
리눅스의 시간 관리
용어 - HZ, juffies
HZ
- HZ란 1초동안 몇 번 째깍거렸나를 나타내는 지표임
- ex) 1초에 천 번 쨰깍거린다면, 1000HZ(Hertz)가 될 것임
- 이를 컴퓨터적인 해석으로 표현하면 다음과 같다
#define HZ 1000 - 위 표현의 의미는 1초에 1000번 인터럽트(interrupt)가 걸린다는 의미이다.
- 대부분의 경우 HZ는 100을 걸어둔다(너무 많은 인터럽트는 오버헤드를 증가시키기 때문).
jiffies
- 시스템이 부팅된 후, 몇 번 째깍거렸는지를
jiffies라고 함 jiffies는 global 변수이며, 카운터의 역할을 함- 이
jiffies를 설정된 HZ로 나누면, 몇 초가 흘렀는지 알 수 있음jiffies가 3000이고 HZ가 100이라면, 부팅된 시간은 (3000/100 →) 30초 전이라는 것을 알 수 있다.
그렇다면 왜 HZ가 필요한걸까? 필요할 떄(입력이 생겼을 때)만 인터럽트를 하면 안 되는 걸까?
- 시스템에 시간 단위를 도입한 이유는 특정 시간마다 반복이 필요한 일들을 처리하려면, 시스템이 시간의 개념을 알아야 하기 때문임
- 또한 시스템이 스케줄링 등을 할 때 필요하게 됨
- 전 시간에 설명한 timeslice를 생각해보자. 각 프로세스들은 CPU 사용 시간을 할당받기 위해 timeslice를 가지고 있다. 이 때 할당받는 시간의 체크 단위를 HZ로 하게 되는 것이다.
→ 즉, HZ 단위로 계속해서 프로세스들이 돌아가며, 작업을 할 수 있게 하기 위해 특정 시간마다 인터럽트(interrupt)를 걸어주는 것이다.
Harware Clock and Timers
시스템 시간은 크게 Timer와 Real-Time Clock(RTC)로 나눌 수 있다.
- Timer는 주기적으로 CPU에게 인터럽트(interrupt)를 거는 역할을 함
- Real-Time Clock(RTC)은 현실 세계의 시간을 표현하며, ****PC의 전원을 꺼두어도 보조 배터리를 통해 계속해서 현재 시간을 측정한다.
그렇다면, Timer 인터럽트는 어떻게 구동되고 있는걸까?

- 앞서 말했든 1번 째깍거릴 때마다 인터럽트가 걸리게 된다.
- (1초에 100번 째깍거린다면, 1초에 100번 인터럽트가 걸린다는 의미)
- 이렇게 인터럽트가 걸리면 인터럽트 핸들러에 의해
do_timer()함수가 안에서 jiffies를 1만큼Tlr 증가시킨다. - 이후
update_process_times()함수가 호출되는데, 현재 동작하고 있는 프로세스의 PCB 정보를 토대로 Kernel-mode인지, User-mode인지에 따라 각 모드의 count를 증가시킨다.- 이 두 모드의 count를 합치면, 해당 프로세스가 얼마만큼 CPU를 사용했는지를 알 수 있음 → 해당하는 정보는 PCB에 존재함
그렇다면, 지금까지 여러번 나오고 있는 Interrupt는 도대체 무엇일까?
Interrupt 구조
interrupt란?
인터럽트(Interrupt)란 CPU가 프로그램을 실행하고 있을 떄, 입출력 하드웨어나 예외상황 등이 발생해 작업 처리가 필요할 경우에 CPU에게 알려서 이를 처리해달라고 요청하는 것임
단일 디바이스의 Interrupt
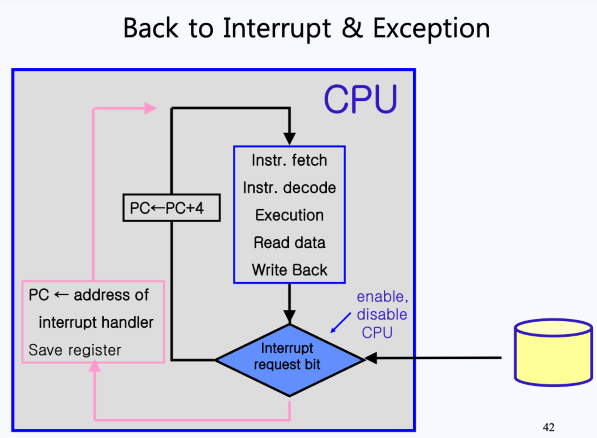
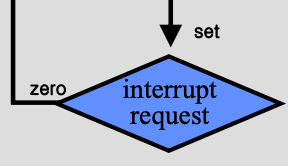
- 위 그림을 보면, CPU는 사이클을 돌면서 fetch, decode, execution 등의 루틴이 돌아가게 된다. 이떄, 하나의 사이클이 끝나면 다음 명령어를 수행하기 위해 PC가 증가한다.
