[230206] 멋쟁이사자처럼 AI SCHOOL 8기 아파트 분양가격 데이터 EDA_박조은강사님' 복습
멋사 AI SCHOOL 8기
- 해당 포스팅의 내용은 '멋쟁이사자처럼 AI SCHOOL 박조은 강사님'의 수업을 토대로 작성되었습니다.
📝Today I learned
🚀 TIL 목차 🚀
사용한 라이브러리
데이터 불러오기
3-1. 기본 전처리
- 데이터 요약
- 결측치 확인
- 데이터 타입 변경
3-2. df_last 전처리
- 평당분양가격 구하기
- 규모구분을 전용면적 컬럼으로 변경
- 필요없는 컬럼 제거
3-3. df_first 전처리
- melt
- 연도 월 분리
- 컬럼명 통일
- 데이터프레임 병합
- 집계 및 시각화
- groupby로 데이터 집계
- pivot table로 데이터 집계 - heatmap
- bar plot
- point plot
- box plot
- violin plot
- swarm plot
아파트 분양가격 데이터 EDA
1. 사용한 라이브러리
import pandas as pd # 분석
import numpy as np # 수치계산
import seaborn as sns # 시각화
import matplotlib.pyplot as plt # 시각화# 한글 폰트 및 선명한 그래프를 위한 작업
import koreanize_matplotlib
%config InlineBackend.figure_format = 'retina'2. 데이터 불러오기
🔹 파일명 불러오기
from glob import glob
file_names = glob("data/apt*.csv")
file_names
🔹 데이터를 변수에 담기
💡 인코딩에 대하여
- euc-kr -> 2,350자 한글 표현 가능 (설믜씨 이름 표현 불가능)
- cp949 -> 11,172자 한글 모두 표현 가능
df_last = pd.read_csv(file_names[1], encoding="cp949")
df_last.head()
df_first = pd.read_csv(file_names[0], encoding="cp949")
df_first.head()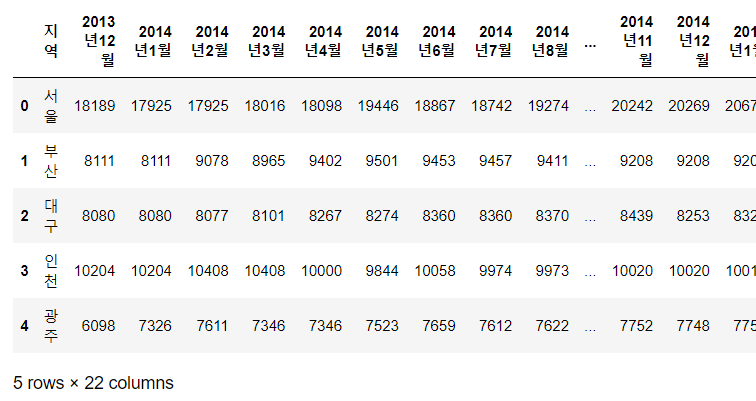
