iterrows() 함수
iterrows() 함수는 pandas 라이브러리에서 제공하는 DataFrame 객체의 메서드
이 함수는 DataFrame의 각 행을 반복하면서 인덱스와 행 데이터를 반환하는 편리한 방법을 제공한다.
iterrows() 함수를 사용하면 DataFrame의 각 행을 반복하면서 해당 행의 인덱스와 행 데이터를 받을 수 있다.
각 반복에서 반환되는 값은 (index, Series)의 튜플 형태
여기서 index는 행의 인덱스이고, Series는 해당 행의 데이터를 포함하는 Series 객체
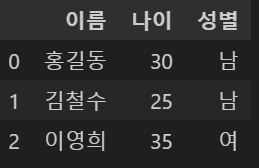
import pandas as pd
# 예제 DataFrame 생성
data = {'이름': ['홍길동', '김철수', '이영희'],
'나이': [30, 25, 35],
'성별': ['남', '남', '여']}
df = pd.DataFrame(data)
# iterrows() 함수를 사용하여 각 행 반복하기
for index, row in df.iterrows():
print(f"인덱스: {index}")
print(f"이름: {row['이름']}, 나이: {row['나이']}, 성별: {row['성별']}")
print("---")위의 예제에서 iterrows() 함수를 사용하여 DataFrame의 각 행을 반복하고, 각 행의 인덱스와 데이터를 출력한다.
결과 :
인덱스: 0
이름: 홍길동, 나이: 30, 성별: 남
---
인덱스: 1
이름: 김철수, 나이: 25, 성별: 남
---
인덱스: 2
이름: 이영희, 나이: 35, 성별: 여
---iterrows() 함수는 반복문을 사용하여 DataFrame의 각 행을 처리해야 할 때 유용하다. 그러나 대량의 데이터를 처리할 때는 성능상의 이유로 다른방법을 생각해 볼 필요가 있다!

keep going