0. 당시 상황
블로그 서버를 만들고 있었고, 인기글 기능을 추가한 뒤 부하 테스트를 돌리고 있었다.
테스트 시나리오는 단순했다.
상세 조회 API는 조회할 때 조회수(view_count)를 1 증가시킨다.
인기글 API는 view_count DESC 로 상위 N개를 가져온다.
0-1. 구현 흐름
- 게시글 상세 조회:
GET /posts/{id} - 조회수 증가: 상세 조회 시
view_count = view_count + 1 - 인기글(랭킹):
ORDER BY view_count DESC LIMIT 20
0-2. 실험 환경
- 앱: Spring Boot + JPA + MySQL + Tomcat
- 커넥션 풀: HikariCP
- 부하 도구: Locust
- 관측: access log, actuator metrics, MySQL
0-3. 스펙
- CPU: 13th Gen Intel(R) Core(TM) i5-13500
- DB 분리 여부: 로컬 동일 머신
- Hikari 설정 maximumPoolSize: 10
0-4. (수정) 테스트 데이터 규모 변경 3 => 약 10만개
처음에는 게시글 테이블에 데이터가 거의 없는 상태(3건 수준)로 테스트했다.
그 상태에서는 인기글 정렬이든, 리스트 조회든 별로 티가 나지 않았다.
그래서 실서비스에 가까운 조건을 만들기 위해 게시글 데이터를 약 100,000건으로 늘려서 다시 테스트했다.
