
Querydsl.. 어려워보여..
과제에서 Querydsl을 사용하기 전 아직 응애 jpa 능력을 가진 나를 위해
한번 정리해놓고 가자! 라는 의미로 적는 글이다.
Spring Data JPA 를 사용하면서 동적쿼리를 작성하기가 어려운 문제가 있다.
N+1 문제 같은 경우는 JPQL 을 사용할 수 있지만 문자열로 작성하기에
오류를 바로바로 알아차릴 수 없다는 점이 있다.
이 때 Querydsl을 사용해보면 좋겠죠?

DSL 이란 이런 의미이다.
데이터베이스 CRUD 를 위한 SQL, 스타일링을 위한 CSS, Regex 등이 해당된다.
Querydsl이란?
SQL 형식의 쿼리를 Type-safe 하게 생성할 수 있도록 하는 DSL을 제공하는 라이브러리이다.
쉽게 말해서 DB CRUD를 할 때 사용하는 SQL 문장을 자바 코드로 쉽게 작성할 수 있게
도와주는 도구라는 의미이다.
Querydsl 어떻게 설정하지?
환경에 따라 다르지만 spring boot 3.0 이후 버전을 사용한다고 가정하겠다
// 9. QueryDSL 적용을 위한 의존성 (SpringBoot3.0 부터는 jakarta 사용해야함)
implementation 'com.querydsl:querydsl-jpa:5.0.0:jakarta'
// annotationProcessor "com.querydsl:querydsl-apt:${dependencyManagement.importedProperties['querydsl.version']}:jakarta"
annotationProcessor "com.querydsl:querydsl-apt:5.0.0:jakarta"
annotationProcessor "jakarta.annotation:jakarta.annotation-api"
annotationProcessor "jakarta.persistence:jakarta.persistence-api"build.gradle 의 dependencies에 이 항목들을 추가해야한다.
annotationProcessor 는 길게 작성했던 것 같은데 이제는 짧게만 작성해도 된다.
길게 작성하는거랑 무슨 차이인지 나중에 알아봐야지
annotationProcessor 는 QClass 를 생성하기 위해 추가한다.
QClass 란?
엔티티 클래스 속성과 구조를 설명해주는 메타데이터이다.
Type-safe 하게 쿼리 조건을 설정 가능하다.
쉽게 말해서 Querydsl 에서 사용하는 엔티티 클래스의 설명서 같은 것이다.
DB 테이블과 컬럼을 자바 코드에서 쉽게 다룰 수 있도록 자동으로 만들어진 자바 클래스이다!
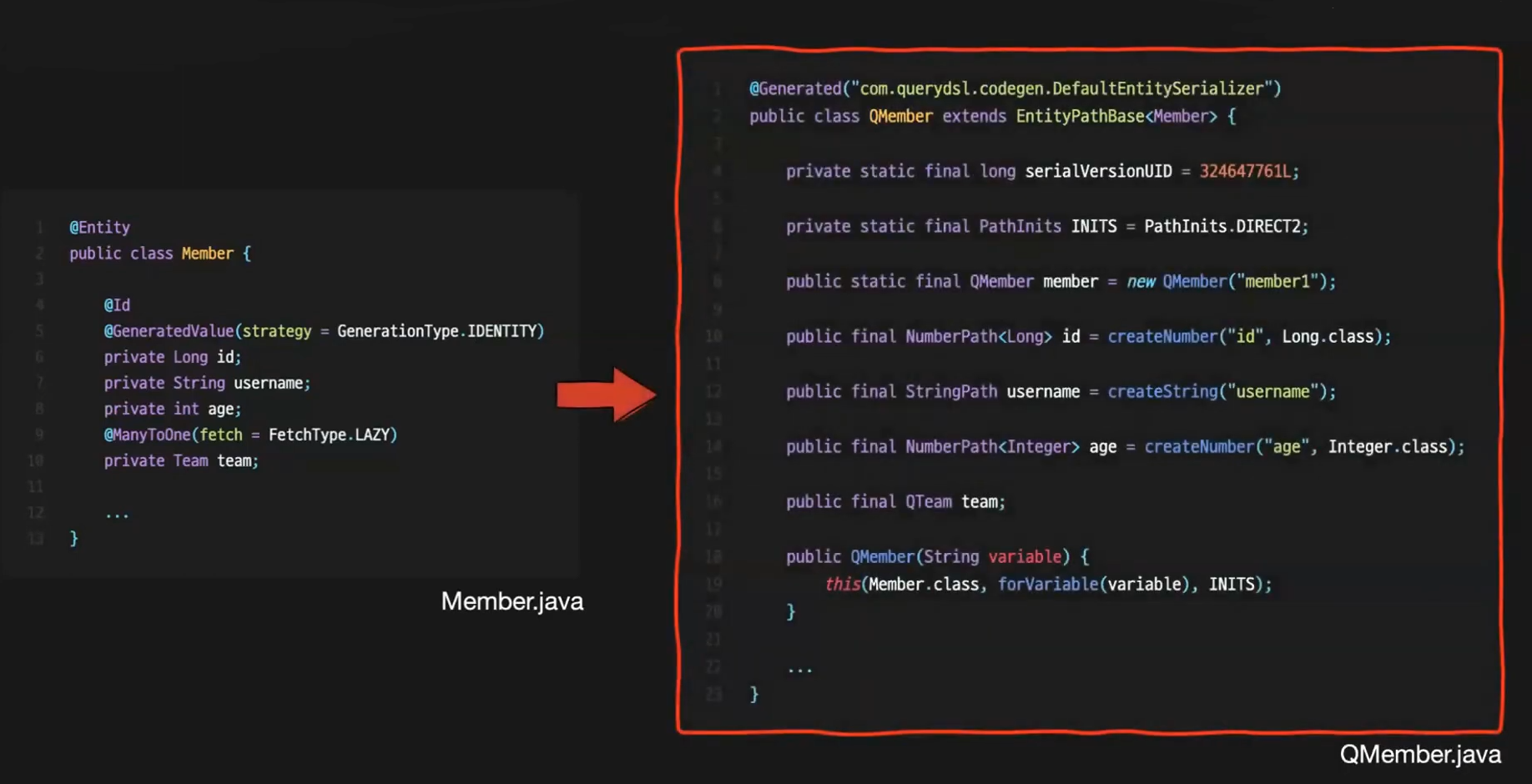
Member라는 엔티티 클래스가 있을 때 생성되는 Q Memeber 클래스의 모습이다.
자기 자신을 static으로 가지고 있고 테이블의 컬럼들이 똑같이 변수로 존재한다.
이들을 alias 처럼 사용할 수도 있고 참조관계인 team도 Qteam으로 가지고 있는 모습이다.
간단한 예시를 보았고 실제로 이것을 사용하려면 어떻게 하는지 알아보자.
Querydsl 사용 전 알아보자!
기존의 Querydsl 구조
기존에 Querydsl을 사용하려면
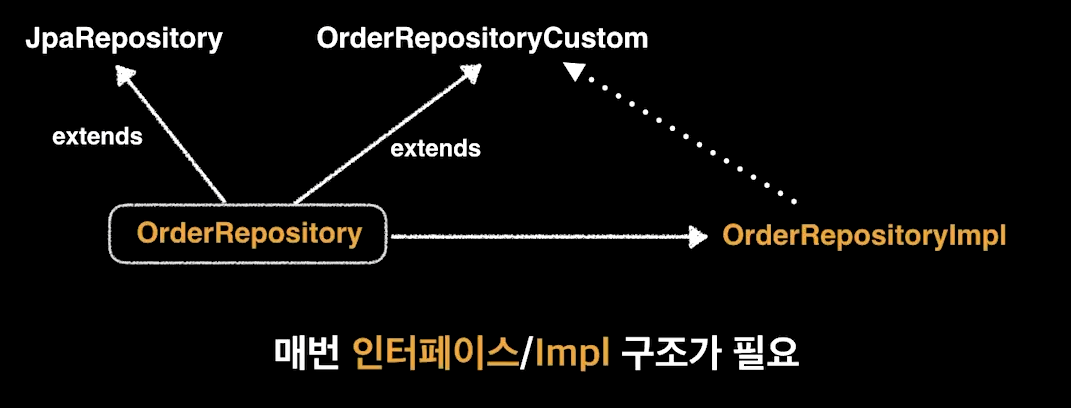
이런 구조가 필요했다.
JpaRepository의 상속을 받되 RepositoryCustom 이라는 별도의 인터페이스를 추가로
상속을 받고 해당 인터페이스의 구현체인 Impl 레포지토리가 필요한데
매번 이런 구조가 필요한 것은 과하다고 여겨질 수 있다.

Querydsl 서포트를 상속받은 구조를 사용할 수도 있지만
이것 역시 super 생성자에 엔티티를 매번 등록해야한다.
그래서 꼭 무언가를 상속/구현 받지 않더라도, 특정 엔티티를 지정하지 않더라도 Querydsl을
사용할 수 있는 방법을 사용할 것이다.
사실을 JPAQueryFactory만 있다면 Querydls 을 사용하는데에는 문제가 없다.
JPAQueryFactory만 생성자 주입을 받아 사용한다면 모든 기능을 이용할 수가 있더라~
이렇게하면 상속 구현 구조를 전부 제거하여도 된다.
동적 쿼리 구현은 어떻게?
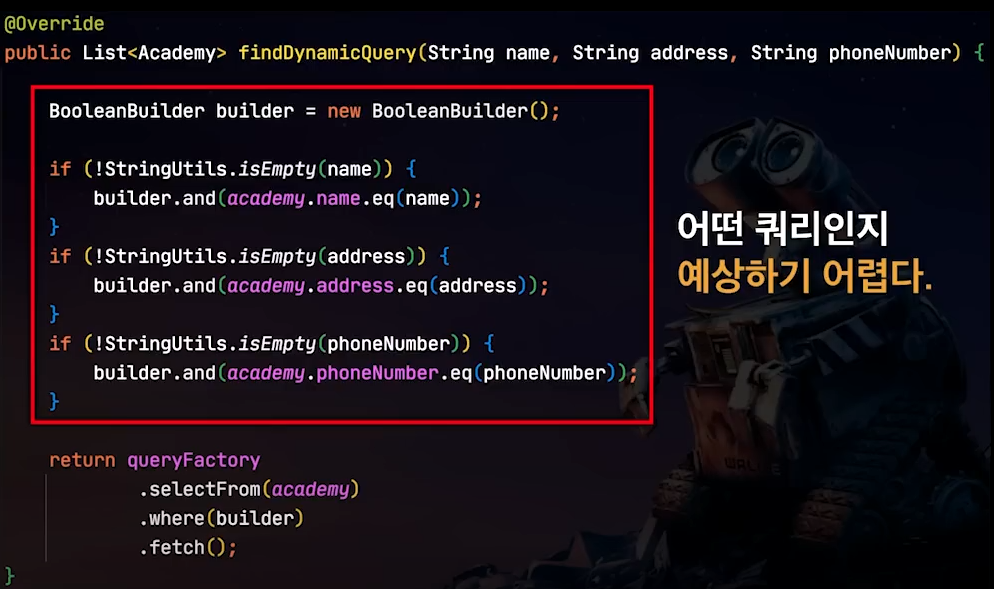
기존에는 BooleanBuilder를 사용했었다
이것은 어떤 코드인지 예상하기 어렵다.
