1. Introduction
-
SfM의 전통적 방식과 딥러닝의 결합: 과거의 3D 재구성(Structure-from-Motion, SfM)은 주로 Bundle Adjustment(BA)와 같은 반복적인 최적화 기법에 의존했다. 최근에는 feature matching이나 monocular depth estimation에 머신러닝을 결합한 연구가 활발하다. 특히 VGGSfM은 BA를 미분 가능하게 하여 기계학습과 SfM 기술을 융합해 기존의 수학적 방법의 성능을 압도하였다.
-
신경망 직접 추론으로의 전환: 이 연구는 기존 연구들의 복잡한 기하학적 사후 처리를 거의 배제하고, Feed-forward만으로 3D 속성을 직접 추정한다. 기존의 DUSt3R이나 MASt3R은 두 장의 이미지만 처리할 수 있었고 여러 장을 합칠 때 Global Alignment라는 별도의 최적화가 필요했지만, VGGT는 수백 장의 이미지를 동시에 입력받아 1초 이내에 처리한다.
-
주요 기여 및 성과:
-
러닝 기반의 빠른 속도로 모든 3D 요소를 한 번에 예측: 수백장의 이미지를 입력받아 1초 이내의 Feed-forward만으로 카메라 파라미터, 깊이 지도(Depth map), 포인트 지도(Point map), 3D 포인트 트래킹 세 가지를 동시에 예측한다.
-
사후 최적화가 없는 최초의 모델: 사후 최적화 없이도 기존의 반복적 최적화(Iterative Optimization) 기반 방법들을 능가하는 성능을 보여준다.
-
범용적이고 단순한 아키텍처: VGGT는 특수한 3D Inductive Bias를 설계하는 대신, 표준적인 대규모 Transformer 구조를 채택했다. 이는 DINO나 CLIP과 같은 대형 모델들처럼 풍부한 3D 주석 데이터를 통해 학습됨으로써 범용적인 백본 역할을 수행할 수 있음을 보여준다.
-
다운스트림 태스크로의 확장 가능성: VGGT 내부의 피처를 활용하면, 동적 비디오의 비강체 포인트 트래킹이나 새로운 뷰 합성(Novel View Synthesis) 등 다양한 다운스트림 작업에서 강력한 성능 향상을 이끌어낸다.
-
2. Related Works
-
Structure from Motion (SfM)
-
SfM은 정적인 장면을 찍은 여러 장의 이미지로부터 카메라의 위치(Parameters)와 희소한 포인트 클라우드(Sparse Point Clouds)를 동시에 추정하는 고전적인 문제다.
-
전통적으로는 특징점 추출, 특징점 매칭, 삼각 측량(Triangulation), Bundle Adjustment(BA) 단계를 거치며, COLMAP이 가장 대표적인 프레임워크다.
-
최근에는 특징점 추출이나 매칭에 ALIKED와 같은 딥러닝 모델을 활용하며, VGGSfM과 같이 미분 가능한 BA를 결합해 전체 과정을 엔드투엔드로 학습하는 방식이 발전하고 있다.
-
VGGSfM: 위의 세 SfM 파이프라인을 딥러닝과 결합하여 미분 가능한 형태로 구현한 모델이다. 특히 기하학적 최적화인 Bundle Adjustment (BA)를 네트워크 내부에 포함시켜 높은 성능을 달성했다. 그러나 여전히 카메라의 위치와 3D 점들의 좌표를 조금씩 수정해가며 수백~수천 번 계산을 반복하는 Iterative Optimization 과정이 필수적이라 계산 복잡도가 높고 속도가 느리다는 단점이 있다.
-
VGGT의 차별성: VGGT는 이러한 반복적 최적화 없이 단 한 번의 Feed-forward 만으로 카메라 파라미터와 3D 구조를 즉시 예측하며, 0.2초 내외의 짧은 시간 안에 VGGSfM과 대등하거나 더 나은 성능을 보여준다.
-
-
Multi-view Stereo (MVS)
-
MVS는 주어진 카메라 파라미터를 이용하여, 여러 이미지로부터 정밀하고 조밀한 포인트 클라우드(Dense Point Clouds)를 복원하는 것이 목표다.
-
최근 DUSt3R나 MASt3R은 카메라 파라미터 없이도 두 이미지 사이의 조밀한 포인트 클라우드를 직접 추정하는 혁신적인 결과를 보여주었다.
-
DUSt3R: 두 장의 이미지 사이의 관계를 딥러닝으로 카메라 파라미터 없이도 3D 재구성을 가능하게 한 획기적인 모델이다. 하지만 한 번에 두 장의 이미지(Pairwise)만 처리할 수 있다는 구조적 한계가 있다. 이로 인해 수십~수백 장의 이미지를 재구성하려면 모든 이미지 쌍에 대해 계산한 후, Global Alignment라는 복잡하고 무거운 사후 최적화(Post-processing)를 거쳐야 한다.
-
MASt3R: DUSt3R의 후속작으로, 3D 포인트 맵 예측과 이미지 매칭 성능을 강화하여 보다 정밀한 대응점을 찾도록 설계되었다. 그러나 DUSt3R와 마찬가지로 이미지 쌍 기반의 로직을 사용하기 때문에, 입력 이미지 수가 늘어날수록 사후 처리 비용이 기하급수적으로 증가하며 연속적인 데이터 처리에 최적화되어 있지 않다.
-
VGGT의 차별성: VGGT도 카메라 파라미터 없이 3D 재구성을 수행하지만, 위 모델들과 달리 수백 장의 이미지를 한 번에 입력받으며, 사후 최적화 과정이 없는 한 번의 Feed-forward 연산으로 1초 내외의 시간만 소요된다.
-
3. Method
3.2. 문제 정의 및 수식 표현법
VGGT 모델의 입력과 출력 관계를 정의하는 핵심 함수를 소개한다. 하나의 피드포워드 신경망이 여러 장의 이미지로부터 다양한 3차원 속성을 동시에 추론함을 보여준다.
-
: 입력 이미지를 여러 3차원 정보로 매핑하는 VGGT Transformer 모델이다.
-
: 입력으로 들어오는 개의 RGB 이미지 시퀀스다. 여기서 는 각 프레임의 인덱스를 의미한다. 이 때, 각 이미지 프레임은 순차적인 시퀀스가 아니라 랜덤하게 섞여 임베딩 된다.
-
: 번째 이미지의 카메라 파라미터다. 카메라의 내부 파라미터(Intrinsics)와 외부 파라미터(Extrinsics)를 포함한다. 이 때, 첫 번째 프레임의 카메라 파라미터 을 월드 좌표계로 선정한다.
-
: 번째 이미지의 Depth Map이다. 각 픽셀 위치에서 카메라까지의 거리를 나타낸다.
-
: 번째 이미지의 Point Map이다. 각 픽셀에 대응하는 3차원 공간상의 좌표를 의미한다. 위에서 설명했듯, 해당 좌표는 카메라 파라미터 을 월드 좌표계로 선정한 공간에서 정의된다.
-
: 포인트 트래킹(Point Tracking)을 위한 특징 벡터다. 이 특징들은 나중에 별도의 모듈을 통해 비디오 전체에서 특정 지점의 위치를 추적하는 데 사용된다.
이 수식의 의미와 특징은 다음과 같다.
-
단일 네트워크 통합: 과거에는 카메라 경로 추정(SfM), 깊이 추정(Depth Estimation), 포인트 클라우드 구축 등을 별개의 모델로 수행했으나, VGGT는 이 모든 것을 하나의 함수 내에서 동시에 처리한다.
-
상호 보완적 학습: 사이에는 기하학적인 연관성이 존재한다. 논문에서는 이러한 중복될 수 있는 정보들을 모두 함께 예측하도록 학습시키는 것이 단일 작업만 수행하는 모델보다 더 높은 정확도를 보인다는 것을 입증했다.
카메라 파라미터
논문에서 카메라 파라미터 를 9개의 요소로 정의한 구체적인 구성 방식은 다음과 같다.
