos 모델로 음성 생성
#codes = model.generate(conditioning)
#wavs = model.autoencoder.decode(codes).cpu()
with torch.no_grad():
with torch.amp.autocast(device_type='cuda',enabled=True):
codes = model.generate(conditioning)
wavs = model.autoencoder.decode(codes).cpu()
# 메모리 버퍼 생성
buffer = io.BytesIO()
# 메모리 버퍼에 wav 저장
torchaudio.save(buffer, wavs[0], model.autoencoder.sampling_rate, format="wav")
buffer.seek(0) # 버퍼 위치 초기화
# S3 업로드
s3_client = boto3.client('s3')
bucket_name = settings.AWS_TTS_BUCKET_NAME
today = datetime.now().strftime("%m%d")
email_prefix = user.email.split('@')[0]
filename = f"질문 {question_number}.wav"
# s3_key = f'tts_outputs/{email_prefix}/{today}/{filename}' # 원하면 고유 이름으로 변경
s3_key = f'tts_outputs/{email_prefix}/{today}/{filename}' # 원하면 고유 이름으로 변경
s3_client.upload_fileobj(buffer, bucket_name, s3_key)
file_url = f'https://{bucket_name}.s3.amazonaws.com/{s3_key}'
response = {
"message": "TTS 생성 및 S3 업로드 성공",
"file_url": file_url
}
return Response(response, status=200)
except Exception as e:
return Response({'error': str(e)}, status=500)
@api_view(['POST'])
@permission_classes([IsAuthenticated])
def generate_resume_question(request):
bucket = settings.AWS_QUESTION_BUCKET_NAME
user_email = request.user.email.split('@')[0]
prefix = f"{user_email}/"
try:
s3 = boto3.client('s3')
response = s3.list_objects_v2(Bucket=bucket, Prefix=prefix)
files = sorted([obj['Key'] for obj in response.get('Contents', []) if obj['Key'].endswith('.txt')])
if not files:
return Response({"error": "No text files found in your S3 folder."}, status=404)
generated_files = []
for key in files:
# 텍스트 읽기
temp = tempfile.NamedTemporaryFile(delete=False, suffix=".txt")
s3.download_fileobj(Bucket=bucket, Key=key, Fileobj=temp)
temp.close()
with open(temp.name, 'r', encoding='utf-8') as f:
text = f.read().strip()
# --- 여기서 기존 tts_view 내부의 TTS 생성 로직 수행 ---
# (중복 방지를 위해 torch 설정 부분은 밖으로 빼는 게 좋음)
torch._dynamo.reset()
torch._dynamo.config.suppress_errors = True
torch._dynamo.disable()
audio_path = os.path.join(settings.BASE_DIR, "cloning_sample.wav")
speaker_wav, sampling_rate = torchaudio.load(audio_path)
speaker = model.make_speaker_embedding(speaker_wav, sampling_rate)
cond_dict = make_cond_dict(
text=text,
speaker=speaker,
language="ko",
emotion=[0.15, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.8],
speaking_rate=23.0,
pitch_std=20.0,
)
conditioning = model.prepare_conditioning(cond_dict)
codes = model.generate(conditioning)
wavs = model.autoencoder.decode(codes).cpu()
buffer = io.BytesIO()
torchaudio.save(buffer, wavs[0], model.autoencoder.sampling_rate, format="wav")
buffer.seek(0)
# S3 업로드
s3_client = boto3.client('s3')
bucket_name = settings.AWS_TTS_BUCKET_NAME
today = datetime.now().strftime("%m%d")
filename = f"{os.path.basename(key).replace('.txt', '')}.wav"
s3_key = f'tts_outputs/{user_email}/{filename}'
s3_client.upload_fileobj(buffer, bucket_name, s3_key)
file_url = f'https://{bucket_name}.s3.amazonaws.com/{s3_key}'
generated_files.append({"text_file": key, "tts_file_url": file_url})
return Response({
"message": "TTS 생성 및 S3 업로드 성공 (batch)",
"results": generated_files
}, status=200)
except Exception as e:
return Response({"error": str(e)}, status=500)
zonos/models.py
import json
from pathlib import Path
from typing import Callable
import safetensors
import torch
import torch.nn as nn
from huggingface_hub import hf_hub_download
from tqdm import tqdm
from zonos.autoencoder import DACAutoencoder
from zonos.backbone import BACKBONES
