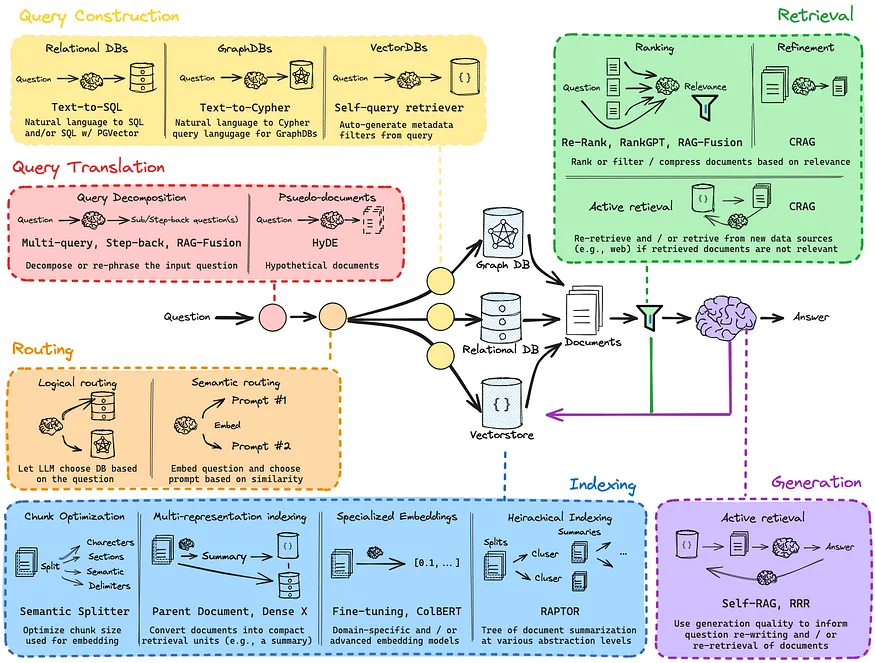
[Part 5] Multi-Query
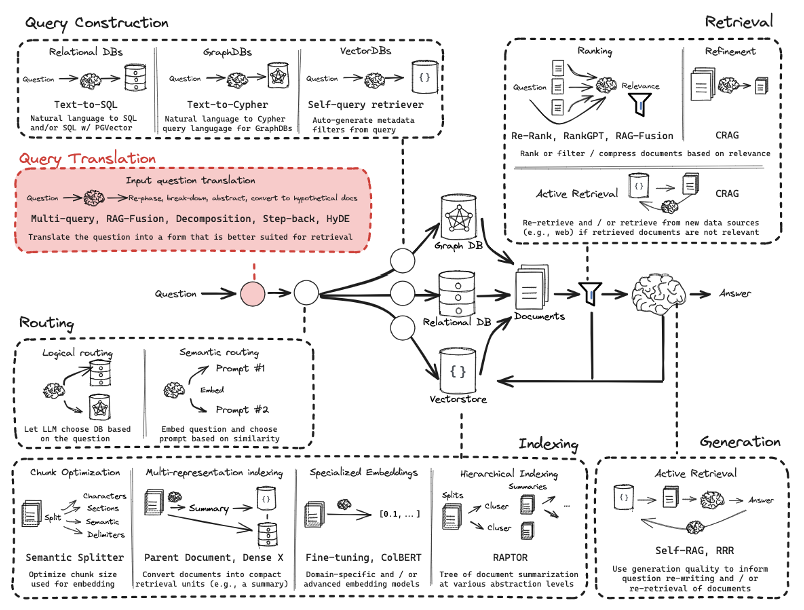
Query Translation은 input query가 모호할 수 있기 때문에 다양한 각도에서 의도를 파악하여 각각 관련된 정보를 탐색하는 방법이다.- input query가 모호하다면 그에 매칭되는 정보나 문서 역시 모호할 가능성이 크기 때문에 input query에 대해서 다방면으로 바라볼 필요가 있다.