ORDER BY view_count DESC LIMIT 20는 데이터가 많아질수록 정렬/스캔 비용이 커진다.- 조회수 UPDATE 핫스팟 문제뿐 아니라 인기글 SELECT 자체도 병목일 수도 있다.
이 글은 약 10만 건 기준으로 병목을 관측/추적한 내용으로 수정했다.
1. 부하 테스트 설계
실제 서비스는 조회가 특정 글/특정 컨텐츠에 몰릴 것이라고 생각했다. 그래서 핫스팟을 의도적으로 만들었다.
1-1. 핫스팟 만들기
특정 게시글 1~2개에 조회 트래픽의 80% 집중
나머지는 랜덤 게시글로 트래픽을 조절했다.
1-2. 성공/실패 기준
Locust
failure rate(실패율)
timeout 발생 여부/개수
p95/p99 응답시간
RPS 변화(피크 찍고 떨어지는지)
서버
access log에서 엔드포인트별 응답시간(%D)이 튀는지
DB(MySQL/InnoDB)
row lock wait / deadlock 흔적
UPDATE가 병목이 되는지
풀(HikariCP)
pending(대기 커넥션) 증가 여부
pool timeout 발생 여부
2. Locust failures가 뜨기 시작했다
2-1. Break test (10,000명)
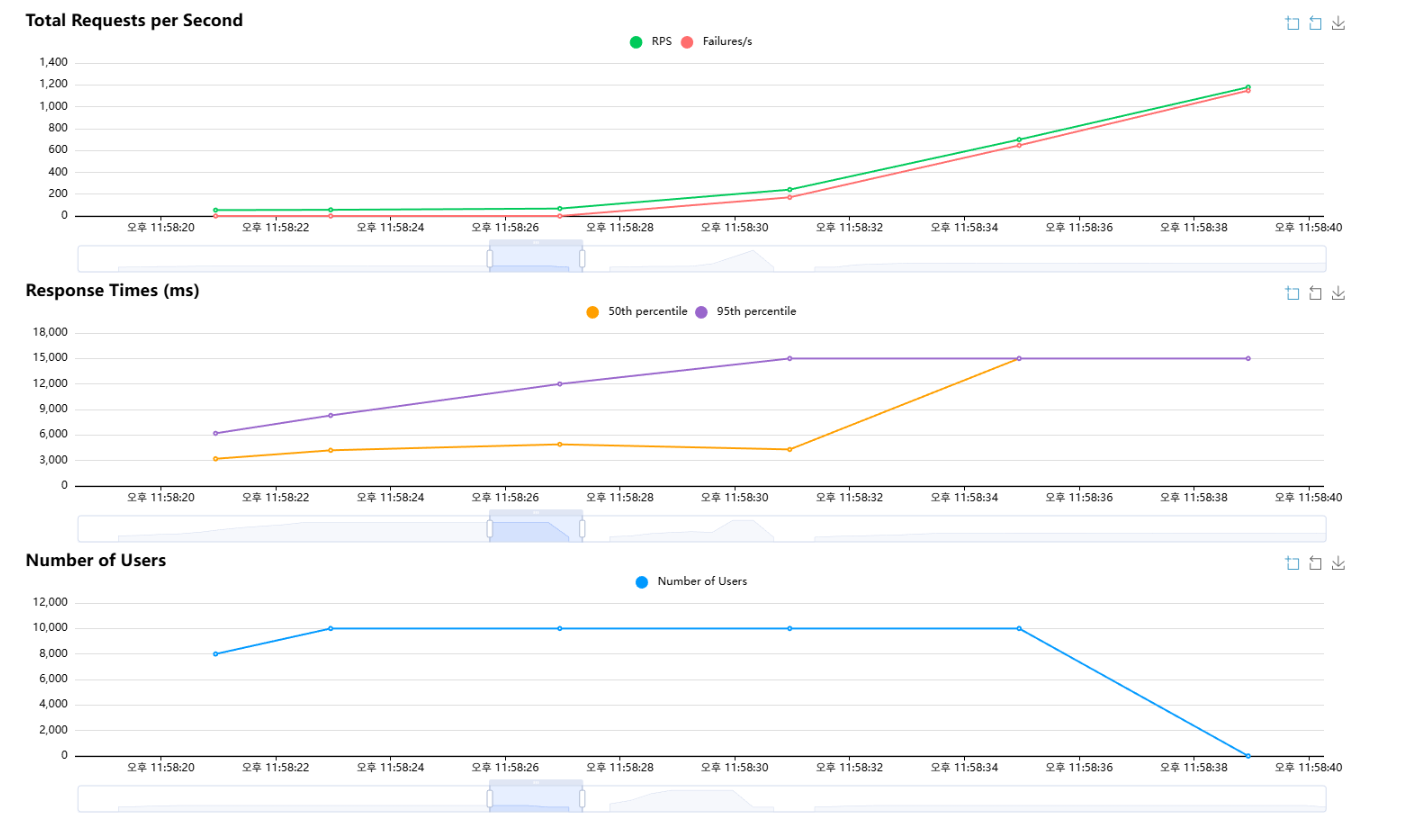
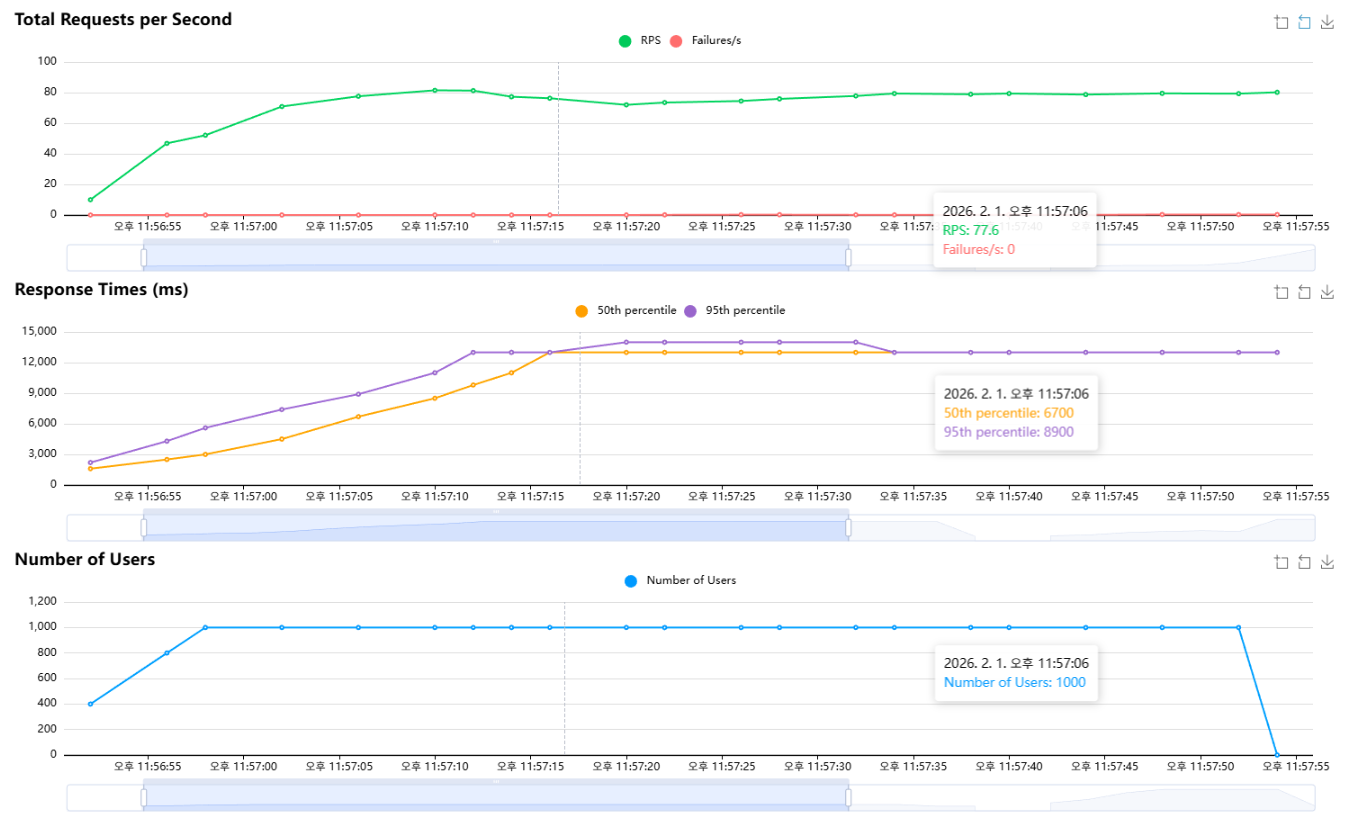
