일정 관리 프로젝트를 진행하면서 겪은 문제들을 정리한 블로그 글이다.
필수 구현 파트
1. 자동 생성되는 칼럼을 어떻게 가져와야 하는가?
CREATE TABLE schedules (
schedules_id INT AUTO_INCREMENT PRIMARY KEY, -- 고유 식별자 (자동 증가)
task TEXT NOT NULL, -- 할일 내용
author_name VARCHAR(30) NOT NULL, -- 작성자 이름
password VARCHAR(20) NOT NULL,
created_at TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP, -- 생성일시
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP -- 수정일시
);우선 내가 짠 schedules 테이블의 CREATE 문을 보자.
일정을 생성할 때 task와 author_name을 Body 형태로 받고,
password를 헤더의 Authorization을 통해 전달받으면
그것을 통해 schedules 테이블을 INSERT 해주는 형태로 만드려고 했다.
{
"id": "게시글 고유 식별자",
"task": "할일 내용",
"authorName": "작성자명",
"createdAt": "YYYY-MM-DD HH:mm:ss",
"updatedAt": "YYYY-MM-DD HH:mm:ss"
}이때 ResponseBody는 이런식으로 가도록 설계했다.
JDBC 사용법은 간단하게 강의를 통해 배운 내용이 그대로 적용되는 부분이 많아서 진행하는 중
@Repository
public class JdbcTemplateScheduleRepository implements ScheduleRepository {
private final JdbcTemplate jdbcTemplate;
public JdbcTemplateScheduleRepository(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@Override
public ScheduleResponseDto addSchedule(String password, Schedule schedule) {
SimpleJdbcInsert jdbcInsert = new SimpleJdbcInsert(this.jdbcTemplate);
jdbcInsert.withTableName("schedule").usingGeneratedKeyColumns("schedule_id");
Map<String, Object> parameters = new HashMap<>();
parameters.put("task", schedule.getTasks());
parameters.put("author_name", schedule.getAuthorName());
parameters.put("password", password);
Number key = jdbcInsert.executeAndReturnKey(new MapSqlParameterSource(parameters));
return new ScheduleResponseDto(key.longValue(), schedule.getTasks(), schedule.getAuthorName());
}
}이 부분에서 문제가 발생했다. ResponseDto에 담을 key값, task, authorname은
넣을 수 있었지만 INSERT 할 때 자동으로 생성되는 작성 일시, 수정 일시는 어떻게 가져와야하지?
하는 문제가 생겼다.
그 때 메모프로젝트를 진행했던 강의에서 조회를 할 때 사용했던 메서드가 떠올랐다.
@Override
public Optional<Memo> findMemoById(long id) {
List<Memo> result = jdbcTemplate.query("select * from memo where id=?", memoRowMapperV2(), id);
return result.stream().findAny();
}
private RowMapper<Memo> memoRowMapperV2() {
return new RowMapper<Memo>() {
@Override
public Memo mapRow(ResultSet rs, int rowNum) throws SQLException {
return new Memo(
rs.getLong("id"),
rs.getString("title"),
rs.getString("contents")
);
}
};
}어떻게 사용하는지는 잘 모르겠지만 query 내부에 query와 Mapper메서드를 넣으면 원하는
객체를 return 해줄 수 있다는 사실은 알 수 있었고 이것을 활용하면 방금 삽입한
schedule 데이터를 꺼내와 값을 꺼내 ResponseDto를 만들 수 있지 않을까 라는 생각이 들었다.
jdbcTemplate.query / queryForObject
jdbcTemplate.query와 jdbcTemplate.queryForObject는
JdbcTemplate 클래스의 메서드로, 각각 다수 또는 단일 결과를 가져올 때 사용된다.
두 메서드는 쿼리를 실행하고, 결과를 Java 객체에 매핑하여 반환한다.
이 토글에선 두 메서드 간 주요 차이점과 각 메서드의 사용 방식을 정리했다.
1. jdbcTemplate.query
주요 특징
- 여러 행 처리: 쿼리 결과가 여러 행일 때 사용
- RowMapper 필수: 각 행을 Java 객체에 매핑하기 위해
RowMapper를 제공 - 리스트 반환: 반환된 결과는
List<T>타입으로, T는 매핑된 객체 타입
사용 예시
예를 들어, 메모 목록을 조회하는 경우 (강의에서 다룬 내용)
public List<Memo> findAllMemos() {
String query = "SELECT * FROM memo";
return jdbcTemplate.query(query, memoRowMapper());
}
private RowMapper<Memo> memoRowMapper() {
return (rs, rowNum) -> new Memo(
rs.getLong("id"),
rs.getString("title"),
rs.getString("contents")
);
}- 여기서
memoRowMapper는 각 행을Memo객체로 변환하며,
query는List<Memo>형태로 반환된다. 참고로 이는 람다 표현식을 이용하여 간결하게 구현할 수 있다.
