1. Introduction
-
FER의 중요성 및 정의:
- 얼굴 표정은 비언어적 의사소통에서 핵심적인 역할을 한다.
- FER은 입력 이미지나 비디오에서 얼굴 표정을 '중립', '행복', '슬픔' 등 미리 정의된 범주로 분류하는 작업이다.
- 마케팅, 교육, 감성 컴퓨팅 등 다양한 HCI(Human-Computer Interaction) 애플리케이션에 활용된다.
-
FER 연구의 발전과 한계:
- 최근 딥러닝과 AffectNet [33], RAF-DB [26], FERPlus [1]와 같은 대규모 데이터셋의 등장으로 FER 분야는 크게 발전했다.
- 다양한 자세, 조명, 가려짐 등 'in-the-wild' 상황에서의 오랜 난제들을 극복하고 있다.
- 하지만 여전히 주석자의 주관성으로 인한 잘못된 레이블링(mislabeling)과 미묘하고 복잡한 얼굴 표정으로 인해 데이터셋 수집의 어려움에 직면해 있다.
-
자기 지도 학습(Self-supervised Learning)의 가능성과 기존 대조 학습(Contrastive Learning)의 한계:
- 새로운 데이터와 주석을 수집하는 것은 시간과 노동 집약적이므로, 완전히 레이블링된 데이터에 의존하지 않는 자기 지도 학습, 특히 대조 학습이 잠재적인 해결책으로 부상하고 있다.
- 그러나 기존 FER 분야의 대부분의 대조 학습 접근 방식 [18, 19, 29, 32, 36]은 여전히 레이블링된 데이터를 필요로 한다는 한계가 있다.
- [29]와 [32]는 레이블링된 데이터셋을 사용하여 ID-불변 FER을 달성했다.
- [18]은 특징 변환에 대한 대조 학습을 수행했지만, 비레이블 데이터셋에 쉽게 적용하기 어렵다.
- [19]는 약한 감정과 강한 감정 간의 대조 학습을 수행했으나, valence 및 arousal 레이블이 필요하다.
- 레이블링되지 않은 데이터만을 사용하는 비지도 학습은 일반적으로 지도 학습보다 성능이 떨어진다 [35, 40, 48].
-
준지도 학습(Semi-supervised Learning)의 부상 및 본 연구의 차별점:
- 레이블링된 데이터를 최대한 활용하면서도 비레이블 데이터를 통합하는 준지도 학습이 주목받고 있다.
- [24]는 비레이블 데이터에 대해 의사(pseudo) 레이블을 얻고 신뢰도 점수에 따라 두 하위 집합으로 나누어, 신뢰도가 낮은 부분에 대조 학습을 적용하는 준지도 알고리즘을 제안했다.
- 하지만 이 방식의 신뢰도 점수는 대조 학습의 목표와 직접적으로 연관되지 않아 최적이 아닐 수 있다고 본 논문은 지적한다.
- 본 논문은 주의 학습(attention learning) 메커니즘을 대조 학습 내부에 통합하여, 대조 학습에 더 적합한 주의(attention)를 제안한다.
-
본 연구의 주요 기여:
- RM(Reaction Mashup) 비디오에서 RMset이라는 새로운 비레이블 데이터셋을 구축했으며, 이는 FER에서 준지도 대조 학습에 효과적으로 활용될 수 있는 최초의 대규모 비레이블 데이터셋이다.
- RMFER라는 새로운 준지도 대조 학습 프레임워크를 제안한다. 이는 샘플 간 주의(inter-sample attention)를 학습하며, 이를 통해 RMset과 같은 비레이블 데이터셋에서 대조 학습이 효과적으로 이루어지도록 한다.
- 광범위한 실험을 통해 RMFER가 AffectNet, RAF-DB, FERPlus 세 가지 벤치마크 FER 데이터셋에서 최신(state-of-the-art) 성능을 달성하며, 더 나은 특징 분포를 유도함을 검증한다.
이 논문은 기존의 FER 대조 학습이 레이블링된 데이터에 의존하는 한계를 극복하기 위해, 비레이블 Reaction Mashup 비디오를 활용한 새로운 데이터셋(RMset)과 주의 메커니즘이 통합된 준지도 대조 학습 프레임워크(RMFER)를 제안하여 FER 성능을 향상시키는 데 기여하고 있다.
2. Related Work
2.1. Deep Facial Expression Recognition
-
신원 불변 (Identity-invariant) FER:
- 개념: 현실 세계에서는 특정 인물에 구애받지 않고 표정을 인식하는 것이 중요하며, 신원 불변 FER은 이러한 목표를 달성하는 것을 의미한다.
- 기존 연구 방법:
- Liu et al.와 Identity-aware CNN은 동일 인물의 다른 표정 이미지를 "hard negatives"로, 다른 인물의 동일 표정 이미지를 "positives"로 간주하여 딥 매트릭 러닝을 수행하였다. 이를 통해 신원과 무관하게 표정을 인식하도록 유도한다.
- Yang et al.은 Conditional GAN을 활용하여 중립적인(neutral) 표정 이미지를 생성함으로써 표정 특징에서 신원 정보를 제거하는 접근 방식을 제안하였다.
- Learning a facial expression embedding disentangled from identity에서는 고정된 신원 모델에서 신원 특징을 추출하고, 동일한 구조의 얼굴 모델에서 얼굴 특징을 추출한 뒤, 두 특징 간의 편차를 표정 특징으로 사용하였다. 이후 FEC 데이터셋을 활용하여 표정 분포를 대조적으로 비교하였다.
