ChatPose는 2024년 IEEE/CVF 컴퓨터 비전 및 패턴 인식 회의(CVPR 2024)에 게재된 연구로, 대형 언어 모델(LLM)을 활용하여 이미지나 텍스트 설명으로부터 3D 인간 자세를 이해하고 추론하는 프레임워크이다.
- 게재 학회: CVPR 2024
- arXiv 링크: https://arxiv.org/abs/2311.18836
- 프로젝트 페이지: https://yfeng95.github.io/ChatPose
1. Introduction
1.1 기존의 방법
- 인간을 감지한 후 세그멘테이션을 통해 분할한 다음, 신경망을 통해 SMPL의 파라미터를 뽑아냄.
- 텍스트 기반의 방법도 등장하였으나, 단지 '단어'를 통해 명령을 내림.
- 2D 이미지나 글로부터 미세한 3D 동작을 만들어내는 것은 정보의 한계가 존재.
- 따라서 프리트레인 된 LLM의 광범위한 지식을 활용할 필요가 있음.
1.2 제안된 방법
- SMPL의 자세를 고유한 pose 토큰으로 LLM에 임베딩
- 자세에 대한 질문의 답으로 이 토큰을 출력하도록 훈련
- SMPL 투영 레이어 훈련
- LoRA로 LLM 모델을 파인튜닝
- LLM의 광범위한 지식을 이용하기 때문에 LoRA를 제외한 추가적인 훈련은 필요 없음
1.3 기여
추론 기반 자세 생성(Speculative Pose Generation, SPG)
앉아있는 모습을 그려달라는 텍스트 말고, '피곤한 사람은 어떤 자세를 취할까?'라고 물었을 때 이에 대한 포즈를 생성해냄. 지금까지 이런 추론 기반의 생성 기법은 없었음.
추론 기반 자세 추정(Reasoning-based Pose Estimation, RPE)
기존의 방법
- 입력 이미지에서 사람 부분만 잘라냄(cropped bounding box).
- 이 이미지를 신경망에 넣어서 SMPL의 파라미터를 업데이트 하도록 리그레션.
- 배경 정보가 모두 삭제된 단 한 명의 포즈 정보만이 입력되므로 상호작용 면에서 성능 저하.
- 한 장면에 여러 인물이 있어도 이들 전반에 대한 이해가 불가능.
논문의 방법
- 바운딩 박스로 인물을 분리하지 않고 모델이 전체 장면을 한 번에 봄.
- 장면 내의 특정 인물이 어떤 포즈를 취하고 있는지 물어볼 수 있음.
이를 달성하기 위한 모델의 기능
1. 개인과 장면의 정보를 융합한 복잡하고 함축적인 질문에 대해 이해하는 능력.
2. 이미지 정보를 텍스트 쿼리와 결합하는 능력.
3. 위의 두 정보를 바탕으로 정밀한 SMPL 파라미터를 추론하는 능력.
1.4 SMPL
SMPL이란?
- Skinned Multi-Person Linear model의 약자로, 2015 SIGGRAPH Asia에서 발표된 통계적 3D 사람 바디 모델.
- 약 6k개의 정점(mesh)과 24개 관절(skeleton)을 갖고, (i) 신체 형태 (Shape)와 (ii) 관절 자세 (Pose)를 서로 독립적으로 조정할 수 있게 선형화해 놓은 것이 특징.
모델 파라미터 구성
| 파라미터 | 기호 | 차원 | 의미 | 비고 |
|---|---|---|---|---|
| Shape | β (beta) | 보통 10 또는 16 | 사람마다 다른 체형(키·몸무게·근육 등)을 PCA basis로 표현 | 전체 프레임 동안 고정 |
| Pose | θ (theta) | 24 × 3 = 72 | 각 관절의 상대적 회전을 축-각(axis-angle) 형식으로 표현 | 프레임마다 변함 |
| Global Trans. | t | 3 | 루트(엉덩이) 관절의 전역 위치 | 카메라·월드 좌표계 기준 |
“SMPL pose parameter”가 의미하는 것
- 72 차원 θ 벡터 전체를 가리키는 경우가 가장 흔함.
- 연구 코드·데이터셋에서는
body_pose(23관절) +global_orient(루트)처럼 두 부분으로 나누어 저장하기도 함.
2. 관련 연구
2.1 Human Pose Estimation
단일 이미지에서 3D 모델을 만드는 연구에 대해 설명한다.
관절에 대한 회전 각도가 파라미터로 주어졌을 때 이를 기반으로 3D 모델을 생성.
Optimization-based Approach
- 2D 이미지에서 관절에 대한 키포인트를 검출.