이 수식은 회전(), 이동(), 그리고 시야각()을 합쳐 총 9개의 숫자로 카메라의 상태를 표현한다. 각 항목을 자세히 설명하면 다음과 같다.
-
외부 파라미터 (Extrinsics) - 7개 요소
-
(4개): 카메라의 회전(Rotation)을 나타내는 쿼터니언(Quaternion)이다. 3차원 회전을 표현할 때 사용되는 행렬보다 구성 요소가 적어 효율적이고, 짐벌락 현상이 없이 안정적이어서 딥러닝 모델에서 자주 사용된다.
-
(3개): 카메라의 3차원 이동 벡터(Translation Vector)다. 세계 좌표계나 기준 카메라 좌표계로부터 해당 카메라가 얼마나 떨어져 있는지를 나타낸다.
-
특히 첫 번째 프레임()의 경우, 회전은 항등 쿼터니언(), 이동은 영 벡터()로 고정하여 기준 좌표계로 삼는다.
-
-
내부 파라미터 (Intrinsics) - 2개 요소
-
(2개): 카메라의 초점거리(Focal Length) 혹은 시야각(Field of View, FoV) 파라미터다. 이미지의 가로()와 세로() 방향에 대해 존재한다.
-
주의 사항: 이 모델은 VGGSfM의 방식을 따라 모든 입력 이미지를 동일한 해상도로 리사이징 한다. 이미지 플레인의 크기가 같아지니, 이미지 플레인 위에 있는 픽셀 플레인의 크기도 같아지고, 따라서 주점 좌표()를 별도로 예측할 필요가 없다. 따라서 내부 파라미터가 초점거리 2개로 압축되는 것이다. 해당 설명이 이해하기 어렵다면, 핀홀 카메라 모델에 대한 이론을 복습하자.
-
이렇게 하여 회전() + 이동() + 시야각()을 모두 더해 총 9개의 숫자가 된다. 이 방식은 전통적인 행렬 방식보다 파라미터 수가 적어 네트워크가 학습하기에 더 효율적이다.
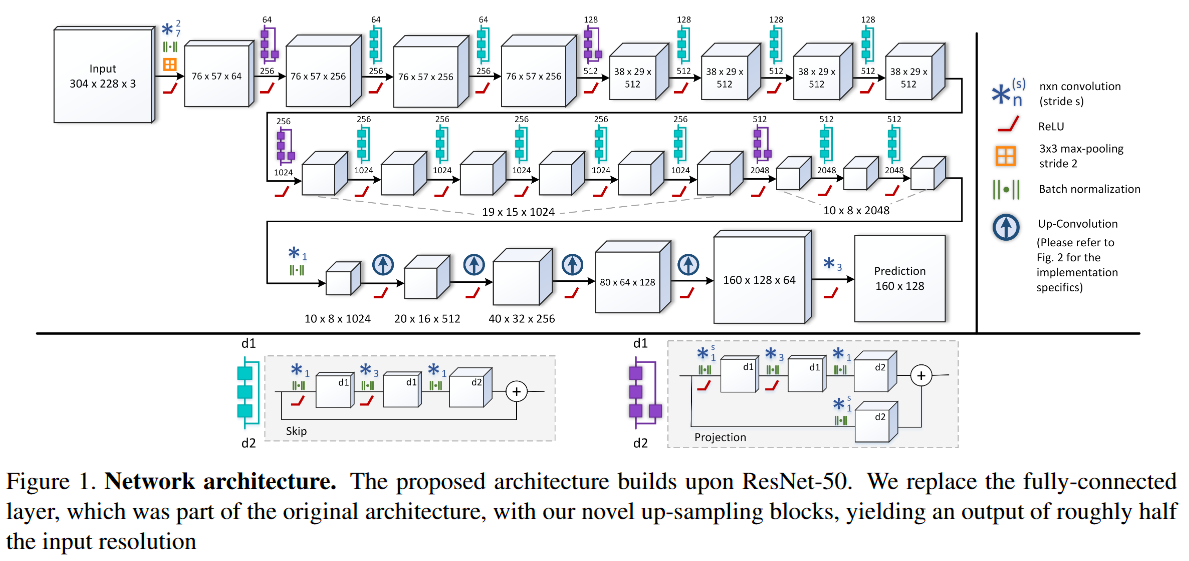
3.2. 백본 네트워크
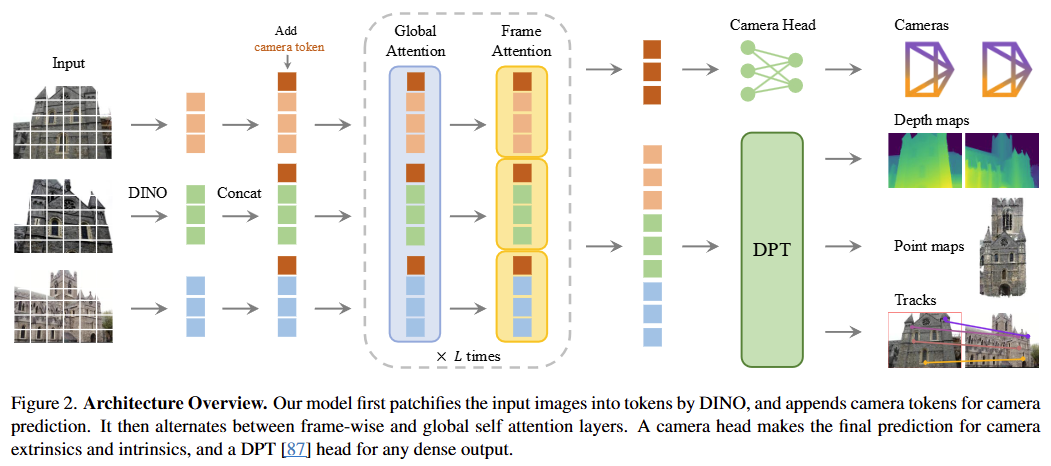
VGGT의 Feature Backbone은 복잡한 기하학적 유도 편향(3D Inductive Bias)을 최소화하고, 대규모 데이터를 통해 스스로 3D 구조를 학습하도록 설계된 트랜스포머 기반의 아키텍처다.
-
입력 데이터의 토큰화 (Patchifying)
입력 이미지 는 DINOv2 모델을 사용하여 개의 토큰 로 변환된다. 논문에서는 단순한 컨볼루션 레이어보다 DINOv2를 사용했을 때 학습 초기 단계에서 훨씬 안정적이고 높은 성능을 보였다고 밝히고 있다. 이는 DINOv2가 이미 수억 장의 이미지를 통해 시각적 특징을 추출하는 법을 완벽히 마스터한 상태이기 때문에, 모델에 의미있는 시각 정보를 효율적으로 전달하기 때문이다. -
특수 토큰의 활용
각 이미지 토큰 세트 에는 카메라 파라미터 예측을 위한 카메라 토큰 와 학습 안정화를 위한 4개의 레지스터 토큰 가 추가된다. 특히 첫 번째 프레임의 카메라 토큰은 다른 프레임과 구분되게 초기화되어, 모델이 첫 번째 이미지를 세계 좌표계의 기준으로 인식하게 만든다. -
기본 아키텍처 (Large Transformer)
-
VGGT는 Attention is all you need에서 제안된 표준적인 Transformer 구조를 기반으로 한다. 총 개의 층으로 구성된 거대한 신경망이며, 약 1.2B 개의 파라미터를 가진다.
-
VGGT가 복잡한 기하학적 수식이나 설계를 배제하고 Large Transformer라는 매우 단순한 구조를 채택한 이유는, 최근 인공지능 분야의 핵심 흐름인 데이터 중심의 학습(Data-driven Learning) 철학을 따르기 때문이다. 이를 이해하기 위해서는 먼저 유도 편향(Inductive Bias)의 정의를 명확히 할 필요가 있다.
