논문 리뷰
1.NoPe-NeRF: Optimising Neural Radiance Field with No Pose Prior

논문의 저자들은 카메라의 포즈 정보 없이 NeRF를 통해 사진을 입체화하는 방법을 제안한다. 해당 방법은 기존의 모델들과 달리 다이나믹한 카메라 이동에서도 정확한 위치를 파악할 수 있다.NeRF는 COLMAP 등의 SfM 알고리즘을 이용한 카메라 파라미터를 사전 정보로
2.Legal Judgment Prediction via Event Extraction with Constraint
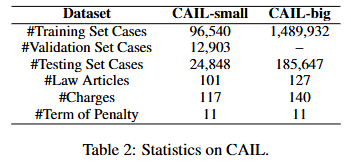
Input data: 범죄 사실Output data: 법 조항($t_a$), 죄명($t_b$), 형량($t_c$) ($t_a, t_c, t_p \\in T$)$$h1, h_2, ... h{lf} = \\text{Legal-BERT}(x_1, x_2, ...x{l_f})
3.LEGAL-BERT: The Muppets straight out of Law Schoo

위키피디아 등의 일반적인 코퍼스로 사전학습 된 LLM은 과학이나 법률 등의 전문 분야에서 성능이 떨어지는 것이 관찰되었다. 이를 해결하기 위해 다음과 같은 두 가지 방법을 사용할 수 있다.Further pre-trainLLM을 해당 도메인의 코퍼스로 다시 한 번 사전학
4.ShapeGPT: 3D Shape Generation with A Unified Multi-modal Language Model
Abstract word-sentence-paragraph 프레임워크 기능 연속된 형태를 '형태 단어'로 분할 해당 단어를 '형태 문장'으로 결합 형태를 프롬프트와 결합시켜 멀티모달 문단 생성 훈련 방법 형태 정보를 언어 정보와 연관짓는 codebook을 만들기 위한
5.PoseScript: Linking 3D Human Poses and Natural Language
PoseScript Dataset: AMASS의 6000개 이상의 3D human pose를 인간의 주석과 짝지음.이를 바탕으로 몇 분 안에 수천개의 캡션을 달 수 있는 주석 파이프라인을 소개.데이터 생성 파이프라인posebits 데이터셋을 더 세부적인 범주로 나누어
6.Unsupervised Keyphrase Extraction via Interpretable Neural Networks
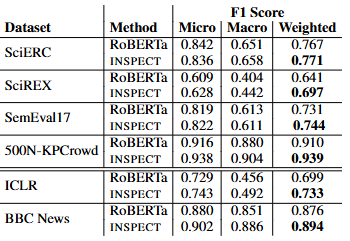
1. Intruduction 기존의 연구 단어의 밀도 등을 이용한 통계적 방법 그래프 중심의 임베딩 제안된 연구 문서의 토픽을 바탕으로 키워드 추출 따로 키워드 태깅을 할 필요가 없음 SelfExplain라는 설명 가능한 문장 분류 모델을 활용 해당 모델의 출력을 문
7.InterFusion: Text-Driven Generation of 3D Human-Object Interaction
1. Introduction 3D Human-object interactions (HOI) 인간과 사물이 상호작용하는 모습을 3D로 구현하는 과제 그러나 아래의 두 가지 이유 때문에 한계가 존재 텍스트 기반 인터렉션 데이터셋이 부족 현재 해당 데이터셋은 모션 캡처 혹은 시뮬레이션 데이터셋이 우세. 모션 캡처: 그들이 만든 시나리오에 한정적이고 노...
8.SELFEXPLAIN: A Self-Explaining Architecture for Neural Text Classifier
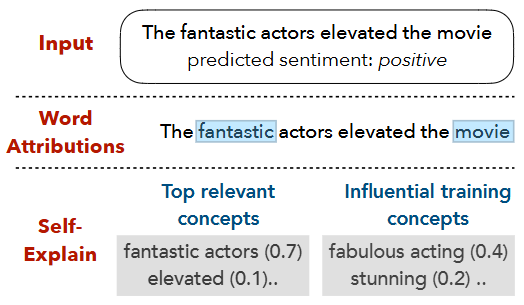
사전 훈련된 모델의 결과를 가지고 설명모델 내부에 설명 가능한 모듈이 내장돼있음attention score를 기반으로 word-level feature attribution 을 사용하는 방식이 일반적그러나 이는 신뢰성이 떨어진다는 것이 증명 됨글로벌, 로컬 해석 가능