칼럼이 늘어날 수록 if문이 길어지기 때문이다.
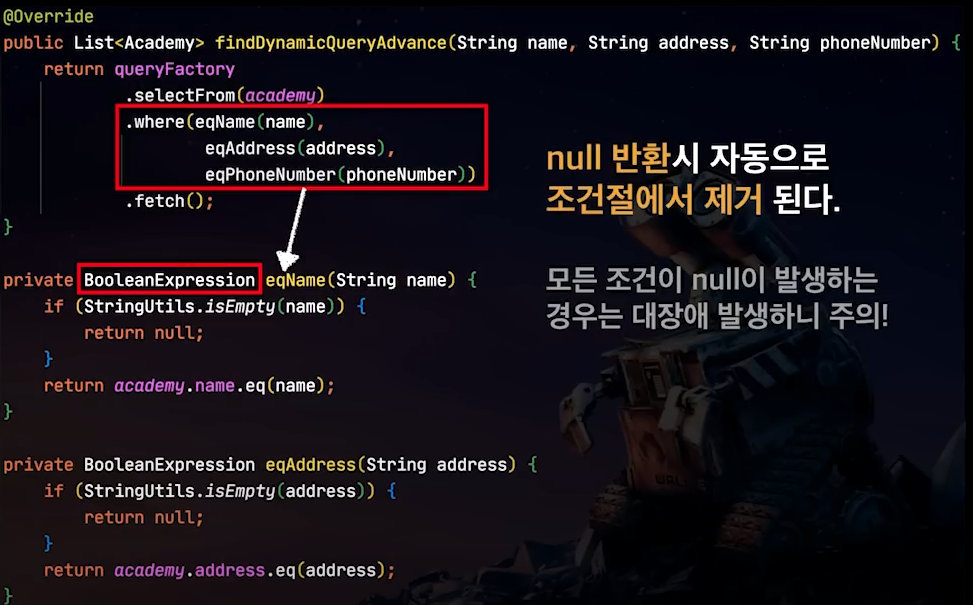
따라서 동적쿼리는 BooleanExpression 을 사용한다.
이것의 특징은 메서드로 만들어서 해당 값이 null 로 리턴될 경우 조건 자체가
제거가 되기 때문에 좀 더 명시적으로 알아볼 수 있는 쿼리형태를 만들 수 있다.
물론 모든 조건이 null 이라면 조건문이 다 삭제되기에 주의해야한다.
그래서 결국 뭘 해야한다구?
querydsl 을 사용할 레포지토리를 만들기 전
@Configuration 으로 config 파일을 만들어 설정해주어야한다.
//쿼리 dsl을 사용하기 위한 config 설정
@Configuration
public class QueryDslConfig {
@PersistenceContext
private EntityManager em;
@Bean
public JPAQueryFactory jpaQueryFactory() {
return new JPAQueryFactory(em);
}
}쿼리 DSL 을 사용하기 위한 config 설정이다
EntityManager를 생성하고 우리가 Querydsl을 사용할 때 필요한 JPAQueryFactory를
빈으로 등록해줄 때 매개변수로 넣어준다.
@Repository
@RequiredArgsConstructor
public class JpaUserListPagingQueryRepository {
//querydsl을 사용하려면 QueryDslConfig에서 설정한 jpa 쿼리 팩토리를 사용해야함
private final JPAQueryFactory jpaQueryFactory;
private static final QUserEntity user = QUserEntity.userEntity;
private static final QUserRelationEntity relation = QUserRelationEntity.userRelationEntity;
public List<GetUserListResponseDto> getFollwerList(Long userId, Long lastFollowerId){
return jpaQueryFactory
.select(이 코드는 예시이다.
후에 Querydsl 을 사용할 레포지토리 클래스를 생성하고 JPAQueryFactory 를 생성자 주입,
사용할 Q 객체를 가져오고 원하는 쿼리를 만들어 내면 되는 것이다.
사용 예시를 보자! 감은 잡아야지?
첫번째 요구사항
감사하게도 유튜브에 좋은 사용 예시를 보여주는 영상이 있다.
이 블로그 글을 쓸 때 참고한 영상들은 마지막 출처에 남겨놓을 것이야
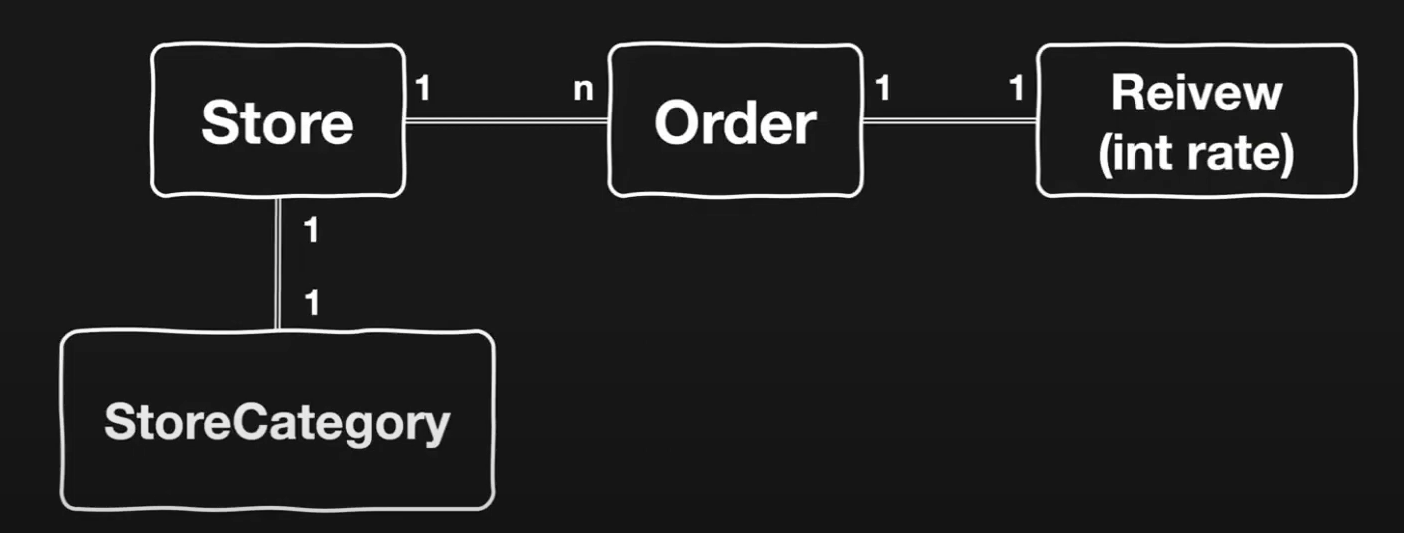
예제 도메인이다.
특정 카테고리에 포함된 모든 가게를 조회해달라는 요구사항이 들어온다면?
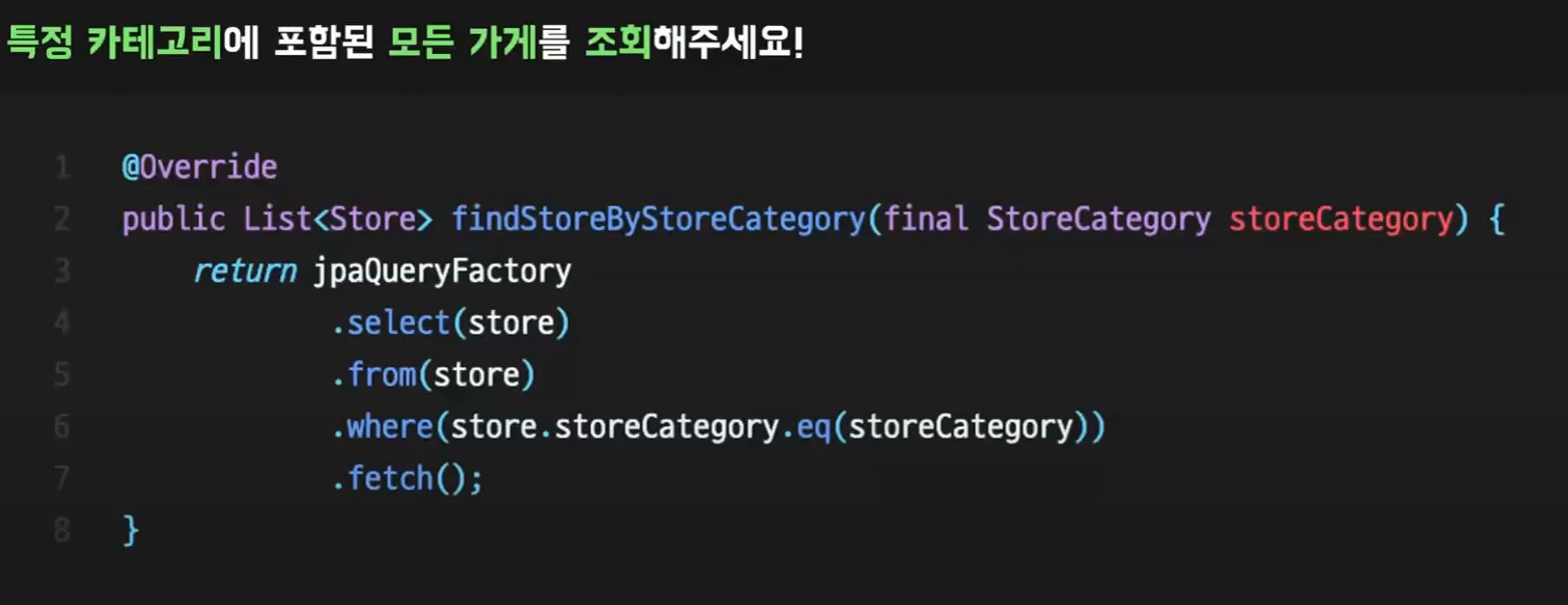
이런식으로 구현하면된다.
어떤 쿼리문인지 SQL 을 알고있는 사람이라면 한눈에 알아볼 수 있을 정도이다.
