📝Today I learned
🚀 TIL 목차 🚀
1) 내용 링크 수집하는 단계별 과정
- 다산 콜센터 1페이지 url 찾기
- requests로 웹페이지 결과 받아오기
- bs로 parsing 하기
- parsing한 html에서 내용 링크만 추출하기(0번째 인덱스로 연습)
- 전체 인덱스의 내용 링크만 추출
- pd.read_html 활용해서 table 정보 읽어와서 df에 저장
- df에 '내용번호' 칼럼 새로 추가하고 내용번호 리스트 입력
2) 모든 단계를 종합하여 함수 만들기
- 특정 페이지의 내용번호 수집하는 함수
- 반복문을 통해 여러페이지 수집하는 함수
- 데이터 병합
서울 다산콜센터 주요질문 목록 및 내용 웹스크래핑
1) 내용 링크 수집하는 단계별 과정
서울 다산콜센터 '120 주요질문' 웹사이트 링크
: https://opengov.seoul.go.kr/civilappeal/list?items_per_page=50&page=1
🔹 다산 콜센터 1페이지 url 찾기
base_url = "https://opengov.seoul.go.kr/civilappeal/list?items_per_page=50&page=1"🔹 requests로 웹페이지 결과 받아오기
response = requests.get(base_url)
response.status_code # 200이 나오면 정상적으로 받아온 것🔹 bs로 parsing 하기
html = bs(response.text)🔹 parsing한 html에서 내용 링크만 추출하기(0번째 인덱스로 연습)
display(html.select('table > tbody > tr > td > a')[0])
display(html.select('table > tbody > tr > td > a')[0]["href"])
display(html.select('table > tbody > tr > td > a')[0]["href"].split('/'))
display(html.select('table > tbody > tr > td > a')[0]["href"].split('/')[-1])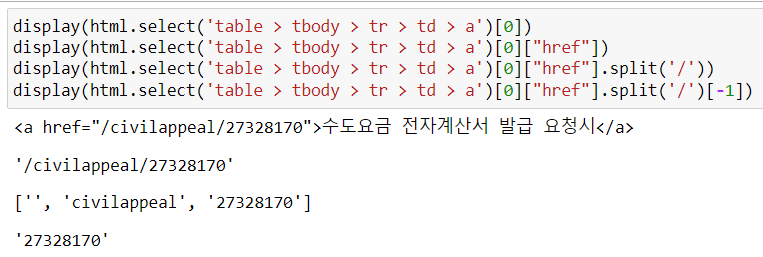
