Fashion MNIST 이미지 분류 - (USE 로지스틱 회귀, SGD, ANN , DNN, CNN)
들어가며
이미지를 분류할 수 있는 다양한 머신러닝, 딥러닝 방법들이 있다.
이 글에서는 의류 데이터인 Fashion MNIST를
로지스틱 회귀, SGD ,ANN, DNN, CNN를 사용하여 분류하고자 한다.
Fashion MNIST 데이터셋 살펴보기
#데이터 로드
from tensorflow import keras
(train_input , train_target) , (test_input , test_target) = keras.datasets.fashion_mnist.load_data()
#데이터 크기 파악
print(train_input.shape ,train_target.shape ) #(60000, 28, 28) (60000,)
print(test_input.shape ,test_target.shape ) #(10000, 28, 28) (10000,)
#데이터의 타겟값 보기
print([train_target[i] for i in range(10)]) [9, 0, 0, 3, 0, 2, 7, 2, 5, 5]
#각 타겟값 별 데이터의 양 확인
import numpy as np
print(np.unique(train_target, return_counts = True))
#(array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=uint8), array([6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000]))
Fashion MNIST data set의 이미지 크기는 28*28이며,
train data set 60,000개 & test data set 10,000개가 있다.
타깃은 0~9까지 10개의 label로 구성되며, 각 레이블은 6000개씩 data를 가지고 있다.
#데이터 이미지로 보기
import matplotlib.pyplot as plt
fig, axs = plt.subplots(1,10, figsize=(10,10))
for i in range(10):
axs[i].imshow(train_input[i], cmap='gray_r')
axs[i].axis('off')
plt.show()
출력📺:

각 레이블 별 이미지는 다음과 같다.

USE: 로지스틱 회귀
로지스틱 회귀(logistic regression)는 activation 함수를 sigmoid로 이용하여 분류하는 방식이다.
이미지 전처리 (28*28 2차원 배열 이미지를 -> 1배열로 변환)
from sklearn.linear_model import LogisticRegression
train_scaled =train_input.reshape(-1,28*28)
test_scaled =test_input.reshape(-1,28*28)
print(train_scaled.shape) # (60000, 784)📺:
로지스틱 회귀로 분류
model = LogisticRegression()
model.fit(train_scaled , train_target)
print("train score: " ,model.score(train_scaled , train_target))
print("test score: ",model.score(test_scaled , test_target))📺:
train score: 0.8632
test score: 0.8412
USE: SGD
SGD(Stochastic Gradient Descent)는 확률적 경사하강법으로
램덤하게 데이터를 하나씩 뽑아서 LOSS 함수를 만들고 Gradient Descent를 빠르게 진행하는 방법이다.
전처리 (train set, test set 특성을 표준화 전처리)
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_scaled)
train_scaled = ss.transform(train_scaled)
test_scaled = ss.transform(test_scaled)SGD로 분류
from sklearn.linear_model import SGDClassifier
#model 만들기
model = SGDClassifier(loss = 'log') # loss 함수를 log로 지정
train_score = []
test_score = []
classes = np.unique(train_target)
#epoch 300으로 학습 (300번 학습)
for epoch in range(300):
model.partial_fit(train_scaled, train_target, classes=classes)
train_score.append(model.score(train_scaled, train_target))
test_score.append(model.score(test_scaled, test_target))학습과정 그래프로 보기
import matplotlib.pyplot as plt
x=np.arange(0,300)
fig, ax1 = plt.subplots()
ax1.plot(x, train_score, color='r')
ax2 =ax1.twinx()
ax2.plot(x, test_score)
plt.xlabel('epoch')
plt.ylabel('moodel score')
plt.show()📺:
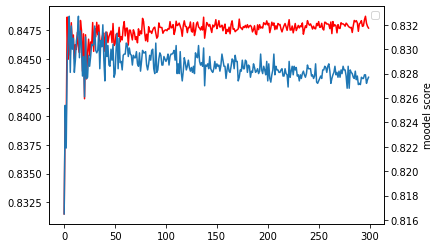
빨간 그래프: train set , 파란 그래프: test set
학습결과
print("train score: " ,train_score[-1])
print("test score: ",test_score[-1])📺:
train score: 0.8477
test score: 0.8277
USE: ANN
인공 신경망 (Artificial Neural Network, ANN)을 이용하여 분류
전처리 (train set를 -> train set 과 validation set으로 나누기)
import tensorflow as tf
from tensorflow import keras
from sklearn.model_selection import train_test_split
train_scaled, val_scaled, train_target, val_target = train_test_split(train_scaled, train_target, test_size = 0.2)
print(train_scaled.shape , train_target.shape) #(48000, 784) (48000,)
print(val_scaled.shape , val_target.shape) #(12000, 784) (12000,)학습을 위해 60,000개의 train set 중 0.2의 비율로 validation set 12,000개를 만들었다.
