자바, MySQL, Redis를 활용한 동시성 제어🚀
최근 자바 애플리케이션에서 발생할 수 있는 동시성 이슈를 해결하기 위해 다양한 방법을 실습해보는 시간을 가졌습니다. 이번 포스팅에서는 다음과 같은 방식으로 동시성 제어를 시도해보고, 각 방법이 실제로 어떻게 작동하며 어떤 상황에 유용한지 살펴보겠습니다.
이 포스팅은 테스트의 성능이나 락, 내부동작의 상세한 내용 보다는 전략 위주로 포스팅 하였습니다.
- 자바 레벨 동시성 제어(
synchronized,Atomic클래스) - MySQL을 이용한 비관적 락(Pessimistic Lock) / 낙관적 락(Optimistic Lock)
- Redis를 이용한 분산 락(Distributed Lock)
직접 구현하고 테스트를 해보도록 하겠습니다. => 동시성 제어 연습장 레포 <=
1. 자바를 이용한 동시성 제어 🤖
가장 기본적인 접근 방법은 자바 레벨에서 synchronized나 원자적 연산(Atomic Classes)을 활용하는 것입니다.
코드 예시: Product 엔티티
@Entity
public class Product {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private AtomicLong atomicQuantity = new AtomicLong(0);
@Version
private Long quantity;
public Product() {}
public Product(Long id, Long quantity) {
this.id = id;
this.quantity = quantity;
}
public Product(Long quantity) {
this.quantity = quantity;
}
public Long getId() {
return id;
}
public Long getQuantity() {
return this.quantity;
}
public Long getAtomicQuantity() {
return this.atomicQuantity.longValue();
}
public void increment() {
quantity++;
}
//synchronized 키워드를 통해 해당 메소드에 락을 걸어 동시성 문제를 해결
public synchronized void syncIncrement() {
quantity++;
}
//현재 인스턴스를 synchronized블록을 통해 락을 걸어 동시성 문제를 해결
public void syncBlockIncrement() {
synchronized(this){
quantity++;
}
}
//Atomic클래스를 이용할 경우 CAS(Compare And Swap) 연산을 통해 동시성 문제를 해결
public void atomicIncrement() {
atomicQuantity.incrementAndGet();
}
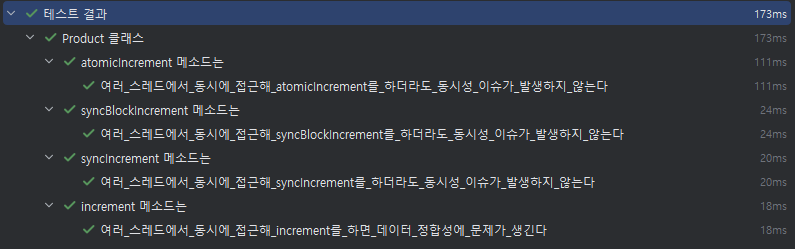
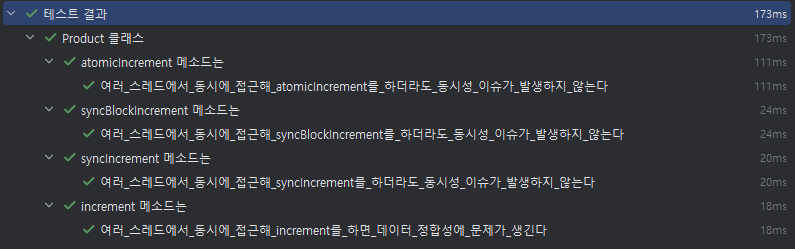
}여기서 increment() 메서드는 아무런 동기화 장치가 없기 때문에 멀티 스레드 상황에서 Race Condition이 발생할 수 있습니다. 반면 syncIncrement(), syncBlockIncrement(), atomicIncrement()는 각각 다른 방식으로 동시 접근을 제어해서 동시성 문제를 예방합니다.
테스트 코드 및 결과
아래는 100개 스레드가 동시에 increment()를 호출하는 상황을 시뮬레이션한 테스트 코드입니다. 동기화가 없는 increment()는 기대하는 결과를 얻지 못하지만, 나머지 세 가지는 정확한 결과를 보여줍니다. 밑에는 테스트 코드 예시 입니다.
@DisplayName("Product 클래스")
public class ProductTest {
@Nested
@DisplayName("increment 메소드는")
class Increment_quantity {
@Test
@DisplayName("여러_스레드에서_동시에_접근해_increment를_하면_데이터_정합성에_문제가_생긴다")
public void 여러_스레드에서_동시에_접근해_increment를_하면_데이터_정합성에_문제가_생긴다() throws InterruptedException {
Product product = new Product(1L, 0L);
long expectQuantity = 100;
int threadCount = 100;
ExecutorService executorService = Executors.newFixedThreadPool(32);
CountDownLatch latch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
executorService.submit(() -> {
try {
product.increment();
} finally {
latch.countDown();
}
});
}
latch.await();
assertNotEquals(product.getQuantity(), expectQuantity);
}
}
}
결과적으로, 자바 레벨에서의 동기화는 단일 인스턴스 내의 멀티 스레드 경쟁 상황을 간단하게 해결할 수 있습니다. 하지만 서비스 규모가 커지거나 DB를 다뤄야 할 경우, 더 복잡한 방식이 필요할 수 있습니다.