Select 절
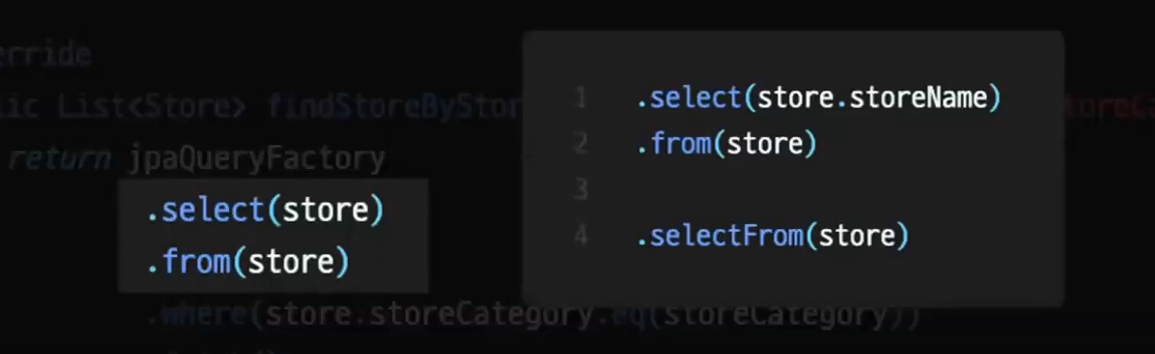
select 절에는 QClass or QClass 내부 필드들을 넣어줄 수 있다.
그 후 from 절에 어디서 조회할 건지 QClass를 넣어주면 된다.
두 개가 동일하다면 selectFrom 으로 한번에 작성이 가능하다.
Where 절
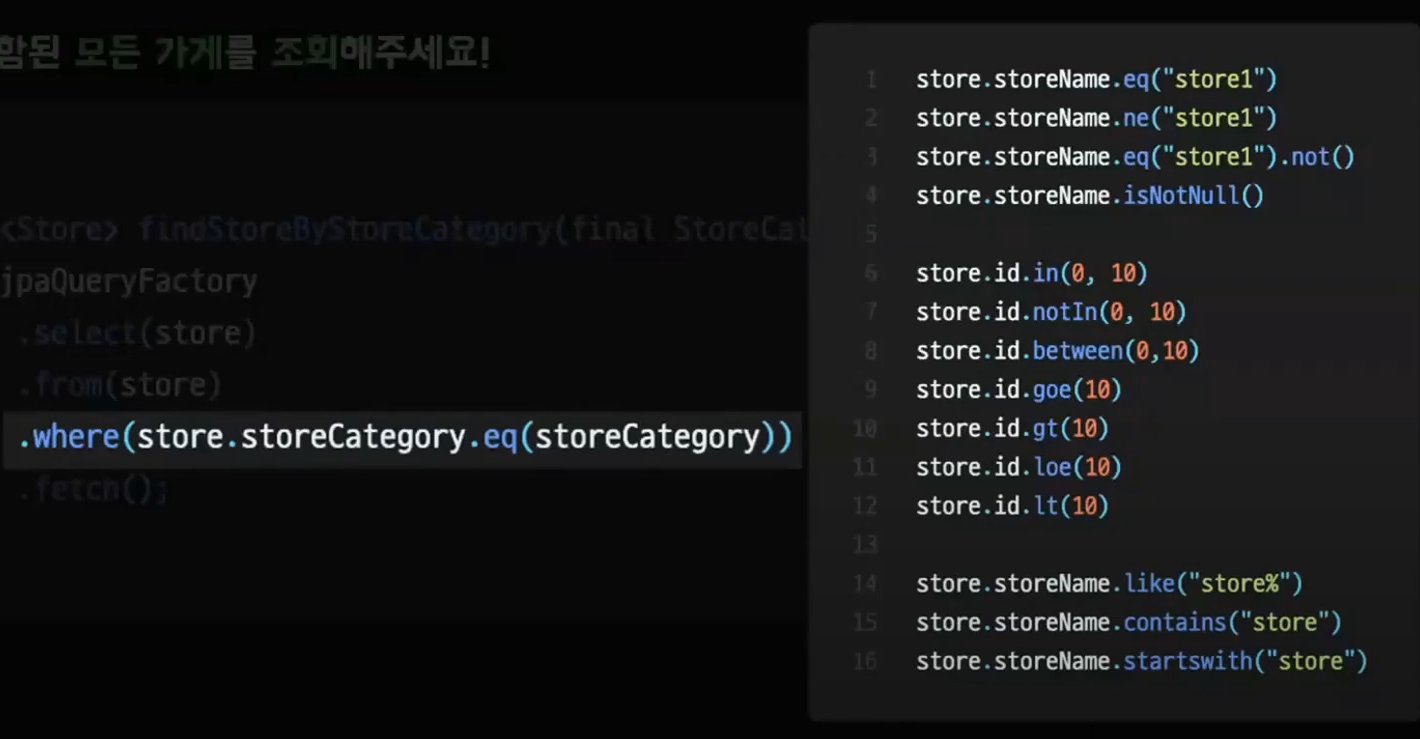
다양한 조건 메서드를 사용할 수 있다
equal notequal in notIn 등 다양한 메서드들을 사용할 수 있다.
결과 조회
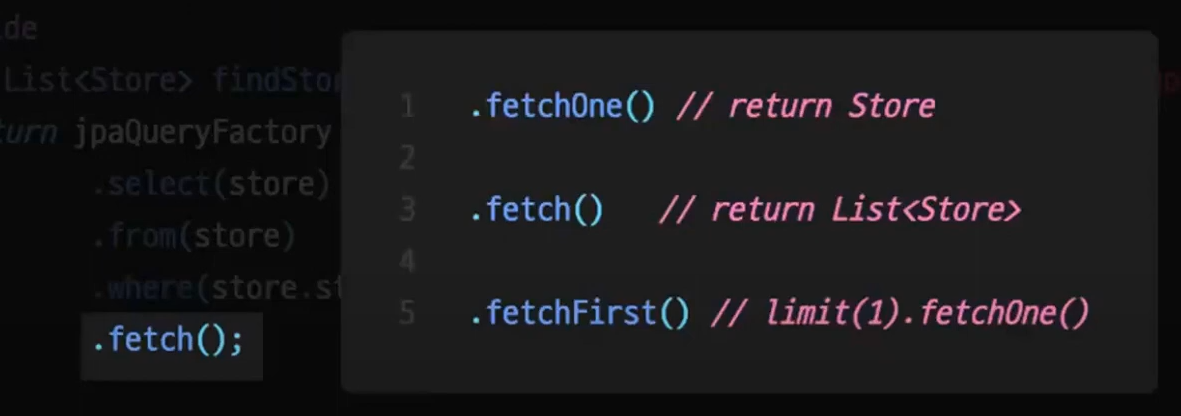
결과 조회에 다양한 메서드들이 존재한다.
3개를 꼽자면 fetch / One / First 를 볼 수 있다.
두번째 요구사항
새로운 요구사항이 들어왔따.
특정 카테고리에 포함된 모든 가게를 리뷰가 높은 순으로 정렬해서 조회해달라는 요구사항이다.
다 했는데 이렇게 새로운 요구사항이 들어온다?
바로 피가 거꾸로 솟을 것 같지만 참아야한다.
우리에겐 Querydsl 이 있으니까

변경된 코드이다.
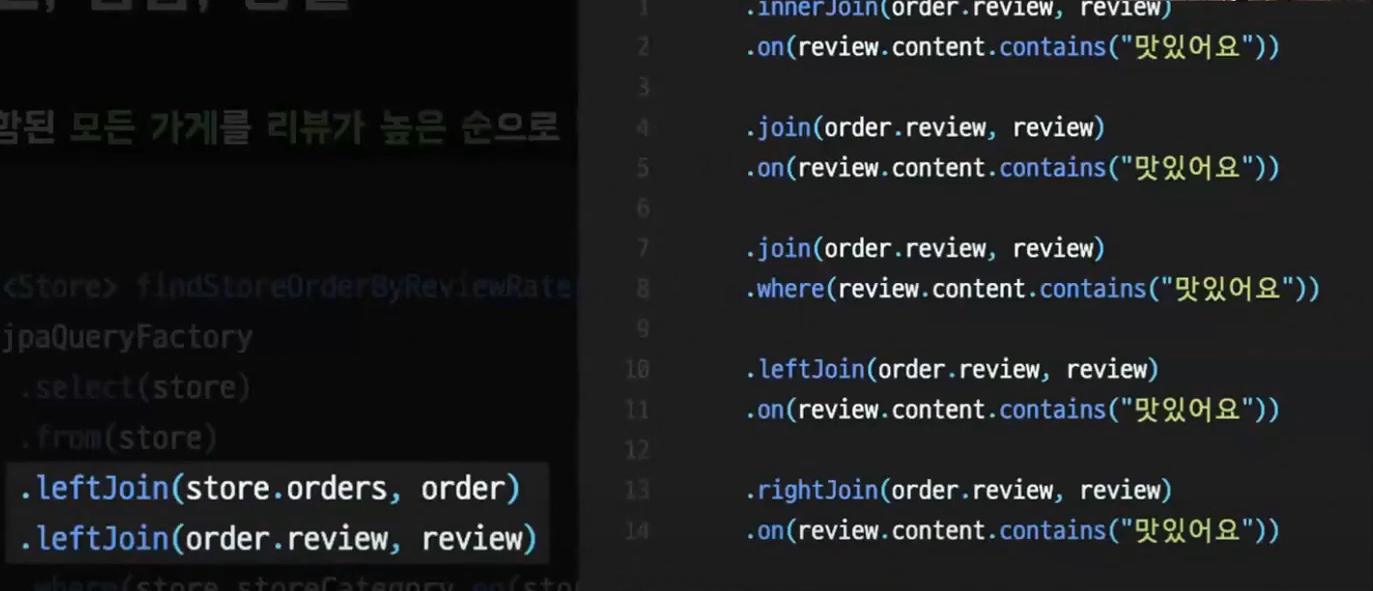
leftJoin 이 추가된 모습을 볼 수 있다.
이 외에도 Querydsl 에서는 다양한 join 을 제공해준다. 참고하자.
inner join 과 join 은 동일하다. on , where 의 차이!
연관관계가 없는 두 테이블도 join 이 가능하다.

where 조건에 넣어주면 되는데 이는 카테시안 곱이 발생하므로 함부로 쓰면 안되겠죠?
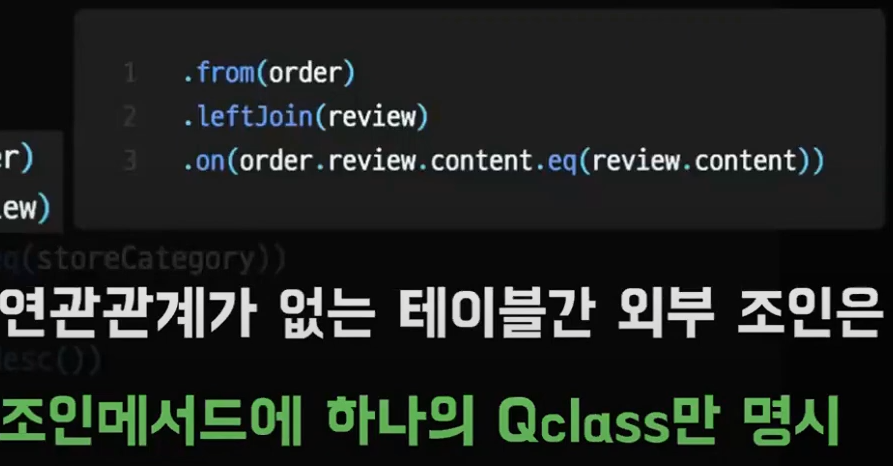
다음으로 연관관계가 없는 테이블 간의 outer join 이다.