2. jdbcTemplate.queryForObject
jdbcTemplate.queryForObject는 쿼리 결과가 단일 행일 때 사용된다.
이 메서드는 결과가 한 개가 아니면 예외를 발생시키므로,
반드시 하나의 결과만 나오는 쿼리에 사용해야 한다.
주요 특징
- 단일 행 처리: 쿼리 결과가 단 한 행일 때만 사용
- 결과가 없거나 여러 개일 경우 예외 발생: 쿼리 결과가 없으면
EmptyResultDataAccessException이, 여러 개면IncorrectResultSizeDataAccessException이 발생 - RowMapper 또는 특정 타입: 결과를 객체에 매핑하기 위해
RowMapper를 사용하거나, 단일 값이라면Integer,String등 타입 클래스를 지정할 수 있다.
사용 예시
예를 들어, 특정 ID의 메모를 조회하는 경우를 생각해보자.
public Memo findMemoById(long id) {
String query = "SELECT * FROM memo WHERE id = ?";
return jdbcTemplate.queryForObject(query, memoRowMapper(), id);
}- 여기서
memoRowMapper는 결과를Memo객체로 변환하며,queryForObject는Memo객체를 직접 반환한다.
두 메서드의 차이점 요약
| 기능 | jdbcTemplate.query | jdbcTemplate.queryForObject |
|---|---|---|
| 목적 | 다수의 행을 처리할 때 사용 | 단일 행만 처리할 때 사용 |
| 반환 타입 | List<T> | T (예: 객체나 단일 값) |
| RowMapper | 필수 | 단일 객체 매핑 시 사용 |
| 결과가 없을 때 | 빈 리스트 반환 (List<T>) | EmptyResultDataAccessException 예외 발생 |
| 결과가 여러 개일 때 | 리스트에 모든 결과를 담아 반환 | IncorrectResultSizeDataAccessException 예외 발생 |
선택 기준
- 결과가 여러 행이라면
query를 사용하여 리스트로 반환하고, 단일 행이라면queryForObject를 사용하여 개별 객체로 반환한다. - 특정 쿼리 결과가 항상 단일 값일 때,
queryForObject가 더 적합하고 간결하다. - 결과가 없거나 여러 개일 가능성이 있다면,
query를 사용하는 것이 더 안전할 수 있다.
하지만! 위에서 살펴봤듯이
queryForObject는 결과로 단일 행을 받는 대신, 만약 0 또는 1 초과의 행이 반환되면 에러를 던진다.
0일 경우 EmptyResultDataAccessException,
2개 이상일 경우 IncorrectResultSizeDataAccessException가 발생한다.
이는 DB에러인 DataAccessException의 상속을 받으며, 500 서버에러로 간주된다.
반면, query 메소드는 List를 반환하는 대신 쿼리문 실행이 실패할 경우에만 DataAccessException을 던진다.
물론, queryForObject를 사용하면서 위의 두 에러(EmptyResultDataAccessException, IncorrectResultSizeDataAccessException)을 따로 핸들링해서 원하는 오류 상태를 만들 수 있지만 번거롭기도하고 DB 오류를 발생시키는 것보다,
Service 클라이언트 오류로 발생시키는 것이 좋은 방향인 것 같아
query를 사용하는 것이 더 좋아보인다.
여기서는 내가 방금 삽입한 schedule 객체 1개를 꺼내오는 것이기에
queryForObject를 사용해보려했지만 이제는 사용하지않는 메서드이기도하고 토글 맨 아래에
추가해놓은 내용에 따라서 query를 사용하기로했다.