9.Diffusion Hyperfeatures: Searching Through Time and Space for Semantic Correspondence
Abstract Diffusion 모델은 고품질의 이미지를 생성할 수 있으며, 이는 모델 내부에 의미 있는 정보인 internal representations가 포함되어 있음을 시사합니다. 하지만 diffusion 모델의 내부 정보를 담고 있는 feature map들은
10.Unsupervised Keypoints from Pretrained Diffusion Model

Fig. 1 문제 인식: Keypoint 및 Landmark 검출 분야에서 최신 신경망 아키텍처 덕분에 비지도 학습 방식에 상당한 발전이 있었지만, 아직까지 성능 면에서 지도 학습 방식에 미치지 못하여 실용성에 의문이 있었습니다. 특히 기존 비지도 학습 방법은 데이터
11.Diffuse, Attend, and Segment: Unsupervised Zero-Shot Segmentation using Stable Diffusion
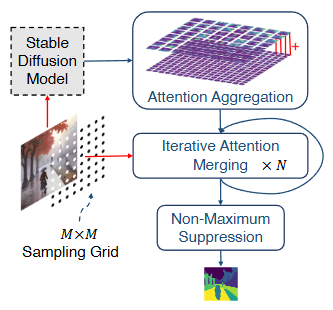
문제 정의: 컴퓨터 비전에서 이미지에 대한 고품질의 세그멘테이션 마스크를 생성하는 것은 중요한 문제입니다. 특히, 대규모 주석(annotation) 없이 모든 종류의 이미지에 대해 제로 샷(zero-shot, 학습 시 보지 못한 데이터에 대해 추론하는 능력) 세그멘테이
12.Object Pose Estimation via the Aggregation of Diffusion Feature
Abstract 핵심 문제: 이미지에서 객체의 포즈를 추정하는 것은 3D 장면 이해에 매우 중요하지만, 기존의 최신 방법들은 학습 데이터에서 보지 못한 새로운 객체(unseen objects)를 다룰 때 성능이 크게 저하되는 문제가 있습니다. 원인 분석: 연구자들은 이
13.Hand Pose Estimation via Latent 2.5D Heatmap Regression
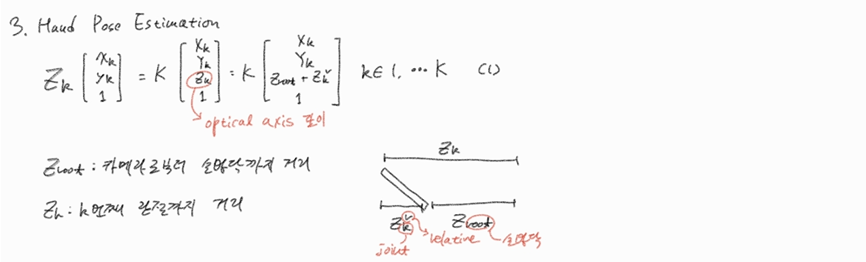
Abstract 문제 정의: 인간-컴퓨터 상호작용에 중요한 3D 손 자세 추정은 단일 RGB 이미지만으로는 어렵습니다. 이는 3D 자세 추정에 필요한 깊이 정보가 RGB 이미지에서 모호하기 때문입니다. 제안하는 해결책: 논문에서는 "2.5D 자세 표현(2.5D pose
14.MeshFormer: High-Quality Mesh Generation with 3D-Guided Reconstruction Model
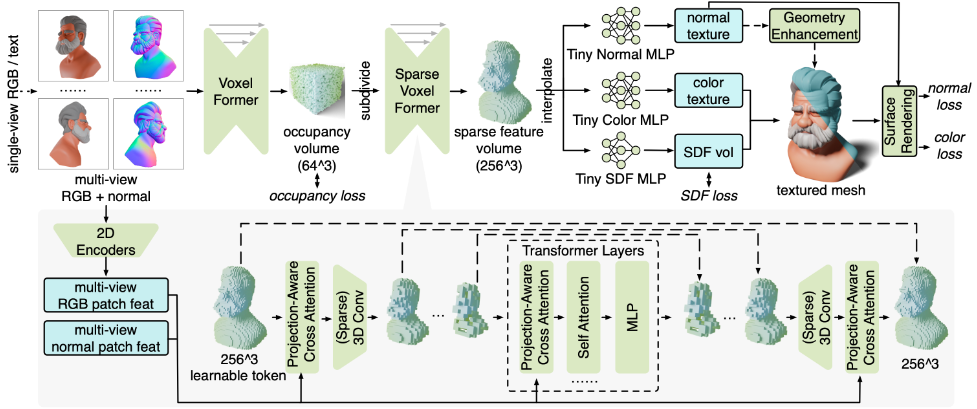
Abstract 한계와 해결방안 이 논문은 기존의 3D 재구성 방법들이 충분한 3D inductive bias가 없으면 고품질 3D 메쉬를 효율적으로 생성하기 어렵고, 학습 비용도 높다는 문제를 지적합니다. MeshFormer는 이러한 한계를 극복하기 위해 다음과 같은
15.Structured 3D Latents for Scalable and Versatile 3D Generation
NeRF, Gaussian 등 여러 3D 표현 기법을 다룰 수 있어야 함통합적인 latent 공간을 구현visual representation을 특성화한 복셀을 생성, 이를 디코딩할 수 있도록 함렌더링된 2D 이미지 피처를 가공하여 복셀에 합성고품질 디코딩 기술 필요텍
16.DINO
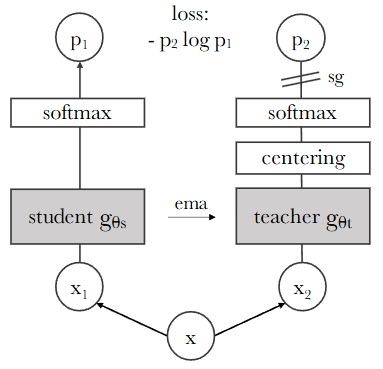
