1. Introduction
MobilNet은 mobile 이나 embedded system에서 사용되기 위해 개발된 모델로서, 이전까지 대부분의 연구가 모델의 performance에 초점을 맞추어 모델을 깊고 넓게 또 복잡하게 설계한 반면, Mobile Nets은 모델의 경량화에 그 목적이 있다.
해당 논문에서는 효율적인 network architecture를 제안하고, 두가지 hyper parameter set을 통해 모델을 쉽게 요구되는 사양에 따라 작게 만들 수 있도록 했다.
2. Prior Work
해당 section에서는 Efficient Net의 목적처럼 모델을 줄이기 위한 다양한 related work에 대해서 소개한다.
작고 효율적인 모델을 만드는 것에 대한 관심이 이 당시에 많은 관심사를 끄는 영역이었다.
위 문제에 대해서 다른 많은 연구들은 pretrained network를 '압축' 하거나 '작은' network를 training시키는 방식으로 진행되었다.
MobileNet은 후자에 가깝지만, 개발자가 요구하는 mobile or embedded system의 사양에 따라 network(latency, size,,, 등)를 자유자재로 조절할 수 있다는 점에서 차별점을 가진다.
이후에는 MobilNet에서 중요한 역할을 하는 depth-wise separable network를 사용한 논문에 대한 간략한 소개 및 다양한 모델 경량화 방법(quantization, pruning, hashing, distillation 등)에 대한 언급이 있다.
...생략
3. Mobile Net Architecture
3.1. Depthwise Separable Convolution
3.1. Depthwise Separable Convolution에서는 제목 그대로 Depthwise Separable Convolution에 대해서 설명한다.