@Repository
public class JdbcTemplateScheduleRepository implements ScheduleRepository {
private final JdbcTemplate jdbcTemplate;
public JdbcTemplateScheduleRepository(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@Override
public ScheduleResponseDto addSchedule(String password, Schedule schedule) {
// 데이터 삽입
SimpleJdbcInsert jdbcInsert = new SimpleJdbcInsert(this.jdbcTemplate)
.withTableName("schedules")
.usingGeneratedKeyColumns("schedules_id");
Map<String, Object> parameters = new HashMap<>();
parameters.put("task", schedule.getTask());
parameters.put("author_name", schedule.getAuthorName());
parameters.put("password", password);
Number key = jdbcInsert.executeAndReturnKey(new MapSqlParameterSource(parameters));
long scheduleId = key.longValue();
// 삽입된 데이터를 다시 조회하여 created_at과 updated_at 가져오기
String query = "SELECT schedules_id, task, author_name, created_at, updated_at FROM Schedules WHERE schedules_id = ?";
List<ScheduleResponseDto> scheduleResponseDtos = jdbcTemplate.query(query, scheduleRowMapper(), scheduleId);
// 조회 결과가 존재할 경우 첫 번째 ScheduleResponseDto 반환
if (!scheduleResponseDtos.isEmpty()) {
return scheduleResponseDtos.get(0);
} else {
throw new DataRetrievalFailureException("Failed to retrieve schedule with id = " + scheduleId);
}
}
// RowMapper 메서드로 분리
private RowMapper<ScheduleResponseDto> scheduleRowMapper() {
return (rs, rowNum) -> new ScheduleResponseDto(
rs.getLong("schedules_id"),
rs.getString("task"),
rs.getString("author_name"),
rs.getTimestamp("created_at"),
rs.getTimestamp("updated_at")
);
}
} 람다식으로 RowMapper가 구현된다는 정보도 알았기에 이렇게 구현했고
이제는 POST 요청을 보내서 실행을 해보았는데?
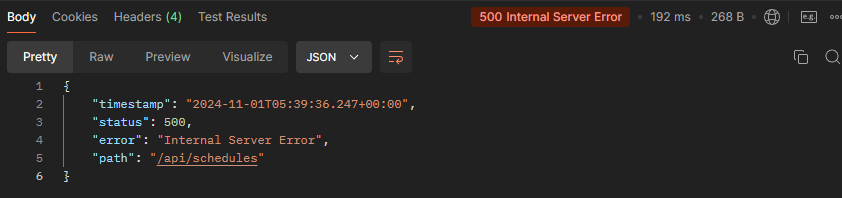
java.sql.SQLIntegrityConstraintViolationException: Column 'created_at' cannot be null엥? 이 오류가 왜 여기서 나오지?
분명 schedules 테이블을 생성할 때 DEFAULT CURRENT_TIMESTAMP를 사용해
자동으로 현재 타임 스탬프가 설정되도록 했는데 왜 null 이 적용되는걸까?
이유는 SimpleJdbcInsert에 있었다. 기본적으로 해당 필드를 NULL로 삽입하려고 시도하기
때문에 이를 방지하려면 parameters에 created_at, updated_at이 포함되지 않도록 설정해주어야한다.
@Override
public ScheduleResponseDto addSchedule(String password, Schedule schedule) {
// 데이터 삽입
SimpleJdbcInsert jdbcInsert = new SimpleJdbcInsert(this.jdbcTemplate)
.withTableName("schedules")
.usingGeneratedKeyColumns("schedules_id")
.usingColumns("task", "author_name", "password");
//..이하 생략이렇게 usingColumns를 이용해 실제로 삽입할 컬럼만 지정해주고 실행하면?
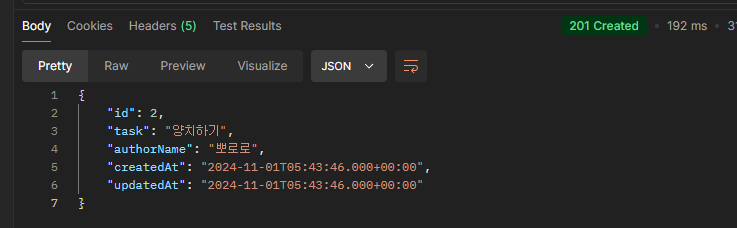

잘 응답도 오고 실제 데이터베이스에도 잘 저장된 것을 볼 수 있다.
삽입부터 쉽지않은 작업이었다........
2. 동적 쿼리 구현을 JDBC로??
SELECT
schedules_id,
task,
author_name,
--DATE_FORMAT(updated_at, '%Y-%m-%d') AS updated_date
created_at,
updated_at
FROM
Schedule
WHERE
(author_name = ? OR ? IS NULL) AND -- 사용자 이름 필터링 (입력값이 없는 경우)
(DATE(updated_at) = ? OR ? IS NULL) -- 수정일 필터링 (입력값이 없는 경우)
ORDER BY
updated_at DESC;
내가 짠 전체 일정 조회 쿼리이다.
요청할 때 받는 수정일자와 작성자명이 있을수도? 없을수도? 있기 때문에 두 경우를 생각해야했다.
그런데 여기서 문제가 있었다.
이렇게 들어오냐 마냐에 따라 달라지는 동적쿼리 는 어떻게 JDBC로 처리해야할까?
강의에서 했던 내용으로는 감을 잡을 수 없었고 결국 구글링의 힘을 받았다.
