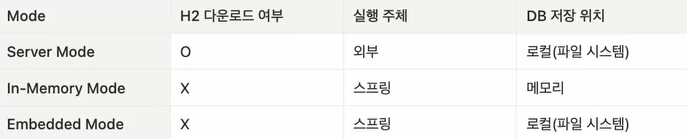
H2 DB
H2는 Server, In-memory, Embedded 3가지 Mode가 존재한다.

Server는 협업에서 많이 사용함. DB서버를 Spring 어플리케이션 서버와 별도로 관리
외부에서 DB 엔진이 구동되기에 애플리케이션을 종료해도 데이터는 남아있음
In-memory는 애플리케이션 내부 엔진 사용
애플리케이션이 종료되면 DB 엔진도 함꼐 종료되어 데이터가 사라짐. (휘발성)
단위 테스트에서 많이 사용된다. properties, yml 설정파일에서 설정해서 사용
Embedded는 엔진 설치 없이 애플리케이션 내부엔진 사용
애플리케이션이 종료되면 DB 엔진도 종료되지만
데이터는 애플리케이션 외부에 저장되어 (로컬 파일) 데이터가 사라지지 않는다.
QueryMapper 쿼리 파일 만들기
MyBatis
전에는 RowMapper를 사용했는데 이는 반복되는 코드가 많고 프로그램 코드가 쿼리 코드와 같이
들어있다는 단점이 있는데 이를 해결하기 위해서 MyBatis가 탄생했다.
반복적인 JDBC 프로그래밍을 단순화하고 SQL 쿼리들을 XML 파일에 작성해 코드와 분리시킨다.
map 인터페이스나 DAO 클래스를 통해 SQL 쿼리를 실행하고 응답값을 받아올 수 있다.
ResultSet 매핑을 위해 XML 파일 및 어노테이션을 사용해 쿼리를 관리할 수 있다.
어쨌든 SQL을 직접 작성해야하니 DB에 종속적이고 CRUD 쿼리는 테이블마다 비슷하니 반복되는
한계점이 존재한다.
동작 순서
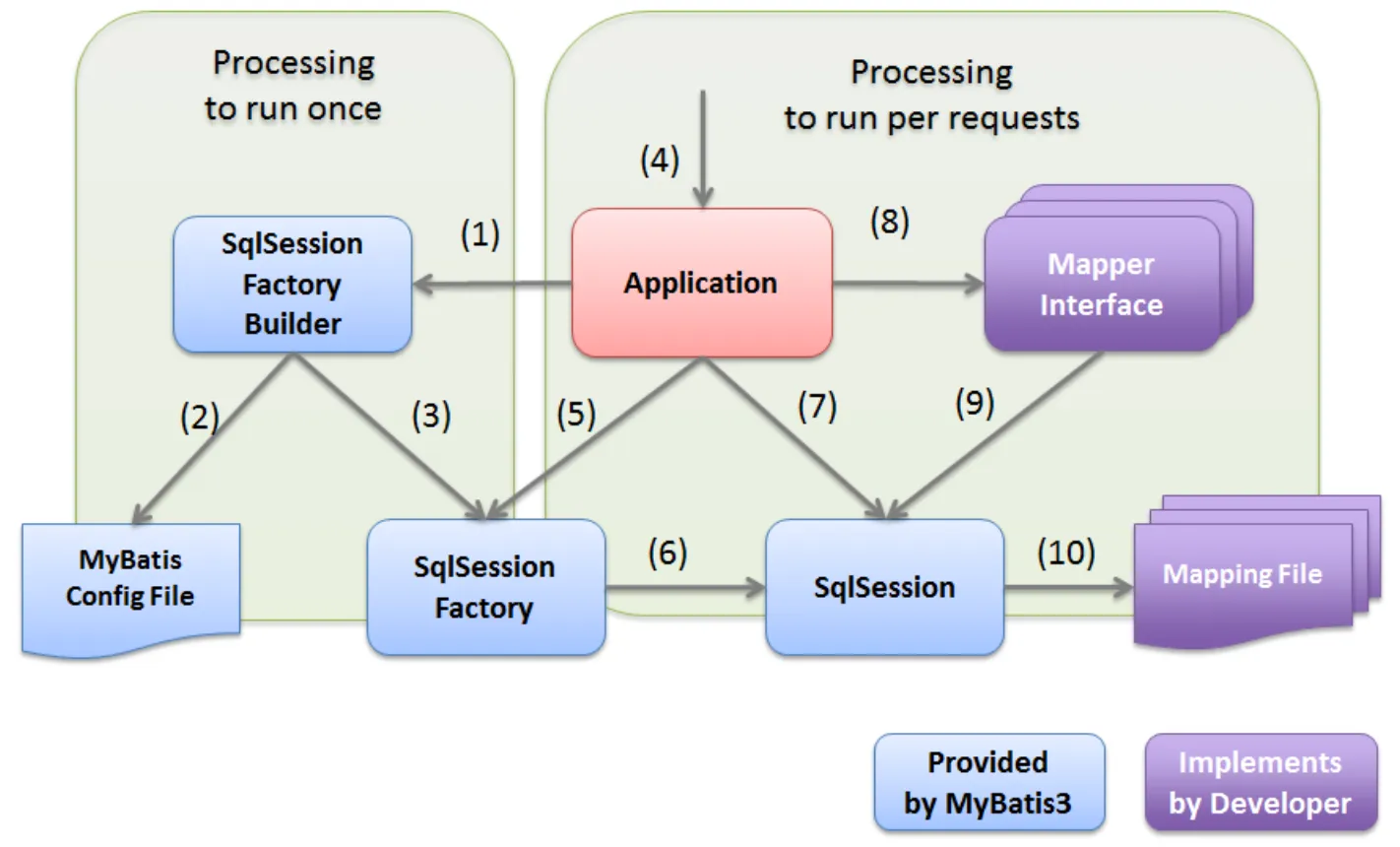
-
응용 프로그램 시작시 수행되는 프로세스
애플리케이션이 실행되면 SqlSessionFactoryBuilder 가 SqlSessionFactory를 생성하기 위해
MyBatis Config File 을 읽고 정의에 따라 Factory를 생성한다. (처음 한번만)
