스프링 컨테이너의 초기화 순서를 알아보기 전
스프링 컨테이너가 무엇인지 확실히 알아야 할 필요성을 느꼈다.
스프링 프레임워크에서 핵심적인 개념은 바로 '스프링 컨테이너'와 '스프링 빈'이 있다.
스프링 컨테이너는 스프링 프레임워크의 주요 구성요소로 이를 통해 개발되는
Inversion of Control(IOC) 을 기반으로 애플리케이션의 구성요소
즉 자바 객체(Bean) 들을 생성 관리하는 역할을 수행한다
자바의 객체를 스프링에서 Bean 이라고 한다.
스프링 컨테이너에서는 이 Bean(객체)의 생성부터 소멸까지를
개발자 대신 관리해주어 부담을 줄여준다.
그러면 자바 객체가 무엇이 있는지 컨테이너에 알려줘야하는 과정이 있어야하지 않겠는가?
그렇기에 스프링 컨테이너에 객체를 등록해야하는 과정이 필요하다.
스프링 컨테이너는 애플리케이션의 설정 정보를 바탕으로 스프링 빈을 생성하고,
이들의 의존 관계를 주입하는 역할을 한다.
애플리케이션의 설정정보?
공식 문서를 보면 다양한 용어가 나온다.
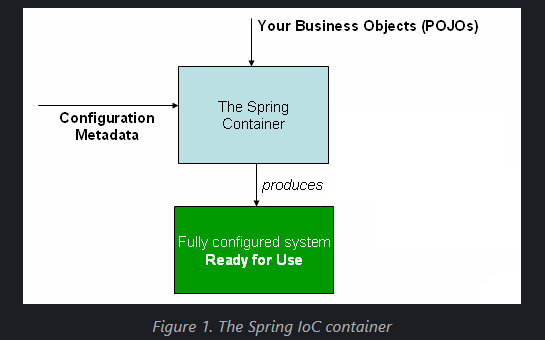
공식문서 Container Overview 에 등장하는 Spring IoC Container 그림이다.
-
POJO?
POJO는 특정 프레임워크나 규약에 얽매이지 않는 일반적인 자바 객체이다.
이러한 객체는 비즈니스 로직, 데이터 모델 등으로 사용될 수 있으며,
스프링 프레임워크의 특정 기능에 의존하지 않는다.
쉽게 말해서 우리가 만들어내는 일반적인 자바 객체를 의미한다.
편의상 POJO 객체를 자바 객체라고 명시하겠다. -
Configuration Metadata?
(번역하면) 구성 메타데이터는 스프링 컨테이너에
자바 객체의 생성 및 의존성 주입 방법을 정의하는 정보를 제공한다.
이 메타데이터는 XML, 어노테이션, Java Config 등을 통해 작성할 수 있다. -
Spring 컨테이너로 이어지는 화살표의 의미?
스프링 컨테이너는 이 구성 메타데이터를 읽고, POJO 객체를 생성하고, 필요한 의존성을 주입한다 예를 들어, 서비스 클래스가 리포지토리 클래스를 필요로 할 때, 컨테이너는 해당 리포지토리 객체를 생성하여 서비스 클래스에 주입한다. (실제로 많이 사용하는 예시) -
Fully configured system ready for use?
이 모든 과정이 완료되면, POJO 객체들이 서로의 의존관계가 설정된 상태로 생성되며,
애플리케이션은 사용할 준비가 된 "Fully configured system" 이 된다.
즉, 개발자는 스프링 컨테이너가 관리하는 객체를 통해 비즈니스 로직을 수행할 수 있다.
이러한 과정을 걸쳐 스프링 컨테이너를 사용하게 된다면
의존성 주입, 생명 주기 관리, 객체 간의 관계 설정 등을 효율적으로 처리하여
애플리케이션의 구조를 단순화하고 유지 보수를 용이하게 해준다.
스프링 컨테이너는 어떻게 구성되어있지?
스프링 컨테이너는 크게 두 가지를 얘기 수 있다.
