
Linux File System을 공부하기에 앞서 근간이 되는 Unix File System을 알아보자.
FCB(File Control Block)
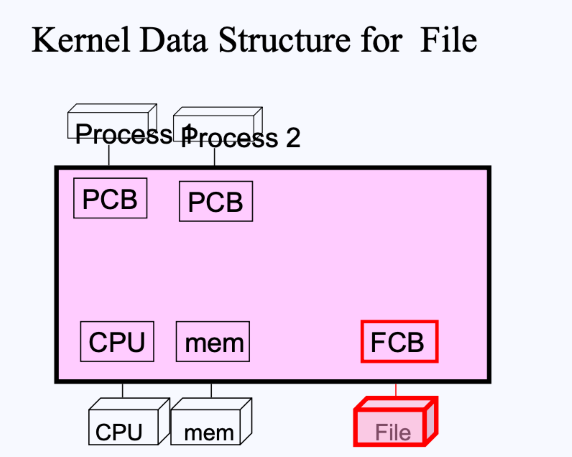
이전에 배웠듯이, 커널(분홍색 영역)은 하드웨어 자원들과 각종 Process들을 관리한다.
- 커널은 이러한 자원들을 관리하기 위한 Data Structure를 각 하드웨어와 프로세스들 마다 가지고 있다.
- ex) 위 그림에서
mem(Data Structure)에는 메모리의 총 크기가 어느정도이며, 어디서부터 어디까지 사용되고 있는지 등에 대한 정보가 담겨있음
- ex) 위 그림에서
- 이때, 프로세스들을 관리하기 위한 Data Structure는 (이전에 배웠던) PCB(Process Control Block)라고 불렀음.
- 또한, 파일들을 관리하기 위한 Data Structure는 FCB(File Control Block)라고 부름.
File Control Block은 이름을 보면 알 수 있듯, File 하드웨어를 위한 메타데이터이다. 여기에는 다음과 같은 정보들이 들어있다.
- Owner : 파일 소유자가 누구인지 (eg. Clinton)
- Protection : 파일의 퍼미션을 무엇인지 (eg. rwx r-- r--)
- Device : 파일이 어디에 있는지 (eg. disk)
- Content : 파일 내용은 어디서 찾을 수 있는지 (eg. sector address)
- Device driver routines : 파일이 들어있는 디바이스의 어떤 부분을 읽어야 함수를 호출할 수 있는지(eg. read(), open() )
- Accessing where now : 현재 파일의 어디를 읽고 있는지 (eg. offset)
이제 파일 저장부터 알아보도록 하자.
File store
파일을 disk에 저장할 때에는 다음과 같은 방식들을 사용할 수 있다.
- Contiguous allocation (variable size)
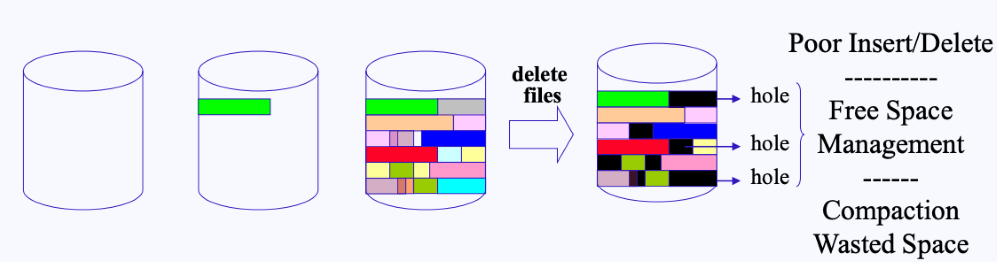
- Contiguous allocation은 간단하게 설명하면, 차례대로(연속적으로) 파일을 저장하는 방식이다.
- 하지만 Contiguous allocation는 중간에 파일이 삭제되고 나면, hole이 생기는 단점을 가지고 있다.
- 만약 새로 저장할 파일의 사이즈가 구멍의 사이즈보다 크게 된다면, 단편화 문제가 생기게 된다.
