
선형 회귀(Linear Regression)
선형 회귀는 통계학과 머신러닝에서 가장 기본적이면서도 중요한 예측 기법 중 하나입니다.
간단히 말해, 선형 회귀는 데이터 포인트들 사이의 선형 관계를 찾아내는 모델입니다. 이 글에서는 선형 회귀의 기본 원리부터, 어떻게 작동하는지, 언제 사용되는지에 대해 상세히 다루어보겠습니다.
선형 회귀의 기본 원리
선형 회귀는 이름에서 알 수 있듯이 변수들 간의 선형 관계를 모델링합니다. 가장 간단한 형태인 단순 선형 회귀는 독립 변수(X) 하나와 종속 변수(Y) 하나의 관계를 아래의 선형 방정식으로 표현합니다.

선형 회귀 모델을 학습시키는 핵심은 최적의 W와 b 값을 찾아내는 것입니다. 이 값들은 모델이 실제 데이터를 가장 잘 설명하고 예측할 수 있는 선을 그리도록 합니다. 이 과정에서 "최소 제곱법"(Least Squares Method)이라는 기법이 널리 사용됩니다.
최소 제곱법은 실제 관측값과 모델에 의해 예측된 값 사이의 차이(잔차)의 제곱합을 최소화하는 W와 b를 찾아내는 방법입니다. 이 기법은 잔차의 제곱을 사용하기 때문에, 큰 오차를 더욱 강하게 처벌하여 모델의 정확도를 높입니다.
학습 단계는 다음과 같습니다.
1. 임의의 W와 b 값을 선택합니다.
2. 이 값들을 사용하여 모든 데이터 포인트에 대한 예측 값을 계산합니다.
3. 실제 값과 예측 값 사이의 잔차의 제곱합을 계산합니다.
4. 잔차의 제곱합을 최소화하는 (a)와 (b) 값을 찾습니다.
5. 이 최적의 값들을 사용하여 데이터를 가장 잘 설명하는 선형 모델을 얻습니다.
이러한 과정을 통해, 선형 회귀 모델은 데이터 사이의 기본적인 선형 관계를 파악하고, 새로운 데이터에 대한 예측을 가능하게 합니다. 이러한 모델은 경제학, 의학, 공학 등 다양한 분야에서 활용되어 왔으며, 머신러닝의 기초를 이루는 중요한 알고리즘 중 하나입니다.
선형 회귀의 주요 가정
선형 회귀 모델은 효과적으로 작동하기 위해 다음의 몇 가지 기본 가정이 필요합니다.
- 선형성: 독립 변수와 종속 변수 사이에는 선형 관계가 있어야 합니다.
- 독립성: 오차 항들은 서로 독립적이어야 합니다.
- 등분산성: 모든 독립 변수 값에 대해 오차 항의 분산이 일정해야 합니다.
- 정규성: 오차 항들은 정규 분포를 따라야 합니다.
선형 회귀의 응용
선형 회귀는 비교적 간단하지만 유용하며, 다양한 분야에서 활용됩니다. 예를 들어, 경제학에서는 소비자 지출과 소득의 관계를 분석하는 데 사용될 수 있고, 의학에서는 특정 질병의 위험 요소를 평가하는 데 사용될 수 있습니다. 또한, 마케팅에서는 광고 지출과 판매량 사이의 관계를 분석하는 데 활용될 수 있습니다.
CNN(Convolutional Neural Networks): 이미지 인식의 혁신
컴퓨터 비전 분야에서 이미지 인식은 머신러닝과 딥러닝 기술을 활용하여 컴퓨터가 사진이나 비디오에서 객체를 식별하고 분류하는 과정입니다. 이 분야에서 혁명적인 발전을 이룬 기술 중 하나가 바로 CNN(Convolutional Neural Networks, 합성곱 신경망)입니다. 이 글에서는 CNN의 기본 원리와 구조, 그리고 다양한 응용 분야에 대해 자세히 살펴보겠습니다.
CNN의 원리
CNN은 이미지 처리에 특화된 딥러닝 모델의 한 종류로, 이미지의 특징을 자동으로 추출하고 이를 기반으로 이미지를 분류합니다. 기존의 신경망과는 다르게, CNN은 이미지의 공간 정보를 유지하면서 학습이 가능하도록 설계되었습니다. 이는 CNN이 이미지 내의 작은 부분(패치)에 집중하여 패턴을 인식할 수 있게 해줍니다.
CNN의 주요 구성 요소
- 합성곱 계층(Convolutional Layer): 이 계층은 이미지에서 특징을 추출하는 역할을 합니다. 여러 개의 필터(커널)를 사용하여 이미지를 스캔하고, 각 필터가 이미지의 특정 특징을 활성화시키는 방식으로 작동합니다.