- 유저 수를 10,000까지 올리자 Failures/s가 RPS와 거의 비슷한 속도로 증가했다.
- 원인 분석은 관측 가능한 구간(1,000명 테스트)에서 진행했다.
2-2. Observation test (1,000명)
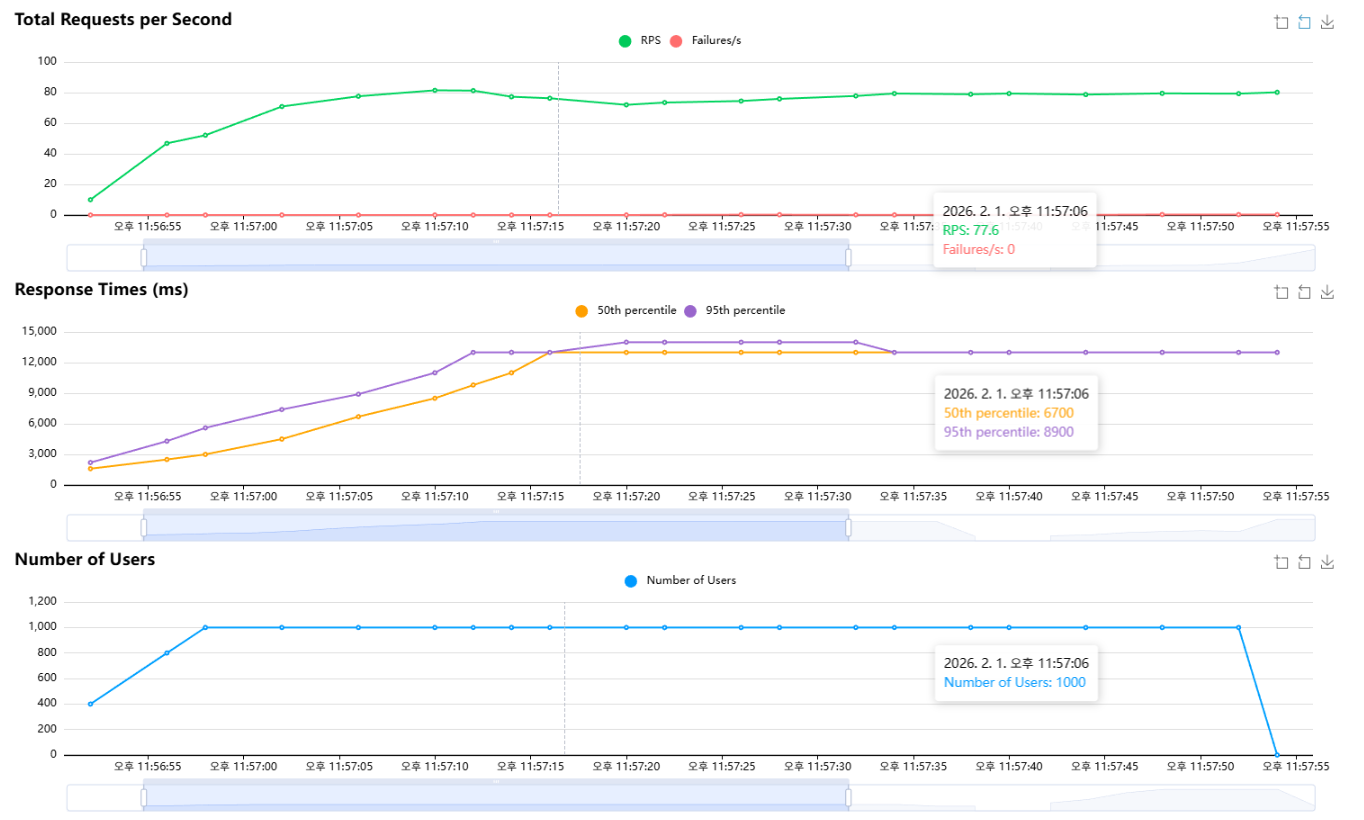
- 10,000명 구간은 실패율이 너무 높아 내부 병목을 관측하기 어려웠다.
- 그래서 유저 수를 1,000명으로 낮추고 동일 시나리오로 재현하여, 실패 없이도 지연이 급증하는 구간을 확보했다.
- 이후의 access log / HikariCP / InnoDB / Tomcat 메트릭 분석은 1,000명 테스트를 기준으로 정리했다.
2-3. 이 failures는 어디에서 나온걸까
Locust의 실패는 서버가 500을 주는 것 같은 HTTP 실패만 의미하지 않는다. 연결 자체 실패도 failures로 묶어서 보여준다.
그래서 나는 제일 먼저 살펴본것은 3가지 였다
- 서버는 요청을 받았고, HTTP 에러를 돌려줬다
- 서버가 너무 느려서 timeout으로 응답을 못 받았다
- 아예 TCP 연결이 성립하지 않았다 (요청이 서버까지 못 갔다)
3. 원인 찾기
관측 가능한 1,000명 재현 테스트를 기준으로 정리했다.
3-1. access log 확인
내가 먼저 확인한 것은 access log였다.
access log에 찍히면 요청이 톰캣까지는 도착했다. 라고 생각하기 떄문이다.
access log에 안 찍히면 애초에 연결이 안 됐거나(서버까지 못 왔음), 톰캣 앞단에서 끊겼다쪽이라고 생각했다.
access log는 아래와 같이 설정했다.
server.tomcat.accesslog.enabled=true
server.tomcat.accesslog.directory=logs
server.tomcat.accesslog.prefix=access_log
server.tomcat.accesslog.suffix=.log
server.tomcat.accesslog.pattern=%h %l %u %t "%r" %s %b %D
server.tomcat.accesslog.buffered=false그리고 확인해보니 아래와 같이 모두 200 응답만 찍혀 있었다.
access log는 톰캣이 받아서 처리한 요청만 찍는다. 연결 단계에서 거절된 요청은 애초에 로그에 남지 않는다.
GET /api/v1/posts?page=0&size=50 HTTP/1.1" 200 562 12155
GET /api/v1/posts?page=0&size=50 HTTP/1.1" 200 562 13103
GET /api/v1/posts?page=0&size=50 HTTP/1.1" 200 562 13111
.