역시 나와 같은 고민을 하던 사람의 질문을 볼 수 있었다.
https://www.inflearn.com/community/questions/269386/jdbctemplate-%EB%8F%99%EC%A0%81%EC%BF%BC%EB%A6%AC-%EC%A7%88%EB%AC%B8%EC%9E%85%EB%8B%88%EB%8B%A4?srsltid=AfmBOopon6gEZIX0_PJ6mKry39pzEr5C3INlauhZiJxoMiGuv_TER5nN
답글을 보면 고전적인 방법이지만 파라미터 존재 여부를 체크해 존재할 때
String을 이어붙이는 방법을 사용하면 동적쿼리를 구현할 수 있다고 한다.
따라서 StringBuilder 와 if 조건문을 이용하여 동적쿼리를 구현했다.
@Override
public List<ScheduleResponseDto> findAllSchedules(String updatedAt, String authorName) {
//동적 쿼리를 구현해야함.
StringBuilder sql = new StringBuilder("SELECT * FROM schedules");
List<String> args = new ArrayList<>();
if (updatedAt != null) {
sql.append(" WHERE DATE(updated_at) = ?");
args.add(updatedAt);
}
if (authorName != null) {
if (updatedAt != null) {
sql.append(" AND");
} else {
sql.append(" WHERE");
}
sql.append(" author_name = ?");
args.add(authorName);
}
sql.append(" ORDER BY updated_at DESC");
return jdbcTemplate.query(sql.toString(), scheduleRowMapper(), args.toArray());
}updatedAt 이 들어온 경우, authorName이 들어온 경우, 둘 다 들어온 경우, 둘 다 들어오지 않은 경우를 모두 만족하는 코드를 작성했다.
더 효율적인 방법이 있는지 다음에 알아보도록 해야겠다.
도전 구현 파트
1. DB를 수정해보자!
필수 구현을 완료했으니 도전 구현을 시작할 차례였다.
CREATE TABLE author (
author_id INT AUTO_INCREMENT PRIMARY KEY, -- 고유 식별자 (자동 증가)
name VARCHAR(100) NOT NULL, -- 작성자명
email VARCHAR(100) UNIQUE NOT NULL, -- 작성자 이메일 (유니크 제약조건)
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, -- 등록일시
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP -- 수정일시
);
CREATE TABLE schedules (
schedules_id INT AUTO_INCREMENT PRIMARY KEY, -- 고유 식별자 (자동 증가)
task TEXT NOT NULL, -- 할일 내용
author_id INT NOT NULL, -- 작성자 고유 식별자 (외래 키)
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, -- 생성일시
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, -- 수정일시
FOREIGN KEY (author_id) REFERENCES author(id) ON DELETE CASCADE -- 외래키 설정 및 연관된 작성자 삭제 시 일정도 삭제
);내가 생각한 DB의 구조는 이러하였고 schedules 테이블은 이미 만들어져 있으니
ALTER 명령어를 통해 존재하던 author_name을 삭제하고 author_id를 추가하면 되겠지?
CREATE TABLE author (
author_id INT AUTO_INCREMENT PRIMARY KEY, -- 고유 식별자 (자동 증가)
name VARCHAR(100) NOT NULL, -- 작성자명
email VARCHAR(100) UNIQUE NOT NULL, -- 작성자 이메일 (유니크 제약조건)
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, -- 등록일시
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP -- 수정일시
);
ALTER TABLE schedules DELETE author_name;
ALTER TABLE schedules ADD CONSTRAINT fk_author FOREIGN KEY (author_id)
REFERENCES author(author_id) ON DELETE CASCADE;
[2024-11-02 13:04:02] [23000][1452] Cannot add or update a child row: a foreign key constraint fails
(schedules.#sql-136c_b, CONSTRAINT fk_author FOREIGN KEY (author_id) REFERENCES author (author_id) ON DELETE CASCADE)어라?? 안되네?? 하고 잘 보았더니 schedules 테이블에 author_id를 추가하지 않아서
제약조건 추가를 실패했다는 것을 알 수 있었고 author_id를 추가해주었다.
-- 2. author_id 컬럼 추가
ALTER TABLE schedules
ADD author_id INT NOT NULL;
-- 3. author_id를 외래 키로 설정
ALTER TABLE schedules
ADD CONSTRAINT fk_author
FOREIGN KEY (author_id) REFERENCES author(author_id) ON DELETE CASCADE;
[2024-11-02 13:04:02] [23000][1452] Cannot add or update a child row: a foreign key constraint fails
(schedules.#sql-136c_b, CONSTRAINT fk_author FOREIGN KEY (author_id) REFERENCES author (author_id) ON DELETE CASCADE)그런데 또 오류가 발생했다. 이 오류는 author_id에 참조되는 값이 author 테이블에 존재하지 않기 때문에 발생하는 오류였다.