3-1. 기본 전처리
🔹 데이터 요약
df_last.info()
# 분양 가격이 object로 되어있음을 확인
🔹 결측치 확인
💡 결측치 처리에 대하여
: 선) 결측치 생성 원인 파악 -> 후) 결측치 처리 방법 결정
: 모든 연도월에 분양이 있는 것은 아니기에 자연스럽게 생긴 결측치
: 삭제하거나 대체값을 넣지 않기로 결정
# 결측치의 합계
df_last.isnull().sum()
# 결측치의 비율
df_last.isna().mean()
🔹 데이터 타입 변경
: 위 데이터 요약에서 df_last["분양가격"]의 타입이 object임을 확인
: 이후 계산하기 쉽게 수치 데이터로 변경하기로 함
df_last["분양가격"] = pd.to_numeric(df_last["분양가격"], errors='coerce')💡 errors='coerce'
: 데이터를 숫자로 바꾸는 과정에서 유효하지 않은 값이 나타나면 NaN으로 만듦

3-2. df_last 전처리
🔹 평당분양가격 구하기
: df_first 데이터는 평당분양가격 기준
: df_last 데이터의 제곱미터당 분양가격에 3.3을 곱해 평당분양가격으로 만들기
df_last["평당분양가격"] = df_last["분양가격"] * 3.3
🔹 규모구분을 전용면적 컬럼으로 변경
: 텍스트 데이터는 로드가 오래 걸리고 전처리나 연산 속도도 느림
: 일반적으로 관리, 속도 이슈로 수치 형태의 코드값으로 관리하는 편
: '규모구분'보다는 '전용면적'이 더 직관적
# regex(regular expression, 정규표현식) <- warning message, |과 같은 정규표현식을 사용할거면 regex=True라고 표현해줄 것을 권장
df_last["전용면적"] = df_last["규모구분"].str.replace("전용면적|제곱미터| |이하", "", regex=True)
df_last["전용면적"] = df_last["전용면적"].str.replace("초과", "~")
df_last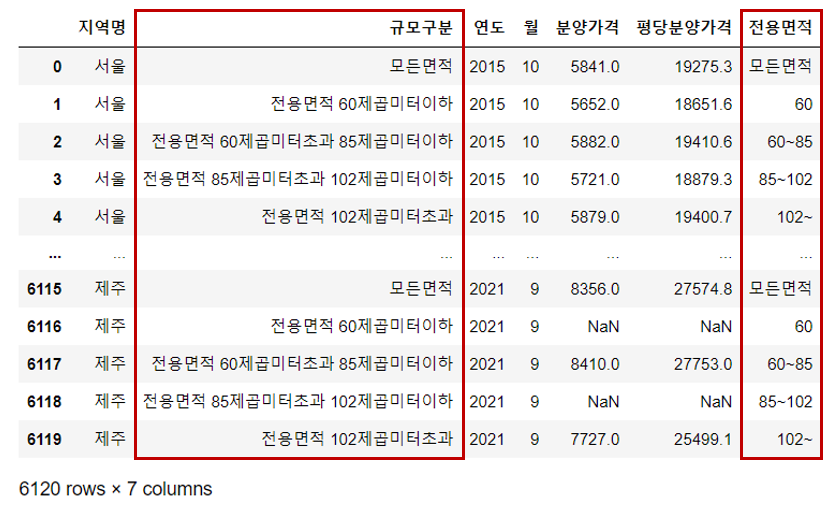
🔹 필요없는 컬럼 제거
df_last = df_last.drop(columns=["분양가격"])