- ** 외부 단편화 : 메모리(디스크) 할당 시 공간들이 연속적으로 붙어있지 않아 빈 공간이 생기는 것
- ** 내부 단편화 : 메모리(디스크) 할당 시 프로세스보다 더 큰 공간을 할당받아서 그 나머지 공간이 낭비되는 것
- (디스크 조각 모음이 바로 이 hole을 메꾸는 작업이다.)
- 만약 새로 저장할 파일의 사이즈가 구멍의 사이즈보다 크게 된다면, 단편화 문제가 생기게 된다.
- Scattered allocation (fixed size)
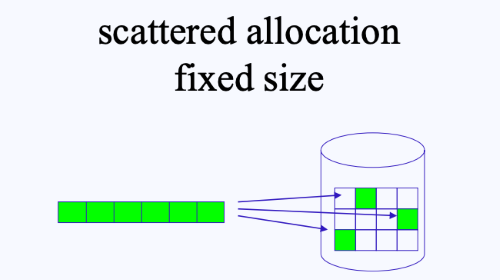
- Scattered allocation은 디스크에 파일을 저장할 때 그대로 저장하는 것이 아니라, 동일한 크기로 조각을 낸 후, 이를 디스크의 섹터에 저장시키는 것이다.
- 이러한 방법을 사용하면 Contiguous allocation에서 보았던 단점(hole)을 보완할 수 있다.
- 그러나 디스크에서 원하는 조각들을 찾기 위해
lseek()같은 함수로 파일 포인터를 옮겨다닐 때 딜레이가 생길 수 있다.- 반면, Contiguous allocation는 첫 포인터만 찾으면 연속적으로 빨리 파일을 읽을 수 있다.
두 방법에는 서로 장단점이 존재하므로, OS에서는 두 방법을 동시에 사용한다. 디스크 파티션 중 일부는 Contiguous allocation를 사용하고, 나머지 일부는 Scattered allocation(대부분은 이 방법을 사용)를 사용하는 것이다.
File open
파일들이 디스크에 저장되어 있는 상태에서 이들을 read할 때에는, 그 파일들의 섹터들의 주소들을 다 알아야 한다. 이 섹터들의 주소는 (FCB에 있는)File 메타데이터에 저장이 되어있다.
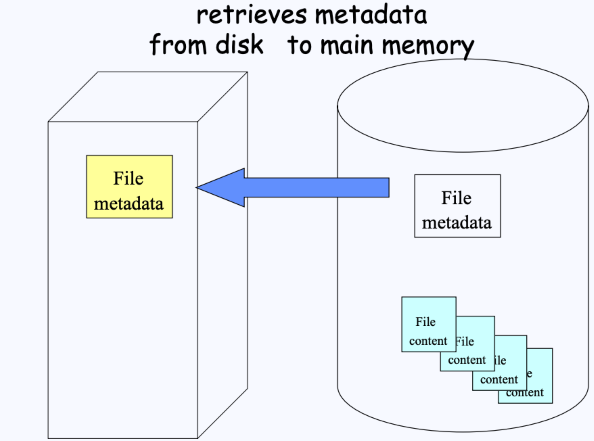
- 우리는 open을 위해 FCB에 존재하는 메타데이터들만 우리 메모리로 가져오고, 메모리에서는 파일의 데이터 섹터를 접근하기 위해 복사해 온 메타데이터 안의 정보를 사용하면 된다.
- 따라서 데이터 섹터 자체가 올라오는 것이 아니라, 필요할 때마다 메타데이터를 보고 필요한 데이터 섹터에 접근하여 가져올 수 있다.
그런데 만약 여러 개의 프로세스들이 동일한 파일을 사용하게 된다면, 세 프로세스 모두 동일한 메타데이터를 복사해와야 할 것이고, 중복이 발생하게 된다. 이를 방지하기 위해서는 메타데이터를 공유해서 사용하기 위한 방법도 생각해야 한다.
