📝Today I learned
🚀 TIL 목차 🚀
- requests와 BeautifulSoup을 활용한 게시글 내용 웹 스크래핑
- 게시글 내용 웹 스크래핑
---아래의 내용은 이전 게시물과 연결됩니다.---
requests와 BeautifulSoup을 활용한 게시글 내용 웹 스크래핑(2)
1) 게시글 내용의 "링크" 웹 스크래핑
🔹 1페이지에서 가져온 목록 테이블을 데이터 프레임으로 변환
df = pd.read_html(response.text)[0]
df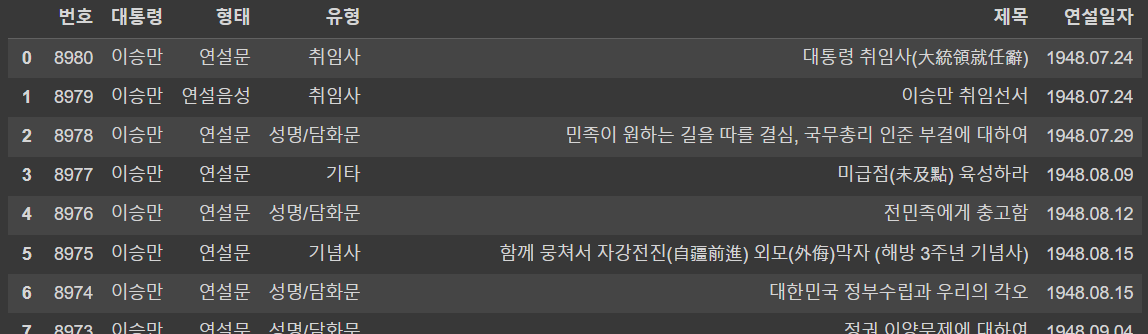
🔹 게시물 목록 페이지에서 내용 페이지로 들어가는 경로 찾기
# 1페이지 모든 게시글 목록 제목의 html 코드
html_list = html.select("#M_More > tr > td.subject > a")
html_list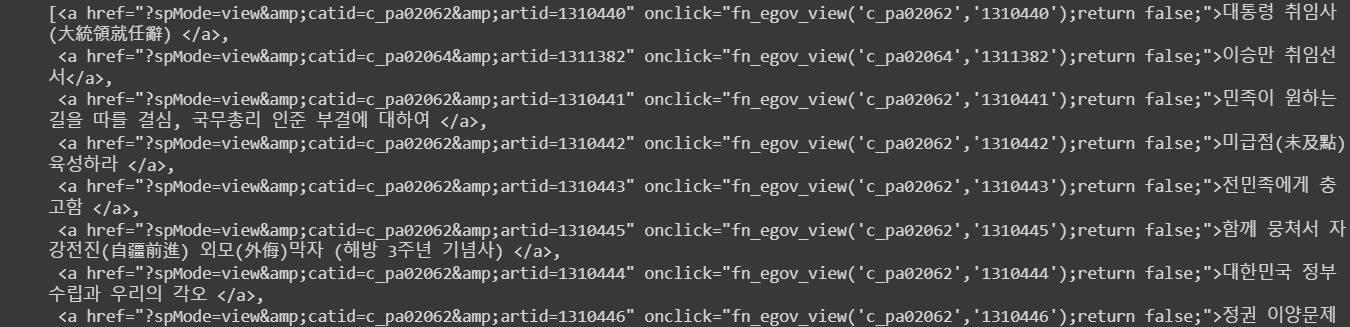
🔹 내용을 특정지을 수 있는 링크(href) 수집
html.select("#M_More > tr > td.subject > a")[0]["href"]
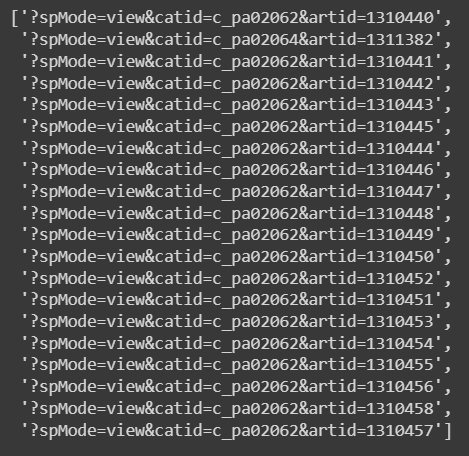
🔹 한 페이지에서 href 목록 만들기
반복문을 만드는 다양한 방법들
방법1 : for문 + 리스트 통째로 가져오기
a_href = []
for a in html.select("#M_More > tr > td.subject > a"):
a_href.append(a["href"])
a_href방법2 : for문 + len 활용
a_href = []
for a in range(len(html.select("#M_More > tr > td.subject > a"))):
a_href.append(html.select("#M_More > tr > td.subject > a")[i]["href"])
a_href방법3 : enumerate (가장 파이썬스러운 방법)
a_href = []
for i, val in enumerate(html.select("#M_More > tr > td.subject > a")):
a_href.append(val["href"])
a_href***단, enumerate는 인덱스와 값을 둘 다 가져올 때 사용하므로 인덱스 값이 굳이 필요하지 않은 경우 적절하지 않음!