- 이때 만약 위 그림처럼 disk가 중간에 인터럽트를 걸었다고 생각해보자.
- 이렇게 되면 CPU 내부에 Interrupt request bit가 설정됨.
- Interrupt request bit가 설정되어 있으면, 작업을 계속 돌지 않고, PC에 인터럽트 핸들러(interrupt handler) 주소가 들어가게 됨.
- 그리고 다시 진행을 하면 해당 주소가 fetch되며, disk를 서비스해주는 인터럽드 핸들러 루틴이 실행됨.
참고: 만약 Interrupt request bit를 disable시킨다면, 인터럽트를 당하지 않게 만들수도 있음
참고: preemption은 인터럽트 후에 발생하는 것임. 그러나 인터럽트가 항상 preemption만을 유발하는 것은 아님
멀티 디바이스의 interrupt
그렇다면, 하나의 디바이스가 아니라 한 번에 많은 디바이스들이 인터럽트를 요청하면 어떻게 될까?
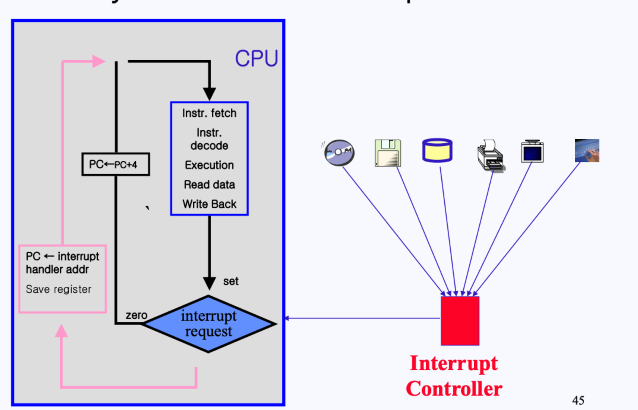
- 이럴 경우 각 디바이스가 Interrupt request bit를 설정시키는 방식이 아니라 중간에 Interrupt Controller가 이들을 통제하게 됨.
- 이 Interrupt Controller를 PIC(Programmable Interrupt Controller)라고 부름
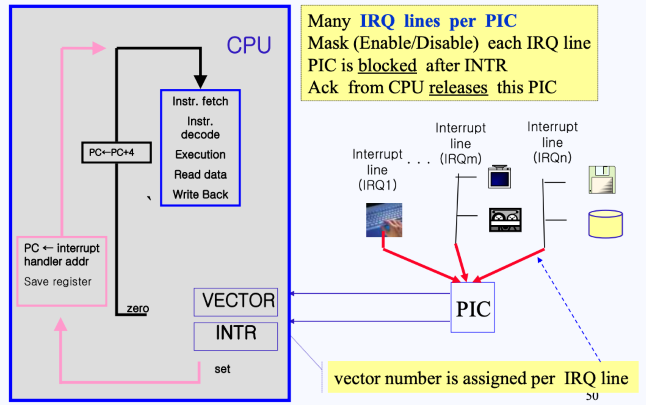
PIC에서 인터럽트를 처리하는 과정은 다음과 같다.
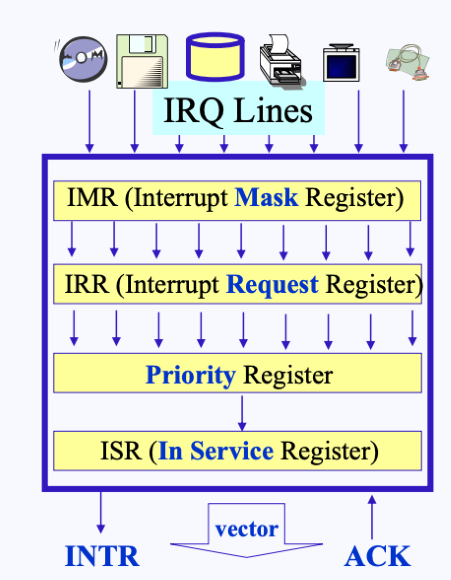
- 요청들을 한 device들은 Interrupt Request Line(IRQ Line)에 연결되게 됨
- 이들은 Interrupt Mask Register를 통해
0일경우 차단이 되고, 아닐경우 통과가 되어 Iterrupt Request Register에 들어가게 됨- 소프트웨어적으로 차단(
0)이 될 장치를 설정할 수 있음
- 소프트웨어적으로 차단(
- 이후 Priority Register에서 전달된 요청들 중 우선순위를 체크하고, 우선순위가 높은 요청(진행되어야 할 요청)들은 In Service Register에 등록되게 됨
- 마지막으로 위 요청이 INTR에 전달되어 Interrupt request bit이 enable되게 됨
- INRT로 요청이 전달될 때 어떤 디바이스가 요청했는지에 대한 정보는 vector에 담아서 보내게 됨
- 여기서 INTR은 CPU그림에서 보았던 interrupt request를 의미
- 이렇게 요청이 처리되고 있을 땐, 다른 PIC와 장치들은 차단되어져 있음
- CPU는 인터럽트 요청을 마친 후 ACK 신호를 보내게 되고, 신호를 받으면 PIC는 다음 인터럽트 요청을 처리하게 됨
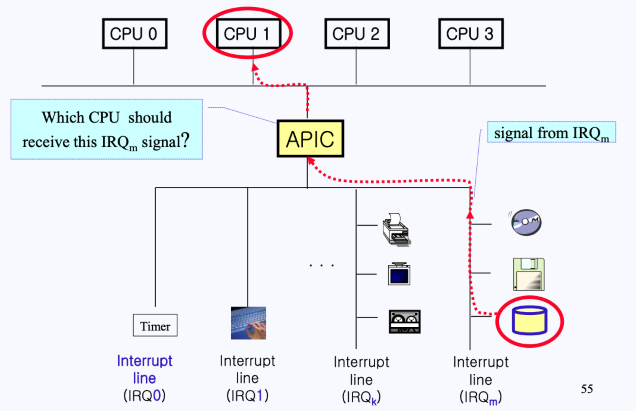
이 과정 전체를 도식화하면 다음과 같음.
