1. Introdcution

1.1 Identity-Free Pre-training
해당 텍스트는 InsTaG(Instant Talking Head Synthesis with Gaussian Splatting) 프레임워크의 핵심 구성 요소 중 하나인 Identity-Free Pre-training (신원 독립적 사전 학습) 전략에 대해 설명하고 있다. 이 전략은 몇 초 길이의 짧은 비디오만으로도 고품질의 개인화된 3D Talking Head를 빠르게 학습하기 위해 고안되었다.
-
배경 및 동기:
- 기존 Radiance-field 기반 방법들을 관찰한 결과, 연구진은 두 가지 중요한 사실을 발견했다.
- 초기 정적 3D Head 재구성: 기본적인 오디오-구동 움직임을 학습하는 데는 오랜 시간이 걸리지만, 정적인 3D Head는 초기 몇 번의 반복(iteration)만으로도 잘 재구성된다.
- 제한된 데이터에서의 개인화된 움직임: 제한된 데이터로 학습할 경우 결과물이 불안정하고 품질이 떨어질 수 있지만, 입술 움직임의 일부는 여전히 뚜렷한 개인화된 스타일을 가지고 인식 가능하게 유지된다.
- 이러한 관찰은 공통적인 오디오-움직임 지식이 확보된다면, 짧은 비디오 클립만으로도 특정 Talking Head를 학습하는 데 필요한 풍부한 개인화 단서를 제공할 수 있음을 시사한다.
- 이에 영감을 받아, 미리 학습된 신원 독립적인 3D motion field를 사전 지식(prior)으로 준비하고 이를 새로운 신원에 정렬(align)하여 적응(adaptation)을 용이하게 하는 InsTaG 프레임워크를 제안한다.
- 기존 Radiance-field 기반 방법들을 관찰한 결과, 연구진은 두 가지 중요한 사실을 발견했다.
-
문제점: 신원 충돌 (Identity-Conflict):
- InsTaG는 Universal Motion과 Personalization 학습을 사전 학습(pre-training)과 적응(adaptation)으로 완전히 분리하여, 새로운 신원에 대한 person-specific 학습을 위해 사전 학습된 3D motion field를 준비한다.
- 하지만 이러한 설계에서 다중 인물 데이터로 사전 학습을 진행할 때 "신원 충돌"이라는 문제가 발생한다.
- 첫째, 다양한 신원이 하나의 person-specific 모델에 공존할 수 없다.
- 둘째, 모델이 다른 사람들을 분리하지 못하면, 충돌하는 개인화된 움직임이 모델의 수렴을 방해하고, 노이즈에 과적합(overfitting)되어 사전 학습된 모듈을 오염시킬 수 있다.
-
해결책: Identity-Free Pre-training 전략:
- 이 문제를 해결하기 위해 Identity-Free Pre-training 전략을 도입한다.
- Universal Motion Field (UMF): 사전 학습된 모듈로서, 대부분의 신원에 적합한 일반적으로 정확한 얼굴 움직임을 예측하는 것을 목표로 한다. 신원 정보를 포함하지 않는 보편적인 움직임 prior를 담고 있다.
- Temporary Personal Fields (임시 개인 필드): 각 훈련 비디오에 대해 일련의 임시 개인 필드를 유지하여 신원 정보를 저장하고 개인화된 움직임을 걸러낸다.
- Negative Contrast Loss (음의 대비 손실):
- 개인화된 움직임과 보편적인 움직임의 분리를 더욱 촉진하기 위해 도입된다.
- 이 손실은 두 가지 원칙을 따른다.
1.2 Motion-Aligned Adaptation
InsTaG는 사전 학습된 UMF (Universal Motion Field)를 새로운 신원(identity)에 빠르고 높은 품질로 적응시키기 위해 Motion-Aligned Adaptation 전략을 제안한다. 이는 주로 세 가지 핵심 기술로 구성되어 있다.
-
Motion Aligner (모션 정렬기)
- 목표: 사전 학습된 UMF가 새로운 신원의 다양한 얼굴 구조와 모션 스케일에 적절히 맞춰지도록 조절하는 것이다. 기존의 UMF는 보편적인 모션 지식을 담고 있지만, 특정 개인의 미묘한 차이까지 반영하기는 어렵다.
- 문제점:
- 구조적 편향: 새로운 신원의 얼굴 구조가 UMF의 암시적(implicit) 구조적 가정과 다를 수 있다.
- 모션 스케일 불일치: 새로운 신원의 특유한 모션 스케일이 UMF의 보편적 모션 스케일과 일치하지 않을 수 있다.
- 해결책:
- 조건 독립적 primitive-wise coordinate offset 학습:
Motion Aligner는 다중 해상도 positional encoder ()를 통해 공간 정보를 저장하고, Gaussian primitive의 중심 가 모션 필드를 쿼리하기 전에coordinate offset를 예측한다. 이 오프셋은 어떤 조건(오디오, 표정)에도 독립적으로 얼굴 구조의 불일치를 보정한다. - 모션 스케일러 학습: UMF에서 예측된 universal deformation 의 위치 변형 부분()에
scaling factor를 곱하여 모션 스케일을 정렬한다.
- 조건 독립적 primitive-wise coordinate offset 학습:
- 효과: 필드 내의 개인화된 모션과 보편적인 모션 사이의
intra-alignment(내부 정렬)를 돕고, 적은 수의 데이터로 미세 조정(few-shot fine-tuning)하는 동안 학습된 지식의 보존을 극대화한다.
-
Face-Mouth Hook (얼굴-입 연결 기술)
- 목표: 얼굴(입술 포함)과 입 안쪽 움직임 사이의
inter-alignment(상호 정렬)를 강화하고, 적은 데이터로 인해 발생할 수 있는 불일치(misalignment) 문제를 해결하여 일반화 능력을 향상시키는 것이다. - 문제점: 기존의 face-mouth decomposition [66]은 얼굴과 입 안쪽을 분리하여 모델링하지만, 훈련 데이터가 부족할 경우 두 부분이 조화롭게 움직이지 못해 시각적 품질 저하를 초래할 수 있다.
- 해결책: 얼굴 브랜치에서 예측된 얼굴 모션 를 입 안쪽 브랜치의 모션을 가이드하는 "hook"으로 사용한다.
- 효과: 얼굴과 입 안쪽 모션 필드 사이에 명시적인 연결을 설정하여, 적은 훈련 데이터에서도 견고한 얼굴-입 정렬 성능을 제공하고, 시각적 충실도(fidelity) 및 모션 품질을 향상시킨다.
- 목표: 얼굴(입술 포함)과 입 안쪽 움직임 사이의
-
Geometry Prior Regularizer (기하학적 사전 지식 정규화)
- 목표: 제한된 뷰 커버리지로 인해 발생하는
geometry ambiguity(기하학적 모호성) 문제를 완화하고, 새로운 신원의 헤드 구조를 추정된 기하학적 사전 지식에 정렬하여view direction에 대한 견고성(robustness)을 높인다. - 문제점: Radiance fields는 학습된 뷰포인트 사이의 보간(interpolation)에서는 뛰어난 시각적 품질을 제공하지만, 외부로 벗어나는 뷰포인트(extrapolation)에서는
geometry degradation[31]이나 불안정성 [9]을 보일 수 있다. 이는 특히 훈련 데이터가 적을 때 심화된다. - 해결책: 고급 휴먼 지오메트리 추정기 [27]에서 제공하는
estimated monocular depth map와normal를 사용하여 렌더링된 깊이 맵 와 표면 법선 에 대한 정규화 손실을 추가한다. - 효과: 3D 헤드 구조 재구성에 추가적인 제약을 제공하여, 제한된 데이터 상황에서도 더욱 정확하고 견고한 기하학적 표현을 학습할 수 있도록 돕는다.
- 목표: 제한된 뷰 커버리지로 인해 발생하는
2. Related Work
-
3D Talking Head Synthesis
- 초기 연구: 초기에는 [8, 14, 25, 45, 52, 54, 71]와 같은 연구들이 주로 2D 이미지 기반의 생성 모델(generative models)을 사용하여 talking head를 합성하는 데 중점을 두었다.
- 한계점: 머리 움직임 시 발생하는 시간적 불일치(temporal inconsistency) 문제가 있었다.
- 3D 기반 방법의 등장: 이후 [39, 51, 62, 68]와 같은 연구들은 명시적인 3D 얼굴 구조(explicit 3D face structure)를 활용하여 자연스러움을 개선하였다.