Self-distillation with no labels 방식, 즉 DINO(DIstillation with NO labels) 프레임워크의 핵심 학습 목표는 레이블 없이 이미지 데이터 그 자체로부터 유용하고 일반화 가능한 시각적 특징(visual features)을
17.EfficientSAM: Leveraged Masked Image Pretraining for Efficient Segment Anything
EMA (Exponential Moving Average) 교사 네트워크의 파라미터 θt를 학생 네트워크의 파라미터 θs 기반으로 업데이트하는 방식. 교사 네트워크가 학생 네트워크의 최근 학습 상태를 부드럽게 따라가도록 하며, 학습의 안정성과 성능 향상에 기여. $$ \thetat \leftarrow \lambda \thetat + (1-\lambda...
18.ChatPose: Chatting about 3D Human Pose
ChatPose는 2024년 IEEE/CVF 컴퓨터 비전 및 패턴 인식 회의(CVPR 2024)에 게재된 연구로, 대형 언어 모델(LLM)을 활용하여 이미지나 텍스트 설명으로부터 3D 인간 자세를 이해하고 추론하는 프레임워크이다.게재 학회: CVPR 2024arXiv
19.CLIP is Also an Efficient Segmenter: A Text-Driven Approach for Weakly Supervised Semantic Segmentation

Weakly Supervised Semantic Segmentation (WSSS)의 문제점과 이를 해결하기 위한 새로운 프레임워크인 CLIP-ES에 대해 소개합니다.WSSS의 목표 및 도전 과제:Semantic segmentation은 픽셀 단위의 레이블을 예측하는
20.3D Gaussian Splatting 강의 정리

영상 출처: https://www.youtube.com/watch?v=uetF_awWYLc
21.LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation
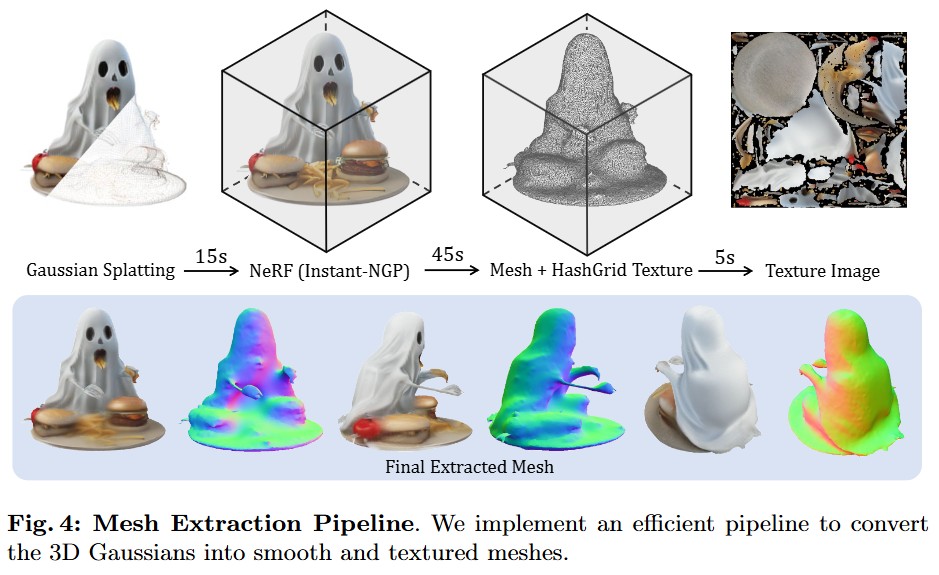
1. Introduction (추후 작성) 2. Related Works (추후 작성) 3. Method 3.1 Preliminaries Large Multi-View Gaussian Model(LGM)의 핵심 구성 요소를 이해하는 데 필요한 두 가지 주요 사전 지식인
22.DINOv2: Learning Robust Visual Features without Supervision
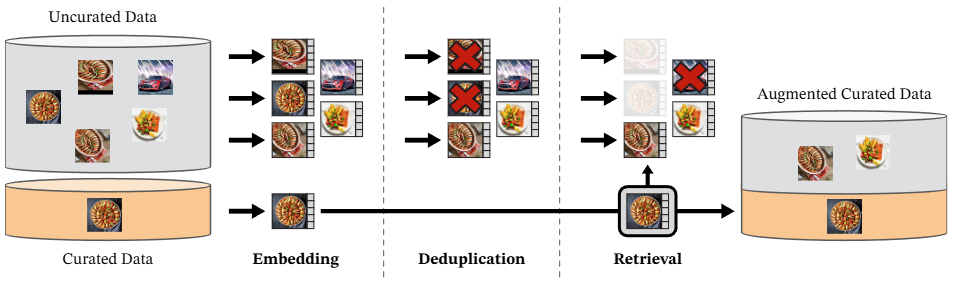
텍스트 기반 비지도학습그러나 캡션은 이미지의 풍부한 정보에 근사할 뿐세그멘테이션 같은 픽셀 레벨의 태스크를 수행할 수 없었음이미지-언어 모델 내부의 시맨틱 연결이 잘 안 될 경우 텍스트 정보에 대응하는 이미지를 잘 못 찾을 수 있음자기 지도 학습엄선되지 않은 방대한 데
23.Segment Anything



26.LangSplat: 3D Language Gaussian Splatting

업무가 바빠 태블릿 대신 노트에 필기하였습니다.
27.EmoTalkingGuassian
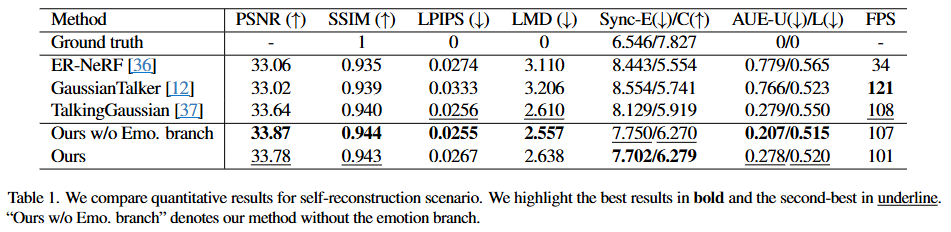
Arxiv: https://arxiv.org/pdf/2502.00654v1이 섹션은 EmoTalkingGaussian 모델에서 입 안쪽(inside-mouth)과 얼굴(face) 영역의 Canonical Gaussians를 최적화하는 방법을 설명합니다. Can
28.Decoupled Multimodal Distilling for Emotion Recognition