멀티 프로세서 환경에서 멀티 디바이스의 interrupt
이번에는 여러 디바이스들의 요청들이 멀티 프로세서 환경에서는 어떻게 처리되는 지 알아보자.
Local-APIC & multi-APIC
멀티 프로세서 환경에서는 PIC가 다음과 같은 구조로 되어있다.
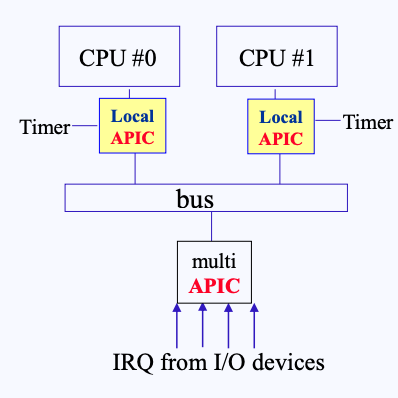
- 위 그림과 같이 CPU가 두 개가 있는 환경이라고 해보자.
- 두 CPU는 bus에 연결되어 있으며, bus는 (multi) APIC(Advanced PIC)에 연결되어 있다. 그리고 디바이스들은 이 (multi) APIC에 연결되어 있다.
- ** APIC : 멀티 프로세스를 위한 Advanced PIC
- CPU에는 local APIC도 존재하며, 이는 정기적으로 인터럽트를 걸어주는 Timer와 연결되어 있다.
Bus & I/O interface
본격적으로 interrupt를 설명하기 이전에 잠시 컴퓨터 구조를 살펴보면 다음과 같다.
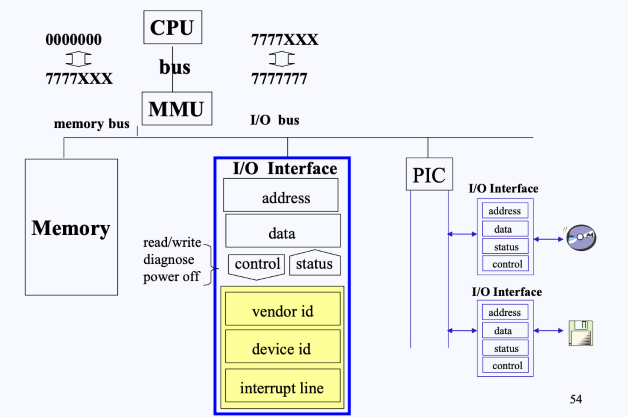
- CPU가
0000000~7777XXX번 메모리를 메모리 관리 유닛(MMU)에게 보내면 bus를 타고 좌측 Memory쪽으로 가게 되고, 7777XXX~7777777번 메모리를 MMU에 보내게 되면 **bus를 타고 I/O Interface**쪽으로 가게 되어있다.- I/O bus들에는 실제로 각 I/O 장치들이 연결되어 있는데, 이 장치들은 컴퓨터를 보면 있는 각종 연결할 수 있는 장치, 즉 I/O Interface card들로 연결이 되거나, 혹은 (그림 우측) PIC를 거쳐서 연결이 될 수도 있다.
SMP와 AMP
본격적으로 멀티 프로세싱에 대해 알아보자. 멀티 프로세싱은 크게 2가지 종류가 있다.
-
SMP(Symmetric Multiprocessing) : 대칭형 멀티 프로세싱
- SMP에서는 모든 프로세서가 하나의 메모리, I/O 디바이스, 인터럽트 등의 자원을 공유하며 하나의 운영체제가 모든 프로세스를 관리한다.
- 이러한 방식에서 디바이스가 I/O 인터페이스 카드에 연결되어 요청을 보내면, APIC가 받아서 처리를 하는데, CPU 간 차이가 없는 대칭형이기 때문에 어느 CPU에 요청을 전달 할 지는 다음과 같은 두 가지 방식을 사용한다.