하나는 BeanFactory이고, 다른 하나는 ApplicationContext다.
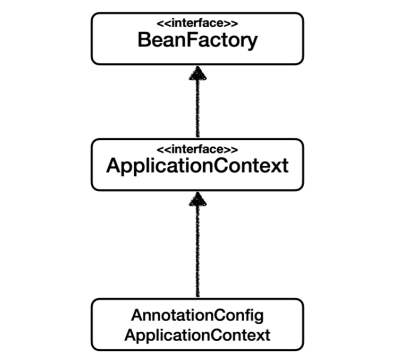
BeanFactory
-
스프링 컨테이너의 최상위 인터페이스
-
스프링 빈을 관리하고, 조회하는 역할을 담당한다.
-
getBean()을 제공한다.
-
지금까지 우리가 사용했던 대부분의 기능들은 BeanFactory가 제공하는 기능이다.
ApplicationContext
- BeanFactory 기능을 모두 상속받아서 제공한다.
둘의 차이는?
애플리케이션을 개발할 때에는 빈을 관리하고 조회하는 기능은 물론이고,
수많은 부가 기능이 필요하다.
단순하게 Bean을 관리하는 것을 떠나서,
애플리케이션을 개발하기 위해 공통적으로 필요한 많은 부가 기능을 제공하기 위해 ApplicationContext를 사용한다.
즉 우리가 주로 사용하는 것이 ApplicationContext이기 때문에
스프링 컨테이너를 ApplicationContext라고 할 수 있다.
그림에 포함되어있는 AnnotationConfigApplicationContext는
ApplicationContext의 구현체 중 하나에 해당한다.
스프링 컨테이너의 초기화 순서이자 생명주기
이제 스프링 컨테이너의 초기화 순서에 대해서 알아보자.
스프링 컨테이너를 초기화한다는 의미?
지금까지의 정보를 따라서 생각해보면
스프링 컨테이너를 초기화한다는 의미는 컨테이너가 필요한 설정 정보를 읽고,
그에 따라 빈(객체)을 생성하고, 의존성을 주입하며,
빈의 생명주기를 관리할 준비를 하는 과정을 의미한다.
그 과정을 상세하게 정리해보자.
-
ApplicationContext 및 BeanFactory 생성
스프링 애플리케이션이 시작되면,
ApplicationContext나 BeanFactory같은 최상위 컨테이너가 생성된다.
이 컨테이너는 빈을 생성하고 관리하는 중심 역할을 담당한다. -
Bean Definition Parsing (빈 정의 분석)
스프링 컨테이너는 XML 파일이나 자바 설정 파일 등을 통해 빈 정의를 분석하고
제공된 메타데이터를 읽는다.
이 과정에서 어떤 빈이 어떤 방식으로 생성되어야 하는지 정의가 된다. (빈의 범위, 의존성 등) -
빈 인스턴스화 및 DI (의존성 주입)
빈 정의에 따라 필요한 빈들을 생성하고, 각 빈에 필요한 의존성을 주입한다.
스프링에서는 주로 생성자/setter/필드 주입 방식을 통해 주입된다.
필요에 따라@Autowired나@Resource등을 사용하여 의존성을 자동 주입할 수 있다.
의존 관계 주입 시 타입이 같은 빈을 찾아서 조회하므로 동일한 타입이 있다면
@Primary나@Qualifier어노테이션을 사용해 우선적으로 주입할 빈을 지정해야한다. -
초기화 콜백 메서드 호출
빈 생성, 의존성 주입이 끝나면 필요한 데이터를 사용할 수 있는 준비가 된다.
스프링은 의존성 주입이 완료되면,
스프링 빈에게 콜백 메서드를 통해 초기화 기능을 할 수 있도록 제공한다.빈 초기화 시,
InitializingBean 인터페이스의 afterPropertiesSet() 메서드나
@PostConstruct를 통해 초기화 작업을 수행할 수 있다.
