이전 글에서 약 10만 건 데이터 기준으로 부하 테스트를 했고, connection refused / 지연 폭증 / Hikari pending 증가 / InnoDB row lock wait 증가까지 연쇄 병목을 확인했다.
이번 글에서는 무엇을 어떻게 개선했고, 왜 그 실험을 했는지를 쓸 예정이다.
0. 실험 목표, 기준
0-1. 목표
Locust failures 감소
p95/p99 지연 감소
InnoDB row lock wait 감소
Hikari pending 감소
Tomcat threads/connections 상한 도달 방지
를 달성하는 것을 목표로 했다.
0-2. 테스트 설계
데이터 규모: 게시글 10만건
트래픽 믹스: 핫스팟 80 / 랜덤 20
Locust 시나리오 대로 실험
1. 개선 후보
개선은 할게 끝이 없다고 생각했다. 그래서 3가지를 잡았다.
- 리소스 상한 튜닝하기 (Tomcat/Hikari)
- DB 최적화하기 (쿼리/인덱스/트랜잭션)
- 아키텍처 변경하기 (Redis/비동기/배치)
2. 실험 설계
2-1. 테스트를 분리
Break test(파괴 테스트): 유저 10,000(스텝 1,000)
Observation test(관측 테스트): 유저 1,000(스텝 100)
파괴 테스트는 failures가 너무 많으면 p95 같은 지표가 왜곡되기 쉽다.
그래서 원인 추적은 관측 테스트 구간에서 진행했다.
2-2. 비교 지표
Locust: failures, RPS, p95/p99, (가능하면 실패 사유 캡처)
DB: Innodb_row_lock_waits, Innodb_row_lock_time
Hikari: active/idle/pending
Tomcat: threads.busy/current/max, connections.current/max, keepalive
3. 상한 튜닝 먼저 해보기
이 실험의 목적은 간단하다.
연결 거절/타임아웃은 줄어들 수 있지만, DB row lock 병목은 남는다. 그냥 조금 더 버틸 것이다.
3-1. 변경한 것
properties
# Tomcat tuning
server.tomcat.threads.max=400
server.tomcat.max-connections=20000
server.tomcat.accept-count=200
# HikariCP tuning 새 요청이 커넥션을 못받고 3초 지나면 타임아웃 에러
spring.datasource.hikari.maximum-pool-size=50
spring.datasource.hikari.minimum-idle=50
spring.datasource.hikari.connection-timeout=3000 3-2. 관측 결과
ERROR [http-nio-8080-exec-386] o.a.c.c.C.[.[.[.[dispatcherServlet] -
Servlet.service() for servlet [dispatcherServlet] in context with path
[] threw exception [Request processing failed: org.springframework.transaction.CannotCreateTransactionException:
Could not open JPA EntityManager for transaction] with root cause
java.sql.SQLTransientConnectionException: HikariPool-1 - Connection is not available,
request timed out after 3003ms (total=50, active=50, idle=0, waiting=2)...- Hikari 풀을 50으로 늘렸지만, 요청이 증가하면서 active가 50까지 고정되고 idle은 0이 된다.
- 그 상태에서 신규 요청은 커넥션을 얻지 못하고
connectionTimeout(3s)이후 실패한다. - 스프링에서는 트랜잭션을 시작하기 위해
EntityManager를 열어야 하는데 커넥션을 못 얻어서CannotCreateTransactionException으로 떨어진다.
상한을 늘려 더 많이 받는 것처럼 보였지만 결국 DB병목이 남아있으면 실패가 발생했다.
3-3. 한 줄 결론
상한을 늘리면 좀 더 늦게 밀리지만, 조회수 UPDATE라는 단일 row 핫스팟은 그대로라서 결국 다시 같은 형태로 포화된다.
4. DB 최적화하기
4-1. 변경한 것
트랜잭션 범위 최소화
이전 코드는 서비스 클래스에 @Transactional이 잘못 걸려서, 조회 API까지도 불필요하게 트랜잭션이 넓게 잡힐 수 있었다.
트래픽이 몰릴 때 DB가 느려지면 트랜잭션이 길어질 것이다. 그리고 트랜잭션을 메서드 단위로 다시 분리했다.
Post get 메소드
@Override
@Transactional(readOnly = true)
public PostDetailDto getPost(Long id) {
viewCountService.increment(id);
return PostDetailDto.from(postRepository.findById(id).orElse(null));
}ViewCountService
@Transactional // 또는 REQUIRES_NEW (의미를 더 강하게 주고 싶으면)
public void increment(Long postId) {
postRepository.incrementViewCount(postId);
}이런식으로 커넥션을 조금이라도 짧게 잡아보고자 생각해봤다.
인기글 쿼리 인덱스 추가
10만 건 기준에서 인기글 API는 아래 쿼리를 사용한다.
WHERE post_status = 'PUBLISHED' ORDER BY view_count DESC LIMIT 20
데이터가 적을 떄는 티가 많이 나지 않지만, 데이터가 커지면 비용이 크게 늘어날 수 있다. 그래서 post_status, view_count가 인덱스를 타도록 추가했다.
CREATE INDEX idx_post_status_viewcount ON post (post_status, view_count, post_id);EXPLAIN ANALYZE 결과 실제로 굉장히 많이 줄어든 것을 확인할 수 있었다. 인덱스 추가 전에는 Sort가 들어가 있고 수십 ms가 걸렸다.
인덱스 추가 전
-> Limit: 20 row(s) (cost=10164 rows=20) (actual time=65.7..65.7 rows=20 loops=1)
-> Sort row IDs: p.view_count DESC, limit input to 20 row(s) per chunk
(cost=10164 rows=99148) (actual time=65.7..65.7 rows=20 loops=1)
-> Filter: (p.post_sta...인덱스 추가 후
-> Limit: 20 row(s) (cost=5704 rows=20) (actual time=0.0324..0.067 rows=20 loops=1)
-> Filter: (p.post_status = 'PUBLISHED') (cost=5704 rows=49574) (actual time=0.0317..0.0657 rows=20 loops=1)
-> Index lookup on p using idx_post_status_view...인덱스 추가 후에는 Sort가 사라지고 Index lookup으로 바뀌었다. 실행 시간도 크게 줄어들었다.