- Static Distribution 방식
- 정적으로 정해진 곳에 보낸다.
- 이미 만들어진 Static Table을 통해 결정을 하게 된다
- Dynamic Distribution 방식
- 동적 IRO 분배 알고리즘으로 보낸다.
- 동적 IRO 분배 알고리즘의 목표는 우선순위가 가장 낮은 프로세스를 돌리고 있는 CPU에게 IRQ를 주는 것이다.
- 만약 running 중인 프로세스의 우선순위가 동일한 CPU가 존재하면, Arbitration 알고리즘을 적용한다.
- Arbitration : 모든 CPU가 카운터를 가진다. 현재 인터럽트 요청을 처리하는 CPU의 카운터는 0으로 만들고, 나머지는 카운터를 1씩 증가시킨다. 카운터가 높을수록 인터럽트를 제대로 수행하지 않은 놈이므로, 그에게 분배한다.
- 동적 IRO 분배 알고리즘으로 보낸다.
- Static Distribution 방식
- SMP에서는 각 CPU들이 자원을 공유하기 때문에 상호배제의 원칙(Mutual Exlusion)이 철저하게 보장되어야 한다. 따라서 상대적으로 구현이 어렵다.
-
AMP(Asymmetric Multiprocessing) : 비 대칭형 멀티 프로세싱
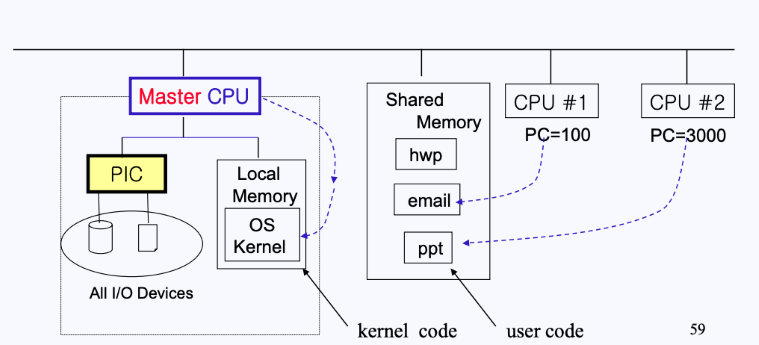
- AMP에서는 각 프로세스가 특정한 업무를 맡아서 한다. Master-Slave 형태로 되어 있으며, 주 프로세스가 전체 시스템을 통제하고, 다른 프로세스들은 주 프로세스의 통제 하에 동작된다.
- Master CPU는 본인만의 메모리를 가지고 있는데, 여기 OS 커널이 들어있음
- 즉, Master CPU만이 I/O를 처리할 수 있기 때문에 다른 CPU가 I/O를 처리하기 위해선 Master CPU에게 요청을 해야함.
- AMP는 SMP 대비 아키텍처 디자인이 간단하다는 장점이 있다.
- AMP에서는 각 프로세스가 특정한 업무를 맡아서 한다. Master-Slave 형태로 되어 있으며, 주 프로세스가 전체 시스템을 통제하고, 다른 프로세스들은 주 프로세스의 통제 하에 동작된다.
Data Structure for Interrupt Handling
Interrupt의 구조를 다시 상기해보면, IRQ Lines에는 많은 디바이스들이 물려있고, 이들의 요청을 컨트롤하기 위해 PLC가 존재한다.
이때, 각각의 IRQ Line에는 다음과 같은 4개의 정보가 담겨져 있다.
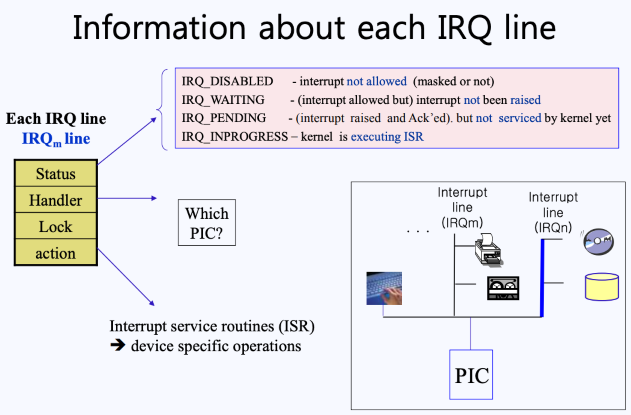
- Status
- IRQ_DISABLES : 인터럽트가 마스킹되어있는지(허용x)에 대한 상태
- IRQ_WATING : 인터럽트가 마스킹되어있진 않지만 아직 interrupt 요청이 오지 않은 대기 상태
- IRQ_PENDING : 인터럽트 요청이 왔지만, 아직 커널이 이를 서비스해주지 않은 상태
- IRQ_INPROGRESS : 커널이 인터럽트 서비스 루틴을 수행하는 상태(ISR)
- Handler : 인터럽트 요청이 어떤 PIC(local PIC? Multi PIC?)로부터 왔는지 확인해줌
- Lock : 공유 자원을 이용할 때(SMP) 상호배제를 위해 존재
- Action : 요청이 어떤 IRQ Line에 있는 어떤 디바이스로부터 왔는가에 대한 정보가 담겨져 있음.
