카프카란?
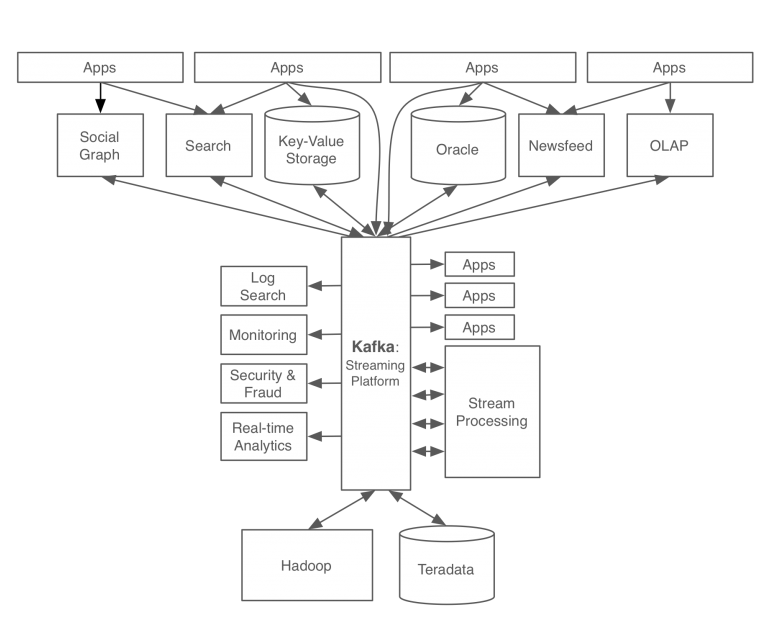
카프카를 개발 후 링크드인의 데이터 처리 시스템
카프카를 적용함으로서 모든 이벤트/데이터의 흐름을 중앙에서 관리할 수 있게 되었고
서비스 아키텍처가 기존에 비해 관리하기 심플해졌다.
Publish/Subscribe 시스템
카프카는 Publish-Subscribe모델을 구현한 분산 메시징 시스템이다.
Publish-Subscribe모델은
- 데이터를 만들어내는 프로듀서(Producer, 생산자)
- 소비하는 컨슈머 (Consumer, 소비자)
- 둘 사이에서 중재자 역할을 하는 브로커 (Broker)
로 구성된 느슨한 결합(Loosely Coupled) 시스템이다.
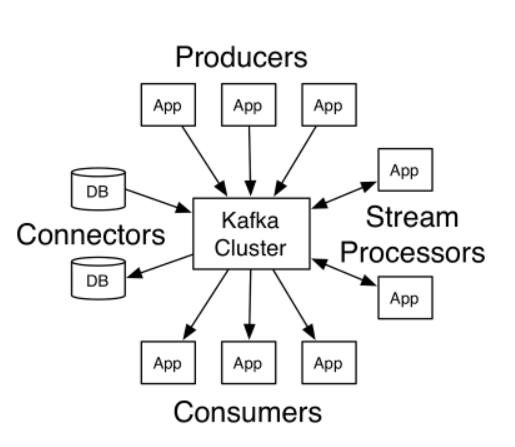
카프카 클러스터로 메세지를 전송할 수 있는 프로듀서와 카프카로부터 메세지를 읽어 갈 수 있는 컨슈머 클라이언트 API를 제공한다.
카프카에서
프로듀서는 특정 토픽(Topic)으로 메세지를 발행할 수 있다.컨슈머역시 특정 토픽의 메세지를 읽어 갈 수 있다.토픽은 프로듀서와 컨슈머가 만나는 지점으로 생각 할 수 있다.