- input query와 document 사이의 의미적 유사성을 기반으로 검색이 이루어지기 때문에 input query가 제대로 쓰이지 않을 경우에는
Index에서 적절한 문서를 검색하지 못할 것이다.
- 입력된 query를 가져와서
Retrieval의 성능을 향상시키고자 하는 목적이 있다.
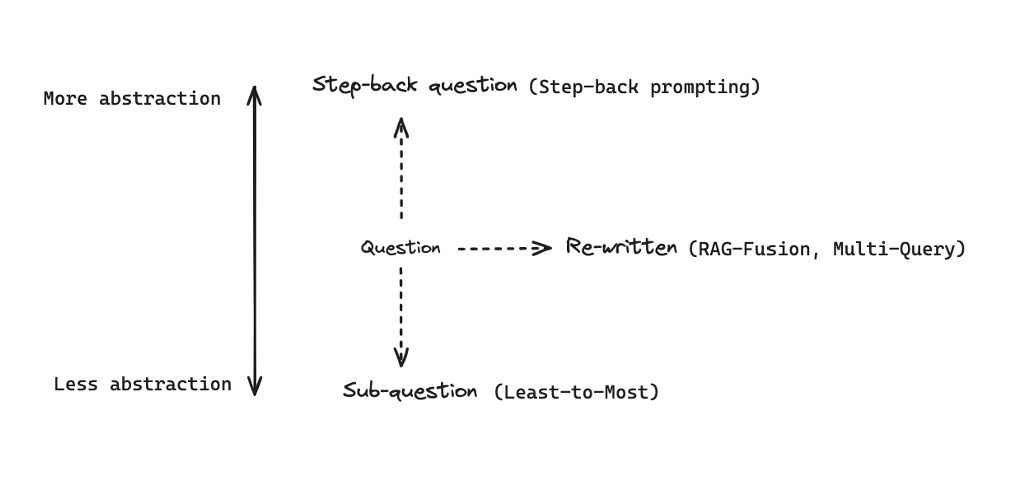
- query를 변형하는 일반적인 접근에는 query를 덜 추상적으로 만드는 Google의
Least-to-Most 방법이 있으며, 더 추상적으로 만드는 Step-back prompting 방법 등이 있다.
- 그 외에 query를 다시 작성하는
RAG-Fusion, Multi-Query등의 방법도 존재한다.
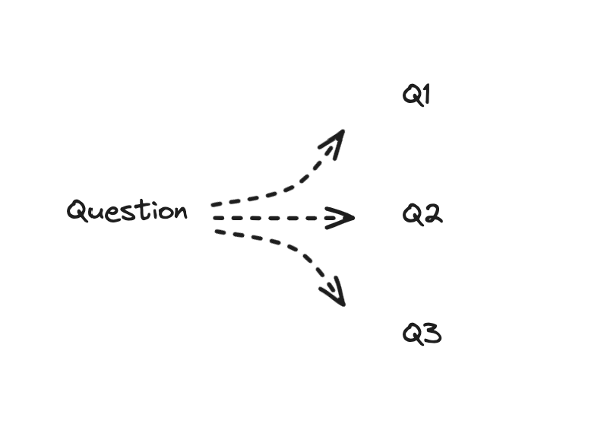
Multi-Query에서는 하나의 query에 대해 여러 관점에서 다른 단어로 표현된 몇 가지 질문으로 나누는 작업이 이루어진다.