전자는 스프링 전용 인터페이스므로 스프링에 의존적이고
후자는 자바 표준 기술이므로 스프링에 종속적이지 않아서 후자를 많이 사용한다.
하지만 외부 라이브러리에는 적용할 수 없다.또한, XML 설정에 정의된 초기화 메서드(init-method)나 자바 설정 파일에서의
@Bean(initMethod=...)옵션으로 초기화 메서드를 지정할 수 있다.
이는 설정 정보를 활용하는 방법이므로 수정할 수 없는 외부 라이브러리에 대해서도
초기화 메서드를 지정할 수 있다.
-
초기화 콜백은 왜 해야하나?
리소스 초기화: 데이터베이스 연결, 파일 핸들러, 캐시 초기화 등과 같이
빈이 사용되기 전에 필요한 리소스를 준비하는 데 사용된다.유효성 검사: 빈의 상태나 의존성이 올바른지 확인하고,
필요한 경우 예외를 던져 초기화를 방지할 수 있다.비즈니스 로직 초기화: 특정 비즈니스 로직을 초기화하는 데 필요할 수 있다.
-
애플리케이션 컨텍스트 완성 및 이벤트 발행
모든 빈의 초기화가 완료되면, 컨테이너가 최종적으로 완성된다.
이 단계에서ApplicationContext가 이벤트를 발행하며,
이벤트 리스너가 등록된 경우 이를 감지한다.
예를 들어,ContextRefreshedEvent, ContextStartedEvent, ContextStoppedEvent등과 같은 이벤트가 발생할 수 있다. -
애플리케이션 시작 준비 완료
모든 준비가 완료되면, 스프링 애플리케이션이 오는 요청을 받아들일 수 있는
최종적으로 준비된 상태가 된다 -
애플리케이션 실행 중 (Running)
준비가 완료되면, 스프링 애플리케이션은 요청을 처리하며,
DispatcherServlet을 통해 사용자 요청을 받아 이를 적절한 컨트롤러에 라우팅한다.요청은 컨트롤러와 서비스 계층을 거쳐
최종적으로 데이터베이스나 다른 API와의 상호작용을 통해 처리된다.비즈니스 로직이 완료된 후 View를 반환하거나 JSON 응답을 제공하며,
필요시 에러를 관리하고 로그를 기록한다.이 상태는 서버가 계속 실행되는 한 유지되며,
사용자 요청 처리 및 트랜잭션 관리가 주된 역할이다 -
애플리케이션 종료 준비 (Shutting Down)
애플리케이션이 종료 신호를 받으면, 스프링 컨테이너는 종료 작업을 준비한다.
종료 작업은 주로 애플리케이션이 종료될 때 미완료된 작업을 정리하고
리소스를 안전하게 해제하는 과정이다.싱글톤 빈들은 스프링 컨테이너 종료 시 빈들도 함게 소멸하기 때문에 소멸 전 콜백이 발생!
@PreDestroy애노테이션이나DisposableBean 인터페이스의 destroy() 메서드가 있다.
빈 소멸 콜백 메서드가 호출되며, 이를 통해 리소스를 안전하게 해제하고
데이터베이스 연결이나 스레드 풀 같은 자원을 종료시킬 수 있다.
-
ApplicationContext 종료 및 이벤트 발행
컨텍스트가 종료되면 스프링 컨테이너는ContextClosedEvent와 같은 종료 이벤트를 발행한다.
이 이벤트는 종료 시에 특별한 처리가 필요한 경우 활용할 수 있으며,
이를 통해 애플리케이션 종료 직전에 마지막으로 필요한 작업을 수행할 수 있다. -
JVM 종료
모든 스프링 빈이 소멸하고 애플리케이션 컨텍스트가 닫힌 이후, JVM이 최종적으로 종료된다.
종료 후에는 모든 시스템 리소스가 해제되고, 스프링 애플리케이션이 메모리에서 완전히 사라지게 된다.
BeanDefinition?
스프링 컨테이너를 자세히 알아보려면 당연히 그 스프링 컨테이너가 생성 관리하는 Bean에
대해서 더 자세히 알아봐야한다고 여겨 작성한다.