df_last = df_last.drop(["규모구분"], axis=1) # 위, 아래 두 가지 방법 모두 가능
df_last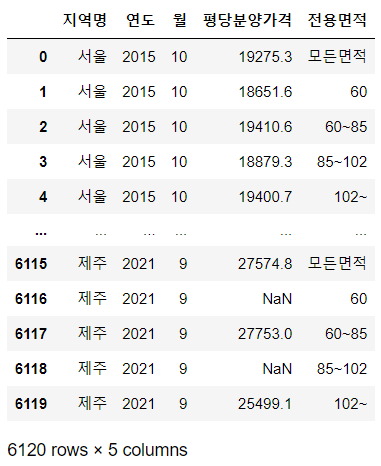
3-3. df_first 전처리
🔹 melt
# 모든 컬럼이 출력되게 설정합니다.
# display하는데 시간이 오래 걸림
# 매우 큰 데이터에 이 기능을 사용하면 노트북이 느려질 수 있음
pd.options.display.max_columns = None
df_first.head()
df_first_melt = pd.melt(df_first, id_vars="지역")
df_first_melt.head()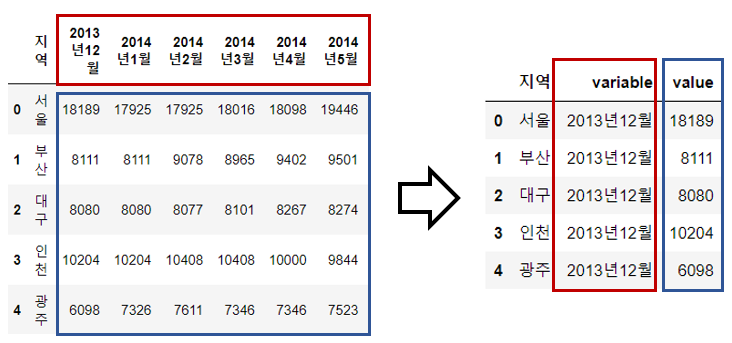
# df_first_melt 변수에 담겨진 컬럼의 이름을
# ["지역명", "기간", "평당분양가격"] 으로 변경
df_first_melt.columns = ["지역명", "기간", "평당분양가격"]🔹 연도 월 분리
: 연도와 같은 방식으로 월도 분리
# 연도만 반환하는 함수
def parse_year(date):
return int(date.split("년")[0])# df_first_melt 변수에 담긴 데이터프레임에서
