< 수강분량 : 알고리즘(1~7), 알고문풀(1~5) >
✅ 알고리즘
- 알고리즘이란?
수학과 컴퓨터과학, 언어학 또는 엮인 분야에서 어떠한 문제를 풀어맺기 위해 정해진 일련의 절차나 방법을 공식화한 형태로 표현한 것이다.
✅ 선형검색
- 선형검색이란?
선형으로 나열되어 있는 데이터를 순차적으로 스캔하면서 원하는 값을 찾는다.
datas = [3, 2, 5, 7, 9, 1, 0, 8, 6, 4]
print(f'datas : {datas}')
print(f'datas length : {len(datas)}')
searchData = int(input('찾으려는 숫자 입력:'))
searchResultIdx = -1
n = 0
while True:
if n == len(datas):
searchResultIdx = -1
break
elif datas[n] == searchData:
searchResultIdx = n
break
n += 1
print(f'searchResultIdx = [{searchResultIdx}]')- 보초법이란?
마지막 인덱스에 찾으려는 값을 추가해서 찾는 과정을 간략화한 것이다.
마지막 인덱스에서 값을 찾는다면 검색실패
datas = [3, 2, 5, 7, 9, 1, 0, 8, 6, 4]
print(f'datas : {datas}')
print(f'datas length : {len(datas)}')
searchData = int(input('찾으려는 숫자 입력:'))
searchResultIdx = -1
datas.append(searchData)
n = 0
while True:
if datas[n] == searchData:
if n != len(datas) - 1:
searchResultIdx = n
break
n += 1
print(f'datas : {datas}')
print(f'datas length : {len(datas)}')
print(f'searchResultIdx = [{searchResultIdx}]')✅ 이진검색
- 이진검색이란?
정렬되어 있는 자료구조에서 중앙값과의 크고 작음을 이용해서 데이터를 검색한다.
datas = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
print(f'datas: {datas}')
print(f'datas length: {len(datas)}')
searchData = int(input('search data: '))
searchResultIdx = -1
staIdx = 0
endIdx = len(datas) - 1
midIdx = (staIdx + endIdx) // 2
midVal = datas[midIdx]
print(f'midIdx: {midIdx}')
print(f'midVal: {midVal}')
while searchData <= datas[len(datas) -1] and searchData >= datas[0]:
if searchData == datas[len(datas) -1]:
searchResultIdx = len(datas) - 1
break
if searchData > midVal:
staIdx = midIdx
midIdx = (staIdx + endIdx) // 2
midVal = datas[midIdx]
print(f'midIdx: {midIdx}')
print(f'midVal: {midVal}')
elif searchData < midVal:
endIdx = midIdx
midIdx = (staIdx + endIdx) // 2
midVal = datas[midIdx]
print(f'midIdx: {midIdx}')
print(f'midVal: {midVal}')
elif searchData == midVal:
searchResultIdx = midIdx
break
print(f'searchResultIdx = {searchResultIdx}')✅ 순위
- 순위란?
수의 크고 작음을 이용해서 수의 순서를 정하는 것을 순위라고 한다.
import random
nums = random.sample(range(50, 101), 20)
ranks = [0 for i in range(20)]
print(f'nums: {nums}')
print(f'ranks: {ranks}')
for idx, num1 in enumerate(nums):
for num2 in nums:
if num1 < num2:
ranks[idx] += 1
print(f'nums: {nums}')
print(f'ranks: {ranks}')
for idx, num in enumerate(nums):
print(f'nums: {num} \t rank: {ranks[idx] + 1}')✅ 버블 정렬
- 버블 정렬이란?
처음부터 끝까지 인접하는 인덱스의 값을 순차적으로 비교하면서 큰 숫자를 가장 끝으로 옮기는 알고리즘이다.
nums = [10, 2, 7, 21, 0]
print(f'not sorted nums: {nums}')
length = len(nums) - 1
for i in range(length):
for j in range(length - i):
if nums[j] > nums[j+1]:
nums[j], nums[j+1] = nums[j+1], nums[j]
print(nums)
print(f'sorted nums: {nums}')✅ 삽입 정렬
- 삽입 정렬이란?
