RAG From Scratch : Part 1 to 4
[Part 1] Overview
- RAG의 주요 동기는 LLM이 내가 관심있는 데이터를 보지 못했다는 점에 있다.
- 개인의 데이터나 최근의 데이터는 LLM이 사전 학습하지 못했기 때문에 원하는 답변을 얻지 못할 가능성이 크다.
- LLM이 입력으로 받을 수 있는 context window의 크기, 즉 토큰(token)의 수는 점점 증가하고 있다.
- 외부 데이터와 LLM을 연결하는 방법 중 하나가 바로
RAG(Retrieval Augmented Generation)이다.
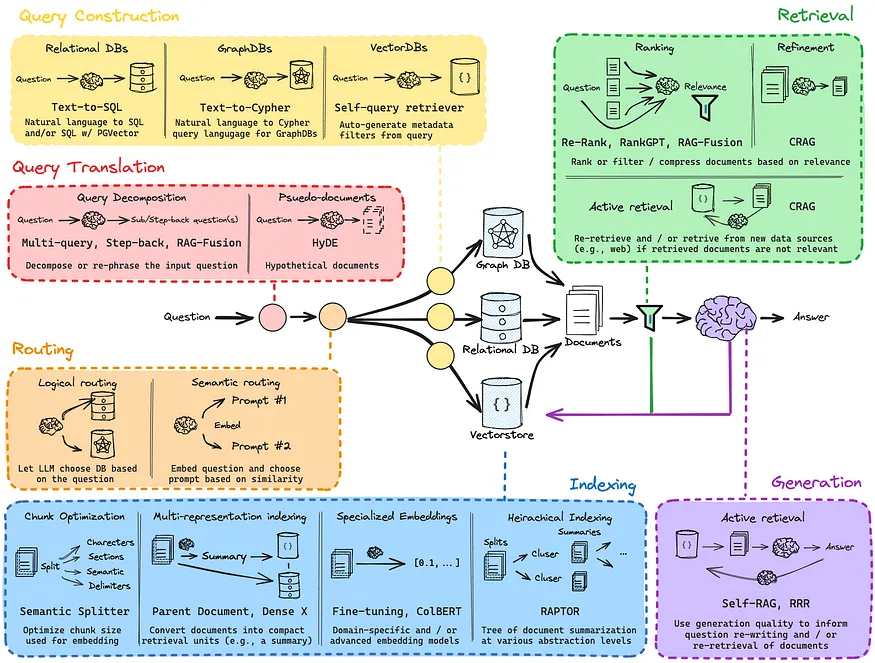
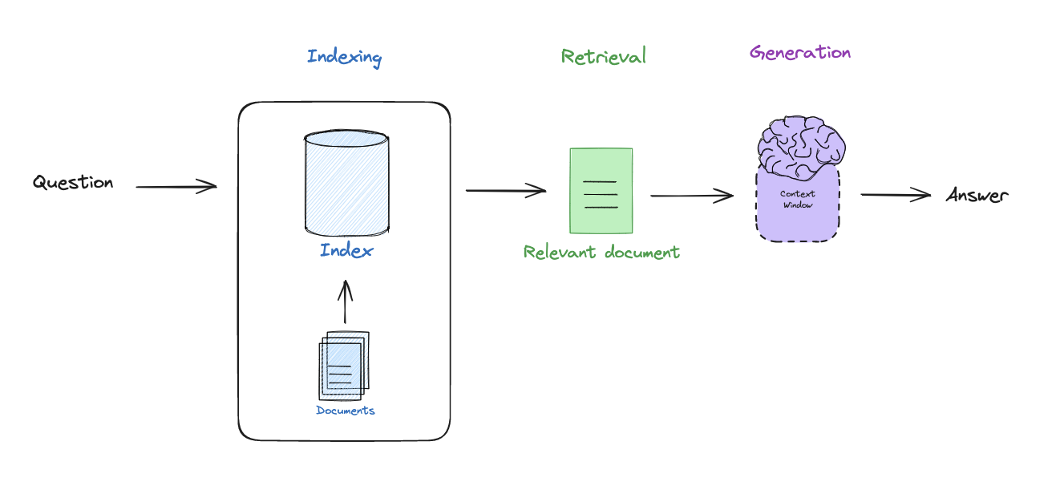
- RAG은 일반적으로 3가지 단계로 나뉜다.
Indexing : input query에 따라 쉽게 retrieval할 수 있도록 외부 document를 indexing하는 단계이다.Retrieval : input query와 관련된 indexing을 retrieval하는 단계이다.Generation : retrieval된 문서에 기반하여 input query와 관련된 답변을 생성하는 단계이다.