즉, author 에도 데이터를 추가하고 schedules 테이블의 author_id 값에 author 테이블의 author_id 값을 넣어줘야 진행이 가능했다.
INSERT INTO author (name, email) VALUES ('작성자 이름', '이메일@example.com');
UPDATE schedules SET author_id = 1 WHERE author_id IS NULL; -- 필요한 조건에 맞게 수정
ALTER TABLE schedules
ADD CONSTRAINT fk_author
FOREIGN KEY (author_id) REFERENCES author(author_id) ON DELETE CASCADE;
이렇게 외래키 제약조건을 추가할 수 있었다.
기존 테이블을 수정하고 외래키를 넣어본 경험은 처음이라 조금 삐걱거렸던 것 같다.
이제는 어떻게 진행되는지 알았으니 실수하지 않을 것이다.
2. 수정 과정의 변화
원래 할일, 작성자명 수정 과정은 단순하게 schedules 테이블에 같이 있었기 때문에 한번에
진행했다.
기존의 데이터 요청방식을 유지하면서 기능은 유지할 수 있는 방법은 무엇이 있을지 고민해보았다.
지금 구조는 controller -> service -> repository 로 이루어져있으며
service와 repository는 인터페이스로 구현하여 최대한의 클린 아키텍처를 구성하도록 했다.
이제는 PathVariable 로 받아온 schedulesId를 이용해 해당 데이터와 연결된
author 데이터를 찾아 그 author 레코드의 이름을 수정하는 형태로 바꿔야했다.
처음에는 scheduleRepository 내부에서 같은 레벨에 존재하는 authorRepository를 참조하여 레포지토리 내부에서 모든 과정을 처리하려고 생각했었다.
그런데 코드를 짜다보니 굳이 같은 레벨에서 모든 것을 처리하기보다는
이미 레포지토리 인터페이스를 통해 데이터를 CRUD하는 서비스 계층에서 처리하는게 어떨까?
라는 생각이 들었고
scheduleService 에서 두 레포지토리를 참조해서 사용하는 방식으로 구성해보았다.
@Override
public ScheduleResponseDto updateSchedule(Long scheduleId,
String task, String authorName, String password) {
Long authorId = scheduleRepository.findScheduleById(scheduleId).getAuthorId();
//task를 먼저 수정해봄으로써 비밀번호 검증이 진행됨
int updatedRowScheduleTask = scheduleRepository.updateSchedule(scheduleId, task, password);
int updatedRowAuthorName = authorRepository.updateAuthorName(authorId, authorName);
if (updatedRowAuthorName == 0) {
throw new ResponseStatusException(HttpStatus.NOT_FOUND, "Author not found");
}
if (updatedRowScheduleTask == 0) {
throw new ResponseStatusException(HttpStatus.NOT_FOUND, "Schedule not found");
}
Schedule schedule = scheduleRepository.findScheduleById(scheduleId);
return new ScheduleResponseDto(schedule);
}이런 식으로 구성해보았다.
scheduleId를 통해서 authorId를 가져오고 각각의 id를 각각의 레포지토리를 이용해
task 와 authorName을 따로 넣어줌으로써 수정하도록 만들었다.
즉 UPDATE 쿼리문을 2개 사용하여 수정하도록 만든 것이다.
이 구조가 효율적이고 올바르게 짠 것인지 잘 모르겠어서 나중에 피드백을 받아보기 위해
블로그 글에 작성한다.
3. 페이지네이션은 어떻게?
페이지네이션은 많은 웹사이트에서 사용하는 기능이다.
분명히 JDBC에도 페이지네이션을 구현하기 편리하게 만들어져있는 클래스나 api 가 있을거라고
생각했고 구글링하여 찾아보기로했다.
역시나 Spring Data JDBC 가 제공하는 CrudRepository 가 존재했고 이를 통해
페이지네이션을 구현해보기로 했다.
Repository 생성
public interface SchedulePaginationRepository extends CrudRepository<Schedule, Long> {
Page<Schedule> findAllByOrderByUpdatedAtDesc(Pageable pageable);
}인터페이스를 생성하여 CrudRepository를 상속받으면 원하는 메서드를 구현할 수 있다.
이 메서드는 Pageable 타입의 객체를 넘겨주면 객체의 정보를 읽고
page 조건을 설정해 데이터를 가져온다.