4-2. 테스트 결과
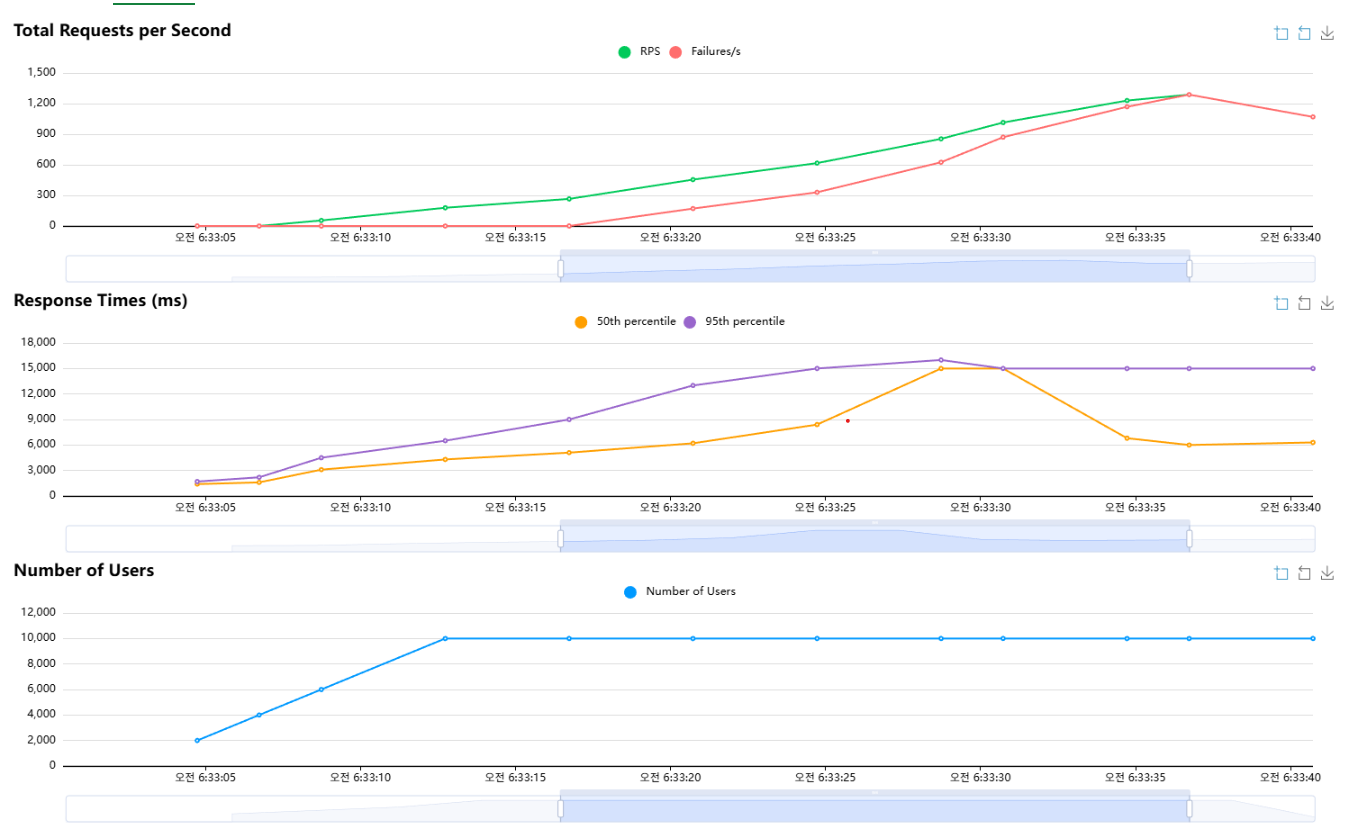
튜닝 후 (10,000명)
튜닝 이후에도 전과 비슷하게 RPS가 급격하게 오르며 실패율이 굉장히 높아졌다.
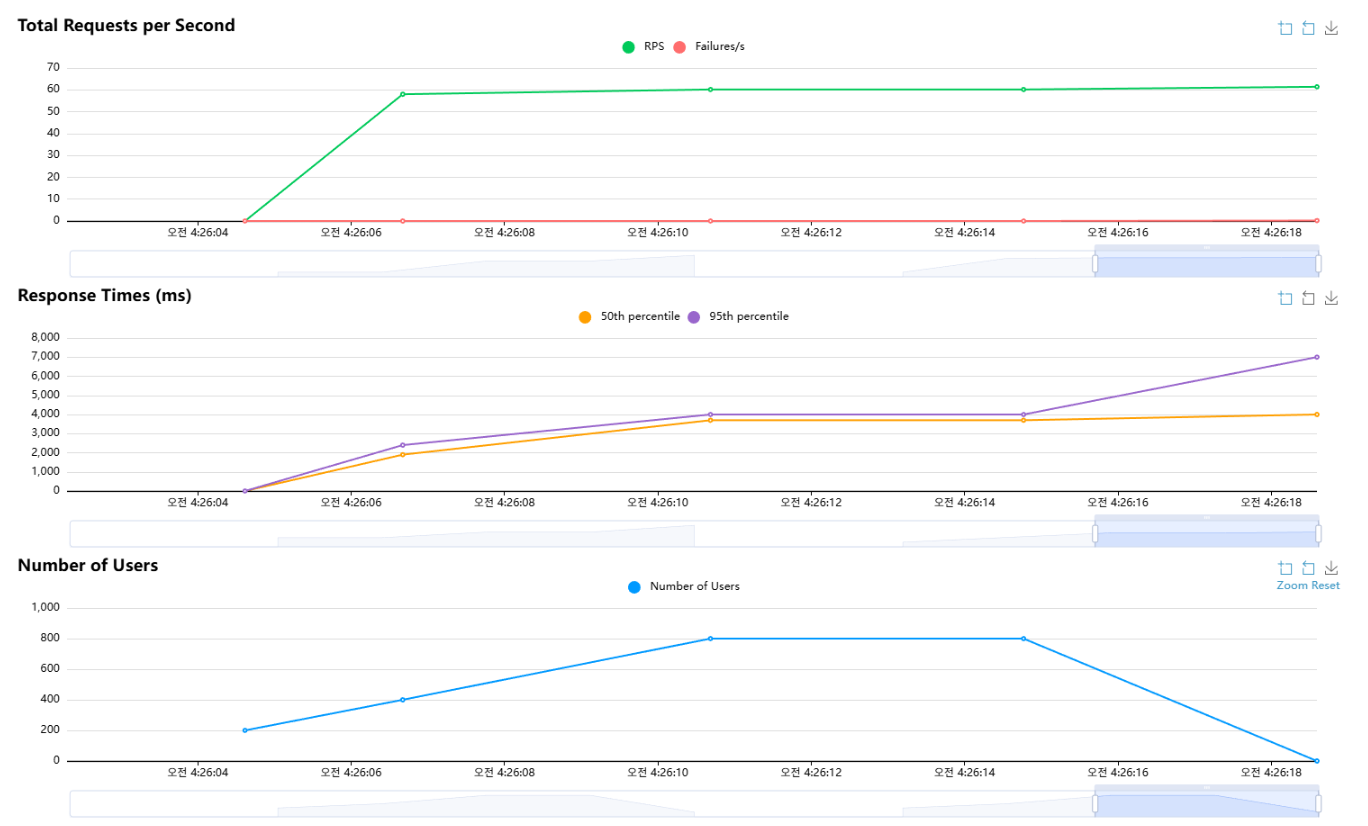
튜닝 전(1,000명)
하지만 튜닝 전 1,000명 테스트에서 RPS가 60대였고, 응답속도가 계속 증가하는 것을 볼 수 있다.