from zonos.codebook_pattern import apply_delay_pattern, revert_delay_pattern
from zonos.conditioning import PrefixConditioner
from zonos.config import InferenceParams, ZonosConfig
from zonos.sampling import sample_from_logits
from zonos.speaker_cloning import SpeakerEmbeddingLDA
from zonos.utils import DEFAULT_DEVICE, find_multiple, pad_weight_
DEFAULT_BACKBONE_CLS = next(iter(BACKBONES.values()))
class Zonos(nn.Module):
def __init__(self, config: ZonosConfig, backbone_cls=DEFAULT_BACKBONE_CLS):
super().__init__()
self.config = config
dim = config.backbone.d_model
self.eos_token_id = config.eos_token_id
self.masked_token_id = config.masked_token_id
self.autoencoder = DACAutoencoder()
self.backbone = backbone_cls(config.backbone)
self.prefix_conditioner = PrefixConditioner(config.prefix_conditioner, dim)
self.spk_clone_model = None
# TODO: pad to multiple of at least 8
self.embeddings = nn.ModuleList([nn.Embedding(1026, dim) for _ in range(self.autoencoder.num_codebooks)])
self.heads = nn.ModuleList([nn.Linear(dim, 1025, bias=False) for _ in range(self.autoencoder.num_codebooks)])
self._cg_graph = None
self._cg_batch_size = None
self._cg_input_ids = None
self._cg_logits = None
self._cg_inference_params = None
self._cg_scale = None
if config.pad_vocab_to_multiple_of:
self.register_load_state_dict_post_hook(self._pad_embeddings_and_heads)
def _pad_embeddings_and_heads(self, *args, **kwargs):
for w in [*self.embeddings, *self.heads]:
pad_weight_(w, self.config.pad_vocab_to_multiple_of)
@property
def device(self) -> torch.device:
return next(self.parameters()).device
# @classmethod
# def from_pretrained(
# cls, repo_id: str, revision: str | None = None, device: str = DEFAULT_DEVICE, **kwargs
# ) -> "Zonos":
# config_path = hf_hub_download(repo_id=repo_id, filename="config.json", revision=revision)
# model_path = hf_hub_download(repo_id=repo_id, filename="model.safetensors", revision=revision)
# return cls.from_local(config_path, model_path, device, **kwargs)
@classmethod
def from_pretrained(
cls, repo_id: str, revision: str | None = None, device: str = DEFAULT_DEVICE, **kwargs
) -> "Zonos":
path = Path(repo_id)
if path.exists():
# repo_id_or_path가 로컬 폴더 경로라면
config_path = path / "config.json"
model_path = path / "model.safetensors"
else:
# huggingface hub에서 다운로드
config_path = hf_hub_download(repo_id=repo_id, filename="config.json", revision=revision)
model_path = hf_hub_download(repo_id=repo_id, filename="model.safetensors", revision=revision)
return cls.from_local(config_path, model_path, device, **kwargs)
@classmethod
def from_local(
cls, config_path: str, model_path: str, device: str = DEFAULT_DEVICE, backbone: str | None = None
) -> "Zonos":
config = ZonosConfig.from_dict(json.load(open(config_path)))
if backbone:
backbone_cls = BACKBONES[backbone]
else:
is_transformer = not bool(config.backbone.ssm_cfg)
backbone_cls = DEFAULT_BACKBONE_CLS
# Preferentially route to pure torch backbone for increased performance and lower latency.
if is_transformer and "torch" in BACKBONES:
backbone_cls = BACKBONES["torch"]
model = cls(config, backbone_cls).to(device, torch.bfloat16)
model.autoencoder.dac.to(device)
sd = model.state_dict()
with safetensors.safe_open(model_path, framework="pt") as f:
for k in f.keys():
sd[k] = f.get_tensor(k)
model.load_state_dict(sd)
return model
def make_speaker_embedding(self, wav: torch.Tensor, sr: int) -> torch.Tensor:
"""Generate a speaker embedding from an audio clip."""
