![]()
Visualizing and Understanding Convolutional Networks(ZFnet) 를 정리!
논문을 번역하면서 요약 정리하는 concept이지만, 내용을 정리하기 위해서 중간중간 제가 정리한 내용도 들어갑니다.
혹시나 틀린 부분이 있다면 댓글로 알려주시면 감사하겠습니다 :)
그리고 정리 편의상 평어체로 서술했으니 양해바랍니다!^.^
Abstract
Alexnet과 같이 큰 cnn model이 ImageNet benchmark에서 좋은 성능을 자랑했다. 하지만 여기에는 왜 그 큰 모델이 좋은 성능을 보여주는지에 대한 이해가 없었다. 해당 논문에서는 이를 증명하고자 한다. 또한 여러가지 실험 및 insight를 제공한다.
-
classifier가 어떻게 분류를 하는지에 대해 insight를 제공해주는 Visualization 기법 소개(이 기법은 모델 아키텍처를 탐색하는데에도 도움이 될 수 있다.)
-
모델 안의 특정한 layer가 모델의 성능에 어느정도 기여를 하는지 파악하기 위한 연구를 진행함.
-
논문에서 Alexnet을 수정한 모델을 제시하는데, 이 모델이 다른 dataset에서도 일반화 성능을 가지는 것을 보여준다.
1. Introduction
커진 dataset과 강력해진 GPU, 더 좋은 모델 규제 기법 등으로 모델의 성능이 더욱 좋아졌다. 그럼에도 불구하고 여전히 모델은 black box이며 어떻게 그렇게 좋은 성능을 달성하는지에 대해서 알 수 없다. 분명한 이해없이는 더 좋은 모델은 만드는데 어려움이 있을 수 밖에 없다.
본 논문에서는 input의 어떤 부분이 feature map을 활성화 시키는지 알아볼 수 있는 Deconvolutional Network를 사용한 시각화 기법을 소개한다.
이 기법을 통해 Alexnet 구조에서 시작해서, Alexnet의 성능을 뛰어넘는 모델 구조를 발견했다.
2. Approach
2.1. Visualization with a Deconvnet
해당 절에서는 Deconvnet을 사용하여 activities를 input pixel space에 되돌려서 매핑하는 새로운 방법을 제시하고, 어떤 input pattern이 feature map에서 활성화를 야기하는지 보여준다.
Deconvnet는 convolution 연산의 역연산이라고 생각할 수 있다.
conv layer 출력인 output activation 중 시각화하기 위한 output activation을 deconvnet layer의 입력으로 넣는다. 입력으로 들어간 output activation은 3단계를 거친다.
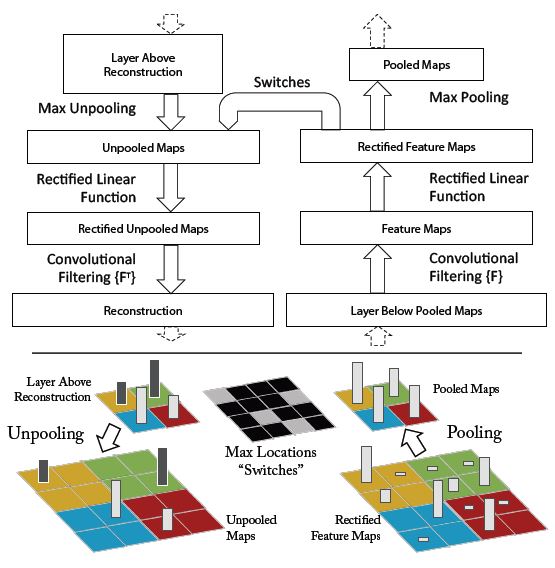
1 unpool > 2. rectify > 3. filter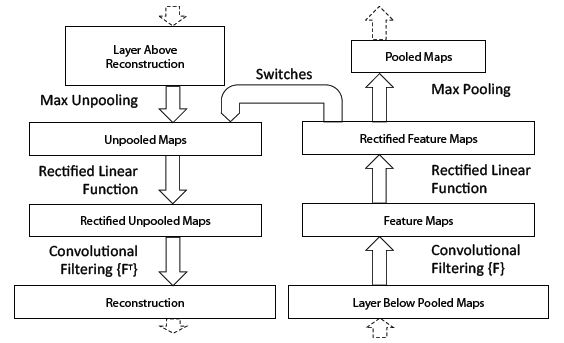
위 이미지는 위에서 설명한 3단계를 도식화한 이미지이다.
