비전 언어 모델
1.언어 모델링
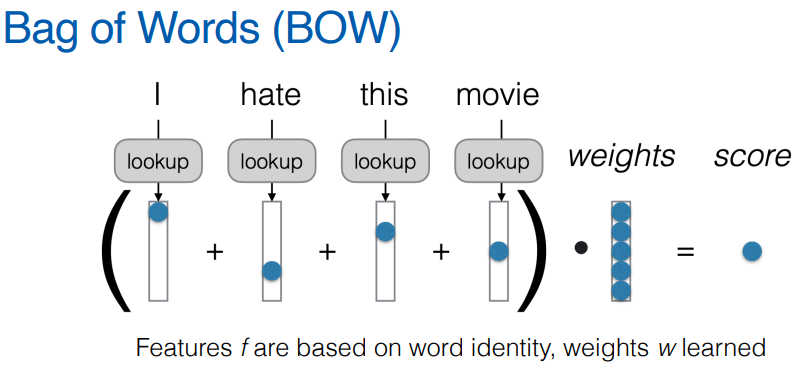
언어 모델링(LM)은 입력(Input) ( X ) 를 출력(Output) ( Y ) 로 매핑하는 함수를 만드는 것을 목표로 하는 작업이다. 대표적으로 다음과 같은 태스크(task)들이 있다.텍스트를 입력받아 다음 텍스트를 생성하는 작업 (언어 모델링)텍스트를 입력받아
2.시퀀스 모델링

데이터가 연속적으로 배열되어있는 경우, 이들의 배열 순서와 맥락을 고려하여 확률적으로 모델링하는 방법. 자연어 처리 분야에서 대표적으로 사용되며, 다음과 같은 태스크에 응용된다.문장 확률 계산 (정상적인 문장 vs 이상한 문장)문장 생성문법 교정 및 패러프레이징이 때
3.트랜스포머
문장의 각 단어를 피처 벡터로 인코딩한 후, 이를 중 모델이 주목해야 할 부분에 대한 가중치를 부여하는 과정.쿼리: 어떤 단어에 집중해야 하는가?키: 쿼리의 질문에 대한 답이 될 수 있는 단어들밸류: 키에 해당하는 단어들의 정보가 융합되어 업데이트 된 단어두 개의 서로
4.LLM 사전학습
대규모의 일반 텍스트 데이터셋에 여러 방법의 비지도학습을 활용하여 모델이 언어를 이해할 수 있는 특성을 부여한다.Masked Language Modeling (BERT):입력 문장의 몇 단어를 마스킹하고, 이를 예측하도록 학습.→ 양방향 학습을 통해 모델의 문맥 이해도
5.LLM 파인튜닝
모델 전체 파라미터를 다시 학습시키는 것. 그러나 대규모 모델의 경우 10B를 넘는 파라미터를 가지고 있으므로, FP16으로 데이터를 간소화해도 1000GB가 넘는 GPU가 필요하다. 이를 해결하기 위해 DeepSpeed ZeRO 기법이 제안되었다.대규모 모델을 단일
6.프롬프트
프롬프트(prompt)는 예를 들어 “영어를 한국어로 번역해줘: Climate change is real.”처럼 자연어 지시문으로 모델이 해야 할 작업을 명시하여, 별도 파인튜닝 없이 번역·분류·요약·코드 생성 등 다양한 태스크를 수행하게 하는 방법이다. 감정 분석
7.효율적인 답안 도출
Train-time scaling은 모델 파라미터, 데이터셋, FLOPs를 늘려 성능을 높이는 전통적 방법이다. 그러나 동일 모델이라도 inference 시간에 얼마나 “생각”할 기회를 주느냐(토큰 길이, 샘플링 횟수, 단계 반복)에 따라 추가 성능 향상이 가능하다.따
8.ViT 기반 VLM
Attention를 CNN에 추가기존 CNN에 self-attention 모듈을 덧붙이는 방식이 먼저 시도되었다. 그러나 전체 구조는 여전히 CNN이라 “Transformer-스러운” 장점을 충분히 살리기 어렵다. citeturn0file0 픽셀 단위 Trans
9.VLM 모델 예시
1\. 학습 목표 이미지 패치의 “시각 토큰”을 예측하도록 마스킹-복원 학습을 수행해 ViT에 고수준 시각 표현력을 부여한다. 2\. 방법론1\. 시각 코드북 구축: Discrete VAE/VQ-GAN으로 약 8 192개 규모의 벡터 ‘코드북’을 사전학습.2\.