Auto Increment
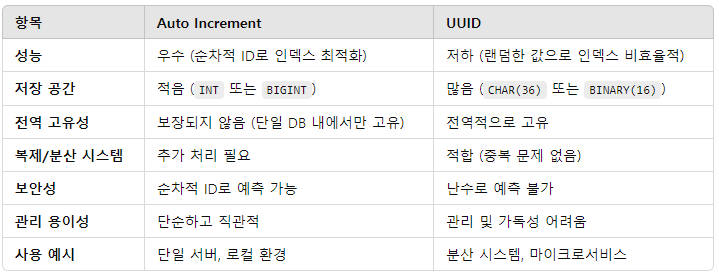
Auto Increment는 데이터를 순차적으로 증가를 시킨 수를 pk로 지정하여 사용한다.
- 장점
- 이러한 방법은 B+ Tree 인덱스 구조에서 순차적인 pk는 데이터 삽입시 디스크I/O를 최소화하고, 페이지 분할을 적게 발생하는 성능의 이점이 있습니다.
저장 공간을 적게 차지하고 관리하는데 좋다.
- 이러한 방법은 B+ Tree 인덱스 구조에서 순차적인 pk는 데이터 삽입시 디스크I/O를 최소화하고, 페이지 분할을 적게 발생하는 성능의 이점이 있습니다.
- 단점
- 분산 시스템이나 여러 데이터 베이스를 사용한다면 pk는 전체 시스템에서 동일한 PK값이 생성될 수 있다. 이를 방지하기 위해서 여러 서버 간 고유성을 보장하는 방법이 필요합니다.
- 복제 및 분산 환경에서 비효율적: 마이크로서비스나 샤딩(데이터 분할) 구조에서 서로 다른 서버 간의 데이터가 병합될 경우, PK의 고유성을 유지하기가 어렵습니다. 이를 해결하려면 복잡한 PK 재구성 또는 ID 할당 메커니즘이 필요합니다.
- 보안 이슈: PK가 순차적으로 증가하기 때문에 데이터가 노출될 가능성이 있다.
UUID
- 장점
- UUID는 전역적으로 고유하면, 분산 시스템에서 충돌 없이 고유한 ID를 생성할 수 있다.
- 고유한 ID이기 때문에 데이터는 분산 시스템에서 적합하며 ID를 가지고 데이터를 추정하기 힘들다.
- 단점
- 순차적 증가에 비해 저장공간을 많이 차지한다.
- 쓰기 작업시 B+Tree를 사용지 페이지분할과 같은I/O작업이 많이 일어나 불리하다.
- UUID를 문자열로 비교작업을 수행시 느리다.
- UUIDv1/UUIDv7와 같은 순차성을 가진 UUID를 사용할 수 있다.
MySQL에서
PK를 클러스터 인덱스로 사용하는 MySQL에서는 랜덤한 값을 생성하여 PK로 가지는 UUID의 경우는 쓰기 작업에는 많은 I/O를 발생할 수 있기 때문에 성능에서는 떨어진다.
하지만 순차적 증가를 사용하여 PK로 지정하고 추가적인 식별자를 사용하면 유지보수 면에서는 안좋아도 쓰기 작업에는 유리한 이점이 있다.
정리하자면
분산 시스템에서 쓰기 작업이 적게 발생하는 데이터에는 UUID를 사용하는 것이 유리할 수 있습니다. UUID는 전역적으로 고유하기 때문에 서로 다른 노드 간에 충돌이 발생하지 않으며, 분산 환경에서 관리가 수월해집니다. 그러나 쓰기 작업이 많이 발생하는 경우에는 UUID의 무작위성이 비효율적일 수 있습니다. 비순차적인 쓰기 작업으로 인해 성능 저하가 발생할 수 있기 때문입니다. 이럴 때는 자동 증가(Auto Increment)와 추가적인 식별자를 사용하는 것이 성능 면에서 더 유리합니다.

안녕하세요.