-
유도 편향(Inductive Bias)이란 모델이 학습 과정에서 만나보지 않은 새로운 데이터에 대해 예측할 때 활용하는 기반 지식을 의미한다. 과거에는 Image Classificaiotn이 큰 난제였고, 이를 해결하기 위해 '사물이 이미지 내에서 자리를 바꿔도 그 존재는 같다.'라는 전제 하에 Sliding Window 기반의 CNN 필터가 발명되었다. 그러나 이러한 작은 필터로 국소적인 정보만을 보기 때문에 멀리 떨어진 픽셀간의 관계를 파악하는 전역적 이해도가 떨어진다는 것이 밝혀졌다.
-
이렇듯, 인간이 설계하고 주입한 전제조건적인 지식은 모델을 적은 데이터로 빠르게 학습시킬 수는 있으나, 성능에 제한을 건다. 그리고 이러한 제한은 복잡한 3D 컴퓨터 비전에서, 삼각측량(Triangulation)이나 에피폴라 기하학(Epipolar Geometry) 같은 물리적 법칙을 코드에 직접 녹여내는 것이 오히려 모델을 그 규칙 안에서만 움직이게 한다.
-
과거에는 3D 데이터를 구하기 어려워 이러한 물리 법칙을 유도 편향으로 가르쳐야 했지만, 이제는 수많은 3D 어노테이션 데이터가 존재한다. 모델에게 규칙을 강요하기보다, 엄청난 양의 데이터를 보고 스스로 물리 법칙을 깨닫게 하는 것이 더 강력한 성능을 낸다는 것이 Scaling Law로 증명된 것이다.
-
이 Scaling Law는 LLM 연구에서 밝혀진 것이지만, VGGT 또한 백본 네트워크가 Attention is All you Need에서 제안된 바닐라 트랜스포머를 기반으로 하고 있기 때문에 똑같이 적용된다.
-
따라서 저자들은 모델의 크기를 12억개의 파라미터로 키우고, 어노테이션 된 엄청난 양의 데이터를 부을수록 성능이 정직하게 올라간다는 Scaling Law를 믿고 실험을 진행한다. 그리고 이렇게 학습된 모델은 이미지 단 한 장에서도 3D 맵을 생성하며, 이는 기존의 삼각측량이나 에피폴라 기하학으로 formulation이 불가능한 영역이다.
-
-
교대 어텐션 (Alternating-Attention, AA)
이 모델의 핵심적인 설계 변경 사항이다. 표준 Transformer와 달리 다음의 두 가지 방식을 번갈아 가며 수행한다.- Global Self-attention: 모든 입력 프레임의 토큰들을 통합하여 어텐션을 수행한다. 이를 통해 서로 다른 뷰 사이의 시각적, 기하학적 관계를 파악하고 정보를 통합한다.
- Frame-wise Self-attention: 각 프레임 내부의 토큰들끼리만 어텐션을 수행하여 개별 이미지의 의미론적 특징들이 정교하게 업데이트 된다.
레지스터 토큰
레지스터 토큰은 Vision Transformers Need Registers (ICLR 2024)에서 처음 소개된 개념이다.
-
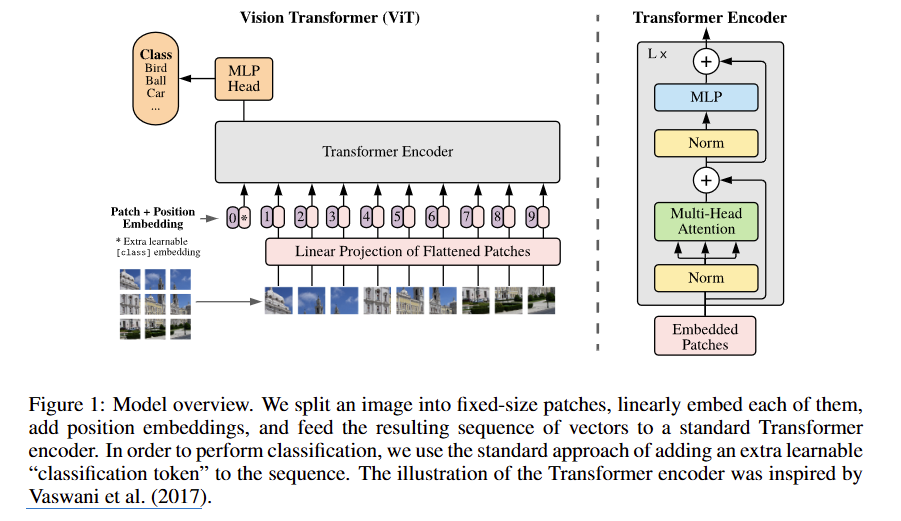
비전 트랜스포머
-
비전 트랜스포머는 이미지를 패치화한 뒤 아무런 정보를 담지 않은 [CLS] 토큰을 추가하여 임베딩한다. 그리고 학습이 완료된 뒤, 이 [CLS] 토큰만을 떼서 해당 이미지가 어떤 클래스인지 분류하는 작업을 한다.
-
모델은 [CLS] 토큰의 출력값만 보고 정답을 맞히도록 학습되기 때문에, 여기에 해당 토큰에 이미지의 모든 정보를 압축하여 저장한다.
-
따라서 트랜스포머에서 어텐션 맵을 시각화할 때, [CLS] 토큰과 이미지의 각 패치(Patch) 토큰들 사이의 코사인 유사도(내적)을 사용하며, 밝게 활성화되는 부분은 의미론적 정보를 많이 가진다고 해석할 수 있다.
-
-
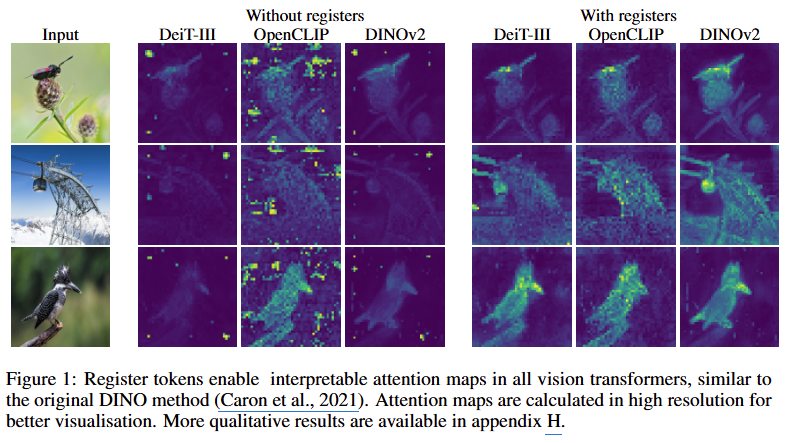
문제 제기: 시각적 아티팩트 발견
-
DINOv2, OpenCLIP, DeiT-III 등 최신 ViT 모델들의 Attention Map을 확인하면, 이미지의 배경 부분(정보량이 적은 곳)에서 비정상적으로 밝은 토큰들이 나타나는 현상이 발견되었다.
-
모델이 너무 커지고 복잡해지다 보니, [CLS] 토큰 하나만으로는 이 방대한 정보를 다 처리하거나 임시로 저장해둘 공간이 부족해진 것이다.
-
공간이 부족해진 모델은 [CLS]처럼 정보가 거의 없는 배경 패치를 점거해 사용하기 시작했고, 이들은 원래 위치의 공간 정보나 픽셀 정보를 모두 잃어버리고, 이미지 전체에 대한 글로벌 정보를 대신 담게 되었다.
-
이런 토큰들이 많아지면, 정작 어텐션을 취했을 때 Softmax에 의하여 중요한 부분의 정확도는 상대적으로 매우 낮아지게 되고, 이는 모델의 성능 저하로 이어진다.