BeanDefinition은 스프링 IoC 컨테이너에서 각 빈을 정의하는 메타데이터를 포함하는
객체이다. 이 객체는 빈의 생성과 관리에 필요한 정보를 담고 있다.
BeanDefinition 객체 내부에는 여러 정보가 존재한다.
- 패키지 한정 클래스 이름: 빈의 실제 구현 클래스
- 빈 동작 구성 요소: 빈의 범위(scope), 생명주기 콜백 등을 정의하는 구성 요소
- 빈 의존성 참조: 빈이 작업을 수행하는 데 필요한 다른 빈에 대한 참조
- 기타 구성 설정: 새로 생성된 객체에 설정할 추가적인 구성 정보(예: 풀의 크기 제한 등)
이 모든 정보가 빈의 메타데이터라고 할 수 있으며,
스프링 컨테이너가 빈을 생성하고 관리하는 데 필요한 지침을 제공하는 것이다.
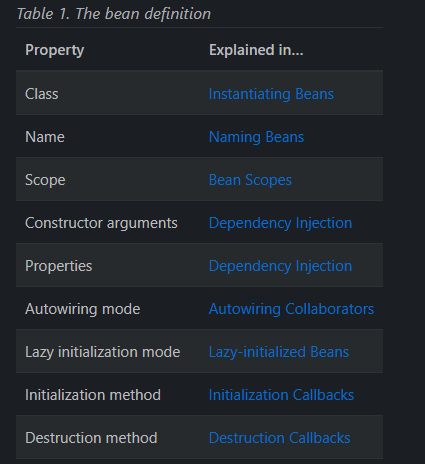
이 테이블은 공식 문서에 존재하는 것인데
BeanDefinition 객체 내부에 존재하는 정보들을 테이블 형태로 설명하는 형식이다.
정말 많은 것들이 존재하지만 챌린지반에서 다룬 Scope를 우선적으로 알아볼 것이다.
Bean Scope
처음 챌린지반 자료에서 보았을 때는 스프링 프레임워크에서의 스코프로 나와있어서
이 범위가 무슨 범위를 의미하는건지 잘 알지 못했는데
알아보고 나니 이것이 빈의 Scope를 의미한다는 것을 알 수 있었다!!
Bean Scope는 우리가 위에서 찾아봤던 Bean Definition을 정의할 때 포함되는 정보이다.
이는 해당 객체가 얼마나 자주 생성되고 사용되는지를 정의한다.
그 정의에 따라 해당 객체의 성격이 달라지게 된다.
Scope 설정 방식의 장점은 Java 클래스 자체를 수정하지 않고도
빈이 존재할 수 있는 범위와 종속성을 쉽게 조정할 수 있다.
빈의 동작을 변경하려면 코드 수정없이 구성 파일이나 에너테이션만 수정하면 되기 때문이다.
스프링에서는 빈의 범위와 종속성을 손쉽게 설정할 수 있어서
개발자가 필요에따라 객체의 생명주기와 관계를 조정할 수 있다.
이를 통해 애플리케이션의 구조를 보다 유연하게 만들 수 있게된다.