- 따라서 Action 필드를 따라가다 보면 ISR이 리스트로 쭉 연결되어 있음
만약 IRQ Line이 여러 개라면, 다음과 같이 위 4개의 정보를 하나의 구조체로 하여 배열 형태로 IRQ Lines의 정보가 관리된다.
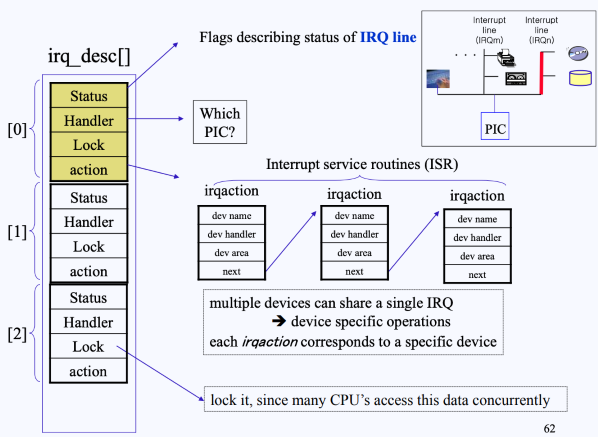
- 만약 IRQ Line이 3개라면 위 그림처럼 IRQ Lines가 존재할 것이다.
- 이 3개의 IRQ Line은
irq_desc라는 배열 형태로 관리된다. irq_desc배열은 Shared variable임
- 이 3개의 IRQ Line은
- 이 중 action 필드는 ISR과 연결되어 있는 것을 확인할 수 있다.
- 해당 포인터를 따라가서 요청이 어떤 디파이스로부터 왔는가를 체킹한다.
이 구조를 전체 구조와 연결지어보면 다음과 같다.
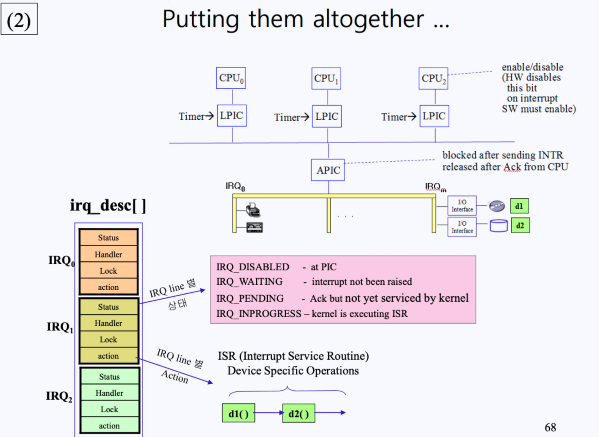
Interrupt 진행
Function for interrupt
실제로 인터럽트가 걸렸을 때 어떤 코드가 실행되는지를 알아보자.
- 제일 먼저
IRQn_interrupt()가 호출된다.- 해당 함수는 어셈블러 함수임.
- ** 어셈블러 : 기계어와 1:1대응이 되는 컴퓨터 프로그래밍 저급 언어
- 해당 함수는 어셈블러 함수임.
IRQn_interrupt()함수가 호출되면, 간단한 동작을 한 후 바로do_IRQ(n)함수를 호출함.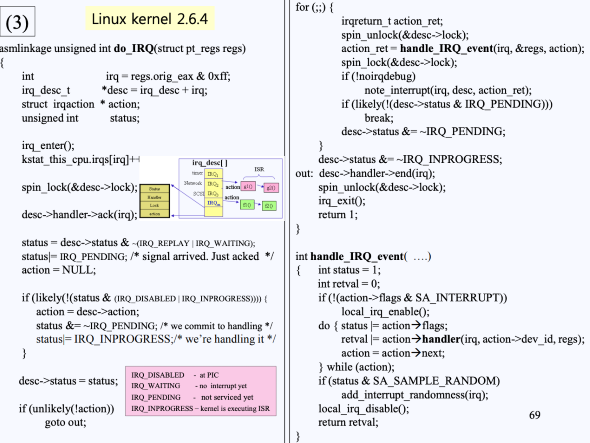
do_IRQ()함수는 struct pt_regs라는 자료형으로, regs 변수를 하나 가지고 들어온다. 이후 reg.irg_eax & 0xff 연산을 통해irq line number를 뽑아낸다.- 해당
irq line number가 바로irq_desc[]배열의 인덱스이다.