- Radiance Fields 기반 방법의 발전: 최근 [41]의 NeRF(Neural Radiance Fields)와 [26]의 3DGS(3D Gaussian Splatting)와 같은 Radiance Fields가 3D 표현(3D representations)에 도입되면서 이 분야에 상당한 발전을 가져왔다.
- Person-specific training: 대부분의 Radiance Fields 기반 방법들 [10, 19, 30, 33, 37, 44, 49]은 특정 인물(person-specific)에 대해 수분 길이의 고품질 비디오를 사용하여 모델을 훈련시킨다.
- 장점: 사실적인 렌더링(photorealistic rendering)과 개인화된 말하는 스타일(personalized talking style)을 성공적으로 재구성한다.
- 한계점: 각 새로운 인물(new identity)에 적응하기 위해 엄격한 훈련 비디오 데이터 품질 요구 사항과 긴 훈련 시간이 필요하며, 학습된 모델이 다른 인물에게 일반화(generalizability)되지 않는다는 단점이 있다.
- Few-shot 또는 One-shot 방법: 일부 연구 [36, 47, 59–61, 64]는 이러한 문제를 해결하기 위해 one-shot 생성기(one-shot generator)를 사용하거나 외부 모듈에서 사전 훈련된 모션을 가져와 적응(adaptation)에 느슨하게 결합하려고 시도한다.
- 한계점: 이러한 방법들은 이미지 품질과 개인화 수준, 효율성 면에서 타협을 보는 경우가 많다.
- InsTaG의 차별점: InsTaG는 person-specific 모델의 사전 훈련(pre-training)을 가능하게 하고, 사전 훈련된 모션 필드(pre-trained motion field)를 사용하여 talking head를 직접 구동함으로써, 더 작고 일관된 아키텍처로 모션 프라이어(motion priors)를 end-to-end 방식으로 완전히 활용하여 높은 효율성으로 정밀한 립싱크를 모델링하는 데 유리하다. 이는 MimicTalk [60]과 같은 동시 연구가 LoRA [24]를 사용하여 미세 조정(fine-tuning) 효율성을 개선하지만, 대규모 백본(large backbone)으로 인해 추론(inference)이 느리다는 점과 대비된다.
- Person-specific training: 대부분의 Radiance Fields 기반 방법들 [10, 19, 30, 33, 37, 44, 49]은 특정 인물(person-specific)에 대해 수분 길이의 고품질 비디오를 사용하여 모델을 훈련시킨다.
- 초기 연구: 초기에는 [8, 14, 25, 45, 52, 54, 71]와 같은 연구들이 주로 2D 이미지 기반의 생성 모델(generative models)을 사용하여 talking head를 합성하는 데 중점을 두었다.
-
Few-shot 3D Head Reconstruction
- 초기 모델 기반 방법: [17, 50, 57, 65]와 같은 초기 모델 기반 방법들은 3DMM(3D Morphable Models) [4, 34, 43]을 사용하여 3D head를 피팅하는 데 집중했지만, 디테일이 부족했다.
- 신경 필드 기반 방법: 신경 필드(neural fields)와 결합된 [5, 40, 46]와 같은 모델 프리(model-free) 방법들은 적은 이미지로 정적인(static) head를 학습한다.
- 동적 Head 재구성 시도: [6, 15, 18, 22, 48, 56, 58]와 같은 많은 연구들은 적은 비디오로 동적(dynamic) head를 재구성하려고 시도했다.
- 한계점: 이러한 방법들은 오디오로부터 예측하기 어려운 파라메트릭 컨트롤(parametric controls)을 사용하며, 입 움직임의 세분화(granularity)를 제한하여 InsTaG가 달성하는 섬세한 오디오-구동 입 움직임(audio-driven mouth motions)을 가진 고도로 개인화된 3D talking head를 표현하기 어렵다.
- 생성 모델(Generative methods): [16, 20, 36, 55, 61, 67]와 같은 일부 생성 방법들은 3D 구조를 가진 talking head 재구성에 초점을 맞추지만, 단 한 장의 이미지로부터 개인화된 talking style을 추론하기 어려워 개인화와 충실도(fidelity)가 약하다는 한계를 가진다.
- Few-shot NeRF 기반 방법: [29, 47, 60]와 같은 최근 연구들은 2D-to-3D 모듈을 사전 훈련과 함께 도입하지만, 오버헤드(overhead)로 인해 속도가 느린 경우가 많다.
- InsTaG의 차별점: InsTaG는 identity-free 모션 프라이어(identity-free motion prior)와 person-specific 적응(person-specific adaptation) 방식을 통해, 값비싼 2D-to-3D 프라이어 대신 적은 데이터로부터 개인화된 오디오 구동 3D talking head를 빠르게 학습하며, 빠른 추론 속도(fast inference)를 달성한다.
3. InsTaG
3.1. 3DGS Talking Head Synthesizer
- 프레임워크의 목표: 이 연구는 "빠른 추론(fast inference)"과 "즉각적인 적응(instant adaptation)"을 통해 개인화된 3D 말하는 얼굴을 학습하는 것을 목표로 한다. 이러한 목표를 달성하기 위해서는 높은 표현 능력을 갖춘 동시에 경량(lightweight) 모델이 필수적이다.
- 기존 방법론 분류: 현재 존재하는 말하는 얼굴 합성 방법론은 크게 두 가지 범주로 나뉜다.
- Image-based (이미지 기반) 방법 [36, 60, 61]: 이러한 방법은 주로 입력 이미지에서 새로운 인물의 얼굴을 모방하여 생성하는 방식이다.
- 장점: 다양한 인물에 대해 비교적 좋은 일반화 능력(generalizability)을 보인다. 즉, 학습에 사용되지 않은 새로운 인물에게도 적용될 수 있는 잠재력이 있다.
- 단점: 하지만 이미지 기반이기 때문에 3D 구조를 명시적으로 다루기 어려워 "개인화(personalization)" 품질이 상대적으로 낮고, 추론 속도가 느린 경향이 있다.
- Person-specific (인물별 특화) 방법 [19, 30, 33, 49]: 이 방법은 특정 인물의 비디오 데이터를 사용하여 해당 인물만을 위한 모델을 학습시킨다.
- 장점: 학습 대상인 인물에 대해 매우 높은 충실도(fidelity)의 렌더링, 정교한 개인화된 움직임, 그리고 빠른 실행 속도를 제공한다. 이는 특정 인물의 미묘한 표정과 말하기 스타일을 정확하게 포착할 수 있다는 의미이다.
- 단점: 하지만 새로운 인물에 대해 모델을 적응시키려면 해당 인물의 많은 고품질 비디오 데이터와 상당한 학습 시간이 필요하다는 치명적인 한계가 있다.
- Image-based (이미지 기반) 방법 [36, 60, 61]: 이러한 방법은 주로 입력 이미지에서 새로운 인물의 얼굴을 모방하여 생성하는 방식이다.
- InsTaG의 선택: InsTaG는 높은 개인화 수준과 효율성이라는 요구사항에 가장 적합한 Person-specific 패러다임을 기반으로 한다. 이 논문은 기존 Person-specific 방법의 단점인 "많은 데이터 및 시간 요구사항"을 극복하고, "Few-second video(몇 초 길이의 비디오)"만으로도 빠르고 고품질의 개인화된 3D 말하는 얼굴을 생성하는 데 초점을 맞춘다. 이를 위해 3DGS 기반 합성기와 함께 범용 모션 사전 학습(universal motion priors) 및 정렬 적응(motion-aligned adaptation) 전략을 제안하는 것이다.
이러한 배경 속에서 InsTaG는 3DGS를 사용하여 경량 모델을 구축하고, 얼굴(face)과 입안(inside-mouth) 부분을 분리하여 모델링하는 전략(TalkingGaussian)을 채택하여 복잡한 얼굴 및 입 움직임을 정교하게 표현한다.
-
Structure Field:
- 정적인(static) Gaussian primitive들을 저장하는 역할을 한다.
- 각 Gaussian primitive는 위치(), 스케일(), 회전(), 불투명도(), 색상() 등의 매개변수 를 가진다.
- 얼굴(face)과 입 안쪽(inside-mouth)은 각각 독립적인 Structure Field를 갖는다.
-
Motion Field:
- Structure Field의 Gaussian primitive들을 동적으로 변형시키는 역할을 한다.
- 주어진 조건에 따라 Gaussian primitive의 위치, 스케일, 회전 변화량을 예측한다.
설정된 텍스트의 수식 (2)는 이 Motion Field가 변형 를 예측하는 방식을 나타낸다:
-
(변형, deformation):
- Gaussian primitive에 적용될 점 단위(point-wise) 변형을 나타낸다.