왼쪽이 deconv, 오른쪽이 conv 연산이다.
Unpooling
여기서 수행하는 deconvnet은 convolution 연산의 역연산이다. 하지만 conv layer에서 대부분 max pooling이 포함되어 있어서 비가역적인 특징이 있다. 즉 다시 되돌릴 수가 없다. 그래서 논문에서는 max pooling시 switch variables를 정의하고 maxima의 location을 기억하는 용도로 사용한다. 이를 통해 max pooling을 역연산한 것의 근사치를 얻을 수 있다.
위 이미지는 unpooling의 이해를 돕는다. 회색과 검은색 행렬로 표시된 'Switches' 가 maxima의 위치를 저장하고 복원할 때 사용되는 것을 그림으로 쉽게 확인할 수 있다.
Rectification
deconvnet에서도 유효한 feature 재구조화를 위해 relu activation을 진행한다.
Filtering
이 절에서는 위 그림 왼쪽 아래에 언급된 Convolutional Filtering{F^T}의 관한 내용을 설명한다.
deconvnet은 convnet이 사용한 filter의 전치행렬을 사용한다.
Deconvolution vs Transposed convolution
대부분 Deconvolution은 Transposed convolution과 같은 의미로 사용된다.
정말 그런 것인지 너무 궁금해서 많은 검색을 해봤는데 아직 정확히 모르겠다.
일단 레퍼를 적고 추후에 정리해보고자 한다..
conv 2d transpose in torch! 여기서 although it is not an actual deconvolution operation라고 언급함.
논문
The term “deconvolution” is sometimes used in the literature, but we advocate against it on the grounds that a deconvolution is mathematically defined as the inverse of a convolution, which is different from a transposed convolution
3. Training Details
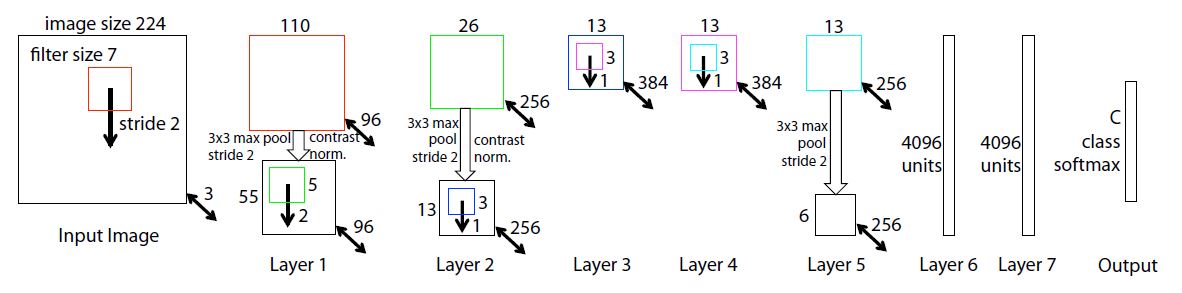
gpu의 병렬적 구성으로 인해서 나누어진 부분만 dense layer로 대체된 것 말고는 Alexnet과 흡사하다.(4.1에서 설명하겠지만 추가적으로 달라진 부분도 존재한다.)
4. Convnet Visualization
이 절에서는 3. Training Details에서 묘사한 모델 구조를 바탕으로 feature activation을 시각화하기 위해 deconvnet을 사용한다.
Feature Visualization


위의 이미지는 top 9 activation을 추려낸 feature visualization의 결과이다.
layer 5의 1행 2열에서 input image는 공통점이 거의 없지만 시각화 결과는 잔디에 집중되어 있음을 알 수 있다.
layer 1,2에서는 주로 영상의 coner,edge를 시각화 한다.
layer 3에서는 layer 1,2에 비해서 비슷한 질감을 갖고있는 특징을 시각화한다.
layer마다 시각화 하는 특질이 다른 것을 확인할 수 있는데, 이는 특정 layer에서 얻어진 시각화를 통해 모델의 학습 경향을 파악할 수 있기 때문에 설계된 모델 아키텍처를 보다 더 잘 이해할 수 있고, 이는 시각화를 활용한 수정을 통해 더 나은 perfomance를 기대하게 한다.
4.1 Architecture Selection
시각화하는 것은 model operation에 이해도를 높여주기도 하지만, 좋은 model architectures를 선택하는 것에 도움을 주기도 한다!
