![]()
NIN
2014년에 ICLR에 발표된 Network In Network를 정리!
논문을 번역하면서 요약 정리하는 concept이지만, 내용을 정리하기 위해서 중간중간 제가 정리한 내용도 들어갑니다.
혹시나 틀린 부분이 있다면 댓글로 알려주시면 감사하겠습니다 :)
그리고 정리 편의상 평어체로 서술했으니 양해바랍니다!^.^
Abstract
논문 작성자는 수용영역안에서 local patches에 대한 모델 차별성을 높이기 위해 Network In Network 모델 구조를 제시한다.
전통적 convolution 모델은 비선형 활성화 함수와 함께 사용되는 선형필터를 사용한다.
반면, Network In Network는 전통적 convolution 모델보다 수용영역 안에 데이터를 더 복잡하게 추상화할 수 있는 micro neural network를 사용한다.
micro neural network의 모델링 성능을 더욱 향상시키기 위해서 global average pooling도 제시한다. global average pooling를 사용하면 모델에 대한 해석이 쉬워질 뿐만 아니라 classification에 필요한 fully-connected layer를 사용하게 되면서 발생하게 될 over-fitting에도 영향을 덜 받을 수 있다.
Introduction
일반적으로 사용되는 CNN의 conv filter는 데이터 패치(data patch)에 대한 generalized linear model(GLM)이다. 저자는 이 glm의 추상화 수준이 낮다고 주장하며, glm을 더 효과있는 비선형 함수 approximator로 대체한다면 model의 추상화 성능을 더욱 높일 것이라고 말한다.
glm은 선형적으로 분리될 수 있는 잠재공간 하에서만 좋은 성능을 보장할 수 있다. 이는 glm을 사용하는 전통적인 cnn이 암시적으로 잠재공간이 선형적으로 분리가능하다는 가정을 하게 만든다.(일반적으로 잠재공간은 비선형적인데도 불구하고!)
(위 사진은 선형적으로 분리가능한 공간을 표현해본 것이다..!)
따라서, NIN에서는 glm을 비선형 함수 추정기인 micro network로 대체한다. 본 논문에서는 glm을 보편적인 함수추정기 이면서, 역전파로 훈련이 가능한, Multilayer Perceptron으로 정했다.
(함수추정기라고 번역한 것은 논문에서 fuction approximator라고 표현한 것을 직역한 것인데, 무슨 뜻인지 잘 모르겠지만 아마 일반적으로 tf,torch에서 사용되는 dense,Linear와 같이, input에 대해서 output을 반환하는 역할을 하는 부분인 것 같다.)

(a)는 선형 cnn layer이고, (b)는 Multilayer Perceptron이 사용된 layer이다. (앞으로 conv + Multilayer Perceptron은 mlpconv layer라고 지칭한다.)
(b)는 비선형 활성화 함수와 함께 여러개의 fully connected layer로 이루어진 Multilayer Perceptron이 입력 local patch를 output feature vector와 매치시키는 모습을 보여준다. Multilayer Perceptron이 여러개의 fully connected layer이루어져 있기 때문에 모든 local receptive field는 공유된다!
mlpconv layer를 여러겹 쌓은 것이 바로 NIN이다.
NIN에서는 classification을 위해 fully connected layer 대신 global average pooling을 사용한다. global average pooling은 마지막 mlpconv layer에서 나온 feature map의 공간 별 평균을 통해 class에 대한 confidence를 출력할 수 있게한다.
global average pooling을 사용하면 좀 더 의미있는 해석이 가능하고, dropout에 의존적이고 over-fitting의 가능성이 높은 fully connected layer에 비해서, global average pooling자체가 구조적으로 regularizer의 역할을 하기 때문에 전반적으로 overfitting을 방지하는 효과를 얻을 수 있다!(fully connected layer는 파라미터 수가 폭발적으로 증가하는 한편, global average pooling은 파라미터 수가 늘어나지 않기 때문에 over-fitting 되지 않는다.)
Convolutional Neural Networks
이 Sector에서는 Introduction에서 언급한 것처럼 전통적 Convolutional Neural Networks에 단점에 대해 언급한다.
그래서 중요하다고 생각되는 부분만 요약하고 넘어가고자 한다.