- 본 연구와의 연관성: RMFER의 attention-based contrastive learning에서는 anchor 얼굴과 다른 인물이지만 같은 표정을 짓는 경우를 positive로, 동일 인물이지만 다른 표정을 짓는 경우를 negative로 간주한다. 즉, 같은 표정은 신원에 관계없이 동일하게 매핑되도록 학습하며, 이는 신원 불변 FER을 위한 전제이다.
-
FER을 위한 특징 학습 (Feature Learning for FER):
- 개념: FER에서 특징 학습은 같은 클래스(표정) 내의 유사성(intra-class similarity)을 최대화하고, 다른 클래스(표정) 간의 분리(inter-class separation)를 최대화하는 것을 목표로 한다.
- 기존 연구 방법:
- Island loss, Regularized center loss, DDL-loss와 같은 Center loss의 변형들이 제안되었다. 이들은 각 클러스터를 응집시키면서 클러스터 간의 거리를 증가시키는 기능을 한다.
- DACL은 각 특징에 대해 Center loss에 고유한 가중치를 할당하여, 모든 특징에 대해 거리를 동일하게 줄이는 기존 Center loss (A Discriminative Feature Learning Approach for Deep Face Recognition)와 달리, 모델에 대한 관련 없는 특징의 영향을 줄였다.
- Efficient facial feature learning with wide ensemble-based CNNs은 ESR (An ensemble with shared representations based on convolutional networks for continually learning facial expressions)이 대규모 FER에 포함될 수 있으며, CNN 앙상블 접근 방식이 더 나은 특징 학습을 가능하게 함을 입증하였다.
- FDRL은 표정 특징이 각 표정 범주의 공유 및 특정 정보로 구성된다고 보고, 표정 특징을 잠재 특징(latent feature)과 재구성(reconstruction)으로 분해하여 정보를 획득하는 방법을 제안하였다.
- 본 연구와의 연관성: RMFER의 inter-sample attention learning과 attention-based contrastive learning은 명시적인 감독 없이도 클래스 간 분리를 명확하게 하고 클래스 내 응집력을 강화하여, 위에서 언급된 Center loss 및 그 변형들과 유사하게 특징 학습의 목표를 달성한다.
2.2. Contrastive Learning
-
핵심 개념: 대조 학습은 데이터 증강(augmentation)을 통해 원본 이미지와 증강된 이미지 쌍을 긍정 쌍(positive pair)으로, 다른 이미지들을 부정 쌍(negative pair)으로 간주하여 모델이 의미 있는 표현(representation)을 학습하도록 유도한다. 즉, 긍정 쌍은 가깝게, 부정 쌍은 멀게 매핑되도록 학습한다.
-
주요 대조 학습 방법론:
- SimCLR [Chen et al., 2020]:
- 데이터 증강(augmentation)이 의미론적 정보(semantic information)를 변경하지 않는다는 전제하에 작동한다.
- 하나의 앵커(anchor) 이미지에 여러 증강을 적용하여 긍정 샘플(positive samples)을 만들고, 다른 이미지들을 부정 샘플(negative samples)로 사용한다.
- 앵커와 긍정/부정 샘플의 임베딩(embedding)은 프로젝션 헤드(projection head)를 거쳐 NT-Xent Loss [Sohn, 2016]를 사용하여 대조 학습을 수행한다.
- MoCo [He et al., 2020] (Momentum Contrast):
- 대조 학습을 동적 사전(dynamic dictionary) 구축 관점에서 접근한다.
- 사전은 "대규모(large scale)"와 "일관성(consistency)"이라는 두 가지 특성을 가져야 한다고 제안한다.
- 큐(queue)를 사용하여 특징의 키 값만 저장함으로써 대규모 사전을 구축하고, 모멘텀 업데이트(momentum update)를 통해 느리게 진행되는 인코더를 사용하여 일관성을 확보한다.
- BYOL [Grill et al., 2020] (Bootstrap Your Own Latent):
- 부정 쌍(negative pairs) 없이 대조 학습을 수행하는 방법을 제안한다.
- "온라인 네트워크(online network)"와 "타겟 네트워크(target network)"라는 두 개의 네트워크를 사용하며, 온라인 네트워크가 동일 이미지의 다른 증강본에 대한 타겟 네트워크의 표현을 예측하도록 학습한다.
- 이를 통해 collapse 문제(모든 입력에 대해 동일한 출력을 내는 문제)를 피하면서 부정 쌍 없이 대조 학습이 가능함을 보여주었다.
- Simsiam [Chen and He, 2021] (Simple Siamese):
- BYOL에서 momentum update보다 "stop gradient"가 collapse 문제를 피하는 데 더 결정적임을 밝혀냈다.
- 긍정 쌍만을 사용하여 대조 학습을 성공적으로 수행한다.
- 비디오 표현 학습으로의 확장 Lee et al., 2020, Lee et al., 2018]: 대조 학습이 정지 이미지뿐만 아니라 비디오 데이터의 표현 학습에도 효과적으로 확장될 수 있음을 보여준다.