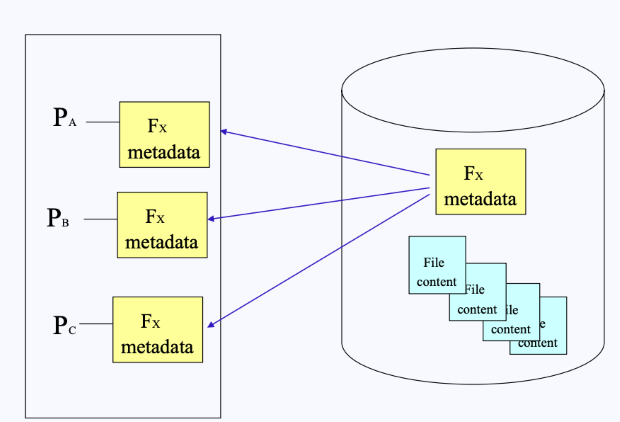
- 따라서 중복으로 인해 낭비가 발생하는 정보들은 프로세스끼리 공유해서 사용하도록 한다.
- 그러나, 반드시 공유되면 안 되는 메타데이터 정보가 하나 있는데, 그것은 바로 offset이다.
- 파일의 어떤 부분을 읽고 있는지에 대한 정보는 프로세스별로 나눠져야 한다.
- 따라서 file의 메타데이터는 두 개의 구조체로 구분된다.
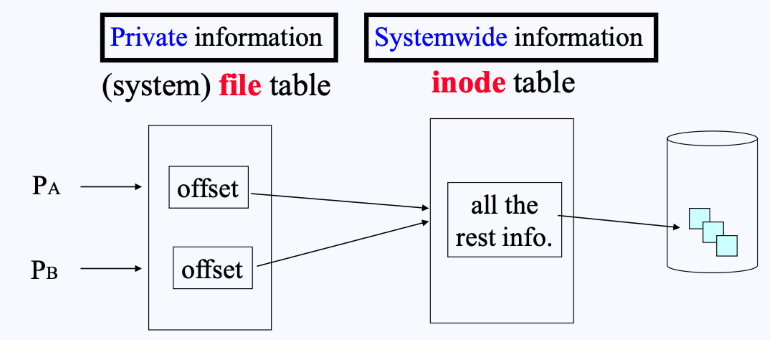
- inode struct : 모든 프로세스들이 공유하는 메타데이터
- file struct : 각 프로세스가 개별적으로 가지고 있는 메타데이터 (offset)
inode struct
inode 구조체에는 다음과 같은 다양한 정보가 들어있다.

- 전부
i_로 시작하는 필드임 i_addr[8]에 실제 파일의 섹터 주소가 들어있음
디스크 공간에는 이러한 inode들이 모여 있는 inode block이 다음과 같이 따로 존재한다(전체 디스크의 1%정도를 차지).

- (data block에는 실제 데이터가 들어가있다.)
- 각 inode는 숫자를 가지고 있으며, 이를 inode number라고 한다.

- 이 inode number로 해당하는 inode로 접근하고, 여기서 content로 접근하게 된다.
file struct
file struct에는 다음과 같은 필드로 구성되어져 있다.
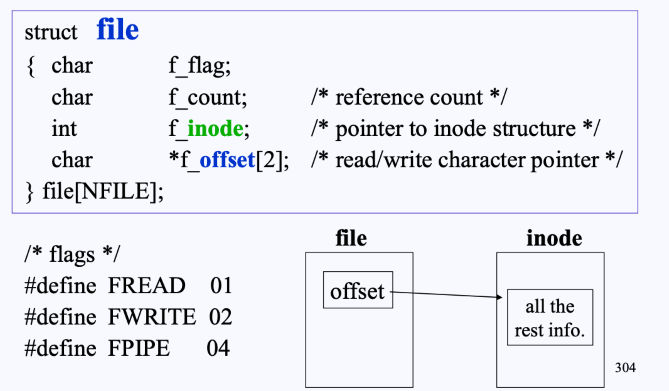
- 전부
f_로 시작하는 필드임. f_offset에는 inode table을 가리키는 인덱스가 들어있음.
Device switch table
Device switch table에는 어떠한 디바이스에서 어떠한 동작을 수행할 것인지에 대한 정보가 2차원 배열 형태로 들어있다.