MobilNet은 depthwise separable convolution 연산에 기반을 둔 network이다. depthwise separable convolution은 기존 covoltuion 연산을 depthwise convolution과 1x1 convolution(pointwise convolution), 2가지 과정으로 분해함으로써 연산량을 줄이고 모델의 크기 또한 줄일 수 있다.
depthwise separable convolution = depthwise convolution + 1x1 convolution 이니까 우선, standard convolution부터! 그 다음엔 depthwise convolution을 시작으로 차근차근 알아가보자!
standard convolution
standard convolution은 kernel과 input을 결합하여 새로운 output을 산출하는 과정을 한번에 진행한다.
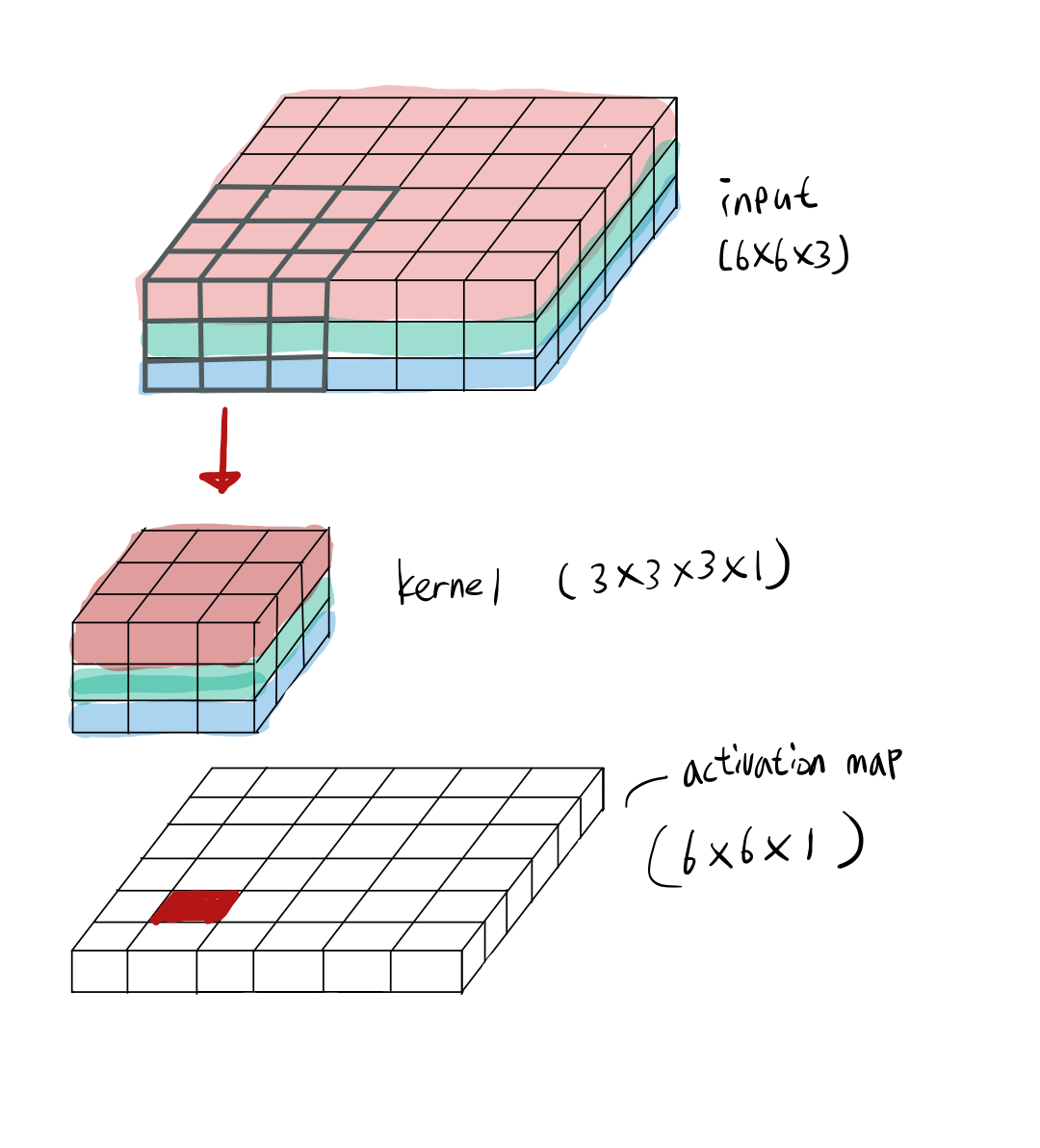
위는 standard convolution 연산 과정이다.
input channel만큼의 kernel channel이 필요하고 사용자가 지정한 kernel의 갯수에 따라 activation map의 channel수가 결정된다.
예를 들어 input으로 6x6x3 이 들어왔을 때 3x3x3 kernel을 1개 사용한다면, output은 6x6x1의 size를 갖는다.
computational cost는
- kernel size
- input channel
- output channel
- input size
를 모두 곱한 이다.
depthwise convolution, 1x1 convolution
앞서 언급한 것처럼 standard convolution은 kernel과 input을 결합하여 새로운 output을 산출하는 과정을 한번에 진행하는데, depthwise separable convolution은 이 과정을 filteling을 위한 과정과 combining을 위한 과정으로 나눈다.