: 2243번 '수도요금 전자계산서 발급 요청서'라는 게시물로 들어갈 수 있는 번호를 html 텍스트에서 찾아낸 결과가 '27328170'이다.
🔹 전체 인덱스(=게시물)의 내용 링크만 추출
a_link_no = [a["href"].split('/')[-1] for a in html.select('table > tbody > tr > td > a')]
a_link_no
🔹 pd.read_html 활용해서 table 정보 읽어와서 df에 저장
df = pd.read_html(response.text)[0]
🔹 df에 '내용번호' 칼럼 새로 추가하고 내용번호 리스트 입력
df["내용번호"] = a_link_no
2) 모든 단계를 종합하여 '게시글 내용 번호' 수집 함수 만들기
🔹 하나의 특정 페이지의 내용번호 수집하는 함수
def get_one_page(page_no):
try:
base_url = f"https://opengov.seoul.go.kr/civilappeal/list?items_per_page=50&page={page_no}"
response = requests.get(base_url)
table = pd.read_html(response.text)[0]
html = bs(response.text)
a_link_no = [a["href"].split('/')[-1] for a in html.select('table > tbody > tr > td > a')]
table["내용번호"] = a_link_no
return table
except Exception as e:
print(f"{page_no}쪽에서 오류가 발생했습니다. \nERROR: {e}") - 없는 페이지를 입력한 경우(예외처리가 잘 작동하는지 확인)

🔹 반복문을 통해 여러 페이지의 목록을 수집하는 함수
page_no = 1
table_list = []
while True:
df_one = get_one_page(page_no)
if len(df_one) == 0:
break