정의: 얼굴 동작 단위(FAU)는 인간의 얼굴에서 나타나는 다양한 표정을 분석하기 위해 개발된 얼굴 동작 코딩 시스템(Facial Action Coding System, FACS) A citation/reference in this paper: OpenFace: An
29.TalkingGaussian: Structure-Persistent 3D Talking Head Synthesis via Gaussian Splatting

Arxiv: https://arxiv.org/pdf/2404.15264
30.Enhancing Zero-Shot Facial Expression Recognition by LLM Knowledge Transfer

이 논문은 총 7개의 'in-the-wild' 얼굴 표정 데이터셋을 사용하여 실험을 수행했으며, 이는 크게 두 가지 유형으로 나뉜다: 정적(Static) 얼굴 표정 인식(SFER) 데이터셋과 동적(Dynamic) 얼굴 표정 인식(DFER) 데이터셋이다. 또한, 투영 헤
31.EmoVIT: Revolutionizing Emotion Insights with Visual Instruction Tuning
Visual Instruction Tuning (VIT) 정의 및 한계:VIT는 사전 학습된 언어 모델을 특정 작업 지침을 사용하여 미세 조정하는 새로운 학습 패러다임이다.이는 다양한 자연어 처리(NLP) 작업에서 유망한 제로샷(zero-shot) 결과를 보였으나, 시
32.CocoER: Aligning Multi-Level Feature by Competition and Coordination for Emotion Recognition
이 논문은 이미지의 여러 레벨(머리, 몸, 맥락)에서 얻은 특징들을 활용하여 사람의 감정을 인식하는 CocoER이라는 새로운 방법을 제안한다. 기존 연구들은 시각적 특징 융합 및 추론을 개선하는 데 초점을 맞추었지만, 각 레벨에서 도출된 감정 인식 결과가 서로 다를 때
33.KeyFace: Expressive Audio-Driven Facial Animation for Long Sequences via Key Frame Interpolation
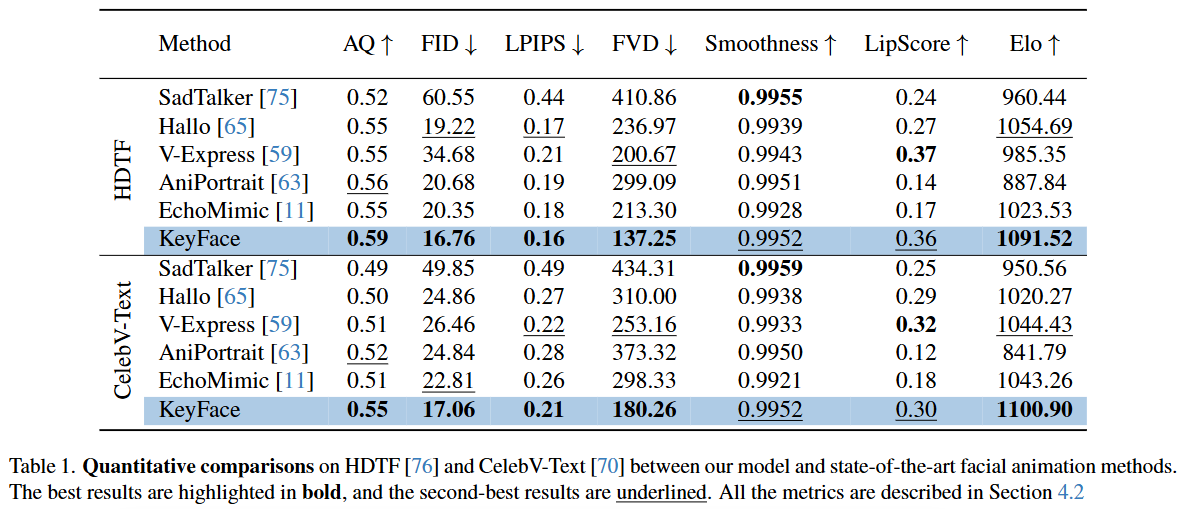
오디오 기반 얼굴 애니메이션 분야의 발전과 한계:최근 GAN(18) 및 Diffusion Model(DM)(13, 22)과 같은 생성 모델의 발전에 힘입어, 오디오 기반 얼굴 애니메이션은 가상 비서, 교육, 가상 현실 등 다양한 분야에서 유망한 응용 가능성을 보여주며
34.DREAM-Talk: Diffusion-based Realistic Emotional Audio-driven Method for Single Image Talking Face Generation
연구 배경 및 중요성최근 대화형 얼굴 생성 분야는 비디오 콘퍼런싱, 가상 비서, 엔터테인먼트 등 다양한 응용 분야에서 핵심 연구 영역으로 크게 발전하고 있다.특히, 10, 13, 14와 같은 연구들에서 MEAD 33와 같은 감정 주석이 달린 비디오 데이터셋을 활용하여
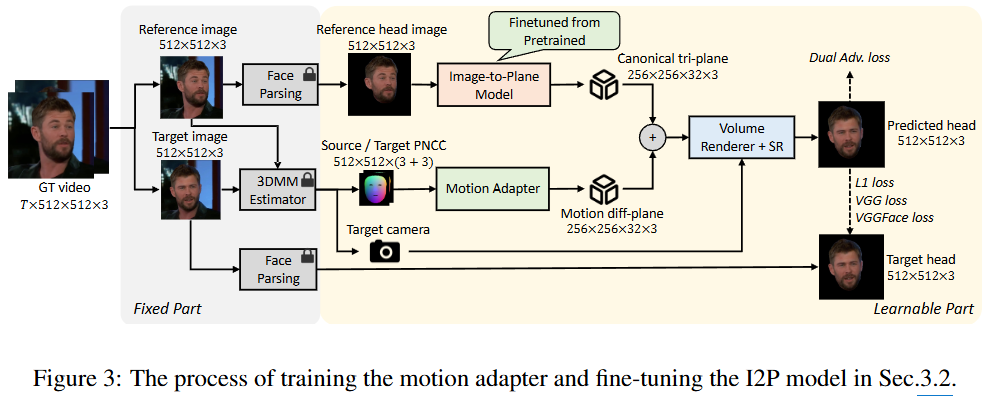
35.InsTaG: Learning Personalized 3D Talking Head from Few-Second Video
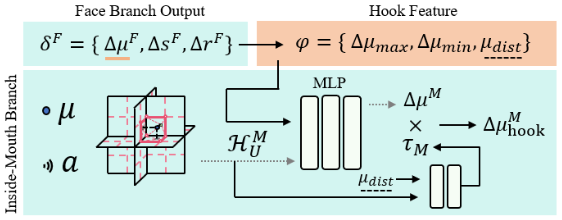
해당 텍스트는 InsTaG(Instant Talking Head Synthesis with Gaussian Splatting) 프레임워크의 핵심 구성 요소 중 하나인 Identity-Free Pre-training (신원 독립적 사전 학습) 전략에 대해 설명하고 있다.