튜닝 후 (1,000명)
튜닝 후 1,00명 테스트에서 RPS가 약 300까지 상승해 개선효과가 있었다.
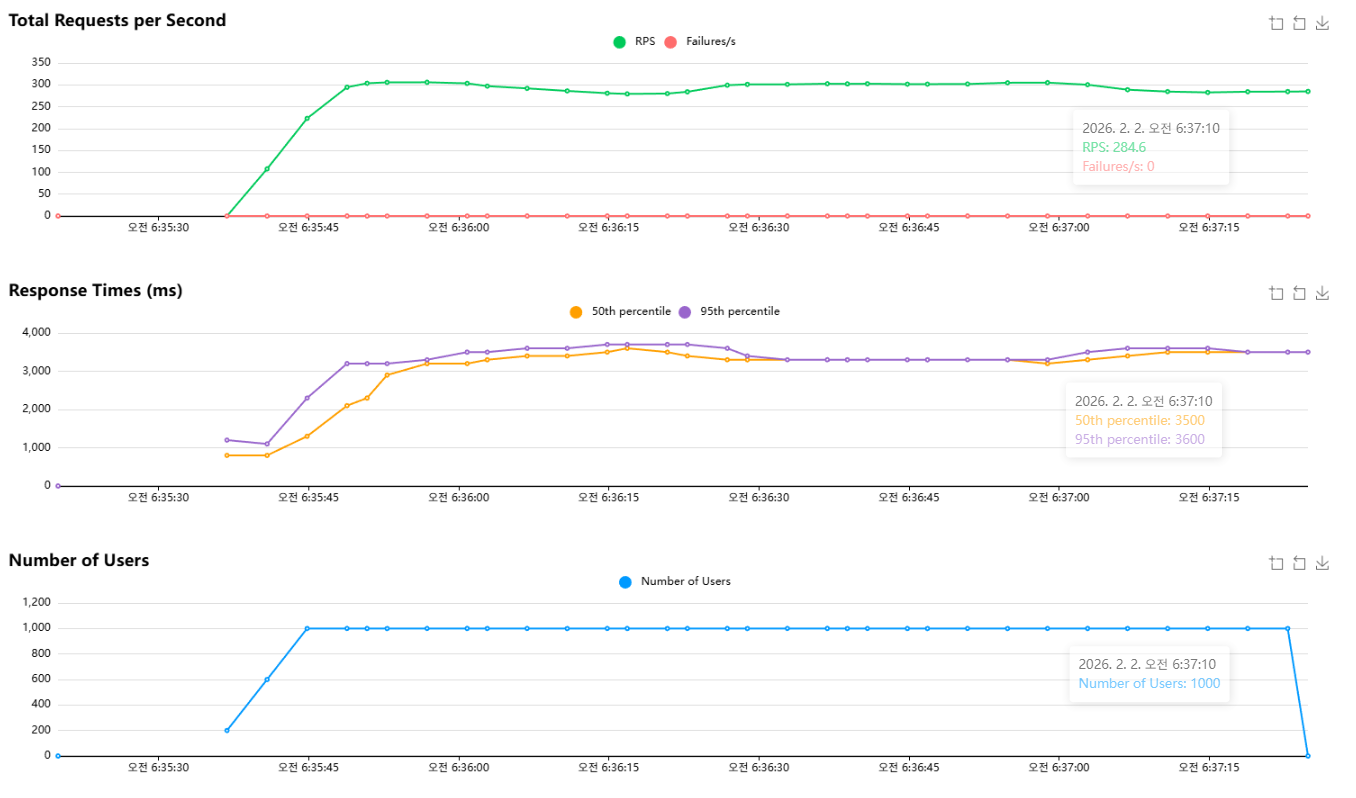
그리고 실패율이 상대적으로 안정되고, p95/p99도 10,000 유저 대비 훨씬 완만한 형태로 보였다.
이 결과로 볼 때, 인기글 쿼리 인덱스 적용으로 정렬/스캔 비용이 크게 완화되었고, 중간 부하 구간에서는 처리량이 눈에 띄게 개선됐다.
4-3. 결론
인기글 인덱스 튜닝으로 정렬/스캔 비용은 줄어 중간 부하(1,000명)에서는 처리량이 크게 개선됐지만, 조회수 증가 UPDATE는 여전히 단일 row 핫스팟 쓰기 병목이라 고부하(10,000명)에서는 커넥션 풀/스레드 포화로 다시 실패했다.
5. 샤딩 해보기
5-1 변경한 점
조회수 증가 로직 샤딩 카운터로 분리
기존 구현은 게시글 상세 조회 시 post.view_count = post.view_count + 1 업데이트가 발생했다. 트래픽이 몰리면 같은 post row를 계속 UPDATE하는 구조가 되고, 결국 row lock 경합과 InnoDB write 부담이 병목이 나는 상황이라고 생각했다.
그래서 post 테이블의 view_count 업데이트를 제거하고, 별도의 샤딩 카운터 테이블로 조회수 증가를 분리했다.
하나의 row에 쓰기가 몰리는 구조를 여러 row로 분산시키면 좋아지지 않을까라는 생각으로 시도해보았다.
테이블 구조 변경
post_view_counter_shard(post_id, shard_id, view_count) 형태로 테이블을 만들고, (post_id, shard_id)를 PK로 뒀다. 하나의 post에 shard 8개(0~7)가 존재하도록 구성했다.
조회수 증가 로직 변경
상세 조회 API에서 더 이상 post를 UPDATE하지 않고, shard_id를 랜덤으로 골라 해당 row만 증가시키도록 바꿨다.
PostServiceImpl
@Override
@Transactional
public PostDetailDto getPost(Long id) {
viewCountService.incrementView(id); // post 테이블 UPDATE 제거
Post post = postRepository.findById(id).orElse(null);
return PostDetailDto.from(post);
}ViewCountService
private static final int SHARD_COUNT = 8;
@Transactional
public void incrementView(Long postId) {
int shardId = ThreadLocalRandom.current().nextInt(SHARD_COUNT);
repo.increment(postId, shardId);
}
PostViewCounterShardRepository
@Modifying
@Query(value = """
UPDATE post_view_counter_shard
SET view_count = view_count + 1
WHERE post_id = :postId AND shard_id = :shardId
""", nativeQuery = true)
int increment(@Param("postId") Long postId, @Param("shardId") int shardId);의도
같은 게시글의 조회수가 몰려도 업데이트 대상 row가 8개로 분산되기 때문에, 단일 row에 락이 몰리는 핫스팟을 완화하려고 했다.
한계
쓰기 경합은 줄일 수 있어도, 읽기와 랭킹에서 비용이 커졌다.
조회수 조회 시 SUM(view_count)로 8개 shard를 합산해야 했다.