table_list.append(df_one)
print(page_no, end=",")
page_no += 1
time.sleep(0.01)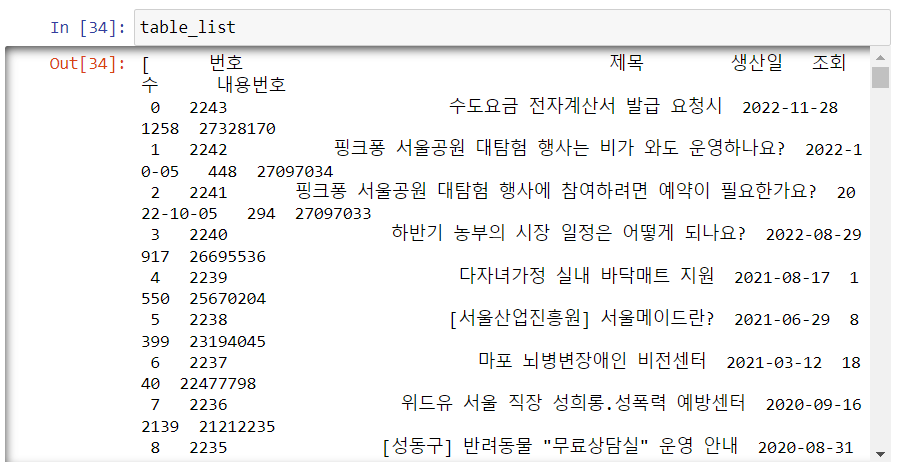
🔹 데이터 병합
# 기존 인덱스를 삭제하고 새 인덱스 생성
# df.reset_index(drop=True)와 똑같은 기능
df = pd.concat(table_list, ignore_index=True)3) 모든 페이지의 내용 텍스트 수집하기
🔹 메인페이지 목록 데이터 가져오기
df = pd.read_csv("data/seoul-120/seoul-120-list.csv")
df = df.head(10)***우선 적은 양으로 진행하고 모든 코드가 완성되면 전체 데이터로 진행한다.
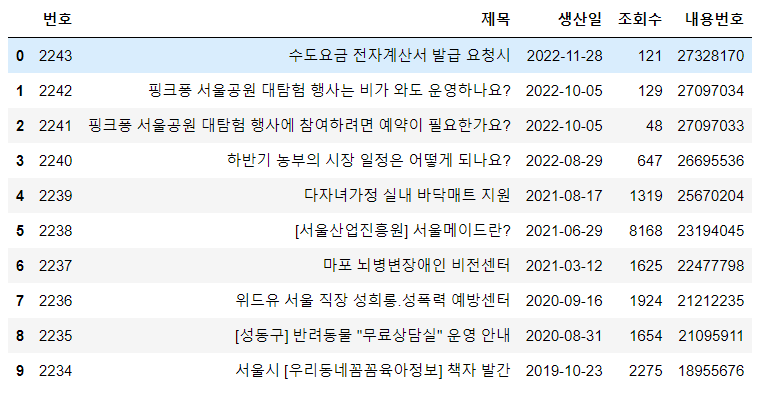
🔹 내용 텍스트가 있는 url 찾기
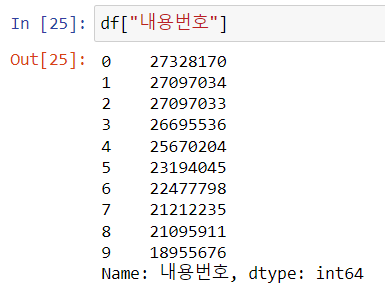
no = df["내용번호"][0] # 27328170
url = f"https://opengov.seoul.go.kr/civilappeal/{no}"
print(url)출력 결과 : https://opengov.seoul.go.kr/civilappeal/27328170
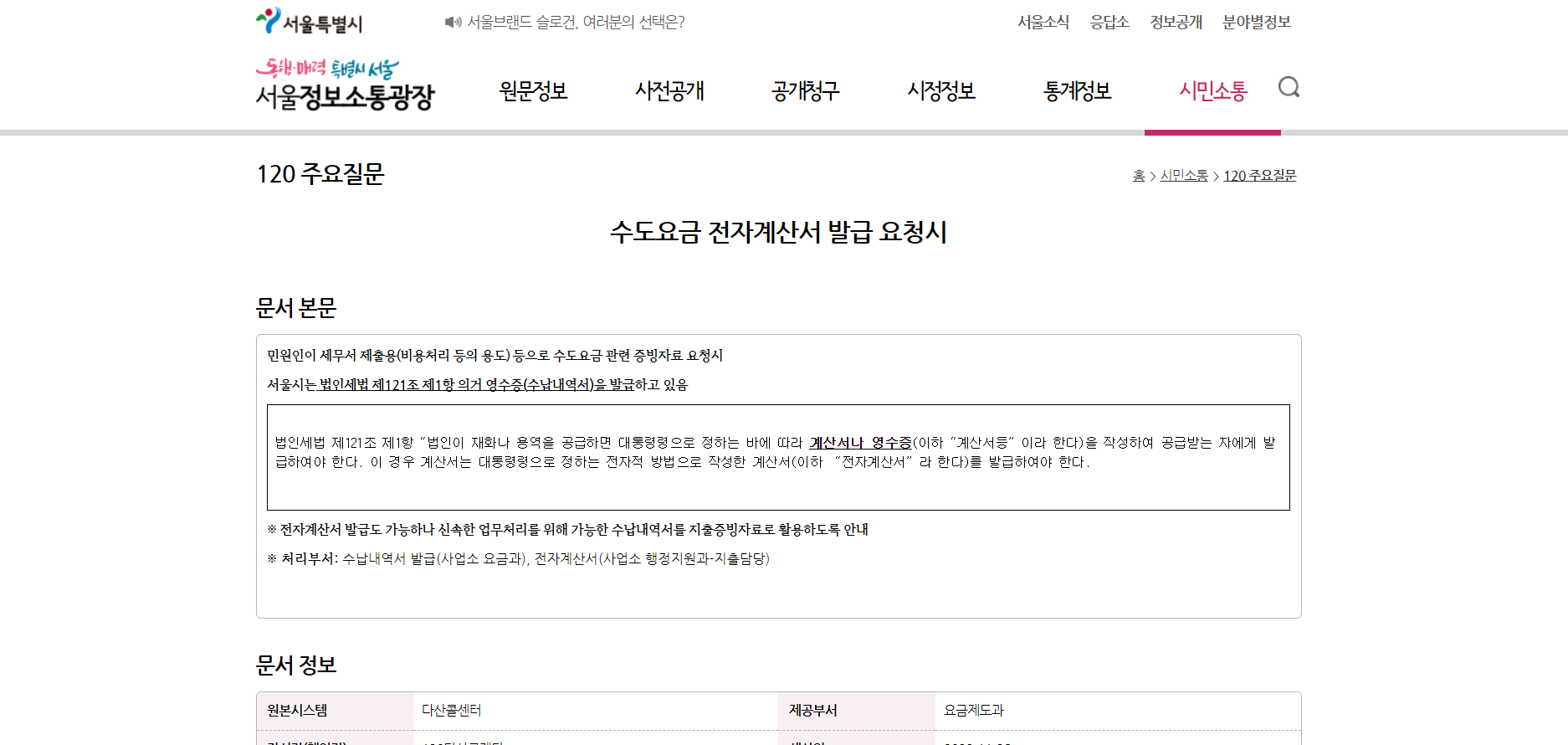
🔹 requests로 내용이 있는 웹페이지 결과 받아오기
response = requests.get(url)🔹 bs로 parsing 하기
html = bs(response.text)* 원하는 정보 1번 : 문서 정보

🔹 '문서 정보' 데이터 가져오기
df_desc = pd.read_html(response.text)[-1]
df_desc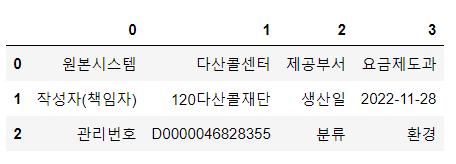
0열의 '원본시스템', '작성자(책임자)', '관리번호'
2열의 '제공부서', '생산일', '분류'
를 컬럼명으로 하는 새 데이터프레임을 만들어야 함.
.
0열('원본시스템', '작성자(책임자)', '관리번호')부터 시작.