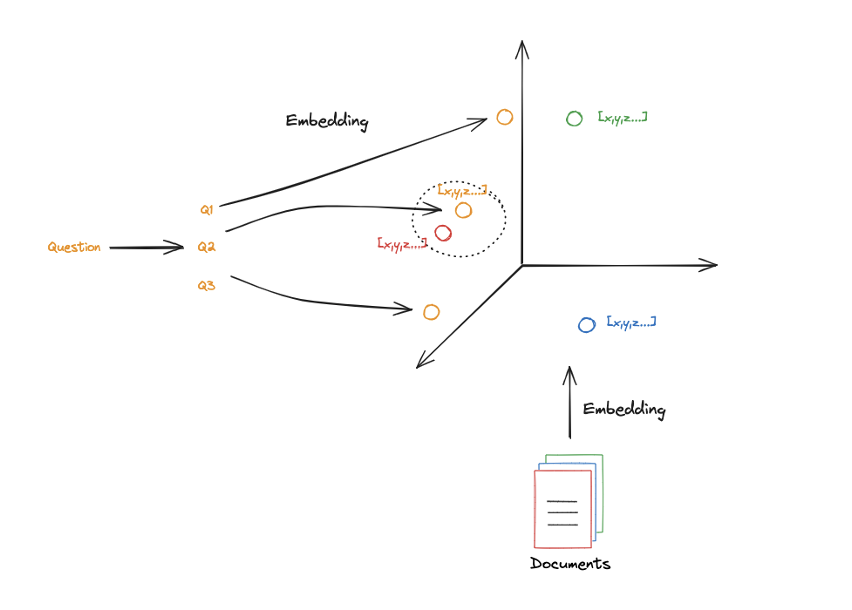
- 초기 query(그림에서의
Question)이 vector space에 embedding되고 난 후에는 제대로 정렬되지 않거나 검색하고자 하는 문서와 유사하지 않을 가능성이 존재한다.
- 초기 query를 다시 써서(
Re-Written) 여러 query(Q1, Q2, Q3, ...)를 사용한다면 원하는 문서를 검색할 확률이 높아진다.
- 해당 접근 방식은 query를 몇 가지 다른 관점으로 분산하여 검색의 신뢰성을 향상시킬 수 있다.
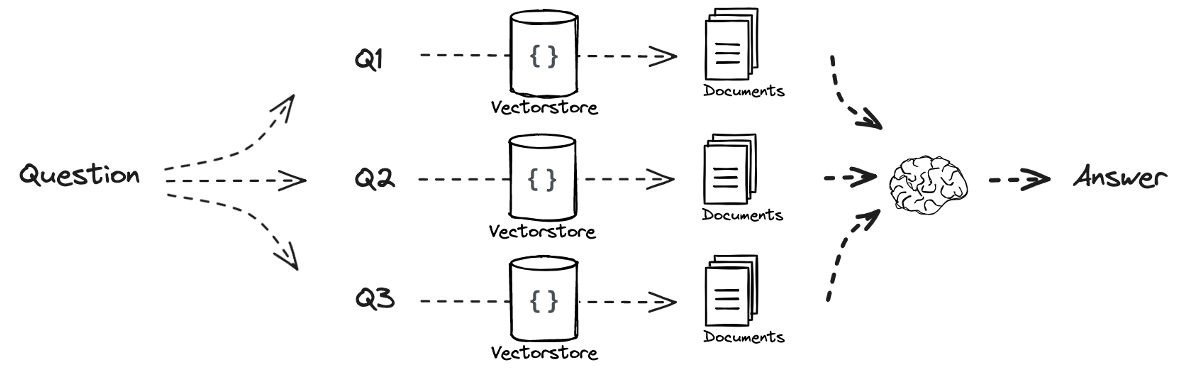
Multi-Query와 Retrieval을 결합하면 하나의 query를 여러 query로 분산하고 각 query에 대해서 유사한 문서를 검색하여 이를 결합하여 답을 생성할 수 있다.Mutli-Query 작업 역시 LLM 통해 이루어진다
from langchain.prompts import ChatPromptTemplate
template = """You are an AI language model assistant. Your task is to generate five
different versions of the given user question to retrieve relevant documents from a vector
database. By generating multiple perspectives on the user question, your goal is to help
the user overcome some of the limitations of the distance-based similarity search.