- SMPL 모델의 3D 관절을 해당 키포인트에 매칭.
- 서로가 겹치도록 파라미터를 조정.
- 이 때 단순히 겹치게만 하면 어색한 모습이 나오므로, 각종 제약 조건이나 선험 지식을 부여.
Regression-based Approach
- 이미지에서 사람의 모습을 크롭.
- 크롭된 이미지를 딥러닝 네트워크에 넣어 SMPL 파라미터를 추정.
- 위 방법과 달리 2D 키포인트와 매칭하는 과정은 없음.
- 위 방법보다 강건하게 동작하지만, 신체가 가려지거나 화질이 낮으면 성능 저하 발생.
그러나 이 두 방법 모두 자연어 처리 모델과 결합된 적은 없었다.
2.2 Language and Human Pose
-
Stable Diffusion과 DALLE2 등은 텍스트 프롬프트를 기반으로 이미지를 생성하지만, 이것은 3D 모델이 아니다.
-
이전 연구인 PoseScript는 텍스트 프롬프트를 받아 SMPL의 파라미터를 추출한다. 그러나, 테스트 설명이 훈련 데이터의 단어 분포와 밀접할 때 효과적이고, 장면과 관련된 복잡한 텍스트 입력은 잘 이해하지 못한다. 이는 human pose와 scene을 연관시키는 장면이 없기 때문이다.
-
그러나 우리의 논문은 이를 LLM 기반으로 훈련시켰기 때문에 동일한 데이터셋으로 모델을 학습했음에도 불구하고 더 복잡한 텍스트 질문을 이해할 수 있다.
2.3 Multimodal Large Language Models
- 비공개 모델: ChatGPT, GPT-4
- 오픈소스 모델: Vicuna, LLaMA, Alpaca
멀티모달 LLM의 훈련 방법
프롬프트 엔지니어링 (인스트럭션 튜닝)
LLM에게 특정 태스크를 수행하도록 하는 명령 프롬프트를 설계하는 것.