비슷하지만 바로 위의 join 예시와는 다르게 leftjoin 괄호 내부에 하나의 QClass 만
명시되어 있는 모습을 볼 수 있다.

N+1 문제를 해결하기위해 JPQL 에서 fetch join 을 사용했었을 텐데
querydsl 도 fetchJoin 을 제공하여 해결할 수 있다.
참고사항은 2개 이상의 OneToMany 관계는 연속된 fetchJoin 이 안된다는 점이다.

아까 store 와 order, store와 review는 oneToMany 관계인 것을 알 수 있었으니
이렇게 사용할 수 없다는 것을 의미한다.
이는 JPQL의 특징이기도 하다.
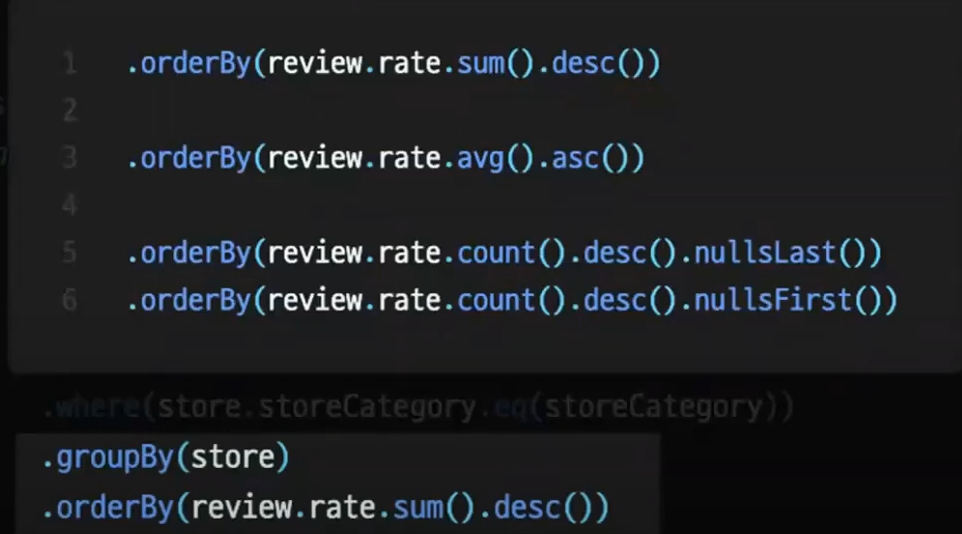
groupBy orderBy 도 생겼다.
그룹핑하고싶은 조건, 정렬 조건을 넣어주면 된다.
집계함 수는 select, groupby 등 다양한 곳에서 활용이 가능하다.
또 outerJoin 같은 경우는 null을 포함하는데 이걸 앞에 넣을지 뒤에 넣을지도 정할 수 있다.
세번째 요구사항
싸울래?
그래도 해야된다.
서비스에 등록된 가게가 너무 많아져서 특정 카테고리에 포함된 가게를 10개씩 페이지네이션 하여
리뷰가 높은 순으로 정렬해서 조회해달라는 요구사항이 새로 들어왔다.
즉 페이지네이션을 추가해달라는 의미이다.
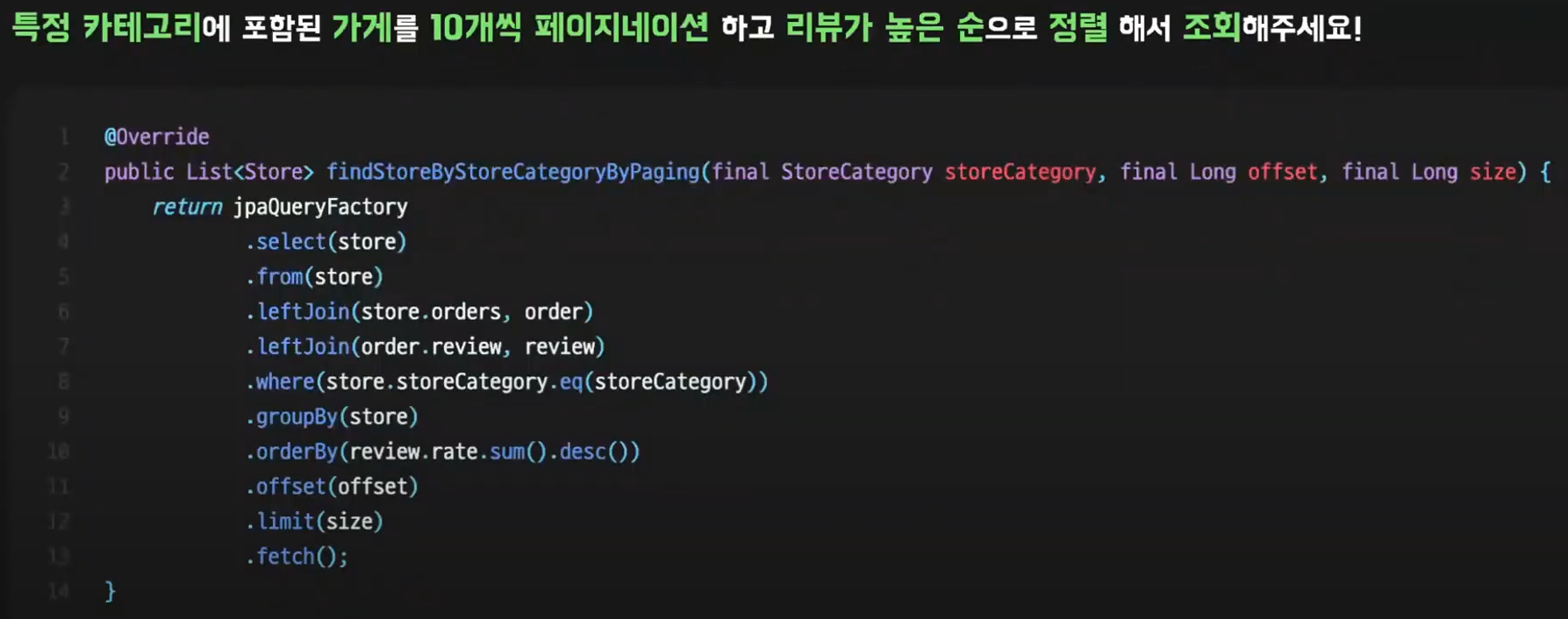
어렵다고 생각할 수 있지만 의외로 쉽게 풀린다.
마지막에 offset, limit을 추가하면 해결된다.
offset을 통해 몇번째 페이지를 조회할건지 size는 limit으로 설정이 가능하다.
네번째 요구사항 (서브쿼리)
이젠 포기할래.. 뭘까
전체 리뷰 평균 별점보다 평점이 높은 가게만 골라 평점 순으로 조회해달라는 요구사항이다.
말만 들어도 어지러워보일 수 있지만 침착하자.
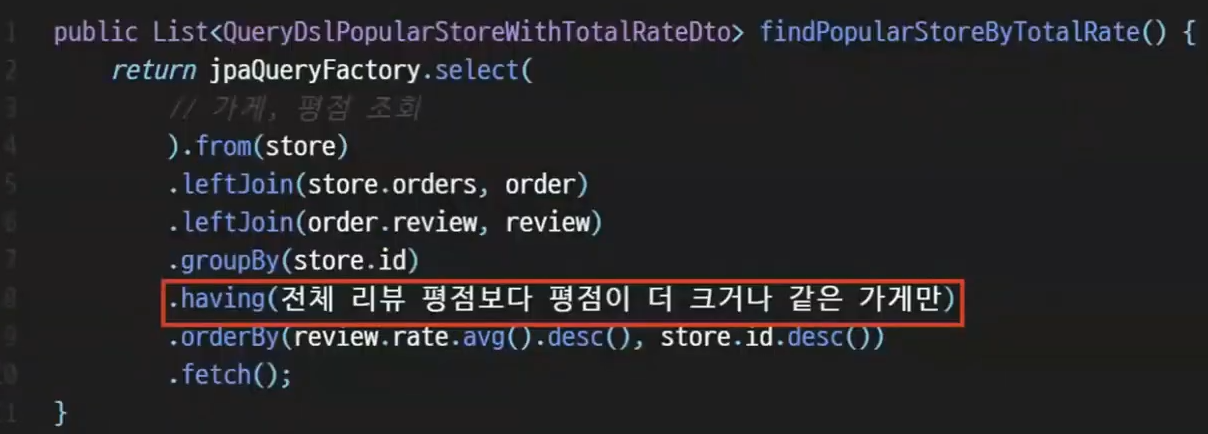
이 요구사항을 만족시키기 위해서는 가게에 대해서 그룹핑을 진행한 후
having 절에 전체 리뷰 평점 평균보다 더 크거나 같은 가게만 뽑아와야한다.
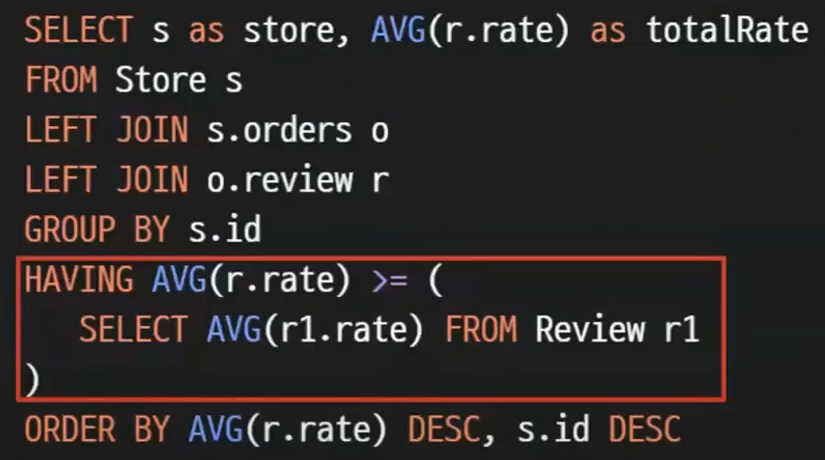
여기 보이는 JPQL 처럼 서브쿼리를 작성하면 되는데 우리는 Querydsl 을 사용하고 있지않은가?
서브쿼리를 어떻게 작성할까?

서브쿼리에 효율적인 JPAExpressions를 사용하면 된다.
이는 서브쿼리에 특화된 유틸성 클래스로 공식문서에서도 서브쿼리를 작성할 때 이것을 사용한다.

이제 어떻게 사용하는지 보자.
리뷰를 의미하는 큐클래스를 만들었고 이걸 이용해서 전체 평점을 계산해주는 쿼리를 작성했다.