우리는 이 Facotry를 등록해놓고 필요할 때마다 사용하여 Sql session을 받아와
DB작업을 수행한다. -
시작 후 클라이언트의 요청에 따라 수행되는 프로세스
요청이 들어오면 SqlSessionFactory에 가서 SqlSession을 가져온다.
가져온 세션으로 매퍼 인터페이스 구현 객체를 가져온다.
가져온 매퍼 인터페이스의 메서드를 호출하면 그 객체가 SqlSession 메서드를 호출하고
SQL의 실행을 요청한다.
그러면 SqlSession이 매퍼 인터페이스 객체를 기반으로 매핑 파일에 존재하는
매핑 쿼리를 찾아서 실행할 SQL을 가져오고 실제로 실행하는 과정
개발자인 우리는 Mapper Interface와 Mapping File 을 구현해주면 된다.
MyBatis Config File 도 생성해줘야함!
- MyBatis Config File
<!-- /resources/mybatis-config.xml -->
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<typeAliases>
<package name="com.thesun4sky.querymapper.domain"/>
</typeAliases>
<mappers>
<mapper resource="mapper/UserMapper.xml"/>
</mappers>
</configuration>설정 파일의 모습이다 configuration 태그를 사용한다.
typeAliases 태그는 사용할 도메인 패키지명 주소가 들어있고
mapper 태그에 매퍼 인터페이스가 바라볼 쿼리가 들어있는 XML 포맷으로 된 쿼리가 들어있는
파일 주소를 넣는다.
이렇게 설정해주면 SqlSession Factory Builder 가 이것을 기반으로
Sql Session Factory를 만든다.
- DAO 클래스 vs Mapper Interface
개발자가 직접 코딩해야하며 실제 DB 조회 객체와 Java 프로그램 객체 간 인터페이스를 정의한다.