- 해당
- 이후
irq_desc + irq;연산을 통해 irq_desc[]의 특정 인덱스에 있는 구조체 주소(desc)를 가져오게 된다. - 이후
spin_lock(desc→lock)함수를 통해 상호배제를 확인- 자원이 사용중이지 않으면, lock을 건 후 자신이 요청을 함
- 자원이 사용중이면 계속 기다리게 됨
- 요청이 된 후에는,
desc → handler를 참조하여 어떤 PIC(local? multi?)가 요청하였는지 찾고, 해당 PIC에 ack 신호를 보냄(다른 인터럽트 처리를 위해) - 이후
desc → status를 가져와서 irq_lines의 IRQ_WATING을 없애고, 처리를 기다린다는 상태인 IRQ_PENDING을 설정함.- 이 때
action = NULL로 설정하여 서로 다른 CPU들이 동일한 ISR(Interrupt Service Routine)을 하지 못하도록 방지함
- 이 때
- 이후 (사진 우측) for문을 돌면서
desk → lock을 unlock 시킴irq_desc[]에서 들어온 요청을 이미 찾았기 때문에 이제 critical_section에 접근할 필요가 없기 떄문
- 이후
handle_IRQ_event(...)을 호출함- 이 함수 안에서 실제로
action →에 연결된 요청 작업을 수행함- ** Action : 요청이 어떤 IRQ Line에 있는 어떤 디바이스로부터 왔는가에 대한 정보가 담겨져 있음.
- 이 함수는 do-while()로 되어 있기 때문에 action 필드가 NULL일 때까지 모든 (해당)IRQ Lines에 연결되어 있는 디바이스의 인터럽트 요청을 처리함
- 이 함수 안에서 실제로
Interrupt Routine이 진행중인 IRQ 라인에서 또 다른 요청이 생기는 경우
Interrupt Routine이 진행중인 IRQ 라인에서 또 다른 요청이 생기는 경우 다음과 같이 실행된다.
(현재 APIC가 CPU0에게 IRQ라인에 대한 처리를 요청한 상태라고 가정한다)
- 만약 현재 요청 들어온 IRQ라인에 일을 해주고 있는 CPU가 없는 상태이다. 이제 CPU0이 이를 해주기 시작한다.
- CPU0이 IRQ 라인을 처리하고 있는 도중 동일한 IRQ 라인에서 요청이 와서 CPU1이 처리해주려고 한다. IPQ 라인의 status는 현재IRQ_INPROGRESS가 설정되어 있기 때문에 CPU1은 이를 확인하고 IRQ_PENDING 값을 추가로 세팅해준 다음 종료한다.
- CPU0이 수행하고 있는
handle_IRQ_event(...)함수가 끝나면 for문에서 다시 한 번 IRQ_PENDING을 체크함. 로직에서 분명 IRQ_PENDING을 껐었지만, 이게 다시 세팅되어있다면, 동일한 라인에서 또 요청이 들어왔다는 것이고, 이는 다른 CPU가 나에게 처리부탁을 요청했다는 의미이다. 따라서 다시handle_IRQ_event(...)함수를 실행한다.
interrupt 흐름 정리
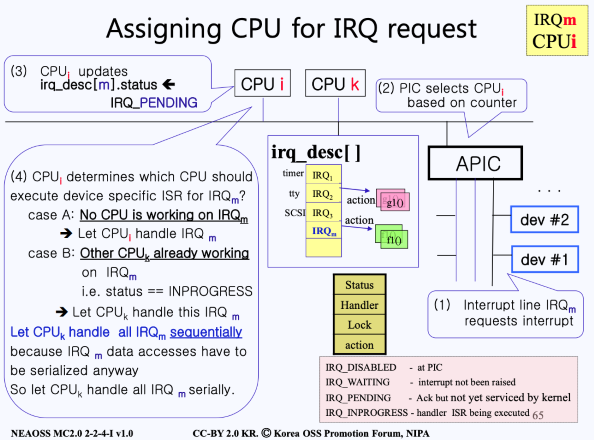
- (multi)APIC의 IRQ Lines에는 여러 디바이스가 물려있음. 따라서 IRQ 라인을 통해 특정 디바이스가 인터럽트 요청을 보내게 됨.
- APIC에서는 이 요청을 여러 CPU 중 (위 그림에서는) CPU을 선택하였음.
- 따라서 CPU의 counter는 0이 됨. (Arbitration)
- CPU는 irq_desc[m]의 status를 IRQ_PENDING으로 업데이트함.
- 이제 어떤 CPU가 해당 인터럽트를 처리하게 될 지 선택함
- 첫 번째 케이스 : 어떠한 CPU도 IRQ을 처리하고 있지 않다면, CPU가 바로 처리함
- 두 번째 케이스 : 만약 다른 CPU(예를 들어. CPU)가 이미 IRQ을 처리하고 있으면, Status에 IRQ_PENDING 값을 추가로 세팅해줌으로써 요청을 CPU에게 넘김
전반부 처리(Top Half)와 후반부 처리(Bottom Half)
인터럽트를 위한 do_IRQ()함수의 로직은 많은 민폐를 끼침
- 요청에 대한 ACK가 오기 전까지 PLC는 block됨
- 공유 메모리를 사용하기 때문에 lock이 걸리면 다른 CPU는 사용하지 못함
do_IRQ()함수의 로직을 들여다보면, 다음과 같은 특징이 있다.