- SimCLR [Chen et al., 2020]:
3. Reaction Mashup Dataset (RMset)
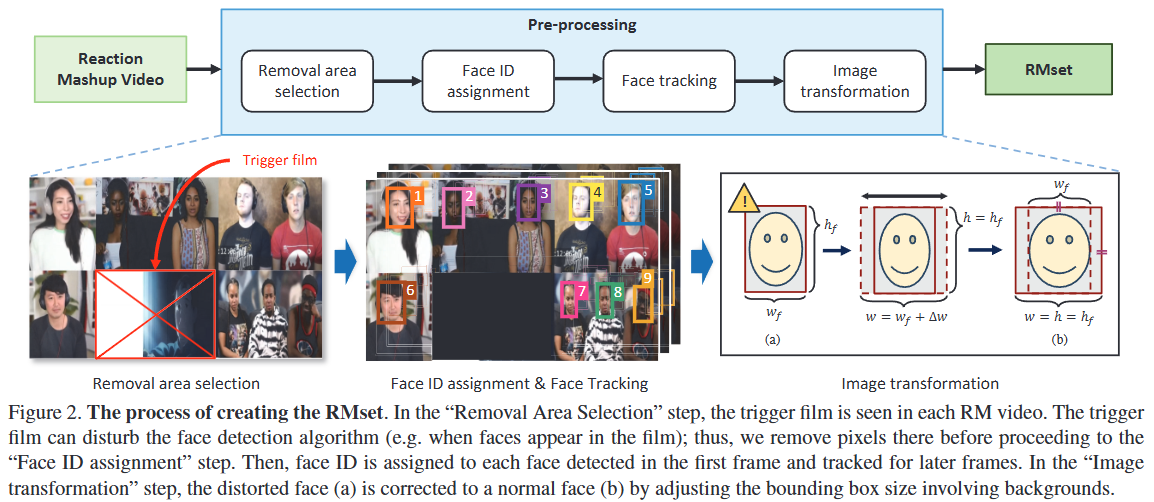
-
RMset의 정의 및 목적:
- Reaction Mashup (RM) 비디오 활용: RMset은 여러 사람이 동일한 영상(trigger film)을 시청하며 각기 다른 화면 분할에서 동시에 반응하는 모습을 담은 RM 비디오로부터 생성된 데이터셋이다.
- 비Labled 데이터셋 구축: 기존 FER 데이터셋은 어노테이션(레이블링)의 주관성 및 표정의 미묘함 때문에 데이터 수집에 어려움이 있었다. RMset은 이러한 한계를 극복하기 위해 대규모의 비Labled (unlabeled) 데이터를 제공하여 semi-supervised contrastive learning에 활용하는 것을 목표로 한다.
- 표정 유사성에 대한 가정: RMset은 특정 비디오를 시청할 때, 가까운 시간대의 다른 인물들의 표정은 유사할 가능성이 높고 (positive), 같은 인물이라도 시간적으로 멀리 떨어진 시점의 표정은 다를 가능성이 높다 (negative)는 핵심 가정을 기반으로 한다. 이러한 가설은 대조 학습(contrastive learning)에서 긍정/부정 샘플을 구성하는 데 사용된다.
-
RMset 생성 방법론:
- 비디오 수집: YouTube에서 "sad reaction mashup", "try not to laugh"와 같은 특정 키워드를 사용하여 RM 비디오를 수집했다. 이미지 노이즈를 줄이기 위해 1080p 이상의 고해상도 비디오만 선택했다. 총 216개의 비디오에서 약 314만 프레임, 3,485명의 인물, 4,567만 개의 얼굴 이미지를 확보했다.
- 전처리 4단계:
- 1단계: 제거 영역 선택 (Removal Area Selection): RM 비디오에 포함된 원본 trigger film이 얼굴 감지 알고리즘을 방해할 수 있으므로, 이 영역의 픽셀을 수동으로 식별하여 제거한다.
- 2단계: 얼굴 ID 할당 (Face ID Assignment): 첫 프레임에서 사전 학습된 얼굴 감지기 [10]로 얼굴을 감지하고, 감지되지 않은 얼굴은 수동으로 경계 상자를 표시한다. 이후 감지된 모든 얼굴에 순서대로 ID를 할당한다.
- 3단계: 얼굴 추적 (Face Tracking): 이후 프레임의 얼굴은 첫 프레임의 얼굴을 기준으로 추적된다. 현재 프레임에서 감지된 경계 상자와 첫 프레임의 경계 상자 간의 IOU(Intersection Over Union) 점수를 비교하여 얼굴 ID를 할당한다. (얼굴 감지기가 놓치거나 새로운 인물이 중간에 나타나는 드문 경우는 무시한다.)
- 4단계: 이미지 변환 (Image Transformation): RM 비디오의 얼굴 이미지 패치들은 폭/높이 비율이 다를 수 있어 FER 성능 저하를 야기할 수 있다. 따라서 얼굴 영역의 높이()를 기준으로 폭()을 만큼 조절하여 로 만들고, 이를 통해 비율이 약 1.31이 되도록 조정한다. 이는 AffectNet 데이터셋과 유사한 비율로, 표준화된 얼굴 이미지를 얻기 위함이다. 마지막으로 이미지 픽셀 값을 정규화한다.