if self.spk_clone_model is None:
self.spk_clone_model = SpeakerEmbeddingLDA()
_, spk_embedding = self.spk_clone_model(wav.to(self.spk_clone_model.device), sr)
return spk_embedding.unsqueeze(0).bfloat16()
def embed_codes(self, codes: torch.Tensor) -> torch.Tensor:
return sum(emb(codes[:, i]) for i, emb in enumerate(self.embeddings))
def apply_heads(self, hidden_states: torch.Tensor) -> torch.Tensor:
return torch.stack([head(hidden_states) for head in self.heads], dim=1)
def _compute_logits(
self, hidden_states: torch.Tensor, inference_params: InferenceParams, cfg_scale: float
) -> torch.Tensor:
"""
Pass `hidden_states` into `backbone` and `multi_head`, applying
classifier-free guidance if `cfg_scale != 1.0`.
"""
last_hidden_states = self.backbone(hidden_states, inference_params)[:, -1, :].unsqueeze(1)
logits = self.apply_heads(last_hidden_states).squeeze(2).float()
if cfg_scale != 1.0:
cond_logits, uncond_logits = logits.chunk(2)
logits = uncond_logits + (cond_logits - uncond_logits) * cfg_scale
logits[..., 1025:].fill_(-torch.inf) # ensures padding is ignored
return logits
def _decode_one_token(
self,
input_ids: torch.Tensor,
inference_params: InferenceParams,
cfg_scale: float,
allow_cudagraphs: bool = True,
) -> torch.Tensor:
"""
Single-step decode. Prepares the hidden states, possibly replicates them
for CFG, and then delegates to `_compute_logits`.
Below we wrap this function with a simple CUDA Graph capturing mechanism,
doing 3 warmup steps if needed and then capturing or replaying the graph.
We only recapture if the batch size changes.
"""
# TODO: support cfg_scale==1
if cfg_scale == 1.0:
hidden_states = self.embed_codes(input_ids)
return self._compute_logits(hidden_states, inference_params, cfg_scale)
bsz = input_ids.size(0)
if not allow_cudagraphs or input_ids.device.type != "cuda":
hidden_states_local = self.embed_codes(input_ids)
hidden_states_local = hidden_states_local.repeat(2, 1, 1)
return self._compute_logits(hidden_states_local, inference_params, cfg_scale)
need_capture = (self._cg_graph is None) or (self._cg_batch_size != bsz)
if need_capture:
self._cg_graph = None
self._cg_batch_size = bsz
self._cg_inference_params = inference_params
self._cg_scale = cfg_scale
for _ in range(3):
hidden_states = self.embed_codes(input_ids)
hidden_states = hidden_states.repeat(2, 1, 1) # because cfg != 1.0
logits = self._compute_logits(hidden_states, inference_params, cfg_scale)
self._cg_input_ids = input_ids.clone()
self._cg_logits = torch.empty_like(logits)
g = torch.cuda.CUDAGraph()
def capture_region():
hidden_states_local = self.embed_codes(self._cg_input_ids)
hidden_states_local = hidden_states_local.repeat(2, 1, 1)
self._cg_logits = self._compute_logits(hidden_states_local, self._cg_inference_params, self._cg_scale)
with torch.cuda.graph(g):
capture_region()
self._cg_graph = g
else:
self._cg_input_ids.copy_(input_ids)
self._cg_graph.replay()
return self._cg_logits
def _prefill(
self,
prefix_hidden_states: torch.Tensor,
input_ids: torch.Tensor,
inference_params: InferenceParams,
cfg_scale: float,
) -> torch.Tensor:
"""
"Prefill" mode: we already have `prefix_hidden_states`, and we want
to append new embeddings, then compute the logits.