방법은 2가지가 존재한다.
- 방법 1 DAO 클래스 정의
// UserDao.java
import org.apache.ibatis.session.SqlSession;
import org.springframework.stereotype.Component;
import com.thesun4sky.querymapper.domain.User;
@Component
@RequiredArgumentConstructor
public class UserDao {
// SqlSession 멤버 변수로 사용하며 쿼리파일 수행 요청
private final SqlSession sqlSession;
public User selectUserById(long id) {
return this.sqlSession.selectOne("selectUserById", id);
}
}sql세션을 직접적으로 사용한다 sql 세션을 멤버변수로 사용해 쿼리파일 수행을 요청한다.
selectOne 메서드를 직접 호출하고 첫번째 문자열 인자로 쿼리 id를 넣어주면 된다.
두번째 파라미터는 쿼리 내부에서 사용하는 id 인 모습이다.
이렇게 selectOne을 호출하면 User 객체로 만들 수 있는데 이는
XML 파일 쿼리 select 태그 내부의 resultType이 "User"로 되어있어야만 가능하다.
- 방법 2 Mapper Interface 정의
// UserMapper.java
@Mapper
public interface UserMapper {
User selectUserById(@Param("id") Long id);
}sql 세션을 간접적으로 사용한다.
ibatis에서 구현해주는 Mapper 어노테이션을 사용하면 자동호출이 가능함
메서드명이 XML 파일로된 쿼리의 id 값과 매칭된다.
@Mapper 어노테이션을 사용해야한다.
이 어노테이션이 MyBatis가 UserMapper로 클래스를 자동적으로 만들어준다
selectUserById 메서드를 선언, 파라미터로 id를 만들어주면
XML 파일에 있는 쿼리를 실행해준다.
- Mapping File
<!-- UserMapper.xml -->
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.thesun4sky.querymapper.mapper.UserMapper">
<select id="selectUserById" resultType="User">
select id, name from users where id = #{id}
</select>
</mapper>쿼리 XML 내부의 내용이다
실제 패키지 경로에 있는 UserMapper 클래스와 매핑해주는 것을 의미하고
select 태그의 id 값이 Mapper 인터페이스의 메서드명과 일치되어야한다.
그러면 이 select 태그 내부의 쿼리가 실행이 되는 것이다.
#{id} 변수가 하나 있는 모습을 볼 수 있는데 이는 Mapper 인터페이스에 파라미터로
넣어주는 모습을 볼 수 있다.
- 사용하는 모습
@SpringBootApplication
public class QueryMappingApplication {
public static void main(String[] args) {
// 어플리케이션 실행 컨텍스트 생성
var context = SpringApplication.run(QueryMappingApplication.class, args);
// 데이터 조회 DAO 클래스 빈 조회
var dao = context.getBean(UserDao.class);
// DAO 를 통해 유저정보 조회
System.out.println("User by dao : " + dao.selectUserById(1L)); // data.sql 에서 미리 저장된것이 하나 있어서 2번
// 데이터 조회 Mapper 클래스 빈 조회
var mapper = context.getBean(UserMapper.class);
// FileMapper 를 통해 유저정보 조회
System.out.println("User by fileMapper: " + mapper.selectUserById(1L)); // data.sql 에서 미리 저장된것이 하나 있어서 2번
}
}그냥 JDBC를 사용할 때 보다 훨씬 간결해진 방법이다
Mapper Interface가 DAO를 사용한 방법보다 훨씬 간편하다.
한줄로 끝나는 모습을 아까 Mapper Interface 코드에서 확인할 수 있음.
이렇게 조회를 하려면 데이터가 사전에 존재해야하는데
데이터를 미리 만드는 방법이 있다.

경로를 보면 resources 하위에 data.sql, schema.sql 이 존재하는 모습을 볼 수 있다.
- data.sql
insert into users (name) values ('Kim');- schema.sql
drop table if exists users;
create table users (id int primary key auto_increment, name varchar);각각 데이터를 삽입하는 것과 이미 존재하는 테이블이 있다면 삭제하고 테이블을 생성해주는
쿼리가 들어가있다.
