![]()
ImageNet Classification with Deep Convolutional Neural Networks 논문을 읽은 내용을 정리해보려고합니다.
논문을 번역하면서 요약 정리하는 concept이지만, 내용을 정리하기 위해서 중간중간 제가 정리한 내용도 들어갑니다.
혹시나 틀린 부분이 있다면 댓글로 알려주시면 감사하겠습니다 :)
그리고 정리 편의상 평어체로 서술했으니 양해바랍니다!^.^
Introduction
본 논문에서 사용된 Cnn Architecture는 ILSVRC-2010, ILSVRC-2012에서 제일 좋은 결과를 달성했다.
The Dataset
Imagenet에 대한 데이터 설명이 있는데, 중요한 내용이 없으니 아래 일부만 언급하고 넘어간다.
ImageNet data셋은 여러 해상도의 이미지로 구성되어 있는데, 해당 모델은 일정한 해상도의 입력을 요구한다. 따라서, 이미지의 해상도를 256X256으로 downsampling 했다.
The Architecture
저자가 생각하는 모델 성능의 기여도가 높은 순으로 작성되어있다. 저자는 Relu > Multi GPUs > LRN > OverLapping Polling 순으로 중요하다고 생각한다..
ReLU Nonlinearity
ReLU activation function에 관한 설명이 첨부된 section이다.
지금이야 activation function의 default가 ReLU이지만, 해당 논문이 발표될 당시만 해도 tanh, sigmoid activation function이 주력으로 사용되었다고 한다.
지금은 대부분 activation function으로 ReLU를 사용하고 있으니, ReLU의 대중화를 이끈 셈이다.
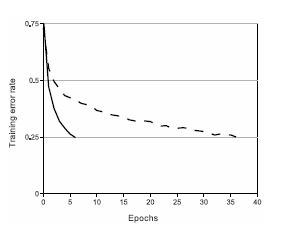
ReLU는 Training time 측면에서 tanh에 비해서 큰 이점을 가진다.
위의 그림에서 처럼 CIFAR-10 dataset에서 error rate 25%에 도달하기 까지 tanh에 비해 약 6배 가량 빠른 학습속도를 보여줬다.
Training on Multiple GPUs
gpu를 병렬적으로 학습하는 부분에 대해서 설명한다.
해당 논문에서는 3gb 메모리를 가진 GTX 580 GPU를 사용했다. 120만 train image를 학습하기에는 해당 gpu로는 감당이 안되어서, GTX 580 2장을 병렬로 구성했다.
각 gpu에는 커널의 절반이 할당되는 방식으로 학습이 진행되는데, 여기에 한가지 trick이 존재한다. GPU의 상호연결이 특정 layer에서만 이루어진다는 점이다.
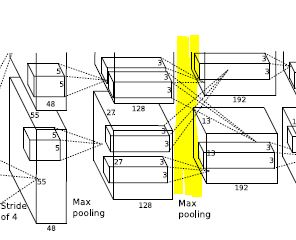
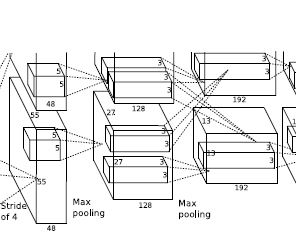
위 이미지는 AlexNet model의 일부분이다.
보면 2번째 layer의 입력은 1번째 layer 각각의 입력에서 받아오지만 3번째 layer는 2번째 layer의 다른 gpu에서도 입력을 받는 것을 확인할 수 있다.(형광색 부분)
gpu의 병렬적 사용으로 인해서 top-1, top-5 error_rate를 각각 1.7%, 1.2% 줄일 수 있었다.
현재는 잘 사용되지 않는다.
Local Response Normalization
Local Response Normalization는 실제 뉴런에서 발생되는 '측면억제(lateral inhibition)'의 한 형태에서 영감을 받아 구현한 것이다.