- 구체적으로는 위치 변화 , 스케일 변화 , 회전 변화 로 구성된다: .
- 이 변형은 정적인 Gaussian primitive들을 움직이게 만들어 동적인 얼굴 애니메이션을 생성하는 핵심 요소이다.
-
(뉴럴 필드, neural field):
- Motion Field의 핵심 구성 요소로, 입력 와 로부터 변형 를 예측하는 함수이다.
- MLP(Multi-Layer Perceptron)와 인코더 의 조합으로 구현된다.
-
(프리미티브 중심, primitive center):
- 변형을 질의할(query) Gaussian primitive의 3D 공간 상의 중심 위치를 의미한다.
- 즉, 어떤 가우시안을 얼마나 움직일지 결정하기 위해 그 가우시안의 현재 위치를 입력으로 사용한다.
-
(조건 피처 세트, condition feature set):
- Motion Field가 변형을 예측하는 데 사용하는 조건 정보를 담은 피처 세트이다.
- 이는 주로 오디오()와 상안면 표현 제어()를 포함한다.
- 오디오 : 화자의 음성 신호를 인코딩한 것으로, 주로 입술 움직임(lip motion)과 연관된 변형을 유도한다.
- 상안면 표현 제어 : 눈썹, 눈, 이마 등의 상안면 움직임을 제어하는 신호로, 전반적인 얼굴 표정 변화에 기여한다.
-
(다층 퍼셉트론, Multi-Layer Perceptron):
- 신경망의 한 종류로, 인코더 와 조건 피처 를 결합한 입력으로부터 최종 변형 를 디코딩(predict)하는 역할을 한다.
- 논문에서는 3-layer MLP 디코더를 사용한다고 언급되어 있다.
-
(트라이-플레인 해시 인코더, tri-plane hash encoder):
- Gaussian primitive의 3D 위치 를 고차원 피처 벡터로 인코딩하는 역할을 한다.
region attention (RA) module이 포함되어 공간 관계를 효과적으로 저장하고 활용한다.- 해당 모듈은
Efficient region-aware neural radiance fields for high-fidelity talking portrait synthesis논문에 제시된 방법으로, tri-plaen hash encoder가 눈, 코, 입 등의 얼굴 부위에 따라 개별적인 어텐션을 할 수 있도록 한다. - 이는 3D 공간 정보를 효율적으로 표현하고 접근하기 위한 기술이다.
-
(연결, concatenation):
H(μ)에 의해 인코딩된 공간 피처와C에 포함된 조건 피처(오디오, 상안면 표현)를 결합(concatenation)하는 연산을 의미한다.- 이렇게 결합된 피처는 MLP 디코더의 입력으로 사용되어, 위치와 조건에 따른 변형을 종합적으로 예측할 수 있게 한다.
렌더링 과정에서의 활용:
렌더링 단계에서는 이 Motion Field가 오디오 와 상안면 표현 등의 입력에 따라 Gaussian primitive 를 변형시킨다. 얼굴(face)과 입 안쪽(inside-mouth) 브랜치에서 각각 변형이 이루어지며, 최종적으로 두 브랜치의 결과가 결합되어 완성된 3D 토킹 헤드 이미지가 렌더링된다. 이를 통해 음성에 정확히 동기화되고 개인화된 사실적인 얼굴 움직임을 표현할 수 있다.
3.2. Identity-Free Pre-training
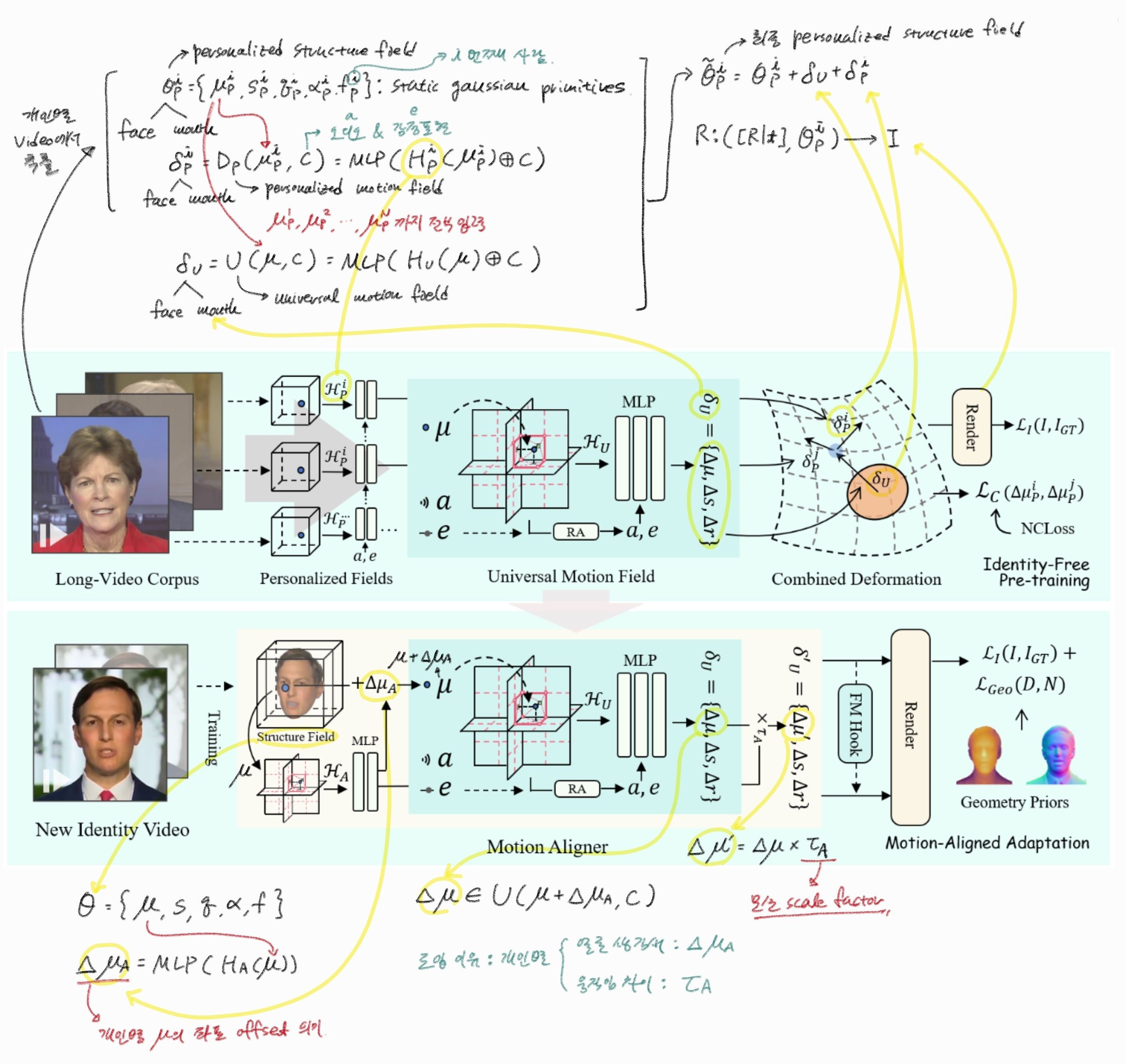

InsTaG는 짧은 영상 데이터만으로 개인화된 3D 토킹 헤드를 빠르게 학습하기 위해 "Identity-Free Pre-training (정체성 비의존적 사전 학습)" 전략을 도입한다. 이 전략은 개인화된 오디오-모션 매핑을 처음부터 학습하기 위한 데이터 부족 문제를 해결하고, 여러 인물의 공통된 모션 지식을 효과적으로 추출하는 데 중점을 둔다.
-
배경 및 동기:
- 짧은 영상 클립만으로는 개인화된 오디오-모션 매핑을 처음부터 학습하기에 데이터가 불충분하다.
- 새로운 인물에 대한 보상으로 긴 영상 데이터로부터 공통된 모션 지식(universal motion knowledge)을 추출하는 사전 학습이 필요하다.
- 기존 생성 모델 기반의 사전 학습 방식(One-Shot High-Fidelity Talking-Head Synthesis, Learning Dynamic Facial Radiance Fields, MimicTalk)은 다중 인물 입력으로 동일 모델을 학습하지만, InsTaG와 같은 사람-특정(person-specific) 모델은 "정체성 충돌 문제(identity-conflict problem)"에 직면한다.
- 서로 다른 인물이 하나의 사람-특정 모델에 공존할 수 없다.