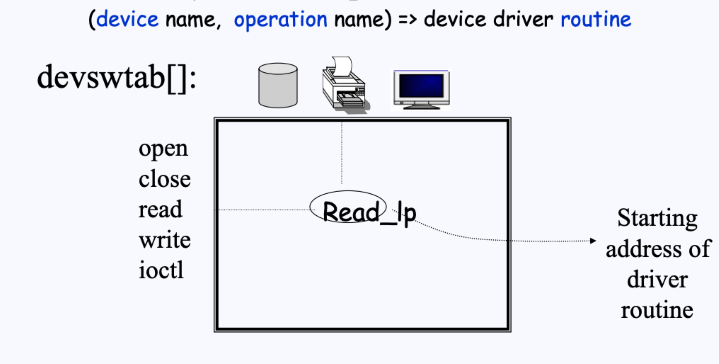
- 이러한 정보를 device driver routine이라고 부른다.
- 이는 devswtab[] 배열 형태로 되어있다.
- 예를 들어 위 그림에서 [device: printer, operation: open]과 같이 접근한다면, 프린터의 open operation driver routine의 시작 주소를 얻을 수 있다.
- (사실 devswtab[] 배열은 다음과 같이 1차원 배열의 구조로 되어있다.)
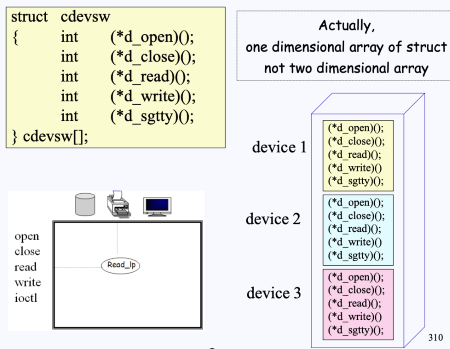
- “Unix에서는 모든 것이 file로 관리된다.”
- 이처럼 Unix에서는 일반 정규 파일부터 디렉토리, 소켓, 파이프 등 모든 객체들을 파일로 관리함
File open 과정

- 컴퓨터가 부팅이 되면, 가장 먼저 커널 프로그램이 올라오면서, 각종 하드웨어 Data Structure역시 올라온다.
- FCB가 올라오며 가장 앞에 존재하는 inode 0이 올라옴
- 이는 root directory file로
‘/'루트임.
- 이제, 만약 유저가
/a/b파일을 open 해 달라고 시스템 콜을 요청한다고 가정하자(위 그림).- 우선 file table에서
/a/b파일의 inode(으로)를 inode table로 가져와야 한다.- 현재 우리가 아는건 inode 0. 즉,
‘/'(루트) 밖에 없으므로, 해당 inode의 포인터를 따라가서 가져와야 한다.
- 현재 우리가 아는건 inode 0. 즉,
- inode 0에 연결된 포인터에는
‘/'(루트)의 content가 들어있다. 여기서 원하는 inode를 가져온다.‘/'(루트)의 content에는 실제 root directory file에 들어있는 data들이 존재하는데, 현재(그림)는a,bin,x3개의 file이 들어있고, 이 파일들은 각각 i-number가 존재한다.
- 우리는
/a파일로 가야하기에, 디스크에서 해당 inode number인 7을 찾아서 가져온다.- 이제 inode table에는
/와ainode가 들어있다.
- 이제 inode table에는
- 위와 동일한 방식으로
ainode를 따라가서 해당 content가 들어있다. 여기서 원하는 inode를 가져온다.ainode의 content를 보면,b,usr,y가 있다. 이 중 b의 inode number가 3이므로, 디스크에서 inode-3을 찾아서 가져온다.
- 이제
/a/b를 open하기 위한 준비가 끝났다. file 구조체에서 offset을 0으로 하여 생성한 뒤, inodeb를 가르키게 한다. - 이제 마지막으로 실제 프로세스의 PCB에 존재하는 open한 파일들을 관리하는 배열(u_ofile[])에 생성한 file→offset 주소를 넣는다.
- 우선 file table에서
- 결국 유저에게 최종적으로 return되는 fd(file descriptor(open file table))는 u_ofile[]의 인덱스이다. 우리는 여기에
read(4, buf, size)와 같이 해당 파일에다가 쓰기 작업을 하게 되는 것이다.
fd table에 대해 좀 더 자세히 알아보자
FD(File descriptor) table (= open file table)
FD table의 특징은 다음과 같다.