다시 말하면, 메세지를 논리적으로 묶은 개념이다. (데이터베이스의 테이블 / 파일시스템의 폴더와 유사한 개념)
아파치 주키퍼란? (Apache Zookeeper)
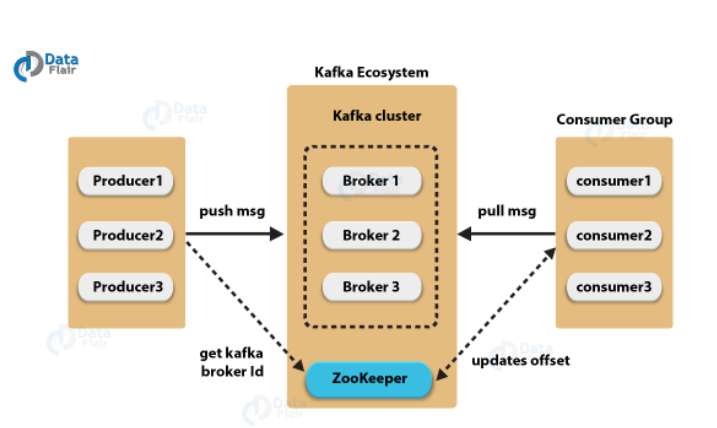
카프카는 수평적인 확장을 위해 클러스트를 구성한다.
카프카를 통해 유통되는 메세지가 늘어나면 브러커의 부담이 증가하게 되어 클러스터의 규모를 확장할 필요가 있다. 카프카는 여러 브로커들의 클러스터링을 위해 아파치 주키퍼를 사용한다.
주키퍼 사용으로 브로커의 추가 및 장애 상황을 간단하게 대응할 수 있다.
카프카 아키텍처
다시한번 구성을 정리해보자
프로듀서
- 메세지를 생산하여 브로커의 토픽으로 전달하는 역할
브로커
- 카프카 애플리케이션에 설치되어 있는 서버 또는 노드를 지칭
컨슈머
- 브로커의 토픽으로부터 저장된 메세지를 받는 역할
주키퍼
- 분산 애플리케이션 관리를 위한 코디네이션 시스템
- 분산된 노드의 정보를 중앙에 집중하고 구성관리, 그룹 네이밍, 동기화 등의 서비스 수행
작동방식
- 프로듀서는 새 메세지를 카프카에 전달
- 전달된 메세지는 브로커의 토픽이라는 메세지 구분자에 저장
- 컨슈머는 구독한 토픽에 접근하여 메세지를 가져옴
카프카 특징
-
다중 프로듀서, 다중 컨슈머
- 하나의 카프카 시스템을 통해 다양한 애플리케이션이 데이터를 주고 받을 수 있게 되었고 데이터의 생산자/소비자 관계도 유연하게 구성할 수 있다.
-
파일 시스템에 저장
- 프로듀서가 생성한 메세지를 브로커가 위치한 서버의 파일 시스템에 저장한다. 따라서 컨슈머는 프로듀서가 생성한 메세지를 바로바로 소비하지 않아도 되며 카프카가 메세지를 보존하고 있는 기간내에서 언제든지 읽어 갈 수 있다.
또한, 컨슈머들이 데이터를 모았다가 처리하는 배치(batch)처리를 가능하게 해주며, 컨슈머 쪽에서 에러가 생겼을 때 이전에 읽었던 데이터를 다시 읽을 수 있게 해준다.
카프카 브로커가 파일 시스템에 저장한 메세지는 관리자에 의해 설정된 일정 보존 기간동안 사용 가능하며 이후 브로커가 위치한 서버의 파일 시스템에서 삭제된다. -
확장성 및 분산형 스트리밍 플랫폼
- 시스템 트래픽이 높아지면 브로커를 추가해서 클러스터를 확장할 수 있다. 이른바 수평적인 확장이 쉽게 이루어진다.
- 일부 노드가 죽더라도 다른 노드가 해당 일을 지속한다. (고가용성) -
고성능 및 페이지 캐시
- 대용량 실시간 로그 처리에 특화되어 있다.
- 카프카는 잔여 메모리를 이용해 디스크 read/write을 하지 않고 페이지 캐시를 통한 read/write으로 인해 처리 속도가 매우 빠르다.
참고