CrudRepository를 구현할경우 위와 같이 특별한 네이밍법칙으로 메서드를 추상화 해주어야만 Pagination을 사용 할수 있다.
- Pageable 이란?
Pagination 요청 정보를 담기위한 추상 인터페이스이다.
실제로 사용하기 위해서는 구현체가 필요하다.
구현체는 QPageRequest, PageRequest, Unpaged 가 존재하지만
가장 기본이되는 PageReuqest를 사용하여 구현해볼 것이다.
Service
@Service
public class ScheduleServiceImpl implements ScheduleService {
//..이하 생략
@Override
public Page<Schedule> findSchedulePaginated(int page, int size) {
PageRequest pageRequest = PageRequest.of(page, size);
return schedulePaginationRepository.findAllByOrderByUpdatedAtDesc(pageRequest);
}
}서비스 계층에서 page 개수와 size 개수를 매개변수로 받아 PageRequest 객체를 생성하고
그것을 CrudRepository를 상속받았던 schedulePaginationRepository 의 메서드의 매개변수로
넣어준다.
그렇게해서 수행된 메서드는 Page<Schedule> 타입의 객체를 반환한다.
Controller
@RestController
@RequestMapping("/api/schedules")
public class ScheduleController {
@GetMapping("/paginated")
public ResponseEntity<SchedulePageResponseDto> findSchedulePaginated(
@RequestParam Integer page,
@RequestParam Integer size
) {
Page<Schedule> schedules = scheduleService.findSchedulePaginated(page - 1, size);
//... 매핑과정이 있어야함.
return new ResponseEntity<>(schedulePageResponseDto, HttpStatus.OK);
}
}그렇게 컨트롤러에서는 Page<Schedule> 타입의 객체를 받게되고
이를 클라이언트에게 Json 형태로 보내기 위해 SchedulePageResponseDto 형태로 변환해야한다.
여기서 SchedulePageResponseDto 의 구조를 살펴보자
@Getter
@AllArgsConstructor
public class SchedulePageResponseDto {
private List<ScheduleResponseDto> schedules;
private PageInfo pageInfo;
@Getter
@AllArgsConstructor
public static class PageInfo {
private int page;
private int size;
private int totalElements;
private int totalPages;
}
}- PageInfo 란?
Page객체 (컨트롤러에서의 schedules를 의미) 에서 제공하는 페이지 개수, 페이지 당 데이터 개수, 총 데이터 수 등의 정보를 이용해 페이지 정보를 담고있는 객체이다.
즉, 이 형태로 변환하기 위해서는 List<ScheduleResponseDto> 객체, PageInfo 객체가 필요하다.
@GetMapping("/paginated")
public ResponseEntity<SchedulePageResponseDto> findSchedulePaginated(
@RequestParam Integer page,
@RequestParam Integer size
) {
//일반적으로 페이지 번호가 0부터 시작하기에 요청받는 페이지 -1 값을 넣어준다.
Page<Schedule> schedules = scheduleService.findSchedulePaginated(page - 1, size);
PageInfo pageInfo = new PageInfo(
schedules.getNumber() + 1,
schedules.getSize(),
(int) schedules.getTotalElements(),
schedules.getTotalPages()
);
List<ScheduleResponseDto> scheduleDtos = schedules.stream()
.map(ScheduleResponseDto::new)
.collect(Collectors.toList());
SchedulePageResponseDto responseDto = new SchedulePageResponseDto(scheduleDtos, pageInfo);
return new ResponseEntity<>(responseDto, HttpStatus.OK);
}맵핑 과정 추가 후의 모습이다.
PageInfo는 생성된 Page<Schedule> schedules 에서의
get 메서드를 통해 필요한 페이지 정보를 가져와 생성하였다.
그런데 여기서 하나의 의문이 생겼다. schedules 객체에서
어떻게 List<ScheduleResponseDto> 로 변환할 수 있을까??
여기서 Page 인터페이스에 대해 상세히 알아보았다.
Page 인터페이스와 PageImpl 클래스
-
Page 인터페이스:
Page<T>는 데이터의 페이지를 나타내는 인터페이스로, 현재 페이지의 콘텐츠와 페이지 정보(예: 페이지 번호, 전체 요소 수 등)를 포함한다.
-
PageImpl 클래스:
PageImpl은Page인터페이스의 기본 구현체로, 실제로 데이터를 담고 있는 클래스이다
이 클래스는 다음과 같은 주요 필드를 포함한다.List<T> content: 현재 페이지에 포함된 데이터 리스트int number: 현재 페이지 번호int size: 페이지당 요소 수long totalElements: 전체 요소 수int totalPages: 전체 페이지 수
Stream 연산을 통한 변환
Page<Schedule> 객체는 List<Schedule> 형태의 콘텐츠를 가지고 있는 것이므로,
getContent() 메서드를 호출하면 현재 페이지에 대한 Schedule 객체의 리스트를 얻을 수 있다.