이렇게 resources 하위에 만들어두면 애플리케이션을 실행할 때 쿼리가 실행된다.
따로 설정해둔 모습은 없는데 애플리케이션 실행시 자동으로 실행해주는 것이 신기하여
튜터님에게 질문을 드렸고 공식문서에 포함되어있는 내용이라는 것을 알려주셨다
Initialize a Database Using Basic SQL Scripts
이 부분에 들어가면 해당 설명을 확인할 수 있다.
간단하게 설명하자면 Hibernate를 사용할 때
기본적으로 스키마 스크립트는 optional:classpath:schema.sql에서 로드하고
데이터 스크립트는 optional:classpath:data.sql에서 로드된다고 한다.
이는 사용자 지정도 가능하며 SQL DB 초기화는
임베디드 인메모리 데이터베이스를 사용할 때만 수행된다고한다.
쿼리 코드 만들기 JpaRepository
지금까지 QueryMapper를 사용하는 것을 보았는데 이는 DB의존성 및 중복되는 쿼리 문제가 있다.
따라서 ORM Object Relation Mapping 갹체 관계 매핑이 등장했다.
이는 DAO 나 Mapper Interface가 아닌 테이블을 객체와 대응시켜 버린다.
말이 쉽지 객체 관계 매핑을 적용시키는 데에는 많은 문제가 발생한다.
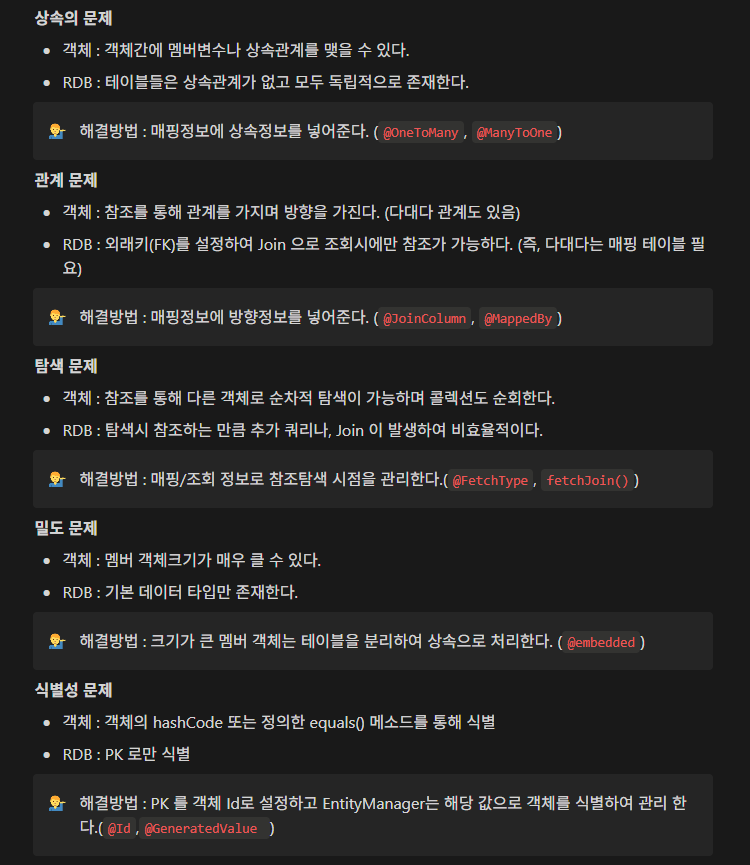
이와 같은 문제들을 해결해야 ORM이 가능한 것이다.
어노테이션들을 잘 활용하면 객체와 DB 테이블 차이점을 해결할 수 있다.
JPA or ORM 구현체가 가지고 있는 기능이 있다.
바로 영속성 컨텍스트 (1차 캐시) 이다.
이것을 활용해 데이터를 임시로 저장하여 재사용하거나
쓰기 지연을 통해 한번에 쓰기를 실행할 수 있다.
영속성이란 데이터를 생성한 프로그램이 종료되어도 데이터는 사라지지 않는 것을 의미한다.