4. The proposed method: RMFER
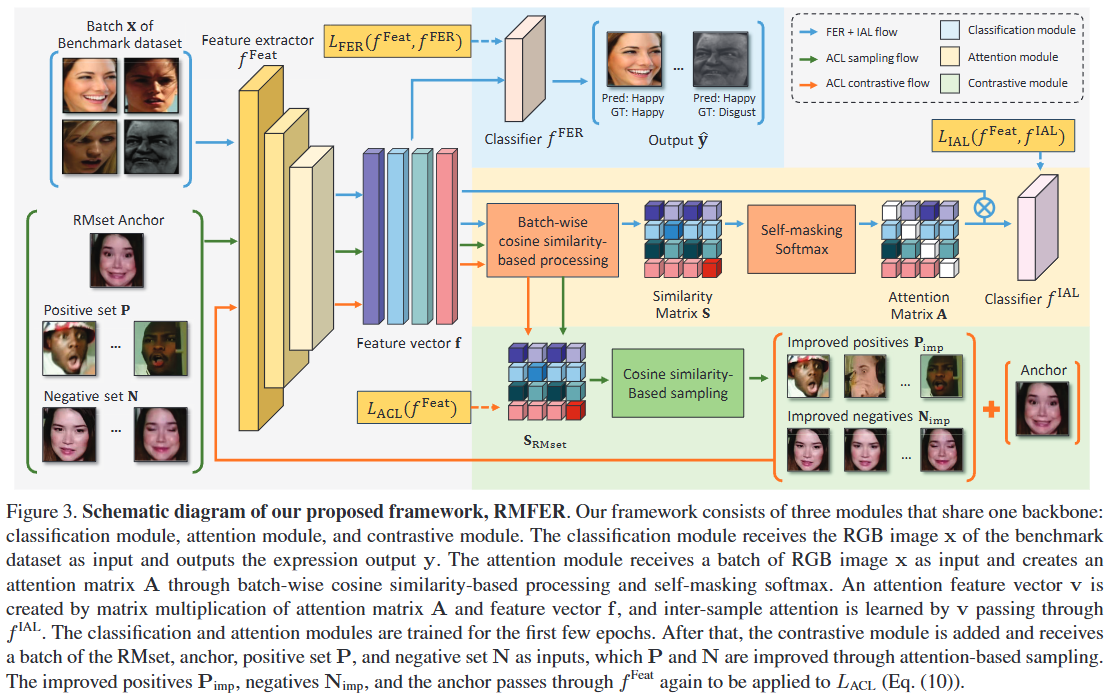
-
RMFER의 목표: FER은 RGB 이미지 를 해당 얼굴 표정 로 분류하는 태스크이다.
- 입력 이미지 는 형태의 RGB 이미지이다. 이는 가로, 세로 260픽셀의 3채널(RGB) 이미지를 의미한다.
- 출력 는 형태의 얼굴 표정 벡터이다. 여기서 는 미리 정의된 표정 카테고리(예: 중립, 행복, 슬픔 등)의 개수를 나타낸다.
-
핵심 구성 요소: RMFER 프레임워크는 이미지에서 특징 벡터를 추출하는 Feature extractor 와 추출된 특징을 기반으로 표정을 분류하는 Classification network 로 구성된다.
- Feature extractor (): 입력 이미지 를 차원의 특징 벡터 로 변환한다. 여기서 은 특징 차원의 수이다.
- Classification network (): 특징 벡터 를 최종 표정 출력 로 매핑한다. 즉, 전체 분류 네트워크는 로 표현된다.
-
세 가지 모듈: RMFER은 세 가지 개별 모듈을 통합하여 학습을 수행한다.
- Classification module: 지도 학습(supervised learning) 방식으로 얼굴 표정을 분류하는 역할을 한다. 이는 벤치마크 데이터셋의 레이블 정보를 사용하여 와 를 훈련시킨다.
- Attention module: 배치(batch) 내 샘플들 간의 유사성(inter-sample similarity)을 학습한다. 이 모듈은 특징 벡터 간의 코사인 유사도를 기반으로 어텐션 행렬을 생성하고, 이를 통해 샘플 간의 표현 유사도를 측정한다. (자세한 내용은 Inter-sample Attention Learning (IAL) 섹션에서 다룸)
- Contrastive module: RMset이라는 레이블 없는 데이터셋을 활용하여 특징 학습을 강화한다. 이 모듈은 어텐션 기반으로 개선된 긍정(positive) 및 부정(negative) 샘플 쌍을 구성하고, 콘트라스티브 학습을 통해 특징 공간을 풍부하게 만든다.
-
학습 과정: RMFER의 학습은 두 단계로 나뉜다.
- 초기 몇 Epoch: 첫 번째 단계에서는 벤치마크 데이터셋 를 사용하여 Classification module과 Attention module을 훈련한다. 이 단계에서 는 분류에 적합한 표정 특징 와 샘플 간 유사도를 학습한다.
- 이후 단계: 초기 학습 후, Contrastive module을 추가하여 학습 프로세스를 강화한다. 이 모듈은 RMset 을 활용하여 의 특징 공간 를 더욱 풍부하게 만든다.
-
데이터셋 활용: RMFER은 두 가지 종류의 데이터셋을 사용한다.
- 벤치마크 데이터셋 (): 레이블이 있는 데이터셋으로, Classification module과 Attention module의 지도 학습에 사용된다.
- RMset (): 본 논문에서 수집한 레이블 없는 Reaction Mashup 비디오 데이터셋으로, Contrastive module의 준지도 학습에 사용된다. 일반적으로 RMset의 샘플 수()는 벤치마크 데이터셋의 샘플 수()보다 훨씬 많다().
4.1. Inter-sample Attention Learning (IAL)
Inter-sample Attention Learning (IAL)은 RMFER 프레임워크의 세 가지 핵심 모듈 중 하나로, 초기 학습 단계에서 피처 추출기 가 입력 이미지와 표정 레이블 간의 매핑을 학습하는 동시에, 배치 내 샘플들 간의 쌍별(pairwise) 유사도를 학습하도록 돕는 과정이다.