df_desc[[0, 1]]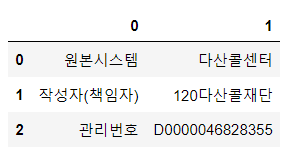
df_desc[[0, 1]].set_index(0) # 0열의 내용을 인덱스로 만들기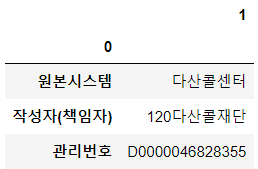
2열('제공부서', '생산일', '분류')도 같은 방식으로 진행
df_desc[[2, 3]]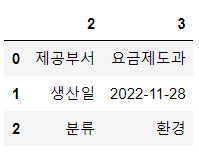
df_desc[[2, 3]].set_index(2) # 2열의 내용을 인덱스로 만들기
tb01 = df_desc[[0, 1]].set_index(0).T # 전치행렬로 만들기
tb02 = df_desc[[2, 3]].set_index(2).T # 전치행렬로 만들기
display(tb01)
display(tb02)
- 전치행렬 : 행 인덱스가 열 인덱스로
tb02.index = tb01.index # 인덱스가 같아야 concat 가능
result = pd.concat([tb01, tb02], axis=1) # axis=1을 해야 열방향으로 결합 가능
result
🔹 한 페이지의 '문서 정보'를 가져오는 함수
def get_desc(response):
df_desc = pd.read_html(response.text)[-1]
tb01 = df_desc[[0, 1]].set_index(0).T
tb02 = df_desc[[2, 3]].set_index(2).T
tb02.index = tb01.index
result = pd.concat([tb01, tb02], axis=1)
return result* 원하는 정보 2번 : 문서 본문

🔹 '문서 본문' 데이터 가져오기
html.find("div", {"class":"line-all"}).text.strip()- strip() : 문자열에서 양쪽 공백을 제거

🔹 한 페이지의 '문서 정보와 본문'을 가져오는 함수
def get_view_page(view_no):
try:
url = f"https://opengov.seoul.go.kr/civilappeal/{view_no}"
response = requests.get(url)
df_temp = get_desc(response) # 문서 정보 가져오기
html = bs(response.text)
context = html.find("div", {"class":"line-all"}).text.strip() # 문서 본문 가져오기
df_temp["내용"] = context
df_temp["내용번호"] = view_no
time.sleep(0.01)
return df_temp
except Exception as e :
print(f"Error_view_no: {view_no} \nERROR: {e}")🔹 '문서 정보와 본문'을 가져오는 함수를 반복
from tqdm.notebook import tqdm
tqdm.pandas()
view_detail = df["내용번호"].head(10).progress_map(get_view_page)
# 우선 10개만 잘라서 내용페이지의 '문서 정보와 본문' 가져오기🔹 수집한 '문서 정보와 본문' 내용 확인
display(view_detail)
display(type(view_detail))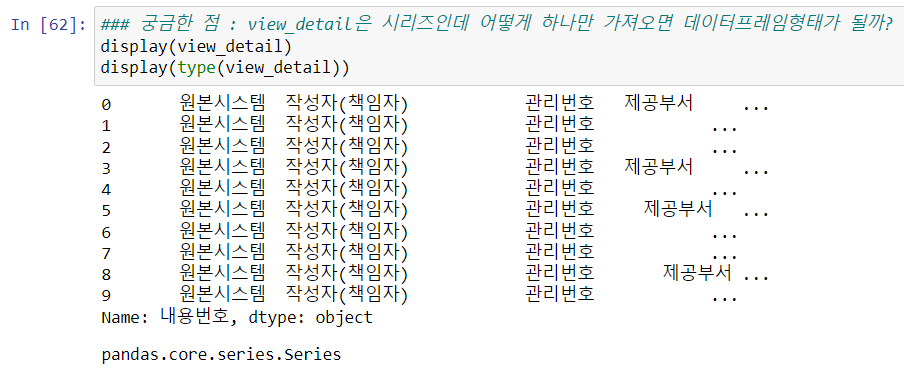

- view_detail의 타입은 '시리즈'이고, 각 시리즈에 담겨있는 데이터의 타입은 '데이터프레임'이다.
=> 즉, 시리즈의 요소로 데이터프레임이 올 수 있다.