우리는 데이터를 파일 or DB에 영구 저장하여 영속성을 부여한다.
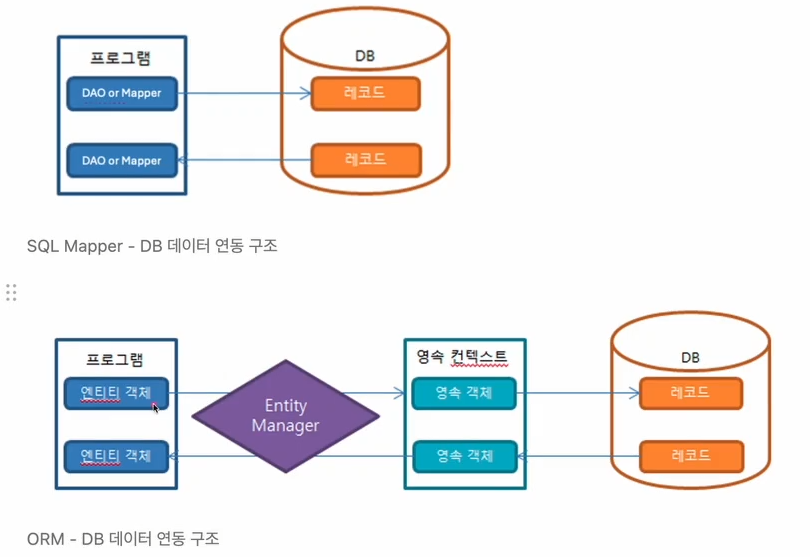
그래서 지금까지는 DAO or Mapper를 이용해서 저장해줬었다면
영속성 컨텍스트를 통해 데이터가 영속성을 가지게 만들고 DB 테이블에 있는
하나의 레코드 값과 매칭이 되게 한다.
엔티티 객체가 테이블을 직접 조회하는 것이 아닌 영속성을 가지는 영속 객체를
영속성 컨텍스트에서 마치 테이블 데이터를 조회하듯이 객체 조회를 하도록 하는 것이 영속성 컨텍스트를 의미한다. 이것은 하나의 저장공간이다.
이 저장공간을 엔티티 매니저가 중간에서 잘 활용하도록 자동화한다.
영속 객체는 4가지 상태로 분리된다.
-
비영속 new/transient
엔티티 객체가 만들어지기만 했지 영속성 컨텍스트와 전혀 관계가 없는 상태 -
영속 managed
엔티티 객체가 영속성 컨텍스트에 저장, 영속성 컨텍스트가 관리할 수 있는 상태
관리할 수 있다라는 것은 동기화를 해준다 라는 것이다. (동기화 외에도 다른 기능들도 존재) -
준영속 detached
영속성 컨텍스트에서 분리된 상태, 영속성 컨텍스트가 관리하지 않는 상태 -
삭제 removed
영속성 컨텍스트와 DB 에서 엔티티 객체를 삭제하겠다고 표시한 상태
- jpa 관점 순서 요약
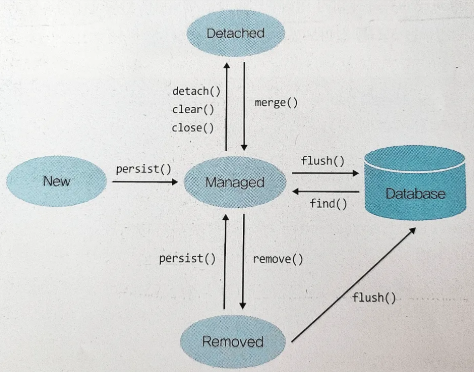
(이 사진 안의 메서드들은 EntityManager의 메서드들)
new로 객체 생성 (비영속 상태)
persist(), merge() 메서드 호출 (영속성 컨텍스트에 저장된 영속상태)
flush() (DB 에 쿼리가 전송된 상태)
commit() (DB에 쿼리가 반영이된 상태)
- 전송 상태와 반영 상태의 차이
우리가 sql 쿼리를 수행하면 기본적으로는 DB에 바로 반영된다 생각하지만 원래는 그렇지않다.