-
목표:
- 입력 이미지 를 해당 표정 레이블 로 매핑하는 방법을 학습한다.
- 동시에, 배치 내 샘플들의 피처 벡터 간의 유사성 ()을 학습한다. 즉, 어떤 샘플들이 서로 유사한 표정을 가지고 있는지를 어텐션 메커니즘을 통해 파악한다.
-
학습 데이터: 이 단계에서는 레이블이 있는 벤치마크 데이터셋 만을 활용한다. 여기서 은 벤치마크 데이터셋의 샘플 수이다.
-
Batch-wise Cosine Similarity-based Processing:
- 피처 변환 ():
- 먼저, 입력 이미지 는 피처 추출 네트워크 를 거쳐 피처 벡터 로 변환된다.
- 이후 는 프로젝션 헤드 를 통과하여 라는 변환된 피처 벡터가 된다. 이는 SimCLR와 같이 원본 피처를 다른 차원의 공간으로 투영하여 유사성 학습에 더 적합하도록 만드는 과정이다.
- 코사인 유사도 행렬 () 생성:
- 동일한 배치(개 샘플) 내의 모든 벡터들에 대해 쌍별 코사인 유사도를 계산하여 크기의 유사도 행렬 를 만든다.
- Self-masking: 이 과정에서 의 대각 요소 (, 즉 자기 자신과의 유사도)는 과 같은 매우 작은 값으로 설정된다. 이는 모델이 자기 자신의 피처(self-attention)가 아닌 다른 샘플들의 피처(inter-sample attention)에 더 집중하도록 강제하는 목적을 가진다.
- 수식 (1):
- 수식 (1):
- 어텐션 행렬 () 생성:
- 행렬의 각 행에 스케일 값 로 나눈 후 소프트맥스(softmax) 함수를 적용하여 어텐션 행렬 를 생성한다.
- 는 번째 샘플이 번째 샘플에 할당하는 어텐션 가중치를 의미하며, 배치 내 다른 모든 샘플에 대한 상대적 유사성을 나타낸다.
- 수식 (2):
- 수식 (2):
- 어텐션 피처 벡터 () 생성:
- 번째 샘플의 어텐션 피처 벡터 는 번째 샘플과 번째 샘플 간의 어텐션 가중치 와 번째 샘플의 원본 피처 벡터 를 가중 합산하여 얻는다.
- 이는 번째 샘플의 피처 표현에 배치 내 다른 모든 샘플들의 정보를 (어텐션 가중치에 따라) 통합하는 과정이다.
- 수식 (3):
- 수식 (3):
- IAL 분류기 (): 생성된 어텐션 피처 벡터 는 이라는 완전 연결 계층(fully connected layer)을 통해 최종적으로 표정 레이블 로 매핑된다. 은 와 동일한 아키텍처를 갖는다.
- 피처 변환 ():
-
학습 원리:
- 번째 샘플과 번째 샘플이 유사하다고 가정하면 (예: 동일한 표정 레이블을 가지는 경우), 값은 높게 학습되고 번째 샘플의 피처 는 를 표현하는 데 더 큰 영향을 미치게 된다.
- 반대로, 번째 샘플과 번째 샘플이 유사하지 않다면, 값은 낮게 학습된다.
- 이러한 방식으로 모델은 명시적인 지도 학습 없이도 샘플들 간의 내재된 표정 유사성을 어텐션 메커니즘을 통해 학습한다.
-
손실 함수 (): IAL의 전체 손실은 다음과 같이 구성된다.
- 수식 (4):
- : 분류기의 예측과 정답 레이블 간의 교차 엔트로피(cross-entropy) 손실이다. 이는 기본적인 표정 분류 성능을 확보하는 역할을 한다.
- 수식 (5):
- 수식 (5):
- : 분류기의 예측()과 정답 레이블 간의 교차 엔트로피 손실이다. 이는 어텐션 피처 가 표정 정보를 잘 담도록 학습시킨다.
- 수식 (6):
- 수식 (6):
- : 와 간의 균형을 맞추는 하이퍼파라미터이다.
- : 분류기의 예측과 정답 레이블 간의 교차 엔트로피(cross-entropy) 손실이다. 이는 기본적인 표정 분류 성능을 확보하는 역할을 한다.
- 수식 (4):
이 과정을 통해 는 단순한 분류뿐만 아니라, 샘플 간의 표정 유사성을 인지하고 이를 피처 공간에 반영하는 능력을 초기 단계부터 학습하게 된다.
4.2. Attention-based contrastive learning (ACL)
-
ACL의 목표:
- 네트워크가 RMset에 내재된 잠재적인 표현 유사성을 학습하여 특징 분포를 개선하는 것이 목표이다.
- 이를 위해 기존 콘트라스티브 학습(contrastive learning) 프레임워크를 RMset의 특성에 맞게 확장하여 활용한다.
-
RMset에 내재된 사전 지식(Priors inherent in the RMset):
- RMset은 여러 사람이 같은 영상을 시청하는 반응 영상(reaction mashup video)으로 구성되어 있다. 이 영상에는 다음과 같은 사전 가정이 존재한다.
- 동일 프레임, 다른 인물: 같은 영상을 시청하는 여러 사람의 얼굴은 유사한 표정을 가질 가능성이 높다. 즉, 시점의 번째 인물 얼굴 와 시점의 다른 인물 얼굴 ()은 유사한 표정을 보일 수 있다.