가령, Alexnet에서 1,2 layer를 시각화했을 때 명백한 문제점이 발생해서 그것을 수정했더니 model의 성능이 좋아진 것처럼 말이다.
시각화의 결과로, Alexnet의 layer 1는 정보의 일부만 담고 있었고, layer 2는 Aliasing 문제가 생기는 것을 발견했다.
따라서 본 논문에서는 1 layer filter size를 기존 11x11에서 7x7로 줄였고, stride도 4에서 2로 변경했다.
그 결과 layer 1,2에서 더 많은 정보를 유지할 수 있었고 결과적으로 더 좋은 performance를 보여줬다.
이처럼 시각화는 모델 구조를 선택하는 것에 많은 도움을 주기도 한다.
4.2 Occlusion Sensitivity
이미지 분류에서 model이 진정으로 객체의 위치를 파악하는지, 아니면 주변의 환경을 근거삼아 객체를 분류하는지에 대한 궁금함이 생길 수 있다.
논문에서는 실험을 통해 이 궁금증을 해결하고자 한다.
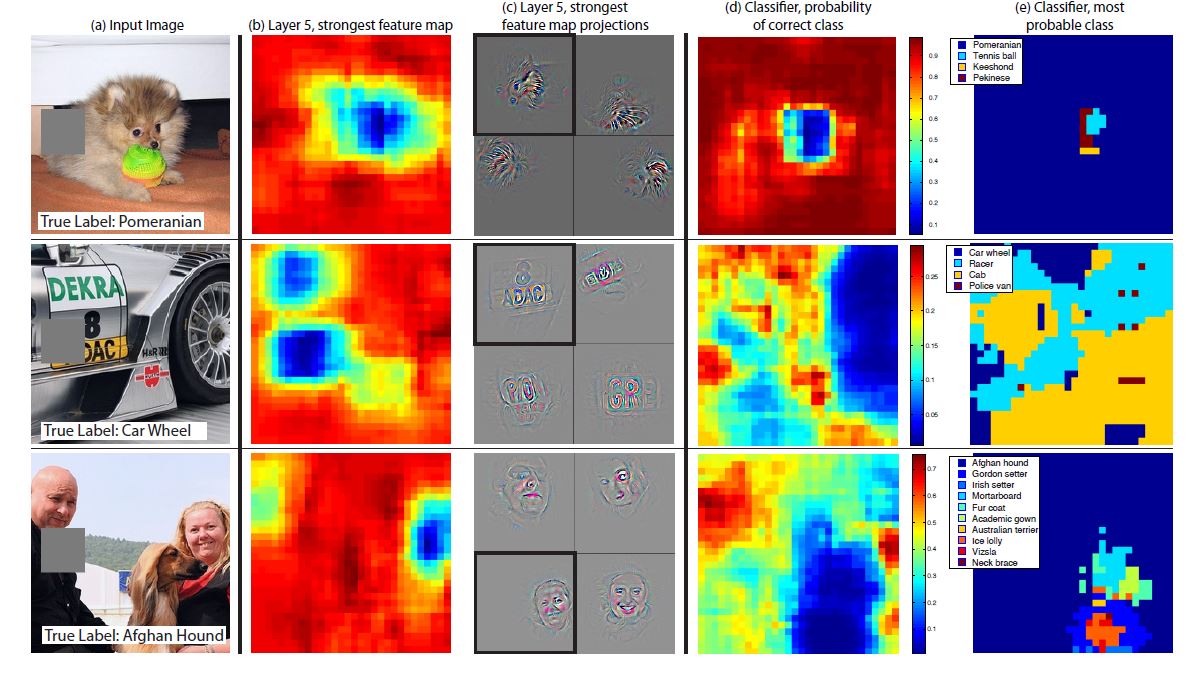
위의 그림을 통해 model이 진정으로 객체의 위치를 파악하고 분류를 한다는 것을 확인할 수 있다. 1번째 행의 포메라니안의 얼굴을 회색박스로 가리면 correct class probabilty가 크게 감소한다. 이는 모델이 정확히 포메라니안의 얼굴을 보고 분류를 하고 있다는 것을 반증한다.
정리
deconvolution을 사용한 시각화 기법을 제시하여, classifier의 operation에 대한 심층적 이해를 돕고, 모델의 취약한 부분을 파악하여 더 나은 방향으로 수정할 수 있는 방법을 제시한데에 의의가 있다.