멀티 모달 LLM은 이미지, 텍스트 등의 이해 및 생성을 하는 각각의 API가 있으며, 인풋 데이터의 종류에 따라 이들을 호출하여 태스크를 수행한다.
그러나 이는 결과적으로 각 모듈들을 따로 작동시켜 결과를 합치는 방법이라, LLM이 멀티모달 데이터 끼리의 관계를 이해하기 어렵다.
모달리티에 대한 정보를 LLM의 언어 임베딩 공간에 매핑
비전 인코더를 통해 이미지를 토큰화하고, 이를 텍스트 토큰에 매핑.
3. Method
3.1 모델 구조
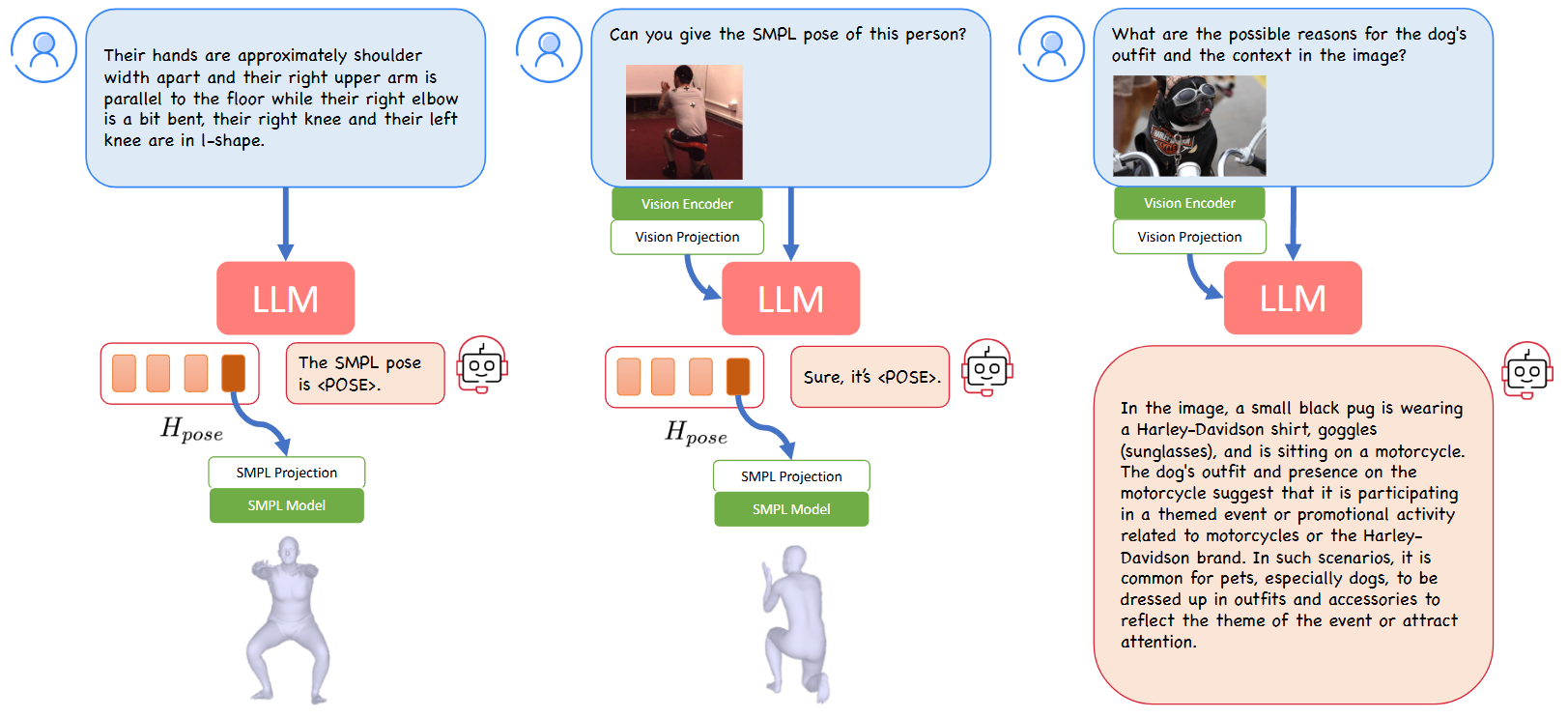
3.1.1 모델 구성 요소
(1) 멀티모달 LLM
-
input data: 텍스트 문자열 , 이미지
-
output data: , 이미지가 없을 경우
- : 언어 임베딩 벡터로 Vocab을 통해 대답인 를 구성
- : 포즈 정보에 해당하는 벡터
-
비전 인코더
이미지에 대한 정보를 토크나이징.
CLIP 모델의 인코더 사용. -
비전 프로젝션 레이어
이미지 토큰을 LLM이 이해할 수 있도록 프로젝션.
CLIP 모델의 프로젝션 레이어 사용. -
LLM 네트워크
LLaVA-1.5V-13B
(2) SMPL 프로젝션 레이어
- LLM이 생성한 답변 토큰을 SMPL 파라미터에 프로젝션
- [5120, 5120, 144]인 MLP
(3) SMPL 데이터
- 포즈 파라미터:
- 신체 형태 파라미터: (평균 신체 형태만 실험하므로 모든 값은 0)
- SMPL 함수 에 의해 버텍스와 메시 생성
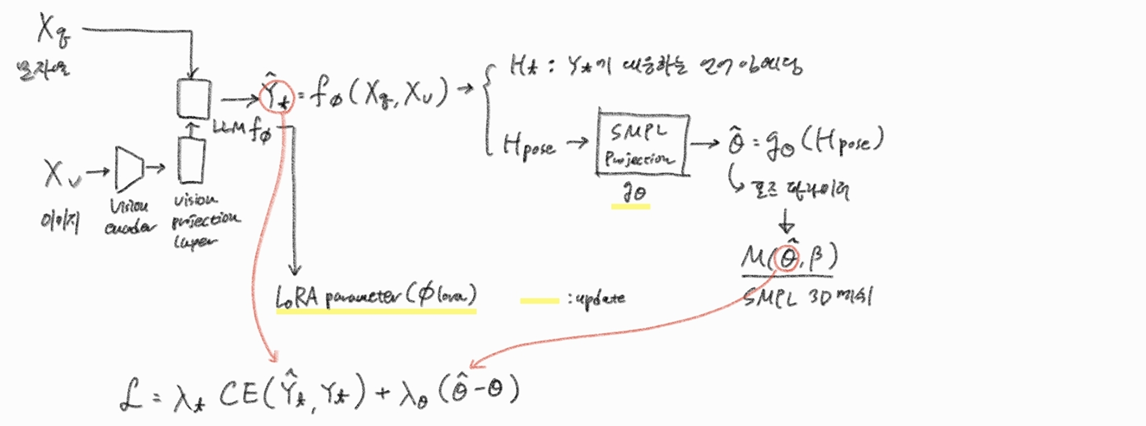
3.2 모델 훈련
3.2.1 학습 가능한 파라미터
- 동결
- 비전 인코더
- 비전 프로젝션 레이어
- 학습
- : SMPL 포즈 프로젝션 레이어
- : LLM의 LoRA
- 최적화할 파라미터:
* LoRA(Low-Rank Adaptation)란?