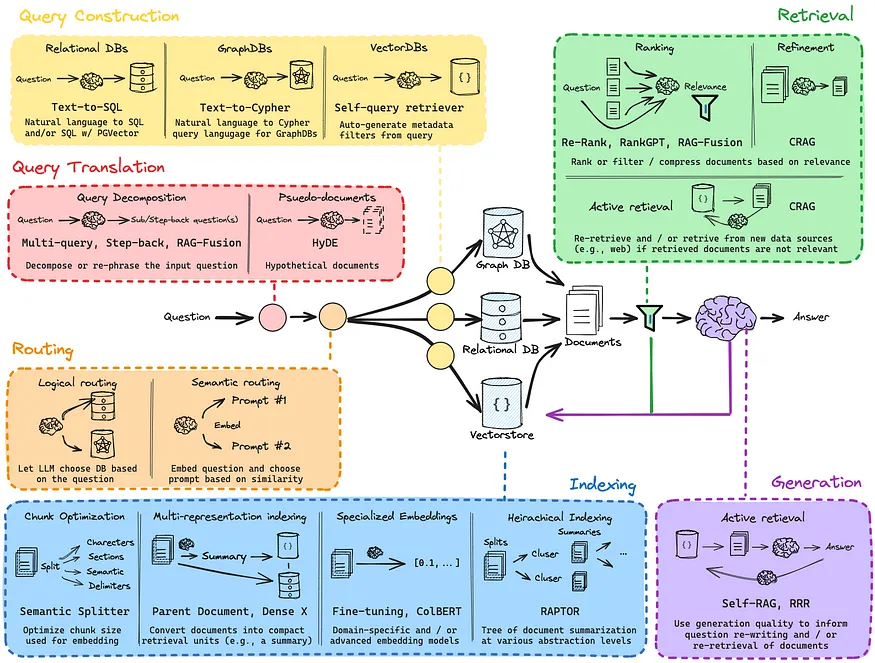
- 각 단계에는 여러 접근 방법이 존재한다.
Langchian을 사용하여 RAG을 구현하는 것이 가능하며, RAG 파이프라인을 구축할 때 tracing을 하기 위한 용도로 LangSmith를 사용한다.
[Part 2] Indexing
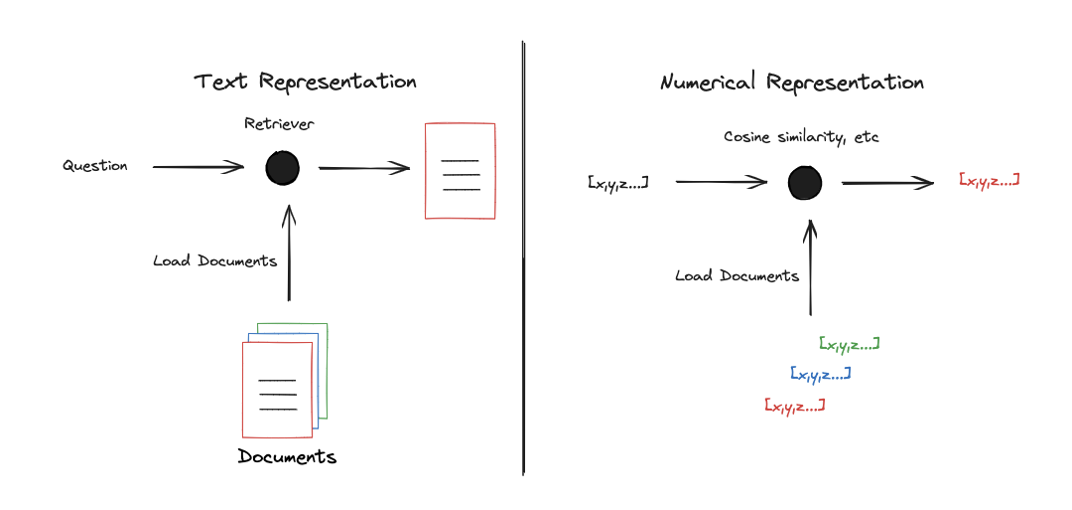
Retriever의 역할은 input query와 관련된 document를 찾는 것이다.- 관련된 document를 찾는 일반적인 방법은 수학적 방법(cosine similarity 등)을 이용하는 것이다.
- 수학적 방법을 통해서 관련된 document를 찾기 위해서는 문서를 벡터로 표현해야 한다.
