질문 번호 부여와 S3 병합
AI 면접 서비스에서는 크게 두 가지 질문이 존재한다. 1. **이력서 기반 질문** → S3 버킷에 저장 2. **꼬리 질문** → 기존에는 저장하지 않고 바로 제공 --- 문제가 된 것은, 이렇게 관리하면 **사용자에게 질문/답변 히스토리를 정리해서 보여주기 어렵다**는 점이었다. 또한, 질문 번호 체계(예: `1, 2, 3, 1-1, 1-2`)가 모호해 관리가 불편했다.
문제
- 꼬리 질문도 저장하지 않으면 질문/답변 히스토리 관리 불가능
- 번호 체계가 일관되지 않아 질문 순서가 꼬임
- 결과적으로 사용자 리포트나 재현 기능에서 불편 발생 해결 방법 확인
- **꼬리 질문도 별도 S3 버킷에 저장**
- **질문 번호 자동 생성 규칙** 추가
- **모든 질문(이력서 기반 + 꼬리 질문)**을 순서대로 병합하여 제공 구현
(1) 꼬리 질문 저장 로직
꼬리 질문이 생성되면 자동으로 번호를 부여(`기본 질문 번호-1, -2 ...`)하고,
별도의 버킷(`knok-followup-questions`)에 텍스트 파일로 저장한다.
```python
@api_view(["POST"])
@permission_classes([IsAuthenticated])
def decide_followup_question(request):
...
# Claude로 follow-up 질문 생성
followup = get_claude_followup_question(prompt)
# 번호 생성 규칙
def next_followup_number(existing_numbers, base_number):
suffixes = [
int(num.split("-")[1])
for num in existing_numbers
if num.startswith(f"{base_number}-") and "-" in num
]
next_num = max(suffixes, default=0) + 1
return f"{base_number}-{next_num}"
new_number = next_followup_number(existing_question_numbers, base_question_number)