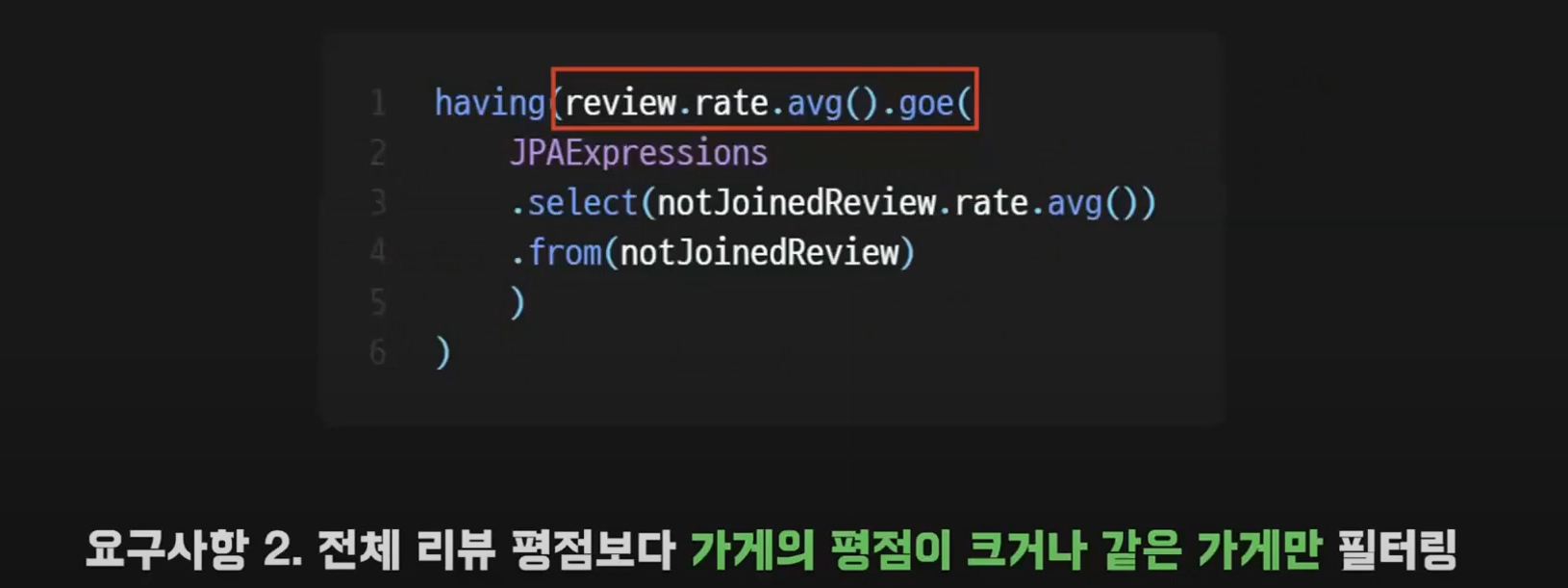
앞에서 계산한 전체 리뷰의 평점보다 가게의 평점이 크거나 같은 가게를 필터링한다.
having 절 내부에서 가게 리뷰의 평점을 구하고 방금 구한 JPAExpressions 의 서브쿼리를 넣어서 조건에 걸리도록 사용했다.
goe 는 greater or equals 이다.
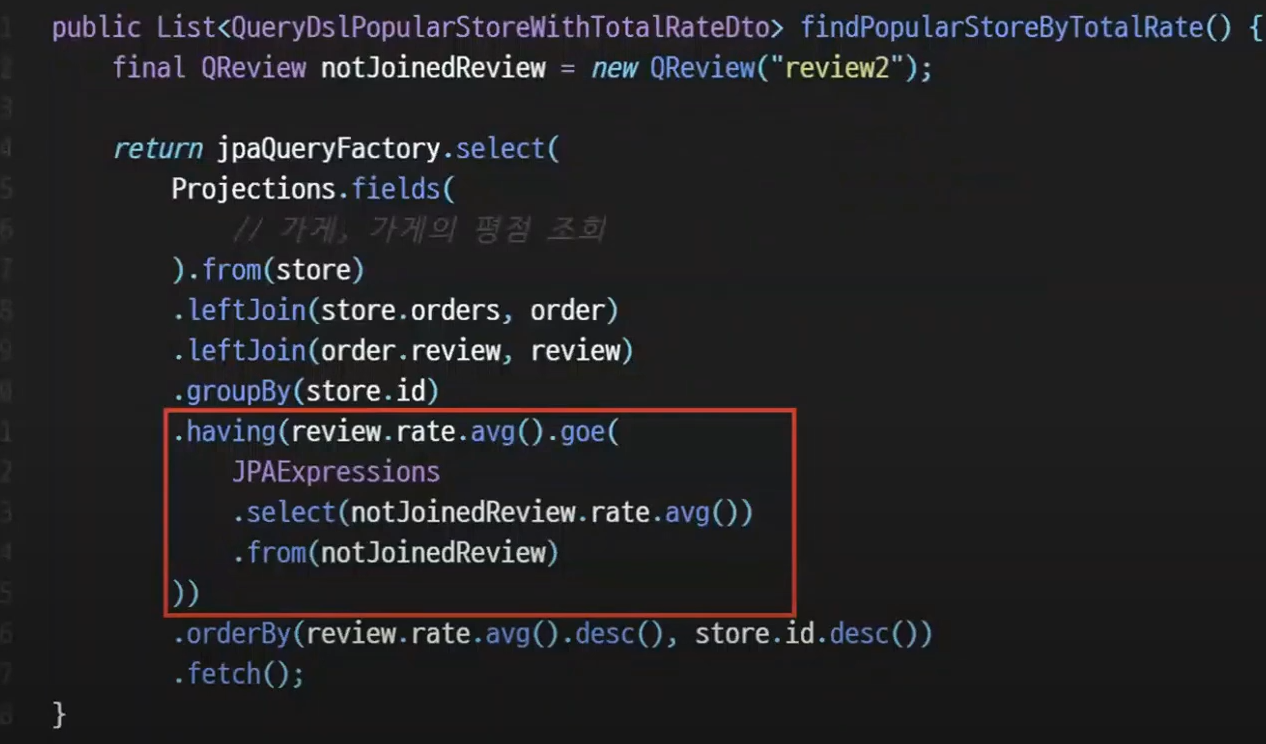
완성본의 모습은 이렇다.
복잡할 것 같았던 서브쿼리문을 JPAExpressions 를 사용하여 꽤 손쉽게 해결했다.
하지만 having 절의 depth가 깊어져서 한 눈에 알아보기가 힘들다.
또 지금은 어느정도 알아볼 수는 있는 쿼리지만 이게 더 길어진다면 알아보기가 더 힘들 것이다.
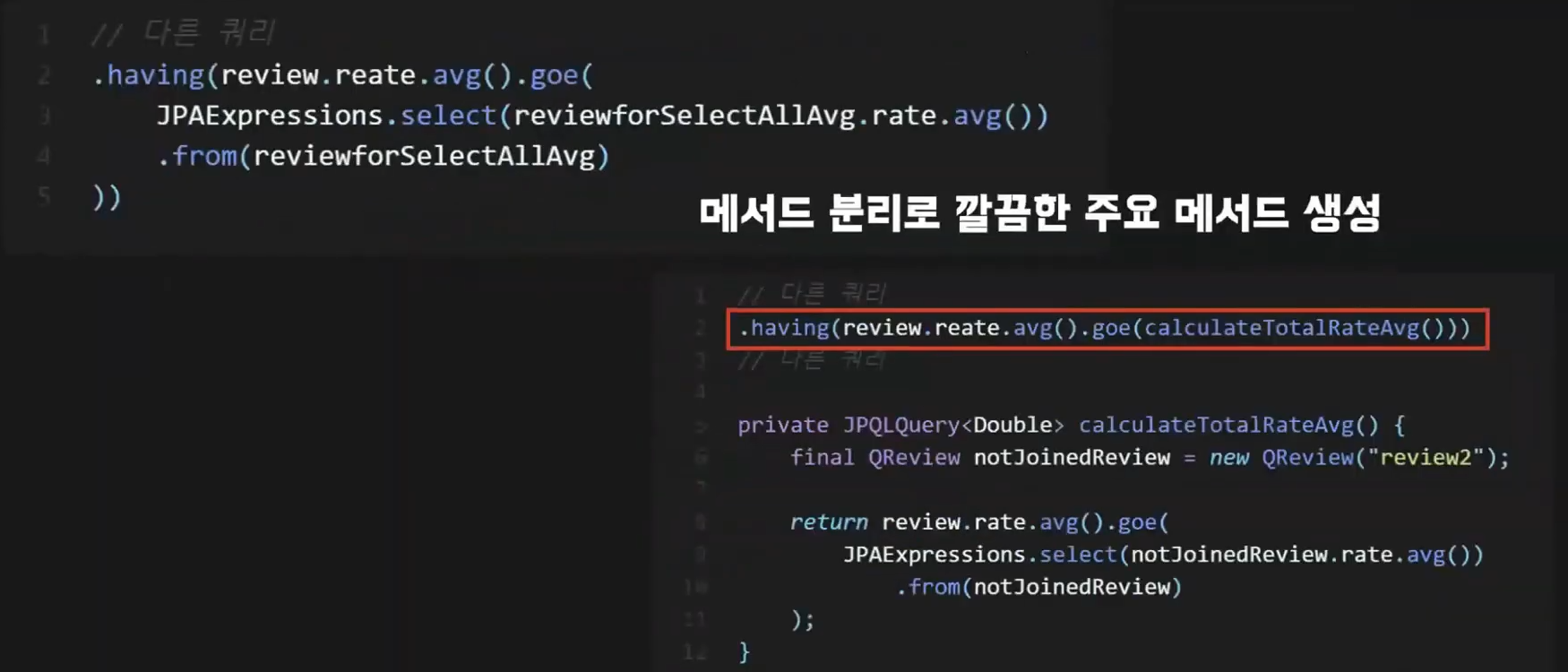
따라서 사용한 서브쿼리를 메서드로 분리할 수도 있다.
calculateTotalRateAvg 라는 메서드에 방금 서브쿼리에 진행했던 작업을 빼서 메서드로 두면
having 절에서 해당 메서드 명으로 쿼리문을 사용이 가능하다.
여기서 의문점
우리는 원래 큐클래스의 미리 만들어진 인스턴스가 static이기 때문에 import 하여 사용한다.
그런데 왜 서브쿼리에서는 review2 라는 QReview를 생성한 것일까?