2. DB 레벨 동시성 제어 🗄️
비관적 락 (Pessimistic Lock) 🔒
비관적 락은 트랜잭션 시작 시점에 해당 레코드를 선점(Lock)하는 방식입니다. 이를 위해 JPA에서는 @Lock(LockModeType.PESSIMISTIC_WRITE)를 활용할 수 있습니다.
Repository 예시:
@Repository
public interface JpaProductRepository extends JpaRepository<Product,Long> {
@Lock(value = LockModeType.PESSIMISTIC_WRITE)
@Query("select p from Product p where p.id = :id")
Product findByIdWithPessimistic(Long id);
}Service 예시:
@Service
public class ProductService {
private final ProductRepository productRepository;
// 비관적 락으로 상품을 가져와 increment
@Transactional
public void pessimisticIncrement(Long productId) {
Product product = productRepository.findByIdWithPessimistic(productId);
product.increment();
productRepository.save(product);
}
}테스트 코드 및 결과
@SpringBootTest
@DisplayName("ProductService 클래스")
public class ProductServiceTest {
@Autowired
private ProductService productService;
@Nested
@DisplayName("pessimisticIncrement 메소드는")
class pessimistic_increment {
@Test
@DisplayName("여러_스레드에서_동시에_접근해_pessimisticIncrement를_하더라도_동시성_이슈가_발생하지_않는다")
public void 여러_스레드에서_동시에_접근해_pessimisticIncrement를_하더라도_동시성_이슈가_발생하지_않는다() throws InterruptedException {
Long productId = productService.save(0L);
long expectedQuantity = 100;
int threadCount = 100;
ExecutorService executorService = Executors.newFixedThreadPool(32);
CountDownLatch latch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
executorService.submit(() -> {
try {
productService.pessimisticIncrement(productId);
} finally {
latch.countDown();
}
});
}
latch.await();
assertEquals(productService.getProduct(productId).getQuantity(), expectedQuantity);
}
}
}
이렇게 비관적 락을 사용하면 충돌 시점에 다른 트랜잭션이 대기하게 되어 정합성을 보장할 수 있습니다. 하지만 자원 점유 시간이 길어질 수 있으므로, 충돌이 빈번한 경우에만 유용합니다.
낙관적 락 (Optimistic Lock) + 재시도(Spin Lock) 🤼
낙관적 락은 충돌이 자주 일어나지 않는 상황에 유용합니다. @Version 필드로 버전을 관리하고, 충돌 발생 시 예외를 던져 재시도하는 방식입니다.
Repository 예시:
@Repository
public interface JpaProductRepository extends JpaRepository<Product,Long> {
@Lock(value = LockModeType.OPTIMISTIC)
@Query("select p from Product p where p.id = :id")
Product findByIdWithOptimistic(Long id);
}Service 예시:
@Transactional
public void optimisticIncrement(Long productId) {
Product product = productRepository.findByIdWithOptimistic(productId);
product.increment();
productRepository.save(product);
}재시도 로직 (Spin Lock) UseCase 예시:
@Service
public class OptimisticIncrementUseCase {
private final ProductService productService;
OptimisticIncrementUseCase(ProductService productService) {
this.productService = productService;
}
public void execute(Long id) throws InterruptedException {
while(true) {
try {
productService.optimisticIncrement(id);
break;
}
catch (ObjectOptimisticLockingFailureException optimisticLockException) {
Thread.sleep(30);
}
catch (Exception e){
break;
}
}
}
}테스트 코드 및 결과
@SpringBootTest
@DisplayName("OptimisticIncrementUseCase 클래스")
public class OptimisticIncrementUseCaseTest {
@Autowired
private ProductService productService;
@Autowired
private OptimisticIncrementUseCase optimisticIncrementUseCase;
@Nested
@DisplayName("execute 메소드는")
class Execute {
@Test
@DisplayName("여러_스레드에서_동시에_접근해_execute를_하더라도_동시성_이슈가_발생하지_않는다")
public void 여러_스레드에서_동시에_접근해_execute를_하더라도_동시성_이슈가_발생하지_않는다() throws InterruptedException {
Long productId = productService.save(0L);
long expectedQuantity = 100;
int threadCount = 100;
ExecutorService executorService = Executors.newFixedThreadPool(32);
CountDownLatch latch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
executorService.submit(() -> {
try {
optimisticIncrementUseCase.execute(productId);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
latch.countDown();
}
});
}
latch.await();
assertEquals(productService.getProduct(productId).getQuantity(), expectedQuantity);
}
}
}
낙관적 락은 충돌 상황에서만 재시도 로직이 동작하므로, 충돌이 적은 상황에서 더 효율적입니다.