이 리스트를 Java Stream API의 stream() 메서드를 사용하여 스트림으로 변환하는 것이다.
예시 코드
Page<Schedule> schedules = scheduleService.findSchedulePaginated(page - 1, size);
// 현재 페이지의 Schedule 객체 리스트를 가져옴
List<Schedule> scheduleList = schedules.getContent();
// Stream을 사용하여 ScheduleResponseDto로 변환
List<ScheduleResponseDto> scheduleDtos = scheduleList.stream()
.map(ScheduleResponseDto::new) // 각 Schedule 객체를 ScheduleResponseDto로 변환
.collect(Collectors.toList()); // 변환된 DTO를 리스트로 수집여기서 끝을 내고자했는데 좀 더 코드를 간략화하는 방법이 있었다.
getContent() 메서드를 사용하지 않고 Page 객체에서 직접 stream 연산을 호출할 수 있었다.
왜냐?
public interface Page<T> extends Slice<T>
public interface Slice<T> extends Streamable<T>
public interface Streamable<T> extends Iterable<T>, Supplier<Stream<T>>Page 인터페이스를 타고 들어가다보면 결국은 Iterable<T> 를 상속받고있는 모습이 보인다.
따라서 Page 객체는 내부적으로 데이터를 담고있는 리스트처럼 동작할 수 있기에 직접
스트림을 생성할 수 있다!
List<ScheduleResponseDto> scheduleDtos = schedules.stream()
.map(ScheduleResponseDto::new)
.collect(Collectors.toList());Page<Schedule> 을 통한 스트림은 현재 페이지에 포함된 Schedule 객체들을 포함하고 있어
map() 메서드를 통해 각 Schedule 객체를 ScheduleResponseDto로 변환할 수 있다.
이렇게 페이지네이션 기능을 구현완료했다..
쉽지않은 과정이었다.
4. 끝인줄 알았지?
페이지네이션이 끝난줄 알았지만 아니다~
튜터님께 피드백을 한번 받아봤는데 CrudRepository 를 사용하는 것은
Jpa를 쓴거 아니냐는 말씀을 해주셨고 솔직히 나도 그렇게 느꼈다.
블로그 글에서 JDBC에서 제공된다는 말을 보아서 바로 사용한 것이었는데 확실한 것인지
찾아봐야했다.
JDBC를 사용하는 블로그 글들 중 CrudRepository를 사용하는 글들도 있고
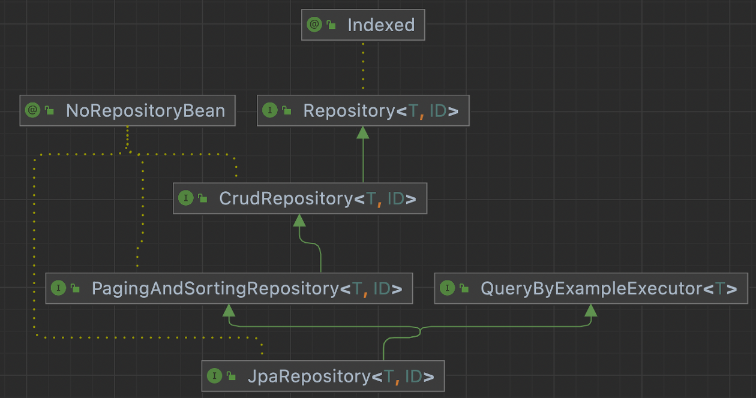
구조를 보면 둘 다 Repository 인터페이스를 확장한 인터페이스지만
JpaRepository는 CrudRepository를 상속한 PagingAndSortingRepository를 상속받길래
JDBC가 제공하는 것인줄 알았는데 아닌가보다..
찾아보니 CrudRepository는 Spring Data JPA가 제공하는 인터페이스 중 하나로,
기본적인 CRUD(Create, Read, Update, Delete) 작업을 추상화한다고 한다..
따라서 튜터님이 피드백으로 두 테이블을 author_id 기준으로 JOIN 해서
그 테이블을 사용해 Page 객체를 만들고 반환해주는 방식을 사용하는게 좋을 것 같다 해주셔서
참고하여 코드를 작성했다.
코드는 별 문제없이 작성했으나 새롭게 알게된 사실이라 작성했다.
5. 공통 에러 처리 중 발생한 알 수 없는 오류
내가 예외처리한 방식은 블로그 글로 정리해두었다.
