![]()
2014년에 발표된 GoogLeNet을 정리!
혹시나 틀린 부분이 있다면 댓글로 알려주시면 감사하겠습니다 :)
GoogLeNet은 ILSVRC14에서 SOTA를 달성한 모델이다.
이 모델 아키텍처에서 주요한 특징은 모델의 depth, width를 늘리면서 모델의 성능을 높이면서도, 컴퓨팅자원을 효율적으로 사용했다는 점이다.
Introduction
2014년을 기준으로 지난 3년동안 CNN의 발전은 드라마틱했다.
새로운 idea, algorithm의 발전이 CNN의 성능 개선을 이끌었는데, GooLeNet은 같은 데이터로 2년전의 AlexNet의 파라미터 보다 12배 적은 파라미터로 더 좋은 성능을 보여줬다.
해당 논문에서 연구자들은 효율적이면서도 deep한 model architecture를 만드는 것에 집중했다.
그 결과 codename Inception이 탄생했다.

Related work
-
LeNet을 시작으로 CNN은 여러개의 convolution layer 뒤에 하나, 그 이상의 fully connected layer가 뒤따르는 구조가 주를 이뤘다.
-
imagenet과 같은 큰 데이터 셋에서 최근 trend는 layer의 수를 늘리거나 layer의 size를 늘리는 것이다 또한 오버 피팅을 해결하기 위해 dropout을 적용한다.
-
Max-pooling layer가 공간정보의 손실을 가져온다는 걱정에도 불구하고, max-pooling을 사용한 Network architecture가 성공적인 결과를 얻었다.
-
모델 전체에서 주요한 기능으로 NIN에서 제안된 1x1 convolution을 사용하는데, 이는 차원축소의 기능을 통해 성능 저하 없이 모델의 depth와 width를 늘릴 수 있게 한다.
(1x1 convolution을 수행하면, 여러 개의 feature-map으로부터 비슷한 성질을 갖는 것들을 묶어낼 수 있고, 결과적으로 feature-map의 숫자를 줄일 수 있으며, feature-map의 숫자가 줄어들게 되면 연산량을 줄일 수 있게 된다. 또한 연산량이 줄어들게 되면, 망이 더 깊어질 수 있는 여지가 생기게 된다.)
NIN이란!
https://velog.io/@whgurwns2003/Network-In-NetworkNIN-%EC%A0%95%EB%A6%AC
Motivation and High Level Considerations
모델의 성능을 향상시키는 가장 직관적인 방법은 그 크기를 늘리는 것이다. 그러나 이 간단한 방법은 두가지 약점이 존재한다.
- 모델의 크기가 커지는 것은 파라미터 수가 많은 것을 의미한다. 이는 over-fitting에 취약해질 수 있다.
- 큰 모델은 더 많은 컴퓨팅 자원을 필요로 한다.
만약 두 Convolutional layer가 연결되어 있다면, 필터의 수가 늘어날 때 컴퓨팅 연산량을 quadratic 하게 증가시킨다.
이러한 상황에서 컴퓨팅 자원은 한정적이므로 네트워크의 크기를 늘리는 것보다 컴퓨팅 자원을 효율적으로 분배하는 것이 더욱 중요하다.
위 두가지 issue를 근본적으로 해결하는 방법은 fully-connected architectures를 sparsely connected architectures로 바꾸는 것이다.

Google팀은 Arora의 논문(Provable bounds for learning some deep representations) 참고했는데, 이는, 생물학적인 모방결과 dataset의 확률적 분포가 크고 아주 sparse한 deep neural network로 표현될 수 있다면, optimal network 구조가 만들어질 수 있다는 것 이다.
하지만 현재의 Numerical Computation은 fully-connected architectures에 효율적으로 만들어져 있기 때문에 sparsely connected architectures을 사용하는 것은 비효율적이다. 따라서 fully-connected architectures을 쓸 수 밖에 없는데 이를 해결하기 위해 GoogleNet 연구진들은 architectures를 Inception module의 도입을 통해 모듈로써 sparsely 하도록 나누고, 반면 모듈 내부는 dense하게 계산하도록 했다.
Architectural Details
Inception architecture의 main idea는 CNN에서의 optimal local sparse structure를 dense components로 근사하는 것 이다.
[Where the light is]
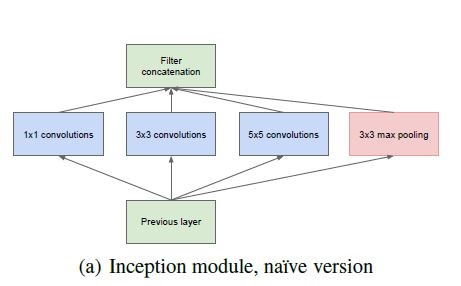
초기 Inception Module의 모습이다.
3x3, 5x5의 커널을 통해 다양한 scale의 feature를 추출해낼 수 있는 구조이지만, 이는 필연적으로 연산량의 증가를 가져온다. 이는 optimal sparse structure라도 매우 비효율적이다.
따라서 연구진들은 수정된 version의 Inception module을 제시한다.