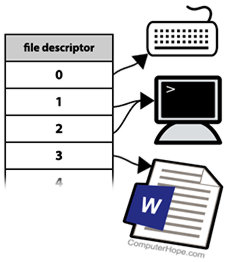
- PCB에 존재
- 각 프로세스마다 open한 파일들의 정보가 담겨있음
open(path_name)으로 call하면, 커널이 해당 파일을 open하여 fd를 리턴해줌- 시스템은 사용하지 않는 fd 중 가장 작은 값(0과 음수가 아닌 정수값)을 할당해줌.
- 0, 1, 2는 예약된 fd임(순서대로 stdin/out/err). 따라서 유저가 open했을 떈 fd=3부터 할당됨.
- 프로세스가 시스템 콜을 통해 파일들에 접근할 땐 이 fd를 사용(파일을 지칭).
File read & write
파일을 열었으니, 이제 Read하고 Write하는 과정에 대해 알아보자.
Accessing File with fd
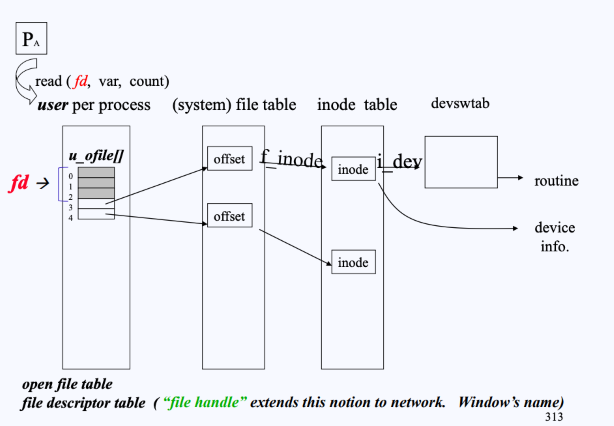
- 그림과 같이
read(4, var, count)라고 요청을 하면, 우선 유저 프로세스의 PCB에 들어있는 fd table을 순회한다. - 요청한 인덱스 4를 찾았으면,
fd_table[4]에 들어있는 file→offset 주소를 확인한다. - 이후 file table에서 offset→inode로 주소를 확인한다.
- 이후 inode table의 (해당하는) inode에서 실제 데이터의 섹터 주소를 얻을 수 있다.
- inode에는 디바이스 정보도 들어있으므로, 만약 disk라면 disk의 핸들러 중 read를 찾고 실제 루틴이 시행된다.
- 이는 위에서 설명한 Device switch table임.
결국 과정을 보면, open 할 때에만 path_name을 사용하고, read/write/close를 할 때에는 전부 open으로 얻은 fd(file descriptor)로만 관리한다.
- open할 때 수행되었던 로직들을 반복하여 수행하는 것은 비효율적이므로 이러한 방식을 사용함.
- fd로만 접근하면, file struct, inode struct, device switch로만 메모리에 access하여 원하는 정보를 다 얻어올 수 있기 때문에 효율적임
Balance tree
현재 내가 가진 디스크의 용량이 10GB이고, 섹터의 사이즈가 1K라고 해보자.
- 내가 현재 사용할 수 있는 섹터는 10,000,000,000 / 1000 = 10,000,000 sectors 이다.
- 만약 1000개의 섹터를 가르키는 포인터를 만드려면, 각 섹터 포인터는 24bits가 필요하다.
- 각 섹터들이 가지고 있는 주소도 어딘가에 저장해야 하는데, 이 저장위치도 섹터이다. 따라서 많은 정보를 저장하기 위해서는 수 많은 섹터들이 필요할 것이다.