Scope의 종류
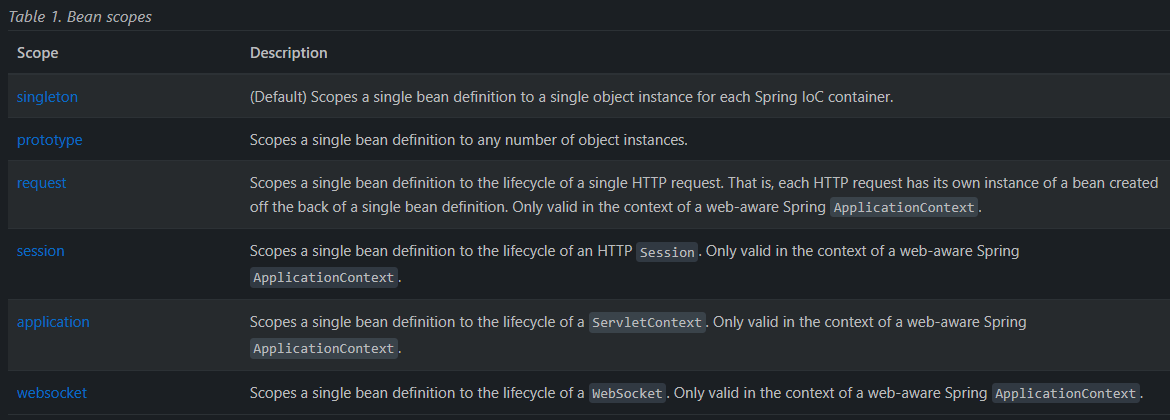
Bean Scope는 대표적으로 6가지의 종류가 존재한다.
1. Singleton Scope (싱글톤 스코프) - 기본 스코프
- 특징:
- 스프링 컨테이너(예:
ApplicationContext)에서 하나의 인스턴스만 생성되어 재사용 - 기본적으로 모든 빈은 싱글톤 스코프이기 때문에, 별도 설정이 없으면 이 방식으로 동작한다
- 공유 상태 관리가 필요할 때 주의해야 한다.
여러 클래스가 동일한 인스턴스를 사용하므로,
클래스에 저장된 데이터가 다른 요청 간에 공유될 수 있다.
- 스프링 컨테이너(예:
- 적용 대상:
- 스프링 코어 컨테이너 (ApplicationContext, Core Containers 등)
- 서비스 계층 빈(Service Layer Beans)
- 리포지토리 빈(Repository Layer Beans), 설정 빈(Configuration Beans) 등 주로 고정적인 리소스
- 생명주기:
- 생성: 스프링 컨테이너가 시작될 때 생성
- 소멸: 스프링 컨테이너가 종료될 때 소멸
가장 넓은 범위이다.
2. Prototype Scope (프로토타입 스코프)
-
특징:
-
빈을 요청할 때마다 새로운 인스턴스를 생성
-
스프링 컨테이너는 빈의 생성과 의존성 주입만 관리하며, 빈의 소멸 시점은 관리하지 않는다.
-
빈이 컨테이너 밖에서 사용되기 때문에 GC(가비지 컬렉터)에 의해 자동으로 메모리에서 해제된다.
컨테이너 밖에서 사용된다는 의미는 스프링 컨테이너가 생성한 빈의 레퍼런스를 외부 코드에서 사용할 수 있는 상황을 의미한다.
-
//빈의 실제 객체는 컨테이너에서 생성되었지만,
//외부 코드에서 레퍼런스를 참조하여 사용하는 상황을 "컨테이너 밖에서 사용"된다고 표현
@Service
public class MyService {
public void doSomething() {
System.out.println("Service is running...");
}
}
// 메인 코드
public class MainApp {
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
MyService service = context.getBean(MyService.class); // 빈을 컨테이너에서 가져옴
service.doSomething(); // 컨테이너 밖의 코드에서 사용
}
}- 적용 대상:
- 상태를 가지거나 멀티스레드 환경에서 필요한 객체
- 동적 프록시 객체나 빈 요청 시마다 새로 생성되어야 하는 객체
- 생명주기:
- 생성: 빈 요청 시 (
getBean()호출 시) 생성 - 소멸: 스프링이 아닌 JVM의 가비지 컬렉터에 의해 관리됨
- 생성: 빈 요청 시 (
3. Request Scope (리퀘스트 스코프)
- 특징:
- HTTP 요청 당 하나의 인스턴스가 생성되며, 요청이 끝나면 인스턴스도 함께 소멸된다.
- 웹 애플리케이션 환경에서 사용된다.
주로 웹 애플리케이션 내에서 각 요청별로 필요한 정보를 관리하기 위해 사용한다.