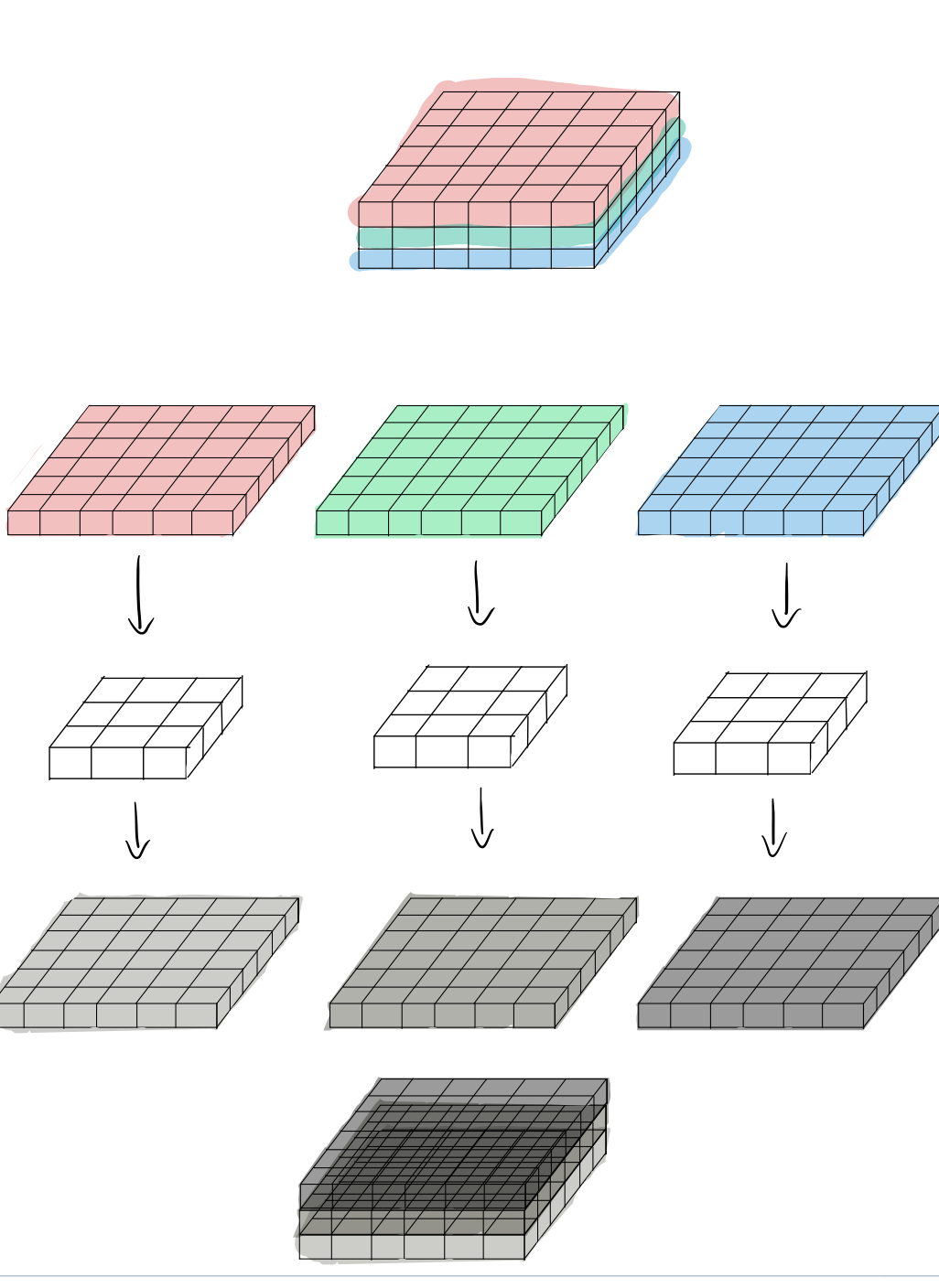
위는 depthwise convolution의 연산과정이다.
standard conv가 한번에 Fliteling과 combining을 진행한 것과 달리 depthwise convolution에서는 filteling만 진행된다.
input의 channel마다 각각 filteling을 거치고, 그 결과를 단순히 쌓는다.
standard convolution에서의 kernel은 모든 채널을 사용하여 연산을 진행하기 때문에 특정 채널의 spatial feature만을 추출하지 못한다.
depthwise convolution은 input의 channel에 각각 독립적으로 대응되는 kernel을 사용한다. 위의 예시와 같이 6x6x3 input이 입력으로 들어왔을 때, input의 각 channel에 대해서 kernel을 적용하여 convolution을 수행하고 그 뒤 산출된 output을 channel 방향으로 concat하여 최종 actiavation map을 결과로 내보낸다.
결국, kernel이 특정 채널의 spatial feature를 학습할 수 있게 된 것이다.
depthwise convolution은 standard convolution에 비해서 연산적으로 효율적이지만, filteling만 가능할 뿐, 정작 새로운 feature를 만들기 위해서 depthwise convolution의 output을 결합시킬 수는 없다.
그래서 depthwise convolution의 output의 선형 결합을 만들어내기 위해서 사용되는 1x1 convolution을 통해 channel 방향의 combining을 수행하여 새로운 feature를 뽑아낸다.
depthwise convolution의 computational cost는
- kernel size
- channel (input과 output의 channel이 같기 때문에 어느 것을 사용해도 상관 x)
- input size
를 모두 곱한 이다.
