MLOps란
배경
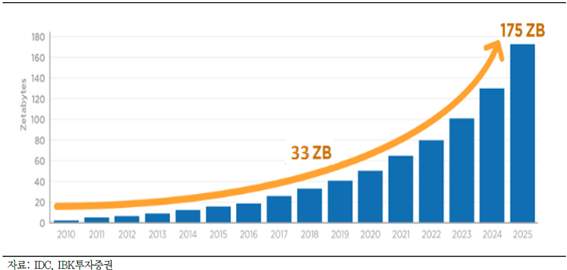
디지털 혁명 이후 수집되는 데이터 양은 기하급수적으로 늘어나게 되었고 '데이터 중심'의 세계가 펼쳐지게 되었습니다. 이에 따라 데이터에서 인사이트를 도출하는 인공지능, 머신러닝, 데이터 사이언스의 중요도는 점차 증가하고 있으며, 학계에는 수 많은 머신러닝의 가능성을 말하는 논문들이 쏟아져 나오고 있습니다.
이러한 머신러닝 트렌드의 도래에도 불구하고 기업들은 실제 문제 해결을 위해 머신러닝을 적용하는데 어려움을 겪고 있습니다. 높은 정확도를 가진 머신러닝 모델을 보유하고 있다고 하더라도, 이를 실제 서비스에 배포하고 운영하는 것은 또 다른 문제이며 매우 어려운 일이기 때문입니다. 예를 들어, 머신러닝 엔지니어가 완성된 모델을 전달하면 프로그래머들은 그들의 방식대로 모델을 배포하고자 할 것입니다. 그러나 작업환경차이, 패키지이해, 구조이해, 데이터에 대한 이해관계차이 등의 이유로 배포가 어려울 때도 있고, 배포했어도 모델이 제대로 동작하지 않는 경우도 발생할 수 있습니다.