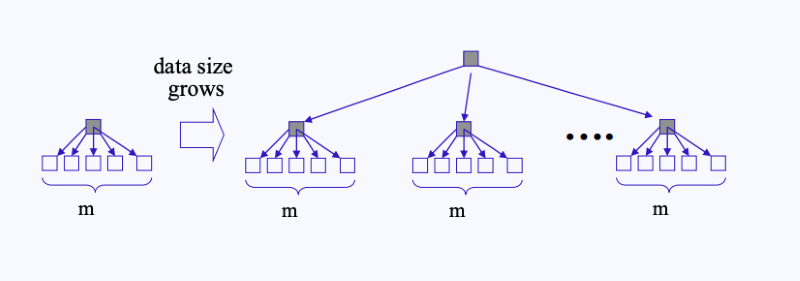
-
위 그림처럼 각 섹터들을 50(m)개 단위로 묶는다면, 이 50(m)개를 관리하기 위한 또 다른 섹터가 필요하고, 이러한 관리 섹터가 많아진다면 이 관리 섹터를 관리하기 위한 관리 섹터도 필요하게 된다.
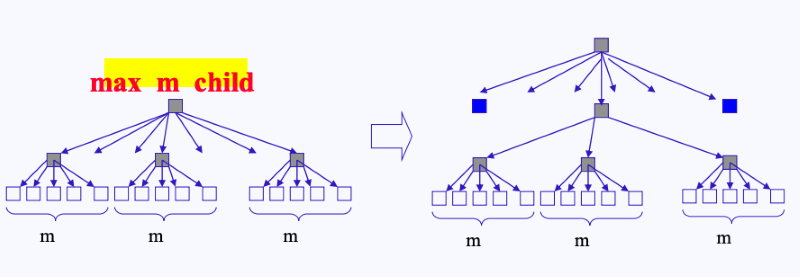
-
결국 이 같은 일이 반복되다 보면 위 그림처럼 점점 큰 트리 형태가 만들어질 것이다.
-
일반적인 이진 트리인 경우 양쪽의 depth가 서로 다를 수 있지만, 섹터가 트리 형태로 관리될 땐 양쪽의 depth가 모두 동일하다. 따라서 이러한 tree를 Balanced Tree(B-Tree)라고 부른다.
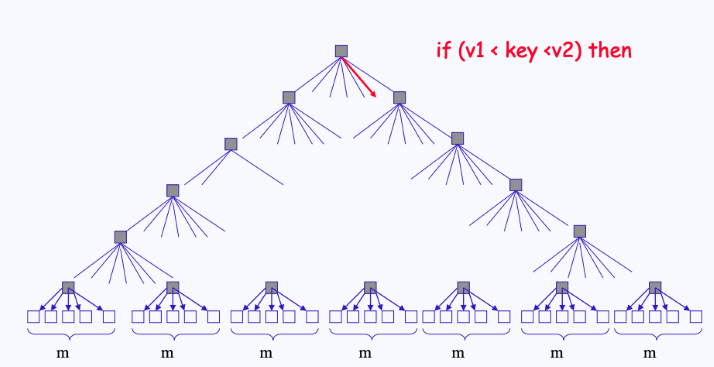
- B-Tree에서 우리는 용량이 큰 데이터를 저장하고, 이용할 떈 제일 최상위에 존재하는 하나의 inode만 알고 있으면 된다.
- 루트 inode를 말면, 여기에 연결되어 있는 자식 노드에 접근해서 데이터를 얻어오면 되기 떄문이다.
- 제일 최상단에 존재하는 노드를 마스터 인덱스라고 부른다.
File System in Disk
super block
File system은 각 data 섹터들을 관리하기 위한 inode와 실제 content가 담긴 data block으로 구성되어 있다고 배웠다. 이 inode와 data의 관리가 또 필요하기 때문에 유닉스에는 super block이라는 영역이 존재한다.
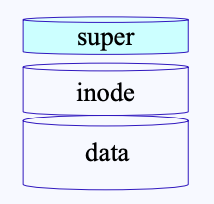
- superblock의 주 역할은 inode나 data의 섹터들이 사용 후 delete 되었을 때 이를 관리하기 위함이 가장 크다.
- 따라서 inode hole sector(free inodes)와 data hole sector(free data blocks)를 가리키는 포인터들이 존재한다.

- 추가적으로는 global 정보가 들어있다.
- 현재 inode, data block의 사이즈는 몇 인지, 접근 권한은 뭔지 등에 대한 정보
따라서, 결국 File System은 SuperBlock, inode, data 영역으로 구성되어 있는 것이다. 이들을 도식화하면 다음과 같이 나타낼 수 있다.