정렬되어 있는 자료 배열과 비교해서, 정렬 위치를 찾는다.
#ascending
nums = [5, 10, 2, 1, 0]
for i1 in range(1, len(nums)):
i2 = i1 - 1
cNum = nums[i1]
while nums[i2] > cNum and i2 >= 0:
nums[i2 + 1] = nums[i2]
i2 -= 1
nums[i2 + 1] = cNum
print(f'nums: {nums}')
#descending
nums = [0, 5, 2, 10, 1]
for i1 in range(1, len(nums)):
i2 = i1 - 1
cNum = nums[i1]
while nums[i2] < cNum and i2 >= 0:
nums[i2 + 1] = nums[i2]
i2 -= 1
nums[i2 + 1] = cNum
print(f'nums: {nums}')✅ 선택 정렬
- 선택 정렬이란?
주어진 리스트 중에 최소값을 찾아, 그 값을 맨 앞에 위치한 값과 교체하는 방식으로 자료를 정렬하는 알고리즘이다.
nums = [4, 2, 5, 1, 3]
print(f'nums: {nums}')
for i in range(len(nums) -1):
minIdx = i
for j in range(i+1, len(nums)):
if nums[minIdx] > nums[j]:
minIdx = j
tempNum = nums[i]
nums[i] = nums[minIdx]
nums[minIdx] = tempNum
#nums[i], nums[minIdx] = nums[minIdx], num[i]
print(f'nums: {nums}')
print(f'nums: {nums}')✏️ 주의할 점 : 얕은 복사로 원래 원본의 데이터가 손상될 수 있으니 깊은 복사를 할 것!
(copy 모듈의 deepcopy 함수 활용)
import random
import sortMod as sm
import copy
scores = random.sample(range(50, 101), 20)
print(f'scores: {scores}')
print(f'scores length: {len(scores)}')
result = sm.sortNumber(copy.deepcopy(scores))
print(f'result = {result}')
print(f'scores: {scores}')
result = sm.sortNumber(copy.deepcopy(scores), asc=False)
print(f'result = {result}')✅ 최댓값과 최솟값
- 최댓값 : 자료구조에서 가장 큰 값을 찾는다.
class MaxAlgorithm:
def __init__(self, ns):
self.nums = ns
self.maxNum = 0
def getMaxNum(self):
self.maxNum = self.nums[0]
for n in self.nums:
if self.maxNum < n:
self.maxNum = n
return self.maxNum
ma = MaxAlgorithm([-2, -4, 5, 7, 10, 0, 8, 20, -11])
maxNum = ma.getMaxNum()
print(f'maxNum: {maxNum}')- 최솟값 : 자료구조에서 가장 작은 값을 찾는다.
class MinAlgorithm:
def __init__(self, ns):
self.nums = ns
self.minNum = 0
def getMinNum(self):
self.minNum = self.nums[0]
for n in self.nums:
if self.minNum > n:
self.minNum = n
return self.minNum
nums = MinAlgorithm([-2, -4, 5, 7, -100, 0, 8, 20, -11])
minNum = nums.getMinNum()
print(f'minNum: {minNum}')✅ 최빈값
- 최빈값 : 데이터에서 빈도수가 가장 많은 데이터를 최빈값이라고 한다.