-
사전학습된 모델 파라미터 는 고정한 채, 그 파라미터에 더해질 변화분(residual) 을 학습시킨다. (주로 트랜스포머의 선형 레이어에 탑재)
-
이 때 를 위와 같이 랭크()가 작은 두 매트릭스 , 의 곱으로 파라미터 분리한다.
-
여기서 이므로, 업데이트할 파라미터 수가
- 원에서
- 로 크게 줄어들며,
학습 후에는 를 원본 에 더해 사용하므로 모델 구조 수정 없이 효율적으로 업데이트 가능하다.
3.2.2 오차함수
-
: ground truth 텍스트 출력
-
: ground truth SMPL 포즈 파라미터
-
첫째 항: (크로스 앤트로피 손실)
-
둘째 항: 파라미터간의
3.2.3 SMPL 포즈 오차 는 어떻게 구하는가?
-
SMPL의 6D 회전 표현 방식:
-
SMPL 모델에서 인체의 자세는 각 관절의 회전 값들로 정의됩니다. 예를 들어, 팔꿈치나 무릎의 굽힘, 몸통의 비틀림 등이 각 관절의 회전으로 표현됩니다. 그리고 3D 공간 상에서 회전을 표현하는 방법에는 오일러 각, 쿼터니언, 회전 행렬 등이 있습니다.
-
오일러 각이나 축-각 같은 방식은 회전을 표현할 때 특정 각도에서 불연속적인 문제(Gimbal Lock 등)가 발생할 수 있어, 딥러닝 모델이 학습하기 어렵게 만들 수 있습니다.
-
회전 행렬은 불연속 문제는 없지만, 회전 행렬이 되기 위한 제약 조건(직교 행렬이면서 행렬식 값이 1인 조건)을 모델이 직접 학습하기 어렵다는 단점이 있습니다.
-
이전 연구에서 제안된 6D 회전 표현은 이러한 문제들을 완화하기 위한 대안입니다. 이 방식은 3D 회전을 6개의 값(사실상 3x3 회전 행렬의 첫 두 개의 열 벡터)으로 표현하며, 모델이 불연속 문제 없이 회전 값을 예측할 수 있도록 합니다. 예측된 6D 값은 간단한 절차를 거쳐 다시 유효한 회전 행렬로 변환될 수 있습니다.
-
이러한 성공적인 기존 연구들에서 6D 회전 표현 방식이 관절 회전 예측에 효과적임이 입증되었습니다. 6D 표현이 학습의 안정성과 성능에 기여한다고 여겨졌기 때문입니다.
-
ChatPose는 이러한 선행 연구들이 사용한 방식의 효과를 인지하고, 3D 인체 자세 예측의 표준적인 접근 방식 중 하나로 자리 잡은 6D 회전 표현을 채택한 것입니다. 이는 검증된 방법을 사용하여 모델의 자세 예측 성능을 확보하려는 목적입니다.
-
-
손실 계산을 위한 회전 행렬 변환:
-
ChatPose 네트워크는 SMPL 자세를 6D 회전 값으로 예측합니다.
-
하지만 예측의 정확성을 평가하고 모델을 업데이트하기 위한 손실 함수를 계산할 때는, 예측된 6D 회전 값을 손실 계산에 용이한 회전 행렬 형태로 변환한 후, 실제 회전 행렬 간의 오차를 계산하여 모델 학습에 활용합니다.
-
3.2.3 학습 태스크

3.2.3.1. Text to Pose
- 텍스트 설명을 주고 이에 대한 SMPL 파라미터 생성
3.2.3.2. Human Pose Estimation
- 이미지를 주고 이에 대한 SMPL 파라미터 생성
3.2.3.3. Multimodal Instruction-following:
-
텍스트와 이미지를 포함한 입력에 대해 결과물 생성하도록 훈련.
-
ChatPose 모델이 멀티턴 대화(multi-turn conversations)를 자연스럽게 수행하기 위해, 즉 여러 차례의 질의응답을 이어나가는 대화 능력을 유지하기 위해 멀티모달 instruction-following 데이터셋을 사용하여 학습을 진행.
-
이 데이터셋은 LLaVA-V1.5-MIX665K라 불리며, GPT-4가 생성한 다양한 질문과 답변 쌍으로 구성되어 있음. 즉, GPT-4가 작성한 광범위한 질의응답 사례들이 포함된 데이터셋을 통해 모델을 훈련시킴으로써, 모델이 복잡하고 다양한 멀티모달 질의에 대해 이해하고 응답할 수 있도록 함.