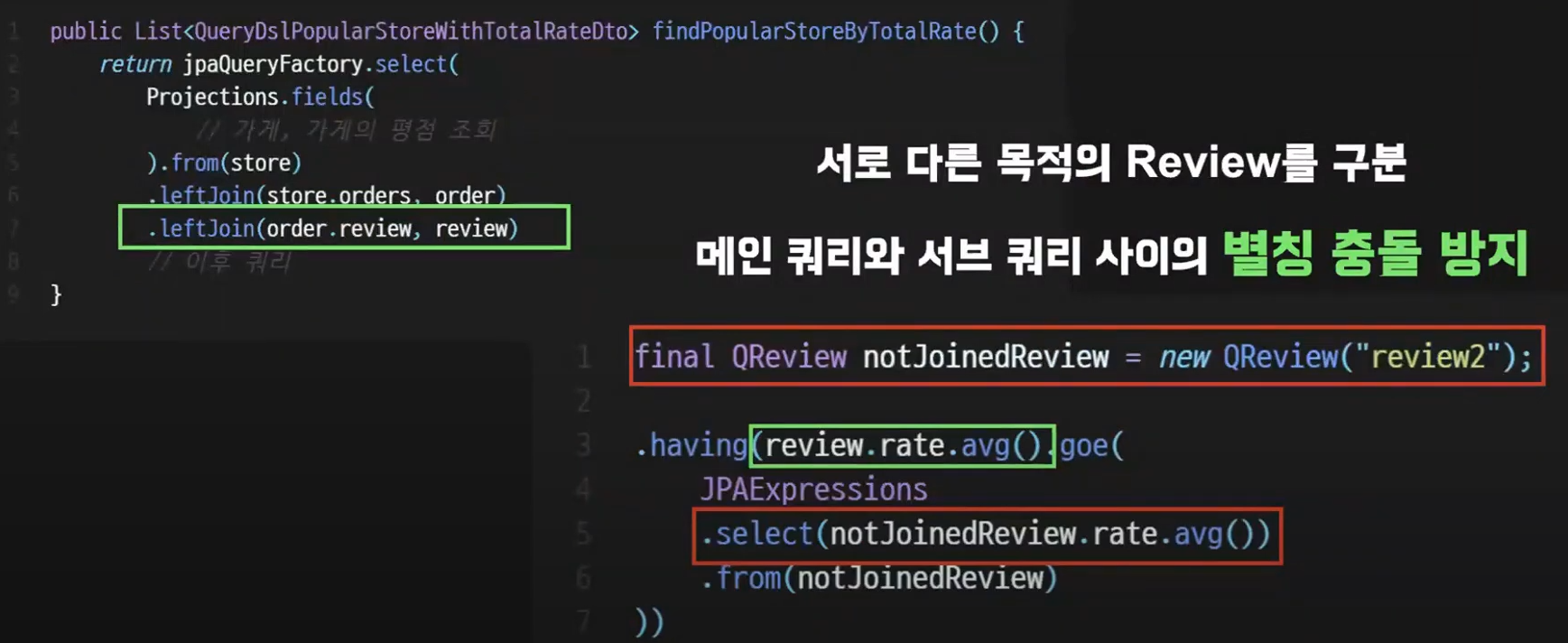
바로 import 되어 leftJoin 에서 사용된 리뷰와
서브쿼리에 사용한 리뷰가 다른 목적을 가지고 있기 때문이다.
왼쪽은 선택하고싶은 대상이 되는 리뷰를 뜻한다. 즉 전체 평균과 비교할 각 가게의 리뷰
오른쪽은 가게와 관련없이 그냥 모든 리뷰에 대해서 전체 평균을 계산하는 것이다.
따라서 별칭이 충돌하지 않게 새로 생성한 것이다.
왼쪽에 있는 review 는 "review1" 이라는 별칭이 적용되어져 있는 상태다.
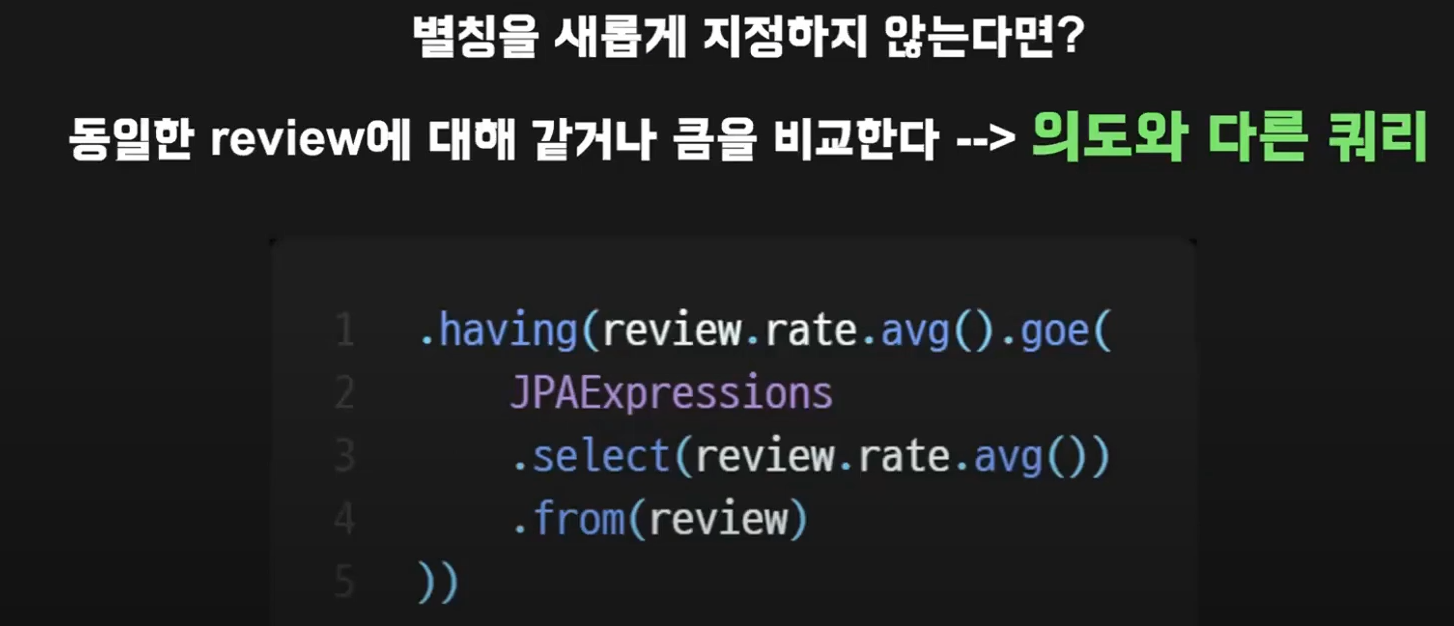
별칭을 따로 지정하지 않는다면 서브쿼리에서 사용되는 리뷰,
메인 쿼리에서 사용되는 리뷰가 같기에 나와 나를 비교해야하는 아이러니한 상황이 벌어진다.
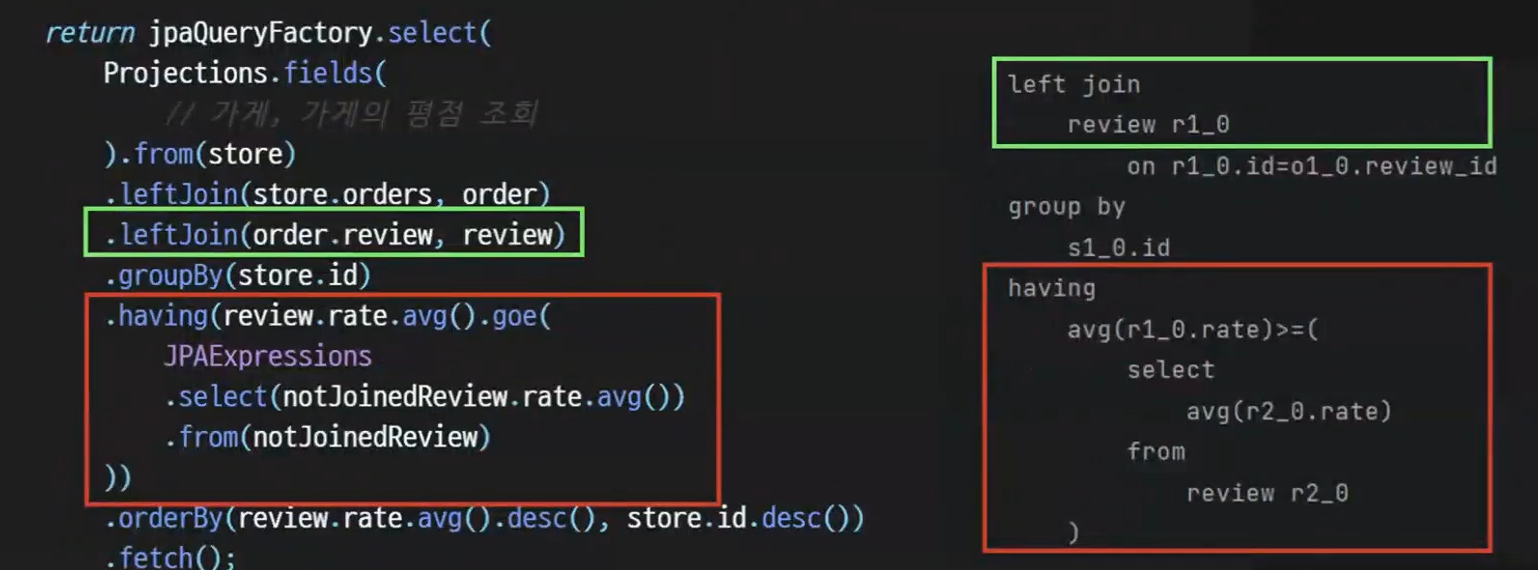
실제로 실행하여 쿼리문을 살펴보면 left join 에 사용된 review는 r1
having 절에서 사용된 review는 r2 인 모습을 볼 수 있다.
마지막 요구사항 (동적쿼리, 정렬, BooleanExpression)
진짜 마지막 맞죠? ㅠㅜ 믿습니다
이번 요구사항은 가게 평점 순, 주문 순 중 선택해서 조회하고 싶고
사용자가 원하는 기준 이상의 가게들만 조회하게 해달라는 요구사항이다.
즉 평점 or 주문을 선택하고 자신이 원하는 별점 이상, 주문수 이상인 건을 조회해달라는 의미다.