- 모델이 다른 인물들을 분리하지 못하면, 충돌하는 개인화된 모션들이 모델 수렴을 방해하고 사전 학습된 모듈을 오염시킬 수 있다.
-
전략:
- 이러한 문제를 해결하기 위해, InsTaG는 신원(identity)에 의존하는 지식은 각 훈련 영상에 할당된 "Personalized Field (개인화 필드)"에 저장하도록 설계한다.
- 이를 통해 범용적인 모션 학습에서 신원 영향을 분리하고 "Universal Motion Field (범용 모션 필드, UMF)"를 사전 학습한다.
-
Universal Motion Field (UMF):
- UMF는 사전 학습된 모듈로서, 대부분의 인물에 적합한 공통적이고 올바른 얼굴 모션을 예측하는 것을 목표로 한다.
- 임의의 Gaussian에 대한 쿼리가 주어지면, UMF는 개인화되지 않은 범용 변형 를 예측한다. 이는 다음 수식과 같다:
- : 쿼리 Gaussian의 중심 (3D 공간 좌표)
- : 오디오 특징 와 상부 얼굴 표정 신호 를 포함하는 조건 특징 세트
- : UMF의 tri-plane hash encoder가 로부터 인코딩한 공간 정보
- : 컨캐티네이션 (concatenation)
- MLP: 다층 퍼셉트론 디코더로, 인코딩된 공간 정보와 조건 특징을 받아 변형 를 예측한다.
- : 각각 Gaussian의 중심 , 스케일 , 회전 에 대한 변형이다.
-
Personalized Fields (개인화 필드):
- 훈련 중, Personalized Fields는 공유되는 UMF와 협력하여 개인화된 토킹 헤드를 합성하며, 서로 다른 인물들의 영상으로부터 감독(supervision)을 가능하게 한다.
- 각 Personalized Field는 자체 소유 영상의 신원 외형(identity appearance)과 개인화된 모션(personalized motion)을 유지하기 위해 개인화된 구조 필드 와 더 작은 모션 필드 로 구성된다.
- UMF 는 -번째 인물에 대한 기본 변형을 예측하고, -번째 개인화 필드는 잔여 모션 를 예측하여 개인화된 조정을 수행한다.
- : -번째 Personalized Field의 Gaussian 중심.
- : -번째 Personalized Field의 hash encoder.
- 최종 렌더링을 위해 두 변형은 결합되어 개인화된 구조 필드를 변형한다.
- : 3DGS 렌더링 프로세스
- : 카메라 포즈 (머리 포즈)
- : 변형된 Gaussian 파라미터.
- 이 설계를 통해 서로 다른 인물의 영상들이 신원 충돌 없이 사전 학습에 사용될 수 있으며, 개인화된 모션은 범용 모션과 분리되어 개인화 필드에 독립적으로 저장된다.
-
Negative Contrast Loss (NCLoss):
- 개인화된 모션과 범용 모션의 분리를 가능하게 했지만, 어떤 모션이 개인화되어야 하고 어떤 모션이 범용적이어야 하는지 결정하는 문제가 발생한다.
- 이를 해결하기 위해 NCLoss를 도입한다.
- 원칙 1: 이상적인 개인화된 모션은 모델의 부드러운 수렴을 가능하게 하는 "최소한의 추가 모션"이어야 한다. 따라서 적을수록 좋다.
- 원칙 2: 원칙 1을 따르면서, 한 인물의 개인화된 모션은 다른 인물들의 개인화된 모션과 "달라야" 한다.
- NCLoss는 다음 수식과 같다:
- : Negative Contrast Loss이다.
- : -번째 개인화 필드(Personalized Field)에서 예측된 Gaussian 중심의 변형(μ-deformation)이다. 즉, 번째 인물의 개인화된 μ-변형을 나타낸다.
- : -번째 개인화 필드에서 예측된 Gaussian 중심의 변형이다. 즉, 번째 인물의 개인화된 μ-변형을 나타낸다.
- : 두 벡터의 내적(dot product)이다. 두 변형의 방향과 크기 유사성을 측정한다.
- : 트렁케이션 함수(truncation function)이다.
- 일 경우: 를 반환한다. 이는 두 개인화된 μ-변형이 유사한 방향을 가리키고 있을 때 패널티를 부여한다.
- 일 경우: 을 반환한다. 이는 두 변형이 서로 다른 방향을 가리키거나(음수 내적) 서로 독립적일 때(0 내적) 패널티를 부여하지 않는다.
- 이 손실은 서로 다른 개인화 필드에서 학습된 개인화된 모션이 서로 다양하도록(diverse) 장려한다. 내적 결과가 양수일 때, 즉 두 개인화 모션이 유사하게 움직이려 할 때 패널티를 줌으로써, 각 인물의 개인화 모션은 고유하게 유지되고 공통된 모션 지식은 UMF에 잘 수집될 수 있도록 유도한다. 이는 범용 모션이 개인화 필드에 부적절하게 저장되는 것을 방지하고, 반대로 너무 많은 범용 지식이 누락되는 것을 막는 데 기여한다.
InsTaG는 이러한 Identity-Free Pre-training을 통해 소량의 데이터로도 고품질의 개인화된 3D 토킹 헤드를 빠르게 학습할 수 있는 기반을 마련한다.
3.3. Motion-Aligned Adaptation

Motion-Aligned Adaptation은 InsTaG의 핵심 전략 중 하나로, 사전 학습된 Universal Motion Field (UMF)를 활용하여 새로운 인물의 3D Talking Head를 빠르고 고품질로 학습하는 방법을 다룬다. 특히, 이 전략은 3D Gaussian Splatting (3DGS) 기반 합성기가 변형을 직접 사용하여 렌더링하는 방식의 특징을 활용하여, 사전 학습된 모션을 새로운 인물의 머리에 정밀하게 정렬하는 데 초점을 맞추고 있다.
-
Motion Aligner (모션 정렬기)
- 문제점: 사전 학습된 UMF는 사람마다 다른 얼굴 구조(facial structure bias)와 모션 스케일(motion scale gap) 때문에, 처음 보는 인물에게 완벽하게 적용되기 어렵다.
- 해결책:
Motion Aligner를 도입하여 이러한 불일치를 조정한다. - 작동 방식:
- 좌표 오프셋 () 예측: 먼저, 다중 해상도 포지셔널 인코더 ()를 통해 공간 정보를 저장하고, 모션 필드에 쿼리하기 전에 가우시안의 중심 에 대한 좌표 오프셋 를 예측하여 기본 구조 바이어스를 조정한다.
- 수식:
- 여기서 는 Gaussian 원시(primitive)의 중심을 나타내고, 는 공간 정보를 저장하는 포지셔널 인코더이며, MLP는 다층 퍼셉트론(Multi-Layer Perceptron)이다. 이 오프셋은 새로운 인물의 얼굴 구조와 사전 학습된 필드 간의 불일치를 보정한다.
- 모션 스케일 팩터 () 예측: UMF로부터 얻은 universal deformation 의 부분에 곱해질 스케일 팩터 를 동일한 방식으로 예측한다.
- 수식: , 여기서
- 는 UMF가 예측한 universal deformation이며, 는 조정된 부분이다. 는 Universal Motion Field를 의미하며, 는 오디오 와 상위 얼굴 표정 를 포함하는 조건 피처 세트(condition feature set)이다.
- 이렇게 조정된 deformation 가 최종 렌더링에 사용된다.
- 좌표 오프셋 () 예측: 먼저, 다중 해상도 포지셔널 인코더 ()를 통해 공간 정보를 저장하고, 모션 필드에 쿼리하기 전에 가우시안의 중심 에 대한 좌표 오프셋 를 예측하여 기본 구조 바이어스를 조정한다.
- 목표: 사전 학습된 지식의 유지력을 극대화하면서, 인물 고유의 모션과 universal motion 간의
intra-alignment를 달성하는 것이다.
-
Face-Mouth Hook
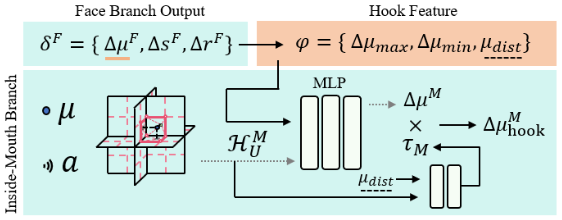
-
배경 및 문제점:
- 이 논문은 TalkingGaussian과 같은 이전 연구에서 사용된 얼굴-입 분해(Face-Mouth Decomposition) 방식을 채택한다. 이는 얼굴(입술 포함)과 입 안의 모델링을 두 개의 분리된 브랜치로 처리하는 것이다.
