HashMap
HashMap은 Key-Value로 이루어져있어 고유한 키를 가지고 빠르게 값을 찾을 수 있다.
- 단건 검색 속도 O(1)
- 범위 탐색은 전체 데이터를 봐야하므로 O(N)
- 전방 일치 탐색: 키의 값을 하나하나 봐야 하기 때문에 불가능ex) like ‘AB%’
- 메모리 DB에서 사용됨
List
- 정렬되지 않은 리스트의 탐색은 전부를 찾아야하니 O(N)
- 정렬된 리스트의 탐색은 이진 탐색을 사용해서 O(logN)
- 정렬되지 않은 리스트를 정렬하는 시간 복잡도는 O(N) ~ O(N *
logN) - 삽입 / 삭제 비용이 매우 높음: 추가 삭제시 뒤의 데이터의 위치 조정이 필요
Tree
(이진 탐색 사용가정)
- 트리 높이에 따라 시간 복잡도가 결정됨
- 트리의 높이를 최소화하는 것이 중요 !
- 한쪽으로 노드가 치우치지 않도록 균형을 잡아주는 트리
사용
ex) Red-Black Tree, B+Tree(RDBMS는 주로 이거 사용) - B+Tree
MySQl의 B+Tree를 사용한 인덱스의 데이터 찾는 방법
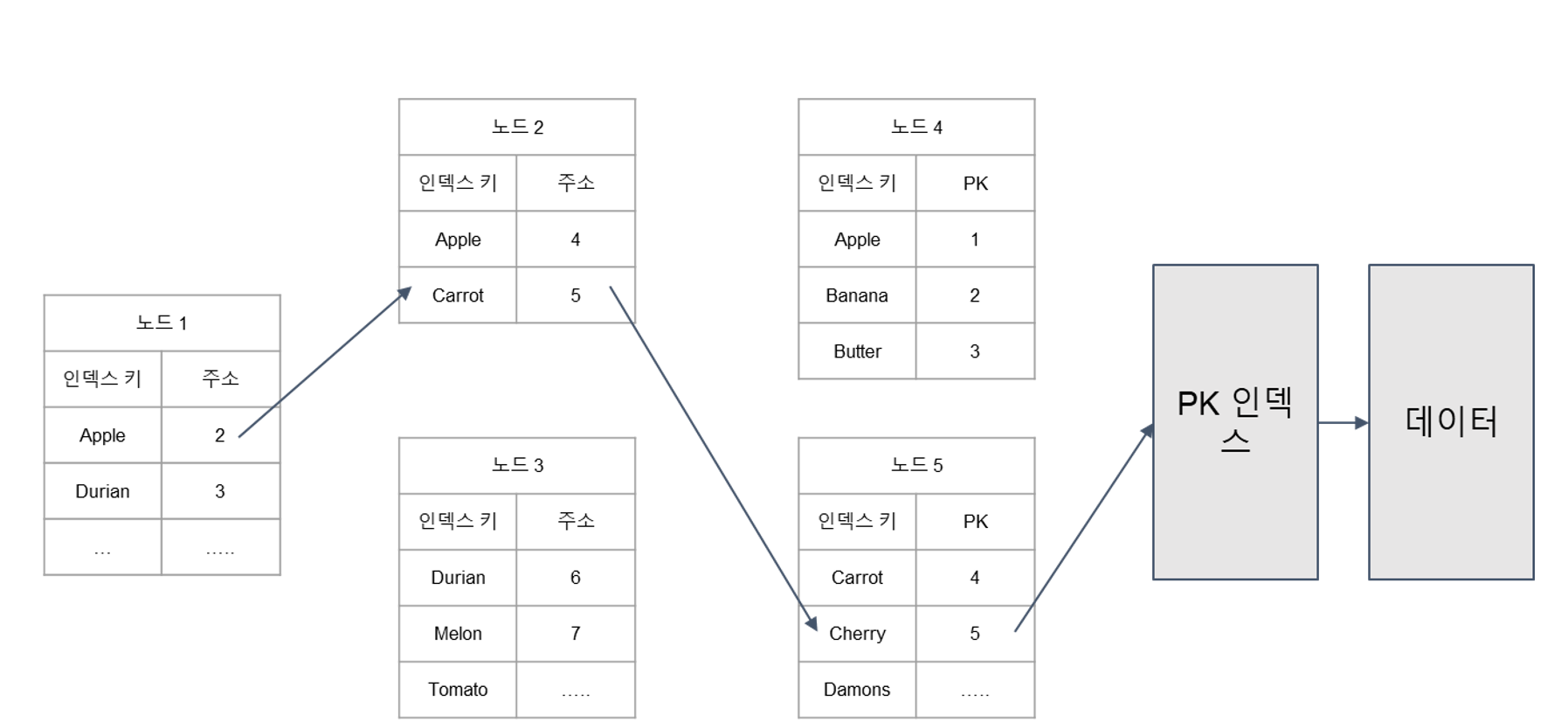
과일이름의 인덱스를 사용하면 과일 이름과 그 데이터의 pk값이 같이 있고 인덱스를 통해 원하는 값을 찾고 그 pk를 값을 가지고 다시 검색을 해 데이터를 찾는데 Orcale의 경우는 pk대신 데이터가 있는 주소를 가지고 있다는 차이점이 있어서 MySQL을 사용할 때는 pk의 선택이 중요하다.
pk의 값이 크면 하나의 노드가 가질 수 있는 데이터의 수가 제한적이고 이는 트리의 높이를 증가 시킨다.
또한 인덱스를 사용하면 조회의 성능은 향상되어도 쓰기와 갱신의 속도는 저하된다.

안녕하세요.