전통적 Convolutional Neural Networks는 선형적으로 분리가능한 상황에서 효과적이지만, 좋은 추상화는 대부분 input에 대해 비선형적이다. 이 때 Convolutional Neural Networks는 비선형 잠재공간을 학습하기 위해서 무리하게 되는데 이는 학습에 좋지 않은 영향을 미친다. 따라서 저자는 저차원의 결합으로 더 나은 고차원의 feature를 만드는 것보다 고차원으로 결합하기전에 각 local patch(저차원)에서 더 나은 추상화를 하는 것이 유리하다고 주장한다.
(중략,,)
이전연구에서도 micro network를 슬라이딩하는 것이 제안되었지만, 특정 task에 특화된 것이었다. NIN은 보다 일반적인 task로서 제안되었다.
Network In Network
MLPconv Layers
잠재공간에 대한 사전분포가 없을 때는 보편적인 함수 추정기를 사용하는 것이 바람직하다. 보편적인 함수 추정기로는 RBF와 MLP가 잘알려져있다.
Micro Neural networks로 이 논문에서는 MLPconv Layers를 채택했다. 2가지 이유가 있다.
1번째 이유
Multilayer Perceptron는 역전파로 훈련된Convolutional Neural Networks와 양립가능하다.
2번째 이유
다층 퍼셉트론은 feature 재사용 정신과 일치하는 심층 모델 그 자체일 수 있다.
1번째 이유가 중요해보인다~!
아래는 mlpconv layer의 계산 과정이다.
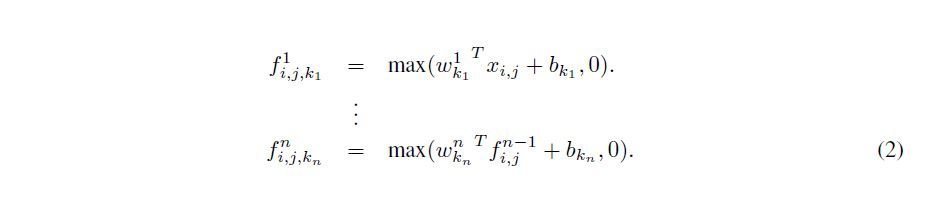
relu를 사용한 mlp conv layer의 계산식이다.
여기서 Equation 2가 CCCP(cascaded cross channel parametric pooling)와 같다는 점이 중요하다!
잠깐! CCCP란??
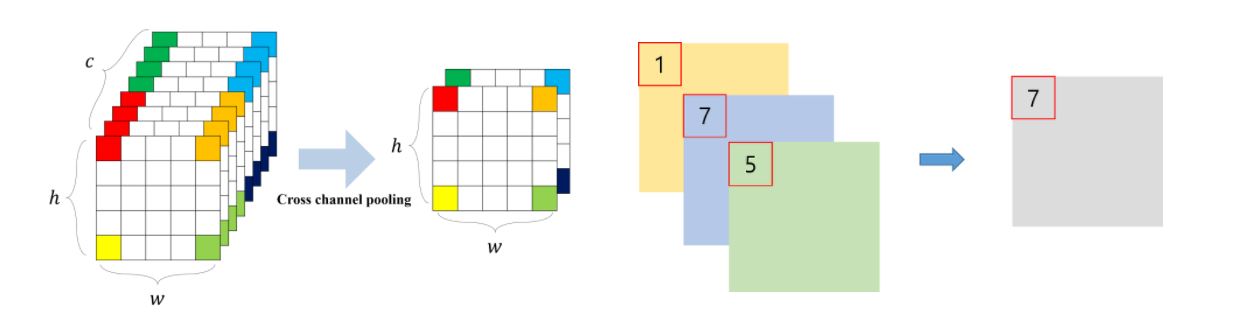
일반적인 pooling은 각 feature map에서 수행되지만 CCCP는 feature map을 가로질러서(Cross) pooling을 한다. 따라서 여러개의 채널 차원을 원하는 채널 수로 줄일 수 있고 이는, 차원을 감소시키는 효과를 가진다.
다시 본론으로 돌아와서, 이 CCCP는 1X1 convolution kernel과 같다. 즉, 논문에서 비선형적인 잠재공간을 더 추상화할 수 있게 Micro Neural networks을 사용했고, 이것을 Mlpconv layer로 정했는데 이건 CCCP와 같다. CCCP는 또한 1X1 convolution kernel와 같은 것이다.