인기글처럼 정렬/랭킹이 필요한 경우 ORDER BY SUM(view_count) DESC 형태가 되어서 쿼리가 너무 복잡해질 것이라고 생각했다.
데이터 규모가 너무 커진다고 생각했다. 지금 게시글이 10만개인데 게시글 개당 8개라고 생각하면 80만개가 들어가야한다. 게시글이 늘어날 수록 카운터 테이블과 인덱스도 함께 커지기 때문에 계속 불어난다고 생각했다.
5-2. 부하 테스트 결과
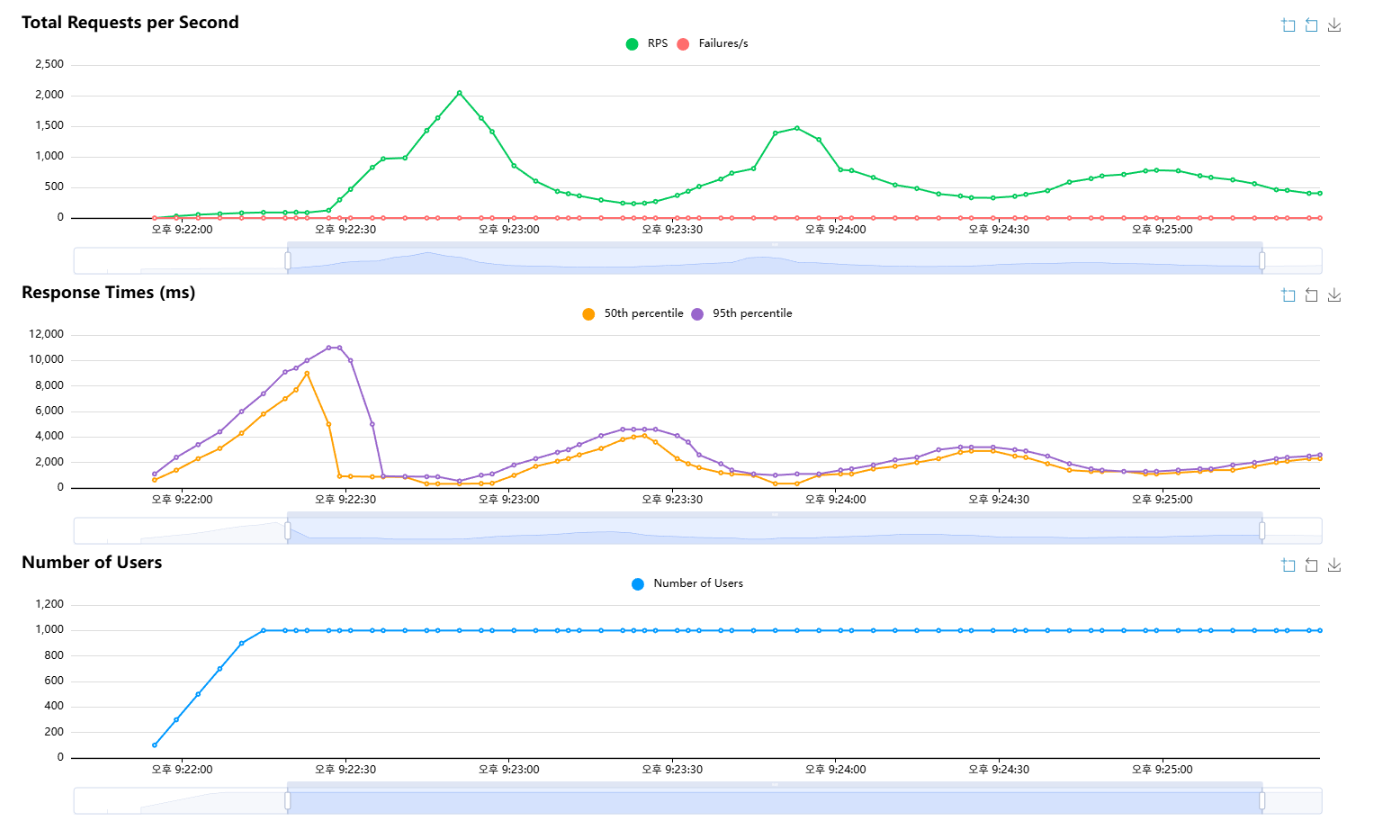
- 테스트 초반 응답 시간이 수 초~10초대로 급상승하는 구간이 존재했다.
- 이후 특정 시점부터 응답 시간이 급격히 내려가며, 동시에 RPS가 크게 상승하는 구간이 나타났다.
- 안정 구간 진입 이후에도 응답 시간과 RPS가 완만하게 오르내리는 파동이 반복됐다.
초반 급상승 => 급회복 => 안정 구간 파동패턴이 반복적으로 나타났다.
5-3. 왜 이렇게 나왔지?
포화 근처에서 시스템이 밀렸다가 회복되는 사이클로 해석하는 게 자연스럽다.
초반 급상승은 워밍업/콜드 상태 영향 가능성이 크다
테스트 시작 직후에는 JVM/DB/OS 캐시가 차지 않은 상태라 지연이 쉽게 튄다. 일정 시간이 지나면서 캐시가 채워지고 실행 경로가 안정화되면 응답 시간이 내려가서 이렇게 나왔다고 생각했다.
Locust(닫힌 모델) 특성
Locust는 요청 => 응답이 끝나야 다음 요청을 보내는 구조라, 서버가 느려지면 유저당 요청 빈도가 줄어 RPS가 내려가고, 잠깐 빨라지면 RPS가 다시 튄다.
그래서 응답 시간이 떨어지는 순간 RPS가 확 올라가는 모양이 만들어질 수 있다.
참고: 닫힌 모델 vs 열린 모델
5-4. Redis를 쓰기로 한 이유
샤딩 카운터는 DB에서 조회수 쓰기 핫스팟을 분산시키는 데는 도움이 됐지만, 구조적으로 한계가 있다고 생각했다.
-
조회수는 고빈도 쓰기인데 샤딩을 해도 조회 1회당 DB write 1회라는 건 바뀌지 않았다. 락 경합을 완화할 수는 있어도 쓰기 트래픽의 근본 비용은 계속 DB가 떠안게 됐다.
-
읽기에서 합산이 필요해졌고, 인기글처럼 정렬이 필요한 순간 너무 복잡해졌다.
SUM(view_count)기반 정렬은 쿼리 비용이 커지고, 결국 결과를 별도로 캐시하거나 집계 테이블로 머지하거나 랭킹을 미리 계산하는 작업이 필요해졌다.
Redis는 메모리 기반이라 INCR 같은 카운터 증가가 매우 가볍고, 랭킹은 Sorted Set으로 상위 N개 조회가 빠르다. 조회수처럼 쓰기 빈도가 극단적으로 높은 데이터와 인기글 조회를 DB보다 훨씬 단순한 형태로 처리할 수 있었다.