이와 같은 문제를 해결하기 위해 나온 개념이 MLOps입니다. 우리는 MLOps를 통해 머신러닝 모델 개발과 머신러닝 서비스 운영 간 격차의 최소화를 기대할 수 있습니다.
MLOps정의
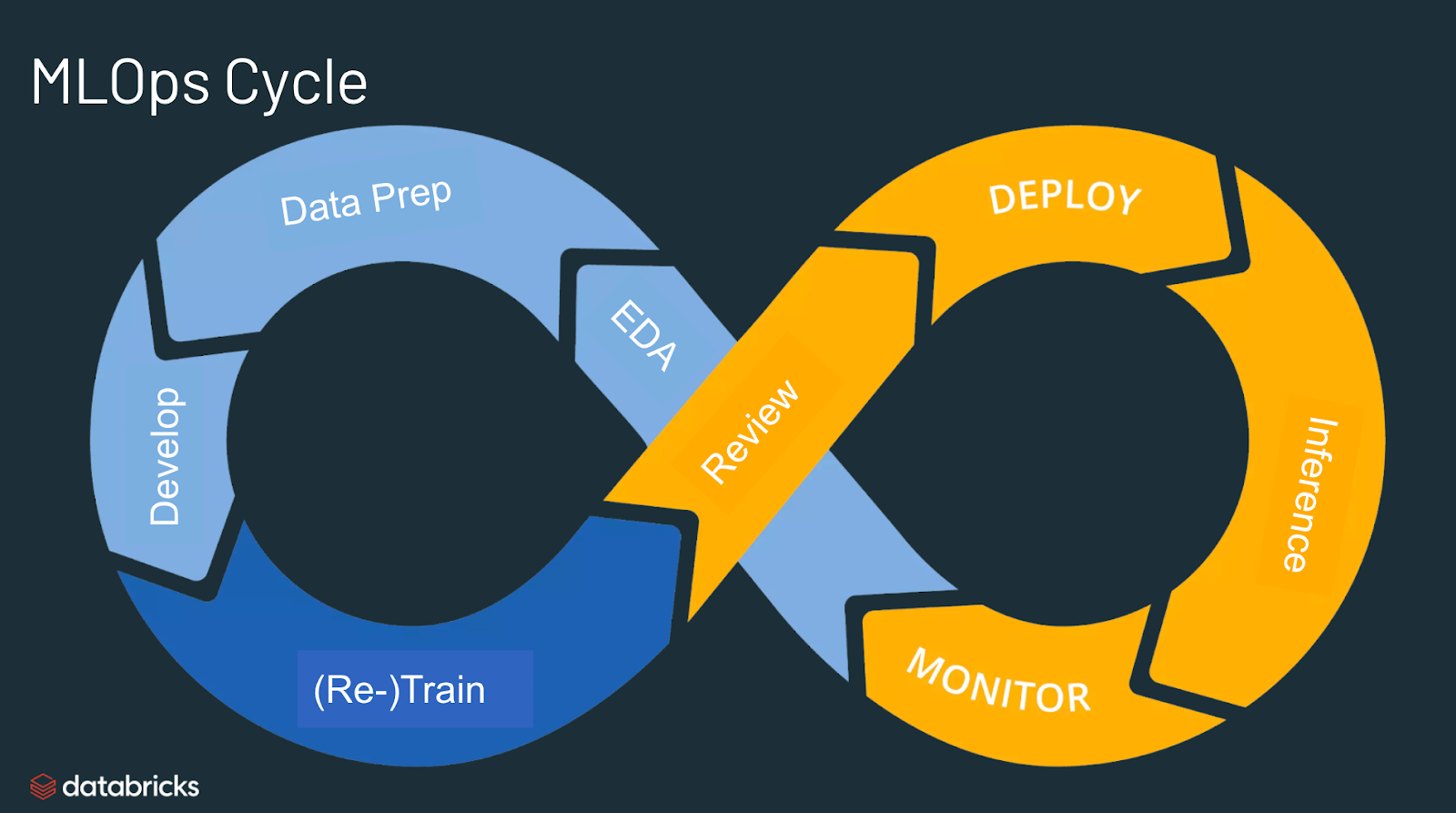
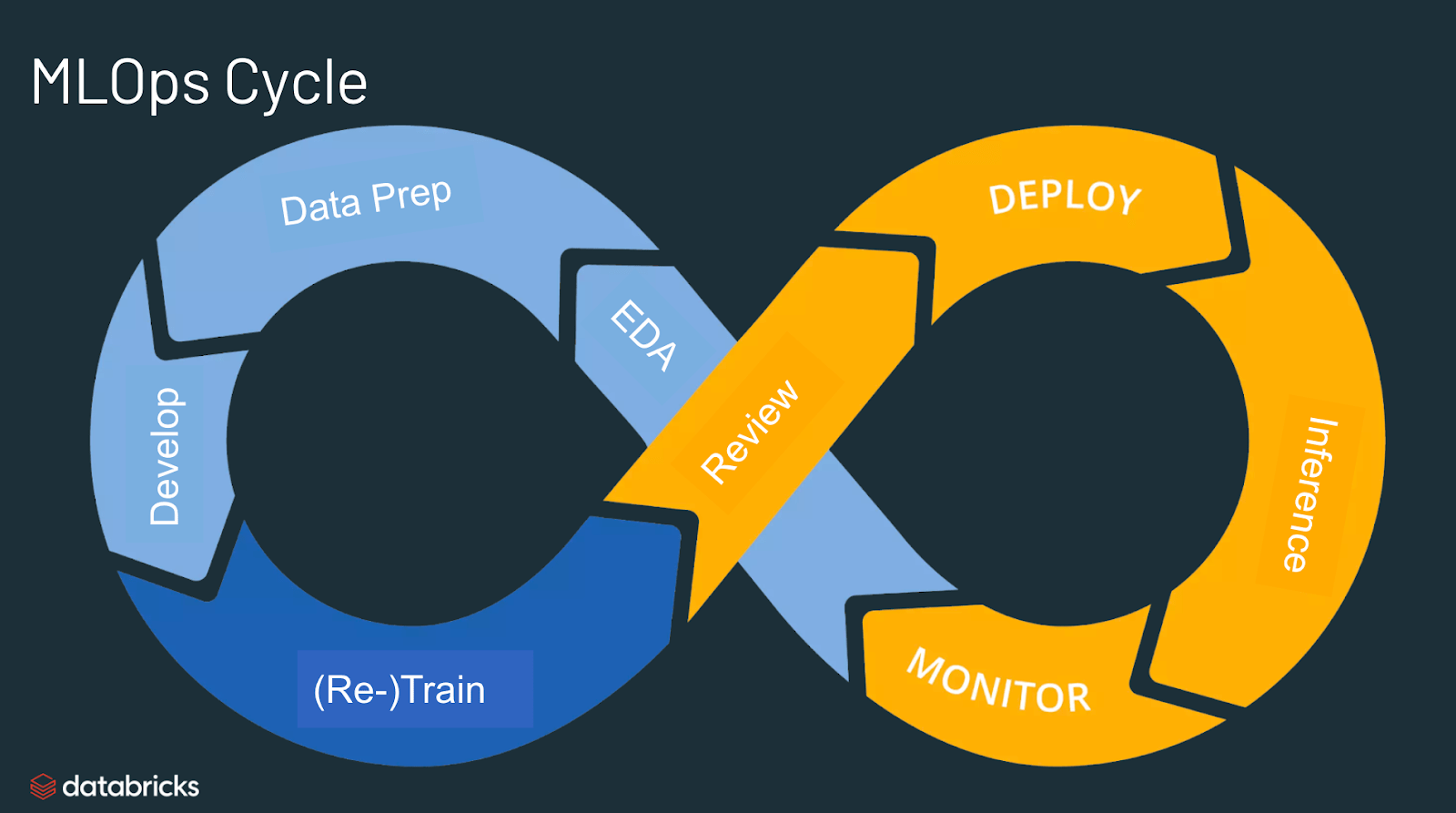
MLOps는 Machine Learning(ML)과 Operations(Ops)를 합친 용어입니다. 즉, 프로덕션 환경에서 머신러닝 모델을 안정적이고 효율적으로 배포 및 유지 관리하는 것을 의미힙니다.
- 머신러닝 모델 개발(ML Dev)과 머신러닝 모델 운영(Ops)의 격차를 최소화(통합)하고 빠르고 효율적으로 비즈니스 가치를 창출하는 것이 목표입니다.
- MLOps는 크게 ML(학습) 단계와 Ops(운영) 단계로 나눌 수 있습니다.
- ML 단계: 데이터 수집, 전처리, 모델 구축, 학습, 평가 등
- Ops 단계: 모델 배포, 모니터링, 테스트 등
- MLOps는 머신러닝 엔지니어링, 데이터 엔지니어링, 클라우드, 인프라 등을 모두 포함하고 있습니다.
Research ML vs Production ML
Research와 Production에서의 Machine Learning은 관점에 따라 약간의 차이가 존재합니다.
- Data: Research에서 데이터는 가공되어 있으며, 고정됩니다. 반면, Production 단계에서 데이터는 지속적으로 변화하며 누락 값 등이 존재합니다.
- 중요 요소: Research에서는 모델 성능의 최대화가 가장 중요한 요소입니다. 반면, Production에서는 모델 성능과 더불어 Inference 속도, 해석 가능 여부 등이 중요하게 됩니다.
- 지향하는 목표: Research는 더 좋은 성능을 내는 모델을 만들어내어 논문 등을 출판하는 것이 목표가 됩니다. 반면, Production에서는 안정적인 운영, 전체 시스템 구조의 최적화를 이루어내어 실 서비스에서 문제를 해결하는 것이 목표가 됩니다.
- 학습: Research에서 데이터는 고정되어 있습니다. 따라서 모델 구조, 하이퍼파라미터 등에 기반하여 재학습됩니다. 반면 Production에서는 시간에 흐름에 따라 데이터가 변경되므로, 이에 기반하여 재학습됩니다.
단계별 MLOps
구글에서는 MLOps의 발전 단계를 총 3(0~2)단계로 나누었습니다.