학습
#모델 만들기
model = keras.Sequential(
keras.layers.Dense(10, activation="softmax", input_shape=(784,))
) #입력층: 784개 뉴런, 출력층: 10개 뉴런, activation function: softmax(다중분류)
model.compile(loss='sparse_categorical_crossentropy', metrics='accuracy') #loss 함수 & 평가방법 지정
#학습
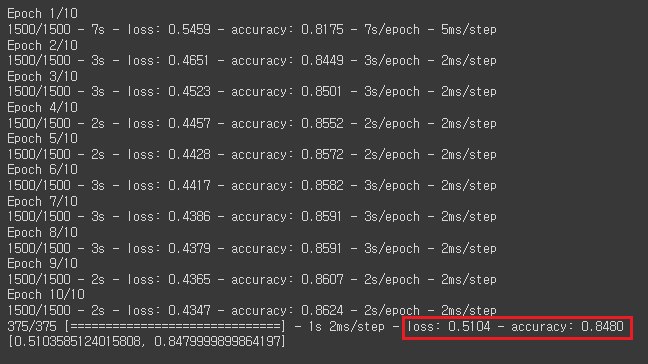
model.fit(train_scaled,train_target, epochs=10, verbose=2) #10 epochs으로 학습
#평가
model.evaluate(val_scaled,val_target)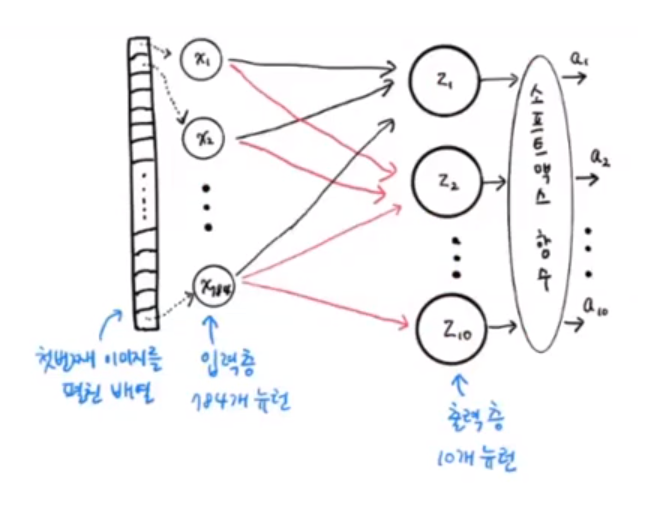
data를 784(28*28)개의 뉴런에서 입력층에서 받고, 10개의 뉴런으로 구성된 출력층에서 10종류의 이미지를 분류한다.
📺:
USE: DNN
심층 신경망(Deep Neural Network, DNN)은 입력층(input layer)과 출력층(output layer) 사이에 여러 개의 은닉층(hidden layer)들로 이뤄진 인공신경망(Artificial Neural Network, ANN)이다.