- 하지만 훈련 데이터가 부족할 경우, 이 두 부분이 조화롭게 움직이는 것을 학습하기 어렵고, 이는 시각적 품질 저하로 이어질 수 있다. 특히 입술과 입 안의 움직임이 비동기화될 수 있다.
- InsTaG는 이러한 문제를 해결하기 위해 Face-Mouth Hook이라는 새로운 기술을 제안한다.
-
Face Branch Output ():
- 얼굴 브랜치(Face Branch)는 얼굴의 움직임에 대한 변형 값 를 출력한다. 여기서 는 가우시안 중심의 변형(deformation), 는 스케일(scale), 는 회전(rotation)을 나타낸다.
- 이 논문에서는 특히 를 사용하여 입술 움직임의 단서를 추출한다.
-
Hook Feature () 추출:
- 얼굴 브랜치에서 예측된 로부터 입술 움직임에 대한 핵심적인 특징인 Hook Feature 가 추출된다.
- 이는 다음과 같이 정의된다: .
- : 중 가장 큰 값.
- : 중 가장 작은 값.
- : . 이 값은 얼굴 전체에서 가장 큰 변형량을 보이는 입술 움직임의 직접적인 스케일 단서(scale cue)로 사용된다.
- 이러한 특징들은 입술의 최대/최소 움직임 범위와 그 크기를 나타내어, 입 안 움직임이 얼굴 움직임과 일관되도록 유도하는 데 활용된다.
-
Inside-Mouth Branch에서의 Hook 적용:
- 입 안 브랜치(Inside-Mouth Branch)는 보편적인 모션 필드(Universal Motion Field)의 해시 인코더 를 통해 쿼리된 가우시안 중심 의 공간 정보를 인코딩한다.
- 여기에 오디오 입력 와 위에서 추출된 Hook Feature 가 결합되어 MLP(Multi-Layer Perceptron) 디코더의 입력으로 사용된다.
- 입 안 변형 예측: MLP는 이 입력들을 바탕으로 입 안의 변형 을 예측한다. 이는 다음 수식으로 표현된다.
- : 입 안 브랜치의 모션 필드(Universal Motion Field).
- : 쿼리 가우시안의 중심.
- : 오디오 특징.
- : 얼굴 브랜치에서 추출된 Hook Feature ().
- 모션 스케일링: 또한, Hook Feature의 값은 입 안 모션의 스케일링을 위해 사용된다. 는 또 다른 MLP에 입력되어 원시별(primitive-wise) 스케일링 팩터 을 예측하는 데 사용된다.
- 최종적으로 "hooked"된 입 안 변형 는 예측된 에 을 곱하여 얻어진다. 이는 다음 수식으로 표현된다.
- : 위에서 예측된 입 안 변형.
- : 입 안 모션의 스케일링 팩터.
- : 입 안 브랜치 UMF의 해시 인코더를 통해 얻은 의 인코딩.
- : Hook Feature에서 추출된 입술 움직임의 스케일 단서.
- 최종적으로 "hooked"된 입 안 변형 는 예측된 에 을 곱하여 얻어진다. 이는 다음 수식으로 표현된다.
-
효과:
- 이 Hook 메커니즘은 얼굴과 입 안의 모션 필드 사이에 명확한 연결을 설정하여, 입 안의 움직임(특히 벌어지는 정도)이 얼굴, 특히 입술의 움직임과 긴밀하게 정렬되도록 돕는다.
- 이는 훈련 데이터가 부족할 때 발생할 수 있는 얼굴-입 안 정렬 불량 문제를 효과적으로 해결하여, 시각적 품질과 움직임의 견고성을 크게 향상시킨다.
-
-
Geometry Prior Regularizer (기하학적 사전 정규화)
- 문제점: 시점 커버리지(view cover)가 부족하여 발생하는 3D 형상 모호성(geometry ambiguity)은 특히 3DGS의 기하학적 저하(geometry degradation) [31] 및 보지 못한 시점에서의 불안정성 [9]으로 이어진다.
- 해결책: 고급 인간 형상 추정기(human geometry estimator)인 Sapeins 모델[27]의 강력한 기능을 활용하여 추가적인 형상 단서(geometry cues)를 제공함으로써 정규화한다.
- 작동 방식:
- 렌더링 시 생성된 이미지 에서 2D 깊이 와 법선 를 계산한다.
- 추정된 모노큘러 깊이 맵 와 법선 를 ground-truth 이미지로부터 사용하여 정규화 손실을 계산한다.
- 수식:
- 는 스케일 불변 깊이 손실(scale-invariant depth loss)이고, 는 픽셀 에서의 법선을 나타낸다. 은 이미지 의 해상도이다.
- 목표: 부족한 뷰 커버리지로 인한 기하학적 불확실성을 줄이고, 보지 못한 각도에서도 3D 머리 구조를 더 견고하게 유지하여 시각적 품질을 향상시킨다.
이 세 가지 전략을 통합함으로써, InsTaG는 몇 초 길이의 짧은 비디오만으로도 높은 충실도와 개인화된 3D Talking Head를 빠르게 학습할 수 있게 된다.
3.4. Training Details
-
Photometric Loss ():
- 모델이 생성한 이미지 와 실제(ground-truth) 이미지 간의 시각적 유사성을 측정하는 주된 손실 함수이다.
- 3D Gaussian Splatting(3D Gaussian Splatting)의 방식에 따라 L1 손실과 D-SSIM(Image quality assessment) 항으로 구성된다. 이는 이미지의 픽셀 단위 정확도와 구조적 유사성을 동시에 고려한다.
-
Pre-training (사전 학습):
- Universal Motion Field (UMF)를 훈련하기 위해 여러 장기 비디오(long-video corpus)로부터 개의 비디오를 사용한다.
- 각 번째 비디오에 대한 사전 학습 손실 는 포토메트릭 손실과 Negative Contrast Loss ()로 구성된다:
- Negative Contrast Loss (): 개인화된 필드(Personalized Field) 간의 -변형() 쌍을 대조하여, 학습된 개인화된 움직임이 서로 다르게 나타나도록 유도한다. 이는 보편적인(universal) 움직임 사전 정보가 UMF에 최대한 많이 수집되도록 장려하며, 개인화된 움직임은 개별 Personalized Field에 격리되도록 돕는다.
- 사전 학습은 총 150,000회 반복(iteration)으로 진행된다.
-
Adaptation (적응 학습):
- 사전 학습된 UMF를 사용하여 새로운 아이덴티티에 특화된 모델을 초기화한다.
- Warm-up 단계: 처음에는 Motion Aligner와 Geometry Loss 없이 짧은 기간(3000회 반복) 동안 모델을 훈련하여 기본적인 헤드 형상을 구축한다.
- 이후 전체 손실 함수를 사용하여 훈련을 진행한다:
- 는 포토메트릭 손실과 Geometry Prior Regularizer를 결합하여 이미지 품질과 3D 구조의 견고성을 동시에 최적화한다.
- 적응 학습은 총 10,000회 반복으로 진행된다.
-
최적화 상세:
- AdamW(Decoupled Weight Decay Regularization) 옵티마이저를 사용하며, 그리드(grid)와 신경망(neural networks)에 각각 5e-3 및 5e-4의 학습률(learning rate)을 적용한다.
- 가중치 는 각각 1e-2, 1e-3, 1로 설정된다.
- 모든 실험은 RTX 3080 Ti GPU에서 수행되며, 전체 사전 학습에는 약 5시간이 소요된다.
4. Experiments
4.1 Datset
4.1.1. 사전 학습 데이터셋 (Pre-training Dataset)
- 목적: 사람의 얼굴 움직임에 대한 범용적인 모션 지식(universal motion priors)을 추출하기 위함이다. 이 지식은
Identity-Free Pre-training전략을 통해Universal Motion Field (UMF)에 저장된다. - 인물 구성: 적응(adaptation) 및 테스트 데이터셋에 사용되는 인물과 겹치지 않는(no identity overlap) 인물들로 구성된다. 이는 사전 학습 모델이 특정 인물에 과적합되지 않고, 보편적인 움직임을 학습하도록 보장한다.
- 출처 및 구성:
- 활용:
Identity-Free Pre-training단계에서Universal Motion Field (UMF)를 학습하는 데 사용된다.