- 적용 대상:
- 요청 정보를 관리하는 HTTP 요청 객체
- 요청별 로깅 컨텍스트나 사용자 입력 데이터와 같이 각 요청에서 분리하여 처리해야 하는 데이터 관리 객체
- 생명주기:
- 생성: HTTP 요청이 시작될 때 생성
- 소멸: HTTP 요청이 종료될 때 소멸
4. Session Scope (세션 스코프)
- 특징:
- HTTP 세션당 하나의 인스턴스가 생성됩니다. 세션이 종료되거나 만료되면 빈 인스턴스도 함께 소멸된다.
- 주로 사용자별 정보를 유지할 필요가 있는 웹 애플리케이션에서 활용된다.
- 적용 대상:
- 사용자 세션 정보나 장바구니 객체, 사용자 인증 정보와 같이 사용자별로 유지해야 하는 정보
- 생명주기:
- 생성: 사용자 세션이 시작될 때 생성
- 소멸: 사용자 세션이 만료되거나 종료될 때 소멸
5. Application Scope (애플리케이션 스코프)
-
특징:
- 웹 애플리케이션의 전체 수명 주기와 동일하게 유지되는 스코프
ServletContext와 동일한 생명주기를 가진다. - 애플리케이션 범위의 공용 데이터나 설정을 공유하고 유지하기 위한 용도로 주로 사용
- 웹 애플리케이션의 전체 수명 주기와 동일하게 유지되는 스코프
-
적용 대상:
- 애플리케이션 전역 설정, 캐시 관리자, 공유 리소스 관리자 등
-
생명주기:
- 생성: 애플리케이션이 시작될 때 생성
- 소멸: 애플리케이션이 종료될 때 소멸
-
ServletContext
서블릿 컨텍스트는 자바 웹 애플리케이션이 작동하는 환경에서 제공하는 전역 컨텍스트 객체이다.
웹 애플리케이션의 전반에 걸쳐 사용되는 설정, 리소스, 환경 속성을 담고있다.
서블릿 컨텍스트는 스프링 컨테이너와 별도로 존재하는 개념이다.애플리케이션 스코프의 빈도 웹 애플리케이션의 전반에 걸쳐 존재하기에 둘의 수명 주기가
유사하다는 것이다.
둘은 같은 것이 아님!
Servlet Container?
애플리케이션 스코프를 공부하다보니 서블릿 컨테이너도 궁금해져 공부해보았다.
1. 서블릿 컨테이너와 스프링 컨테이너의 관계
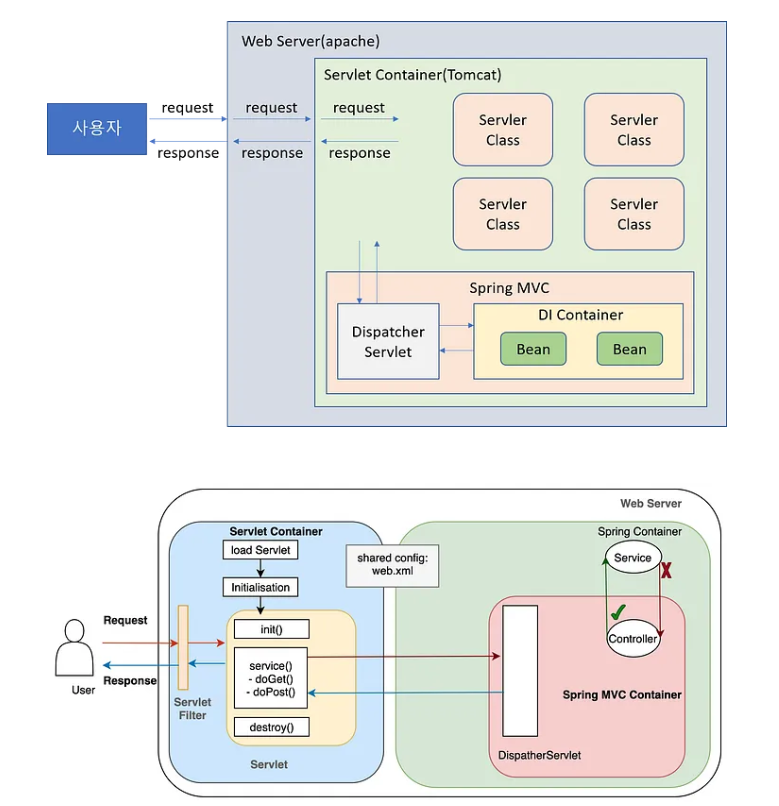
-
서블릿 컨테이너:
- 예: Tomcat, Jetty
- Java Servlet 기반의 웹 애플리케이션을 실행하기 위한 환경을 제공한다
- 서블릿 컨테이너는 서블릿 컨텍스트(ServletContext)라는 객체를 통해 애플리케이션 전반에 대한 정보를 관리한다
- 스프링 웹 애플리케이션은 서블릿 컨테이너에서 실행된다.