"""
# Replicate input_ids if CFG is enabled
if cfg_scale != 1.0:
input_ids = input_ids.expand(prefix_hidden_states.shape[0], -1, -1)
hidden_states = torch.cat([prefix_hidden_states, self.embed_codes(input_ids)], dim=1)
return self._compute_logits(hidden_states, inference_params, cfg_scale)
def setup_cache(self, batch_size: int, max_seqlen: int, dtype: torch.dtype = torch.bfloat16) -> InferenceParams:
max_seqlen = find_multiple(max_seqlen, 8)
key_value_memory_dict = self.backbone.allocate_inference_cache(batch_size, max_seqlen, dtype=dtype)
lengths_per_sample = torch.full((batch_size,), 0, dtype=torch.int32)
return InferenceParams(max_seqlen, batch_size, 0, 0, key_value_memory_dict, lengths_per_sample)
def prepare_conditioning(self, cond_dict: dict, uncond_dict: dict | None = None) -> torch.Tensor:
if uncond_dict is None:
uncond_dict = {k: cond_dict[k] for k in self.prefix_conditioner.required_keys}
return torch.cat(
[
self.prefix_conditioner(cond_dict),
self.prefix_conditioner(uncond_dict),
]
)
def can_use_cudagraphs(self) -> bool:
# Only the mamba-ssm backbone supports CUDA Graphs at the moment
return self.device.type == "cuda" and "_mamba_ssm" in str(self.backbone.__class__)
@torch.inference_mode()
def generate(
self,
prefix_conditioning: torch.Tensor, # [bsz, cond_seq_len, d_model]
audio_prefix_codes: torch.Tensor | None = None, # [bsz, 9, prefix_audio_seq_len]
max_new_tokens: int = 86 * 60,
# max_new_tokens = max(86 * 55, prefix_conditioning.shape[1] * 2),
cfg_scale: float = 2.0,
batch_size: int = 1,
sampling_params: dict = dict(min_p=0.1),
progress_bar: bool = True,
disable_torch_compile: bool = False,
callback: Callable[[torch.Tensor, int, int], bool] | None = None,
):
assert cfg_scale != 1, "TODO: add support for cfg_scale=1"
prefix_audio_len = 0 if audio_prefix_codes is None else audio_prefix_codes.shape[2]
device = self.device
# Use CUDA Graphs if supported, and torch.compile otherwise.
cg = self.can_use_cudagraphs()
decode_one_token = self._decode_one_token
# decode_one_token = torch.compile(decode_one_token, dynamic=True, disable=cg or disable_torch_compile)
decode_one_token = torch.compile(decode_one_token, dynamic=True, disable=True)
unknown_token = -1
audio_seq_len = prefix_audio_len + max_new_tokens
seq_len = prefix_conditioning.shape[1] + audio_seq_len + 9
with torch.device(device):
inference_params = self.setup_cache(batch_size=batch_size * 2, max_seqlen=seq_len)
codes = torch.full((batch_size, 9, audio_seq_len), unknown_token)
if audio_prefix_codes is not None:
codes[..., :prefix_audio_len] = audio_prefix_codes
delayed_codes = apply_delay_pattern(codes, self.masked_token_id)
delayed_prefix_audio_codes = delayed_codes[..., : prefix_audio_len + 1]
logits = self._prefill(prefix_conditioning, delayed_prefix_audio_codes, inference_params, cfg_scale)
next_token = sample_from_logits(logits, **sampling_params)
offset = delayed_prefix_audio_codes.shape[2]
frame = delayed_codes[..., offset : offset + 1]
frame.masked_scatter_(frame == unknown_token, next_token)
prefix_length = prefix_conditioning.shape[1] + prefix_audio_len + 1
inference_params.seqlen_offset += prefix_length
inference_params.lengths_per_sample[:] += prefix_length
logit_bias = torch.zeros_like(logits)
logit_bias[:, 1:, self.eos_token_id] = -torch.inf # only allow codebook 0 to predict EOS
stopping = torch.zeros(batch_size, dtype=torch.bool, device=device)
max_steps = delayed_codes.shape[2] - offset
remaining_steps = torch.full((batch_size,), max_steps, device=device)