-
-
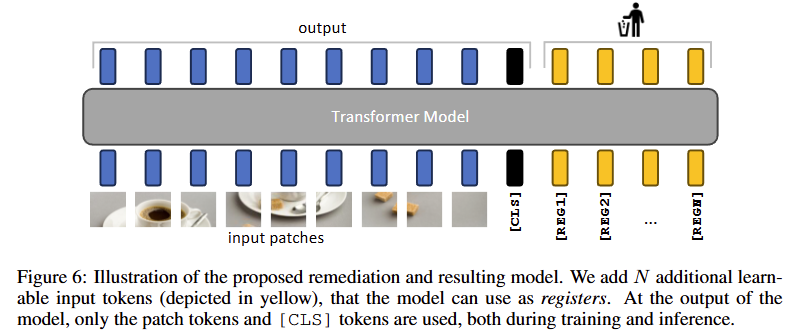
제안 방법: 레지스터 토큰 도입
-
모델이 배경 패치 토큰을 억지로 재활용하지 않도록, 학습 가능한 별도의 입력 토큰인 레지스터를 시퀀스에 추가하는 방안을 제시했다.
-
입력 패치와 독립적인 개의 레지스터 토큰을 추가하여 모델이 글로벌 정보를 저장하고 처리하는 저장소로 활용하게 한다.
-
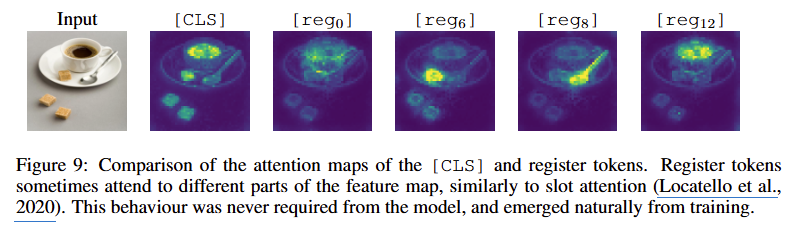
-
기대 효과 및 결과
-
레지스터 토큰에 의미론적 정보들이 나뉘어 저장되면서, 정보를 우겨넣어 생성된 시각적 아티팩트가 완전히 사라지고, Attention Map이 훨씬 매끄럽고 해석 가능해진다.
-
DINOv2모델에서 객체 발견(Object Discovery) 성능이 크게 향상되며, 하위 작업(Downstream Tasks)에서도 성능 저하 없이 더 나은 특징 추출이 가능하다.
-
3.3. 예측 헤드
-
입력 토큰의 구성과 처리
- 각 개의 카메라 토큰, 이미지 토큰, 레지스터 토큰이 concat 되어 의 형식으로 모델에 임베딩 된다.
- 이들이 Alternating-Attention(AA) Transformer를 통과하면, 각 속성의 예측에 최적화된 출력 토큰 이 생성된다.
-
카메라 예측 헤드 (Camera Head)
- 출력 카메라 토큰 를 입력으로 받아 4개의 Self-Attention 레이어와 Linear 레이어를 거쳐 카메라 파라미터 를 예측한다.
- 예측값에는 회전 쿼터니언 , 이동 벡터 , 시야각 가 포함되며, 첫 번째 프레임의 카메라는 항상 Identity(회전 없음, 이동 없음)로 설정되어 세계 좌표계의 기준이 된다.
-
DPT 헤드 (DPT Head)
-
이미지 토큰 은 는 DPT(Dense Prediction Transformer) 레이어를 통해 고해상도 특징 맵 과 트래킹 피처맵 를 생성하며, 이들은 각각 조밀한 예측 헤드와 포인트 트래킹 헤드에 입력된다.
-
조밀한 예측 헤드 (Dense Prediction Heads)
-
위에 Convolution 레이어를 적용하여 각 픽셀별로 깊이 와 포인트 맵 를 도출한다.
-
이때 모델은 자신의 예측에 대한 불확실성()도 함께 출력하여 학습 시 손실 함수의 가중치를 조절하는 데 사용한다.
-
-
포인트 트래킹 헤드 (Tracking Head)
-
는 CoTracker 아키텍처 기반의 트래킹 모듈로 전달된다.
-
특정 쿼리 지점 가 주어지면, 해당 지점의 특징을 추출하고 다른 프레임의 특징 맵과 상관관계(Correlation)를 계산하여 모든 이미지에서의 대응점 위치를 찾아낸다.
-
-
DPT
DPT는 Vision Transformers for Dense Prediction (ICCV 2021)에 제안된 네트워크로, ViT가 나온 해에 빠르게 이를 백본으로 한 인코더-디코더 모델이다. Dense Prediction(조밀한 예측)은 이미지의 특정 부분이나 전체적인 분류를 넘어, 이미지 내의 모든 픽셀에 대해 개별적인 예측값을 내놓는 태스크들을 통칭하며, 대표적으로 Monocular Depth Estimation이나 Semantic Segmentation 등이 있다.
- 기존 방식의 한계: 기존의 Dense Predictoin 모델들은 CNN을 기반으로 한다. CNN은 연산 효율을 위해 이미지를 점진적으로 다운샘플링하는데, 이 과정에서 이미지의 세밀한 특징(Granularity)이 손실된다. 이를 복구하기 위해 Dilated Convolution이나 Skip Connection 같은 기술을 쓰지만, 근본적으로 Convolution의 국소적인 Receptive Field(수용 영역) 제한을 완전히 극복하기 어렵다.
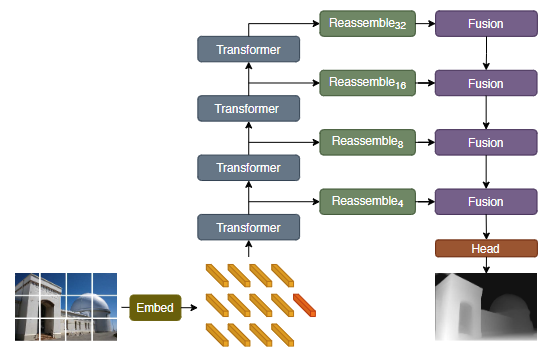
-
Vision Transformer(ViT)의 도입: DPT는 CNN 대신 ViT를 Encoder로 사용한다. ViT는 이미지 전체를 패치 단위의 토큰으로 처리하며, 모든 단계에서 Global Receptive Field(전역 수용 영역)를 유지한다. 또한, 초기 임베딩 이후에는 해상도를 낮추는 다운샘플링 과정 없이 일정한 차원의 표현을 유지한다.
-
Reassemble 및 Decoder 구성: Transformer가 내뱉는 토큰 형태의 출력을 다시 이미지와 유사한 형태의 특징 지도로 재구성(Reassemble)한다. 이후 여러 해상도의 특징들을 Convolutional Decoder를 통해 결합하여 최종 예측을 수행한다. Convolution은 인접한 픽셀 간의 관계를 처리하는 데 매우 효율적이므로, 픽셀 단위의 정밀한 경계를 나누거나 세부적인 형태를 다듬는 작업은 Transformer보다 CNN이 더 잘 수행한다. 또한 기존의 성공적인 디코더 구조들이 이미 Convolution 기반으로 잘 설계되어 있어, 이를 활용해 연산량을 줄이면서도 ViT가 뽑아낸 강력한 특징들을 효과적으로 융합할 수 있다.
-
DPT의 장점: 전역적인 정보를 활용하기 때문에 전체적인 일관성(Global Coherence)이 뛰어나며, 해상도 손실이 적어 매우 세밀한(Fine-grained) 예측이 가능하다.
-
실험 결과: 단안 깊이 추정(Monocular Depth Estimation)에서 기존 SOTA 대비 최대 28%의 성능 향상을 보였다.
3.4. 모델 훈련
오차함수
VGGT는 카메라 파라미터, 깊이 맵, 포인트 맵, 포인트 트래킹이라는 네 가지 서로 다른 정보를 동시에 학습하기 위해 여러 항의 합으로 구성된 멀티태스크 손실 함수(Multi-task Loss)를 사용한다. 전체 손실 함수는 다음과 같이 정의된다.
-
전체 손실 함수 구조 (): 카메라, 깊이 맵, 포인트 맵 손실은 범위가 비슷하여 별도의 가중치 없이 더한다. 반면 트래킹 손실()은 학습 안정성을 위해 라는 작은 가중치를 곱해 반영한다.