Provide these alternative questions separated by newlines. Original question: {question}"""
prompt_perspectives = ChatPromptTemplate.from_template(template)
Multi-Query 방식은 이후 등장하는 방법들과는 달리 각각의 질문에 대한 답변을 평행적으로 사용하기 때문에 각각의 답변은 서로 의존하지 않는다.
[Part 6] RAG-Fusion
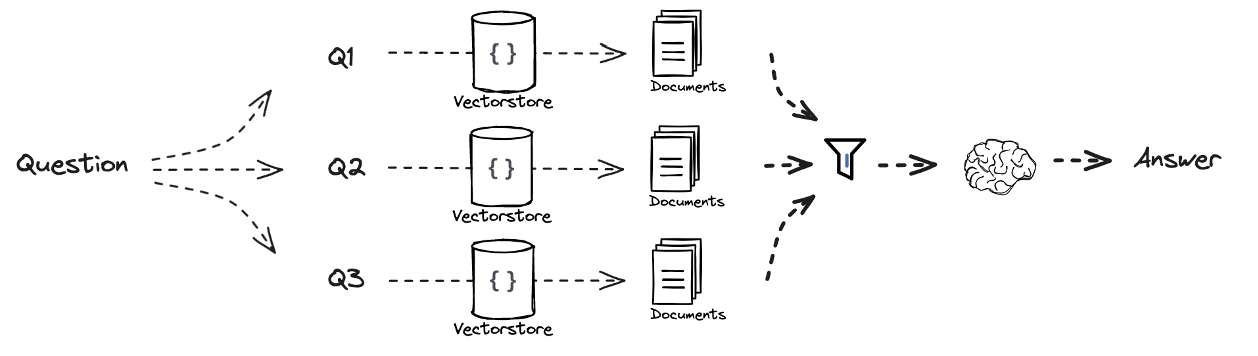
RAG-Fusion에서는 Multi-Query와 유사한 과정을 거치지만 검색된 문서들의 순위를 매긴다는 점에서 차이가 있다.RAG-Fusion에서도 LLM을 이용하여 여러 query로 생성하고 해당 query와 관련된 문서를 탐색한다.
from langchain.prompts import ChatPromptTemplate
template = """You are a helpful assistant that generates multiple search queries based on a single input query. \n
Generate multiple search queries related to: {question} \n
Output (4 queries):"""
prompt_rag_fusion = ChatPromptTemplate.from_template(template)
- 탐색한 문서들에 순위를 매기는 함수를 적용하여 최종적으로 문서별로 순위가 부여된다.
[Part 7] Decomposition
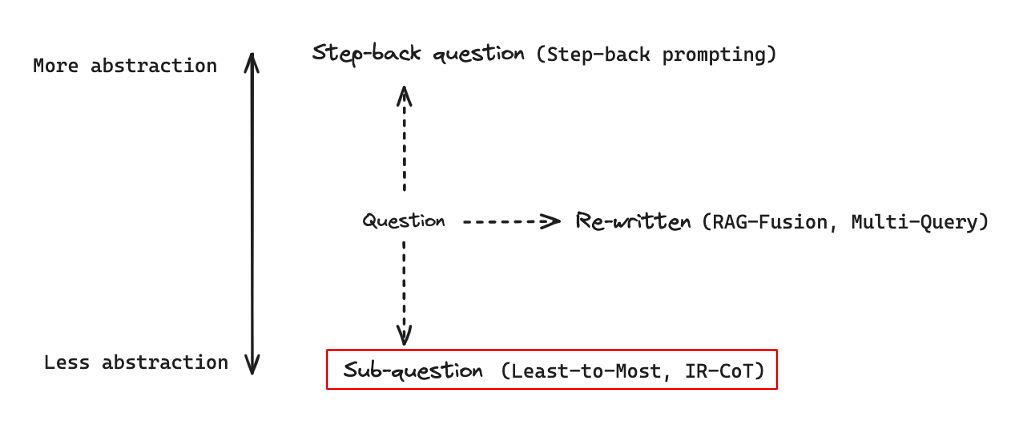
- query를 변형하는 방법에는 query를 부분 query로 나누거나 분해하는 방법도 있다.