DB는 데이터의 정합성과 영속 저장에 집중시키고, 조회수/랭킹처럼 변동이 극심한 값은 Redis로 분리하는게 더 좋아보인다고 생각했다.
5-5. 결론
DB에서 조회수는 결국 쓰기 핫스팟이었고, 샤딩으로 락을 완화할 수는 있었지만 읽기 합산/랭킹과 충돌하면서 복잡도가 급격히 증가했다. 그래서 조회수/랭킹은 Redis 같은 인메모리 구조로 분리하는 방향이 더 현실적이라고 생각했다.
6. Redis로 요청당 DB UPDATE 제거
요청 경로에서 조회수 쓰기(UPDATE) 를 빼버리는 방식으로 바꿨다.
기존에는 게시글 상세 조회 요청이 들어올 때마다 DB에서 view_count = view_count + 1 같은 쓰기 트랜잭션이 매번 발생했다. 이 구조는 트래픽이 몰릴수록 DB가 락/redo/flush 비용을 계속 떠안게 되고, 결국 조회 API인데도 DB write 병목이 터지는 형태라고 판단했다.
그래서 조회수와 랭킹은 Redis로 처리하고, DB 반영은 나중에 하는것으로 생각을 했다.
6-1. 변경점
요청 경로에서 DB UPDATE를 제거했다
상세 조회 요청이 들어와도 더 이상 DB에 조회수 UPDATE를 하지 않게 바꿨다.
Redis에만 카운트를 올리도록 바꿨다.
조회수: HINCRBY (Hash)
랭킹: ZINCRBY (Sorted Set)
랭킹 쿼리를 DB 정렬에서 Redis ZSET으로 바꿨다
DB에서 인기글을 구하려면 ORDER BY view_count DESC LIMIT N을 계속 했어야 했다.
Redis ZSET은 점수 기반 정렬이 기본이어서, 상위 N개 조회가 구조적으로 유리하다고 생각했다.
정합성은 최종 DB 반영이 아니라 요청 경로 분리가 목표였다
이 단계에서 목표는 완벽하게 실시간으로 DB에 맞추기가 아니었다.
목표는 요청 경로에서 write를 제거해 병목을 없애는 것이었다.
UI에서 보여줄 조회수는 Redis에서 읽으면 된다.
DB 반영은 배치/스케줄로 나중에 합쳐도 된다.
6-2. 테스트 결과
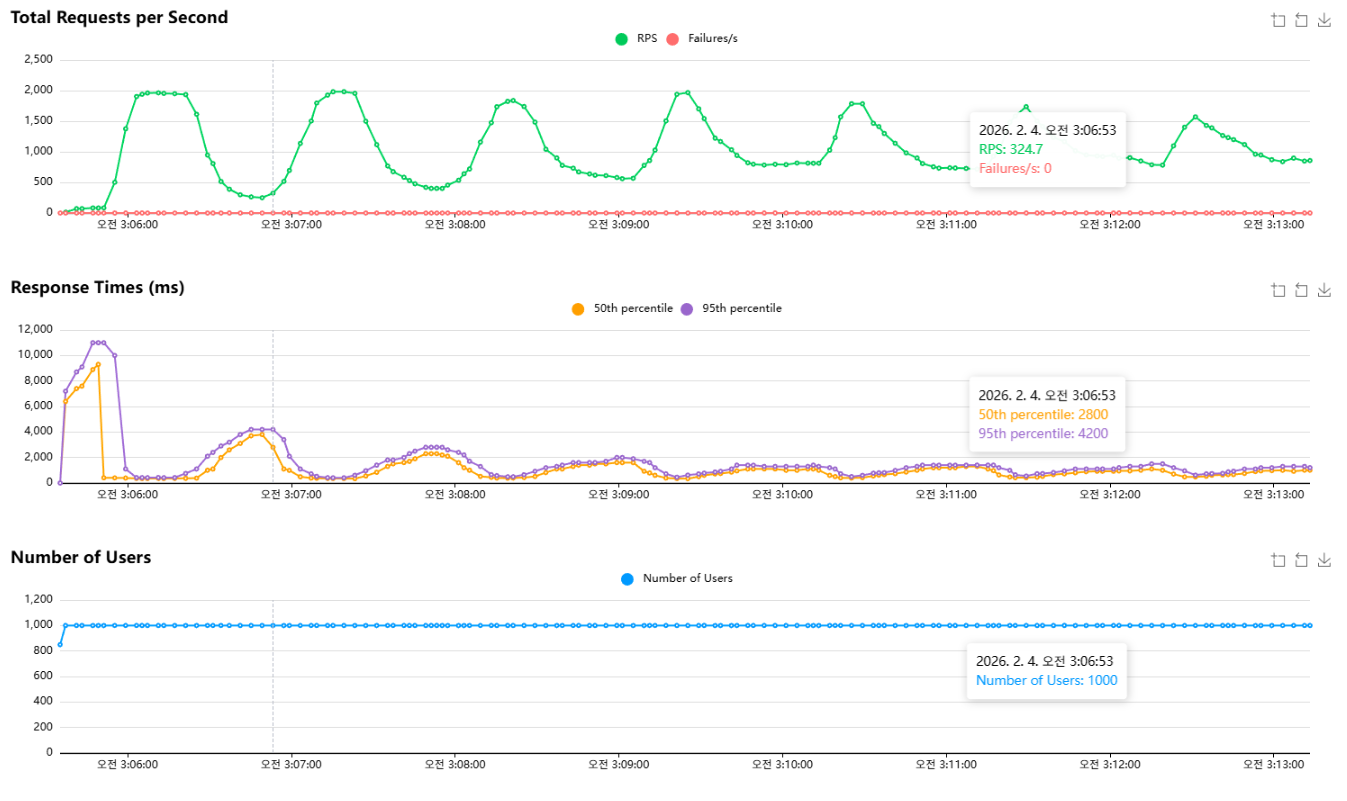
RPS 상승
Redis 적용 후 차트에서 피크 구간 RPS가 약 1,900~2,000 수준까지 올라간 구간이 확인됐다.
동일하게 1,000 유저 조건에서 진행했는데도, DB UPDATE를 제거하자 처리량 상한이 크게 올라갔다고 생각했다.
레이턴시가 급락하는 구간 존재
3시 6분쯤에는 지연시간이
p50 ≈ 360ms
p95 ≈ 430ms
수준까지 내려간 구간이 보였다.
쓰기 제거가 응답시간과 처리량에 반영됐다고 생각했다.
6-3. 근데 그래프가 왜 이렇게 출렁거릴까?
차트가 반복적으로 출렁이는 이유는, 이번 캡처들이 DB가 완전히 병목에서 해방된 상태는 아니었기 때문이라고 생각했다.
Hikari 풀 자체가 꽉 찼다
hikaricp.connections.max = 10

hikaricp.connections.active = 10

hikaricp.connections.idle = 0

hikaricp.connections.pending ≈ 182 ~ 190

풀 최대치(10)까지 항상 active가 꽉 찼다. idle(대기 커넥션)은 0이었다 커넥션을 못 빌려서 기다리는 스레드(pending)가 180명대까지 쌓였다.