-
카메라 손실 ():
-
: 모델이 예측한 번째 프레임의 카메라 파라미터(회전, 평행이동, 시야각)다.
-
: 실제 정답(Ground Truth) 카메라 파라미터다.
-
: Huber Loss를 의미하며, 오차가 작을 때는 제곱 오차를, 클 때는 절대 오차를 적용한다. 해당 오차를 사용하는 이유는 다음과 같다.
-
데이터의 노이즈: VGGT 학습에 쓰인 데이터 중 MegaDepth 같은 인터넷 사진 기반 데이터는 SfM(COLMAP 등)으로 정답을 추출한 것인데, 이 과정에서 완전하게 틀린 카메라 포즈가 정답으로 포함될 수 있다.
-
의 위험성: 만약 를 쓰면, 이렇게 완전히 틀린 '가짜 정답' 하나 때문에 손실값이 기하급수적으로 커져서 모델 전체가 망가질 수 있다.
-
Huber의 역할: 오차가 작을 때는 처럼 정밀하게 학습하고, 오차가 너무 클 때는 처럼 선형적으로 처리하여 이상치(Outlier)의 영향을 억제한다. 즉, "가끔 나오는 엉터리 데이터는 적당히 무시하고 대세를 따르라"는 의도다.
-
-
-
깊이 손실 ():
-
가중치 적용 오차 (Weighted Pixel-wise Error)
-
수식 의미: 예측값()과 실제값()의 차이에 모델이 예측한 불확실성()을 곱한다.
-
예시: 모델은 예측값()과 실제값()의 차이를 줄이도록 학습한다. 그러면 오차 항이 작아진다. 그러나 유리창이나 아주 먼 배경처럼 깊이를 도저히 측정하기 어려운 영역이 있다고 가정하자. 이곳은 모델이 도저히 이를 맞출 수가 없어서 () 값을 낮추는 식으로 학습한다. 하지만, 이 때 패널티 항이 급격히 커지기 때문에, 모델은 '정말 맞추기 힘든 곳'이 아니면 불확실성을 함부로 낮추지 못한다. 결과적으로 이 영역에서 큰 오차가 발생하더라도 전체 손실 값에 미치는 영향이 줄어들어 학습이 불안정해지는 것을 막는다. 반대로 벽처럼 명확한 곳은 불확실성을 높게(1에 가깝게) 두어 오차를 엄격하게 잡는다.
-
-
경계선 변화율 오차 (Gradient-based Error)
- 수식 의미: 깊이 값 자체의 차이뿐만 아니라, 인접한 픽셀끼리의 변화량(, 미분값)이 실제와 같은지 비교한다. 여기에 똑같이 불확실성 가중치를 곱한다.
- 예시: 책상의 모서리 부분을 상상해 보자. 실제 깊이 지도()에서는 모서리를 경계로 깊이 값이 급격하게 변한다. 만약 모델이 이 경계선을 뭉뚱그려 완만하게 예측()한다면, 미분값()이 실제()와 크게 달라지므로 높은 손실이 발생한다. 이 항은 결과적으로 물체의 윤곽선이 뚜렷하고 날카로운 깊이 지도를 만들도록 돕는다.
-
불확실성 패널티 (Uncertainty Regularization)
- 수식 의미: 불확실성 값()이 너무 작아지지 않도록 제동을 거는 로그 항이다. (는 가중치 상수)
- 예시: 만약 이 항이 없다면, 모델은 모든 픽셀의 불확실성()을 그냥 0으로 만들어버릴 것이다. 그러면 어떤 오차가 발생해도 전체 손실이 0이 되어 학습이 아예 일어나지 않기 때문이다. 이 로그 항은 모델이 정말로 모르는 부분에서만 조심스럽게 불확실성을 낮추도록 강제하는 역할을 한다.
-
-
포인트 맵 손실 ():
깊이 손실과 동일한 구조를 가지며, 3D 공간상의 좌표인 포인트 맵()에 대해 계산된다. 불확실성 를 활용해 3D 복원 정확도를 높인다.
-
트래킹 손실 ():
- : 번째 쿼리 포인트가 번째 프레임에서 실제로 위치해야 할 2D 좌표다.
- : 모델이 예측한 대응점의 좌표다.
- 여기에 포인트가 화면에서 사라졌는지를 판별하는 가시성 손실(Visibility Loss)이 추가되어 동적인 장면 이해를 돕는다.
- VGGT의 트래킹 모듈은 CoTracker 구조를 따르는데, 해당 연구에서 오차 기반의 최적화가 대응점 매칭에 가장 효과적임이 이미 검증되었다.
데이터셋
VGGT 학습에 사용된 방대한 데이터셋은 크게 실세계 환경(Real-world), 합성 환경(Synthetic), 그리고 특정 객체 중심(Object-centric) 데이터로 분류할 수 있다. 모델이 다양한 조명, 구도, 기하학적 구조를 학습할 수 있도록 구성되었다.
1. 실세계 환경 데이터 (Real-world Scenes)
실제 카메라로 촬영된 영상이나 사진을 기반으로 하며, 주로 SfM(Structure-from-Motion)이나 센서를 통해 3D 주석을 얻은 데이터셋이다.
- 실외 및 도시 경관:
- MegaDepth: 전 세계 유명 랜드마크 사진을 활용해 대규모 깊이(Depth) 정보를 학습한다.
- Mapillary: 도로 및 거리 뷰 이미지로 구성되어 도시 환경의 기하학적 이해를 돕는다.
- 실내 환경:
- ScanNet: RGB-D 비디오로 촬영된 실내 공간 데이터로, 가구와 방의 구조를 학습한다.
- WildRGB: 실제 환경에서 촬영된 다양한 객체와 장면을 포함한다.
- 복합 및 기타:
- DL3DV: 최근 제안된 대규모 3D 비전 데이터셋으로 다양한 실세계 장면을 제공한다.
2. 합성 환경 데이터 (Synthetic Scenes)
시뮬레이션 엔진으로 생성되어 완벽하고 정밀한 3D Ground Truth(카메라 포즈, 깊이, 포인트 클라우드 등)를 제공하는 데이터셋이다.
- 실내 시뮬레이션:
- Hyper-Sim: 극사실적인 실내 합성 이미지로, 빛의 반사와 재질감을 학습한다.
- Replica / Habitat: 고품질 3D 스캔 기반의 가상 실내 환경으로, 로봇 내비게이션 및 재구성에 자주 쓰인다.
- Aria Synthetic Environments / Aria Digital Twin: 메타(Meta)에서 제공하는 웨어러블 장치 관점의 합성 및 디지털 트윈 데이터셋이다.
- 실외 및 주행 시뮬레이션:
- Virtual KITTI: 자율주행 시나리오를 위한 합성 비디오 데이터셋이다.
- MVS-Synth: 멀티뷰 스테레오(MVS) 학습을 위해 생성된 합성 데이터다.
- 포인트 트래킹 전용:
- Kubric: 물리 엔진을 활용해 객체의 움직임과 가려짐(Occlusion)을 정교하게 제어한 데이터다.
- PointOdyssey: 장기 포인트 트래킹(Long-term tracking) 학습을 위한 대규모 합성 데이터셋이다.
3. 객체 중심 데이터 (Object-centric Datasets)
특정 장면 전체보다는 개별 사물 하나하나의 형태와 구조를 집중적으로 학습하기 위한 데이터셋이다.
- Co3Dv2 (Common Objects in 3D): 일상적인 사물 카테고리에 대해 수천 개의 다각도 촬영 영상을 포함하여 사물의 3D 형태를 학습한다.
- BlendMVS: 다양한 3D 모델을 합성하여 멀티뷰 재구성을 위해 가공된 데이터다.
- Objaverse 스타일 합성 데이터: 예술가가 제작한 고품질 3D 자산(Assets)을 활용해 모델이 본 적 없는 복잡한 사물 형태에도 대응할 수 있게 한다.