1x1 convolution 의 computational cost는
- input channel
- output channel
- input size
를 모두 곱한 이다.
depthwise separable convolution
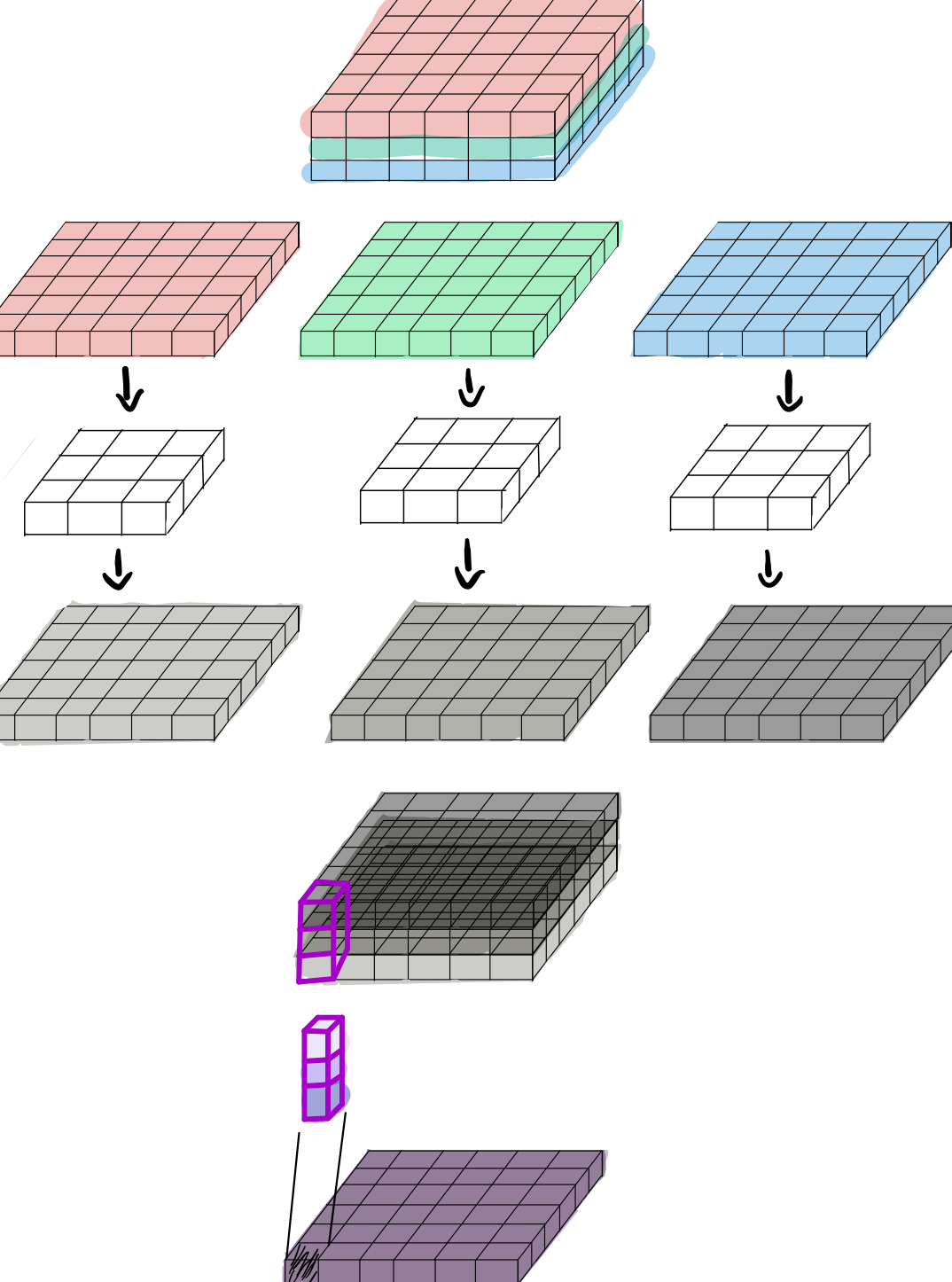
depthwise convolution과 1x1 convolution을 결합한 depthwise separable convolution의 연산과정이다.
앞서 그림으로 살펴본 depthwise convolution 연산의 결과를 1x1 convolution연산을 통해 channel 방향으로 linear combining하여 새로운 Feature를 만들어 낸다.
depthwise separable convolution 의 computational cost는 depthwise convolution과 1x1 convolution의 computational cost을 모두 더한
이다.
standard convolution의 computational cost로 해당 값을 나누면,
이고, 계산하면 이 된다.
결국 MobileNet은 model architecture에서 standard convolution을 depthwise separable convolution으로 일부 대체하면서 만큼의 연산량을 줄일 수 있는 것이다.