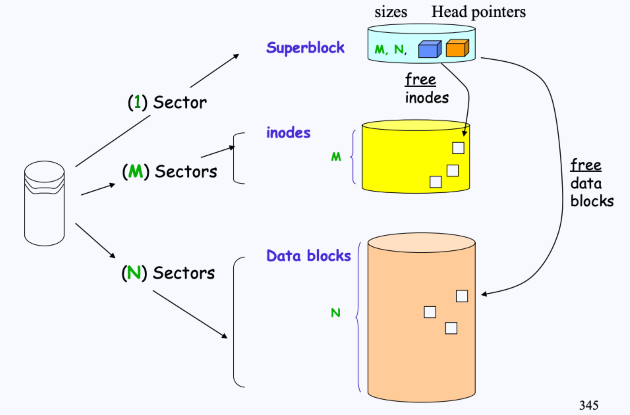
- (여기서 M은 inode의 사이즈를, N은 data block의 사이즈를 의미한다)
boot block
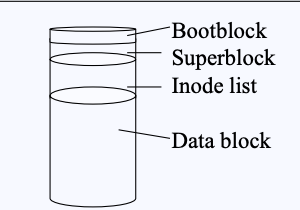
추가로, 리눅스에는 boot block도 존재한다. boot block은 이름 그대로 부팅 시에 로딩되기 위해 필요한 정보가 저장되어 있다.
Mount
이렇게 유닉스의 File System은 Bootblock, Superblock, I-node, Datablock 으로 구성되어 있따. 이때 이러한 File System은 disk에만 존재하는 것이 아니라, USB 같은 곳에도 들어있으며, 하드가 여러 개라면, 각 하드마다 하나씩 존재한다. 그렇다면 이렇게 여러 개의 File System이 있을 때, 어느 것이 root가 되어야 할까?
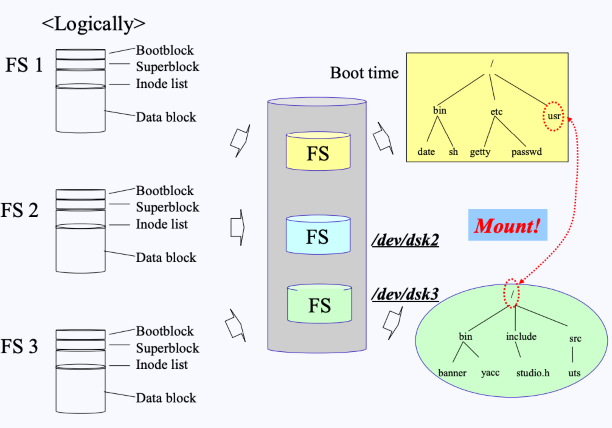
- 우선, 유닉스에서는 여러 File System 중에서 하나를 무조건 root로 하여 부팅을 해야한다.
- 만약 위 그림처럼 FS_1을 root로 부팅했다면, 부팅 시 화면에 FS_1이 루트로 세팅되어 올라오게 된다.
- 그리고 FS_2나 FS_3에 접근할 때에는 마운트(Mount)(시스템 콜)를 이용하여 접근하게 된다

- 위 그림처럼, 만약 FS_1의 root로 부팅을 했고, FS_1의 하위폴더 중
/usr에다가 FS_3(3번 디스크)를 마운트시키면,/usr를 통해/dev/dsk3의 FS에 접근할 수 있게 된다. 즉,/usr/은 다음 그림처럼/dev/dsk3의 root가 되어버리는 것이다.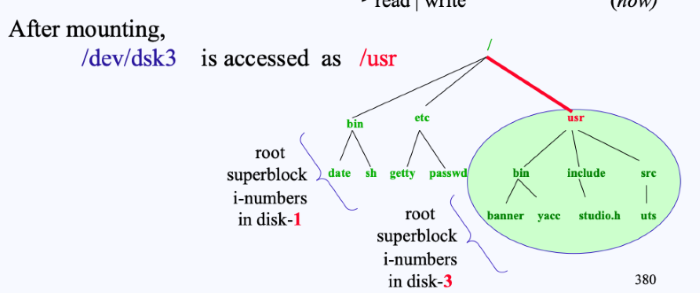
Reference