4. 데이터셋 통합의 의의
- 일반화 능력: 실내/실외, 합성/실제 데이터를 모두 사용함으로써 모델이 특정 도메인에 치우치지 않는 범용적인 3D 재구성 능력을 갖추게 된다.
- 멀티태스크 학습: 포인트 트래킹(PointOdyssey)부터 카메라 포즈 추정(MegaDepth), 밀집 재구성(ScanNet)까지 각기 강점이 있는 데이터를 섞어 씀으로써 여러 3D 속성을 동시에 예측하는 능력을 극대화했다.
구현 디테일
데이터 정규화
-
3D 재구성의 모호성 해결: 3D 장면을 전체적으로 확대/축소(Scale)하거나 기준 좌표계(Global Reference Frame)를 바꾸더라도, 그 장면을 찍은 2D 이미지들은 변하지 않는다. 따라서 신경망이 하나의 정답을 일관되게 학습할 수 있도록 정규화된 기준(Canonical Choice)을 정해주는 과정이 필요하다.
-
첫 번째 카메라 기준 좌표계: 모든 3D 속성(카메라 파라미터, 포인트 맵 등)을 첫 번째 입력 이미지의 카메라 을 기준으로 변환한다. 즉, 첫 번째 카메라의 위치를 원점()으로 삼는다.
-
스케일 정규화(Scale Normalization): DUSt3R의 방식을 따라, 포인트 맵 에 있는 모든 3D 점들이 원점으로부터 떨어진 평균 유클리드 거리를 계산한다. 이 평균 거리를 기준으로 카메라의 평행 이동 벡터 , 포인트 맵 , 깊이 지도 를 나누어 전체 스케일을 통일한다.
실험 환경
-
개의 레이어를 사용하며, 각 레이어는 프레임별 어텐션(frame-wise attention)과 글로벌 어텐션(global attention)이 번갈아 나타나는 구조로 설계되었다.
-
이미지 토큰화를 위해 DINOv2 모델을 활용하며, 이는 학습 초기 단계의 안정성을 높여준다.
-
하드웨어: 64개의 NVIDIA A100 GPU를 사용하여 약 9일 동안 학습을 진행한다.
-
AWS나 Google Cloud 같은 클라우드 서비스에서 A100 80GB 모델의 시간당 대여 비용을 약 달러로 가정하면, 한 번 학습시키는 데 대략 달러(한화 약 만 원 이상)의 순수 컴퓨팅 비용이 발생한다.
4. Experiments
4.1. Camera Pose Estimation
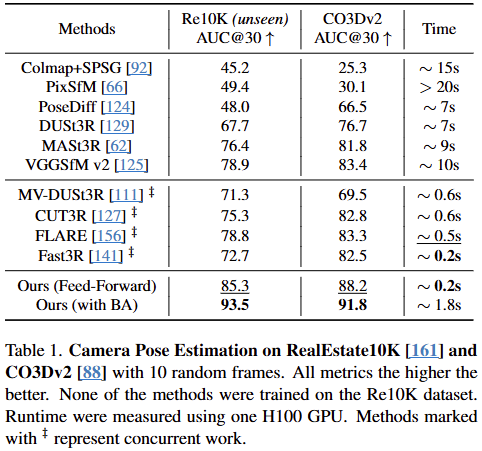
해당 표는 VGGT 모델이 기존의 최신 기술들과 비교했을 때 카메라 포즈 추정(Camera Pose Estimation) 작업에서 얼마나 뛰어난 성능과 속도를 보이는지 나타낸다.
-
비교 데이터셋 및 지표:
- RealEstate10K (Re10K): 학습에 사용되지 않은 미지의 데이터셋(unseen)으로, 모델의 일반화 능력을 평가한다.
- CO3Dv2: 일반적인 사물 중심의 데이터셋이다. 실험에서 비교 대상이 된 학습 가능 모델들은 CO3Dv2 데이터셋으로 학습되었고, RealEstate10K(Re10K) 데이터셋으로는 학습되지 않았다. 모델들의 일반화 성능을 비교하기 위해 일부러 서로 다른 도메인의 데이터셋을 비교한 것이다.
- AUC@30: 회전 오차와 평행 이동 오차를 종합하여 계산한 정확도 지표이며, 값이 높을수록 정밀도가 높음을 의미한다.
- Time: 10장의 이미지를 처리하는 데 걸리는 시간이다.
-
VGGT의 성능 우위:
- Ours (Feed-Forward): 후처리 최적화 없이 신경망 계산만으로도 Re10K에서 85.3, CO3Dv2에서 88.2라는 점수를 기록했다. 이는 최적화 과정을 포함한 기존의 강력한 모델들인 DUSt3R이나 MASt3R, VGGSfM v2보다 높은 수치다.
- 특히 Re10K 데이터셋에서 타 모델 대비 점수 차이가 크게 벌어지는 것을 통해 VGGT의 뛰어난 일반화 성능을 확인할 수 있다.
-
압도적인 처리 속도:
- 기존 모델들이 7초에서 20초 이상 소요되는 반면, VGGT는 단 0.2초 만에 결과를 도출한다. 이는 실시간 응용 가능성을 시사한다.
- 최근 등장한 고속 모델들(표 중간의 ‡ 표시)과 비교해도 가장 빠르거나 대등한 수준이면서 정확도는 훨씬 높다.
- 이들은 주로 DUSt3R가 가진 한계(두 장의 이미지만 처리 가능, 다수 이미지 처리 시 느린 최적화 필요)를 해결하기 위해 신경망 기반의 고속 재구성을 시도한 모델들이다.
-
Bundle Adjustment(BA) 결합 시 효과:
-
Ours (with BA): VGGT의 예측값을 초기값으로 하여 번들 조정(Bundle Adjustment) 최적화를 추가하면 정확도가 Re10K 기준 93.5까지 대폭 상승한다.
-
최적화를 포함하더라도 전체 소요 시간은 약 1.8초에 불과하여, 기존의 최적화 기반 방식들보다 훨씬 효율적이며, 그 이유는 다음과 같다.
-
삼각측량(Triangulation) 생략: 전통적인 SfM에서는 카메라 포즈를 먼저 구한 뒤, 여러 이미지에서 매칭된 점들을 쏘아 올려 3D 위치를 계산해야 한다. 하지만 VGGT는 네트워크가 직접 3D 포인트 맵을 예측하므로, 별도의 기하학적 삼각측량 계산 없이도 즉시 BA에 넣을 3D 좌표를 얻을 수 있다.
-
최적화된 BA 초기화: 기존 VGGSfM 같은 방식은 초기값이 부정확하여 BA 과정 중에 삼각측량과 포즈 수정을 수없이 반복하며 단계적으로 정밀도를 높여야 했다. 반면, VGGT는 처음부터 실제값에 매우 근접한 결과를 내놓기 때문에, 복잡한 최소한의 최적화만으로도 충분히 고품질의 재구성이 가능하다.
-
-
AUC@30 계산 방법
AUC@30은 오차 임계값을 0도에서 30도까지 설정하여 계산한 면적이다. 구체적인 계산 단계는 다음과 같다.
- 이미지 쌍별 오차 계산:
- 모든 이미지 쌍에 대해 회전 오차()와 평행 이동 오차()를 각도 단위()로 구한다.
- 임계값별 정확도 산출:
- 임계값 를 와 같이 일정 간격으로 설정한다.
- 각 에 대해 다음 조건을 만족하는 비율을 계산한다.
- 지표의 의미:
- 단순히 "5도 이내 오차"만 보면 6도 오차와 30도 오차를 구분하지 못한다.
- AUC는 아주 정밀한 범위(예: 1도 이내)부터 다소 관대한 범위(예: 30도 이내)까지의 전체적인 성능 분포를 한눈에 보여주기 때문에 카메라 포즈 추정 연구에서 표준적으로 사용된다.