# apply를 활용해 연도만 추출해서 새로운 컬럼으로 만들기
df_first_melt["연도"] = df_first_melt["기간"].apply(parse_year)# 함수가 아닌 string accessor를 사용하는 법
# expand=True : Dataframe으로 반환
df_first_melt["연도"] = df_first_melt["기간"].str.split("년", expand=True)[0].astype(int)🔹 컬럼명 통일
# 공통적으로 필요한 컬럼
cols = ['지역명', '연도', '월', '평당분양가격']# 최근 데이터가 담긴 df_last 에는 전용면적이 있음
# 이전 데이터에는 전용면적이 없기 때문에 "모든면적"만 사용
# loc를 사용해서 전체에 해당하는 면적만 copy로 복사해서 df_last_prepare 변수에 담기
# .copy() : 원 데이터를 변경하지 않는 깊은 복사
df_last_prepare = df_last.loc[df_last["전용면적"] == '모든면적', cols].copy()
df_last_prepare.head()
# df_first_melt에서 공통된 컬럼만 가져온 뒤
# copy로 복사해서 df_first_prepare 변수에 담기
df_first_prepare = df_first_melt[cols].copy()
df_first_prepare.head()
🔹 데이터프레임 병합
df = pd.concat([df_first_prepare, df_last_prepare])4. 집계 및 시각화
🔹 groupby로 데이터 집계
df_yr = df.groupby(["연도", "지역명"])["평당분양가격"].mean().unstack()
df_yr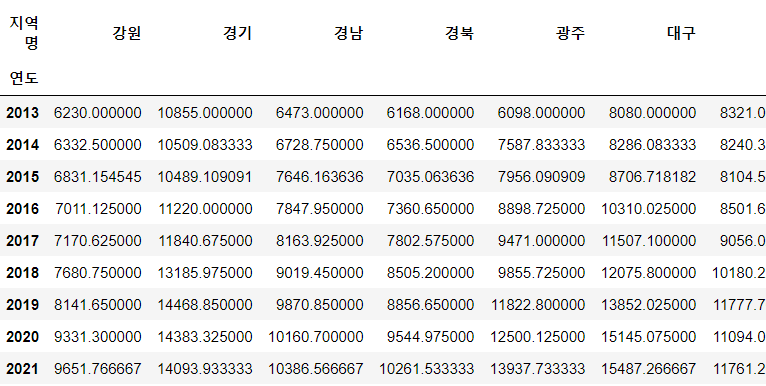
df_yr[["서울", "경기", "제주", "울산"]].plot.bar(rot=0, figsize=(10,5), title="연도별 지역별 평당분양가격평균");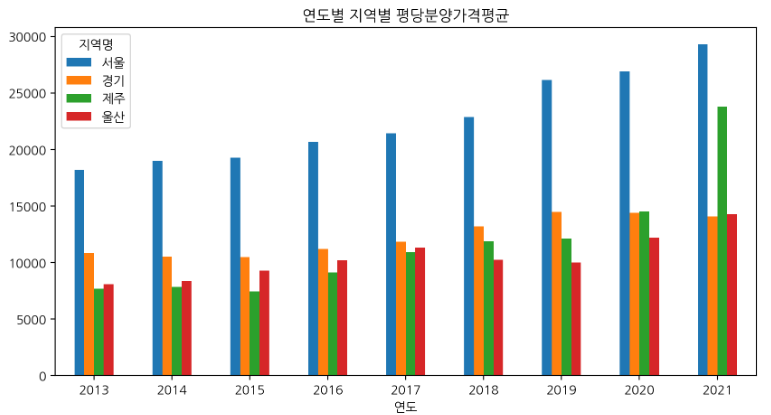
🔹 pivot table로 데이터 집계 - heatmap
df_pv = df.pivot_table(index="연도", columns="지역명", values="평당분양가격")
df_pv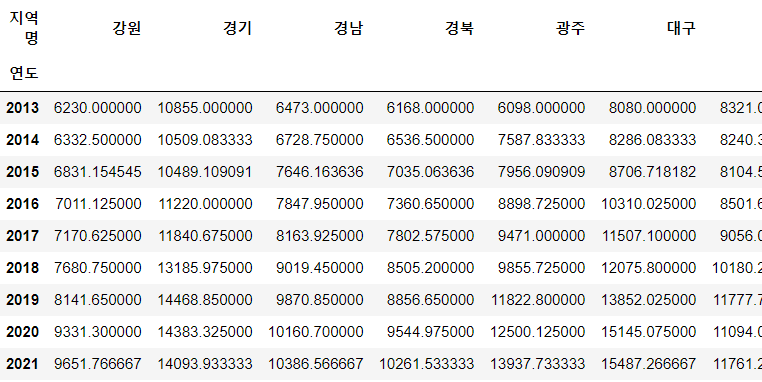
plt.figure(figsize=(12, 6))
sns.heatmap(df_pv.T, cmap='Greens', annot=True, fmt=',.0f');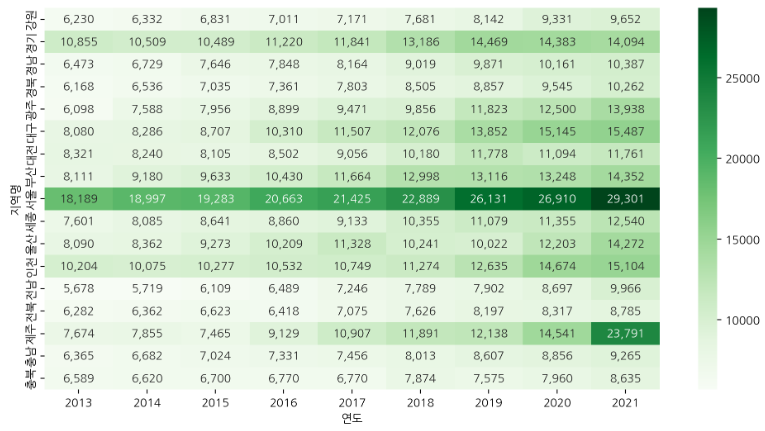
🔹 bar plot