.
.
GET /api/v1/posts?page=0&size=50 HTTP/1.1" 200 564 643916
GET /api/v1/posts?page=0&size=50 HTTP/1.1" 200 564 641821
GET /api/v1/posts?page=0&size=50 HTTP/1.1" 200 564 633855여기서 생각한건 서버가 받은건 대부분 정상 처리됬는데 Locust는 failures가 40%정도였다. 서버가 500을 한게 아니고 서버에 도달하지 못했거나 도달 전에 끊겼다고 생각을 하였다.
3-1-1. %D가 계속 증가
access log에는 요청 처리 시간(%D = ms단위) 도 같이 찍히게 해두었다. (요청을 받아서 응답을 완료할 때까지 처리 시간)
부하가 올라갈수록 access log에 200은 유지되지만 %D가 계속 커지는 현상을 발견하였다.
이것을 보고 서버는 정상 응답을 주긴 주지만, 점점 더 오래걸리며 처리가 제대로 되지 않는 것을 확인하였다.
- 처리 시간이 커지니까 (%D 증가) =>
- 워커 스레드가 더 오래 잡고 있으면 (스레드가 고갈되니까) =>
- threads, connections가 상한에 도달함 =>
- 그때부터 연결이 거절됨.
처리 시간이 증가하니까 워커 스레드가 더 오래잡고있게 되고, 오래 잡으니까 스레드가 상한에 도달하게 된다. 그때부터 연결이 거절될 수 있다고 생각하게 되었다.
3-2. Locust failure 확인
access log 다음으로 본 건 Locust failures 상세였다.
실패 메시지는 아래와 같았다.

HTTP 요청을 보내고 500을 받은 게 아니다. TCP 연결 자체가 성립하지 않았다.
그래서 access log에 안 찍히는 게 정상이라고 생각했다.
애플리케이션이 아닌 서버에서 새 연결을 받아줄 여유가 없었던 상태였다고 생각했다.
4. 그럼 왜 connection refused가 났을까?
localhost:8080에서 connection refused가 나오는 대표 원인은 보통 이거라고 한다.
- 해당 시점에 8080 리스너가 없었다 (프로세스 죽음/재시작/포트 변경)
- 리스너는 있지만 Tomcat 리소스(threads/maxConnections)가 포화되어 새 연결이 거절되는 상태
- 로컬 환경 특수 이슈(방화벽/보안SW 등)
5. 8080 리스너 확인
아래 순서로 확인했다.
5-1. 8080 리스닝 PID확인
netstat -ano | findstr :8080- 결과:
LISTENING 49260
5-2. PID가 뭔지 확인:
tasklist /FI "PID eq 49260"- 결과:
java.exe 49260
5-3. 이 java.exe 가 내 서버인지 확인
wmic process where "ProcessId=49260" get ProcessId,Name,ExecutablePath,CommandLine /format:list- 결과: CommandLine에 프로젝트
classpath랑com.example.blog.BlogApplication이 찍혔다.
8080은 내 스프링 서버가 맞았다.
6. 원인 생각 (앱, 풀, DB)
나는 아래 3개로 원인을 생각해보았다.
6-1. 애플리케이션 CPU/GC 병목
CPU가 100%에 붙거나
GC가 길게 발생하거나
스레드가 특정 락에 묶이거나
6-2. 커넥션 풀 병목(Hikari)
DB가 느려지면 커넥션이 반환이 안 되고
결국 요청 스레드가 커넥션 기다리다가 잠듦
결과적으로 API가 타임아웃/실패
6-3. DB(InnoDB) 락/쿼리 병목
- 상세 조회마다 실행되는 쿼리:
UPDATE post SET view_count = view_count + 1 WHERE id=?
특정 게시글에 트래픽이 몰리면 같은 row를 동시에 update
InnoDB row lock wait 증가 => 트랜잭션 지연 => 풀 대기 증가
- 인기글 쿼리:
ORDER BY view_count DESC LIMIT 20
데이터가 10만 건이라서 인덱스 구성에 따라 정렬/스캔 자체가 병목이 될 수 있다.