측면 억제는 신경생리학 용어로, 한 영역에 있는 신경 세포가 상호 간 연결되어 있을 때 한 그 자신의 축색이나 자신과 이웃 신경세포를 매개하는 중간신경세포를 통해 이웃에 있는 신경 세포를 억제하려는 경향이다. 즉, 신경세포들이 흥분하게 되면 옆에 있는 이웃 신경세포에 억제성 신경전달물질을 전달하여, 이웃 신경 세포가 덜 활성화되도록 만드는 것이다.(위키백과:https://ko.wikipedia.org/wiki/%EC%B8%A1%EB%A9%B4_%EC%96%B5%EC%A0%9C)
이와 같은 상황이 ReLU를 적용했을 때도 나타난다.
ReLU는 max(a,0)과 같은 형태인데, 양수 방향의 값은 그대로 사용하기 때문에 특정 activation map의 한 pixel 값이 엄청나게 크다면 주변의 pixel도 영향을 받게 된다. 위의 bold체와 비슷한 상황이다. 한 pixel이 흥분하게 되어서 이웃 pixel을 덜 활성화되게 하는 상황이라고 볼 수 있다.(해당 사항은 신경생리학 요소가 들어가 있기 때문에 정확한 표현이 아닐 수 있으며, 이해를 돕기 위함입니다. )
이를 해결하기 위해 다른 activation map의 같은 위치에 있는 픽셀끼리 정규화하는 방식인 LRN이 사용된다.
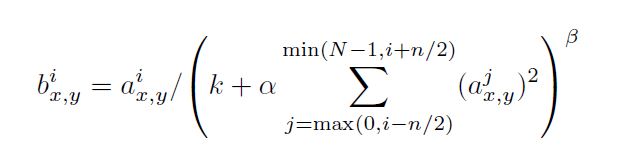
위는 LRN 식이다.
k,n,α,β가 논문에서는 k=2, n=5, α=10^-4, β=0.75로 설정되어있다.
해당 논문에서는 LRN으로 top-1, top-5 error_rate를 각각 1.4%, 1.2% 줄일 수 있었다.
현재에는 잘 쓰이지 않고, Batch normalization이 자주 사용된다.
Overlapping Pooling
일반적인 pooling layer는 겹쳐지지 않게 구성되어 있다.
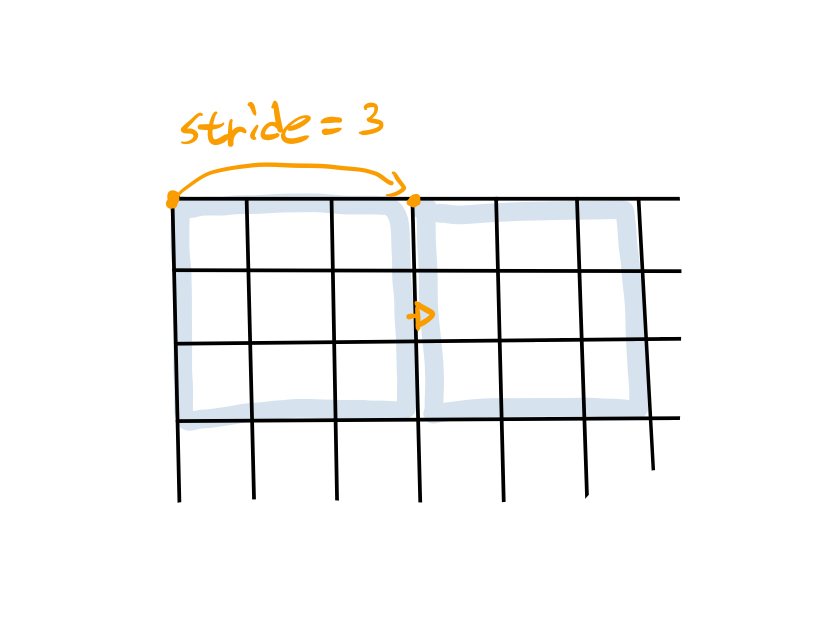
위 그림처럼 ZxZ(위 그림에서 3x3) size의 grid라면, stride도 Z와 같게 하여 pooling시에 겹쳐지는 pixel이 없도록 하는게 일반적이다.