progress = tqdm(total=max_steps, desc="Generating", disable=not progress_bar)
cfg_scale = torch.tensor(cfg_scale)
step = 0
while torch.max(remaining_steps) > 0:
offset += 1
input_ids = delayed_codes[..., offset - 1 : offset]
logits = decode_one_token(input_ids, inference_params, cfg_scale, allow_cudagraphs=cg)
logits += logit_bias
next_token = sample_from_logits(logits, generated_tokens=delayed_codes[..., :offset], **sampling_params)
eos_in_cb0 = next_token[:, 0] == self.eos_token_id
remaining_steps[eos_in_cb0[:, 0]] = torch.minimum(remaining_steps[eos_in_cb0[:, 0]], torch.tensor(9))
stopping |= eos_in_cb0[:, 0]
eos_codebook_idx = 9 - remaining_steps
eos_codebook_idx = torch.clamp(eos_codebook_idx, max=9 - 1)
for i in range(next_token.shape[0]):
if stopping[i]:
idx = eos_codebook_idx[i].item()
next_token[i, :idx] = self.masked_token_id
next_token[i, idx] = self.eos_token_id
frame = delayed_codes[..., offset : offset + 1]
frame.masked_scatter_(frame == unknown_token, next_token)
inference_params.seqlen_offset += 1
inference_params.lengths_per_sample[:] += 1
remaining_steps -= 1
progress.update()
step += 1
if callback is not None and not callback(frame, step, max_steps):
break
out_codes = revert_delay_pattern(delayed_codes)
out_codes.masked_fill_(out_codes >= 1024, 0)
out_codes = out_codes[..., : offset - 9]
# out_codes = out_codes[..., : offset - 9]
self._cg_graph = None # reset cuda graph to avoid cache changes
return out_codes
수정버전 - v1
V1 핵심 포인트
Zonos.from_pretrained()로 모델을 전역 1회 로드
요청마다 스피커 임베딩 재계산(개발 초기 편의)
torch.amp.autocast(cuda)로 FP16 연산 적용
결과 WAV를 S3 업로드 후 URL 반환
장점: 빠르게 동작 검증 가능
단점: 요청마다 스피커 임베딩 계산 → 지연/오버헤드views.py
# Create your views here.
from rest_framework.decorators import api_view
from rest_framework.response import Response
from rest_framework.permissions import IsAuthenticated
from rest_framework.decorators import api_view, permission_classes
from datetime import datetime
import tempfile
import boto3
import torchaudio
import torch
import os
import io
import hmac
import hashlib
import base64
from zonos.model import Zonos
from zonos.conditioning import make_cond_dict
from zonos.utils import DEFAULT_DEVICE as device
from django.conf import settings
# from .models import Resume
from django.http import JsonResponse
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"현재 사용하는 device: {device}")
# Create your views here.
# Zonos TTS 모델 로딩(로컬에서 1회만 실행할 수 있게 변경)
model = Zonos.from_pretrained("/root/model/models--Zyphra--Zonos-v0.1-transformer", device=device)
model.to(device)
model.eval()
model = torch.compile(model)
# 2) speaker embedding도 1회만 캐싱 (샘플 음성 고정)
audio_path = os.path.join(settings.BASE_DIR, "cloning_sample.wav")
speaker_wav, sampling_rate = torchaudio.load(audio_path)
speaker_embedding = model.make_speaker_embedding(speaker_wav, sampling_rate).to(device)
@api_view(['POST'])
@permission_classes([IsAuthenticated])
# @permission_classes([AllowAny]) # 인증 없이 Postman에서 테스트 가능
def generate_followup_question(request):
text = request.data.get('text')
question_number = request.data.get('question_number')
user = request.user
print("type(text):", type(text))
print("text raw:", repr(text))
if not text:
return Response({'error': 'text field is required'}, status=400)
try:
#torch._dynamo.reset()
#torch._dynamo.config.suppress_errors = True
#torch._dynamo.disable()
# 임시 음성 파일 로딩 (스피커 임베딩을 위한 샘플 음성)
# 실제 환경에서는 사용자의 음성을 업로드받거나 기본값 지정
#audio_path = os.path.join(settings.BASE_DIR, "cloning_sample.wav")
#speaker_wav, sampling_rate = torchaudio.load(audio_path)