🔹 수집한 '문서 정보와 본문' 내용 병합하기
# 수집한 내용(view_detail)을 to_list() 를 통해 리스트로 변환 후 concat 으로 병합
# view_detail 변수 안에 들어있는 값은 Series 형태
# concat()으로 병합하기 위해서는 리스트 형태로 되어있어야 함
# ignore_index=True 로 기존 인덱스를 삭제함
df_view = pd.concat(view_detail.to_list(), ignore_index=True)
df_view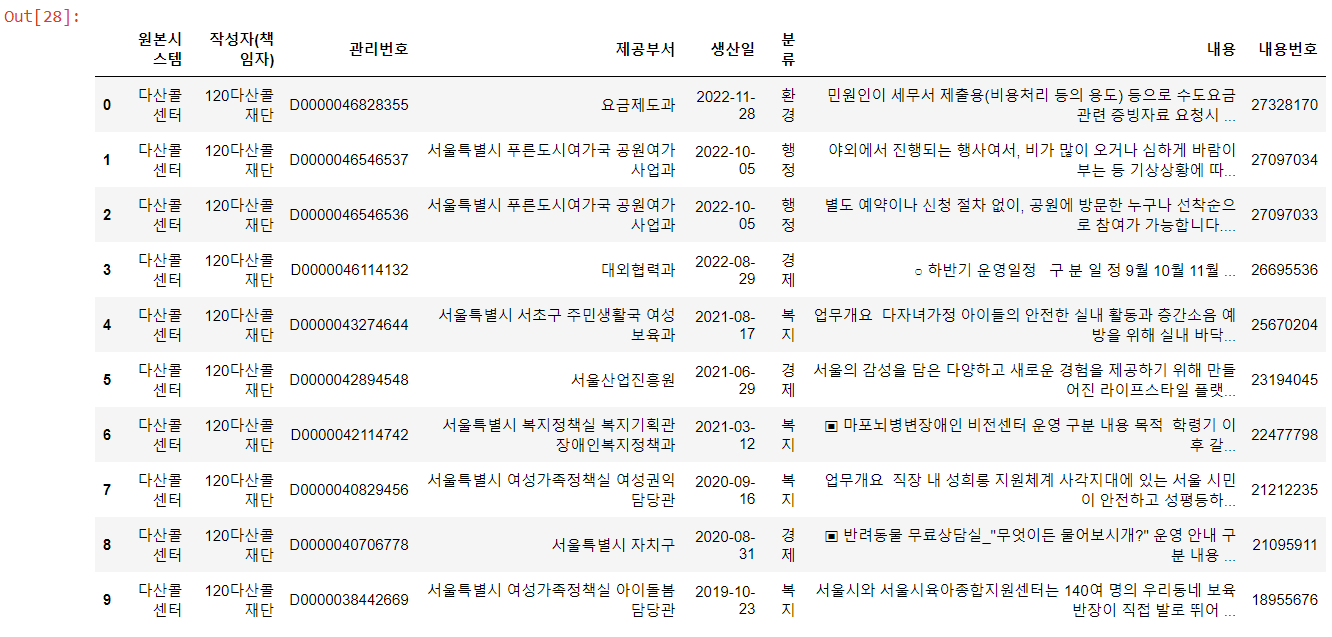
🔹 기존 데이터와 내용 데이터 병합
# 기존 데이터(메인페이지 게시글 목록)와 이후 수집한 내용 데이터 병합
# merge는 컬럼, 혹은 인덱스를 기준으로 병합
# join은 인덱스 기준으로 병합
# how left : df를 기준으로 '내용번호'와 '생산일'이 df_view에 없으면 df_view가 NaN값으로 나타남
df_detail = df.merge(df_view, on=["내용번호", "생산일"], how="left")
df_detail
🔹 사용할 컬럼만 남기기
df_save = df_detail[['번호', '분류', '제목', '내용', '내용번호']]
df_save
❗이것만은 외우고 자자 Top 3
📌 시리즈에는 데이터프레임 타입을 담을 수 있다. 리스트에도 데이터프레임 타입을 담을 수 있다.
📌 pd.merge는 공통된 열을 기준으로 두 df를 합쳐줌.
left join은 왼쪽 df기준으로 조인하며 오른쪽 df에 없는 값은 NaN으로 나타남.
right join은 left join의 반대.
inner join은 두 df에 공통된 값만 보여줌.
outer join은 두 df의 모든 값을 보여줌.
📌 concat을 할 땐 리스트로 변환 후 concat()으로 병합할 수 있다.
🌟데일리 피드백
1. 오늘의 칭찬&반성
수집하는 데이터가 많아지니 찾아야 할 url, html 속 필요한 정보들도 많아져서 정신이 없었다. 하지만 내가 익숙하지 않아서 어려운 것이라 생각하고 2번, 3번 읽으니 이제 이해가 된다. 중간에 포기하지 않고 끝까지 붙들고 간 내가 대견하다!
2. 내가 부족한 부분
시리즈 요소로 데이터프레임이 있을 때 왜 이런 모양이 나오는 지 모르겠다.
이게 뭐람??

3. 내일의 목표
이번주 복습 내용 1회독 하기