하지만 해당 논문에서는 겹쳐진 pooling layer로 구성했다.
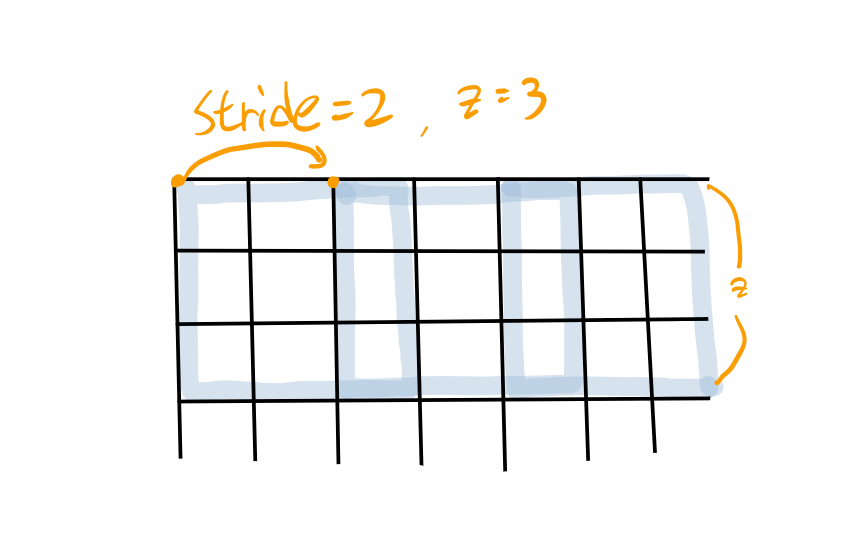
ZxZ의 grid보다 stride을 작게 설정하여 pooling 진행 중에 겹쳐지는 pixel이 있도록 pooling layer를 구성한다.
위 그림에서는 3,6번째 열에 있는 pixel에서 overlapping이 발생한다.
이는 top-1, top-5 error_rate를 각각 0.4%, 0.3% 줄일 수 있었다.
Overall Architecture
AlexNet의 전반적인 구조를 설명하는 section이다.
5개의 convolutional layer, 3개의 fully-connected layer로 구성되어 있다.
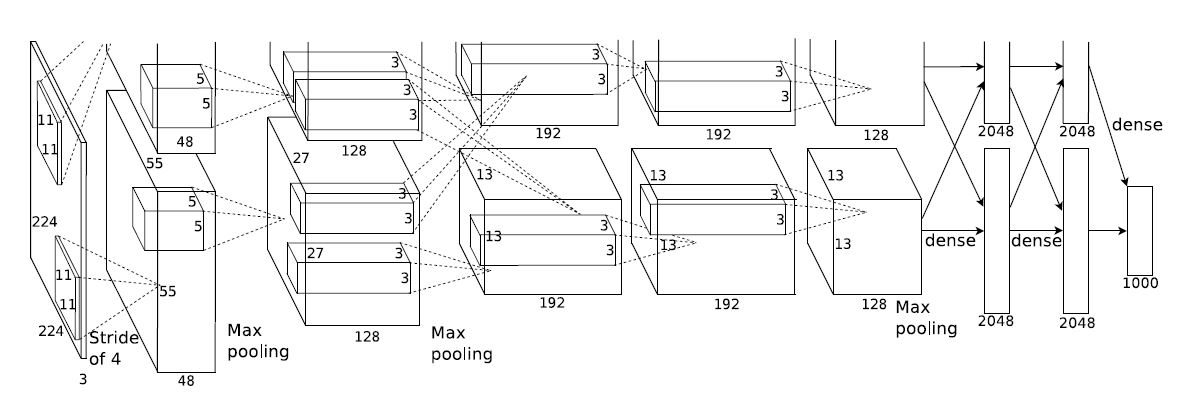
ReLU - 모든 layer
LRN - 1,2 번째 convolutional layer
Maxpooling(overlapping) - 1,2,5 번째 convolutional layer
모델의 구체적인 구조는 https://bskyvision.com/421 가 이해하기 쉽다.