36.PERSONA: Personalized Whole-Body 3D Avatar with Pose-Driven Deformations from a Single Image
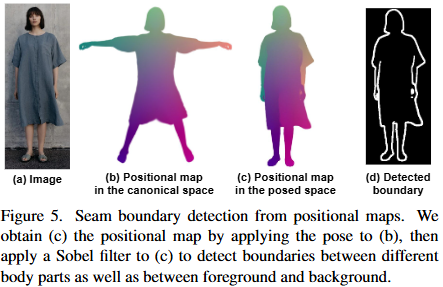
Animatable Human Avatar의 정의 및 중요성:Animatable Human Avatar는 새로운 전신(whole-body) 포즈와 얼굴 표정을 움직일 수 있으며, 어떤 시점에서도 렌더링(rendering) 가능한 3D 인체 모델을 의미한다.컴퓨터 비전(
37.RMFER: Semi-supervised Contrastive Learning for Facial Expression Recognition with Reaction Mashup Video
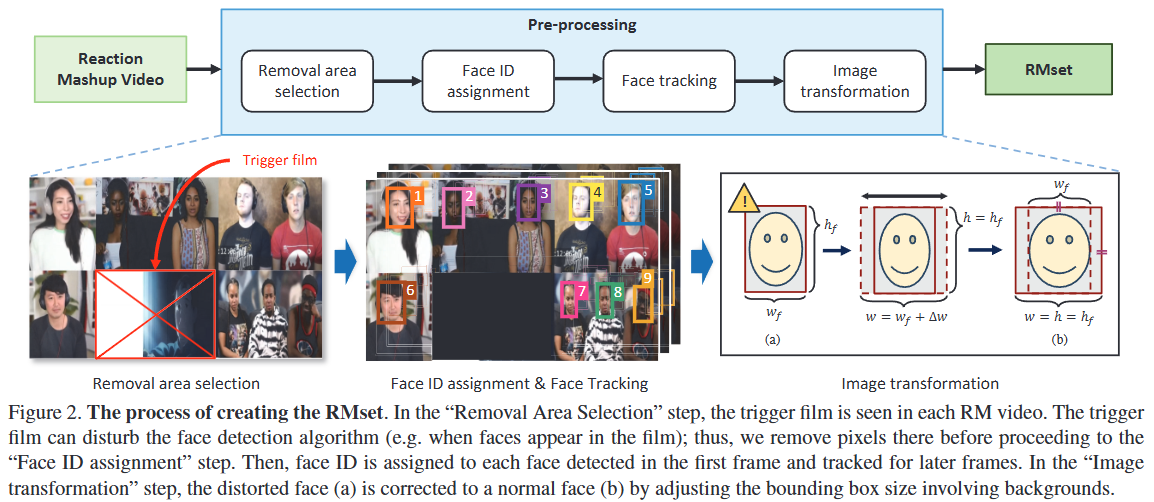
FER의 중요성 및 정의:얼굴 표정은 비언어적 의사소통에서 핵심적인 역할을 한다.FER은 입력 이미지나 비디오에서 얼굴 표정을 '중립', '행복', '슬픔' 등 미리 정의된 범주로 분류하는 작업이다.마케팅, 교육, 감성 컴퓨팅 등 다양한 HCI(Human-Compute
38.Contrastive Adversarial Learning for Person Independent Facial Emotion Recognition (AAAI 2021)
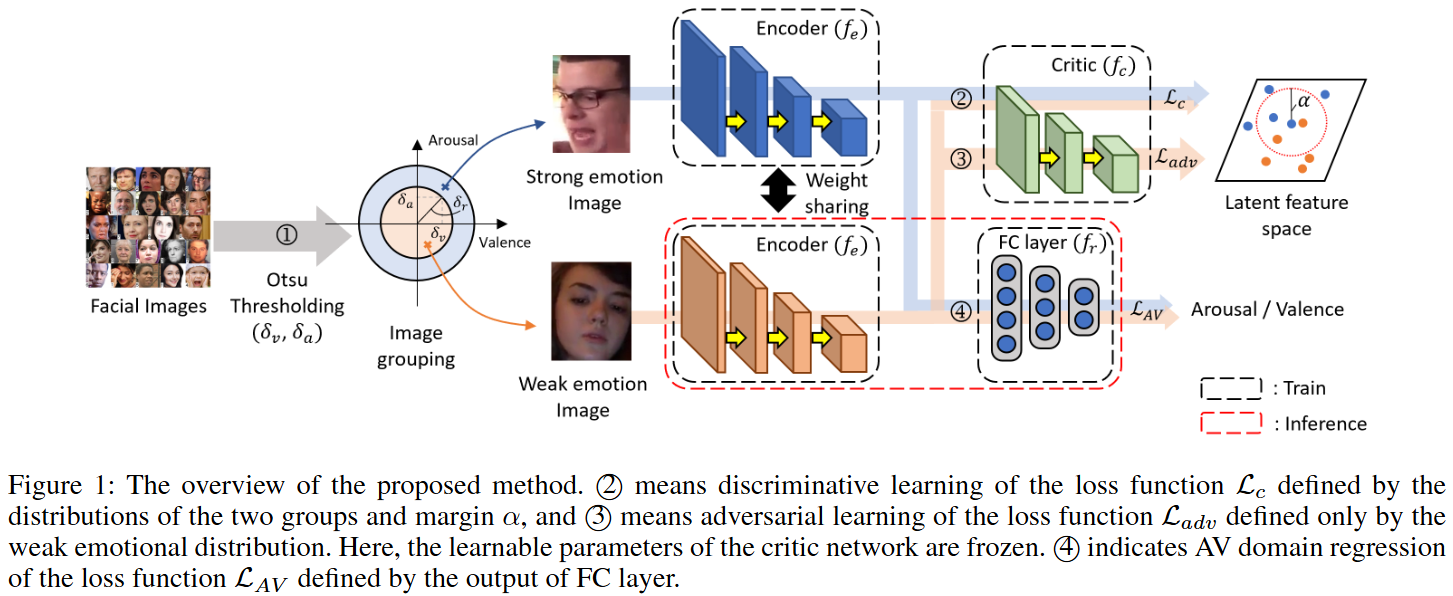
이 이미지는 논문에서 제안하는 Contrastive Adversarial Learning for Person Independent Facial Emotion Recognition(CAF) 방법의 전체적인 구조를 보여준다. 이 모델은 사람에 구애받지 않는(person-i
39.Expressive Whole-Body 3D Gaussian Avatar
논문 링크: https://arxiv.org/pdf/2407.21686 1. Introduction 생략 2. Related Works 생략 3. ExAvatar 3.1. Accurate co-registration of SMPL-X 본 섹션은 SMPL-X 파라미터들
40.Facial Affective Behavior Analysis with Instruction Tuning (ECCV 2024)
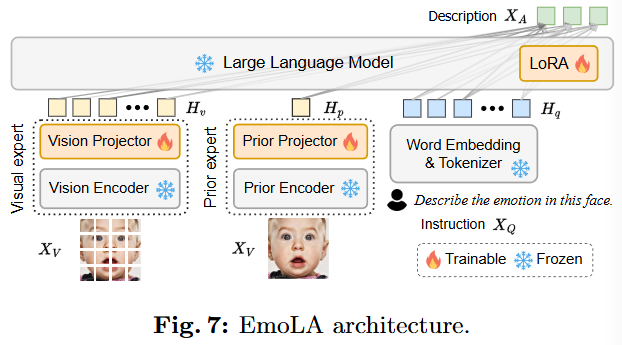
논문: https://arxiv.org/pdf/2404.05052(생략)(생략)FABA 데이터셋의 필요성:기존 FABA 데이터셋은 MLLM의 instruction tuning을 수행하기에 적합하지 않다는 문제가 있다.주된 이유는 주석(annotation)이 너
41.EDTalk: Efficient Disentanglement for Emotional Talking Head Synthesis (ECCV 2024)
project: https://tanshuai0219.github.io/EDTalk/배경 및 기존 연구의 한계점:Talking head animation은 교육, 영화 제작, 가상 디지털 휴먼 등 다양한 분야에서 중요성이 커지고 있는 연구 분야이다.기존의 방법
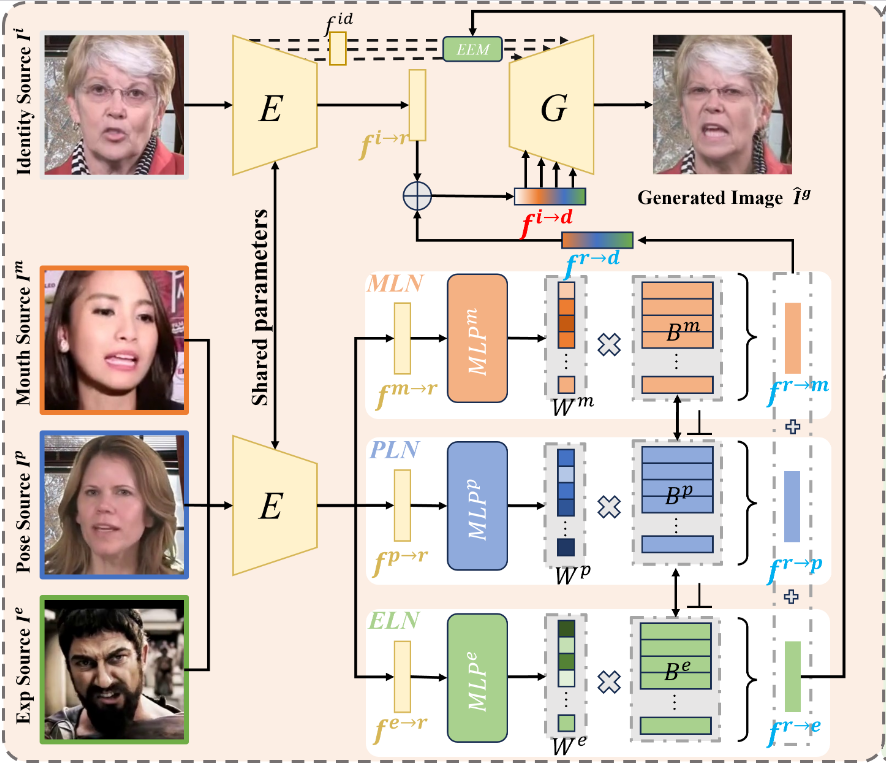
42.Progressive Disentangled Representation Learning for Fine-Grained Controllable Talking Head Synthesis (CVPR 2023)
Talking Head Synthesis의 중요성:사실적인 비디오 아바타를 생성하는 데 필수적인 작업이다.시각적 더빙, 대화형 라이브 스트리밍, 온라인 회의 등 다양한 애플리케이션에서 활용 가능하다.기존 연구 동향:최근 딥러닝 기술을 활용하여 생생한 Talking He