4.1.2. 적응 데이터셋 (Adaptation Dataset)
- 목적: 사전 학습된
UMF를 바탕으로, 새로운 인물(unseen new identity)의 개인화된 3D 토킹 헤드를 빠르고 고품질로 학습(미세 조정/adapt)하기 위함이다. 이 단계에서Motion-Aligned Adaptation전략이 적용된다. - 인물 구성: 사전 학습 데이터셋의 인물과는 다르지만, 테스트 데이터셋과는 같은 인물이다.
- 출처 및 구성:
- 활용:
Motion-Aligned Adaptation단계에서 새로운 인물에 맞춰 모델을 미세 조정하는 데 사용된다.
4.1.3. 테스트 데이터셋 (Test Dataset)
- 목적: 적응 과정을 거친 모델이 학습되지 않은 새로운 오디오 입력에 대해 얼마나 사실적이고 개인화된 3D 토킹 헤드를 생성하는지 평가하기 위함이다.
- 인물 구성: 적응 데이터셋과 동일한 인물이지만, 모델이 학습 과정에서 전혀 보지 못한(unseen) 영상 프레임으로 구성된다.
- 출처 및 구성:
- Self-reconstruction setting: 적응 데이터셋으로 사용된 4개의 인물 비디오 각각에서 (5초, 10초, 20초 학습 클립을 제외한) 최소 12초 길이의 영상 클립을 테스트 세트로 사용한다.
- Cross-domain setting:
NVP [51]에서 가져온 보지 못한 영어 남성 오디오와[19]에서 가져온 독일어 여성 오디오를 사용하여 모델의 교차 도메인 일반화 능력을 평가한다. 이 경우, 모델은 20초 학습 데이터로 훈련된 후 이 오디오에 맞춰 영상을 생성한다. (이때는 오디오만 입력으로 주어지고, 실제 얼굴 이미지 GT는 없다).
- 활용:
- 모델에는 사전 정보로 테스트 데이터셋으로부터 추출된 오디오 a, 상부 얼굴 표정 제어 e(upper-face expression control), 카메라 포즈를 받는다.
- Self-reconstruction setting: 학습된 인물에 대한 재구성 및 동기화 품질을 PSNR, LPIPS, SSIM, LMD, AUE, Sync-C 등의 지표로 평가한다.
- Cross-domain setting: 모델이 새로운 언어, 성별, 발음 등 다양한 오디오 입력에 대해 얼마나 강건하게 동작하는지 평가한다.
요약:
| 데이터셋 유형 | 목적 | 인물 관계 | 출처 | 길이/구성 |
|---|---|---|---|---|
| 사전학습 | 범용 모션 지식 학습 | 적응/테스트 인물과 겹치지 않음 | [30], [59] | 5개 유명인 비디오, 각 5000 프레임 (약 3분 20초) |
| 적응 | 새로운 인물에 대한 개인화 모델 학습 | 사전 학습 인물과 다름, 테스트 인물과 같음 | [47], [59] | 4개 인물 비디오에서 추출한 5초, 10초, 20초 클립 |
| 테스트 | 학습된 인물의 성능 평가 (재구성/일반화) | 적응 인물과 같음, 모델이 보지 못한 프레임 | 적응 비디오의 나머지 부분, [51], [19] | 최소 12초 (self-reconstruction), 외부 오디오 (cross-domain) |
4.2 Comparsion
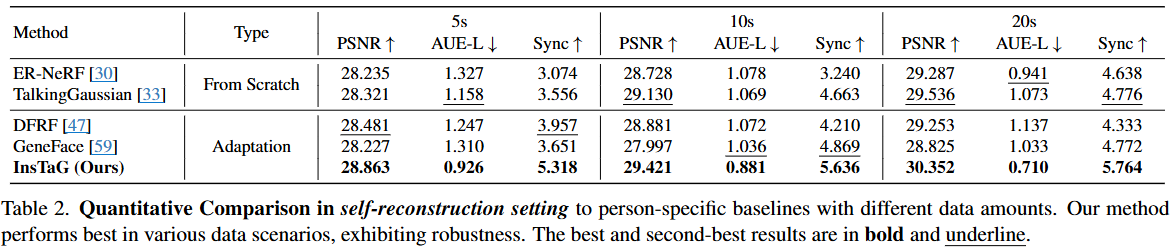
이 표는 다양한 적용 데이터 길이(5초, 10초, 20초)에 따른 여러 3D 토킹 헤드 합성 방법들의 성능을 정량적으로 비교한 결과이다.
- Methods (방법): 비교된 연구 방법들을 나열한다.
- ER-NeRF 및 TalkingGaussian은 "From Scratch" 방식에 해당한다.
- DFRF, GeneFace, 그리고 본 논문의 제안 방법인 InsTaG는 "Adaptation" 방식에 해당한다.
- Type (유형):
- From Scratch: 매 새로운 인물(identity)에 대해 모델을 처음부터 학습시키는 방법이다. 많은 훈련 데이터와 시간이 필요할 수 있다.
- Adaptation: 미리 대규모 데이터로 사전 학습된 모델을 새로운 인물 데이터에 맞춰 미세 조정(fine-tuning)하는 방법이다. 일반적으로 적은 데이터로 더 빠르게 학습할 수 있다.
- 5s, 10s, 20s: 각 방법이 훈련에 사용한 비디오 데이터의 길이(초)를 의미한다. 짧은 시간일수록 "few-shot" 또는 "few-second" 학습 시나리오에 해당한다.
- Metrics (평가지표):
- PSNR ↑ (Peak Signal-to-Noise Ratio): 렌더링된 이미지의 화질을 측정하는 지표이다. 원본 이미지와 합성 이미지 간의 픽셀 값 차이를 기반으로 하며, 값이 높을수록 원본과 유사하여 화질이 좋음을 의미한다.
- AUE-L ↓ (Action Unit Error - Lower face): 하관(lower face) 움직임의 정확도를 나타내는 지표이다. Action Unit은 얼굴 근육 움직임에 따른 표정을 표준화한 단위인데, AUE-L은 하관 부위의 Action Unit 예측 오류를 의미한다. 값이 낮을수록 대상 인물의 개인화된 말하기 동작을 더 정확하게 재현함을 나타낸다.
- Sync ↑ (SyncNet confidence): 립싱크(Lip-synchronization) 정확도를 측정하는 지표이다. SyncNet은 음성과 입술 움직임의 동기화를 평가하는 모델이며, 값이 높을수록 음성과 입술 움직임이 더 잘 일치함을 의미한다.
- 결과 표기: 각 지표에서 가장 좋은 성능은 굵은 글씨로, 두 번째로 좋은 성능은 밑줄로 표시되어 있다.
결과 분석:
- From Scratch 방식: ER-NeRF와 TalkingGaussian은 훈련 데이터가 증가함에 따라 PSNR, AUE-L, Sync 점수가 전반적으로 향상되는 경향을 보인다. 하지만 다른 Adaptation 기반 방법들, 특히 InsTaG에 비해 전반적인 성능이 낮은 편이다. 이는 짧은 데이터로 처음부터 학습하는 것이 고품질의 결과를 내기 어렵다는 것을 시사한다.
- Adaptation 방식: DFRF, GeneFace, InsTaG는 사전 학습된 지식을 활용하여 새로운 인물에 적응하므로 From Scratch 방식보다 효율적이다.
- DFRF는 5초 데이터에서 PSNR이 상대적으로 좋지만, AUE-L과 Sync는 InsTaG보다 떨어진다.
- GeneFace는 데이터 양이 증가함에 따라 Sync가 다소 향상되지만, PSNR이나 AUE-L에서는 InsTaG에 미치지 못하는 모습을 보인다.
- InsTaG (Ours)의 성능:
- InsTaG는 5초, 10초, 20초의 모든 훈련 데이터 시나리오에서 PSNR, AUE-L, Sync 지표 모두에서 가장 좋은 성능을 달성하였다.
- 특히 5초의 매우 짧은 훈련 데이터만으로도 다른 최신 방법들보다 월등히 높은 립싱크 정확도(Sync: 5.318)와 개인화된 움직임 재현 능력(AUE-L: 0.926)을 보여주어, 적은 데이터로도 고품질의 결과를 얻을 수 있다는 본 논문의 핵심 강점을 입증한다.
- 훈련 데이터의 양이 늘어남에 따라(5s -> 10s -> 20s), InsTaG의 모든 지표(PSNR, AUE-L, Sync)가 꾸준히 개선되는 경향을 보여주어, 다양한 데이터 시나리오에 대한 견고성과 확장 가능성을 입증한다.