[MLOps: Continuous delivery and automation pipelines in machine learning]
Level 0: 수동 프로세스
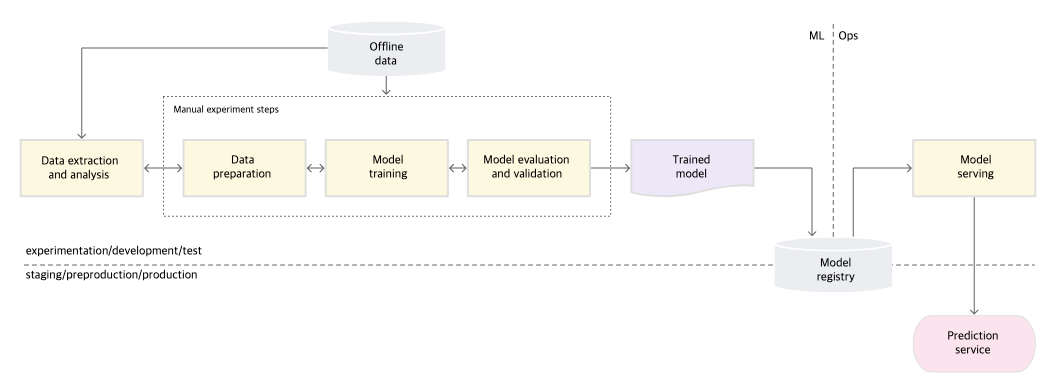
Level 0에서는 ML 모델을 빌드하고 배포하는 과정이 완전히 수동으로 이루어집니다.
- 특징
- 데이터 추출과 분석, 모델 학습, 검증을 포함한 모든 단계가 수동입니다.
- 머신러닝 팀과 운영 팀이 분리되어 있습니다.
- 이 단계에서는 모델을 개발하는 머신러닝 팀과 배포 및 운영을 담당하는 운영팀이 분리되어 있습니다.
- 머신러닝 팀은 데이터로 모델을 학습시키고, 학습된 모델을 운영팀에 전달합니다. 운영팀은 이렇게 전달받은 모델을 배포합니다.
- 새 모델 버전의 배포가 드물게, 비정기적으로 발생합니다.
- 변경이 많지 않으므로 CI가 필요하지 않습니다.
- 배포가 자주 없으므로 CD가 필요하지 않습니다.
- 모델 예측 및 작업 추적(로깅)을 하지 않습니다.
- 도전 과제(모델의 정확도를 프로덕션 환경에서 유지하기 위해)
- 프로덕션 환경에서 모델의 품질을 모니터링 하여 성능 저하 및 모델 비활성을 감지해야 합니다.
- 새로운 데이터 패턴이 포착(Data Shift)되면 최신 데이터로 모델을 재학습시켜야 합니다.
- 특성 추출, 아키텍처, 하이퍼파라미터 등의 새로운 구현을 지속적으로 시도해야 합니다.
Level 1: ML파이프라인 자동화
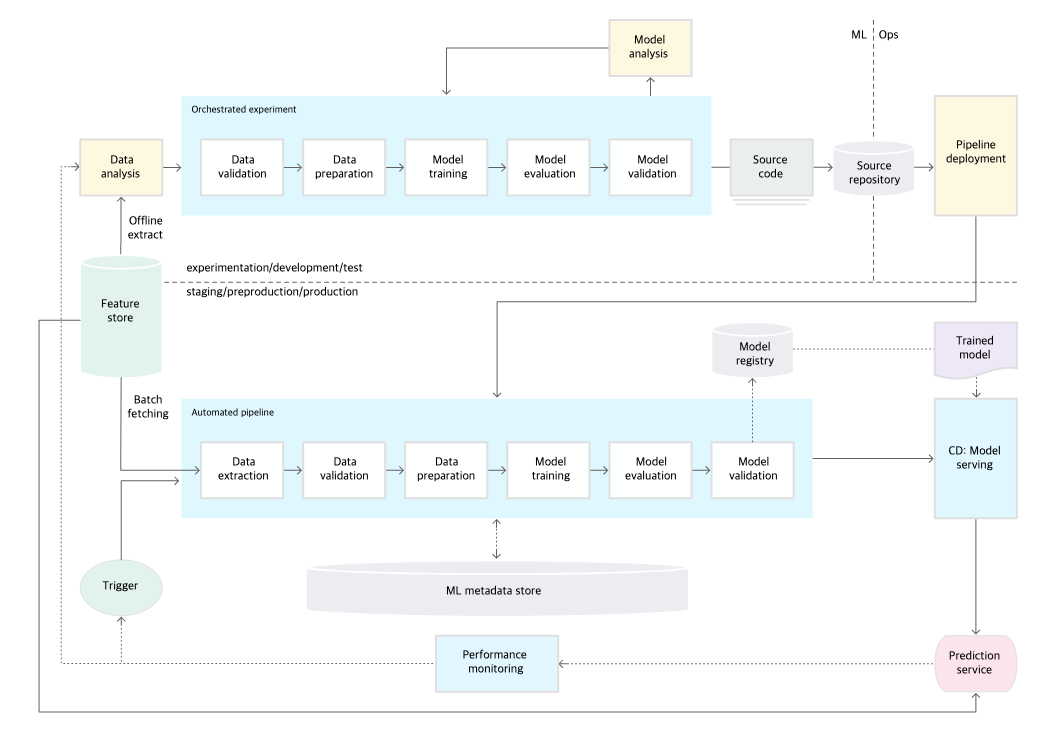
Level 1의 목표는 ML 파이프라인을 자동화하여 모델을 지속적으로 학습시키는 것입니다. 이를 위해 파이프라인 트리거, 메타데이터 관리, 자동화된 데이터 및 모델 검증 단계 등을 시스템에 도입하여야 합니다.