위 수정된 Inception module에서는 1x1 conv가 추가되었다.
1x1 conv가 연산비용이 큰 3x3, 5x5 conv layer 이전에 추가되어 reduction을 하면서 기존 navie version이 가지고 있던 장점인 다양한 scale의 feature 추출이라는 장점을 유지하면서도 단점으로 꼽히던 연산량의 폭발적인 증가를 해결할 수 있었다. 여기에 더하여, Convlution 연산 후에 ReLU를 통해 비선형적 특징을 더할 수 있다.
이 architecture의 주요한 이점은 컴퓨팅 연산의 증가 없이 unit의 갯수를 증가시켜 모델의 성능 개선을 꾀할 수 있다는 점과 시각정보가 다양한 1 x 1, 3 x 3, 5 x 5 Convolution 연산을 통해 여러 scale로 처리되고 이를 통해 다음 layer는 서로 다른 scale의 특징을 동시에 추상화할 수 있다는 점이다.
GoogLeNet
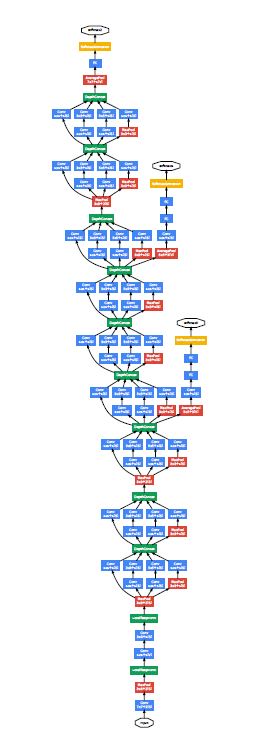
위는 GoogLeNet의 전체적인 구조이다.
lower layer에서는 메모리의 효율적인 사용을 위해 기본적인 cnn 구조를 따르고 있고, 다음 단계에선 inception module의 사용이 반복되는 구조이다.
특이하게 inception module 옆에 튀어나온 부분이 있는데 이는 auxiliary classifier 이다.
auxiliary classifier
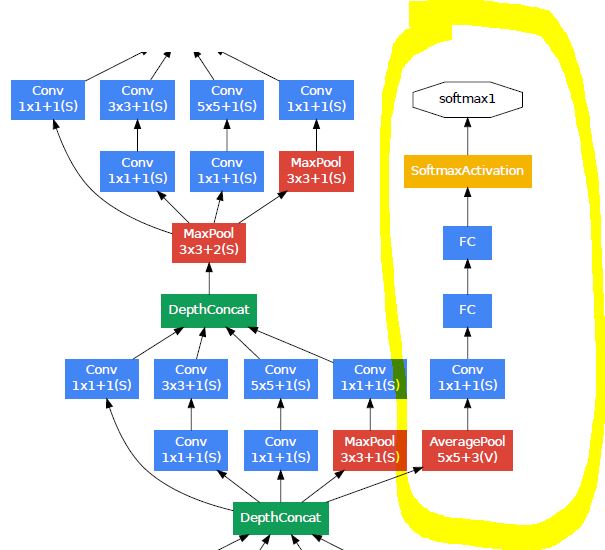
비교적 큰 network에서는 vanishing gradient문제가 있기 때문에, 어떻게 해야 기울기를 효율적으로 역전파할 수 있는가에 대한 문제에 대한 고민이 필요하다.
상대적으로 얕은 네트워크의 강력한 성능은 네트워크 중간에 있는 layer들에 의해 생성된 feature들이 매우 차별적인 것에서 기인하는 insight를 발견한 연구진들은 GoogLeNet의 중간에 있는 layer의 feature를 학습에 효율적으로 활용하여 vanishing gradient문제를 해결하고 수렴을 효과적으로 하기위해 GoogLeNet의 중간 layer에 보조 classifier를 도입했다.
이 auxiliary classifier는 중간 layer의 back propagation의 결과를 더할 수 있기 때문에 layer가 깊어짐에 따라 intermediate layer의 gradient가 작아지는 문제를 피한다. 또한 훈련시에 auxiliary classifier의 loss가 network의 loss에 더해지기 때문에 추가적인 regularization의 역할도 한다.
auxiliary classifier는 학습이 원활하게 되기 위한 도구이기 때문에 학습이 끝난 후에는 auxiliary classifier를 삭제한다.
Conclusion
Inception 구조는 Sparse structure를 Dense structure로 근사화하여 성능을 개선하였다.
본 논문에서 Sparse structure를 Dense structure로 근사하는 것에 대한 실현가능성과 유용함에 대한 증명을 보였다.
느낀점
모델을 깊게, 넓게 쌓으면서도 1x1 conv, auxiliary classifier 등의 사용을 통해 deep and wide한 모델의 단점을 해결하고자 한 점이 인상깊었따,,
Reference
http://www.hellot.net/new_hellot/magazine/magazine_read.html?code=202&sub=002&idx=45531