#speaker = model.make_speaker_embedding(speaker_wav, sampling_rate)
# 텍스트와 스피커 임베딩으로 conditioning 구성
cond_dict = make_cond_dict(
text=text,
speaker=speaker,
language="ko",
emotion=[0.15, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.8],
speaking_rate=23.0,
pitch_std=20.0,
)
conditioning = model.prepare_conditioning(cond_dict).to(device)
# Zonos 모델로 음성 생성
#codes = model.generate(conditioning)
#wavs = model.autoencoder.decode(codes).cpu()
with torch.no_grad():
with torch.amp.autocast(device_type='cuda',enabled=True):
codes = model.generate(conditioning)
wavs = model.autoencoder.decode(codes).cpu()
# 메모리 버퍼 생성
buffer = io.BytesIO()
# 메모리 버퍼에 wav 저장
torchaudio.save(buffer, wavs[0], model.autoencoder.sampling_rate, format="wav")
buffer.seek(0) # 버퍼 위치 초기화
# S3 업로드
s3_client = boto3.client('s3')
bucket_name = settings.AWS_TTS_BUCKET_NAME
today = datetime.now().strftime("%m%d")
email_prefix = user.email.split('@')[0]
filename = f"질문 {question_number}.wav"
# s3_key = f'tts_outputs/{email_prefix}/{today}/{filename}' # 원하면 고유 이름으로 변경
s3_key = f'tts_outputs/{email_prefix}/{today}/{filename}' # 원하면 고유 이름으로 변경
s3_client.upload_fileobj(buffer, bucket_name, s3_key)
file_url = f'https://{bucket_name}.s3.amazonaws.com/{s3_key}'
response = {
"message": "TTS 생성 및 S3 업로드 성공",
"file_url": file_url
}
return Response(response, status=200)
except Exception as e:
return Response({'error': str(e)}, status=500)
@api_view(['POST'])
@permission_classes([IsAuthenticated])
def generate_resume_question(request):
bucket = settings.AWS_QUESTION_BUCKET_NAME
user_email = request.user.email.split('@')[0]
prefix = f"{user_email}/"
try:
s3 = boto3.client('s3')
response = s3.list_objects_v2(Bucket=bucket, Prefix=prefix)
files = sorted([obj['Key'] for obj in response.get('Contents', []) if obj['Key'].endswith('.txt')])
if not files:
return Response({"error": "No text files found in your S3 folder."}, status=404)
generated_files = []
for key in files:
# 텍스트 읽기
temp = tempfile.NamedTemporaryFile(delete=False, suffix=".txt")
s3.download_fileobj(Bucket=bucket, Key=key, Fileobj=temp)
temp.close()
with open(temp.name, 'r', encoding='utf-8') as f:
text = f.read().strip()
# --- 여기서 기존 tts_view 내부의 TTS 생성 로직 수행 ---
# (중복 방지를 위해 torch 설정 부분은 밖으로 빼는 게 좋음)
torch._dynamo.reset()
torch._dynamo.config.suppress_errors = True
torch._dynamo.disable()
audio_path = os.path.join(settings.BASE_DIR, "cloning_sample.wav")
speaker_wav, sampling_rate = torchaudio.load(audio_path)
speaker = model.make_speaker_embedding(speaker_wav, sampling_rate)
cond_dict = make_cond_dict(
text=text,
speaker=speaker,
language="ko",
emotion=[0.15, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.8],
speaking_rate=23.0,
pitch_std=20.0,
)
conditioning = model.prepare_conditioning(cond_dict)
codes = model.generate(conditioning)
wavs = model.autoencoder.decode(codes).cpu()
buffer = io.BytesIO()
torchaudio.save(buffer, wavs[0], model.autoencoder.sampling_rate, format="wav")
buffer.seek(0)
# S3 업로드
s3_client = boto3.client('s3')
bucket_name = settings.AWS_TTS_BUCKET_NAME
today = datetime.now().strftime("%m%d")
filename = f"{os.path.basename(key).replace('.txt', '')}.wav"
s3_key = f'tts_outputs/{user_email}/{filename}'
s3_client.upload_fileobj(buffer, bucket_name, s3_key)
file_url = f'https://{bucket_name}.s3.amazonaws.com/{s3_key}'
generated_files.append({"text_file": key, "tts_file_url": file_url})
return Response({
"message": "TTS 생성 및 S3 업로드 성공 (batch)",
"results": generated_files
}, status=200)
except Exception as e:
return Response({"error": str(e)}, status=500)

수정버전 v2.