-
스프링 컨테이너:
- 예: ApplicationContext
- 서블릿 컨테이너 내부에서 동작하며, 빈(bean)을 생성하고 의존성을 관리하는 역할을 한다.
- 스프링 MVC 같은 웹 애플리케이션에서는 서블릿 컨테이너가 스프링 컨테이너를 초기화하고 종료할 때 스프링 컨테이너의 생명주기를 관리한다.
- 스프링 컨테이너의 생성과정
복잡한 생성과정이 있다.
-
WebApplication이 실행되면, WAS에 의해web.xml이 로딩된다. -
web.xml에 등록되어 있는ContextLoaderListener가 Java Class 파일로 생성된다.ContextLoaderListener는ServletContextListener인터페이스를 구현한 것으로서,
root-content.xml또는ApplicationContext.xml을 기반으로ApplicationContext를 생성하는 역할을 한다.
Servlet Context는Spring Bean에 접근하려면Application Context를 참조해야 한다.ApplicationContext도ServletContainer에 단 한 번만 초기화되는Servlet이다. -
ApplicationContext.xml에 등록되어 있는 설정에 따라Spring Container가 구동되며, 이 때 개발자가 작성한 비즈니스 로직과 DAO, VO 등의 객체가 생성된다.
즉 서블릿 컨테이너에서 스프링 컨테이너를 생성하는 구조라고 이해를 했다.
여기서 하나의 의문이 들었다.
서블릿 컨테이너가 스프링 컨테이너보다 큰 개념(?)이면
서블릿 컨텍스트는 스프링 컨테이너보다 상위에 있으니 싱글톤 스코프보다
더 나중에 종료되어야하는거 아닌가?
그러면 Spring Bean의 Scope는 Bean의 생명주기를 정의하는 개념으로,
Bean이 생성되고 관리되는 범위를 의미하는 것이기 때문에
가장 넓은 범위는 애플리케이션 스코프가 가져야하는 것이 아닌가?
라는 생각이 들었다.
- 종료 순서
간단한 예시로 알아보자.
-
웹 애플리케이션 종료 요청:
- 사용자가 서버를 종료하거나 웹 애플리케이션을 undeploy한다.
-
서블릿 컨테이너 종료 시작:
- 서블릿 컨테이너(Tomcat 등)는 자신이 관리하는 서블릿 컨텍스트를 종료한다
- 이 과정에서, 서블릿 컨테이너는 스프링 컨테이너(ApplicationContext)에게도 종료 신호를 보낸다
-
스프링 컨테이너 종료:
- ApplicationContext가 종료되면서 싱글톤 스코프의 빈을 포함한 모든 빈을 정리하고 소멸 콜백(
@PreDestroy등)을 호출한다.
- ApplicationContext가 종료되면서 싱글톤 스코프의 빈을 포함한 모든 빈을 정리하고 소멸 콜백(
-
서블릿 컨텍스트 종료:
- 서블릿 컨텍스트가 종료되며, HTTP 세션 및 애플리케이션 스코프 객체도 정리된다.