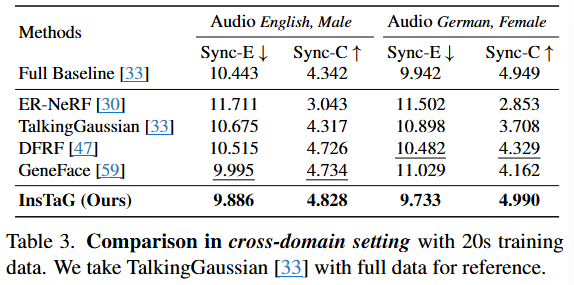
이 표(Table 3)는 20초의 훈련 데이터를 사용하여 교차 도메인(cross-domain) 환경에서 다양한 3D 토킹 헤드 합성 방법들의 성능을 비교한 결과이다. 특히, 훈련 데이터는 영어 여성 비디오에서 20초를 사용하여 각 모델을 훈련하고, 테스트 오디오는 영어 남성과 독일어 여성이라는 다른 특성을 가진 오디오를 사용하여 모델의 일반화 능력과 견고성을 평가한다.
-
교차 도메인 설정(Cross-domain Setting) 이해:
- 모델들은 특정 정체성(identity)을 가진 "영어 여성"의 20초 비디오 데이터로 훈련된다.
- 하지만 실제 테스트는 "영어 남성" 오디오와 "독일어 여성" 오디오를 사용하여 진행된다.
- 이러한 설정은 모델이 훈련 과정에서 보지 못했던 새로운 인물(남성), 다른 언어(독일어), 다른 성별(여성이지만 훈련 데이터와는 다른 사람)의 오디오에 대해 얼마나 잘 일반화되어 자연스러운 립싱크를 생성하는지를 측정한다.
- 이는 실제 애플리케이션에서 새로운 사용자나 다양한 언어에 대한 모델의 유용성을 평가하는 데 매우 중요하다.
-
평가 지표:
- Sync-E (SyncNet Error): 오디오와 입술 움직임 간의 동기화 오류를 나타내는 지표이다. 이 수치는 낮을수록 오디오와 비디오가 더 정확하게 동기화되었음을 의미한다. SyncNet에서 파생된 메트릭이다.
- Sync-C (SyncNet Confidence): 오디오와 입술 움직임 간의 동기화에 대한 신뢰도를 나타내는 지표이다. 이 수치는 높을수록 동기화의 신뢰도가 높고, 이는 더 정확하고 자연스러운 립싱크를 의미한다. 이 역시 SyncNet에서 파생된 메트릭이다.
-
각 방법론:
- Full Baseline [33]: TalkingGaussian 논문에서 전체 데이터를 사용하여 훈련된 모델의 성능을 참고용으로 제시한다. 이 값은 교차 도메인 테스트 결과가 아니며, 이상적인 성능 기준을 나타내는 역할을 한다.
- ER-NeRF [30]: Efficient Region-Aware Neural Radiance Fields 방법이다.
- TalkingGaussian [33]: Structure-Persistent 3D Talking Head Synthesis via Gaussian Splatting 방법이다.
- DFRF [47]: Learning Dynamic Facial Radiance Fields for Few-Shot Talking Head Synthesis 방법이다.
- GeneFace [59]: Generalized and High-Fidelity Audio-Driven 3D Talking Face Synthesis 방법이다.
- InsTaG (Ours): 본 논문에서 제안하는 방법이다.
-
InsTaG (Ours)의 성능:
- Audio English, Male:
- Sync-E는 9.886으로, 모든 비교 방법 중 가장 낮은 오류를 기록하였다. (GeneFace [59]의 9.995보다 우수하다.)
- Sync-C는 4.828로, 모든 비교 방법 중 가장 높은 신뢰도를 기록하였다. (GeneFace [59]의 4.734보다 우수하다.)
- Audio German, Female:
- Sync-E는 9.733으로, 모든 비교 방법 중 가장 낮은 오류를 기록하였다. (DFRF [47]의 10.482보다 우수하다.)
- Sync-C는 4.990으로, 모든 비교 방법 중 가장 높은 신뢰도를 기록하였다. (Full Baseline [33]의 4.949보다 근소하게 우수하다.)
- Audio English, Male:
-
결론:
- InsTaG는 20초의 훈련 데이터만을 사용했음에도 불구하고, 교차 도메인 설정(즉, 훈련 시 보지 못했던 새로운 인물, 성별, 언어의 오디오)에서 다른 최신 방법론들보다 훨씬 뛰어난 립싱크 동기화 성능을 보여준다.
- 특히, "Full Baseline [33]"이 전체 데이터를 사용하여 얻은 결과(영어 남성 Sync-C 4.342, 독일어 여성 Sync-C 4.949)와 비교했을 때, InsTaG는 20초의 적은 데이터로도 그에 필적하거나 심지어 더 나은 Sync-C 값을 달성하여 본 방법론의 뛰어난 일반화 능력과 효율성을 입증한다. 이는 "pre-training"과 "adaptation" 전략이 효과적으로 작용했음을 시사한다.
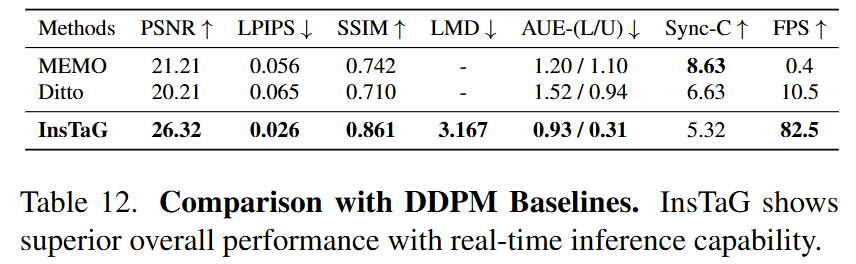
이 섹션은 InsTaG 방법론의 성능을 Diffusion Model (DDPM) 기반의 최신 기술과 비교하는 내용을 다루고 있다.
- 비교 대상 모델:
- 이 논문은 현재 DDPM 기반 방법 중 최첨단(SOTA)으로 평가받는 두 가지 모델, MEMO와 Ditto를 InsTaG와 비교한다.
- 이 두 모델은 512x512 해상도의 이미지 생성을 지원하며, 이는 Table 1에서 제시된 주요 정량적 비교 결과와 일관성을 유지하기 위해 선택된 기준이다.
- 비교의 한계 및 지표:
- DDPM 기반 모델들은 일반적으로 얼굴 이미지 생성에는 뛰어나지만, "head trace (머리 움직임 궤적)를 재현할 수 없다"는 중요한 한계가 있다. 즉, 특정 인물의 머리 움직임을 정확히 추적하고 재현하는 데에는 InsTaG와 같은 3D Talking Head 모델과 차이가 있을 수 있다.
- 이러한 한계 때문에, 비교는 주로 "aligned face (정렬된 얼굴)의 이미지 품질 지표"에 초점을 맞춘다. 이는 얼굴의 외형적 사실성 및 품질에 대한 평가를 의미하며, PSNR, LPIPS, SSIM과 같은 지표가 사용된다.
- 비교 결과:
- DDPM 기반의 생성 모델들(MEMO, Ditto)은 "개인화(AUE), 시각적 품질, 그리고 속도" 측면에서 InsTaG보다 성능이 저조함을 보인다.
- 특히, InsTaG는 실시간 추론(real-time inference)이 가능하며, 전반적으로 우수한 성능을 보여준다.
이러한 비교는 InsTaG가 특정 작업, 즉 "적은 데이터로 개인화된 3D Talking Head를 빠르고 사실적으로 학습하는 것"에 얼마나 효과적인지를 강조한다. DDPM은 일반적인 이미지 생성 능력은 뛰어나지만, 인물의 고유한 움직임과 외형을 고정된 3D 구조 안에서 정밀하게 제어하고 실시간으로 렌더링하는 데에는 InsTaG의 3D Gaussian Splatting (3DGS) 기반 접근 방식이 더 유리하다는 것을 시사한다. 이는 Radiance Fields나 3DGS와 같은 명시적/준명시적 3D 표현 방식이 동적 3D 아바타 생성에서 여전히 중요한 강점을 가지고 있음을 보여준다.
DDPM은 데이터 분포를 학습하여 새로운 데이터를 생성하는 데 탁월하며, 일반적인 이미지/비디오 생성 태스크에서는 인상적인 결과를 보여준다. 그러나 이 논문의 Talking Head 합성 태스크는 단순히 그럴듯한 이미지를 생성하는 것을 넘어, 특정 인물의 고유한 특성(Personalization), 오디오와의 정확한 립싱크(Lip-synchronization), 3D 일관성(3D consistency), 그리고 실시간 작동(Real-time inference)을 요구한다. DDPM이 이러한 미세하고 제어 가능한 동적 특성을 기존 아키텍처로 직접적으로 모델링하기에는 한계가 있음을 보여주는 결과이다. 반면, InsTaG는 3DGS와 보편적인 모션 프라이어(Universal Motion Prior)를 활용하여 이러한 제어 가능성과 효율성을 달성하고자 하였다.