Reducing Overfitting
Data Augmentation
over-fitting을 방지하는 쉽고, 흔한 방법은 dataset을 인공적으로 늘리는 것이다.
논문에서는 2가지 Data Augmentation을 제시한다.(2가지 모두 매우 적은 연산으로 만들어지기 때문에 disk에 저장될 필요가 없으며 이전 batch의 image가 gpu에서 train되는 동안, cpu에서 그 다음 batch의 Augmentation이 진행된다. )
- 256x256의 원본 이미지를 상하대칭을 포함해서 224x224의 patch가 되도록 무작위로 뽑아낸다. 그럼 이론 상 2048개까지 늘릴 수 있게 된다.
2.training image의 RGB pixel 값에 대하여 PCA를 수행한다.
Dropout
Dropout은 논문이 발표될 당시 최신 논문에서 소개된 방식이었다.
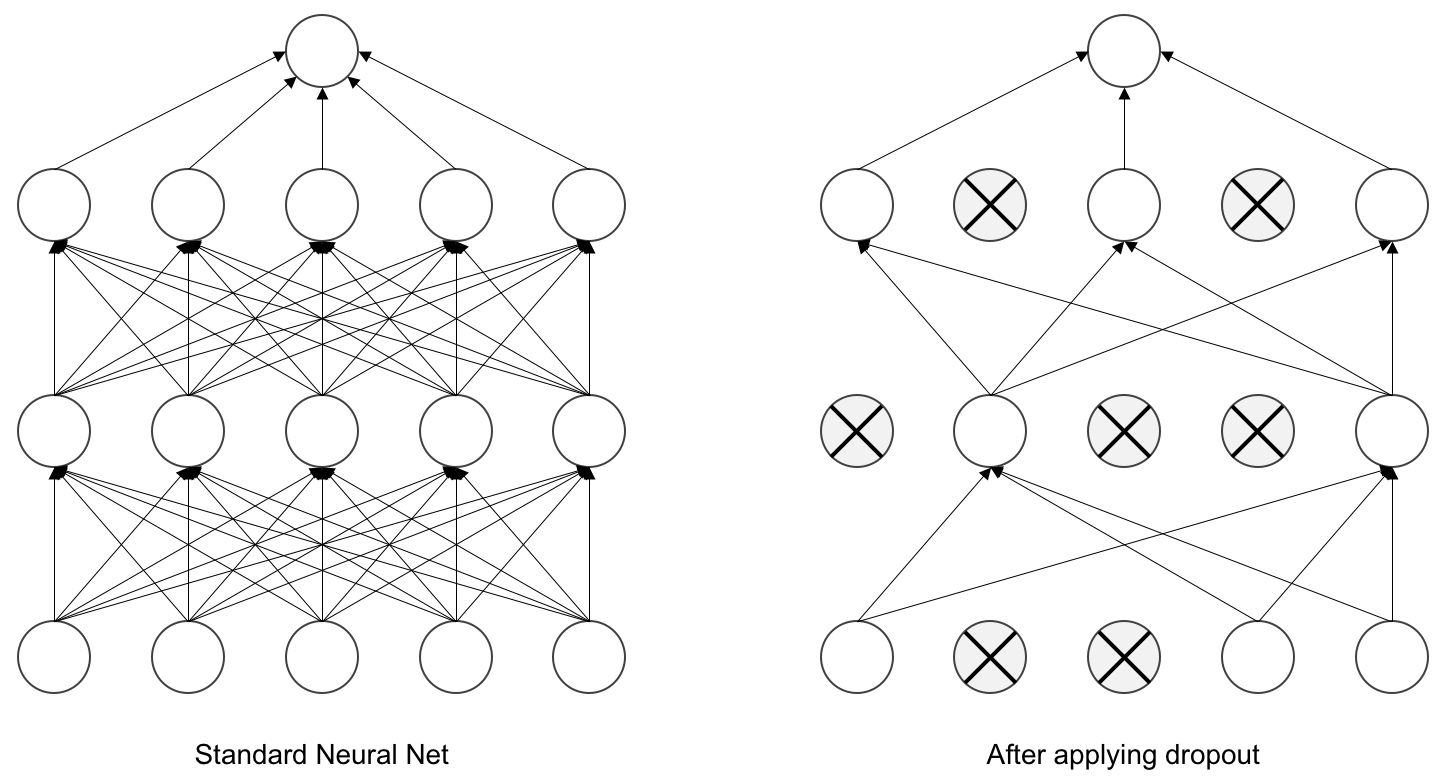
Dropout은 위 그림처럼 hidden layer의 일부 neuron output값을 p의 확률로 0으로 변경하는 것을 말한다.(논문에서는 p=0.5)
Dropout으로 인해 0으로 변경된 neuron은 순전파 및 역전파에서 전혀 사용되지 않을 것이다.
이 방법은 일부 neuron을 강제로 0으로 변경하면서 각 neuron이 서로 다른 neuron에게 의지할 수 없게 하며, neuron간의 복잡한 상호 의존을 감소시킨다.
단, dropout을 사용하면 학습의 속도가 사용하지 않았을 때보다 더디다.