3.2. Network Structure and Training
3.2. section에서는 Network의 구조와 Train 방식에 대해서 설명한다.
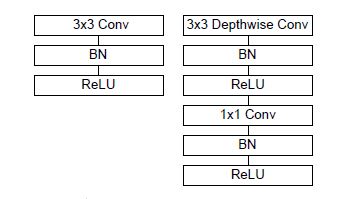
Network는 이전 section에서 언급한 depthwise separable convolution을 기반으로 이루어져 있으며, 모든 layer에는 위 그림처럼 BatchNorm, ReLU가 적용된다.
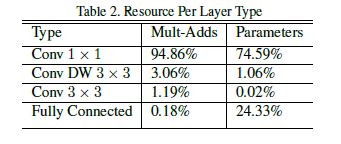
MobileNet처럼 단순하고 효과적인 연산을 기반으로 한 Network를 구성하는 것 외에도 이 연산이 효율적으로 구현될 수 있는지를 확인하는 것 또한 중요한 작업이다.
MobileNet에서 대부분의 Mult-Adds(한 이미지를 인식하는데 필요한 곱셈-함 연산의 수)는 위 그림에서 알 수 있는 것처럼 1x1 convolution에서 발생하기 때문에 이를 효율적으로 구현할 필요가 있다.
이는 고도로 최적화된 GEMM에 의해서 구현될 수 있으며, 그 안에서 필요한 메모리 재정렬을 1 * 1 컨볼 루션은 요구하지 않기 때문에 가장 최적화 된 알고리즘 중 하나 인 GEMM에 의해 직접 구현 될 수 있다. 따라서 효율적인 연산 구현 또한 가능해진다.
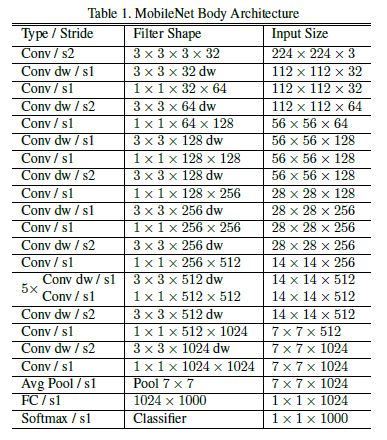
전체적인 Network의 구조는 위와 같다.
classifier의 input으로 들어가기 위해서 gloabal average pooling이 적용되었다.
해당 모델은 TensorFlow에서 학습되었으며, RMSprop이 optimizer로 사용되었다.
큰 모델을 훈련시키는 것과는 달리 MobileNet에서는 over-fitting이 일어날 가능성이 비교적 적기 때문에 regularization, augmentation이 덜 사용되었다.
추가적으로 연구진들은 DW filter에 파라미터가 매우 적기 때문에 weight decay를 적게 주거나 아예 안주는 것이 중요하다는 것을 알아냈다고 한다.
3.3. Width Multiplier: Thinner Models
3.3. section에서는 Network의 Width를 조절할 수 있는 hyperparameter인 Width Multiplier에 대해서 소개한다.
MobileNet이 이미 작고, Low latency를 가진 model이지만, 사용자에 따라서 더 작고, 더 빠른 속도가 필요할 수도 있다.
MobileNet은 Width Multiplier라고 불리는 hyper parmeter 를 사용하여 간단하게 Model을 더 축소시킬 수 있다.
의 역할은 균일하게 각 layer를 '얇게' 만드는 것이다.
layer와 가 주어졌을 때 input channel 는 가 되고, output channel 는 가 된다. channel에 를 곱해주어서 모델을 작게 만드는 단순한 아이디어이다.
가 적용된 depthwise separable convolution의 computational cost는 이다.
는 0초과 1이하의 값을 가지며, 1일 때는 basic network와 같다. 일반적으로 1, 0.75, 0.5, 0.25의 값을 가지도록 설정한다.
Width Multiplier는 합리적으로 작은 모델을 만들기 위해서 다른 Model에도 적용될 수 있다! (accuracy와 size의 trade off가 존재하기 때문에 결정이 필요함,,,)
3.4. Resolution Multiplier: Reduced Representation
3.4. section에서는 Network의 computational cost를 줄일 수 있는 또 다른 방법인 Resolution Multiplier에 대해서 소개한다.