전처리
#데이터 load
from tensorflow import keras
(train_input ,train_target) ,(test_input , test_target)= keras.datasets.fashion_mnist.load_data()
from sklearn.model_selection import train_test_split
#1차원 데이터로 변경
train_scaled=train_input/255
train_scaled=train_scaled.reshape(-1,28*28)
train_scaled, val_scaled , train_target, val_target= train_test_split(train_scaled, train_target, test_size=0.2)
모델 만들기
model=keras.Sequential([
keras.layers.Dense(100, activation="sigmoid",input_shape=(784,), name='hidden'),
keras.layers.Dense(10, activation="softmax",name="output")
]
)
model.summary()📺:
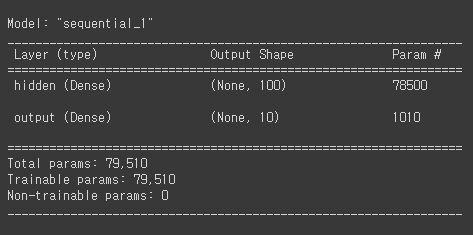
입력층(input layer): 784개 뉴런 , 은닉층(hidden layer): 100개 뉴런 , 출력층(output layer): 10개 뉴런
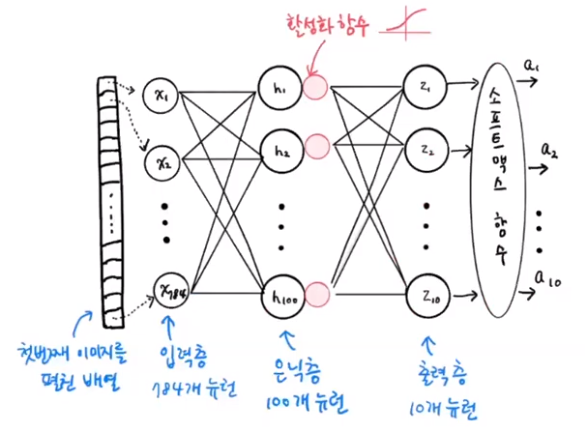
학습 및 평가
#학습 방법 지정
#optimizer: 어떻게 Gradient Descent를 할지 선택, loss 함수 & 평가방법 선택
model.compile(optimizer='adam', loss="sparse_categorical_crossentropy", metrics="accuracy")
#학습
model.fit(train_scaled,train_target, epochs=10)
#평가
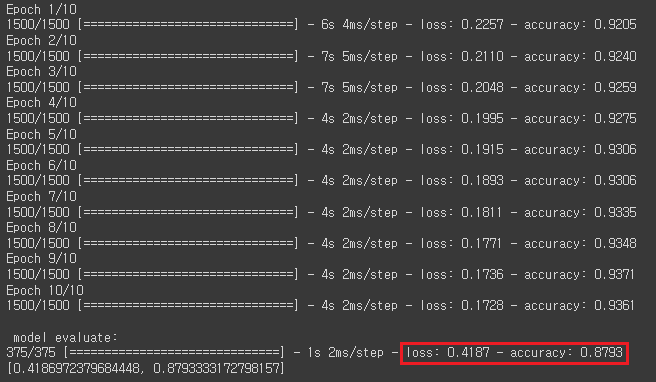
print("\n model evaluate:")
model.evaluate(val_scaled,val_target)📺:
USE: CNN
CNN(Convolutional neural network)은 수동으로 특징을 추출할 필요 없이 데이터로부터 직접 학습하는 딥러닝
전처리
#데이터 로드 및 전처리
from tensorflow import keras
from sklearn.model_selection import train_test_split
(train_input,train_target),(test_input, test_target)=keras.datasets.fashion_mnist.load_data()
train_scaled = train_input.reshape(-1,28,28,1) / 255.0
train_scaled, val_scaled, train_target, val_target =train_test_split(train_scaled, train_target, test_size=0.2)모델 만들기
model= keras.Sequential()
#Convolution, Pooling
model.add(keras.layers.Conv2D(32, kernel_size=3, padding='same', activation='relu', input_shape=(28,28,1)))
model.add(keras.layers.MaxPool2D(2))