43.VTimeLLM: Empower LLM to Grasp Video Moments (CVPR 2024)
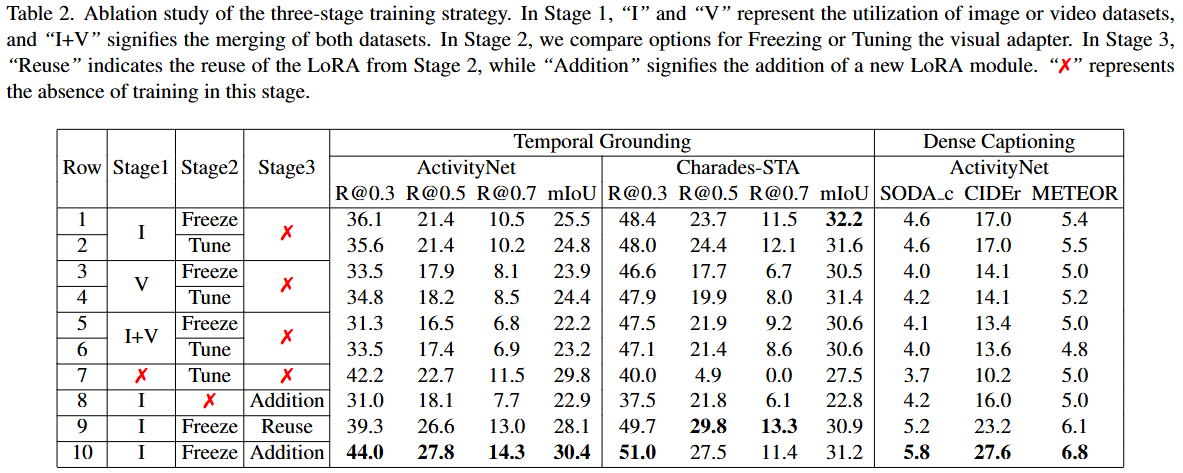
2.1 멀티모달 대규모 언어 모델 (Multimodal Large Language Model)Image LLM (이미지 LLM):대규모 언어 모델(LLM)이 시각 정보를 이해할 수 있도록 시각 및 언어 양식을 정렬하려는 노력에 대해 다룬다.BLIP-2는 Q-Former
44.Valence & Arousal Datset 조사 01
공식 명칭 / 논문: AFEW-VA database for valence and arousal estimation in-the-wild (Image and Vision Computing, 2017, Kossaifi et al.) (jeankossaifi.com)참여자(
45.Valence & Arousal Datset 조사 02
| Dataset | 주요 라벨(시간해상도) | 규모/특징 | 링크
46.EmoSphere-TTS: Emotional Style and Intensity Modeling via Spherical Emotion Vector for Controllable Emotional Text-to-Speech (Interspeech 2024)
논문 링크: https://arxiv.org/abs/2406.07803 1. Introduction 이 섹션은 감정적인 텍스트 음성 변환(Emotional Text-to-Speech, TTS) 분야의 최신 연구 동향과 한계점을 제시하고, 이를 해결하기 위해 EmoSphere-TTS 모델을 제안하는 내용이다. 감정 TTS의 발전과 한계점: 최근 ...
47.Emotion LLM 스펙 정리
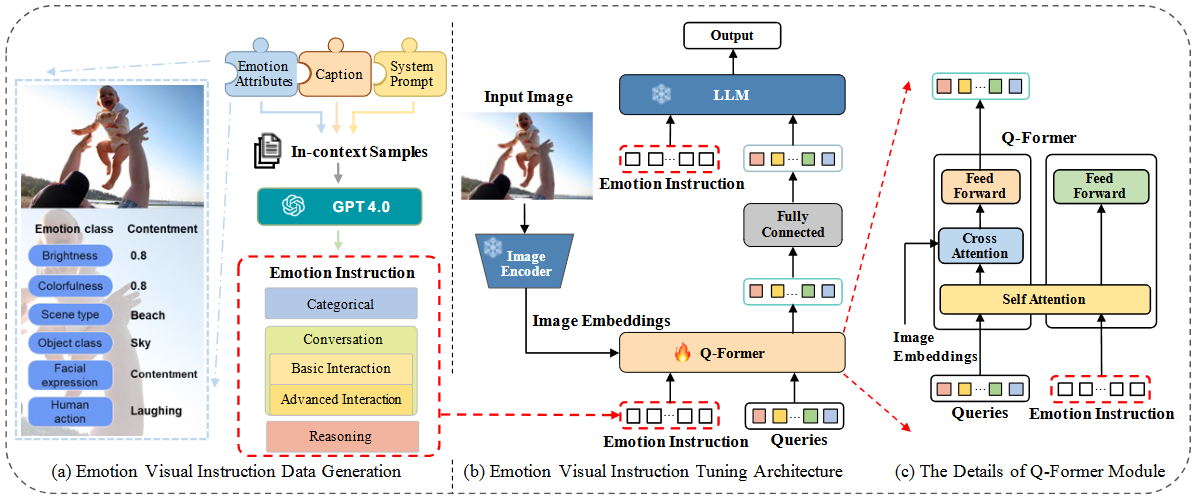
이 섹션은 EmoVIT의 핵심적인 혁신 중 하나로, 시각 감정 인식 분야의 주석이 달린 명령 데이터 부족 문제를 해결하기 위해 GPT-4 3를 활용하여 명령 데이터를 자동 생성하는 파이프라인이다.단계별 프로세스:입력 이미지 (Input Image): 감정 명령 데이터를
48.Real3D-Portrait: One-shot Realistic 3D Talking Portrait Synthesis (ICLR 2024 Spotlight)
기존 Talking head의 연구2D Talking HeadGAN 기반으로 이미지를 생성하기 때문에, warping artifact, unrealistic distortion, temporal jitters 등이 발생. 특히 이런 오류는 고개가 크게 돌아갈 때 심각해
49.Can3Tok: Canonical 3D Tokenization and Latent Modeling of Scene-Level 3D Gaussians (CVPR 2025)

VAE(Variational Autoencoder)에서 잠재 공간(Latent space)은 입력 데이터의 핵심 정보를 압축하여 저장하는 저차원 연속 공간이다. 이 공간의 각 점은 원본 데이터의 특징을 나타내는 잠재 벡터(latent vector)이다. VAE의 인코더
50.SemGauss-SLAM: Dense Semantic Gaussian Splatting SLAM (IROS 2025)
논문 링크: https://arxiv.org/pdf/2403.07494 Introduction SemGauss-SLAM은 3D 가우시안 표현 기법을 활용하여 정밀한 3D 의미론적 매핑(Semantic Mapping)과 견고한 카메라 추적(Tracking), 그리고 고품질 렌더링을 동시에 수행하는 밀집 의미론적 SLAM 시스템이다. 논문의 서론에서 강조하...