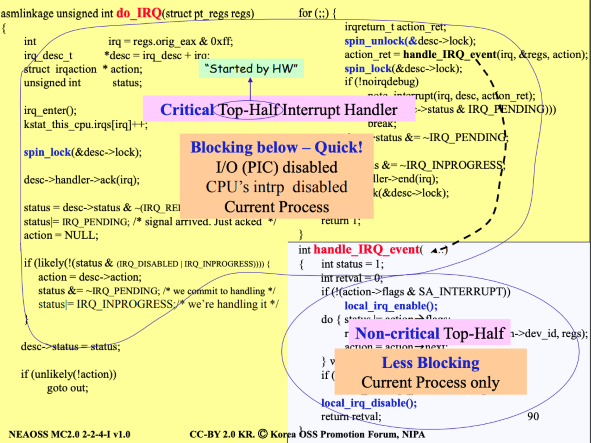
- 민폐를 끼치는 영역은 위와 같이 Critical Top-Half 영역에서 주로 발생한다.
- 따라서 해당 영역은 매우 신속한 처리를 필요로 한다.
- Critical Top-Half 영역이 아닌 Non-Critical Top-Half 영역은 보다 민폐를 끼지는 상황이 덜하지만, 존재하긴 함
그렇다면, 만약 인터럽트의 작업이 굉장히 무거워서, 신속한 처리를 하지 못한다면 어떻게 될까?
- 리눅스에서는 이와 같은 문제를 해결하기 위해 작업을 나눠서 처리한다.
- 또한 한 번에 처리하지 못하는 작업을 이후에 다시 처리할 수 있도록 soft-irq이라는 bit를 설정한다.
- 해당 bit가 설정되어 있다면,
do_softirq()함수를 통해 남은 작업을 다시 수행하도록 소프트웨어적으로 구현되어 있다. - 이러한 매커니즘을 Bottom Half 라고 부른다.
- 즉, Top Half(전반부 처리)는 하드웨어에 의해, Bottom Half(후반부 처리)는 소프트웨어에 의해 실행되는 로직을 갖는다.
- 해당 bit가 설정되어 있다면,
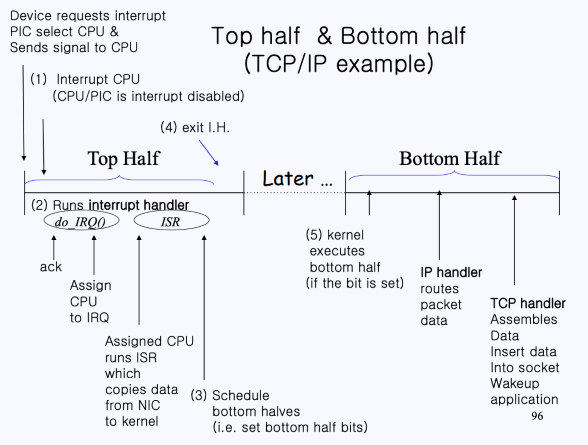
네트워크 장치의 경우에서 Top Half와 Bottom Half이 동작되는 예시를 생각해보자.
- 현재 NLC(네트워크 인터페이스 카드)에서 인터럽트 요청이 들어왔다.
- 네트워크 전송량과 지연시간을 최적화하고, 타임아웃을 막으려면 즉시 이 작업을 처리해야 함.
- 그러므로 즉시 인터럽트를 발생시켜서 커널에게 새로운 패킷이 왔다는 것을 알린다.
- 커널은 이에 반응해 네트워크 장치에 등록된 인터럽트를 실행시킴.
- PIC는 특정 CPU를 선택하고, CPU에서는
do_IRQ()를 호출하여 Top Half를 수행함.- Top Half를 수행하면서 ACK를 보내고, 새로 수신한 네트워크 패킷을 주 메모리에 복사한 다음, 네트워크 카드를 다시 패킷을 수신할 수 있는 상태로 조정함
- 이후 실제 패킷의 동작 처리는 Bottom Half에서 처리될 수 있도록 softiqr_pending[] 을 세팅함 (Top Half가 수행할 일은 여기서 끝나게 됨)
- 이후 시스템 제어권을 인터럽트 발생으로 실행이 중단된 코드로 다시 돌려주며, 나머지 패킷 처리는 나중에 후반부 처리에서 진행함.
- CPU가 처리할 작업의 우선순위를 보고 처리하는데, softiqr_pending[] 이 설정된 애들은
do_softiqr()을 실행시켜 나머지 Bottom Half가 처리될 수 있도록 함
- CPU가 처리할 작업의 우선순위를 보고 처리하는데, softiqr_pending[] 이 설정된 애들은
위 예시를 도식화하면 다음과 같다.