인덱스가 없으면 큰 지연이 일어날 수 있다.
7. 병목이 일어나는 시나리오
한번 병목이 일어나는 시나리오를 생각해보았다.
- 요청이 들어온다
- 톰캣 worker thread가 처리한다
- 처리 중 DB 작업에서 막힌다(락/슬로우쿼리/커넥션풀 대기)
- worker thread가 대기 상태로 점유된다
- 어느 순간 톰캣의 처리 스레드가 꽉 찬다
- 새 연결은 대기열로 쌓이다가, 클라이언트에서 timeout/거부 같은 형태로 failures가 생겨난다.
DB 대기 → 애플리케이션 스레드 점유 → 새 연결을 못 받음
8. 원인 추적 결과 정리
나는 크게 3가지를 확인하였다.
8-1. HikariCP(커넥션풀)에 대기열이 생기나?
HikariCP 메트릭 찍는방법
active(사용 중 커넥션) = 10 (모두 사용중)

idle(남은 커넥션) = 0 (없음)

pending(커넥션 기다리는 스레드 수) = 188~190

pool timeout 발생 여부 = 0 (Hikari의 connectionTimeout으로 실패한 건수는 관측되지 않았다)

active가 max(10)에 고정되고 idle은 0이고 pending은 계속 증가했다. 요청 스레드가 DB 커넥션을 못 얻고 있다는 뜻이라고 생각했다.
pending이 190까지 올라간 걸 보면, 커넥션 대기가 엄청났고, 일부 요청은 Hikari timeout까지 가지기 전에 톰캣 연결 단계에서 실패했을 것 같다.
8-2. InnoDB row lock wait로 병목 확인
조회수 증가가 UPDATE post SET view_count=view_count+1 형태면,
핫스팟 트래픽에서는 같은 row에 업데이트가 몰린다.
8-2-1. InnoDB Row Lock Wait확인
부하 테스트 직후 MySQL 상태 변수에서 아래 값을 확인했다.
SHOW GLOBAL STATUS LIKE 'Innodb_row_lock%';| variable_name | value |
|---|---|
| Innodb_row_lock_current_waits | 1 |
| Innodb_row_lock_time | 3056796 |
| Innodb_row_lock_time_avg | 25 |
| Innodb_row_lock_time_max | 140 |
| Innodb_row_lock_waits | 118284 |
Innodb_row_lock_waits 는 행 락 대기 발생 횟수이고, Innodb_row_lock_time 은 누적 대기 시간이다. 핫스팟 UPDATE가 반복되면 이 값들이 빠르게 증가한다.
조회수 UPDATE가 같은 row에 몰리면서 락 경합이 실제로 발생했고, 그 대기가 커넥션 반환 지연과 pending 증가로 이어진 것 같다.
8-2-2. 실제로 시간이 많이 든 쿼리
슬로우/요약에서 쿼리 분포를 보니, 가장 비중이 큰 쿼리가 조회수 UPDATE였다.
SELECT
DIGEST_TEXT,
COUNT_STAR,
ROUND(SUM_TIMER_WAIT/1e12, 3) AS total_sec,
ROUND(AVG_TIMER_WAIT/1e12, 6) AS avg_sec
FROM performance_schema.events_statements_summary_by_digest
ORDER BY SUM_TIMER_WAIT DESC
LIMIT 20;
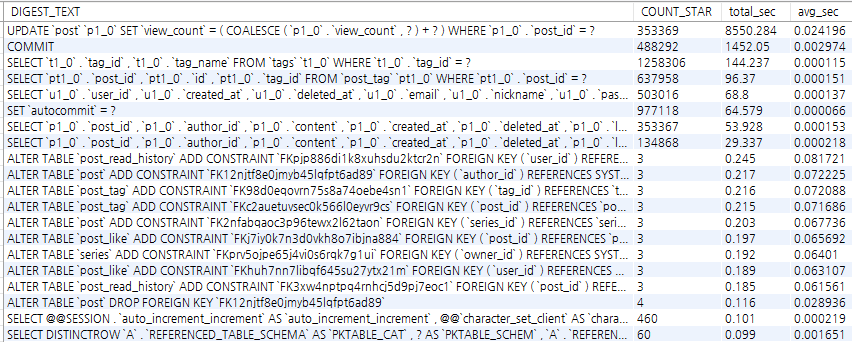
이 상황은 인기글/상세조회가 읽기처럼 보여도, 조회수 때문에 결국 쓰기 병목이 된 것 같다.