논문에서 test할 때는 모든 neuron을 사용하고 거기에 0.5(p)를 곱해주는 방식을 취한다.
이유는 train은 50%만큼의 neuron이 0이 되었는데 test는 그냥 진행한다면, test시에는neuron값이 train에 비해 커지기 때문이다.
근데, 위처럼 test를 scaling하는 방식이 내가 알던 것과는 달라서 pytorch의 공식 문서를 찾아봤다.
Dropout in pytorch

pytorch에서는 training시에 dropout이 적용된 output에 1/1-p를 곱해줘서 scaling을 해준다.
따라서 논문과는 달리 이미 scaling이 진행되었기 때문에 test할 때 neuron에 0.5(p)를 곱해줄 필요가 없다.
dropout이 더 효율적인 방식으로 변한 것인지 단순한 구현의 차이인지는 잘 모르겠다.
Details of learning
optimizer로 SGD를 사용했고, batch size는 128이다.
momentum 가중치는 0.9로 weight decay는 0.0005로 설정했다.
논문에서는 작게 설정한 weights decay값이 단순히 regularizer로서의 역할 뿐만 아니라, training error를 실질적으로 줄여주는 것을 발견했다고 한다.
논문에서 가중치를 업데이트 하는 식을 보다가 momentum, weight decay가 합쳐진 식이라서 이해가 어려웠다.
그래서 그 부분을 정리하고자 한다.
weights decay
weight decay는 모델의 weihgt가 커지지 않게 방지하는 역할을 한다.