@Getter
public class CustomException extends RuntimeException {
@Serial
private static final long serialVersionUID = 1L;
private final ExceptionClassType exceptionClassType;
private final HttpStatus httpStatus;
public CustomException(ExceptionClassType exceptionClassType, HttpStatus httpStatus,
String message) {
super(exceptionClassType.toString() + message);
this.exceptionClassType = exceptionClassType;
this.httpStatus = httpStatus;
}
public int getHttpStatusCode() {
return httpStatus.value();
}
public String getHttpStatusType() {
return httpStatus.getReasonPhrase();
}
}
@RestControllerAdvice
public class CustomExceptionHandler {
//발생하는 에러의 정보를 받아와 요청자가 어떤 오류인지 알기 쉽게 처리해줌
@ExceptionHandler(value = CustomException.class)
public ResponseEntity<Map<String, String>> ExceptionHandler(CustomException e) {
Map<String, String> map = new HashMap<>();
HttpHeaders headers = new HttpHeaders();
map.put("error type", e.getHttpStatusType());
map.put("error code", Integer.toString(e.getHttpStatusCode()));
map.put("error message", e.getMessage());
return new ResponseEntity<>(map, headers, e.getHttpStatus());
}
//@Valid 의 유효성 검사에 실패했을때의 에러를 공통으로 처리하여 반환
@ExceptionHandler(value = MethodArgumentNotValidException.class)
public ResponseEntity<Map<String, String>> MethodArgumentNotValidExceptionHandler(
MethodArgumentNotValidException e) {
Map<String, String> errors = new HashMap<>();
e.getBindingResult().getAllErrors().forEach((error) -> {
String fieldName = ((FieldError) error).getField();
String errorMessage = error.getDefaultMessage();
errors.put(fieldName, errorMessage);
});
return new ResponseEntity<>(errors, HttpStatus.BAD_REQUEST);
}
}
CustomException을 생성하고 그것을 Handler를 통해서 처리하도록 만들었다.
@Override
public int updateSchedule(Long scheduleId, String task, String password) {
//validatePassword 메서드를 통해 비밀번호 검증, 비밀번호가 틀리다면 커스텀 에러처리
if (validatePassword(scheduleId, password)) {
return jdbcTemplate.update("UPDATE schedules SET task = ? where schedules_id = ?", task,
scheduleId);
} else {
throw new CustomException(
ExceptionClassType.SCHEDULE,
HttpStatus.FORBIDDEN,
"패스워드가 일치하지 않습니다."
);
}
}그 후 예외가 발생하는 메서드에서 해당 커스텀 예외를 생성하여 던지면
사용자가 어떤 문제로 에러가 발생한 것인지 알 수 있다.
그런데 열심히 코드를 리팩토링하면서 통합처리하면서 필요가 없을 것 같은 에러처리 부분들은
지우면서 실행해보고 있었는데....
갑자기 import 문을 Cannot Resolve Symbol 로 찾지못해 실행조차 되지 않았다.
열심히 해결방법을 찾아보다가 재빌드하여 문제를 해결하기는 했는데...
왜 그런 오류가 발생했는지 짐작하기도 힘들었다.
처음에는 CustomExeption의 serialID 가 없이 코딩을 진행했는데
직렬화 역직렬화와 관련해서 그런 에러가 생긴건지
아니면 그냥 스프링부트의 일시적인 오류였던건지 알 수 없다..
그래도 금방 해결되는 일이라 다행이라고 여겼다.
끝마치며
JDBC는 처음 사용해봐서 빨리 끝낼 수 있을줄 알았던 프로젝트인데
생각보다 자료를 찾는데도 오래걸리고 적용시키는건 더욱 더 오래 걸렸다.
JDBC를 다루는게 쉽지않다.. 많이 사용하지 않는 것이라 그런지 자료도 별로 없다.
또한 처음 설계단계에서 절반 정도의 시간이 투자된 것 같고 그것을 또 보기좋게 정리하는 것도
오랜 시간이 걸렸다..
중간중간 수정해야할 부분들이 생기면 READ.me 나 sql 파일도 수정해야했는데
코딩하는 것도 힘들었지만 저런 자료를 정리하는게 에너지 소비가 많이 됐다.
그래도 JDBC를 공부하면서 쿼리문도 다시 한번 사용해보고
api 명세서나 ERD, 쿼리문을 짜놓고 시작하니 맨땅에서 시작하는 것보다는 훨씬 수월했다.
설계의 중요성을 깨닫게되었고 앞으로 진행할 프로젝트에서도 설계를 탄탄하게 해놓고
진행해야겠다고 여겼다.