- 동일 인물, 다른 프레임: 같은 인물의 얼굴이라도 시간상으로 멀리 떨어진 프레임에서는 다른 표정을 가질 가능성이 높다. 즉, 번째 인물의 시점 얼굴 와 번째 인물의 시점 얼굴 (가 로부터 멀리 떨어져 있을 때)은 다른 표정을 보일 수 있다.
- RMset은 여러 사람이 같은 영상을 시청하는 반응 영상(reaction mashup video)으로 구성되어 있다. 이 영상에는 다음과 같은 사전 가정이 존재한다.
-
긍정/부정 샘플 세트 구성:
- 위의 사전 지식을 바탕으로 특정 얼굴(, 앵커)에 대한 긍정(Positive) 및 부정(Negative) 세트의 초기 후보를 구성한다.
- 앵커 (Anchor): 번째 인물의 번째 프레임 얼굴 .
- 긍정 세트 (P): 앵커와 같은 프레임() 또는 주변 프레임(부터 까지)에 있는 다른 인물()의 얼굴들이다.
- 여기서 는 영상 내 전체 인물 수, 는 주변 프레임을 정의하는 하이퍼파라미터이다.
- 부정 세트 (N): 앵커와 같은 인물()이지만 멀리 떨어진 프레임( 또는 에 있는)의 얼굴들이다.
- 여기서 은 멀리 떨어진 프레임을 정의하는 하이퍼파라미터이다.
- 위의 사전 지식을 바탕으로 특정 얼굴(, 앵커)에 대한 긍정(Positive) 및 부정(Negative) 세트의 초기 후보를 구성한다.
-
어텐션을 활용한 긍정/부정 세트 개선 (Improving Positive/Negative Sets using Attention):
- 단순히 프레임이나 인물의 근접성만으로 긍정/부정 세트를 구성하는 것은 완벽하지 않다. 예를 들어, 같은 프레임에 있어도 표정이 다를 수 있고, 멀리 떨어진 프레임에 있어도 표정이 비슷할 수 있다.
- 이러한 한계를 극복하기 위해, 이전에 IAL(Inter-sample Attention Learning) 모듈에서 학습된 표정 유사성 측정 능력을 활용한다.
- IAL은 유사한 표정 간에는 높은 어텐션을, dissimilar한 표정 간에는 낮은 어텐션을 학습하도록 를 훈련시켰다. 따라서, IAL 학습을 거친 에서 추출된 특징 벡터 간의 코사인 유사도는 표정 유사성을 잘 반영하게 된다.
- 개선된 긍정 세트(): 초기 긍정 세트 내의 샘플들 중 앵커와 코사인 유사도가 높은 상위 비율의 샘플들을 선택한다.
- 개선된 부정 세트(): 초기 부정 세트 내의 샘플들 중 앵커와 코사인 유사도가 낮은 하위 비율의 샘플들을 선택한다.
- 이 논문에서는 값을 0.1로 설정하였다.
-
ACL 손실 함수 (Loss):
- 최종 손실 은 사전 학습 손실 와 ACL 손실 의 합으로 구성된다.
- 여기서 는 두 손실 항의 균형을 맞추는 하이퍼파라미터이다.
- 를 함께 사용하는 이유는 이미 레이블이 있는 데이터로 학습된 정보를 잊지 않기 위함이다(prevent forgetting).
- ACL 손실 은 다수의 긍정 및 부정 샘플을 처리할 수 있도록 NT-Xent loss [43]를 확장한 형태로 정의된다.
- : 스케일 값(온도 파라미터)으로, 식 (2)의 와 동일하다. 유사도 분포의 민감도를 조절한다.
- : 앵커와 개선된 긍정 샘플 사이의 코사인 유사도이다.
- : 앵커와 개선된 부정 샘플 사이의 코사인 유사도이다.
- 이 손실 함수는 앵커와 개선된 긍정 샘플들 간의 유사도를 높이고, 앵커와 개선된 부정 샘플들 간의 유사도를 낮추어 특징 공간에서 클래스 간의 분리도(inter-class separation)와 클래스 내 응집도(intra-class similarity)를 학습한다. 즉, 앵커를 긍정 샘플에 가깝게 당기고 부정 샘플에서 멀리 밀어내는 방식으로 를 훈련시킨다.
- 최종 손실 은 사전 학습 손실 와 ACL 손실 의 합으로 구성된다.
-
Test:
- 이후 테스트 때는 과 만을 사용하여 분류를 진행한다.
- 이나 은 가 더 강력한 판별적 특징을 학습하도록 유도하는 도구일 뿐이다.
5. Experiment
5.1. Experimental Settings
-
평가 데이터셋 (Datasets)
- AffectNet [33]:
- 가장 큰 표정 데이터베이스 중 하나이며, 8가지 범주형 기본 감정(7가지 기본 감정 + 경멸(contempt))을 제공한다.
- 약 28만 장의 이미지가 수동으로 어노테이션되어 학습 세트로 사용되며, 각 감정당 500장씩 총 4천 장의 이미지가 검증 세트(validation set)로 사용된다. 테스트 세트는 공개되지 않아 검증 세트를 평가에 활용한다.
- 검증 세트는 각 레이블의 샘플 수가 균형을 이루고 있어 평균 정확도(average accuracy)를 측정할 필요가 없다고 명시한다.