조회수 UPDATE는 Redis로 빠졌지만, 상세 조회 자체가 DB SELECT를 계속 필요로 했고 (게시글/태그/작성자 등), 그 read 트래픽으로 커넥션 풀이 꽉 찼다고 생각했다.
Locust의 닫힌 모델
이 패턴은 Locust가 기본적으로 요청 => 응답 후 다음 요청을 보내는 닫힌 모델이라, 서버가 잠깐 느려지면 RPS가 같이 내려가고, 잠깐 빨라지면 RPS가 튀는 특성이 반영된 결과로 볼 수 있다.
그래서 서버가 느려져 응답이 밀리면, Locust가 초당 요청을 덜 보내게 되고 RPS가 내려가고
잠깐이라도 응답이 빨라지면 유저들이 한꺼번에 더 자주 때리면서 RPS가 확 올라간것같다.
6-4. 결론?
조회수 증가에서 요청당 DB UPDATE를 제거하자, 처리량이 눈에 띄게 올라갔다.
Failures/s가 0에 수렴하는 구간이 길게 유지되어, 쓰기 병목 패턴이 크게 줄었다고 봤다.
Actuator 지표에서 Hikari 풀(max=10)이 상시 포화(active=10, idle=0, pending 180~200) 상태였기 때문에, 병목이 완전히 사라진 것이 아니라 DB read/커넥션 풀이 병목이 됬다고 생각한다.
그래서 다음 단계는 Redis 도입 성공에서 끝이 아니라, DB 조회의 커넥션 점유 시간을 줄여서 병목을 완화시키는 게 목표이다.
7. 또 다른 병목
7-1. Read 병목
Redis로 조회수 UPDATE를 요청 경로에서 제거했지만, 병목이 완전히 사라진 것은 아니었다.
Actuator에서 Hikari가 active=max, idle=0, pending 180+ 상태로 포화된 것을 확인했다. 즉, 병목이 write에서 read로 이동했다고 판단했다.
Locust 통계에서도 GET /posts (list)가 다른 API보다 지연이 크게 튀는 순간이 있었고, 그 타이밍에 전체 RPS가 함께 꺾였다. 목록(list)이 DB 커넥션을 오래 점유하면서 풀 포화를 유발했다고 해석했다.
7-2. 쿼리 인덱스 추가
목록 API는 PUBLISHED 필터와 정렬을 사용한다.