- 활성화 함수(Activation Function): 대부분의 CNN에서는 ReLU(Rectified Linear Unit) 활성화 함수가 사용됩니다. 이 함수는 비선형성을 도입하여 네트워크가 복잡한 패턴을 학습할 수 있게 도와줍니다.
- 풀링 계층(Pooling Layer): 풀링 계층은 이미지의 차원을 축소하여 계산량을 줄이는 동시에 중요한 정보를 유지합니다. 가장 흔히 사용되는 방법은 맥스 풀링(Max Pooling)으로, 지정된 영역 내에서 가장 큰 값을 선택하는 방식입니다.
- 완전 연결 계층(Fully Connected Layer): 이 계층은 합성곱 계층과 풀링 계층을 거친 후의 정보를 바탕으로 최종 분류를 수행합니다. 이미지가 속할 클래스에 대한 확률을 출력하기 위해 사용됩니다.
CNN의 응용 분야
- 객체 인식(Object Detection): 이미지 내의 다양한 객체를 식별하고 위치를 파악합니다.
- 얼굴 인식(Face Recognition): 얼굴의 특징을 학습하여 개인을 식별합니다.
- 자율 주행(Autonomous Driving): 도로의 상황을 인식하고 이해하여 자동차가 스스로 주행할 수 있도록 합니다.
- 의료 이미징(Medical Imaging): X-레이, MRI 등의 의료 이미지를 분석하여 질병을 진단합니다.
CNN은 이미지 인식과 처리 분야에서 중요한 돌파구를 제시하였으며, 계속해서 발전하고 있는 기술입니다. 그 능력을 넘어, CNN은 머신러닝과 인공지능의 미래를 형성하는 데 중요한 역할을 하고 있으며, 앞으로도 그 가치와 가능성은 계속해서 확장될 것입니다.
전이학습

전이 학습은 사람이 배운 지식을 다른 문제나 상황에 적용하는 학습 방식에서 영감을 받았습니다. 구체적으로, 이미 특정 작업을 수행하기 위해 학습된 모델을 기반으로 새로운 모델을 훈련시키는 과정을 말합니다. 이 때, 기존 모델의 지식을 새 모델에 '전이'하여 학습 과정을 가속화하고, 데이터가 부족한 상황에서도 모델의 성능을 개선할 수 있습니다.
비글을 한 번 해보겠습니다.
import sys
import numpy as np
import cv2
filename = 'data/beagle.jpg'
img = cv2.imread(filename)
if img is None:
print('Image load failed!')
exit()
# Load network
net = cv2.dnn.readNet('data/bvlc_googlenet.caffemodel', 'data/deploy.prototxt')
if net.empty():
print('Network load failed!')
exit()
# Load class names
classNames = None
with open('data/classification_classes_ILSVRC2012.txt', 'rt') as f:
classNames = f.read().rstrip('\n').split('\n')
# Inference
inputBlob = cv2.dnn.blobFromImage(img, 1, (224, 224), (104, 117, 123))
net.setInput(inputBlob)
prob = net.forward()
# Check results & Display
out = prob.flatten()
classId = np.argmax(out)
confidence = out[classId]
text = '%s (%4.2f%%)' % (classNames[classId], confidence * 100)
cv2.putText(img, text, (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 0, 255), 1, cv2.LINE_AA)