class MaxAlgorithm:
def __init__(self, ns):
self.nums = ns
self.maxNum = 0
self.maxNumIdx = 0
def setMaxIdxAndNum(self):
self.maxNum = self.nums[0]
self.maxNumIdx = 0
for i, n in enumerate(self.nums):
if self.maxNum < n:
self.maxNum = n
self.maxNumIdx = i
def getMaxNum(self):
return self.maxNum
def getMaxNumIdx(self):
return self.maxNumIdx
nums = [1, 3, 7, 6, 7, 7, 7, 12, 12, 17]
maxAlo = MaxAlgorithm(nums)
maxAlo.setMaxIdxAndNum()
maxNum = maxAlo.getMaxNum()
print(f'maxNum: {maxNum}')
indexes = [0 for i in range(maxNum + 1)]
print(f'indexes: {indexes}')
print(f'indexes length: {len(indexes)}')
for n in nums:
indexes[n] = indexes[n] + 1
print(f'indexes: {indexes}')
maxAlo = MaxAlgorithm(indexes)
maxAlo.setMaxIdxAndNum()
maxNum = maxAlo.getMaxNum()
maxNumIdx = maxAlo.getMaxNumIdx()
print(f'maxNum: {maxNum}')
print(f'maxNumIdx: {maxNumIdx}')
print(f'즉, {maxNumIdx}의 빈도수가 {maxNum}로 가장 높다.')✅ 근삿값
- 근삿값 : 특정 값(참값)에 가장 가까운 값을 근삿값이라고 한다.
import random
nums = random.sample(range(0, 50), 20)
print(f'nums: {nums}')
inputNum = int(input('input number: '))
print(f'inputNum: {inputNum}')
nearNum = 0
minNum = 50
for n in nums:
absNum = abs(n - inputNum)
#print(f'absNum: {absNum}')
if absNum < minNum:
minNum = absNum
nearNum = n
print(f'nearNum: {nearNum}')✅ 평균
- 평균 : 여러 수나 양의 중간값을 갖는 수를 평균이라고 한다.
import random
nums = random.sample(range(0, 100), 10)
print(f'nums: {nums}')
total = 0
for n in nums:
total += n
average = total / len(nums)
print(f'average: {average}')✅ 재귀
- 재귀 : 나 자신을 다시 호출하는 것을 재귀라고 한다.
- 보통 무한반복에 빠지지 않기 위해 조건을 붙이는 편이다.
def recusion(num):
if num > 0:
print('*' * num)
return recusion(num-1)
else:
return 1
recusion(10)
def factorial(num):
if num > 0:
return num * factorial(num-1)
else:
return 1
print(f'factorial(10): {factorial(10)}')✅ 하노이의 탑 (재귀)
- 하노이의 탑 : 퍼즐 게임의 일종으로 세 개의 기둥을 이용해서 원판을 다른 기둥으로 옮기면 되고, 제약 조건은 다음과 같다.
조건1) 한 번에 한개의 원판만 옮길 수 있다.
조건2) 큰 원판이 작은 원판 위에 있어서는 안 된다.
#원판 개수, 출발 기둥, 도착 기둥, 경유 기둥
def moveDisc(discCnt, fromBar, toBar, viaBar):
if discCnt == 1:
print(f'{discCnt}disc를 {fromBar}에서 {toBar}(으)로 이동!')
else:
# (discCnt - 1)개들을 경유 기둥으로 이동
moveDisc(discCnt-1, fromBar, viaBar, toBar)
# disCnt를 목적 기둥으로 이동
print(f'{discCnt}disc를 {fromBar}에서 {toBar}(으)로 이동!')
# (discCnt - 1)개들을 도착 기둥으로 이동
moveDisc(discCnt-1, viaBar, toBar, fromBar)
moveDisc(3, 1, 3, 2)✅ 병합 정렬 (재귀)
- 병합 정렬 : 자료구조를 분할하고 각각의 분할된 자료구조를 정렬한 후 다시 병합하여 정렬한다.
- 만약, 내림차순, 오름차순 같은 변수가 들어간다면 이 부분도 재귀될 수 있도록 코딩해주어야 한다.