# 검은색 막대는 신뢰구간
# errorbar는 기본적으로 신뢰구간을 표기하는데 시간이 오래 걸려서 None으로 처리하는 것을 추천
plt.figure(figsize=(12, 4))
sns.barplot(data=df, x="연도", y="평당분양가격", errorbar=None).set_title("연도별 평균 평당분양가격");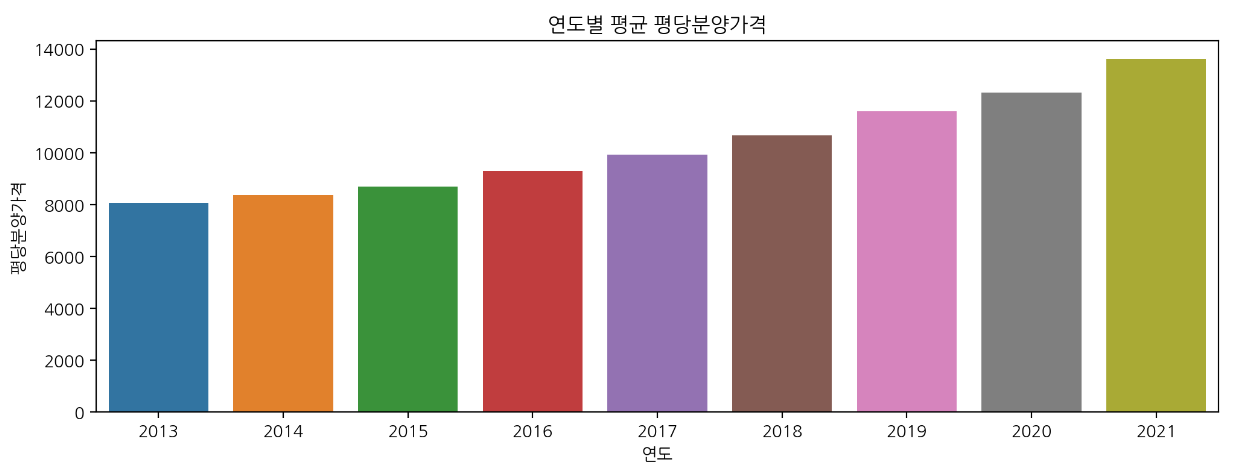
🔹 point plot
plt.figure(figsize=(12, 4))
sns.pointplot(data=df, x="연도", y="평당분양가격", errorbar=None).set_title("연도별 평균 평당분양가격");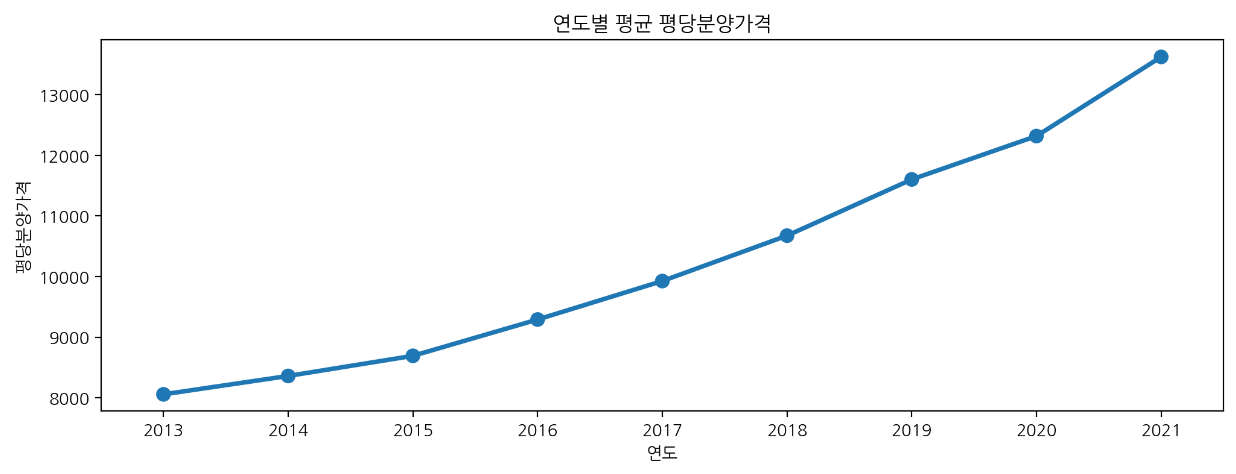
🔹 box plot
: 4분위수 표기
plt.figure(figsize=(12, 4))
sns.boxplot(data=df, x="연도", y="평당분양가격").set_title("연도별 평당분양가격");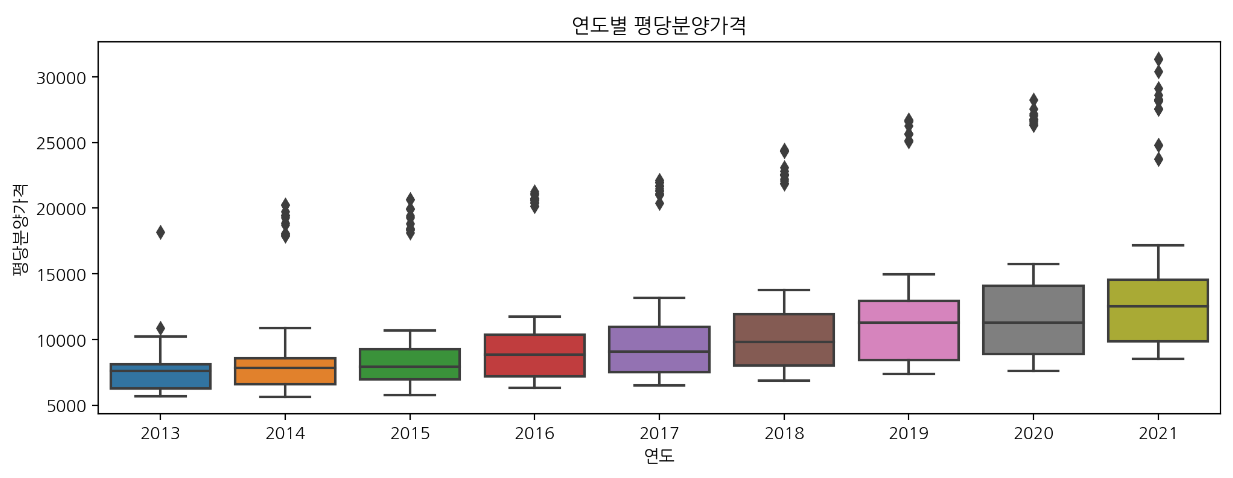
🔹 violin plot
: 분포 표기
plt.figure(figsize=(12, 4))
sns.violinplot(data=df, x="연도", y="평당분양가격").set_title("연도별 평당분양가격");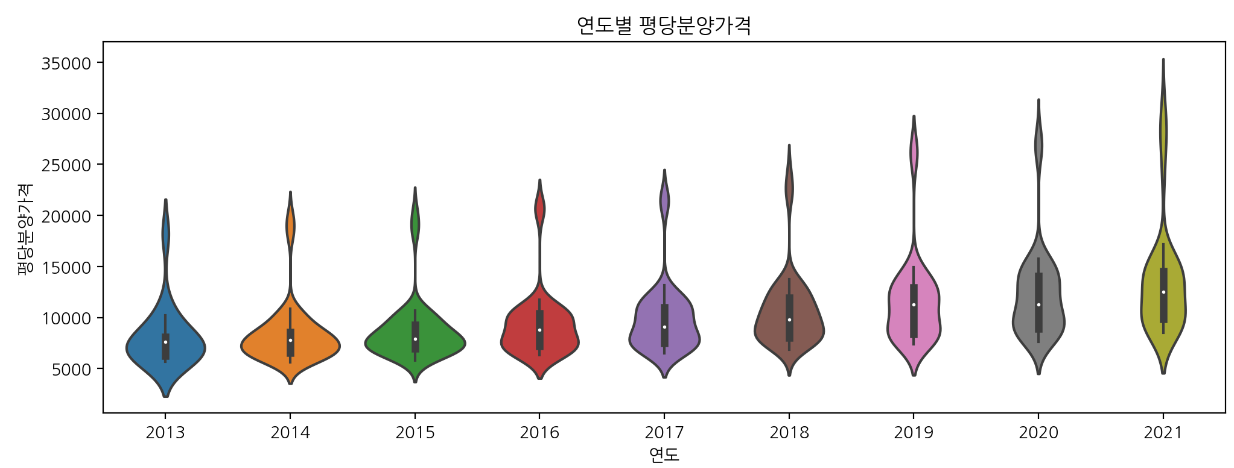