Resolution Multiplier은 로 표현되고, input image 또는 각 layer의 internal representation(activation map을 말하는 듯?)에 곱해주어서 연산량을 줄일 수 있도록 하는 hyper parameter이다.
즉, input의 Height, Width에 p를 곱해서 resolution을 줄여주는 역할을 한다.
와 가 적용된 depthwise separable convolution의 computational cost는 이다.
는 0초과 1이하의 값을 가지며, 1이라면 basic network와 동일하다. 일반적으로 224, 192, 160, 128의 resolution을 가지도록 설정한다.
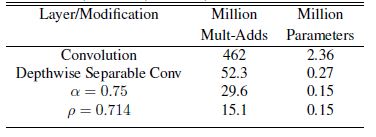
4. Experiments
- section에서는 연구진들이 Network의 layer 수를 줄이는 것 대비 depthwise separable convolution을 사용하거나 위에서 소개한 multiplier를 사용했을 때 어느정도 효과가 있는지 조사한 결과를 살펴본다.
그리고 여러 유명한 model들과 비교하면서 Width Multiplier, Resolution Multiplier를 사용하면 어느정도의 trade off가 생기는지도 알아본다.
4.1. Model Choices

table 4.를 살펴보면 MobileNet architecture를 모두 standard convolution으로 구성했을 때 대비 depthwise separable convolution을 섞은 MobileNet이 Mult-Adds는 크게 줄었지만,
accuracy는 약 1% 정도만 손해를 본 결과를 확인할 수 있다.
이는 MobileNet의 Mobile이나 Embedded system을 위한 Model을 만드려는 목표에 부합하는 결과이다!
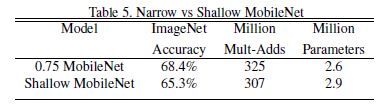
table5.에서는 model의 layer를 얕게 쌓는 것보다 width Multiplier을 사용하여 thinner model을 사용하는 것이 더 낫다는 결과를 보여준다. Mult-Adds가 조금 많지만 정확도는 그것을 감수할정도로 더 높다.
4.2. Model Shirinking Hyperparameters
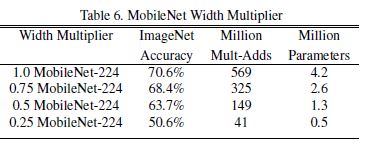
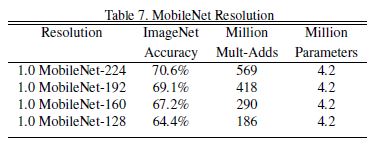
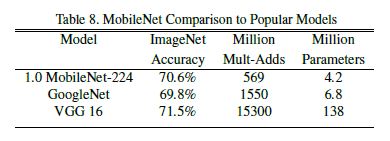
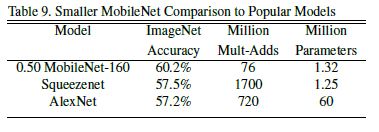
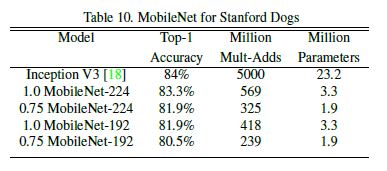
위 table들은 MobileNet haper parameter에 따른 비교, 다른 유명한 모델들과의 비교를 보여준다.
4.3.... etc
4.3. section부터는 MobileNet이 적용될 수 있는 다양한 영역을 소개한다.
정리할 것이 크게 없어서 생략!
느낀 점,,
지금까지 읽어 본 논문들은 대부분 '성능'에 초점을 맞추고 있어서 읽는게 재미가 없었다,,,
mobileNet은 모델의 경량화에 초점을 맞추고, 그 방식 또한 간단해서 읽기가 쉽고 재밌었다^-^
model의 성능 또한 중요하지만, 상용화를 위해서는 경량화에 대한 연구가 필수적으로 진행되어야 할 것이다. 그런점에서 많은 insight를 얻을 수 있는 논문이었따!
Reference
참고논문: MobileNets: Efficient Convolutional Neural Networks for Mobile Vision
https://eehoeskrap.tistory.com/431
https://medium.com/@zurister/depth-wise-convolution-and-depth-wise-separable-convolution-37346565d4ec