- 일부 연구에서는 '경멸' 표현을 제외한 7가지 감정만 사용하기도 하여, 이 논문에서도 두 가지 경우(7 emotion, 8 emotion) 모두에 대해 평가를 수행한다.
- RAF-DB [26]:
- 총 29,672장의 이미지로 구성되며, 크라우드소싱(crowdsourcing) 방식으로 어노테이션되었다.
- 놀람(surprised), 두려움(fearful), 혐오(disgusted), 행복(happy), 슬픔(sad), 분노(angry), 중립(neutral)의 7가지 기본 감정을 제공한다.
- 15,339장의 기본 감정 이미지는 12,271장의 학습 세트와 3,068장의 테스트 세트로 나뉜다.
- FERPlus [1]:
- FER2013 [14] 데이터셋의 확장 버전으로, 10명의 새로운 어노테이터가 레이블에 투표하여 생성되었다.
- 48x48 해상도의 흑백 이미지로 구성되며, 8가지 감정 범주를 포함한다.
- 학습, 검증, 테스트 세트는 각각 28,389장, 3,553장, 3,546장의 이미지로 구성된다.
- 이러한 데이터셋들은 FER 연구에서 널리 사용되는 벤치마크이며, 모델의 일반화 능력과 다양한 실제 환경에서의 성능을 평가하는 데 중요한 역할을 한다.
- AffectNet [33]:
-
평가 지표 (Evaluation Metrics)
- 전체 정확도 (Overall Accuracy):
- 전체 테스트 세트에 대한 정확도를 나타내는 지표로, 클래스별 성능을 고려하지 않는다.
- 테스트 세트가 불균형한 경우, 이 지표는 표본 수가 가장 많은 클래스의 성능에 강하게 영향을 받아 모델의 실제 성능을 왜곡할 수 있다.
- 평균 정확도 (Average Accuracy):
- 각 클래스별 성능의 평균을 나타내는 지표이다. 혼동 행렬(confusion matrix)의 대각선 값(각 클래스의 정답률)들의 평균으로 계산된다.
- 테스트 세트가 불균형할 때, 각 클래스의 평균적인 성능을 더 잘 반영하므로 전체 정확도의 단점을 보완한다.
- RAF-DB와 FERPlus는 테스트 세트가 불균형하므로 평균 정확도를 추가로 보고하며, AffectNet의 검증 세트는 균형 잡혀 있어 해당 지표가 필요하지 않다고 언급한다.
- 이 두 가지 지표를 함께 사용함으로써, 모델이 전체적으로 얼마나 잘 작동하는지(Overall Accuracy)와 더불어 특정 소수 클래스에서도 균형 잡힌 성능을 보이는지(Average Accuracy)를 종합적으로 평가할 수 있다.
- 전체 정확도 (Overall Accuracy):
5.2. Results and Discussion
-
평가 데이터셋 및 지표:
- 데이터셋: AffectNet, RAF-DB, FERPlus의 세 가지 주요 표정 인식(FER) 벤치마크 데이터셋을 사용하여 모델을 평가한다.
- 평가 지표:
- Overall Accuracy (전체 정확도): 전체 테스트 세트에서 올바르게 분류된 샘플의 비율이다. 테스트 세트가 불균형할 경우 특정 클래스의 성능을 제대로 반영하지 못할 수 있다는 한계가 있다.
- Average Accuracy (평균 정확도): 각 클래스별 정확도를 계산한 후 그 평균을 내는 지표이다. 클래스 불균형이 있는 데이터셋(예: RAF-DB, FERPlus)에서 각 클래스의 평균 성능을 공정하게 평가하는 데 유용하다. AffectNet의 검증 세트는 균형적이므로 평균 정확도를 별도로 측정할 필요가 없다고 언급한다.
-
정량적 비교 결과:
- 베이스라인 모델 (
Ours w/o ACL, IAL): 손실 함수만을 사용하여 학습한 기본적인 분류 네트워크이다. EfficientNet-b2와 유사한 설정이지만, 배치(batch) 내 레이블 불균형을 추가적으로 고려하여 약간 더 나은 성능을 달성했다고 설명한다. - Attention 모듈 추가 (
Ours w/o ACL): 손실(즉, + )을 사용하여 학습한 모델이다. 이 모델은 베이스라인보다 거의 모든 데이터셋에서 성능 향상을 보인다. 이는 IAL이 표정 분류 성능에 긍정적인 영향을 미친다는 것을 시사한다. - 전체 RMFER 프레임워크 (
Ours (full)): 모든 모듈(분류, Attention, 컨트라스티브)을 사용하여 학습한 최종 모델이다. FERPlus의 Overall Accuracy를 제외한 모든 지표에서 가장 우수한 성능을 달성한다. FERPlus의 Overall Accuracy가 낮은 것은 테스트 세트의 극심한 불균형 때문이라고 설명한다.
- 베이스라인 모델 (
-
준지도 학습(Semi-supervised Learning) 방법론과의 비교:
- RAF-DB 데이터셋에서 4,000개의 레이블된 이미지만을 사용하여 다른 SOTA 준지도 학습 방법론들(MixMatch, UDA, ReMixMatch, FixMatch, Ada-CM)과 비교한다.
- RMFER는 Ada-CM을 포함한 모든 비교 모델들을 명확하게 능가하며, 컨트라스티브 학습 내에 Attention Learning 메커니즘을 포함하는 것의 효과성을 입증한다.