- 대표적인 방법으로는
Least-to-Most, IR-CoT 등이 있다.

Least-to-Most 방법은 query를 입력받아 sub-query로 나누어 순서대로 해결한다.- 우선
think machine learning이라는 입력에 대해 마지막 단어의 마지막 글자를 합치는 작업을 하기 위해 think, think machine, think machine learning으로 나눈다.
- 이후 각 query에 대해서 개별적으로 답변을 생성한고 이를 결합하여 최종 답변을 생성한다.
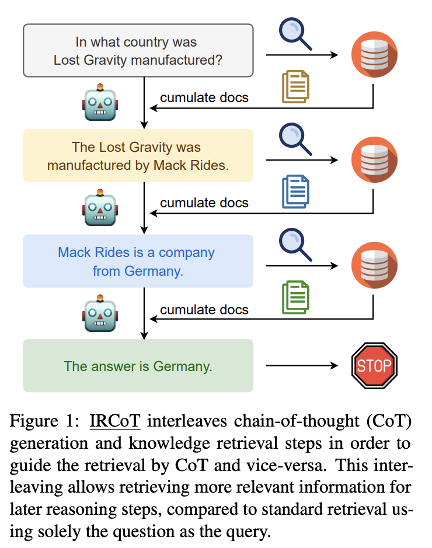
IR-CoT는 Retrieval과 Chain-of-Thought를 결합한 방법으로 연쇄적으로 Retrieval을 이용하여 나누어진 sub-query에 대해서 답변을 생성하고 이를 다시 이용하는 방식으로 최종 답변을 생성한다.
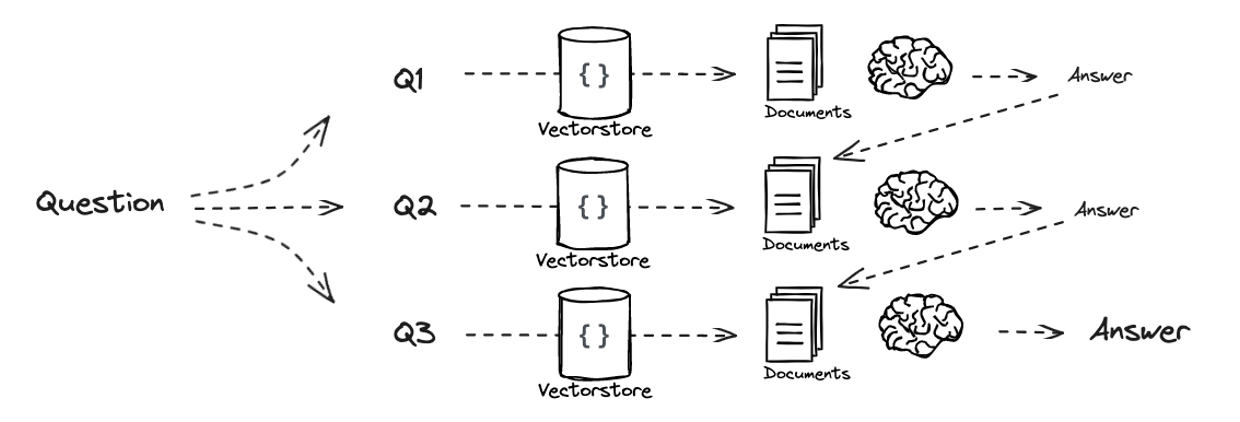
- 하나의 sub-query를 이용하여 답변을 생성하고, 생성된 답변을 이용하여 또 다른 sub-query에 대한 답변을 생성한다.