🔹 swarm plot
: 관측값을 그대로 표기
plt.figure(figsize=(16, 8))
sns.swarmplot(data=df.reset_index(drop=True), x="연도", y="평당분양가격", size=3).set_title("연도별 평당분양가격");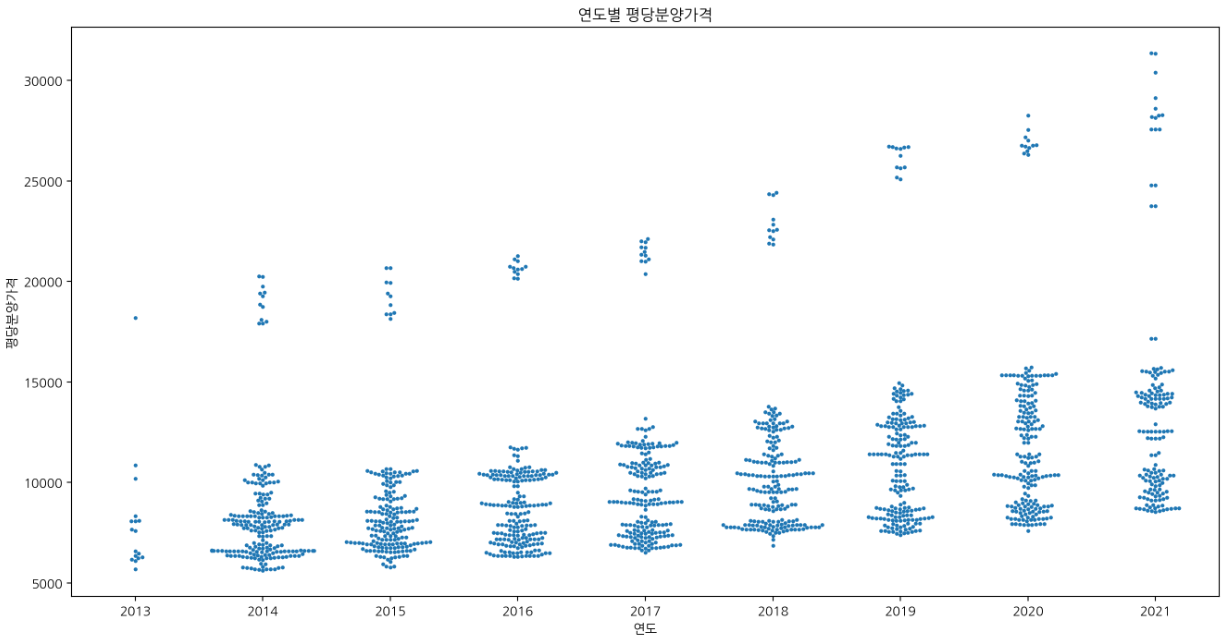
❗이것만은 외우고 자자 Top 3
📌 Tidy data : 각 변수가 "열"이고 각 관측치가 "행"이 되도록 배열된 데이터
📌 replace와 str.replace의 차이
- replace : 데이터프레임에만 사용가능(regex=True 를 지정하지 않으면 완전히 일치하는 데이터에 대해서만 변경)
- str.replace : 시리즈에만 사용가능, 일부만 일치해도 변경 가능
📌 seaborn에서 신뢰구간 막대 안보이게 하는 법 : errorbar=None
🌟데일리 피드백
1. 오늘의 칭찬&반성
칭찬 : 매우 피곤하지만 끝까지 오늘 복습을 한 것. 무사히 EDA 미니플젝 발표를 마친 것.
반성 : 스스로 건강에 대해 안일하게 생각한 것. 아프면 병원가라 세연아!
2. 내가 부족한 부분
원 데이터로 작업하지 말고 파생변수를 적절히 만들어 활용하자
3. 내일의 목표
7시 이전에 일어나서 seaborn 튜토리얼 1일차 시작하기