3. Redis 분산 락(Distributed Lock) 🌐
멀티 인스턴스(멀티 서버) 환경에서는 자바나 DB 락만으로는 동시성 제어가 어렵습니다. 이 때 Redis를 이용하면 간단한 분산 락 구현이 가능합니다.
Redis Lock Repository 예시:
@Repository
public class RedisLockRepositoryImpl implements RedisLockRepository {
private final RedisTemplate<String, String> redisTemplate;
public Boolean acquireLock(String key) {
return redisTemplate.opsForValue().setIfAbsent(key, "gift", Duration.ofMillis(2000));
}
public void releaseLock(String key) {
redisTemplate.delete(key);
}
}SET key value NX EX 명령을 통해 해당 키에 대해 한번에 하나의 클라이언트만 점유할 수 있도록 합니다. NX(키 존재 안할 때만 SET), EX(유효시간 설정) 옵션을 사용하여 데드락을 방지합니다.
UseCase 예시:
@Service
public class ProductRedisLockUseCase {
private final RedisLockService redisLockService;
private final ProductService productService;
public void execute(Long productId) {
boolean lock = false;
while(true) {
try {
lock = redisLockService.acquireLock(productId);
if (lock) {
productService.increment(productId);
break;
} else {
Thread.sleep(30);
}
} catch (Exception e) {
break;
}
}
if (lock) redisLockService.releaseLock(productId);
}
}테스트 코드 및 결과
@SpringBootTest
@DisplayName("ProductRedisLockUseCaseTest 클래스")
public class ProductRedisLockUseCaseTest {
@Autowired
private ProductService productService;
@Autowired
private ProductRedisLockUseCase productRedisLockUseCase;
@Nested
@DisplayName("execute 메소드는")
class Execute {
@Test
@DisplayName("여러_스레드에서_동시에_접근해_execute를_하더라도_동시성_이슈가_발생하지_않는다")
public void 여러_스레드에서_동시에_접근해_execute를_하더라도_동시성_이슈가_발생하지_않는다() throws InterruptedException {
Long productId = productService.save(0L);
long expectedQuantity = 100;
int threadCount = 100;
ExecutorService executorService = Executors.newFixedThreadPool(32);
CountDownLatch latch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
executorService.submit(() -> {
try {
productRedisLockUseCase.execute(productId);
} finally {
latch.countDown();
}
});
}
latch.await();
assertEquals(productService.getProduct(productId).getQuantity(), expectedQuantity);
}
}
}
Redis를 통해 멀티 인스턴스 환경에서도 하나의 자원(상품)에 대해 단일 접근을 보장할 수 있습니다.
정리 💡
- 자바 레벨 동기화: 단일 인스턴스 내 멀티 스레드 환경에서 간단히 동시성 제어 가능.
- DB 비관적/낙관적 락: 트랜잭션 단위로 레코드 잠금 혹은 낙관적 재시도 전략을 통해 데이터 정합성 보장.
- Redis 분산 락: 멀티 서버 환경에서 공용 자원에 대한 단일 접근 보장.
각 전략은 상황에 따라 장단점이 다릅니다. 트래픽 패턴, 충돌 빈도, 시스템 아키텍처 등을 고려해 적절한 락 전략을 선택하는 것이 중요합니다. 이 모든 과정을 테스트 코드로 검증하며, 실제 운용 환경에 적용하기 전에 충분히 실험하는 것이 핵심입니다.
이외에도 자바 레벨에서 Lock을 이용한다던가 Redisson라이브러리의 RLock을 이용해 Pub/Sub기반의 잠금을 하는 방식 등 더 많은 전략이 있으니 상황에 맞게 사용하면 될 것 같습니다.
느낀점
개발을 공부하면 서 느끼는 점은 사용되는 전략들이 어느정도 서로 닮아있다는 점 입니다. 실제 하드웨어의 속도면의 성능을 높여주는 레지스터 => 캐시 메모리 => 주 메모리 => 디스크 처럼 계층형으로 데이터를 찾게 되는데 어플리케이션 레벨이나 디비에서도 비슷한 전략들을 사용하여 구현이 되는 것 도 있는것 처럼 이번 동시성 제어를 실습할때도 비슷한 구현의 연속이였던 것 같습니다. 몇까지 꼽자면
- 자바 레벨에서 Atomic클래스의 경우에서 CAS연산과 낙관적 락의 version을 비교하는 부분과 스핀락을 통해 계속해서 성공을 시도하는것
- synchronized와 비관적 락의 뮤텍스 잠금과 대기큐
이러한 부분들이 닮았다고 느껴졌고 흥미로웠던 것 같습니다.
