1. 언어 모델링(Language Modeling)의 정의
언어 모델링(LM)은 입력(Input) ( X ) 를 출력(Output) ( Y ) 로 매핑하는 함수를 만드는 것을 목표로 하는 작업이다. 대표적으로 다음과 같은 태스크(task)들이 있다.
- 텍스트를 입력받아 다음 텍스트를 생성하는 작업 (언어 모델링)
- 텍스트를 입력받아 다른 언어의 텍스트로 변환하는 작업 (번역)
- 텍스트를 입력받아 적절한 레이블(label)을 붙이는 작업 (텍스트 분류)
- 텍스트를 입력받아 언어적 구조(linguistic structure)를 분석하는 작업 (언어 분석)
- 이미지를 입력받아 텍스트로 묘사하는 작업 (이미지 캡셔닝)
- 텍스트를 입력받아 이미지를 생성하는 작업 (이미지 생성; 기술적으로는 NLP 분야에 속하지 않음)
2. 언어 모델링 시스템의 구축 방법
언어 모델링 시스템은 크게 세 가지 방식으로 구축될 수 있다.
- 규칙 기반(Rule-based): 사람이 수동으로 규칙을 생성
- 학습 기반(Training-based): 입력과 출력이 짝지어진 데이터를 사용하여 기계학습으로 모델을 훈련
- 프롬프팅(Prompting): 학습 없이 미리 훈련된 언어 모델을 프롬프트(prompt)를 이용해 제어
2.1 규칙 기반(Rule-based) LM 시스템
규칙 기반 시스템은 영화 리뷰의 감정 분석(sentiment analysis)과 같은 작업에서 사용된다. 이를 위한 프로세스는 다음과 같은 단계로 구성된다.
- 특징 추출(feature extraction): 텍스트로부터 필요한 특징을 추출
예를 들어 주어진 텍스트에서 감정을 나타내는 키워드를 골라내는 과정
"이 영화는 스토리가 정말 재미있다."라고 하면, "재미있다"를 추출
- 점수 계산(score calculation): 하나 이상의 가능성에 대한 점수를 계산
"재미있다", "훌륭하다" 등이 +2점이라면, 이를 모두 더해 점수 계산
- 결정 함수(decision function)): 점수를 기반으로 최종 결정을 내림
계산된 점수를 바탕으로 리뷰가 긍정적인지, 부정적인지 판단하는 기준
하지만 규칙 기반 시스템은 몇 가지 한계를 가지고 있다.
-
빈도수가 낮은 단어 처리 어려움 → 외부의 감정 사전을 활용하여 해결 가능
예를 들어 '환상적'이란 단어는 매우 드물게 나타나므로, 미리 규칙을 설정해두지 않으면 이 단어를 모델이 이해할 수 없다. 그러나 외부 사전에 해당 단어가 +3점이라고 명시되어있으면, 이를 가져와서 점수화할 수 있다. -
단어의 활용(conjugation) 형태 문제 → 품사(POS, part-of-speech)를 활용하여 해결 가능
"좋았다"라는 단어를 "좋다"라는 기본형으로 매핑하여 원래 점수를 계산한다. -
부정(negation)의 처리 문제 → 구문 분석(syntactic analysis)을 통해 해결 가능
"이 영화는 재미있지 않다."라는 문장을 ["이 영화는", ["재미있다", "않다(부정)"]]으로 구문 분석한 뒤 +2점을 -2점으로 변환하여 최종 점수를 내린다.
2.2 학습 기반(Learning-based) LM 시스템
학습 기반 방식의 대표적인 방법으로는 단어 모음(Bag of Words, BOW) 모델이 있다. BOW 모델은 텍스트 내 단어의 존재 여부나 빈도를 특징으로 사용하여, 가중치(weight)를 학습하여 예측한다.
하지만 BOW 모델의 문제점은 다음과 같다.
- 희귀한 단어 처리 어려움 → 서브워드 모델(Subword Models) 사용 필요
- 단어의 문맥적 의미를 파악하지 못함 → 단어 임베딩(word embeddings) 필요
서브워드 모델(Subword Models)
서브워드 모델은 낮은 빈도의 단어들을 여러 개의 토큰(token)으로 나누는 방법이다. 이를 통해 복합어나 단어 변형 간 매개변수(parameter)를 공유하여 전체 단어 사전(vocabulary)의 크기를 줄이고, 연산량(compute)과 메모리를 절약할 수 있다.
대표적인 서브워드 모델로는 바이트 쌍 인코딩(Byte Pair Encoding, BPE)이 있으며, 원리는 다음과 같다.
- 처음에 모든 단어를 개별 문자로 나눈다.