방법4 : List Comprehension
a_href = [a["href"] for a in html.select("#M_More > tr > td.subject > a")]
a_href***반복문에서 append 로 추가할 때는 리스트 초기화가 필요하지만 리스트컴프리헨션을 사용하면 초기화 하지 않아도 됨
🧐 내 생각으론 enumerate를 제외하고 방법2 > 방법1 > 방법4 순서로 코드를 더욱 간단하게 줄일 수 있다. 앞으로 list comprehension을 많이 사용하도록 해야겠다.
🔹 '내용링크'라는 파생변수를 만들고 df에 추가하기
df["내용링크"] = a_href
df.head()
🔹 페이지별 내용링크를 수집하여 df에 추가하는 함수
def page_scrapping(page_no):
# 1) page 번호로 URL 만들기
url = "https://www.pa.go.kr/research/contents/speech/index.jsp"
params = f"spMode=&artid=&catid=&pageIndex={page_no}&searchHistoryCount=0&searchStartDate=&searchEndDate=&pageUnit=20"
# 2) requests.post()로 요청하기
response = requests.post(url, params=params, verify=False)
# 3) bs 적용
html = bs(response.text)
# 4) 테이블 찾기
df = pd.read_html(response.text)[0]
# 5) 내용 링크 리스트 만들기
a_href = [a["href"] for a in html.select("#M_More > tr > td.subject > a")]
# 6) 내용링크 컬럼에 5번 리스트 추가하기
df["내용링크"] = a_href
# 7) 결과값 리턴
return df
🔹 여러 페이지의 내용링크를 수집하는 함수
from tqdm import trange
import time
# 경고메시지가 있으면 tqdm 로그가 너무 많이 찍히기 때문에 경고메시지를 제거
requests.packages.urllib3.disable_warnings(requests.packages.urllib3.exceptions.InsecureRequestWarning)
page_list = []
last_page = int(html.select("nav.board-paging > ul > li > a")[-1]["href"].split("=")[-1])
for no in trange(1, last_page + 1):
result = page_scrapping(no)
page_list.append(result)
df = pd.concat(page_list)
df = df.reset_index(drop=True)
df.index = df.index+1
time.sleep(0.01)
df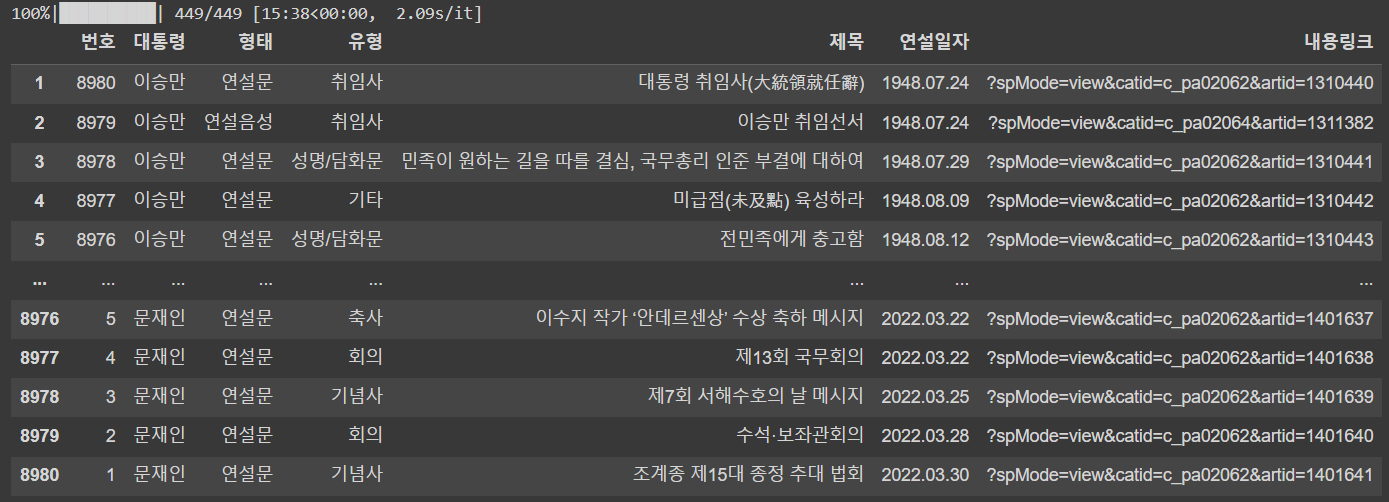
-> 해당 결과를 csv 파일로 저장함
2) 게시글 "내용 텍스트" 웹 스크래핑
🔹 저장된 df 불러오기
df = pd.read_csv("대통령연설문.csv")
df🔹 내용 페이지 내 텍스트 수집을 위한 url 만들기
base_url = "https://www.pa.go.kr/research/contents/speech/index.jsp"