4.2. Dense MVS Estimation
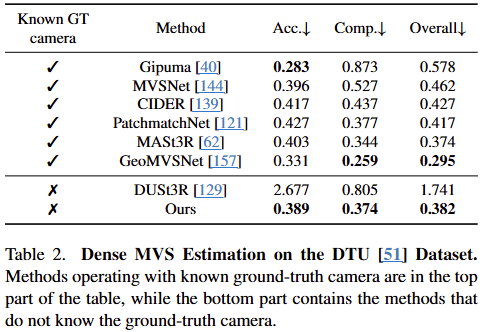
제시된 이미지는 VDTU 데이터셋에서 다양한 Multi-view Stereo(MVS) 방법들의 밀집 재구성 성능을 비교한 표다. 이 표는 카메라 파라미터 정보의 유무에 따른 성능 차이를 극명하게 보여준다.
-
DTU Dataset:
- DTU 데이터셋은 Multi-view Stereo (MVS) 알고리즘의 성능을 평가하기 위해 가장 널리 사용되는 표준 벤치마크 중 하나다.
- 구성: 정밀하게 제어된 실험실 환경에서 산업용 로봇 팔에 카메라를 부착하여 촬영한 데이터셋이다.
- Ground Truth: 구조광(Structured Light) 스캐너를 사용하여 매우 정밀한 3D 포인트 클라우드 데이터를 확보하고 있어, 알고리즘이 생성한 결과물이 실제와 얼마나 일치하는지 정확하게 측정할 수 있다.
-
비교 그룹의 분류 (Known GT camera)
- 상단 그룹 (): Ground-truth 카메라 파라미터를 알고 있다는 가정하에 작동하는 방법들이다. Gipuma, MVSNet, GeoMVSNet 등이 포함된다.
- 하단 그룹 (): 카메라 정보를 사전에 알지 못한 상태에서 이미지 데이터만으로 3D 재구성을 수행하는 방법들이다. DUSt3R와 본 논문의 제안 방법(Ours)이 여기에 해당한다.
-
평가 지표 (낮을수록 우수한 성능)
- Acc. (Accuracy): 예측된 포인트 클라우드에서 실제 Ground-truth까지의 최소 유클리드 거리를 의미한다.
- Comp. (Completeness): 실제 Ground-truth 포인트에서 예측된 포인트까지의 최소 유클리드 거리를 의미하며, 얼마나 빠짐없이 재구성했는지를 나타낸다.
- Overall: Accuracy와 Completeness의 평균값으로, 전반적인 챔퍼 거리(Chamfer Distance) 성능을 나타낸다.
-
핵심 분석 및 결과
-
기존 무카메라 방식(DUSt3R) 압도: 동일하게 카메라 정보 없이 작동하는 DUSt3R의 Overall 점수 1.741과 비교했을 때, VGGT는 0.382로 성능을 대폭 향상시켰다. DUSt3R가 여러 이미지를 한 쌍씩 묶어 순차적으로 정렬하기 때문에 오차가 평균내어지며 누적되는 반면, VGGT는 수백 장의 이미지를 한 번에 처리하여 다중 뷰 기하학적 일관성을 더 잘 학습했기 때문이다.
-
카메라 정보 없이도 높은 성능 달성: 제안된 VGGT(Ours)는 카메라 정보를 전혀 모르는 상태()임에도 불구하고, Overall 지표에서 0.382를 기록했다. 이는 카메라 정보를 미리 알고 있는() PatchmatchNet(0.417)이나 MASt3R(0.374)과 대등한 수준의 놀라운 성과다.
-
4.3. Point Map Estimation
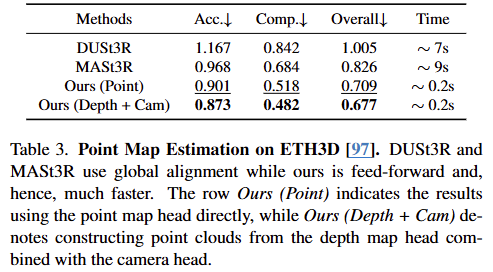
이 표는 ETH3D 데이터셋에서 본 논문의 모델(VGGT)과 기존 최첨단 모델인 DUSt3R 및 MASt3R의 포인트 맵(Point Map) 추정 성능을 비교한 결과다.
-
Table 2(DTU 데이터셋)는 Multi-view Stereo (MVS) 성능을 비교한다. MVS는 보통 카메라 파라미터(위치, 회정 등)가 미리 주어졌다고 가정하고 정밀한 기하 구조를 찾는 작업이다. 그래서 카메라 정보를 아는 기존 MVS 모델들과 비교가 가능하다.
-
반면 Table 3(ETH3D 데이터셋)은 Point Map 추정 성능을 비교한다. 이는 카메라 파라미터를 모르는 상태에서 이미지들만 보고 3D 포인트 클라우드와 카메라 위치를 동시에 예측하는 훨씬 어려운 작업이다. 따라서 이것이 가능한 DUSt3R, MASt3R와만 비교한다.
-
주요 결과 및 분석
-
압도적인 속도 향상: 10 프레임을 처리하는데 DUSt3R(7초)나 MASt3R(9초)는 전역 정렬(Global Alignment)과 같은 복잡한 최적화 과정을 거치지만, VGGT는 순수하게 Feed-Forward 방식으로 단 0.2초 만에 결과를 도출한다. 이 결과는 DUSt3R이나 MASt3R이 가진 복잡한 후처리 최적화의 한계를 지적한다.
-
정확도 우위: VGGT는 대규모 3D 데이터를 학습한 대형 Transformer 아키텍처를 통해, 기하학적 최적화 없이도 실시간에 가까운 속도로 모든 지표에서 기존 모델들보다 더 우수한 수치를 보여준다. 특히 Overall 지표에서 MASt3R 대비 약 18% 이상의 성능 향상을 보였다. Introduction에서 소개했던 내용이 여러 실험 결과를 통해 계속 이어지며 증명되는 것을 볼 수 있다.
-
출력 방식에 따른 차이:
-
Ours (Point): 네트워크의 전용 Point Map Head에서 직접 3D 좌표를 예측한 결과다.
-
Ours (Depth + Cam): 예측된 Depth Map과 Camera Parameter를 조합하여 3D 포인트를 역투영(Unproject)한 결과다.
-
표 결과에 따르면, 직접적인 포인트 예측보다 깊이와 카메라 정보를 조합하는 방식이 더 정확한 기하학적 구조를 형성하는 데 유리함을 알 수 있다.
-
-
4.4. Image Matching
해당 실험에서는 VGGT의 트래킹 모듈 가 Two View Image Matching 태스크에서 얼마나 뛰어난 성능을 보이는지 입증한다.
4.4.1. 트래킹 모듈
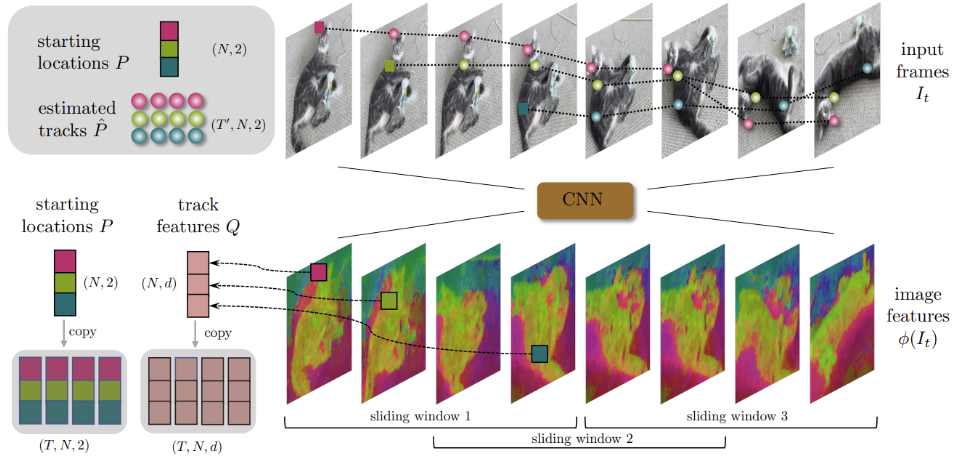
(1) 네트워크 아키텍처
-
기본 CoTracker: 원래 CoTracker는 자체적인 CNN 백본을 사용하여 비디오 프레임에서 특징을 직접 추출한다.