후반부 처리(Bottom half) 살펴보기
전반부 처리와 후반부 처리를 다시 상기해보자. 인터럽트 요청이 오면 Top Half 루틴이 수행되고, 큰 작업이 필요한 경우에는 softiqr_pending[] 을 설정한다.
softiqr_pending: bit
softiqr_pending: bit는 다음과 같은 구조로 되어있다.
- 왼족 아래 softiqr_pending[] 을 보면, 1로 세팅되어 있는 부분이 현재 Bottom Half 으로 처리해야 할 부분을 의미한다.
- 이는 인덱스마다 정해져 있음
- ex) 0번 인덱스는 디스크 관련, 1번 인덱스는 TCP/IP 관련
- 만약 인덱스 1의 bit가 설정되어 있다면, 같은 인덱스의 soft_vec[]을 참조한다.
- 위 그림에서 action data 부분은 기능을 수행하는 action과 실제 데이터를 가르키는 필드로 이루어진 구조체임.
do_softiqr()
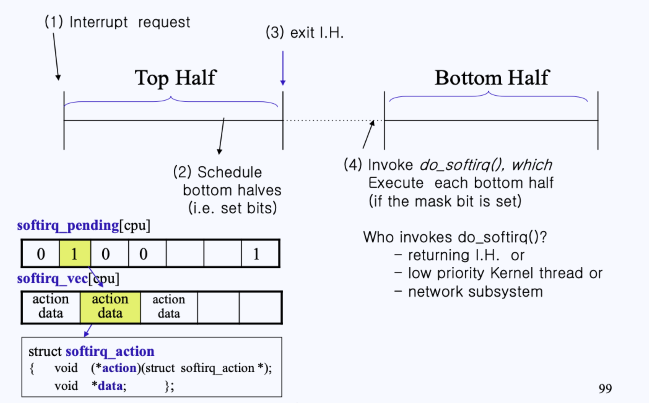
이제do_softiqr()함수를 살펴보자.

- Top Half는
do_irq()함수를 호출하고, Bottom Half는do_softirq()함수를 호출한다. - 위 그림과 같이
do_softirq()함수의 로직은do_irq()와 비슷하다. - 로직
- softiqr_pending[]을 확인하여 1(→ softirq_vec)이면, 이에 해당하는
h → action을 호출한다. - 이후 pending을 쉬프트 연산을 통해 하나씩 반복해서 확인한다.
- 이떄,
h → action이 Bottom Half의 softirq handler역할을 수행한다.
- softiqr_pending[]을 확인하여 1(→ softirq_vec)이면, 이에 해당하는
Softirq, Tasklet, Work Queue
Softirq
앞서 배웠던 Softiqr은 여러 개의 CPU가 동시에 ISR 핸들러를 실행시킬 수 있다. 동시성이 높아지기 때문에 처리량이 많아진다면 이러한 장점은 네트워크 패킷 핸들링과 같은 곳에 매우 유용하다.
- 하지만 코딩하기에는 많은 복잡성이 따른다.
Tasklet
Tasklet은 굳이 동시성이라는 것이 필요없는 함수를 수행하기 위해 등장하였다.
- Tasklet은 softirq이긴 하지만, CPU가 한 번에 하나의 ISR 핸들러만 수행시킬 수 있다.
- 따라서 구현은 간단하지만, softirq보다는 처리량이 떨어진다
- 따라서 간단한 일을 처리할 때 사용될 수 있다.
- Tasklet의 구조체를 보면, state라는 필드가 있다.
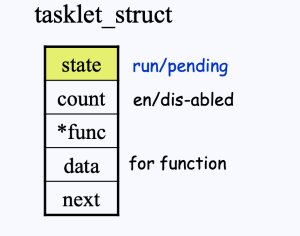
- 이 state 필드가 1이면 접근을 못하고, 0이면 접근하여 사용이 가능하다.
workqueue
Softirq와 Tasklet은 interrupt를 받은 상태로 동작하기 때문에 더 우선순위가 높은 interrupt가(ex. HW interrupt) 오지 않는 이상 작업을 모두 수행하기 전까지 다른 프로세스가 끼어들 수 없다. 만약 Softirq와 tasklet에서 처리하는 작업이 길고 남발하면 다른 작업들은 그만큼 뒤로 밀리게 돼 시스템 전반의 성능 저하가 올 수도 있다.
이러한 경우 workqueue를 사용할 수 있다.
- workqueue는 일반 프로세스가 동작하는 것처럼 동작한다.
- workqueue를 관리하는 handler는 일반 프로세스처럼 CPU의 스케줄링을 받기 때문에 Softirq와 Tasklet과는 달리 작업이 끝나지 않았더라도 sleep에 들 수 있다.
- 즉, 시스템에 무리를 줄 수 있는 요소가 없기 때문에 시간이 충분한 경우 유용하게 사용할 수 있다.
Reference