- 텍스트 데이터에서 가장 자주 나오는 연속된 문자 쌍을 찾아 새로운 토큰으로 결합한다.
- 이 과정을 사용자가 원하는 토큰 수가 될 때까지 반복한다.
단어 임베딩(Word Embeddings)
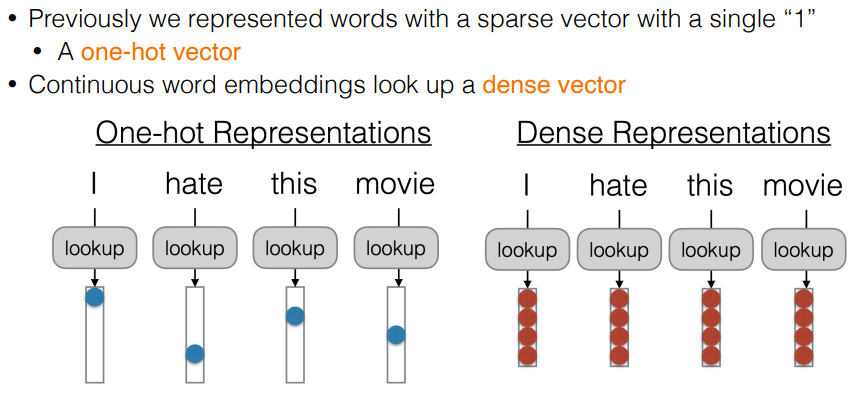
이전의 단어 표현 방식은 원-핫 벡터(one-hot vector)를 이용한 희소(sparse) 표현이었지만, 최근에는 밀집된(dense) 벡터 형태인 단어 임베딩을 사용한다.
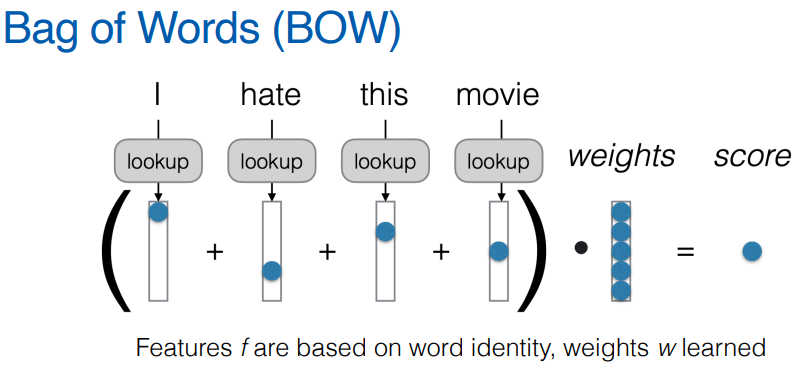
-
대표적인 임베딩 모델로는 BOW(Continuous Bag of Words)가 있으며, 단어들을 벡터 공간 내의 밀집 벡터로 표현하여, 유사한 의미 또는 문법적 특성을 가진 단어들이 벡터 공간에서 가깝게 위치하도록 한다.
-
임베딩 행렬(embedding matrix)에서 특정 벡터를 선택하는 작업은 'lookup'으로 표현될 수 있으며, 원-핫 벡터와 행렬 곱으로 구현된다.
-
즉, 원핫 벡터는 Vocab에 존재하는 토큰 개수의 차원을 가지는 인덱스이며, 임베딩 행렬은 해당 단어의 원핫 벡터를 받아, 그 인덱스에 있는 벡터 정보를 가져오는 역할을 한다.
- 이후에는 인덱스 벡터 또한 원핫이 아닌 더 고차원 벡터로 변환하여 높은 성능을 냄.
3. 시퀀스 모델링(Sequence Modeling)
언어 모델링은 단순히 단어의 집합이 아니라 문장이나 단어 열(sequence)에 확률(probability)을 부여하는 작업이다.
- 조건부 언어 모델(conditional language model)은 문맥(context)을 고려하여 다음 단어의 확률을 예측한다.
- 이때 조인트 확률(joint probability), 조건부 확률(conditional probability), 체인 규칙(chain rule) 등 기초 확률 이론(probability theory) 개념들이 중요하게 사용된다.
- 확률적으로 독립적(independent)이라는 것은 두 확률 변수(random variables)의 결합 확률(joint probability)이 각 변수의 확률의 곱으로 표현된다는 것을 의미한다.
이러한 시퀀스 모델링을 통해, 단순히 단어를 독립적으로 다루는 BOW 모델의 한계를 극복하고 문맥 정보를 반영할 수 있는 개선된(improved) 언어 모델이 만들어질 수 있다.