CREATE INDEX idx_post_status_created_at_id ON post (post_status, created_at, post_id);튜닝 전
-> Limit: 50 row(s) (cost=5704 rows=50) (actual time=103..103 rows=50 loops=1)
-> Sort: p.created_at DESC, p.post_id DESC, limit input to 50 row(s) per chunk
(cost=5704 rows=49574) (actual time=103..103 rows=50 loops=1) -> Index lookup on p...튜닝 전에도 조건 자체는 인덱스를 탔지만, 정렬(created_at DESC)을 만족시키지 못해 Sort 단계를 진행한것 같다.
튜닝후
-> Limit: 50 row(s) (cost=5701 rows=50) (actual time=0.3..0.318 rows=50 loops=1)
-> Filter: (p.post_status = 'PUBLISHED') (cost=5701 rows=49549) (actual time=0.299..0.315 rows=50 loops=1)
-> Index lookup on p using idx_post_status_created_a...인덱스가 (post_status → created_at → post_id) 순서로 잡히면서, 옵티마이저가 정렬을 별도 Sort로 처리하지 않고 인덱스 순서로 해결할 수 있는 형태가 됐다.
7-3. 적용후 부하 테스트 결과
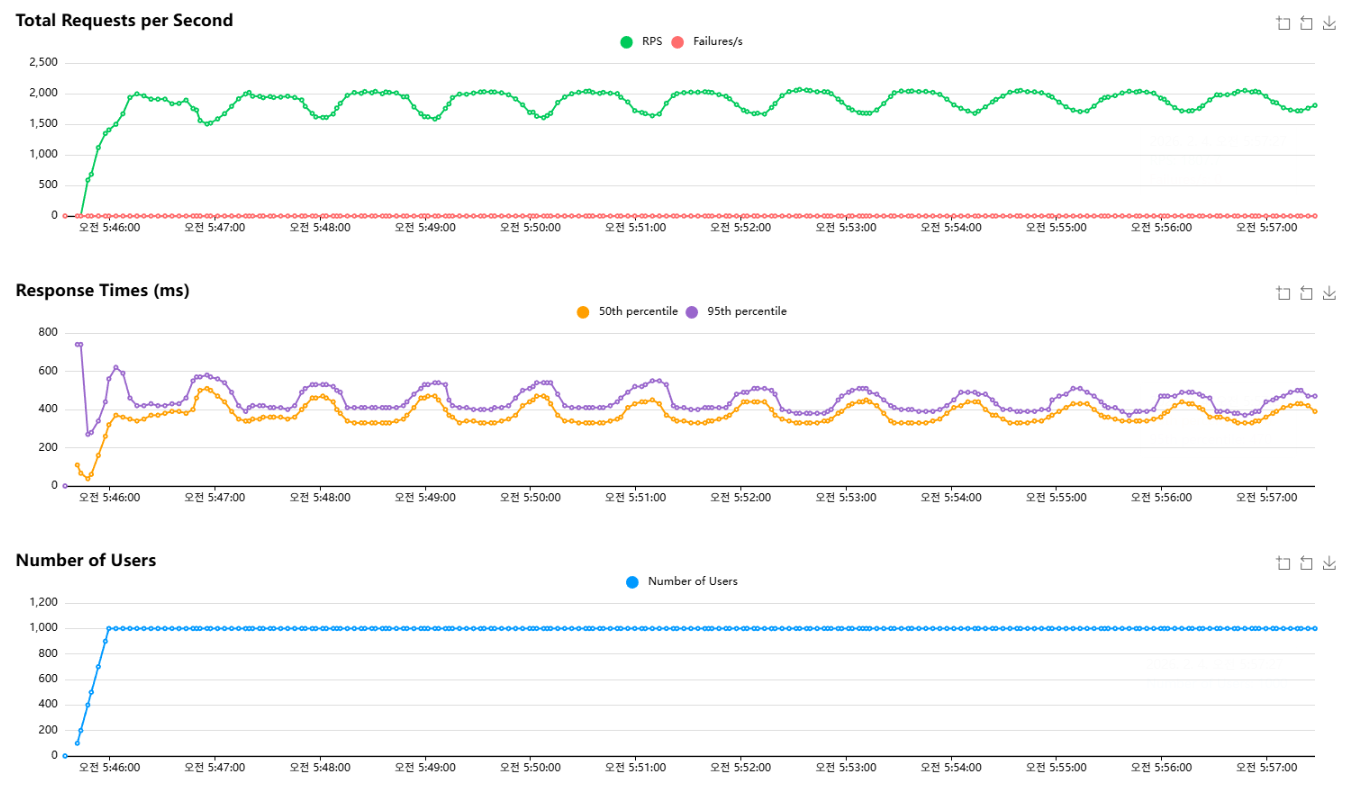
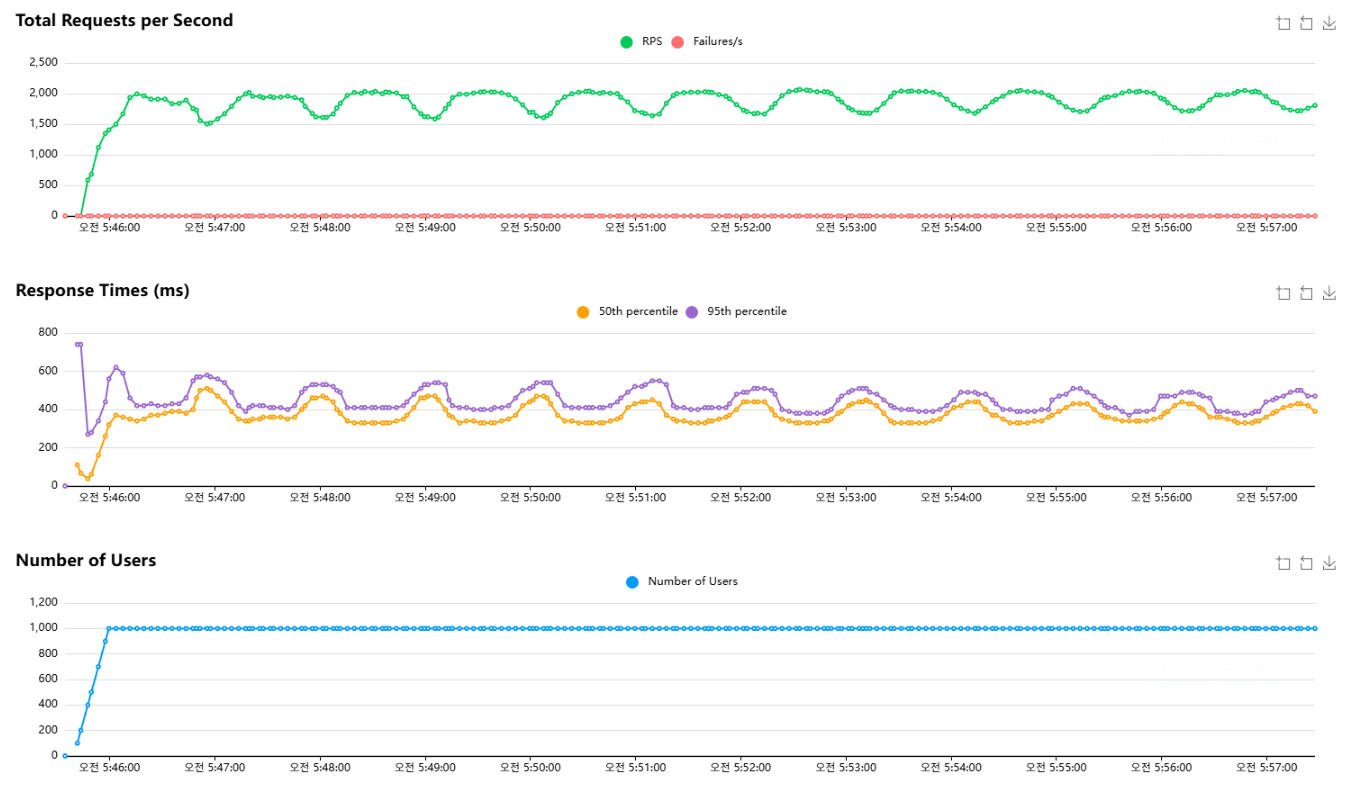
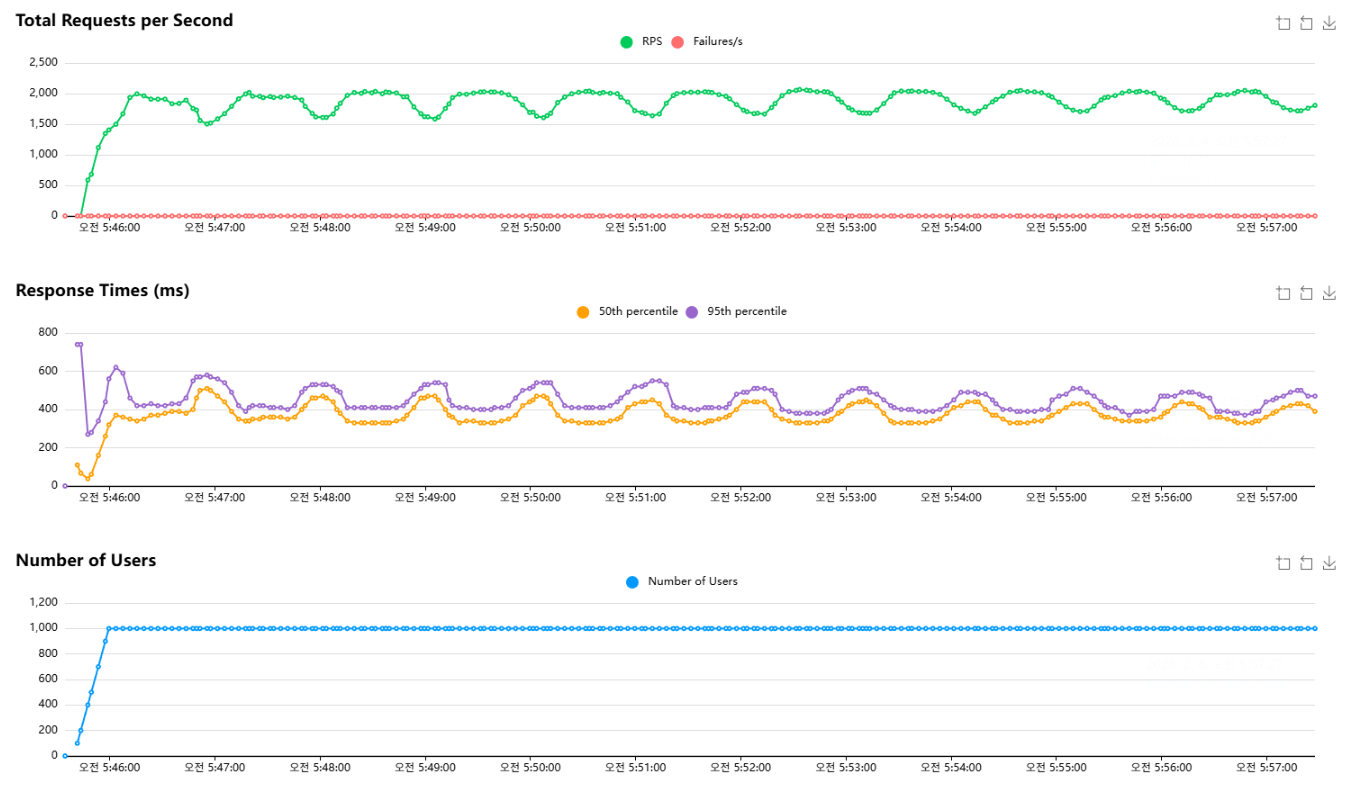
인덱스 적용 후에는 failures가 0으로 유지된 상태에서 RPS가 1,700~2,100 범위로 훨씬 안정적으로 유지되었고, p50/p95 지연도 300~500ms대에서 안정적으로 관측되었다.