-
정성적 결과 (Qualitative Results):
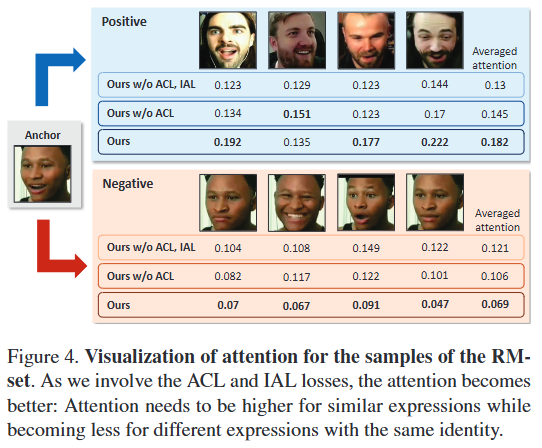
-
Attention 시각화 (Fig. 4): RMset 샘플에 대한 Attention 값을 시각화하여,
Ours모델에서 긍정(positive) 샘플에 대한 Attention이 가장 높고 부정(negative) 샘플에 대한 Attention이 가장 낮음을 보여준다. 이는 IAL이 동일한 신원(identity)을 가진 샘플이라 할지라도 표정 유사성에 따라 Attention을 다르게 학습하며, Attention-based Contrastive Learning(ACL)이 이러한 효과를 더욱 강화한다는 것을 의미한다. -
MDS 플롯 (Fig. 5): MDS(Multi-dimensional Scaling) 플롯을 사용하여 IAL과 ACL이 피처 학습(feature learning)에 미치는 영향을 시각적으로 분석한다.
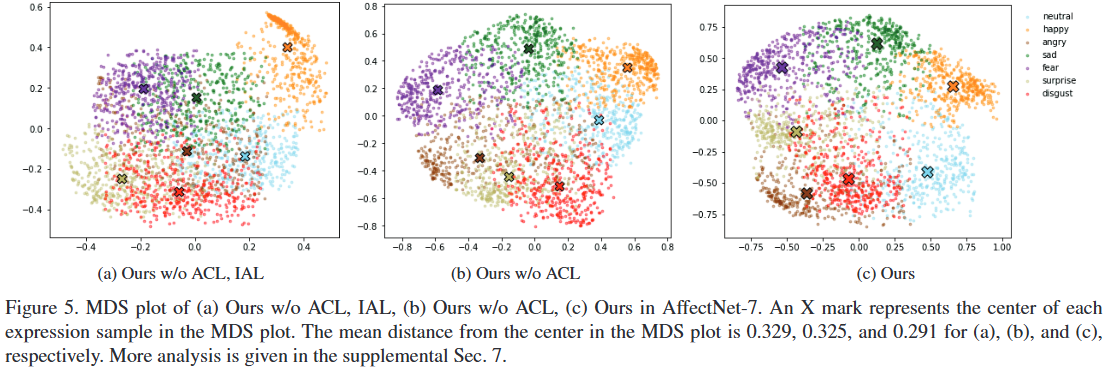
Ours w/o ACL, IAL에서는 각 클래스가 서로 혼합되어 명확한 경계가 없음을 보여준다.Ours w/o ACL에서는 Attention 학습을 통해 각 클래스별로 경계가 형성되기 시작함을 관찰할 수 있다.Ours (full)에서는 컨트라스티브 학습을 통해 각 클래스 클러스터가 더욱 응집되고 클래스 간 분리가 더욱 명확해지는 것을 보여준다. 각 클래스 중심으로부터의 평균 거리가 0.329 (a) 0.325 (b) 0.291 (c)로 점진적으로 감소하는 것이 이를 뒷받침한다.
-
5.3 Ablation Study
- Self-masking Softmax의 효과 검증:
- 목적: IAL(Inter-sample Attention Learning) 모듈에서 제안된 'self-masking softmax' 기법이 일반적인 softmax 함수에 비해 얼마나 효과적인지 평가하는 것이 목적이다. Self-masking softmax는 자기 자신과의 어텐션 값을 0에 가깝게 만들어 모델이 배치 내의 다른 샘플 간의 유사성에 집중하도록 강제한다 (4.1절의 (1)번 수식 참고).
- 결과: Table 3에서 'Ours w/o SM'과 'Ours w/o ACL, SM' 라인의 결과를 통해 self-masking softmax를 사용했을 때(‘Ours’ 및 ‘Ours w/o ACL’) 성능이 일관되게 향상됨을 보여준다. 이는 self-masking softmax가 inter-sample attention 학습에 긍정적인 영향을 미쳐 표현 분류 성능을 높이는 데 기여함을 시사한다.
- RMset 크기의 영향 분석:
- 목적: 제안된 RMset(Reaction Mashup dataset)의 양이 ACL(Attention-based Contrastive Learning)의 성능에 어떤 영향을 미치는지 검증하는 것이 목적이다.
- 결과: Table 4에서 RMset의 사용 비율을 0%, 50%, 100%로 늘려가며 성능을 측정했다. 결과는 RMset의 양이 많아질수록 AffectNet과 RAF-DB의 7가지 감정 및 8가지 감정 인식 성능이 일관되게 향상됨을 보여준다. 이는 RMset이 레이블 없는 데이터임에도 불구하고 모델의 특징 학습 능력(feature learning ability)을 효과적으로 강화함을 입증하며, 데이터셋 확장의 용이성이 추가적인 성능 향상으로 이어질 수 있음을 시사한다.