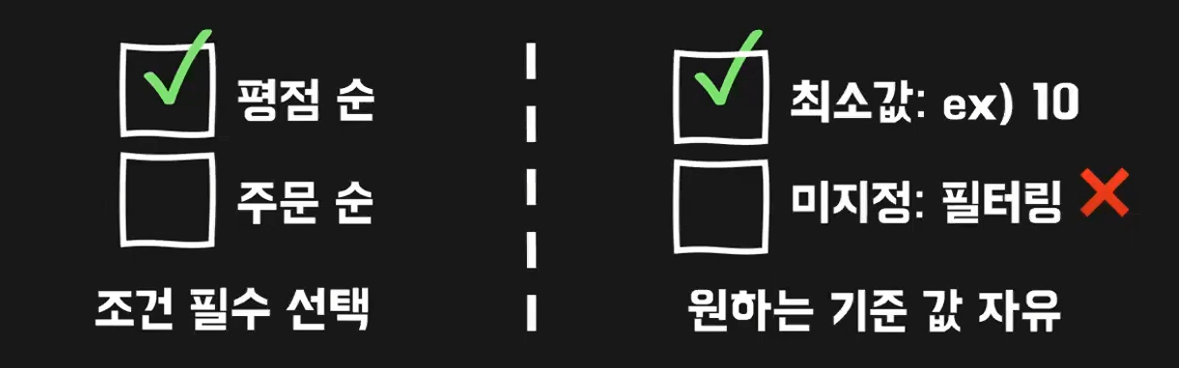
평점과 주문 조건은 둘 중에 하나를 필수로 선택해야하고 기준값은 자유롭게 해도 된다.
전달된 요청에 따라 쿼리가 변화하는 동적쿼리인 모습이다.
이에따라
-
주문 순인지 평점 순인지에 따라 계산식, 정렬 순서가 달라진다.
-
기준이 되는 최소값의 선택 여부에 따라 가게들의 필터링 여부가 결정된다.
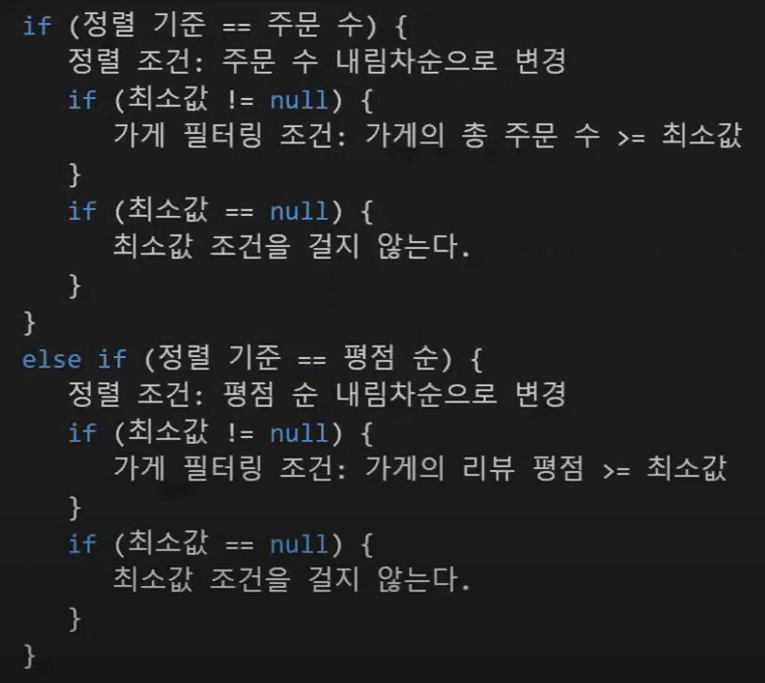
수도 코드로 작성하면 이렇게 나온다. JPQL 로 작성한다면 상상하고 싶지 않다.
이렇게만 봐도 복잡한데 이런 조건을 어떻게 Querydsl 로 구현할 수 있을까?
이제 처음 부분에서 동적쿼리에 사용하라고 말했던 BooleanExperssion 이 등장한다.

예를들어 이러한 Querydsl 이 존재한다고 할 때 store.name.eq("덮밥") 은
가게 이름이 덮밥과 같은 것을 고르는 조건을 건 모습이다.
이 자체가 바로 BooleanExpression 이다.
조건을 나타내는 부분에 들어가는 참/거짓 표현식을 BooleanExpression 이라고 한다.

또한 BooleanExpression 은 조합해서 더 큰 Expression을 만들 수도 있다.
즉 여러 조건을 , 를 통해 같이 적용시키는게 가능하다는 의미이다.
또한 null 이 반환된다면 자동으로 조건에서 무시되게 된다.
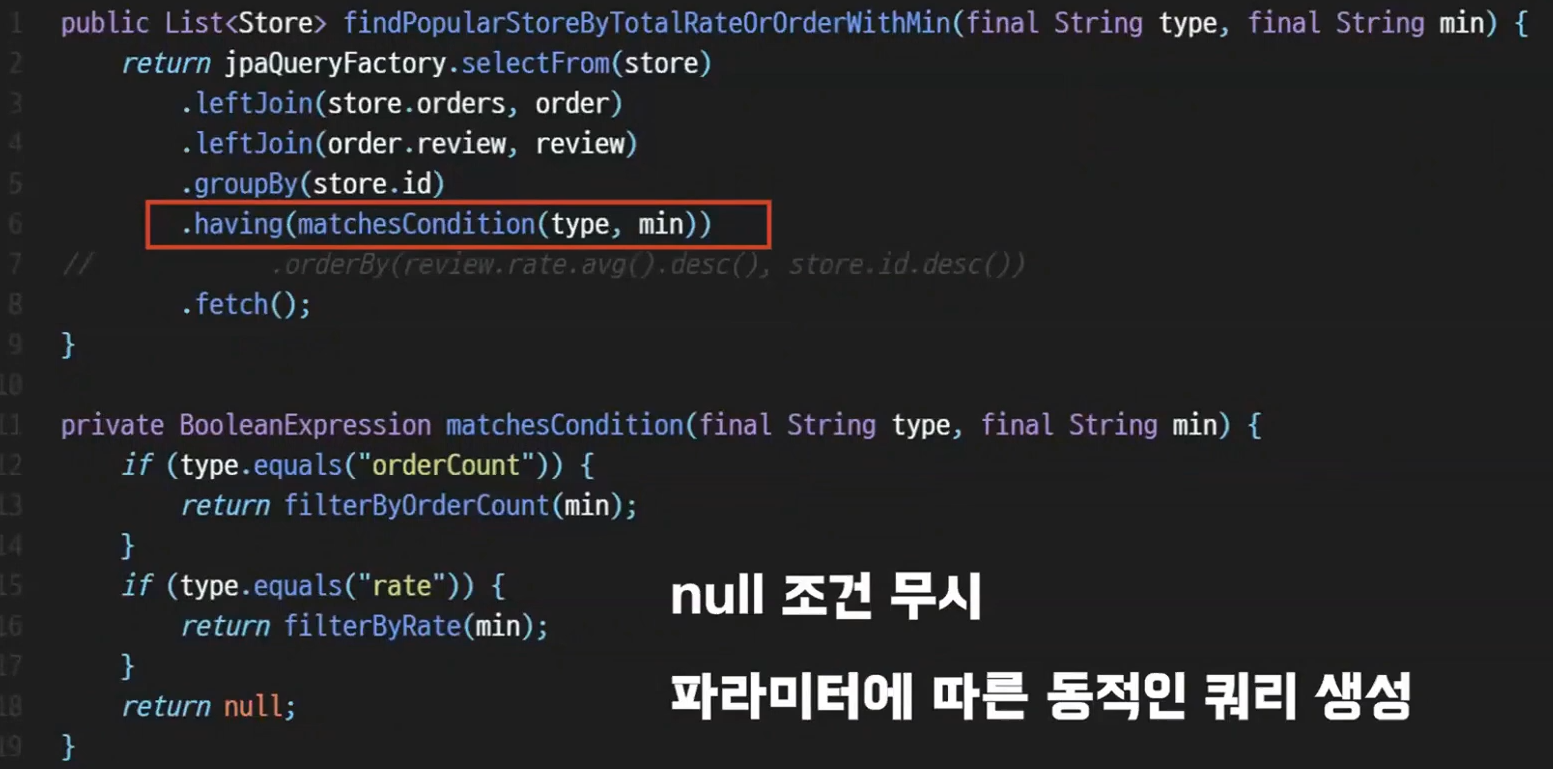
실제로 적용한 모습을 보자. having 절에서 메서드를 호출하는 모습으로 깔끔히 정리되었다.
matchesCondition 메서드는 BooleanExpression 인 모습이다.
type 이 orderCount 로 들어오면 filterByOrderCount 에 최소 기준값을 넘겨주게된다
rate 도 마찬가지로 동작한다
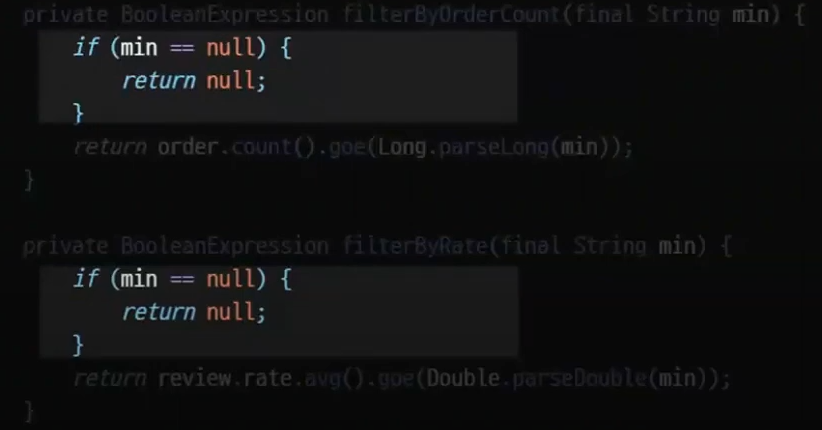
최소값 min 을 지정하지 않으면 null 이므로 조건이 걸리지 않게 처리가 가능하다.
현재 작업은 QueryDSL을 사용하여 store 데이터를 그룹화하고,
그룹화된 데이터에 조건을 적용하는 단계까지 완료한 상태이다.
-
그룹화는 store를 기준으로 이루어졌으며,
관련된 주문(order) 및 리뷰(review) 데이터를 조인하였다. -
조건은 사용자가 선택한 type(예: 주문 수 또는 평점)과 최소 기준값(min)을 기반으로
동적으로 추가시켰다. -
type, min 둘 중 하나라도 없는 경우 null 이 return 되므로
해당 조건은 무시되도록 설계되었다. -
이제 조건에 맞는 데이터를 정렬하는 로직을 추가하는 작업을 진행해야한다.
정렬된거라고 순간 착각하여 코드의 의미를 적어두려고한다.
min 이 있는 경우에만 해당된다.
코드의 의미:
-
return order.count().goe(Long.parseLong(min));- 해석:
order.count()는 특정 가게(store)에 연결된 주문의 총 개수를 계산한다.
goe(Long.parseLong(min))는 계산된 주문 개수가min값 이상인지 확인한다. - 결과:
type이"orderCount"일 경우, 주문 수가 최소 기준(min) 이상인 가게들만 조회된다.
- 해석:
-
return review.rate.avg().goe(Long.parseDouble(min));- 해석:
review.rate.avg()는 특정 가게(store)에 연결된 리뷰의 평균 평점을 계산한다.
goe(Long.parseDouble(min))는 계산된 평균 평점이min값 이상인지 확인한다. - 결과:
type이"rate"일 경우, 평균 평점이 최소 기준(min) 이상인 가게들만 조회된다.
- 해석:
요약:
- 주문 수 조건 (
type = orderCount):- 특정 가게의 주문 수가 최소 기준 이상인 가게들을 조회한다
- 평점 조건 (
type = rate):- 특정 가게의 평균 평점이 최소 기준 이상인 가게들을 조회한다
즉 여기까지는 조회만 진행한 것이고 Order by 정렬을 따로 해줘야하는 것이다.
그렇다면 orderCount 인 경우 주문 순 정렬, rate 인 경우 평점 순 정렬을 해야한다.
동적인 정렬조건을 적용하려면 OrderSpecifier를 사용하면 된다.
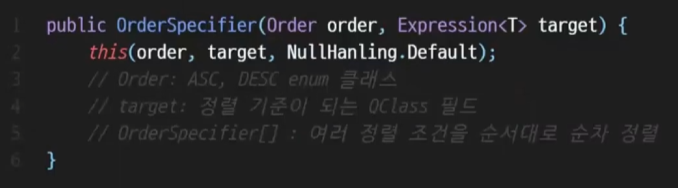
OrderSpecifier 가 뭔데?
Querydsl 에서 제공하는 클래스이다.
오름 차순, 내림 차순을 의미하는 Enum 값,
어떤걸 기준으로 정렬할지의 필드 값,
세번째는 배열값으로 첫번째값으로 정렬하고 두번째 값으로 정렬할 수 있는 조건이있다
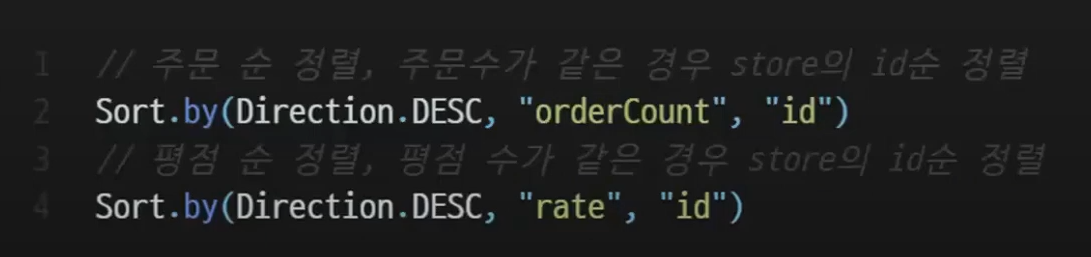
여기에 Pageable의 정렬 Sort 를 사용해 동적인 OrderSpecifier를 생성한다.
Sort 도 OrderSpecifier 와 비슷하다. 정렬 순서를 나타내며 어떤걸 기준으로 정렬할지를 적어줄 수 있다. 개발자가 지정한 문자열을 적어주면된다.
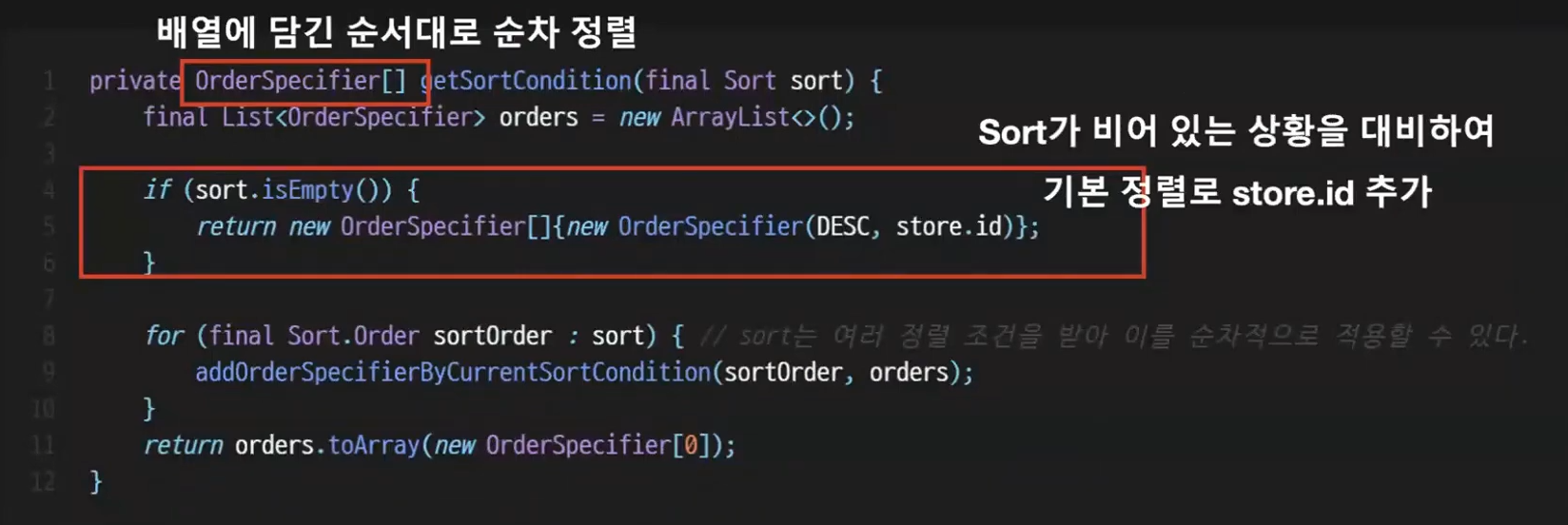
OrderSpecifier 배열이므로 순차정렬을 진행할 것이라는 의미이다.
sort를 넘겨받는데 이게 비어있다면 정렬조건을 지정하지 않았다는 의미이므로
null을 반환하면 오류가 터지므로 그렇지 않게 기본 정렬으로 store.id를 지정해두었다.
sort에는 정렬 조건이 여러개 들어올 수 있으므로 순회하면서 specifier 배열에 넣어준다.
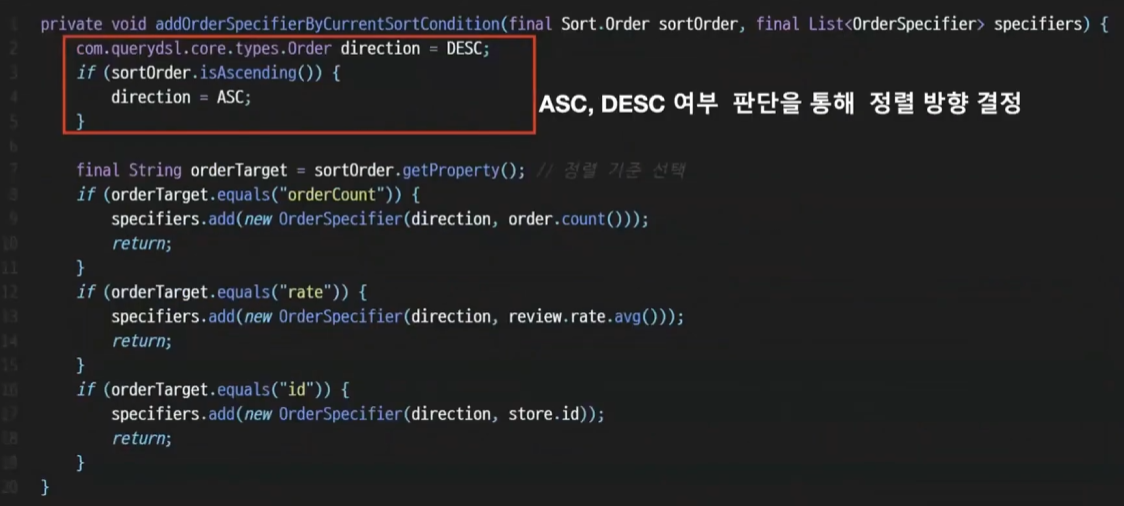
-
단일 order의 오름차순 내림차순 여부를 판단한다
-
sortOrder 에서 getProperty를 호출하면

아까 넣어준 orderCount, rate 값이 들어오게 된다.
이 값에 따라 OrderSpecifier 를 따로 지정해주고 넣어주는 것이다.

이렇게 사용하고 나서 정렬조건을 받는다면 실제 결과는 저렇게 나온다.
최종적으로 만들어지는 Querydsl 의 모습이다.
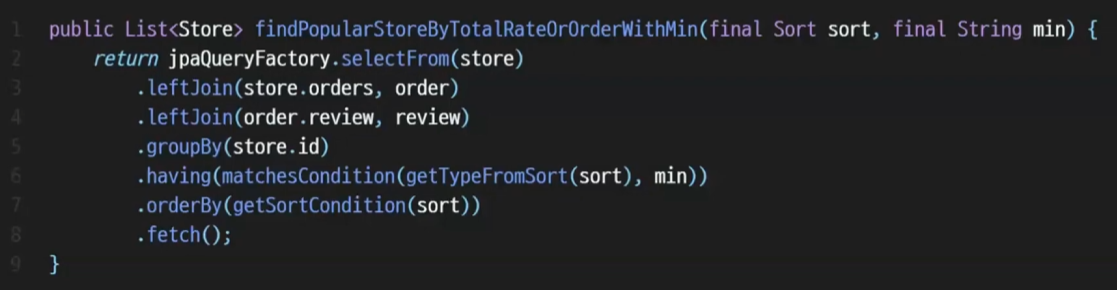
복잡한 요구사항도 한 눈에 볼 수 있게 만들어졌다.
메서드 이름을 통해서 어떤 조건을 만족하는지도 파악할 수 있으니 어떤 쿼리인지도 알 수 있는 것이다.
장점 정리
가독성이 향상되고 메서드 네이밍을 통해 쿼리 조건, 정렬 방식이 유추 가능하면
메서드 분리로 인한 재사용성이 향상된다.
또한 type-safe 한 Qclass 를 통한 기본적인 문법으로 런타임 에러가 나는 것을 방지한다.
필드를 잘못써서 에러가 난다거나...
단점 정리

하지만 1차캐시의 장점을 누릴 수 없다.
JPQL의 특징이기도 한데 Querydsl 로 작성하고 실행시키면
기본적으로 JPQL 로 변환이되어 DB로 쿼리가 직접 날아간다.
결과를 조회해 올때도 1차캐시에 저장된 값이 이미 있다면 DB 에서 조회한 결과를 버리고
캐시에 저장된 값을 읽어온다는 단점이 있다.
Querydsl 은 Type-safe 한 JPQL 빌더일 뿐인 것이지 새로운 혁신적인 기술은 아니다.
현재 업데이트도 진행되고 있지 않기 때문에 판단을 잘 해서 사용할지 말지를 결정해야한다.

아까의 수도코드이다.
조건을 필터링, 조회 크기 범위 지정, 정렬, 그룹화를 하나의 쿼리에서 다 하고있는데
이렇게 쿼리가 길어진다면 쿼리에 비즈니스 로직이 들어있는 것이 아닌지 의심해야한다.
이런 한방 쿼리를 조심하자는 의미이다.
참고