51.Hier-SLAM: Scaling-up Semantics in SLAM with a Hierarchically Categorical Gaussian Splatting (ICRA 2025)
Introduction 계층적 구조의 중요성: 현실 세계의 시맨틱 정보는 본질적으로 계층적인 구조를 가진다. 예를 들어, '자동차'라는 클래스는 '차량'이라는 더 큰 범주 아래에 있고, '차량'은 다시 '운송 수단' 아래에 속하는 식이다. 기존의 평면적인 시맨틱 표현 방식은 이러한 계층적 특성을 반영하지 못하여 정보의 압축률이 낮고, 복잡한...
52.VGGT: Visual Geometry Grounded Transformer (CVPR 2025 Best Paper Award)
1. Introduction SfM의 전통적 방식과 딥러닝의 결합: 과거의 3D 재구성(Structure-from-Motion, SfM)은 주로 Bundle Adjustment(BA)와 같은 반복적인 최적화 기법에 의존했다. 최근에는 feature matching이나 monocular depth estimation에 머신러닝을 결합한 연구가 활발하다. 특히...
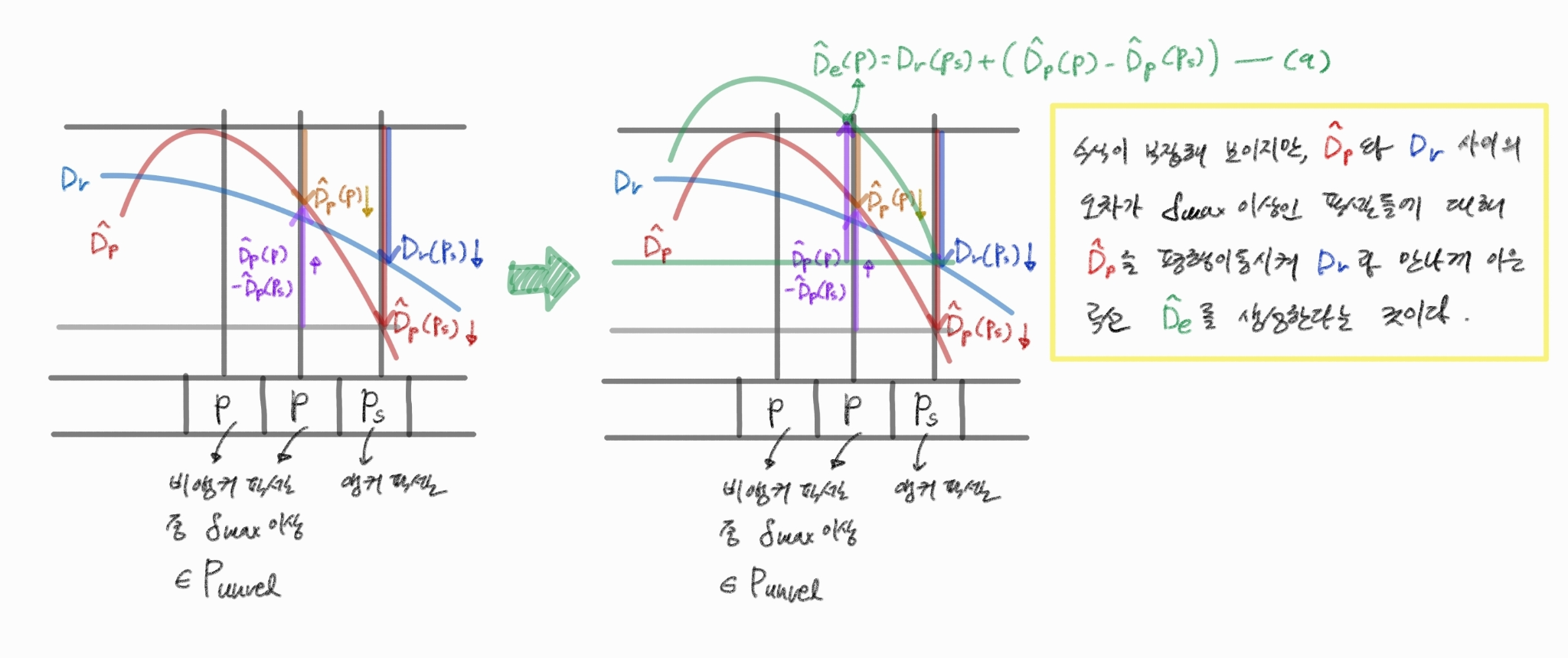
53.3D Gaussian Splatting Rasterization
가우시안 스플래팅을 표현법으로 사용한 SLAM 논문에서 이에 대한 수식을 간단히 짚고 넘어가는데, 한 번 깊게 이해하고 정리해둘 필요가 있어 해당 포스트를 적는다. 위 이미지의 $(1), (2), (3)$번 식을 이해해보자. 논문 링크: https://arxiv.org/pdf/2506.06909 1. 중심 좌표 투영 공식 이 수식은 3차원 공간에 ...