# S3에 저장
s3.put_object(
Bucket='knok-followup-questions',
Key=f"{email_prefix}/질문{new_number}.txt",
Body=followup.encode('utf-8'),
ContentType='text/plain'
)
return Response({"number": new_number, "text": followup})(2) 질문 병합 로직
이력서 기반 질문과 꼬리 질문을 번호 순서에 맞게 병합해서 반환한다.
정렬 기준은 숫자 및 하위 번호(1, 2, 2-1, 2-2 ...) 순이다.
@api_view(['GET'])
@permission_classes([IsAuthenticated])
def get_all_questions_view(request):
...
base_questions = fetch_questions('resume-questions')
followup_questions = fetch_questions('knok-followup-questions')
merged = {**base_questions, **followup_questions}
sorted_merged = dict(sorted(
merged.items(),
key=lambda x: [int(part) if part.isdigit() else part for part in x[0].split('-')]
))
return Response({"questions": sorted_merged})테스트 결과
1.꼬리 질문 생성 시 번호가 자동 부여됨
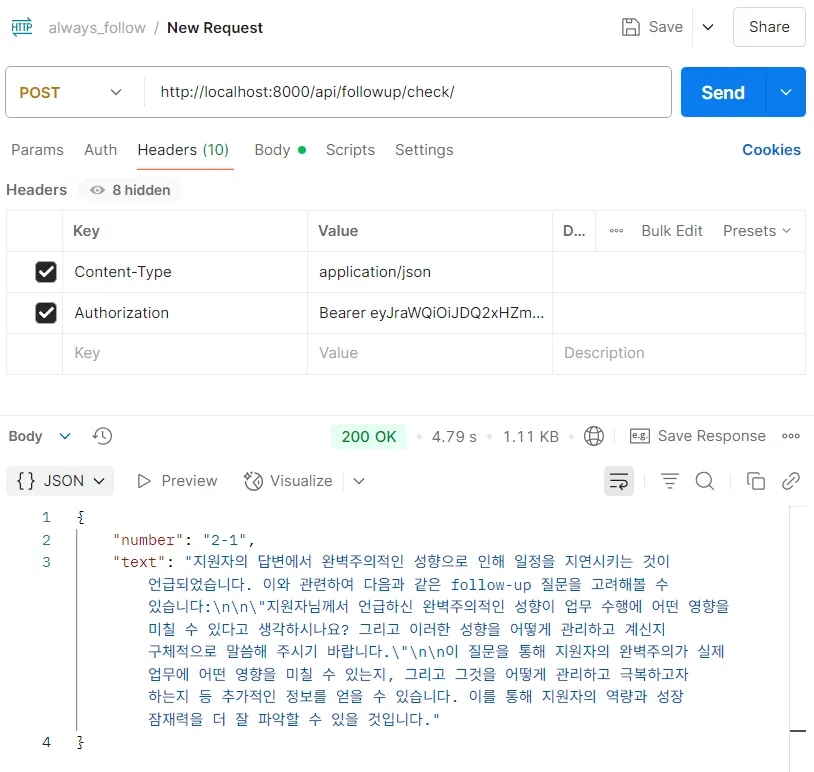
2. 이력서 기반 질문과 꼬리 질문이 병합되어 순서대로 제공됨
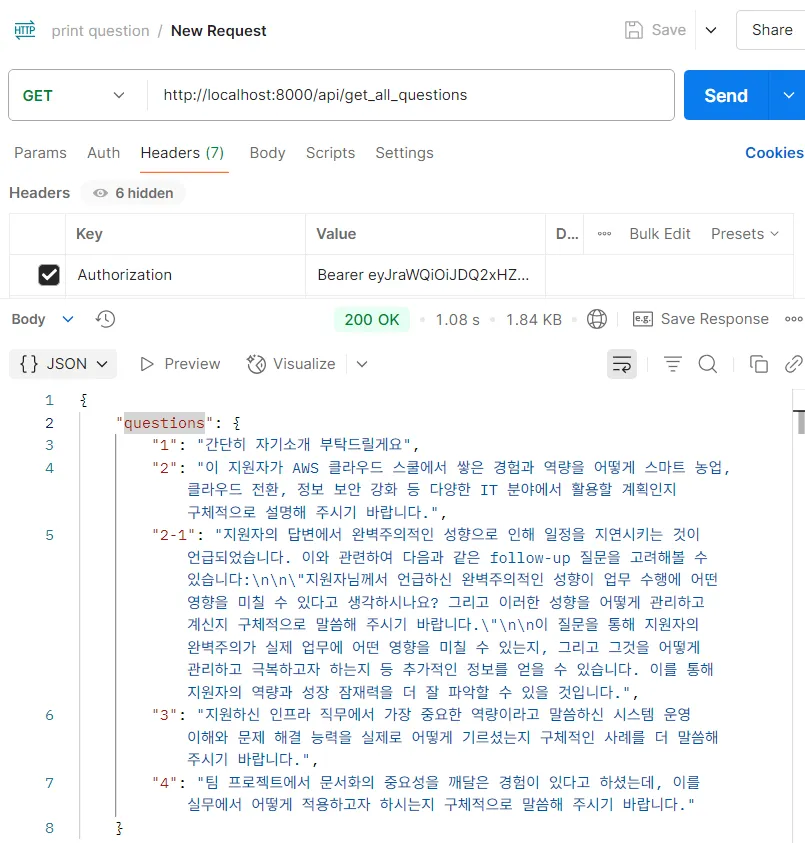
마무리
-
저장하지 않는 데이터는 결국 관리하기 어렵다.
-
이력서 기반 질문뿐 아니라 꼬리 질문까지 저장해야 질문 히스토리를 일관되게 관리할 수 있다.
-
단순한 규칙(번호 부여 + 병합)만으로도 사용자 경험과 운영 편의성을 크게 개선할 수 있었다.

꿈나무🌳