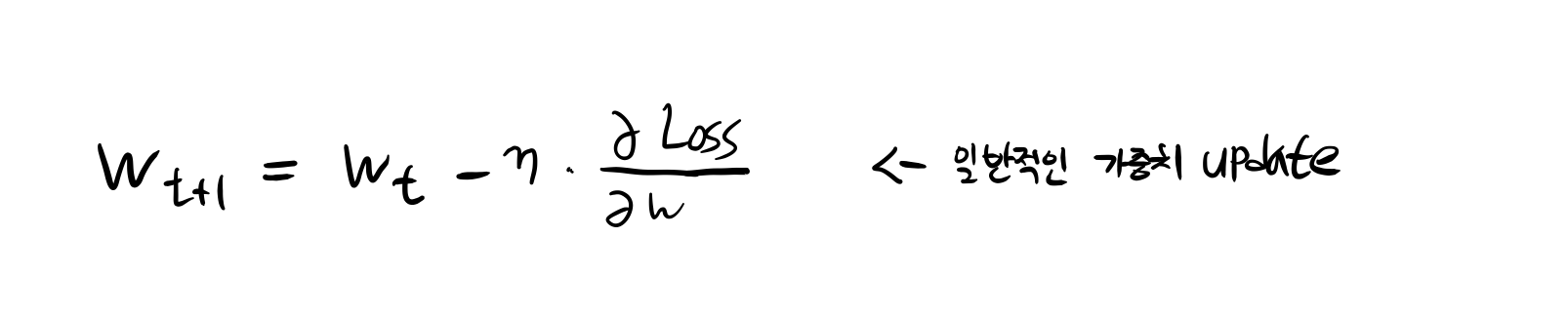
위는 weights decay가 적용되지 않은 일반적인 GD이다.
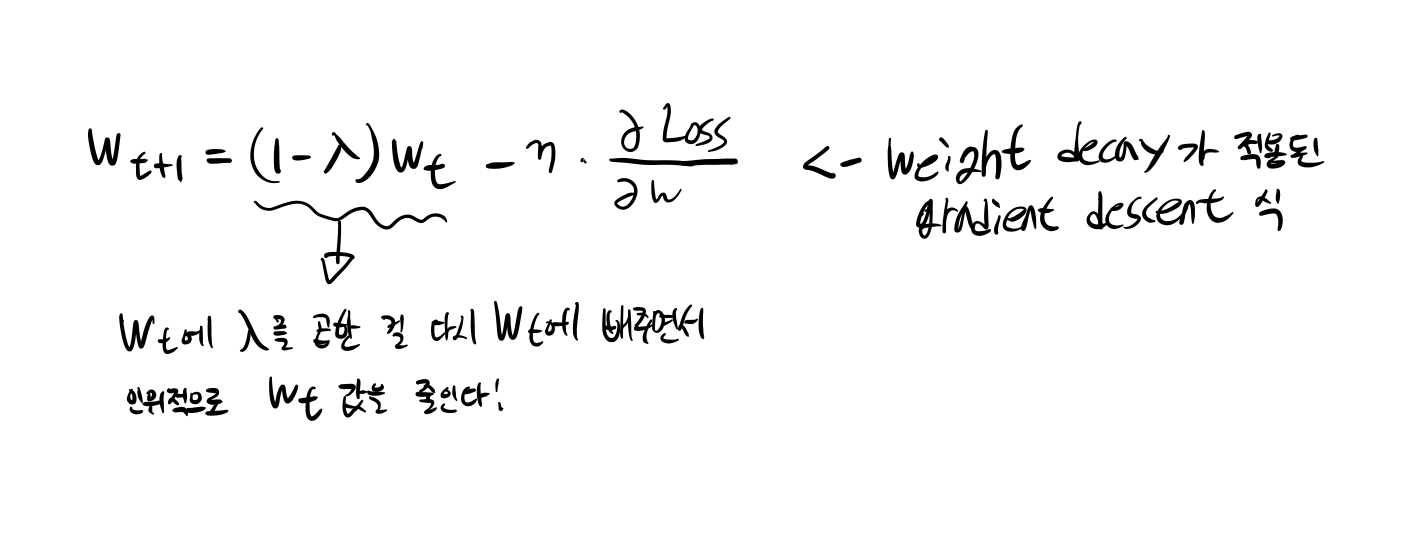
위는 weights decay가 적용된 GD이다.