이 섹션은 InsTaG 모델이 극단적인(extreme unseen) 시야각에서 학습된 3D 헤드를 어떻게 렌더링하는지를 시각적으로 보여주는 추가 실험 결과이다.
- 실험 목적: 5초의 짧은 학습 데이터로 학습된 3D 헤드가 이전에 보지 못한 매우 특이한 각도에서 얼마나 잘 작동하는지 검증한다. 이는 모델의 3D 구조 보존 능력과 일반화 능력을 평가하는 중요한 지표이다.
- 주요 결과:
- 3D 기하학적 일관성 유지: 논문의 Figure 11에 시각화된 결과는 InsTaG가 학습한 3D 기하학적 일관성(geometry consistency)이 극단적인 시야각에서도 잘 유지됨을 보여준다. 이는 얼굴의 형태나 구조가 심하게 왜곡되지 않고 원래의 일관성을 유지하고 있음을 의미한다.
- 텍스처 품질 저하: 학습 데이터 커버리지 부족(lack of data coverage)으로 인해 일부 텍스처(texture) 품질 저하가 발생할 수 있음을 언급한다. 이는 주로 정면(frontal) 위주의 제한된 학습 뷰에서 파생된 한계로 보인다. 즉, 모델이 보지 못한 각도의 세부적인 텍스처 정보를 충분히 학습하지 못했을 수 있다.
- 강력한 구조 보존: 학습 뷰가 주로 정면이었음에도 불구하고, 모델이 3D 헤드 구조를 효과적으로 보존하는 견고함(robustness)을 보여준다는 점을 강조한다. 이는 InsTaG의 핵심 기여 중 하나인 "Motion-Aligned Adaptation" 전략의 Geometry Prior Regularizer(Section 3.3 및 6.1에서 논의됨)가 제한된 데이터와 어려운 뷰 상황에서 3D 기하학적 안정성을 유지하는 데 중요한 역할을 했음을 시사한다.
이러한 결과는 InsTaG가 최소한의 학습 데이터만으로도 고품질의 3D 대화형 헤드를 생성할 수 있으며, 특히 3D 형상(geometry) 보존 능력이 뛰어나다는 것을 증명한다. 제한된 데이터로 학습하는 상황에서 발생하는 시야각 외삽(extrapolation) 문제에 대해 InsTaG가 효과적인 해결책을 제시하고 있음을 보여주는 대목이다.
4.3 Ablation Study
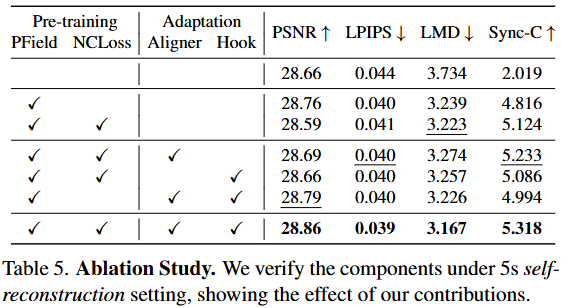
해당 표는 InsTaG 프레임워크를 구성하는 핵심 전략 및 모듈 각각의 기여도를 정량적으로 평가하기 위한 어블레이션 연구(Ablation Study) 결과이다. 각 구성 요소가 최종 성능에 미치는 영향을 파악하기 위해, 특정 구성 요소를 제외하거나 추가했을 때의 성능 변화를 보여준다. 실험은 5초 학습 데이터 환경에서의 자기 재구성(self-reconstruction) 설정을 기반으로 한다.
-
PField (Personalized Field)
- 설명: InsTaG의
Identity-Free Pre-training전략의 핵심 요소이다. 여러 다른 사람의 영상 데이터로 사전 학습할 때 발생하는 '신원 충돌(identity-conflict)' 문제를 해결하기 위해 도입되었다. Universal Motion Field(UMF)가 보편적인 모션 지식(universal motion prior)을 학습하는 동안, 각 학습 영상에 특화된 신원 정보와 개별화된 모션(personalized motion)은 이Personalized Field에 임시로 저장되어 UMF에 영향을 주지 않도록 한다. - 효과:
PField가 없으면(첫 번째 줄), 사전 학습이 신원 충돌 문제로 인해 효과적으로 이루어지지 못하여Sync-C점수(오디오-립싱크 일치도)가 2.019로 매우 낮게 나타난다.PField를 적용하면(✓표시된 두 번째 줄부터)Sync-C가 4.816으로 크게 상승하여, 사전 학습의 효과를 가능하게 하고 모션 학습에 중요한 기여를 함을 보여준다.
- 설명: InsTaG의
-
NCLoss (Negative Contrast Loss)
- 설명:
Identity-Free Pre-training전략의 두 번째 핵심 요소이다.PField가 각 신원의 개별화된 모션을 저장하는 역할을 하지만, 어떤 모션이 '개별화된' 것이고 어떤 모션이 '보편적인' 것인지 명확히 분리하기 어렵다.NCLoss는 서로 다른Personalized Field의 μ-변형(deformation) 쌍을 대조하여, 학습된 개별화된 모션들이 서로 다양하도록 장려한다. 이를 통해 불필요하게 보편적 모션 필드에 개별화된 모션이 저장되는 것을 방지하고, 보편적 모션 지식 수집을 극대화한다. - 효과:
PField만 적용했을 때(두 번째 줄)보다NCLoss를 추가했을 때(세 번째 줄),Sync-C점수가 4.816에서 5.124로 더욱 상승한다. 이는NCLoss가 개별화된 모션과 보편적 모션의 효과적인 분리를 촉진하고, 립싱크 정확도 향상에 기여함을 의미한다.
- 설명:
-
Aligner (Motion Aligner)
- 설명:
Motion-Aligned Adaptation전략의 핵심 요소이다. 사전 학습된UMF는 보편적인 모션 지식을 가지고 있지만, 새로 학습할 대상(new identity)의 얼굴 구조는 다양하기 때문에UMF의 모션이 모든 신원에 완벽하게 들어맞지 않을 수 있다.Motion Aligner는 대상의 얼굴 구조와UMF의 암묵적인 구조 간의 편향을 조정하기 위한 좌표 오프셋()과, 모션의 스케일 차이를 조정하기 위한 스케일링 팩터()를 학습한다. - 효과:
PField와NCLoss만 적용했을 때(세 번째 줄)보다Aligner를 추가했을 때(네 번째 줄),PSNR은 28.59에서 28.69로,Sync-C는 5.124에서 5.233로 개선된다. 이는Aligner가 사전 학습된 지식을 새로운 신원에 효과적으로 정렬하여 이미지 품질과 립싱크 정확도를 높이는 데 도움을 준다는 것을 보여준다.
- 설명:
-
Hook (Face-Mouth Hook)
- 설명:
Motion-Aligned Adaptation전략의 또 다른 핵심 요소이다. 이 논문은 얼굴(face)과 입 안(inside mouth) 모션을 두 개의 분리된 브랜치로 모델링하는Face-Mouth Decomposition기법을 사용한다. 그러나 데이터가 적은 상황에서는 이 두 부분이 조화롭게 움직이는 것을 학습하지 못해 불일치(misalignment)가 발생할 수 있다.Face-Mouth Hook은 얼굴 브랜치에서 예측된 얼굴 모션(특히 입술 모션)을 입 안 브랜치의 모션 학습에 가이드로 제공하여, 두 브랜치 간의 상호 정렬을 강화한다. - 효과:
PField와NCLoss에Hook만 추가했을 때(다섯 번째 줄)LMD는 3.223에서 3.257로 약간 증가했지만,PSNR은 28.59에서 28.66으로 개선되었다.Aligner와Hook을 모두 적용했을 때(PField,NCLoss,Aligner,Hook모두✓인 마지막 줄)PSNR은 28.86,LPIPS는 0.039,LMD는 3.167,Sync-C는 5.318로 모든 지표에서 가장 우수한 성능을 보인다. 이는Hook이 얼굴-입 불일치 문제를 해결하여 시각적 품질과 동적 품질을 모두 향상시키는 데 기여함을 의미한다. 특히,Aligner와Hook이 상호 보완적으로 작동하여 전반적인 성능을 극대화함을 알 수 있다.
- 설명:
