데이터베이스 개요
데이터베이스 개념
- 방대한 데이터를 효율적으로 관리하기 위해 컴퓨터에 통함-저장 한 것
- 특정 조직의 여러 사용자가 공유하여 사용할 수 있도록 통합해서 저장한 운영 데이터의 집합
- 데이터베이스 관리 시스템(DBMS)라는 프로그램을 이용하여 관리
데이터베이스에 저장된 데이터의 특징
1. 공유 데이터(Shared)
: 특정 조직의 여러 사용자가 함께 소유하고 이용할 수 있는 공용 데이터
2. 통합 데이터(Intergrated)
: 최소의 중복과 통제 가능한 중복만 허용하는 데이터
3. 저장 데이터(Stored)
: 컴퓨터가 접근할 수 있는 매체에 저장된 데이터
4. 운영 데이터(Operational)
: 조직의 주요 기능을 수행하기 위해 지속적으로 필요한 데이터
데이터베이스의 특징
1. 실시간 접근(Real-time accessibility)
: 사용자의 데이터 요구에 실시간으로 응답
2. 계속 변화(Continuous evolution)
: 데이터의 계속적인 삽입, 삭제, 수정을 통해 현재의 정확한 데이터를 유지
3. 동시 공유(Concurrent sharing)
: 서로 다른 데이터의 동시 사용뿐 아니라 같은 데이터의 동시 사용 지원
4. 내용 기반 참조(Content reference)
: 데이터가 저장된 주소나 위치가 아닌 내용으로 참조(ex. 성적이 70점 이상인 학생)
파일 처리 시스템
이전에는 응용 프로그램마다 필요한 데이터를 별도의 파일로 관리했음
- 파일 처리 시스템 : 데이터를 파일로 관리하기 위해 파일을 생성, 삭제, 수정, 검색하는 기능을 제공하는 소프트웨어
파일 처리 시스템의 문제점
- 데이터 중복성
- 같은 내용의 데이터가 여러 파일에 중복 저장될 수 있음
- 따라서 저장 공간의 낭비는 물론, 데이터의 일관성과 무결성을 유지하기 어려움
- 데이터 종속성
- 응용 프로그램이 데이터 파일에 종속적
- 따라서 사용하는 파일의 구조를 변경하면 응용프로그램도 함께 변경해야 함
- 데이터 파일에 대한 동시 공유, 보안, 회복 기능 부족
- 하나의 파일을 동시에 공유해서 사용하기 어렵고
- 누가 접근해서 사용하는지 보안 관리가 없으며
- 시스템 문제가 발생하여 파일의 내용이 사라져도 회복이 어려움
- 응용 프로그램 개발이 쉽지 않음
- 파일에 대한 처리 및 관리를 응용 프로그램에서 일부 해주어야 하므로 개발 자체가 쉽지 않음
데이터베이스 관리 시스템(DataBase Management System, DBMS)
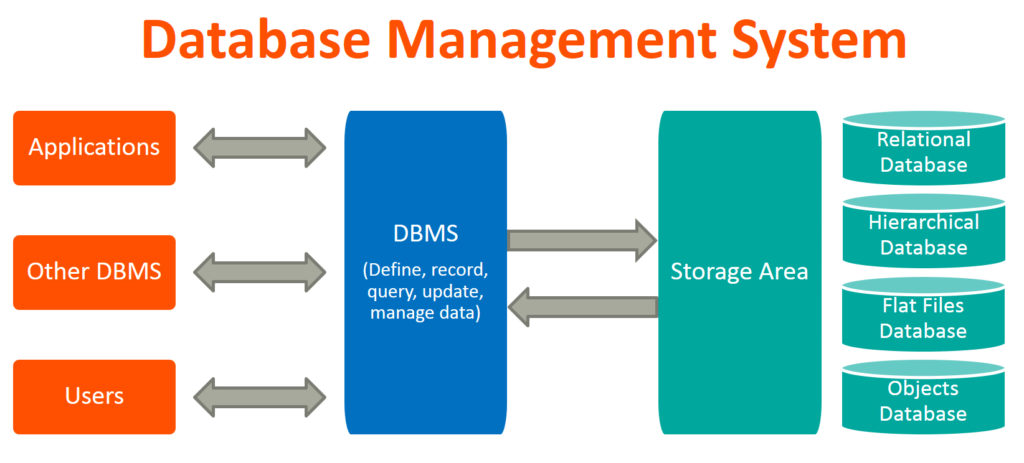
- 기존 파일 시스템의 무넺를 해결하기 위해 제시된 소프트웨어
- 조직에 필요한 데이터를 데이터베이스에 통합하여 저장하고 관리함
- 사용자와 응용 프로그램에 편리하고 효율적인 데이터베이스 사용환경을 제공하는 소프트웨어
데이터베이스 관리 시스템의 주요 기능
1. 정의 기능
: 데이터베이스 구조를 정의하거나 수정 가능
- 데이터 정의 언어(Data Definition Language, DDL) : 데이터 저장 구조, 데이터 접근 방법, 데이터 형식 등의 정의 가능
2. 조작 기능
: 데이터를 삽입, 삭제, 수정, 검색하는 연산 가능
- 데이터 조작 언어(Data Manipulation Language, DML) : 데이터베이스에 저장된 데이터를 검색, 수정, 삽입, 삭제할 떄 사용
3. 제거 기능
: 데이터를 항상 정확하고 안전하게 유지
- 데이터 제어 언어(Data Control Language, DCL) : 데이터베이스의 무결성 유지, 보안 및 접근 제어, 시스템 장애로부터의 복구, 병행 수행 제어 기능 등을 수행
데이터베이스 관리 시스템의 장점
- 데이터의 중복과 불일치 감소
- 데이터 독립성 확보 (파일시스템 등에 대해서)
- 데이터의 공유와 동시 접근이 가능
- 데이터의 보안 향상 (스토리지에 있는 데이터에 직접 접근하는 것이 아니라, DBMS를 거치고 접근)
- 데이터 무결성 향상
- 표준화 용이
- 시스템의 융통성 향상
- 응용 프로그램 개발 및 유지 비용 감소(데이터와 응용프로그램 개발을 분리)
- 사용자에게 더 나은 서비스 제공(보안 & 회복, …)
- 시스템 고장으로부터 데이터베이스 복구 가능
- 데이터 중심의 중앙 집중 관리
데이터 모델링
데이터 모델링이란
현실 세계에 존재하는 데이터를 컴퓨터 세계의 데이터베이스로 옮기는 변환 과정 (데이터베이스 설계의 핵심 과정)
- 개념적 데이터 모델 : 사람의 머리로 이해할 수 있도록 현실 세계를 개념적 모델링하여 데이터베이스의 개념적 구조로 표현하는 도구(ex. 개체-관계 모델)
- 논리적 데이터 모델 : 개념적 구조를 논리적 모델링하여 데이터베이스의 논리적 구조로 표현하는 도구(ex. 관계 데이터 모델)
개체-관계 모델(Entity-Relationship model, E-R model)
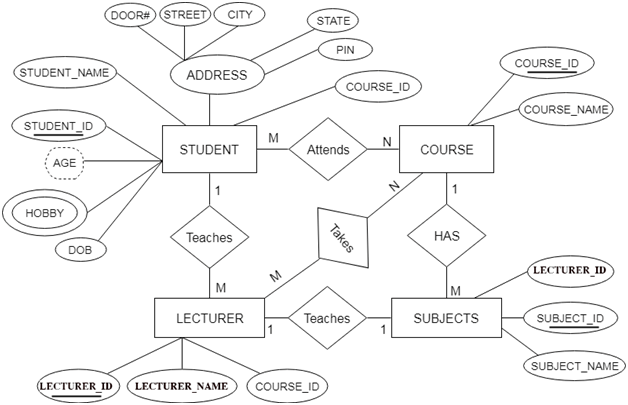
- 피터 첸(Peter Chen)이 제안한 개념적 데이터 모델
- 개체와 개체 간의 관계를 이용해 현실 세계를 개념적 구조로 표현
- 핵심 요소
- 개체(Entity)
- 현실 세계에서 사람이나 사물과 같이 구별되는 모든 것
- 저장할 가치가 있는 중요 데이터를 가지고 있는 사람이나 사물, 개념, 사건 등
- 다른 개체와 구별되는 이름을 가지고 있고, 각 개체만의 고유한 특성이나 상태. 즉, 속성을 하나 이상 가지고 있음.
- 속성(Attribute)
- 개체나 관계가 가지고 있는 고유의 특성
- 의미 있는 데이터의 가장 작은 논리적 단위
- 파일 구조의 필트(field)와 대응됨
- E-R 다이어그램에서 타원으로 표현하고, 타원 안에 이름을 표기
- 개체 타입(Entity Type)
- 개체를 고유의 이름과 속성들로 정의한 것
- 파일 구조의 레코드 타입(record type)에 대응됨
- 개체 인스턴스(Entity Instance)
- 개체를 구성하고 있는 속성이 실제 값을 가짐으로써 실체화된 개체
- entity occurrence라고도 함
- 파일 구조의 레코드 인스턴스(record instance)에 대응됨
- 개체 집합
- 특정 개체 타입에 대한 개체 인스턴스들을 모아놓은 것
- 개체(Entity)
- 개체-관계 다이어그램(E-R diagram) : 개체-관계 모델을 이용해 현실 세계를 개념적으로 모델링한 결과물을 그림으로 표현한 것
관계 데이터 모델
- 개념적 구조를 논리적 구조로 표현하는 논리적 데이터 모델
- 하나의 개체에 대한 데이터를 하나의 릴레이션에 저장
관계 데이터 모델 용어
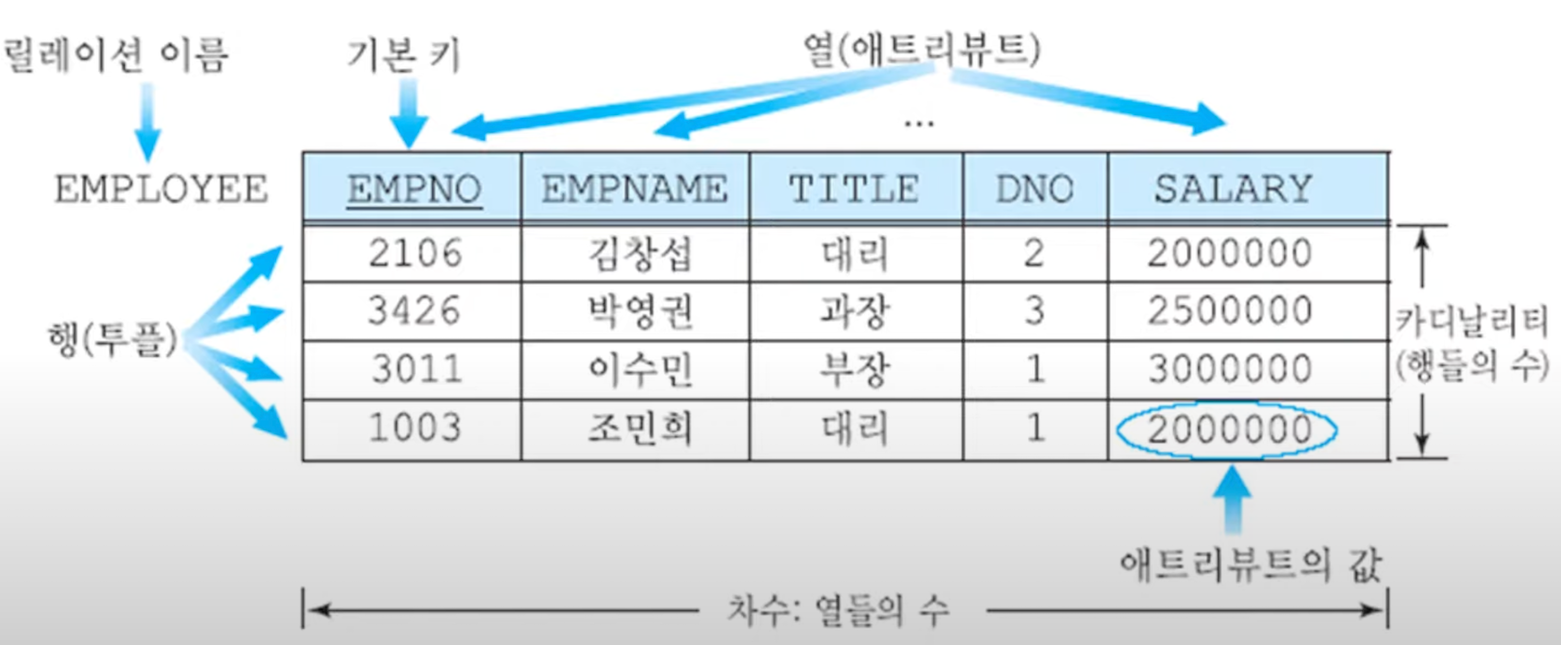
- 릴레이션(relation)
- 하나의 개체에 관한 데이터를 2차원 테이블의 구조로 저장한 것
- 파일 관리 시스템 관점에서 파일(file)에 대응
- 속성(attribute)
- 릴레이션의 열(애트리뷰트)
- 파일 관리 시스템 관점에서 필드(field)에 대응
- 튜플(tuple)
- 릴레이션의 행
- 파일 관리 시스템 관점에서 레코드(record)에 대응
- 도메인(domain)
- 하나의 속성이 가질 수 있는 모든 값의 집합
- 속성 값을 입력 및 수정할 때 적합성 판단의 기준이 됨
- 일반적으로 속성의 특성을 고려한 데이터 타입으로 정의
- 널(null)
- 속성 값을 아직 모르거나, 해당하는 값이 없음을 표현
- 차수(degree)
- 하나의 릴레이션에서 속성(열) 전체의 개수
- 카디널리티(Cardinality)
- 하나의 릴레이션에서 튜플(행)의 전체 개수
릴레이션 구성
- 릴레이션 스키마(relation schema)
-
릴레이션의 논리적 구조
-
릴레이션의 이름과 릴레이션에 포함된 몯느 속성 이름으로 정의
- ex) 고객(고객아이디, 이름, 나이, 등급, 직업, …)
-
릴레이션 내포(intension)라고도 함
-
정적인 특징이 있음
→ 릴레이션 스키마의 모음 = 데이터베이스 스키마
-
- 릴레이션 인스턴스(relation instance)
-
어느 한 시점에 릴레이션에 존재하는 튜플들의 집합
-
릴레이션 외연(relation extension)이라고도 함
-
동적인 특징이 있음
→ 릴레이션 인스턴스의 모음 = 데이터베이스 인스턴스
-
릴레이션 특성
- 튜플의 유일성
- 하나의 릴레이션에는 동일한 튜플이 존재할 수 없음
- 튜플의 무순서
- 하나의 릴레이션에서 튜플 사이의 순서는 무의미
- 속성의 무순서
- 하나의 릴레이션에서 속성의 순서는 무의미
- 속성의 원자성
- 속성 값으로 원자 값만 사용할 수 있음
키(key)
- 릴레이션에서 튜플들을 유일하게 구별하는 속성 또는 속성들의 집합
- 키의 특성
- 유일성(uniqueness) : 하나의 릴레이션에서 모든 튜플은 서로 다른 키 값을 가져야 함
- 최소성(minimality) : 꼭 필요한 최소한의 속성들로만 키를 구성
- 키의 종류
- 슈퍼 키(super key) : 유일성을 만족하는 속성 또는 속성들의 집합
- ex) 고객 릴레이션의 슈퍼키 : 고객 아이디, 고객 고유 번호, 고객 이름, … 등
- 후보 키(candidate key) : 유일성과 최소성을 만족하는 속성 또는 속성들의 집합
- ex) 고객 릴레이션의 슈퍼키 : 고객 아이디, 고객 고유 번호, … 등
- 기본 키(primary key) : 후보키 중에서 기본적으로 사용하기 위해 선택한 키
- ex) 고객 릴레이션의 슈퍼키 : 고객 아이디
- 대체 키(alternate key) : 기본키로 선택되지 못한 후보키
- ex) ex) 고객 릴레이션의 슈퍼키 : 고객 고유 번호
- 외래 키(foreign key) : 다른 릴레이션의 기본키를 참조하는 속성 또는 속성들의 집합 → 릴레이션들 간의 관계를 표현
- 슈퍼 키(super key) : 유일성을 만족하는 속성 또는 속성들의 집합
무결성 제약조건(integrity constraint)
: 데이터의 무결성을 보장하고 일관된 상태로 유지하기 위한 규칙 (무결성 : 데이터를 결함이 없는 상태. 즉, 정확하고 유효하게 유지하는 것)
- 개체 무결성 제약조건(entity integrity constraint)
- 기본키를 구성하는 모든 속성은 널(null) 값을 가질 수 없음
- 참조 무결성 제약조건(referential integrity constraint)
- 외래키는 참조할 수 없는 값을 가질 수 없는 규칙
관계 데이터 연산
- 관계 데이터 모델의 연산
- 원하는 데이터를 얻기 위해 릴레이션에 필요한 처리 요구를 수행하는 것
- 관계 대수 : 원하는 결과를 얻기 위해 데이터의 처리 과정을 순서대로 기술
- 관계 해석 : 원하는 결과를 얻기 위해 원하는 데이터가 무엇인지 기술
관계 대수(relational algebra)의 개념
- 절차 언어 : 원하는 결과를 얻기 위해 릴레이션의 처리 과정을 순서대로 기술하는 언어
- 폐쇄 특성(closure property) : 피연산도 릴레이션이고 연산의 결과도 릴레이션임
- 릴레이션 처리 연산자 : 일반 집합 연산자와 순수 관계 연산자로 분류
- 집합 연산자
- 합집합(union)
- 교집합(intersection)
- 차집합(difference)
- 카티션 프로덕트(cartesian product) :두 릴레이션의 조합 가능한 모든 경우의 수를 구하기 위한 집합 연산. 두 릴레이션에 속상 각 튜플들을 모두 연결하여 만들어진 새로운 튜플로 결과 릴레이션을 구성 → 집합 연산자는 피연산자가 2개 필요함 → 합집합, 교집합, 차집합은 두 릴레이션이 합병가능해야 함 → 합병가능 조건 : 1. 두 릴레이션의 차수가 같아야 함 2. 두 릴레이션에서 서로 대응되는 속성의 도메인이 같아야 함
- 관계 연산자
- 셀렉트(select) : 릴레이션 에서 조건을 만족하는 튜플들을 반환 (
릴레이션 where 조건식) - 프로젝트(project) : 릴레이션 에서 주어진 속성들의 값으로만 구성된 튜플들을 반환 (
릴레이션[속성1, …]) - 조인(join) : 공통 속성을 이용해 릴레이션 과 의 튜플들을 연결하여 만들어진 새로운 튜플들을 반환
- 디비전(division)() : 릴레이션 의 모든 튜플과 관련이 있는 릴레이션 의 튜플들을 반환
- 셀렉트(select) : 릴레이션 에서 조건을 만족하는 튜플들을 반환 (
- 집합 연산자
JOIN의 종류
- INNER JOIN
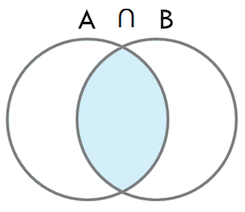
- 내부 조인은 2개의 릴레이션의 컬럼 값을 결합함하는 것으로, 마치 교집합 연산과 같음(양쪾 데이터 집합에서 공통적으로 존재하는 데이터만 조인)
- 내부 조인은 기본 조인 형식으로 간주된다.
- LEFT OUTER JOIN
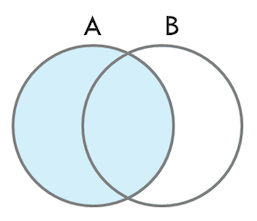
- LEFT OUTER JOIN은 조인 키 컬럼 값이 양쪽 릴레이션에서 공통적으로 존재하는 데이터와, 왼쪽 릴레이션에 명시된 테이블에만 존재하는 데이터를 결과로 추출하게 된다.
- RIGHT OUTER JOIN
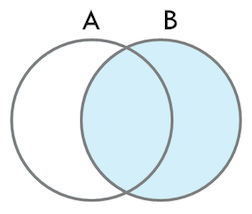
- RIGHT OUTER JOIN은 조인 키 컬럼 값이 양쪾 릴레이션에서 공통적으로 존재하는 데이터와, 오른쪽 릴레이션에 명시된 테이블에만 존재하는 데이터를 결과로 추출하게 된다.
- FULL OUTER JOIN
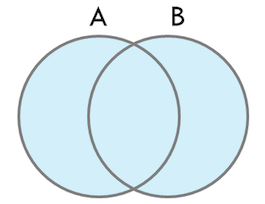
- FULL OUTER JOIN은 조인 키 컬럼 값이 양쪽 릴레이션에서 공통적으로 존재하는 데이터와, 한 쪽 릴레이션에만 존재하는 데이터도 모두 결과 데이터 집합으로 추출하게 된다.
관계 해석(relational calculus)
- 비절차 언어(nonprocedural language) : 처리를 원하는 데이터가 무엇인지만 기술하는 언어
- 수학의 프레디킷 해석(predicate calculus)에 기반을 두고 있음
- 분류
- 튜플 관계 해석(tuple relational calculus)
- 도메인 관계 해석(domain relational calculus)
SQL(Structured Query Language) 기본
- 관계형 데이터베이스의 조작과 관리에 사용되는 데이터베이스 질의용 언어
- 원하는 데이터가 무엇인지만 기술하는 비절차적 언어임
SQL 분류
- 데이터 정의어(DDL) : 테이블을 생성하고 변경-제거하는 기능을 제공
- 데이터 조작어(DML) : 테이블에 새 데이터를 삽입하거나, 테이블에 저장된 데이터를 수정-삭제-검색하는 기능을 제공
- 데이터 제어어(DCL) : 보안을 위해 데이터에 대한 접근 및 사용 권한을 사용자별로 부여하거나 취소하는 기능을 제공
데이터 정의어(DDL)
CREATE TABLE

- 테이블을 생성할 때 사용됨
- [ ]내용은 생략 가능
- SQL 질의문은 세미콜론(;)으로 문장의 끝을 표시
- SQL 질의문은 대소문자를 구분하지 않음(그
- CREATE TABLE문은 기본 제약사항, 기본키, 대체키, 외래키, 데이터 무결성을 위한 제약조건 정의를 포함
- 속성 데이터 타입
- INT(INTEGER) : 정수
- SMALLINT : INT보다 작은 정수
- CHAR(n) or CHARACTER(n) : 길이가 n인 고정 길이의 문자열
- VARCHAR(n) or CHARACTER VARYING(n) : 최대 길이가 n인 가변 길이의 문자열
- NUMERIC(p, s) or DECIMAL(p, s) : 고정 소수점 실수. p는 소수점을 제외한 전체 숫자의 길이 / s는 소수점 이하 숫자의 길이
- FLOAT(n) : 길이가 n인 부동 소수점 실수
- REAL : 부동 소수점 실수
- DATE : 연, 월, 일로 표현되는 날짜
- TIME : 시, 분, 초로 표현되는 시간
- DATETIME : 날짜와 시간
- 키의 정의
- PRIMARY KEY : 기본키를 지정하는 키워드
- ex) PRIMARY KEY (고객아이디)
- UNIQUE
- 대체키를 지정하는 키워드
- 대체키로 지정되는 속상의 값은 유일성을 가지며, 기본키와 달리 널(null) 값이 허용됨
- FOREIGN KEY
- 외래키가 어떤 테이블의 무슨 속성을 참조하는지 REFERENCES 키워드 다음에 제시
- 참조 무결성 제약조건 유지를 위해 참조되는 테이블에서 튜플 삭제 시 처리방법을 지정하는 옵션도 있음
- ON DELETE NO ACTION : 튜플을 삭제하지 못하게 함
- ON DELETE CASCADE : 관련 튜플을 함께 삭제
- ON DELETE SET NULL : 관련 튜플의 외래키 값을 NULL로 변경
- ON DELETE SET DEFAULT : 관련 튜플의 외래키 값을 기본 값을 ㅗ변경
- ex) FOREIGN KEY (소속부서) REFERENCES 부서 (부서번호) ON UPDATE CASCADE → 부서번호가 변경되면, 소속부서 외래키 값도 함께 변경됨
- PRIMARY KEY : 기본키를 지정하는 키워드
- 무결성 제약조건 정의(CHECK)
- 테이블에 정확하고 유효한 데이터를 유지하기 위해 특정 속성에 대한 제약조건을 지정
- CONSTRAINT 키워드와 함꼐 고유의 이름을 부여할 수도 있음
- ex) CHECK (재고량 >= 0)
- ex) CONSTRAINT CHK_CPY CHECK(제조업체=’오뚜기’) → CHK_CPY라는 이름으로 제약조건을 생성한 것임
ALTER TABLE
- 새로운 속성 추가

- 기존 속성 삭제

- 만약 삭제할 속성과 관련된 제약조건이 존재하면, 속성 삭제가 안 됨(관련된 제약조건을 먼저 삭제해야 함)
- 새로운 제약조건 추가

- 기존 제약조건 삭제

DROP TABLE
- 테이블 삭제

- 만약 삭제할 테이블을 참조하는 테이블이 있다면, 테이블 삭제가 수행되지 않음(관련된 외래키 제약조건을 먼저 삭제해야 함)
데이터 조작어(DML)
SELECT

- FROM 키워드와 함꼐 검색하고 싶은 속성이 있는 테이블의 이름을 나열
- ALL : 결과 테이블이 튜플의 중복을 허용하도록 지정(생략 가능)
- DISTINCT : 결과 테이블이 튜플의 중복을 허용하지 않도록 지정
- AS 키워드를 이용해 결과 테이블에서 속성의 이름을 바꾸어 출력 가능
- 새로운 이름에 공백에 포함되면 큰따옴표나 작은따옴표로 묶어주어야 함
- 생략 가능
- SELECT는 산술식을 이용한 검색이 가능
- SELECT 키워드와 함꼐 산술식 제시
- 속성의 값이 실제로 변경되는 것은 아니고, 결과 테이블에서만 계산된 값이 출력됨
- SELECT는 조건을 만족하는 데이터만 검색이 가능

- WHERE 키워드와 함께 비교 연산자와 논리 연산자를 이용한 검색 조건 제시
- 숫자뿐 아니라 문자나 날짜 값을 비교하는 것도 가능(문자나 날짜는 작은 따옴표로 묶어서 표현)
- LIKE 키워드를 이용해 부분적으로 일치하는 데이터를 검색할 수 있음
- % 기호 : 문자의 내용과 개수는 상관 없음
- _ 기호 : 문자의 내용은 상관 없음
- ex)
- LIKE ‘data%’ : data로 시작하는 문자열(길이 상관 x)
- LIKE ‘%data’ : data로 끝나는 문자열(길이 상관 x)
- LIKE’%data%’ : data가 포함된 문자열(길이 상관 x)
- LIKE’data____’ : data로 시작하는 8자리 문자열
- LIKE’____data’ : data로 끝나는 9자리 문자열
- IS NULL 혹은 IS NOT NULL 키워드를 통해 널 값을 비교할 수 있음
- 널 값은 다른 값과 크기를 비교할 순 없음
- 정렬 검색

- ORDER BY 키워드를 이용해 결과 테이블 내용을 사용자가 원하는 순서로 출력할 수 있음
- 오름차순(기본) : ASC / 내림차순 : DESC
- 집계 함수를 이용하여 검색을 할 수 있음(COUNT, MAX, MIN, SUM, AVG)
- 집계함수는 WHERE절에서는 사용할 수 없고, SELECT 절이나 HAVING 절에서만 사용 가능
- 그룹별 검색

- GROUP BY 키워드를 이용해 특정 속성의 값이 같은 튜플을 모아 그룹을 만들고, 그룹별로 검색
- GROUP BY 키워드로 그룹을 나누는 기준이 되는 속성을 지정
- HAVING 키워드로 그룹에 대한 조건을 작성
- 여러 테이블에 대한 조인 검색
- 조인 속성 : 조인 검색을 위해 테이블을 연결해주는 속성
- 연결하려는 테이블 간 조인 속성의 이름은 달라도 되지만, 도메인은 같아야 함
- 일반적으로 외래키를 조인 속성으로 이용함
- FROM절에 필요한 모든 테이블을 나열
- WHERE절에 조인 속성의 값이 같아야 함을 의미하는 조인 조건을 제시
- 조인 속성 : 조인 검색을 위해 테이블을 연결해주는 속성
- SELECT문 안에 또 다른 SELECT문을 포함하는 부속 질의문을 이용할 수 있음
- 상위(주) 질의문 : 다른 SELECT문을 포함하는 SELECT문
- 부속(서브) 질의문 : 다른 SELECT문 안에 들어 있는 SELECT문
- 부속 질의문은 괄호로 묶어서 작성되며 ORDER BY절을 사용할 수 없음
- 부속 질의문을 먼저 수행하고, 그 결과를 이용해 상위 질의문을 수행
- 부속질의문과 상의 질의문을 연결하는 연산자가 필요
- IN : 부속 질의문의 결과 값 중 일치하는 것이 있으면 검색 조건이 참
- NOT IN : 부속 질의문의 결과 값 중 일치하는 것이 없으면 검색 조건이 참
- EXISTS : 부속 질의문 결과 값이 하나라도 존재하면 검색 조건이 참
- NOT EXISTS : 하나라도 존재하지 않으면 검색 조건이 참
- ALL : 부속 질의문의 결과 값 모두와 비교한 결과가 참이면 검색 조건 만족(비교 연산자와 함께 사용)
- ANY 또는 SOME : 부속 질의문의 결과 값 중 하나라도 비교한 결과가 참이면 검색 조건 만족(비교 연산자와 함께 사용)
INSERT

- INTO 키워드와 함께 튜플을 삽입할 테이블의 이름과 속성의 이름을 나열
- 속성 리스트를 생략하면 테이블을 정의할 때 지정한 속성의 순서대로 값이 삽입됨
- 그러나, 웬만하면 속성 리스트를 지정해주는게 안전함
- VALUES 키워드와 함께 삽입할 속성 값들을 나열
- INTO절의 속성 이름과 VALUES절의 속성 값은 순서대로 일대일 대응되어야 함
- SELECT문을 이용해 다른 테이블에서 검색한 데이터를 삽입할 수도 있음

UPDATE

- 테이블에 저장된 튜플에서 특정 속성의 값을 수정할 때 사용
- SET 키워드 다음에 속성 값을 어떻게 수정할 것인지를 지정
- WHERE절에 제시된 조건을 만족하는 튜플에 대해서만 속성 값을 수정(❗️생략하면 모든 튜플을 대상으로 수정)
DELETE

- 테이블에 지정된 데이터를 삭제할 때 사용
- WHERE 절에 제시한 조건을 만족하는 튜플만 삭제(❗️생략하면 모든 튜플을 삭제해 빈 테이블이 됨)
뷰(VIEW)
- 뷰는 사용자에게 접근이 허용된 자료만을 제한적으로 보여주기 위해 하나 이상의 기본 테이블로부터 유도된, 이름을 가지는 가상 테이블임.
- 데이터를 실제로 저장하지 않고 논리적으로만 존재하는 테이블이지만, 일반 테이블과 동일한 방법으로 사용함
- 다른 뷰를 기반으로 새로운 뷰를 만드는 것도 가능함
- 뷰를 통해 기본 테이블의 내용을 쉽게 검색할 수는 있지만, 기본 테이블의 내용을 변화시키는 작업은 제한적으로 이루어짐
- 기본 테이블 : 뷰를 만드는 데 기반이 되는 물리적인 테이블
- 뷰의 장점
- 질의문을 좀 더 쉽게 작성 가능 → 미리 특정 뷰를 만들어놓고, 간단히 검색이 가능
- 데이터 보안 유지에 도움이 됨(제한된 자료만을 보여줌)
- 데이터를 좀 더 편리하게 관리 가능 → 제공된 뷰와 관련이 없는 다른 내용에 대해 사용자가 신경 쓸 필요가 없음
CREATE VIEW

- 뷰 생성
- CREATE VIEW 키워드와 함께 생성할 뷰의 이름과 뷰를 구성하는 속성의 이름을 나열
- AS 키워드와 함께 기본 테이블에 대한 SELECT문 작성
- WITH CHECK OPTION : 뷰에 삽입이나 수정 연산을 할 떄 SELECT문에서 제시한 뷰의 정의 조건을 위반하면 수행되지 않도록 하는 제약조건을 지정
SELECT VIEW
- SELECT VIEW로는 일반 테이블과 같은 방법으로 원하는 데이터를 검색할 수 있음
- 뷰에 대한 SELECT문이 내부적으로 기본 테이블에 대한 SELECT문으로 변환되어 수행함
INSERT, UPDATE, DELETE VIEW
- 뷰에 대한 삽입-수정-삭제 연산은 실제로 기본 테이블에 수행되므로 결과적으로 기본 테이블이 변경됨
- 따라서 뷰에 대한 삽입-수정-삭제 연산은 제한적으로 수행됨(변경 불가능한 뷰)
- 변경 불가능한 뷰의 특징
- 기본 테이블의 기본키를 구성하는 속성이 포함되어 있지 않은 뷰
- 기본 테이블에 있던 내용이 아닌 집계 함수로 새로 계산된 내용을 포함하는 뷰
- DISTICNT 키워드를 포함하여 정의한 뷰
- GROUP BY 절을 포함하여 정의한 뷰
- 여러 개의 테이블을 조인하여 정의한 뷰는 변경이 불가능한 경우가 많음
DROP VIEW

- 뷰를 삭제해도 기본 테이블은 영향을 받지 않음
- 만약, 삭제할 뷰를 참조하는 제약 조건이 존재하면, 뷰 삭제가 수행되지 않음(제약 조건을 먼저 삭제해야 함)
데이터베이스 발전과 종류
1세대 : 계층 DBMS, 네트워크 DBMS
- 계층 DBMS : 데이터베이스를 트리형태로 구성한 것
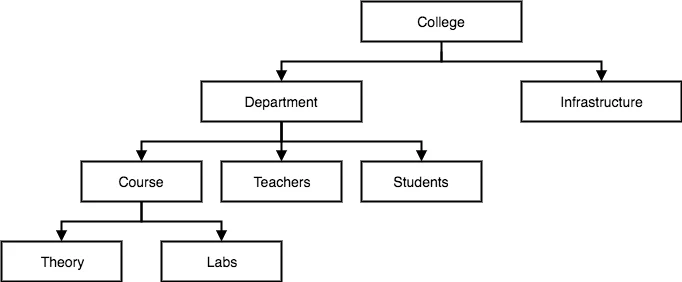
- ex) IMS(Information Management System)
- 네트워크 DBMS : 데이터베이스를 그래프 형태로 구성한 것
- ex) IDS(Intergrated Data Store)
2세대 : 관계 DBMS
- 관계 DBMS : 데이터베이스를 테이블 형태로 구성
- ex) 오라클, MySQL, 액세스(Access), ….
3세대 : 객체 지향 DBMS, 객체 관계 DBMS

- 객체지향 DBMS : 객체를 이용해 데이터베이스를 구성
- ex) 오투(O2), 젬스톤(GemStone), …
- 객체관계 DBMS ; 객체 DBMS + 관계 DBMS
4세대 : NoSQL
- NoSQL : 비정형 데이터를 처리하는 데 적합하고 확장성이 뛰어난 데이터베이스
- 안정성과 일관성 유지를 위한 복잡한 기능을 포기
- 데이터 구조를 미리 정해두지 않는 유연성
- 확장성이 뛰어나 여러 대의 서버 컴퓨터에 데이터를 분산하여 저장하고 처리하는 환경에서 주로 사용
- ex) MongoDB, HBase, Cassandra, Redis, ….
- 배경 및 장점
- 관계 데이터베이스를 대신할 새로운 대안의 필요성
- 정형화된 데이터를 주로 처리하는 관계 데이터베이스는 빠른 속도로 대량 생산되는 다양한 유형의 비정형 데이터를 저장 및 관리하는데 적합하지 않음
- 단일 컴퓨터 환경에서 주로 사용되는 관계 데이터베이스는 확장성 측면에서 비효율적임
- 빠른 속도로 생성되는 대량의 비정형 데이터를 저장하고 처리하기 위해 ACID(원자성, 일관성, 격지성, 지속성)를 위한 트랜잭션 기능을 제공하지 않는 대신 저렴한 비용으로 여러 대의 컴퓨터에 데이터를 분산-처리-저장하는 것이 가능한 데이터베이스
- 스키마 없이 동작하기 떄문에 데이터 구조를 미리 정의할 필요가 없고 수시로 그 구조를 바꿀 수 있어 비정형 데이터를 저장하기에 적합
- 대부분 오픈 소스로 제공
RDBMS vs NoSQL
| 구분 | 관계 데이터베이스 | NoSQL |
|---|---|---|
| 처리 데이터 | 정형 데이터 | 정형 데이터, 반정형 데이터, 비정형 데이터 |
| 대용량 데이터 | 대용량 처리 시 성능 저하 | 대용량 데이터 처리 지원 |
| 스키마 | 미리 정해진 스키마 존재 | 스키마가 없거나 변경이 자유로움 |
| 트랜잭션 | 트랜잭션을 통해 일관성 유지를 보장 | 트랜잭션을 지원하지 않아 일관성 유지를 보장하기 어려움 |
| 검색 기능 | 조인 등의 복잡한 검색 기능 제공 | 단순한 데이터 검색 기능 제공 |
| 확장성 | 클러스터 환경에 적합하지 않음 | 클러스터 환경에 적합 |
| 라이선스 | 고가의 라이선스 비용 | 오픈 소스 |
| 예시 | Oracle, MySQL, MS SQL 서버, … | Cassandra, MongoDB, HBase, … |
NoSQL 종류
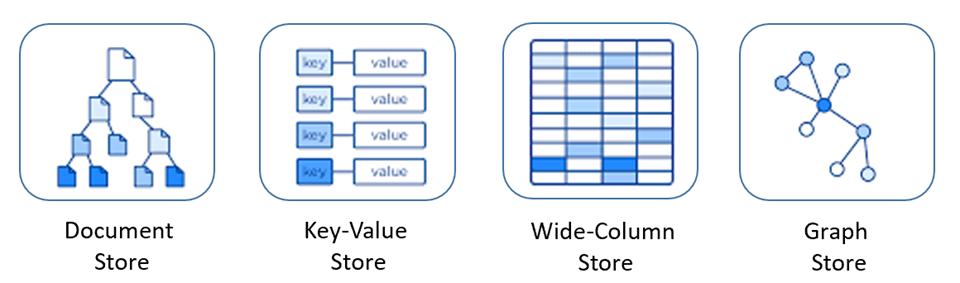
- key-value store(kvs) : 다수의 키와 값을 관련지어 저장하는 데이터베이스
- ex) Riak, Redis, …
- document store : JSON과 같은 복잡한 데이터 구조를 저장하는 데이터베이스
- ex) MongoDB, CouchDB, …
- wide-column store : 여러 키를 사용하여 높은 확장성을 제공하는 데이터베이스
- ex) Cassandra, …
- graph-based store : 노드에 데이터를 저장하고 간선으로 데이터 간 관계를 표현하는 그래프 형태
- ex) Neo4J, OrientDB, …
Reference