8-2-3. 이게 왜 Locust failures / %D 증가 / Hikari pending으로 이어졌을까?
DB에서 row lock 대기가 늘어나면, 트랜잭션이 오래 잡히고 커넥션이 늦게 반환된다.
- DB 락 대기 커지면 => 커넥션 반환 지연 커짐
- 커넥션 반환 지연 커짐 => Hikari active=10(고정), idle=0, pending 약 190
- pending(대기 스레드) 커짐 => 요청 처리시간 증가(access log의 %D 폭증)
- 처리 스레드가 대기로 묶이면 => 결국 일부 요청은 connection refused, timeout로 Locust 실패로 측정됨.
이 문제는 DB 락 대기가 애플리케이션 스레드/커넥션풀을 잠그면서 생긴 리소스 병목이었다.
8-3. 톰캣/서버 메트릭 확인
Actuator에서 Tomcat 메트릭을 찍어보니:
tomcat.threads.busy = 200

tomcat.threads.current = 200

워커 스레드가 200개 전부 바쁘다. (스레드 풀 고갈)
그리고
tomcat.connections.current = 8192

tomcat.connections.keepalive.current = 8192 (열려있는 연결이 keep-alive로 살아있는 상태)

tomcat.threads.config.max = 200

tomcat.connections.config.max = 8192

threads.busy(200) == threads.config.max(200)
connections.current(8192) == connections.config.max(8192)
tomcat.threads.busy=200 이고 tomcat.threads.config.max=200 이었다.
톰캣 워커 스레드 풀이 상한에 도달해 더 이상 요청을 처리할 여유가 없었다.
또한 tomcat.connections.current=8192 와 tomcat.connections.config.max=8192 가 똑같았다.
동시 연결이 설정 상한까지 차서 새 연결은 OS/Tomcat 단계에서 거절될 수 있는 상태였다.
- DB 락 대기 때문에 요청 처리가 느려짐
- 느려지니 커넥션이 오래 열려있음(keep-alive 포함)
- 스레드는 DB 대기 상태로 점유됨
- 결국 톰캣은 threads도 상한, connections도 상한
- 그 순간부터 신규 연결은 거절/실패로 되고, 그게 Locust의 WinError 10061로 관측된 것 같다.
Tomcat 메트릭 사용 커맨드
curl.exe -s "http://localhost:8081/actuator/metrics/tomcat.threads.busy"
curl.exe -s "http://localhost:8081/actuator/metrics/tomcat.threads.current"
curl.exe -s "http://localhost:8081/actuator/metrics/tomcat.connections.current"
curl.exe -s "http://localhost:8081/actuator/metrics/tomcat.connections.keepalive.current"
curl.exe -s "http://localhost:8081/actuator/metrics/tomcat.threads.config.max"
curl.exe -s "http://localhost:8081/actuator/metrics/tomcat.connections.config.max"9. 정리
9-1. 증상
- InnoDB row lock wait 증가
- 커넥션 반환 지연
- pending 누적
- 처리 지연이 누적되면서 톰캣 스레드/커넥션이 상한 도달
DB 락대기 => 풀 대기 => 톰캣 리소스 X => 클라 연결 실패
9-2. 결론
조회수 UPDATE는 핫스팟 트래픽에서 DB row lock 경합을 만든다
그 결과 DB에서 끝나지 않고, Hikari pending, %D (요청시간) 폭증, Tomcat threads/connections 상한까지 연쇄로 번진다
그래서 Locust failures는 연결 레벨에서 거절로 관측될 수 있다.
9-3. 개선 과정
개선 과정은 다음 글에 정리하겠습니다.