-
이러한 학습 방식은 ChatPose가 이미지와 텍스트를 모두 입력받아도 대화를 자연스럽게 이어가면서, SMPL 포즈 생성 및 추정 뿐만 아니라, 사용자의 복잡한 지시에 따른 합리적인 응답도 가능하도록 만듦.
3.3 Reasoning about Human Pose
3.3.1 추론 기반 자세 생성(Speculative Pose Generation, SPG)
-
기존의 text-to-pose 데이터셋 대신 '피곤한 사람은 어떤 자세를 취할까?'라는 간접적인 질문을 사용.
-
데이터셋 생성: PoseScript 데이터셋의 자세 설명을 GPT4에게 문의하여 이와 연관된 활동에 대한 질문으로 간접적으로 묘사한 20K의 재구성 데이터셋. 이 중 870개를 평가에 사용.
3.3.2 추론 기반 자세 추정(Reasoning-based Pose Estimation, RPE)
-
Human Detector를 이용해 사람을 찾고, 이를 크롭하여 데이터 인풋으로 사용하던 기존의 방법과 달리, 전체 이미지를 넣고, '{검은 머리를 가진 남자}의 SMPL 포즈를 알려줘.'라고 인물을 특정하여 질문.
-
훈련 방법:
-
image-to-SMPL 포즈로 사전 훈련.
-
이후 3DPW 테스트 셋에서 여러 사람이 있는 50개의 이미지를 샘플링.
-
GPT4V로 사진 속 각 인물에 대한 묘사를 생성 후 인간이 재첨삭.
-
이렇게 총 50개의 질문과 답변 쌍을 생성하여 파인 튜닝.
-
4. Experiments
4.1 Dataset
4.1.1 Text to Pose Generation
PoseScript의 text-to-SMPL 을 동일하게 사용
- AMASS 데이터셋에서 생성한 20K의 다양한 포즈에 대한 설명.
- 2만 개의 포즈 전체 세트에 대해 6가지 유형의 자동화된 레이블이 존재.
- 6.5k개의 텍스트는 사람이 직접 레이블링.
4.1.2 Human Pose Estimation
Human3.6M, MPI-INF-3DHP, COCO,MPII dataset 사용
- 이미지와 SMPL 파라미터 쌍
- 가려지지 않은 완전한 데이터만 사용
4.2 Evaluation Metric
4.2.1 포즈 생성(Pose Generation) 평가
일반적인 텍스트 기반 포즈 생성 작업
- '양 손을 허리에 얹고 서있는 사람'이라는 텍스트 정보에 대한 SMPL 파라미터 추출
- PoseCript와 비슷한 수준의 성능을 보임
추론 기반 포즈 생성(Speculative Pose Generation, SPG)
- '피곤한 사람이 취할 수 있는 포즈를 그려줘'라는 간접적인 질문에 대한 SMPL 파라미터 추출
- 아래 평가 지표에서 PoseScript보다 2배 높은 성능을 보임
평가 지표
- PoseScript 논문에서 사용된 평가 지표를 활용.
- RT2P(Text-to-pose recall rate): 텍스트를 통해 포즈를 검색
- RP2T(Pose-to-text recall rate): 포즈를 통해 텍스트를 검색
4.2.2 포즈 추정(Pose Estimation) 평가
전통적인 3D 인체 포즈 추정 작업
- 사람의 모습이 크롭되어 들어가는 포즈 추정 작업
- 이미지를 통해 SMPL 파라미터를 추정하는 특화 모델인 SPIN, HMR 2.0 보단 낮은 성능
- 멀티모달 모델인 GPT4-P, LLaVA-P 등의 기존 모델보다 훨씬 좋은 성능
추론 기반 포즈 추정(Reasoning-based Pose Estimation, RPE)
- 이미지 전체에서 특정 인물('계단 근처의 여자'로 명시)의 자세를 SMPL 파라미터로 추출
- 크롭 이미지 특화 모델인 SPIN, HMR 2.0보다 더 좋은 성능
평가 지표
- MPJPE (Mean Per-Joint Position Error): 관절 위치의 평균 오류
- 각 관절마다 예측 위치와 GT 위치의 유클리디언 거리를 계산
- 이를 전체 관절에 대해 평균냄
- PA-MPJPE (Procrustes Aligned MPJPE): 강체 정렬 후의 관절 위치 오류
- 평행 이동을 통해 중심점을 일치
- 스케일링을 통해 크기를 일치
- 회전을 통해 방향을 일치