54.InstanceGaussian: Appearance-Semantic Joint Gaussian Representation for 3D Instance-Level Perception (CVPR 2025)
1. Introduction 논문에서 지적한 기존 연구의 세 가지 핵심 한계점과 InstanceGaussian이 이를 어떻게 해결했는지 설명한다. 1.1. 외형과 의미 정보의 불균형 (Imbalance between Appearance and Semantics) 한계
55.Efficient Decoupled Feature 3D Gaussian Splatting via Hierarchical Compression (CVPR 2025)
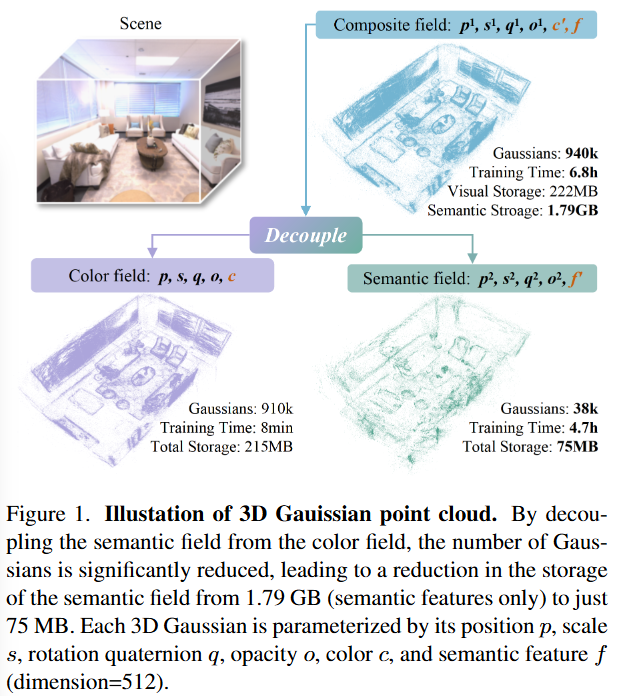
3D Gaussian Splatting의 효율성을 극대화하기 위해 제안된 Decoupled Feature 3D Gaussian Splatting의 필요성과 핵심 아이디어를 설명하고 있다.기존 연구의 한계:최근 3D 비전 분야에서는 Neural Radiance Field
56.트랜스포머의 셀프 어텐션 이해하기
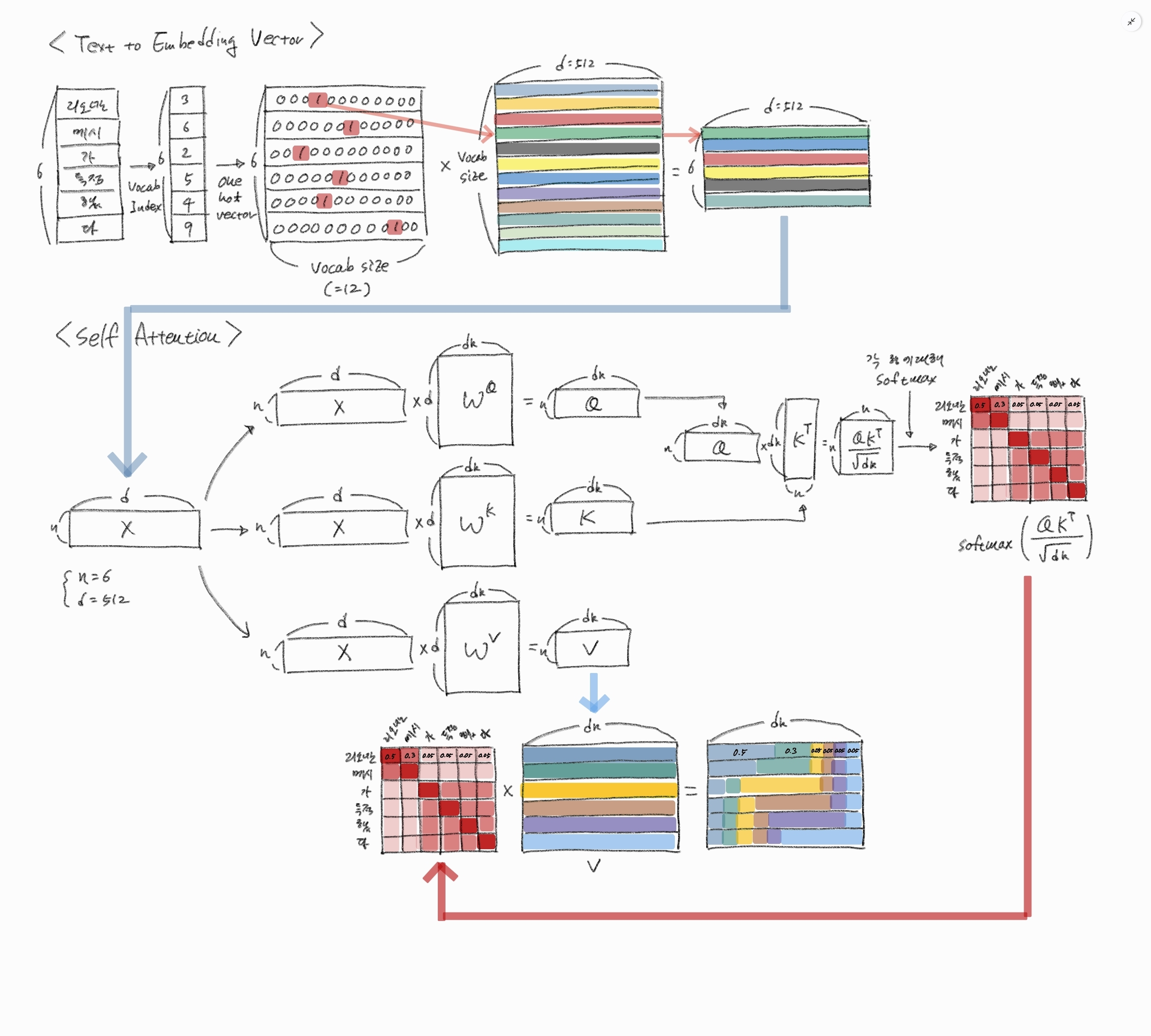
트랜스포머의 셀프 어텐션은 한 번 이해해둬도 자주 까먹어서 이번 기회에 깊게 정리해본다. 1. 전체 그림의 의미 내가 그린 도표는 문장 $$ \text{``리오넬 메시가 득점했다.''} $$ 가 트랜스포머 내부에서 어떻게 숫자 행렬로 바뀌고, 그 행렬이 셀프
57.VGGS: VGGT-guided Gaussian Splatting for Efficient and Faithful Sparse-View Surface Reconstruction (AAAI 2026)
Sparse-view 3D surface reconstruction은 적은 수의 입력 이미지로부터 정확한 3D 표면을 복원하는 문제다. NeRF와 3D Gaussian Splatting 계열 방법은 dense-view setting에서는 좋은 성능을 보이지만, 입력 v