- input query를 기반으로 여러 sub-query를 만들기 위한 prompt를 작성한다.
from langchain.prompts import ChatPromptTemplate
template = """You are a helpful assistant that generates multiple sub-questions related to an input question. \n
The goal is to break down the input into a set of sub-problems / sub-questions that can be answers in isolation. \n
Generate multiple search queries related to: {question} \n
Output (3 queries):"""
prompt_decomposition = ChatPromptTemplate.from_template(template)
- prompt를 LLM에 입력하여 sub-query를 생성한다.
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
llm = ChatOpenAI(temperature=0)
generate_queries_decomposition = ( prompt_decomposition | llm | StrOutputParser() | (lambda x: x.split("\n")))
question = "What are the main components of an LLM-powered autonomous agent system?"
questions = generate_queries_decomposition.invoke({"question":question})
- 생성된 sub-query를 바탕으로 연쇄적으로 생성된 답변을 사용할 수 있도록 prompt를 작성한다.
template = """Here is the question you need to answer:
\n --- \n {question} \n --- \n
Here is any available background question + answer pairs:
\n --- \n {q_a_pairs} \n --- \n
Here is additional context relevant to the question:
\n --- \n {context} \n --- \n
Use the above context and any background question + answer pairs to answer the question: \n {question}
"""
decomposition_prompt = ChatPromptTemplate.from_template(template)
- 이전 query와 생성된 답변의 쌍이 지속적으로 prompt에 추가될 수 있도록 한다.
from operator import itemgetter
from langchain_core.output_parsers import StrOutputParser
def format_qa_pair(question, answer):
"""Format Q and A pair"""
formatted_string = ""
formatted_string += f"Question: {question}\nAnswer: {answer}\n\n"
return formatted_string.strip()
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
q_a_pairs = ""
for q in questions:
rag_chain = (
{"context": itemgetter("question") | retriever,
"question": itemgetter("question"),
"q_a_pairs": itemgetter("q_a_pairs")}
| decomposition_prompt
| llm
| StrOutputParser())
answer = rag_chain.invoke({"question":q,"q_a_pairs":q_a_pairs})
q_a_pair = format_qa_pair(q,answer)
q_a_pairs = q_a_pairs + "\n---\n"+ q_a_pair
[Part 8] Step-back
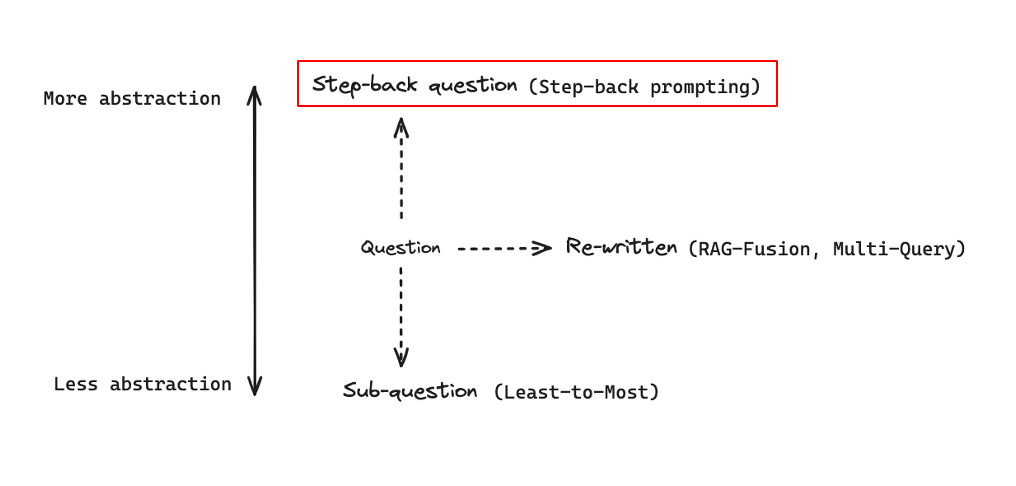
Step-back은 query를 더 추상화하는 방법으로 Least-to-Most와 마찬가지로 구글에 의해 제안되었다.