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
cv2.waitKey(1)
cv2.waitKey(1)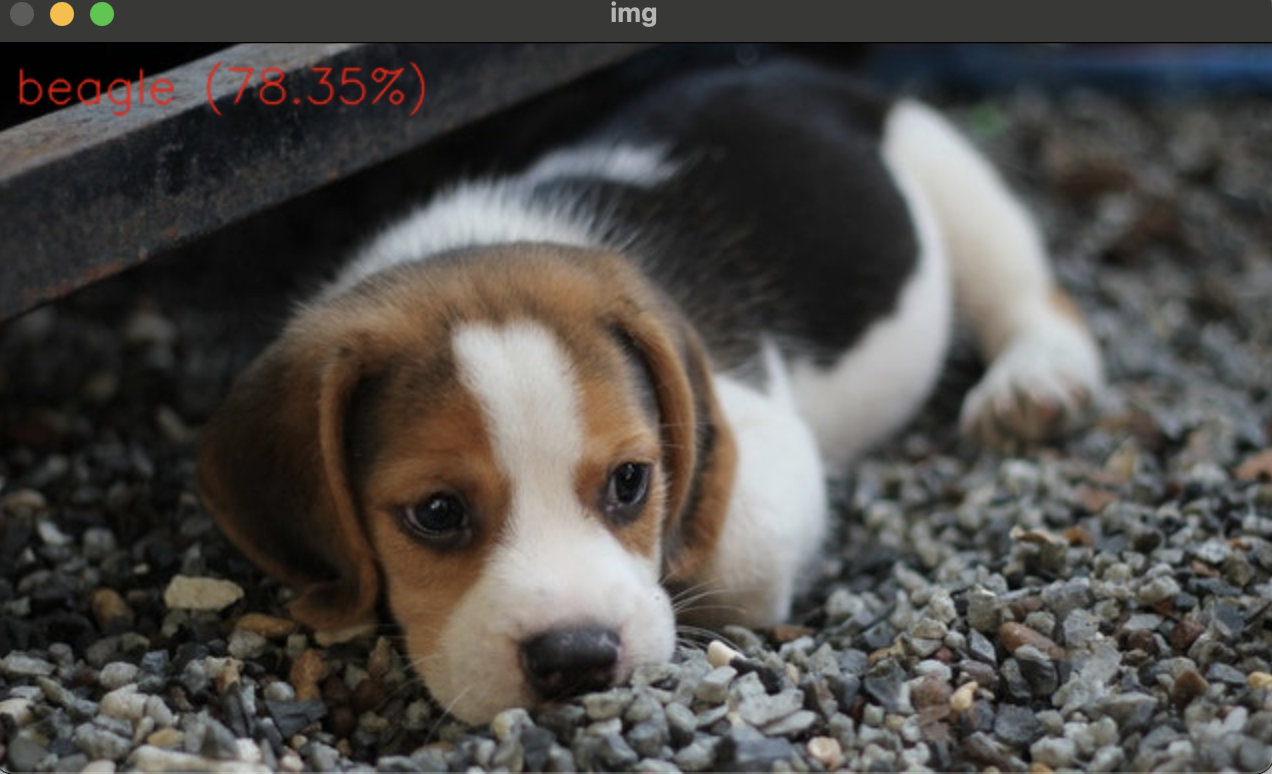
MediaPipe
미디어파이프는 구글에서 주로 인체를 대상으로하는 비전인식기능들을 AI모델 개발과 기계학습까지 마친 상태로 제공하는 서비스입니다.
이걸 이용해 욕 제스쳐하면 모자이크 처리하는 프로그램을 만들어 봅시다.
import cv2
import mediapipe as mp
# mediapipe에서 손 감지 모델을 불러옵니다.
mp_hands = mp.solutions.hands
# 손 감지 모델을 초기화합니다. 최대 손 개수를 1로 설정합니다.
hands = mp_hands.Hands(static_image_mode=False, max_num_hands=1)
# 모자이크 함수
def mosaic(img, x, y, w, h, size=30):
# 이미지를 모자이크 처리합니다.
for i in range(int(w / size)):
for j in range(int(h / size)):
xi = x + i * size
yi = y + j * size
# 모자이크 영역을 블러 처리합니다.
img[yi:yi + size, xi:xi + size] = cv2.blur(img[yi:yi + size, xi:xi + size], (23, 23))
cap = cv2.VideoCapture(0)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
continue
frame = cv2.flip(frame, 1)
rgb_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# 손 감지 모델을 통해 손을 감지합니다.
results = hands.process(rgb_frame)
# 손이 감지된 경우
if results.multi_hand_landmarks:
for hand_landmarks in results.multi_hand_landmarks:
# 중지 손가락 끝의 y 좌표와 중지 손가락 끝의 y 좌표를 추출합니다.
index_finger_tip_y = hand_landmarks.landmark[mp_hands.HandLandmark.INDEX_FINGER_TIP].y * frame.shape[0]
middle_finger_tip_y = hand_landmarks.landmark[mp_hands.HandLandmark.MIDDLE_FINGER_TIP].y * frame.shape[0]
# 중지 손가락 끝의 y 좌표가 중지 손가락 끝의 y 좌표보다 큰 경우
if index_finger_tip_y > middle_finger_tip_y:
# 모자이크를 적용할 영역의 좌상단과 우하단 좌표를 계산합니다.
x_min, y_min = int(min(l.x * frame.shape[1] for l in hand_landmarks.landmark)), int(min(l.y * frame.shape[0] for l in hand_landmarks.landmark))
x_max, y_max = int(max(l.x * frame.shape[1] for l in hand_landmarks.landmark)), int(max(l.y * frame.shape[0] for l in hand_landmarks.landmark))
# 모자이크 함수를 호출하여 모자이크를 적용합니다.
mosaic(frame, x_min, y_min, x_max - x_min, y_max - y_min)
cv2.imshow('Fuck you Gesture Mosaic', frame)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()

잘 됩니다.
끝