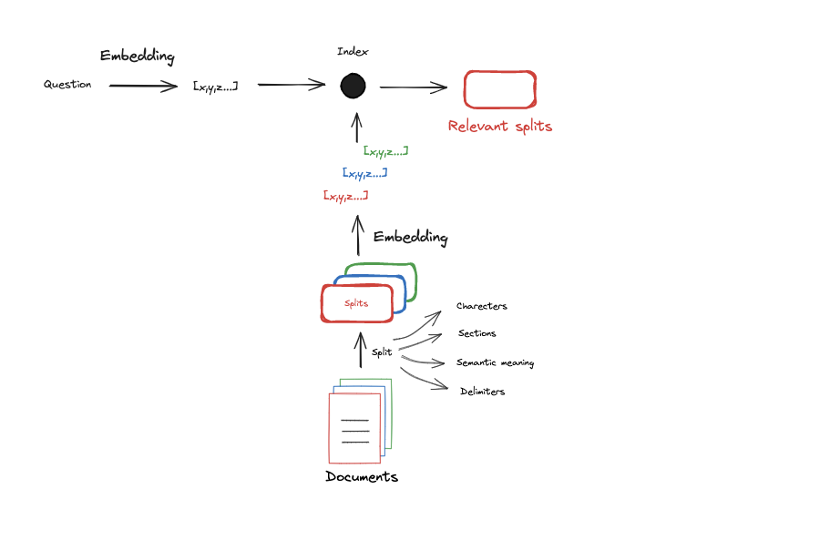
chunking : 문서를 작은 단위로 분리하는 작업을 말하며, 분리된 각각을 chunk라고 부른다.- embedding model은 제한된 context window(=max_tokens)를 가지기 때문에
chunking을 진행하는 것이며 embdding model을 통해 각 chunk를 embed하여 embedding vector를 얻는다.
- input query에 대해서도 동일한 embdding model을 적용하여 embedding vector를 얻고 input query의 embedding vector와 유사한 chunk의 embedding vector를 top_k개 찾아 최종적으로
Retrieval 단계에 활용한다.
- 일반적으로 embedding model과 LLM은 token을 기반으로 동작하기 때문에 입력하고자 하는 문서의 크기를 이해하는 것이 좋다.
[Part 3] Retrieval
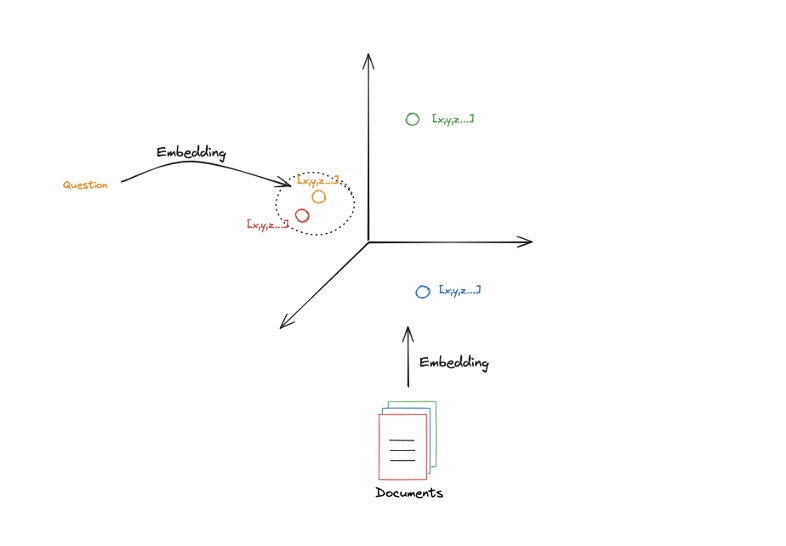
- embedding vector가 3차원이라고 한다면 여러 문서는 3차원 공간의 특정 지점에 투영되며, 해당 공간에서의 embedding vector의 위치는 그 문서의 의미나 내용에 의해 결정된다.
- 따라서 해당 공간에서 인접한 위치에 있는 embedding vector들은 비슷한 의미 정보를 포함하고 있다.
- 동일한 embedding model을 통해 input query도 같은 공간 상에 표현되며 이를 통해 비슷한 의미 정보를 담고 있는 문서를 탐색할 수 있다.
- 이것이
Vectorstore에서 볼 수 있는 많은 검색 방법의 초석이 된다.
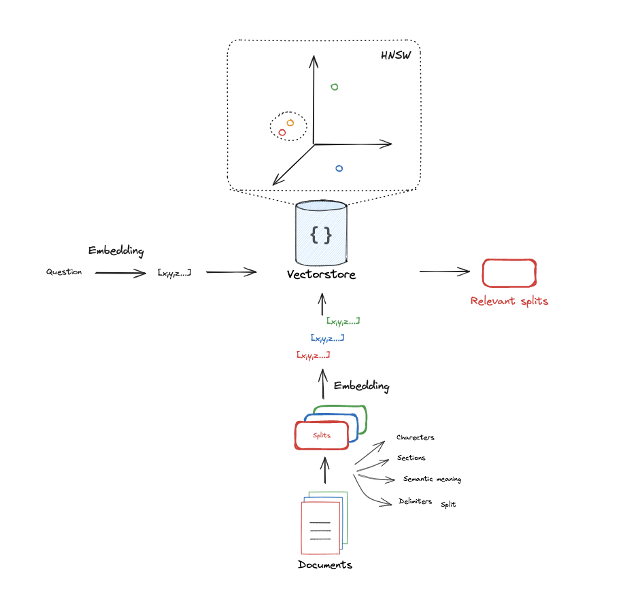
- 문서를 chunking하고 각각의 chunk에 대해 embedding하는 과정을 거치면 각각은 특정 공간 상에 존재하게 된다.