Step-back에서는 few-shot prompting을 통해서 기존 query로부터 더 추상적인 query를 생성한다.- 예를 들어, 한 사람의 출생지를 묻는 구체적인 질문을 바탕으로 한 사람의 개인적 일대기를 묻는 추상적인 질문을 생성하도록
few-shot example을 넣고 <Original Quetion>에 해당하는 query를 넣어 해당 query로부터 추상적인 질문을 생성한다.
- 이후 기존 query와
Step-back query 각각에 대해서 관련된 문서를 검색하고 이를 결합하여 최종 답변을 생성한다.
[Part 9] HyDE

- RAG에서는 query를 embedding하고, document를 embedding한 후 query와 document 사이의 embedding을 이용하여 유사성을 판단한다.
- 하지만 query와 document는 매우 다른 텍스트 객체이다. document의 경우에는 chunk들로 이루어져있지만 query에 경우에는 단일 문장에 불과하다고 할 수 있다.
HyDE에서의 직관은 query를 포함하는 가상의 document를 이용하여 vector space에 mapping하는 것이다.
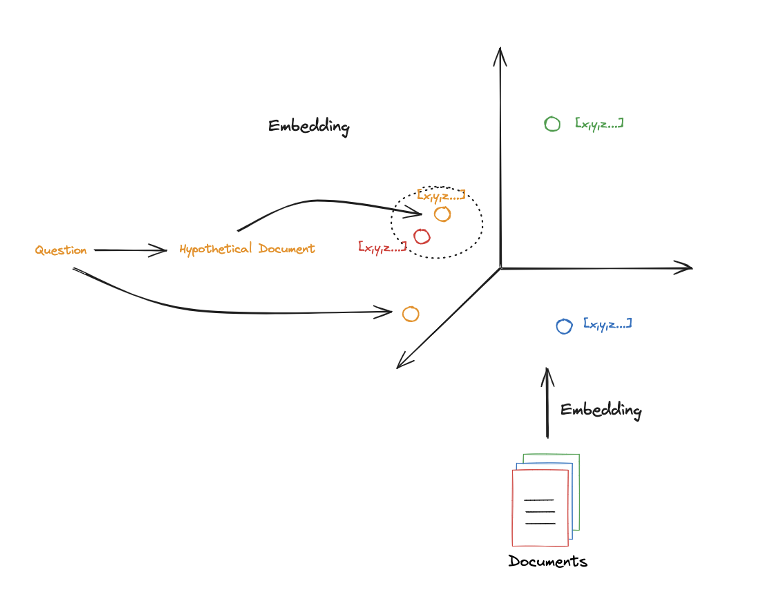
HyDE는 다시 말해서 query를 Hypothetical Document로 변환하고 이를 이용하여 Retrieval을 수행하는 방법이다.- query만을 이용하여
Retrieval을 수행했을 때보다 더 효과적인 문서 검색을 할 수 있다.
- query로부터 Hypothetical Document를 생성하는 prompt를 작성한다.
from langchain.prompts import ChatPromptTemplate
template = """Please write a scientific paper passage to answer the question
Question: {question}
Passage:"""
prompt_hyde = ChatPromptTemplate.from_template(template)
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
generate_docs_for_retrieval = (
prompt_hyde | ChatOpenAI(temperature=0) | StrOutputParser()
)
question = "What is task decomposition for LLM agents?"
generate_docs_for_retrieval.invoke({"question":question})
- Hypothetical Document와 괄년된 chunk들을
Retriever에서 가져온다.
retrieval_chain = generate_docs_for_retrieval | retriever
retireved_docs = retrieval_chain.invoke({"question":question})
retireved_docs
- chunk들을 이용하여 다시 기존 query에 대해
Retrieval을 수행한다.
template = """Answer the following question based on this context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
final_rag_chain = (
prompt
| llm
| StrOutputParser()
)
final_rag_chain.invoke({"context":retireved_docs,"question":question})