Locust 통계에서 GET /posts (list)는 median이 1초대, p95가 4~11초까지 튀었고, detail은 p95가 1~2초대로 상대적으로 낮았다.
그래프가 주기적으로 출렁이는 형태는 남아있었는데, 이는 Locust 시나리오에서 list를 일정 주기로 refresh하는 요청이 순간적으로 몰리면서 read 경로가 잠깐 포화되고, 닫힌 모델 특성상 RPS가 같이 출렁이는 패턴이라고 생각을 하고 있다.
실제로 Locust시나리오에 list를 60초 주기로 refresh하도록 설정되어있어 60초마다 list 요청이 몰리는 상태였다.
def _refresh_post_pool(self, force=False):
now = time.time()
if not force and (now - self._last_refresh) < REFRESH_LIST_EVERY_SEC:
return8. 정리
처음 병목은 단순했다. 상세 조회가 들어올 때마다 view_count = view_count + 1 UPDATE가 발생했고, 트래픽이 몰리면 특정 post row에 쓰기가 집중되면서
InnoDB row lock wait => 커넥션 점유 시간 증가 => Hikari pending 증가 => 지연 폭증/실패로 이어졌다.
-
상한(Tomcat/Hikari) 튜닝은 실패를 늦게 만들 뿐이었다. DB 병목이 남아 있으면 active가 max에 붙고, 결국 connection timeout으로 무너졌다.
-
DB 인덱스/트랜잭션 정리는 중간 부하에서는 분명 효과가 있었지만, 조회수 UPDATE라는 본질적인 쓰기 핫스팟은 고부하에서 한계가 왔다.
-
샤딩 카운터는 쓰기 락 경합을 분산시키는 데는 도움이 됐지만, 읽을 때 합산(SUM)과 랭킹(ORDER BY SUM)을 만들기가 너무 복잡해졌다.
그래서 최종적으로 선택한 방식이 Redis로 요청 경로에서 DB UPDATE를 제거하는 것이었다. 그 결과 failures가 0으로 수렴했고, 처리량 상한도 눈에 띄게 올라갔다.
마지막으로, 인덱스를 정렬 패턴에 맞춰 추가하면서 list의 Sort 비용을 줄였고, 그 결과 RPS와 지연이 더 안정적인 형태로 바뀌었다. 그래프에 남아 있는 출렁임은 Locust 시나리오에서 list refresh가 일정 주기로 몰리는 구조가 반영된 결과라고 생각했다.
개선 전
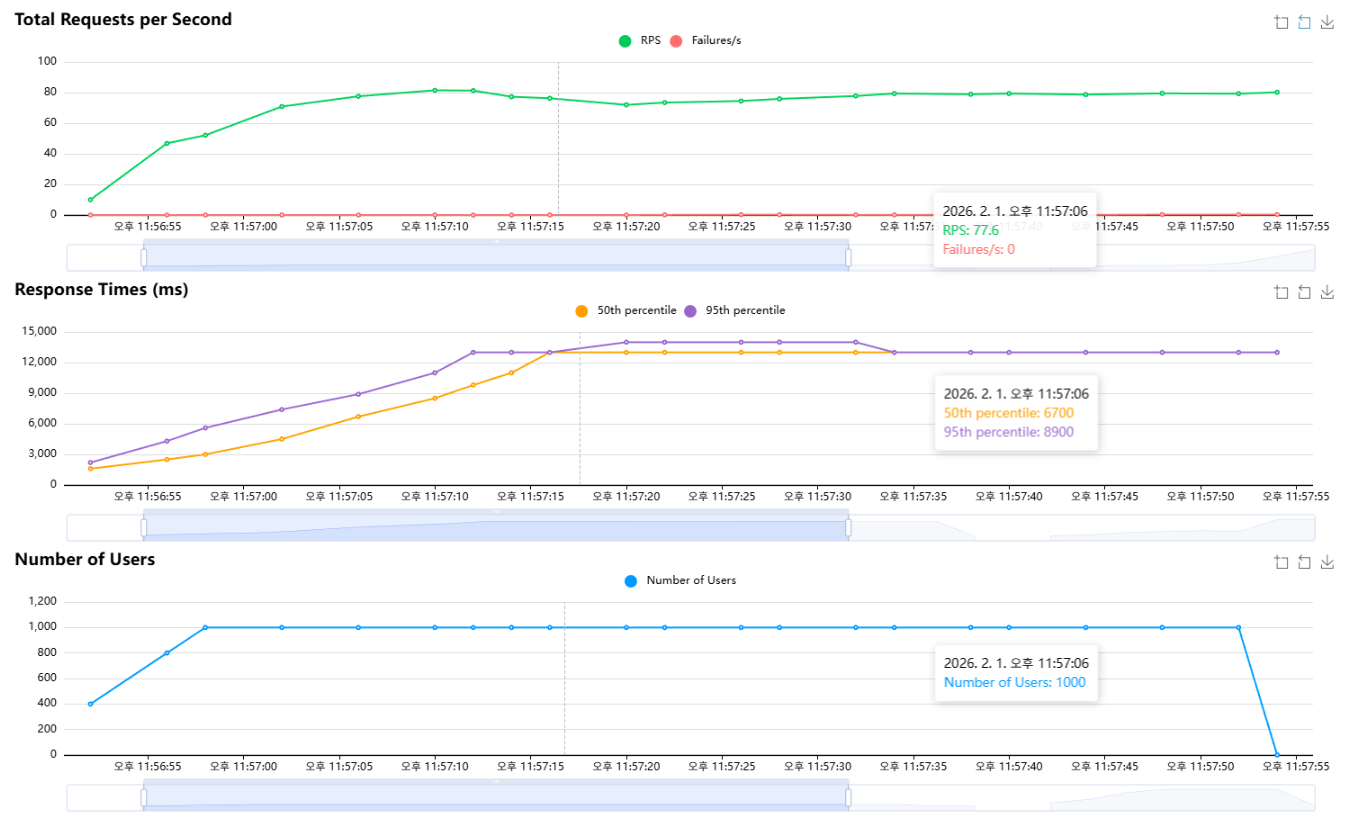
개선 후