sub_url = df.iloc[0]["내용링크"]
base_url + sub_url # 내용 페이지로 바로 갈 수 있는 url 완성🔹 내용 페이지에 HTTP 요청
response = requests.get(base_url + sub_url, verify=False)***웹 스크래핑을 하기 전에 request method가 get방식인지 post방식인지 먼저 확인할 것
🔹 BeautifulSoup 적용
html = bs(response.text)
html🔹 내용 수집
content = html.find_all("td", {"class":"content"})[0].text
content🔹 내용 수집 함수
def get_content(sub_url):
# 1) 수집할 URL 만들기
base_url = "https://www.pa.go.kr/research/contents/speech/index.jsp"
url = base_url + sub_url
# 2) requests로 HTTP 요청하기
response = requests.get(url, verify=False)
# 3) response.text에 BeautifulSoup 적용하기
html = bs(response.text)
# 4) 내용 가져오기
content = html.select("td.content")[0].text
# 5) time.sleep()
time.sleep(0.01)
# 6) 내용 반환하기
return content🔹 전체 페이지의 내용 수집 함수
from tqdm.notebook import tqdm
tqdm.pandas()
df = df.head(10) # 적은 분량으로 진행
view = df["내용링크"].progress_map(get_content)
view- 함수를 반복해서 사용해야할 때 : pandas에서는 map, apply, applymap 사용
- 단, 진행상태까지 표시하려면 tqdm 의 progress_map, progress_apply 사용
🔹 '내용' 컬럼 만들고 df에 추가하기
df["내용"] = view
df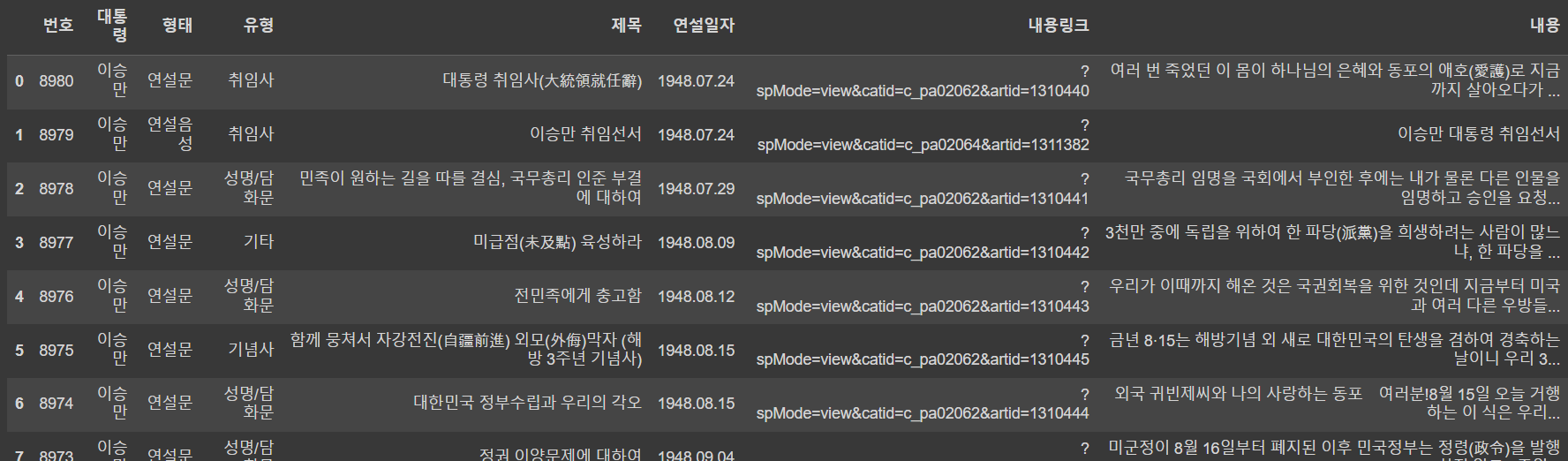
🔹 원하는 컬럼 내용만 남기기
cols = ['번호', '대통령', '형태', '유형', '제목', '연설일자', '내용'] # 원하는 컬럼 및 컬럼 순서 결정
df = df[cols] # 원래 df에 적용🔹 최종 결과물 저장 및 불러오기
file_name = "대통령연설문내용.csv"
df.to_csv(file_name, index=False)
pd.read_csv(file_name)❗이것만은 외우고 자자 Top 3
📌 enumerate 함수는 인덱스와 원소로 이루어진 튜플을 반환함
📌 함수를 호출할 때 전달하는 입력값은 parameter가 아니라 argument
📌 변수명을 설정할 땐 예약어를 사용하지 않도록 주의하자(특히 list)
🌟데일리 피드백
1. 오늘의 칭찬&반성
그냥 코드를 복붙하지 않고 단계를 차근차근 생각해가며 함수를 만든 것이 뿌듯했다. 다만 시간이 너무 오래걸리는데 이건 계속 연습하면 속도가 날 것 같다.
2. 내가 부족한 부분
코드를 더 간략하게 효율적으로 작성할 수 있는 방법을 고민하고 직접 찾아봐야겠다.
3. 내일의 목표
수업시간 풀 집중!