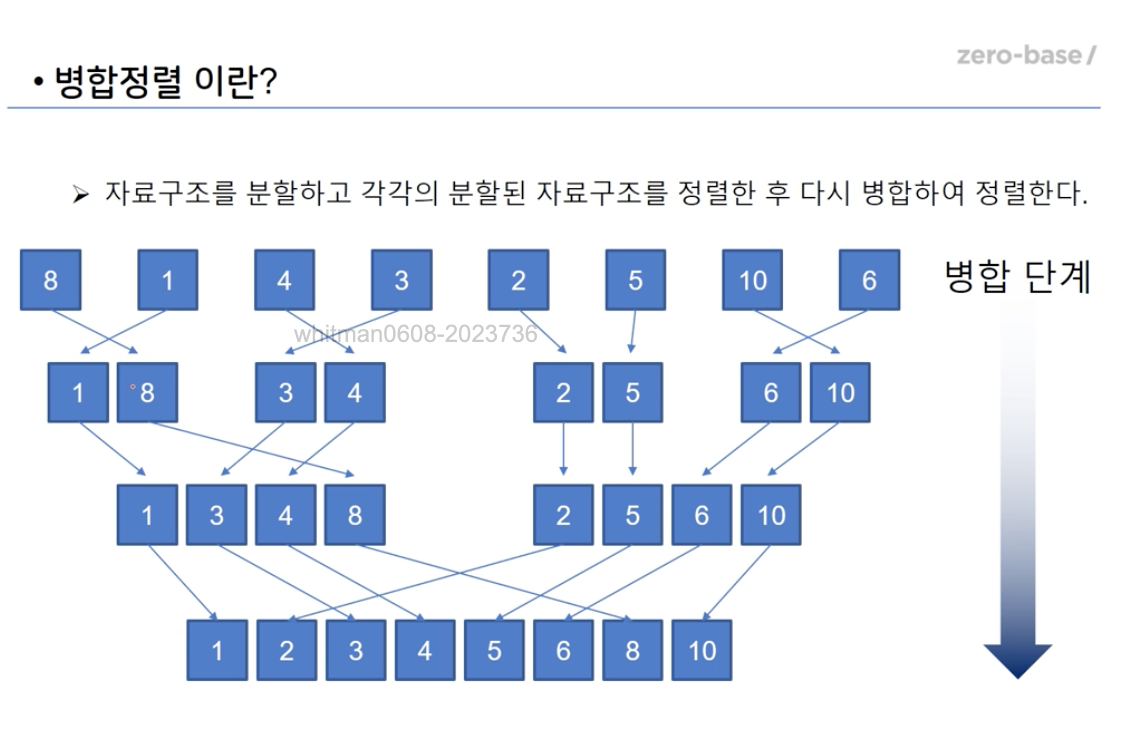
def mSort(ns):
if len(ns) < 2:
return ns
midIdx = len(ns) // 2
leftNums = mSort(ns[0:midIdx])
rightNums = mSort(ns[midIdx:len(ns)])
mergeNums = []
leftIdx = 0; rightIdx = 0
while leftIdx < len(leftNums) and rightIdx < len(rightNums):
if leftNums[leftIdx] < rightNums[rightIdx]:
mergeNums.append(leftNums[leftIdx])
leftIdx += 1
else:
mergeNums.append(rightNums[rightIdx])
rightIdx += 1
mergeNums = mergeNums + leftNums[leftIdx:]
mergeNums = mergeNums + rightNums[rightIdx:]
return mergeNums
nums = [8, 1, 4, 3, 2, 5, 10, 6]
print(f'mSort(nums): {mSort(nums)}')✅ 퀵정렬 (재귀)
- 퀵정렬 : 기준 값보다 작은 값과 큰 값으로 분리한 후 다시 합친다.

def qSort(ns):
if len(ns) < 2:
return ns
midIdx = len(ns) // 2
midVal = ns[midIdx]
smallNums = []; sameNums=[]; bigNums = []
for n in ns:
if n < midVal:
smallNums.append(n)
elif n == midVal:
sameNums.append(n)
else:
bigNums.append(n)
return qSort(smallNums) + sameNums + qSort(bigNums)
nums = [8, 1, 4, 3, 2, 5, 4, 10, 6, 8]
print(f'qSort(nums): {qSort(nums)}')✏️ 퀴즈 복습

- 클래스에서 객체가 생성될 때 생성자를 호출 하면 _ init _() 은 자동호출 된다.
"이 글은 제로베이스 데이터 취업 스쿨의 강의 자료 일부를 발췌하여 작성되었습니다."