위 그림처럼 weight에 weight* lamda를 곱한 값을 빼준다.
L2 norm and weights decay
대부분의 블로그에서 weights decay와 L2 regularization이 같은 것으로 나타내고 있는데 이는 SGD를 optimizer로 사용할 때만 맞는 말이다.
아래 링크는 weights decay와 L2 regularization가 어떻게 다른지 설명하고 있는 문서들이다.
https://hiddenbeginner.github.io/deeplearning/paperreview/2019/12/29/paper_review_AdamW.html
https://towardsdatascience.com/weight-decay-l2-regularization-90a9e17713cd
momentum
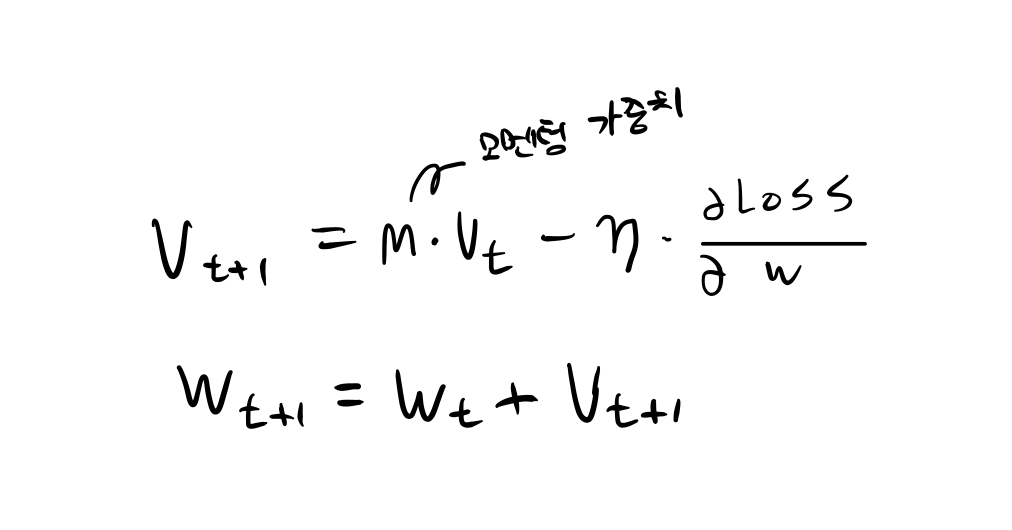
vt는 학습초기에 0으로 초기화되어있다. 경사하강법에서 모멘텀항이 추가된 것 뿐이다.
gradient descent in paper
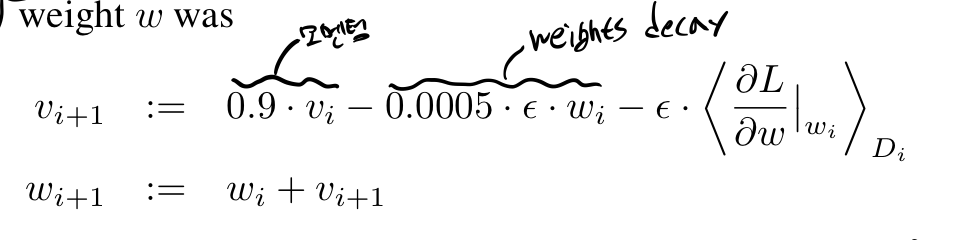
해당 논문에서는 위와 같이 가중치 업데이트가 진행된다.
정리
AlexNet은 딥러닝(CNN)의 획기적인 발전으로 여겨진다. 이전의 competition에서는 딥러닝의 사용이 드물었는데, AlexNet이 딥러닝의 좋은 성능을 증명해냈다. 또한 ReLU, Dropout등 현재에도 활발히 쓰이는 것들의 실질적인 사용 및 성능의 개선을 증명한 것에 큰 의의가 있는 논문이다.
참고