이렇게 유도된 1X1 convolution는 channel reduction의 효과로 인해 훗날 GoogLeNet 및 여러 논문에서 사용된다.
1X1 Convolution kernel
논문에서는 따로 이 section은 없지만, 이참에 1X1 Convolution kernel 대한 이해도 있으면 좋을 것 같아서 해당 kernel에 대해 잘 설명해놓은 링크를 첨부한다.
Global Average Pooling
일반적으로 cnn을 사용하는 classifcation task에서는 마지막 conv층을 지난 feature map이 fully-connected layer를 거친 후 softmax layer을 통해 결과값을 제시한다.
그러나, fully-connected layer는 over-fitting 되기 쉽고, 전반적인 network의 일반화 성능에 좋지 않은 영향을 미친다.
classifcation task에서 fully-connected layer가 사용된 모델의 일반화 성능을 개선하기 위해 Dropout이 사용되곤 하는데, 본 논문에서는 global average pooling이라는 새로운 방법을 제시했다.

global average pooling은 위 그림에서 나타난 것처럼 각 feature map의 평균을 계산하는 것이다.
feature map에 fully-connected layer를 사용하게 되면 모든 feature map의 정보가 연결되기 때문에 각 class가 어떤 이유로 선택되었는지 알기가 어렵다. 하지만 global average pooling는 conv층을 통과한 각각의 feature map을 평균한 것 이기 때문에 어느정도 각 feature map의 특성을 가지고 있다고 할 수 있다. 이는 모델의 해석에 도움을 줄 수 있다.
또한 fully-connected layer의 Weight와 달리 훈련데이터에 최적화 해야 할 parameter가 없기 때문에 이 layer에서 만큼은 overfitting을 방지할 수 있다는 장점도 있다!
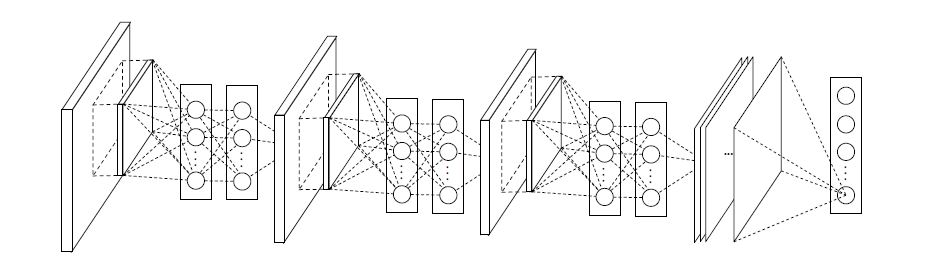
Network In Network Structure
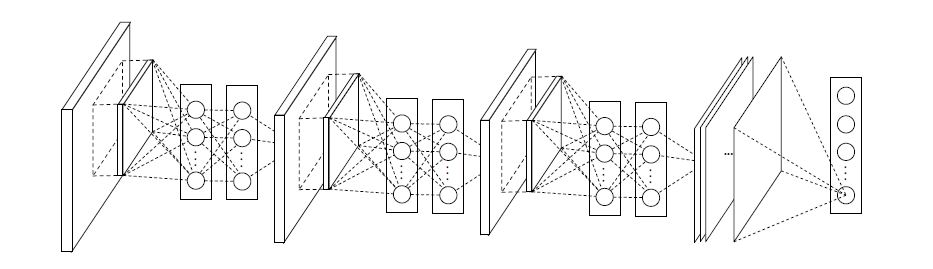
3개의 mlpconv layers와 하나의 global average pooling layer로 구성되어있다. layers의 갯수는 특정 task에 따라 변할 수 있다.
Conclusions
논문에서는 NIN이라는 Classfication Task에서의 새로운 모델을 제시했다. 이 모델은 Mlp conv 및 gap 라는 새로운 구조를 도입했다. Mlp conv를 사용하면서 local patches를 더 잘 반영할 수 있었고, gap를 사용해서 fc layer에 비해서 over-fitting을 방지할 수 있었다.
결과적으로, CIFAR-10, CIFAR-100, SVHN dataset에서 SOTA를 달성할 수 있었다.
정리
gap와 1x1 convolution layer을 제시한 좋은 논문이라고 생각한다. 특히, 1x1 convolution layer의 channel reduction 효과는 한정된 컴퓨팅 자원하에서 유용한 tool이 될 것 같다!!
첫번째 논문 정리 끝!!