model.add(keras.layers.Conv2D(64, kernel_size=3, padding='same', activation='relu'))
model.add(keras.layers.MaxPool2D(2))
#DNN
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(100, activation='relu'))
model.add(keras.layers.Dropout(0.4))
model.add(keras.layers.Dense(10, activation='softmax'))
model.summary()📺:
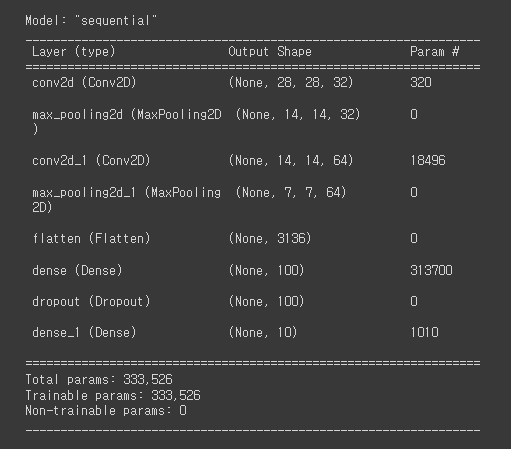
2번의 Convolution & Pooling -> 학습
학습
#학습 방법 지정
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics='accuracy')
#콜백(callback)
checkpoint_cb = keras.callbacks.ModelCheckpoint('best_cnn_model.h5', save_best_only=True)
#3번 연속 학습 점수가 좋아지지 않으면, 조기종료
early_stopping_cb = keras.callbacks.EarlyStopping(patience=3, restore_best_weights=True)
#학습
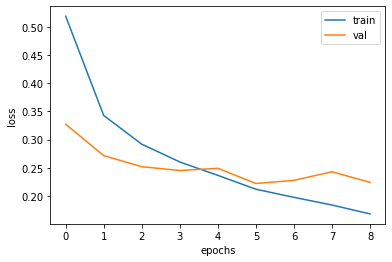
history = model.fit(train_scaled, train_target, epochs=20, callbacks=[checkpoint_cb,early_stopping_cb] , validation_data=(val_scaled, val_target))학습과정 그래프로 보기
import matplotlib.pyplot as plt
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.xlabel('epochs')
plt.ylabel('loss')
plt.legend(['train','val'])
plt.show()📺:
평가
model.evaluate(val_scaled, val_target)📺:loss: 0.2219 - accuracy: 0.9193
결과
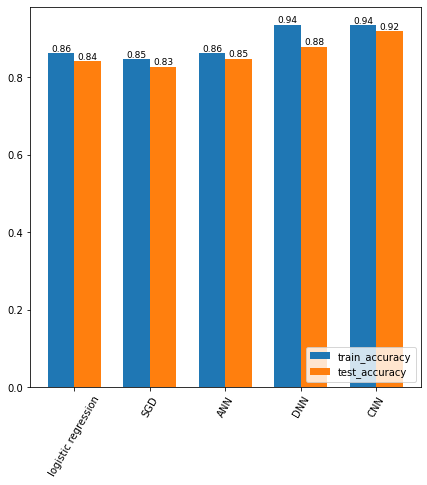
** 학습결과 상향을 위해 추가적인 알고리즘 사용 없이 단순 비교하였다.
Fashion MNIST 분류에서 신경망을 적용하고 & 신경망을 깊게 쌓을 수록 이미지 분류를 잘 수행하였다.
추가적으로 심층신경망보다 Convolution, Pooling를 한 CNN의 결과가 더 좋았다.
이미지 출처 및 참고자료
-박해선. 『혼자공부하는 머신러닝+딥러닝』. 서울:한빛미디어, 2020.
-Fashion MNIST label 이미지: https://www.researchgate.net/publication/340299295/figure/fig1/AS:875121904476163@1585656729996/Fashion-MNIST-Dataset-Images-with-Labels-and-Description-II-LITERATURE-REVIEW-In-image.jpg
-ANN 모델 설명 이미지: https://youtu.be/ZiP9erf5Fo0
-DNN 모델 설명 이미지: https://youtu.be/JskWW5MlzOg

{kind=link}