V2 개선 포인트 (권장)
모델 전역 로딩 + eval + to(device) 유지
**torch.compile(model)**로 런타임 최적화(드라이버/환경 호환 이슈 시 해제 가능)
스피커 임베딩 1회 캐싱 → 요청당 재사용
오토캐스트 dtype 지정: torch.float16
전역 S3 클라이언트 캐싱
settings.ALLOWED_HOSTS = ['*'] (개발/테스트 한정)
→ 운영 시 허용 도메인/아이피만 명시# config.setting.py
# ...
ALLOWED_HOST ['*'] # <- 안하면 보안 오류 발생, 테스트만 '*'이고 추후에 요청받는 HOST 명시해줘야함.
# ...python manage.py migrateV2 요약 버전
# settings.py (개발)
ALLOWED_HOSTS = ['*'] # 운영에서는 반드시 제한하세요.
# views.py
s3_client = boto3.client('s3')
bucket_name = settings.AWS_TTS_BUCKET_NAME
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = Zonos.from_pretrained("/root/model/models--Zyphra--Zonos-v0.1-transformer", device=device)
model.eval().to(device)
model = torch.compile(model) # 환경에 따라 비활성화 고려
# 스피커 임베딩 캐싱 (1회)
audio_path = os.path.join(settings.BASE_DIR, "cloning_sample.wav")
speaker_wav, sampling_rate = torchaudio.load(audio_path)
speaker_embedding = model.make_speaker_embedding(speaker_wav, sampling_rate).to(device)
@api_view(['POST'])
@permission_classes([IsAuthenticated])
def generate_followup_question(request):
text = request.data.get('text')
question_number = request.data.get('question_number')
if not text:
return Response({'error': 'text field is required'}, status=400)
cond_dict = make_cond_dict(
text=text,
speaker=speaker_embedding, # 캐싱된 임베딩 사용
language="ko",
emotion=[0.15, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.8],
speaking_rate=23.0,
pitch_std=20.0,
)
conditioning = model.prepare_conditioning(cond_dict).to(device)
with torch.no_grad():
with torch.amp.autocast(device_type='cuda', enabled=True, dtype=torch.float16):
codes = model.generate(conditioning)
wavs = model.autoencoder.decode(codes).cpu()
buf = io.BytesIO()
torchaudio.save(buf, wavs[0], model.autoencoder.sampling_rate, format="wav")
buf.seek(0)
today = datetime.now().strftime("%m%d")
email_prefix = request.user.email.split('@')[0]
s3_key = f'tts_outputs/{email_prefix}/{today}/질문 {question_number}.wav'
s3_client.upload_fileobj(buf, bucket_name, s3_key)
url = f'https://{bucket_name}.s3.amazonaws.com/{s3_key}'
return Response({"message": "OK", "file_url": url})
마무리 및 다음 계획
현재 상태: GPU 인스턴스에서 Zonos TTS가 구동되고, Django API로 질문 음성 생성 → S3 업로드가 자동화됨. V2 기준으로 지연/안정성이 개선됨.
다음 단계
질문/꼬리질문 TTS 배치 생성 안정화 및 큐잉(예: Celery)
S3 객체에 수명 주기 정책 적용(임시 파일 자동 삭제)
프리사인 URL로 보안 강화
클라이언트 캐싱 전략(재생 지연 최소화)
실서비스에서는 성능(지연/처리량) 지표를 꾸준히 수집해 병목을 정확히 파악하고,
모델/인프라/코드 레벨에서 작은 개선을 반복하는 것이 핵심입니다.

꿈나무🌳