- 스프링 컨테이너와 애플리케이션 스코프의 종료 타이밍
- 스프링 컨테이너(ApplicationContext)는 서블릿 컨테이너가 종료되는 과정 중간에 종료된다.
- 애플리케이션 스코프(ServletContext와 동일한 생명주기)는 서블릿 컨테이너 종료 직전까지 유지된다.
즉, 애플리케이션 스코프의 객체가 더 나중에 종료되며, 스프링 컨테이너의 종료가 먼저 이루어진다.
정리
- 서블릿 컨테이너는 스프링 컨테이너를 제어한다.
- 스프링 컨테이너는 서블릿 컨테이너 종료 과정에서 먼저 종료된다.
- 애플리케이션 스코프는 서블릿 컨텍스트와 동일한 생명주기를 가지므로 스프링 컨테이너보다 나중에 종료된다.
-
생명주기를 기준으로 판단할 때:
애플리케이션 스코프 > 싱글톤 스코프
애플리케이션 스코프는 서블릿 컨텍스트와 함께 애플리케이션 전체 수명 동안 유지되며,
싱글톤 스코프는 스프링 컨테이너의 수명 동안만 유지된다. 하지만 -
애플리케이션 전반에서 사용 가능 여부를 기준으로 판단할 때:
싱글톤 스코프 > 애플리케이션 스코프
싱글톤 스코프의 빈은 스프링 컨테이너가 관리하는 모든 계층에서 사용 가능하다.
반면, 애플리케이션 스코프의 객체는 서블릿 컨텍스트가 관리하는 영역에서만 사용된다.
즉 스프링 컨테이너 중심으로 애플리케이션을 볼 때는 싱글톤 스코프가 가장 넓어보이고
스프링 컨테이너가 서블릿 컨테이너에 의해서 동작한다는 것을 이해하면
생명주기는 애플리케이션 스코프가 더 오래 유지됨을 알 수 있었다.
이게 정확히 정리한 것인지 잘 모르겠다.
서블릿 컨테이너와 스프링 컨테이너의 관계가 모호한 느낌이어서
나중에 다시 정리해보아야겠다.
참고자료 : Servlet Container and Spring Framework
ServletContainer와 SpringContainer는 무엇이 다른가?
6. WebSocket Scope (웹소켓 스코프)
- 특징:
- WebSocket 세션당 하나의 인스턴스가 생성
- WebSocket 연결이 종료되면 해당 인스턴스가 소멸
- 적용 대상:
- 실시간 통신 핸들러, 메시지 버퍼, WebSocket 세션 관리자 등, 각 WebSocket 연결별 상태를 유지할 필요가 있는 객체
- 생명주기:
- 생성: WebSocket 세션이 시작될 때 생성
- 소멸: WebSocket 세션이 종료될 때 소멸
7. Custom Scope (사용자 정의 스코프)
- 특징:
- 개발자가 필요한 대로 새로운 스코프를 정의할 수 있다.
- 예를 들어, 테넌트별로 다른 리소스를 사용하는 멀티 테넌트 환경에서는
Tenant Scope같은 사용자 정의 스코프를 만들 수 있다.
- 적용 대상:
- 예를 들어, 테넌트별 데이터 소스, 테넌트별 설정 정보, 테넌트별 캐시 등이 있다.
- 생명주기:
- 사용자가 정의한 스코프에 따라 달라지며, 일반적으로 스프링 설정을 통해 관리된다.
scope 결론
내가 이해한 바로는 Spring Bean은 스프링 컨테이너 내부에 존재하는 것이며 scope는
이 빈이 생성되는 주기와 생존 범위를 나타내는 개념이다.
이러한 빈 객체는 스프링 컨테이너에 의해 생성 및 초기화, 관리된다.
하지만 소멸은 스프링 컨테이너에 의해 관리될 수도 아닐 수도 있다. (다른 곳에서 관리)
각 Scope는 상황에 따라 적절히 사용할 수 있다. 대부분은 싱글톤 스코프를 사용한다.
참고자료 : Spring Bean Scopes - 공식 문서