지금까지 바로 반영된 이유는 auto-commit 설정을 true로 해놔서
commit() 호출을 하지 않더라도 쿼리 전송만 하면 자동으로 DB에 커밋이 날라가
전송된 상태에서 반영된 상태까지 자동으로 넘어갔기 때문이다.
실제로는 내부적으로는 쿼리 전송을 했어도
commit() 메서드를 호출하거나 commit sql을 명령어를 사용해야 실제 DB에 반영되게 된다.
- 코드로 알아보기
Item item = new Item(); // 1
item.setItemNm("테스트 상품");
EntityManager em = entityManagerFactory.createEntityManager(); // 2
EntityTransaction transaction = em.getTransaction(); // 3
transaction.begin();
em.persist(item); // 4-1
em.flush(item). // 4-2 (DB에 SQL 보내기/commit시 자동수행되어 생략 가능함)
transaction.commit(); // 5
em.close(); // 6
1️⃣ 영속성 컨텍스트에 담을 상품 엔티티 생성
2️⃣ 엔티티 매니저 팩토리로부터 엔티티 매니저를 생성
3️⃣ 데이터 변경 시 무결성을 위해 트랜잭션 시작
4️⃣ 영속성 컨텍스트에 저장된 상태, 아직 DB에 INSERT SQL 보내기 전
5️⃣ 트랜잭션을 DB에 반영, 이 때 실제로 INSERT SQL 커밋 수행
6️⃣ 엔티티 매니저와 엔티티 매니저 팩토리 자원을 close() 호출로 반환
엔티티 매니저를 생성하는데 대부분 우리는 무엇을 만들 때 Factory를 사용하면 된다.
엔티티 매니저 팩토리에서 메서드를 호출하면서 엔티티 매니저를 가져오고
엔티티 매니저에서 트랜잭션을 가져올 수 있다.
begin() ~ commit() 까지가 하나의 트랜잭션 즉 하나의 작업인 것이다.
flush() 를 하기 전까지는 DB 에 쿼리문이 보내지지않는다.
이것이 쓰기 지연 효과인 것이다.
여러 개의 객체를 생성해서 한번에 보낼 수도 있다.
영속성 상태에서 객체가 생성되었다 삭제되면 실제 DB에는 아무런 동작이 이뤄지지 않을 것이다.
쿼리가 트랜잭션 당 최적화가 진행되어 최소로 필요한 쿼리만 날라가게 해준다.
하지만 @Id 를 생성할 때 @GeneratedValue 전략을 IDENTITY로 설정한다면
생성 쿼리는 쓰기지연 효과를 볼 수 없다.
new 메서드를 호출하는 순간 insert 쿼리가 날라간다.
이유는 identity 전략은 단일쿼리로 수행되면서 외부 트랜잭션에 의한 중복키 생성을
방지하여 단일키를 보장해야하기 때문이다.
JpaRepository
지금까지 트랜잭션에 대해서 알아봤고
지금까지 보았던 EntityManager를 사용하여 persist() 하고,, commit() 하고 하는 과정을
실제로 이렇게 코딩으로 구현해야할까? 아니다!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
우리는 JpaRepository가 있기에 이것을 상속받으면 SpringDataJpa 에 의해서
엔티티 CRUD, 페이징, 정렬 등 메소드들을 가진 빈이 등록되고 이것을 사용하면 된다.
// UserRepository.java
@Repository
public class UserRepository {
@PersistenceContext
EntityManager entityManager;
public User insertUser(User user) {
entityManager.persist(user);
return user;
}
public User selectUser(Long id) {
return entityManager.find(User.class, id);
}
}// UserRepository.java
public interface UserRepository extends JpaRepository<User, Long> {
// 기본 메서드는 자동으로 만들어짐
}확 줄어들었다. 간접적으로 엔티티 매니저를 사용해준다.
우리는 앞으로 이것을 사용해서 개발을 할 것이다.