- input query에 대해서도 embdding 과정을 거쳐 같은 공간에 투영한다.
- input query에 대한 embedding vector 인근에 있는 top_k개의 문서를 선택한다.
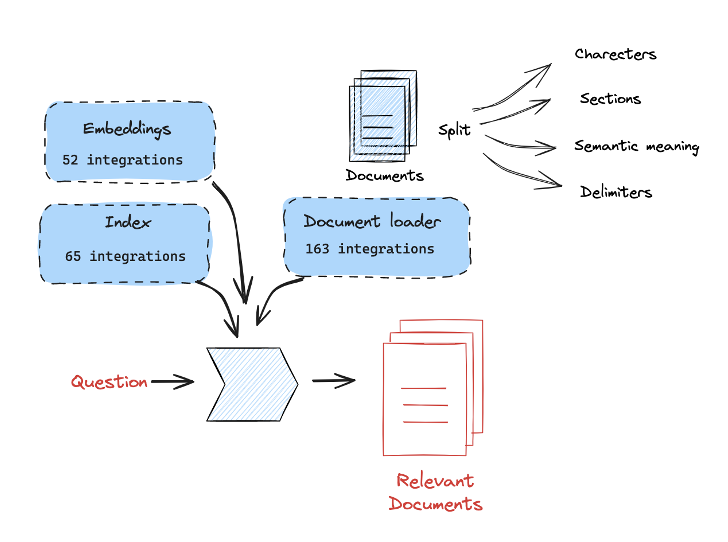
Langchain에서는 RAG과 관련된 다양한 기능을 제공하기 때문에 전반적인 과정을 손쉽게 구현할 수 있다.
Embedding modelDocumentLoaderIndexSplitter
[Part 4] Generation
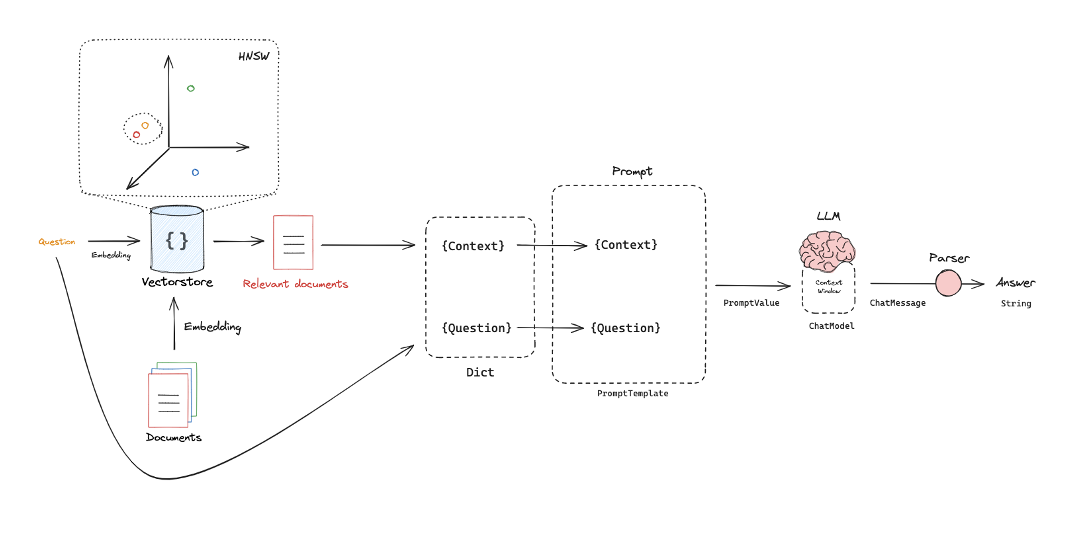
Retrieval 단계에서 검색한 top_k개의 문서(혹은 chunk)를 input query와 함께 context window에 넣어 LLM으로부터 답변을 생성한다.PromptTemplate의 형태로 된 prompt에 input query와 retreve된 chuk들을 넣어 ChatModel과 같은 LLM에 입력하면 그 결과로 ChatMessage가 나오며 그것을 분석하여 답변을 얻을 수 있다.