-
VGGT의 수정: CoTracker의 내장 백본을 제거하고, VGGT의 거대한 Alternating-Attention 트랜스포머 백본이 출력한 고차원 특징 맵 를 입력으로 직접 넣는다.
-
이 는 이미 3D 기하학적 정보(카메라 포즈, 깊이 등)를 함축하고 있는 훨씬 강력한 특징이다.
-
DPT 헤드를 통해 가 생성되므로, 수정된 CoTracker는 훨씬 정제된 기하학적 단서 위에서 추적을 수행하게 된다.
-
트래킹 모듈도 VGGT를 학습할 때 오차를 줄이도록 end-to-end로 학습된다.
-
(2) 학습 데이터 구축
-
쿼리 픽셀 선택
- 유효한 깊이 중심: 우선, 정답 깊이(Ground Truth Depth) 값이 존재하는 픽셀들만 후보가 된다.
- 랜덤 및 균등 샘플링: 한 이미지 내에서 수천 개에서 수만 개의 픽셀을 무작위로 뽑거나, 이미지 전체에 골고루 퍼지도록 그리드(Grid) 방식으로 샘플링한다.
-
기하학적 투영을 통한 필터링
- 쿼리 픽셀의 정답 깊이값과 카메라 파라미터를 이용해 해당 픽셀의 3D 좌표를 계산한다.
- 다른 각도에서 바라본 이미지에 해당 3D 좌표를 투영하여 깊이값()를 계산한다.
- 투영된 픽셀에 할당된 GT 깊이값()과 거의 일치한다면 어노테이션 된 데이터로 선택한다.
- 두 값이 일치하지 않는 경우:
- Case 1: (가려짐)
- 투영된 점의 깊이()가 실제 그 위치의 정답 깊이()보다 더 뒤에 있다면, 그 점 앞을 가로막는 다른 물체가 확실히 있다는 뜻이다. 이것은 오클루전으로 판정하여 후보에 포함한다.
- 논문에 적혀있지는 않지만, 오차 수식 내부에는 오클루전에 대한 크로스 엔트로피 로스가 포함되어있어, 모델이 이를 학습할 수 있다.
- Case 2: (오류 또는 공중 부양)
- 반대로 투영된 점이 실제 물체보다 더 앞에 떠 있는 것으로 계산된다면, 이것은 물리적으로 불가능하기 때문에 오차(Error)일 가능성이 높다.
- 이런 경우, 해당 점은 학습용 정답(GT) 데이터에서 제외(Discard)해 버린다. 즉, 모델에게 잘못된 정보를 가르치지 않기 위해 필터링하는 것이다.
- Case 1: (가려짐)
4.4.2. 실험 결과
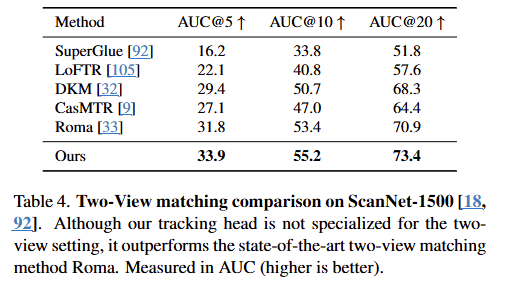
이 표는 ScanNet-1500 데이터셋을 활용하여 두 이미지 간의 매칭 성능을 다양한 기존 기법들과 비교한 결과다. VGGT 모델의 Tracking Head가 이미지 매칭 작업에서도 탁월한 성능을 보임을 증명하고 있다.
-
실험의 목적
- 이 실험은 VGGT가 여러 장의 이미지를 동시에 처리하는 능력 외에도, 두 이미지 사이의 정밀한 픽셀 단위 매칭(Matching) 능력이 얼마나 뛰어난지 검증하기 위한 것이다.
- 카메라 헤드에서 직접 출력되는 포즈 값을 쓰는 것이 아니라, 모델이 찾은 매칭 쌍들이 얼마나 정확한지를 기하학적으로 평가하려는 의도다.
-
카메라 헤드 대신 트래킹 헤드를 사용하는 이유
- Roma, SuperGlue 등 기존의 매칭 모델들은 카메라 포즈를 직접 출력하는 헤드가 없다. 그들은 오직 점과 점의 연결만 수행한다.
- 따라서 이들과 공평하게 비교하기 위해, VGGT도 카메라 헤드의 예측값을 쓰는 대신 "매칭 결과를 이용해 포즈를 역산하는 방식"을 택한 것이다.
-
실제 계산 과정
- 특징점 검출: ALIKED 모델(딥러닝 기반 특징점 검출(Keypoint Detection) 및 기술자(Descriptor) 추출 네트워크)을 사용하여 첫 번째 이미지에서 쿼리 포인트()들을 추출한다.
- 포인트 추적: 이 쿼리 포인트들을 VGGT의 트래킹 모듈()에 입력하여 두 번째 이미지에서의 대응점()들을 찾는다.
- 기하학적 추정: 이렇게 얻은 수많은 2D-2D 매칭 쌍들을 사용해 Essential Matrix ()를 계산한다. (이때, Threshold로 매칭된 점들 중 최종 계산에 사용할 점의 개수와 RANSAC의 Threshold 등을 Roma와 동일하게 세팅한다.)
- 포즈 도출: 계산된 행렬을 분해하여 상대적인 카메라 포즈()를 얻는다.
- 오차 측정: 이렇게 계산된 포즈와 실제 정답(Ground-truth) 포즈를 비교하여 AUC를 산출한다.
-
요약
- VGGT는 4.1. Camera Pose Estimation 실험처럼 카메라 포즈를 직접 예측할 수도 있지만, 매칭 결과물만을 가지고 전통적인 기하학적 방식(Essential Matrix 추정)을 통해 정확도를 계산했다. 결과적으로 VGGT가 찾은 매칭 쌍들이 기존 전문 매칭 모델들보다 더 정확했다는 것이 핵심이다.
5. Conclusion
VGGT(Visual Geometry Grounded Transformer)는 수백 장의 이미지로부터 카메라 파라미터, 깊이 지도, 3D 포인트 트랙 등 주요 3D 속성을 단 한 번의 연산(Feed-forward)으로 직접 추정하는 혁신적인 모델이다. 이 논문이 제시하는 결론의 핵심 내용은 다음과 같다.
-
통합된 3D 속성 추정 아키텍처
- 기존 모델들이 특정 작업에 국한되었던 것과 달리, VGGT는 카메라 파라미터(), 깊이 지도(), 포인트 맵(), 포인트 트랙()을 동시에 예측하는 범용적인 구조를 가졌다.
- 이러한 상호 연관된 3D 속성들을 함께 학습함으로써 개별 작업을 수행할 때보다 더 높은 정확도를 달성했다.
-
기하학적 최적화 없는 고성능 구현
- 전통적인 Structure from Motion(SfM) 방식이나 Geometric 3D Vision Made Easy와 같은 최신 방식이 사후 최적화(Bundle Adjustment 등)에 의존하는 것과 대조적이다.
- VGGT는 사후 처리 없이도 기존의 최적화 기반 방법들보다 뛰어난 성능을 보이며, 수백 장의 이미지를 1초 미만의 짧은 시간에 처리할 수 있는 효율성을 입증했다.
-
강력한 범용 백본으로서의 활용성
- 사전 학습된 VGGT의 특징(Feature)은 비강체 포인트 트래킹(Non-rigid Point Tracking)이나 새로운 시점 합성(Novel View Synthesis)과 같은 하위 작업(Downstream Tasks)에서도 성능을 크게 향상시켰다.
- 이는 3D 비전 분야에서도 대규모 데이터를 기반으로 학습된 강력한 기초 모델(Foundation Model)이 가능함을 시사한다.