- 특징
- 개발과 운영의 개발 환경이 통일됩니다(-> 파이프라인)
- 학습된 모델을 서비스로 제공하기 위해 자동으로 실행되는 전체 학습 파이프라인을 배포합니다.
- 단계 간 전환이 자동으로 이루어지기 때문에, 실험을 빠르게 반복하고 전체 파이프라인을 프로덕션으로 빠르게 배포할 수 있습니다.
- 파이프라인 트리거를 통해 프로덕션 모델이 자동으로 학습됩니다(Continuous Training).
- CT에 의해 학습된 서비스를 지속적으로 배포합니다.
- 개발과 운영의 개발 환경이 통일됩니다(-> 파이프라인)
- CT(Continuous Training)를 위해서는 다음과 같은 요소가 추가적으로 필요합니다.
- 데이터 & 모델 검증
- 데이터 검증: 모델 학습 전에 모델을 재학습 할 것인지 혹은 파이프라인 실행을 중지 할 것인지를 결정합니다.
ex) 예상치 못한 데이터가 Input으로 들어온 경우, 데이터 패턴이 변경되었을 경우 - 모델 검증: 새 데이터로 모델을 학습시킨 뒤, 해당 모델을 프로덕션에 올려보낼 것인지를 평가하고 검증합니다.
ex) 오프라인 모델 테스트(정확도, 정밀도, 재현율, ...), 온라인 모델 테스트(A/B 테스트, ...) 등
- 데이터 검증: 모델 학습 전에 모델을 재학습 할 것인지 혹은 파이프라인 실행을 중지 할 것인지를 결정합니다.
- 특성 저장소(Feature Store): 학습과 서빙에 사용되는 feature들을 모아둔 저장소입니다. 특성 저장소는 다음과 같은 요소들로 구성되어 있습니다.
- 원시 데이터를 처리 및 가공하여 feature를 생성합니다.
- 생성된 feature를 저장합니다.(data warehouse)
- feature의 메타정보를 저장합니다.(metadata storage)
- 데이터 과학자가 feature에 쉽게 접근할 수 있는 API를 제공합니다.
- 메타데이터 관리: 재현성, 비교, 로깅 등을 위해 파이프라인을 실행할 때마다 다음과 같은 메타데이터를 기록합니다.
- 실행된 파이프라인 & 구성요소 버전, 시간정보
- 파이프라인 실행자
- 매개변수 인수
- 파이프라인의 각 단계에서 생성된 아티팩트에 대한 포인터(라인 중간중간의 기록을 남기기 위해)
- 이전 모델에 대한 포인터(롤백이 필요한 경우를 위해)
- 모델 평가 측정 항목(성능 비교를 위해)
- ML파이프라인 트리거
- 데이터 & 모델 검증
Level 2: CI/CD 파이프라인 자동화
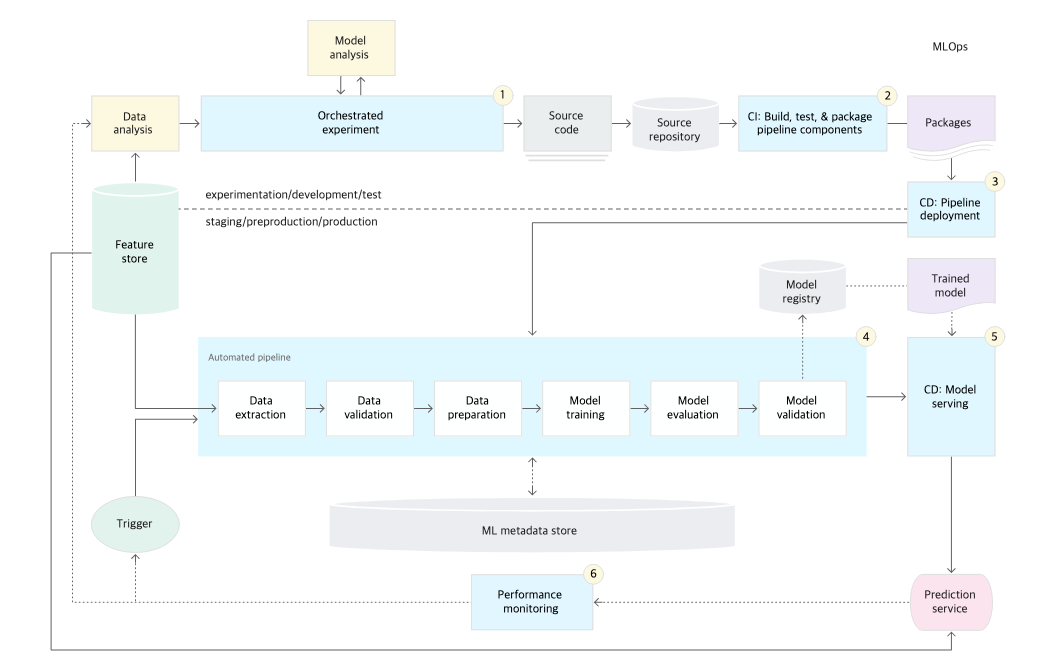
Level2의 핵심은 CI와 CD의 자동화입니다. MLOps에서 말하는 자동화된 CI/CD의 대상은 DevOps와 같은 소스 코드이지만, 중점은 '학습 파이프라인'에 있습니다. 따라서 모델을 학습하는데 있어서 영향이 있는 소스코드 변화에 대해 실제로 모델이 정상적으로 학습이 되는지, 학습된 모델이 정상적으로 동작하는지 등을 확인합니다.
- 지속적 통합(Continuous Integration): 소스코드가 커밋되거나 공유저장소로 푸쉬될 때 빌드, 테스트, 패키징됩니다. CI에선 다음과 같은 테스트가 포함될 수 있습니다.
- 특성 추출 로직 테스트
- 모델 학습이 수렴하는지 테스트
- 모델에 구현된 메서드를 단위 테스트
- NaN 값을 생성하진 않는지 테스트
- 파이프라인의 각 구성요소 간 통합을 테스트
- ...
- 지속적 배포(Continuous Delivery): 새 파이프라인 구현을 지속적으로 배포하여 새 모델의 서비스를 Production에 전달합니다. 빠르고 안정적인 CD를 위해 다음 사항을 고려해야 합니다.
- 모델 배포 전 모델과 인프라의 호환성을 확인(패키지, 메모리, 컴퓨팅 자원, ...)
- API 호출 테스트
- 서비스 부하 테스트
- 예측 성능이 목표치를 충족하는지
- ...
MLOps 구성요소
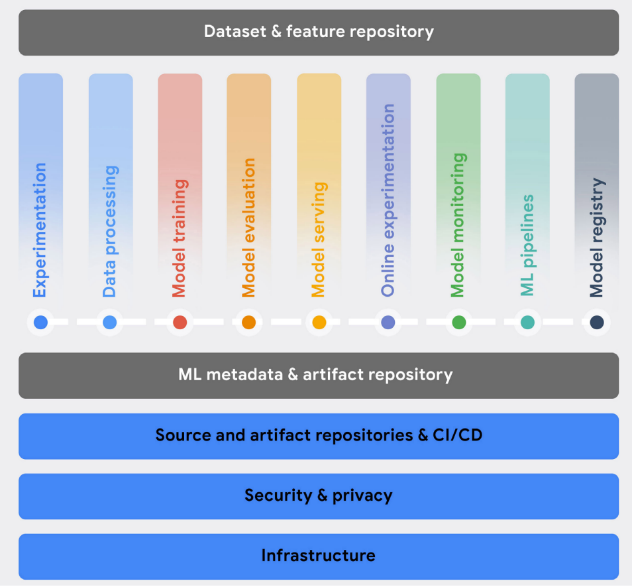
2021년 5월에 발표된 구글의 Practitioners guide to MLOps:
A framework for continuous delivery and automation of machine learning.에서는 다음과 같은 MLOps의 기능들을 언급하였습니다.
Experimentation
Experimentation은 데이터 과학자들이 데이터를 분석하고, 프로토타입 아키텍처를 만들고 학습을 구현할 수 있도록 합니다. Experimentation의 주요 기능은 다음과 같습니다.
- 버전관리 도구(Git과 같은)와 통합된 노트북 환경을 제공합니다.
- 데이터, 하이퍼파라미터, 평가지표 등에 대한 정보를 저장합니다.(실험 추적)
- 데이터와 모델을 분석하고 시각화하는 기능을 제공합니다.
Data Processing
Data Processing은 머신러닝 개발, CT(Continuous Training), Serving 단계에서 대규모 데이터를 준비시키고, (목적에 맞게)변환시킵니다. Data Processing의 주요 기능은 다음과 같습니다.
- 다양한 데이터 형식에 대한 인코더와 디코더를 제공할 뿐 아니라, 광범위한 데이터 소스(source) 및 서비스에 대한 데이터 커넥터를 제공합니다.
- 다양한 형태의 데이터에 대한 데이터 변환과 피처 엔지니어링을 제공합니다.
- 학습 & 서빙을 위해 확장 가능한 배치, 스트림 데이터 처리를 제공합니다.
Model Training
Model Training에서는 학습을 위한 알고리즘을 효율적으로(비용 포함) 실행할 수 있도록 합니다. Training의 주요 기능은 다음과 같습니다.
- ML 프레임워크와 (커스텀)런타임 환경을 제공합니다.
- 여러 GPU를 사용하기 위한 대규모 분산 처리 환경을 제공합니다.
- 효율적인 하이퍼파라미터 튜닝과 최적화 기능을 제공합니다.
- (이상적으로는)자동화된 피처 선택 & 엔지니어링, 자동화된 모델 아키텍처 선택 등 AutoML 기능을 제공합니다.
Model Evaluation
Model Evaluation은 실험 환경과 프로덕션 환경에서 동작하는 모델의 효율성을 평가합니다. Model Evaluation의 주요 기능은 다음과 같습니다.
- 평가(test) 데이터 셋에 대한 모델 성능 평가 기능을 제공합니다.
- CT(Continuous Training) 과정의 예측 성능을 추적합니다.
- 다양한 모델의 성능을 시각화하고 비교합니다.
- 설명가능한(explainable) 다양한 AI 기술을 사용하여 결과를 해석하는 기능을 제공합니다.
Model Serving
Model Serving은 프로덕션 환경으로 모델을 Serving하고 배포시킵니다. Model Serving의 주요 기능은 다음과 같습니다.
- 온라인 서빙(낮은 지연, 더 나아가 실시간 예측이 요구되는), 배치 서빙(많은 처리량이 요구되는)을 지원하는 기능을 제공합니다.
- 다양한 ML 서빙 프레임워크(TensorFlow Serving, TorchServe, NVIDIA Triton, Scikit-learn, XGBoost)를 지원합니다.
- 전처리, 후처리 기능을 더하거나 여러 모델이 계층적으로(혹은 동시에) 호출되어 결과를 집계하는 등의 복잡한 추론이 가능하도록 하는 기능을 제공합니다.
- 트래픽이 허용치를 갑자기 초과하는 것을 방지하고, 평상시 처리비용을 아끼기 위해 오토 스케일링(autoscaling)을 지원합니다.
- 예측 서비스 요청과 결과 응답에 대한 로깅을 지원합니다.
Online Experimentation
Online Experimentation은 새 모델과 기존 모델의 수행을 비교하여 새로운 모델이 어느정도 성능을 보일 것인지를 검증합니다. 이때, Online Experimentation은 Model Registry와 연동되어 새로운 모델 출시(배포)에 대한 결정을 용이하게 합니다(새로운 모델을 실제로 사용할 것인가?).
- canary 배포(구 버전의 모델과 새 버전의 모델들을 구성하고 일부 트래픽을 새 버전으로 분산하여 오류 여부를 판단하는 기법)를 지원합니다.
- 데이터 트레픽 분할 및 A/B 테스트 지원합니다.
- MAB(Multi-Armed Bandit) 테스트를 지원합니다.
Model Monitoring
Model Monitoring은 프로덕션 환경에 배포된 모델의 성능과 효율성 등을 추적하여 오래된 모델에 대한 업데이트가 필요한지 등을 검증합니다. Model Monitoring의 주요 기능은 다음과 같습니다.
- 지연시간 등과 같은 모델 효율성을 측정합니다.
- 데이터 왜곡, 스키마 이상, 데이터 Concept shift & drift 등을 감지합니다.
- 배포된 모델의 성능을 지속적으로 평가하기 위해 모니터링을 모델 평가 기능과 통합할 수 있습니다.
ML Pipeline
ML Pipeline은 복잡한 ML 학습 및 예측 파이프라인을 프로덕션 환경에서 구성하고, 조정하고, 자동화할 수 있도록 합니다. ML Pipeline의 주요 기능은 다음과 같습니다.
- 예약된 일정 혹은 지정된 이벤트를 trigger로 파이프라인을 동작시킵니다.
- ML Metadata and Artifact Tracking 기능과 통합하여 파이프라인 실행 파라미터를 포착하고 아티펙트를 생성합니다.
- 로컬 시스템, 클라우드 등 다양한 환경에서 실행가능합니다.
Model Registry
Model Registry를 통해 중앙 리포지토리에서 ML 모델의 수명주기(lifecycle)를 관리할 수 있습니다. Model Registry의 주요 기능은 다음과 같습니다.
- 학습/배포된 모델을 등록, 구성. 추적, 버전화합니다.
- (Model Evaluation과 통합하여)여러 지표를 기반으로 모델 출시 프로세스를 관리합니다(모델 검토, 승인, 배포, 롤백).
- 배포를 위해 모델 메타데이터 및 필요 패키지 등에 대한 정보를 저장합니다.
Dataset and Feature Repository
데이터 자산을 Dataset and Feature Repository로 통합하여 관리함으로써 공유/검색/재사용을 가능케 합니다. 또한 데이터 과학자들은 업무에 상당한 시간을 차지하는 데이터 준비 및 feature engineering에 소요되는 시간을 절약할 수 있습니다. Dataset and Feature Repository의 주요 기능은 다음과 같습니다.
- 데이터에 대한 공유/검색/재사용할 수 있으며, 버전 관리 기능을 지원합니다.
- 학습 및 추론 시 데이터 준비 및 feature enginnering에 소요되는 비용을 아낌으로써 이벤트 스트리밍과 온라인 서빙 등 낮은 지연시간을 필요로 하는 작업들을 가능케 합니다.
- 특정 시점 쿼리에 대한 feature 버전을 관리합니다.
- 표 데이터, 이미지, 텍스트 등 다양한 데이터 포멧을 지원합니다.
ML Metadata and Artifact Tracking
MLOps 수명주기 내 다양한 단계에서 기술 통계량, 학습된 모델, 평가 결과 등의 다양한 아티팩트가 생성됩니다. ML Metadata는 이런 아티팩트에 대한 위치, 유형, 속성, 실험 및 실행 등의 정보를 의미하며, 이를 통해 복잡한 ML 파이프라인을 재현하고 디버깅할 수 있게 합니다. ML Metadata and Artifact Tracking의 주요 기능은 다음과 같습니다.
- ML 아티펙트에 대한 저장/접근/조사/시각화/다운/보관 등의 히스토리 관리 기능을 제공합니다.
- 실험 및 파이프라인 파라미터의 구성을 추적하고 공유할 수 있습니다.
- 다른 MLOps 기능과의 통합을 제공합니다.
참고
