회귀분석 프로젝트
학교 과제인 회귀분석 프로젝트를 시작하도록 하겠습니다.
1회차
주제 선정
가장 먼저 주제를 찾아봐야겠죠?
뉴스를 좀 찾아봤습니다.
https://www.newneek.co/CvK5t6
위 기사를 보고 핫한 이슈인 국민연금을 선택했습니다.
국민연금 기금 적립 현황에 가장 큰 영향을 미치는 요인들을 바탕으로
미래의 국민연금 기금의 규모를 예측하고자 합니다.
2회차
작품 개요 작성
주제를 정했으니 작품 개요를 작성했습니다.
+서울갔다왔습니다.
데이터 수집
데이터를 찾아야 합니다.
인구・성장・이자・소득의 상대적 관계가 국민연금 기금에 미치는 영향에 대한 고찰(https://www.kihasa.re.kr/hswr/assets/pdf/79/journal-38-1-396.pdf)를 바탕으로 경제활동인구, 물가상승률, 가입자 수등이 국민연금에 영향을 끼친다는 것을 알았습니다.
시간이 부족해 경제활동인구와 물가상승률만 바탕으로 회귀분석을 했습니다.
구글에 검색하여 가장 먼저 나오는 데이터들을 다운로드 받았습니다.
국민연금공단 기금적립현황 - https://www.data.go.kr/data/15106891/fileData.do?recommendDataYn=Y
경제활동인구 - https://kosis.kr/search/search.do?query=%EA%B2%BD%EC%A0%9C%ED%99%9C%EB%8F%99%EC%B0%B8%EA%B0%80%EC%9C%A8
소비자물가상승률 - https://snapshot.bok.or.kr/dashboard/C6
국민연금 가입자 수 - https://www.nps.or.kr/jsppage/app/cms/view.jsp?seq=29369&cPage=1&cmsId=public_data&SK=&SW=&SK2=
회귀분석 시작
코드 작성
다양한 곳에서 데이터를 다운받았으니, 데이터 클렌징을 해야겠죠?
연도를 기준으로 다듬었습니다.
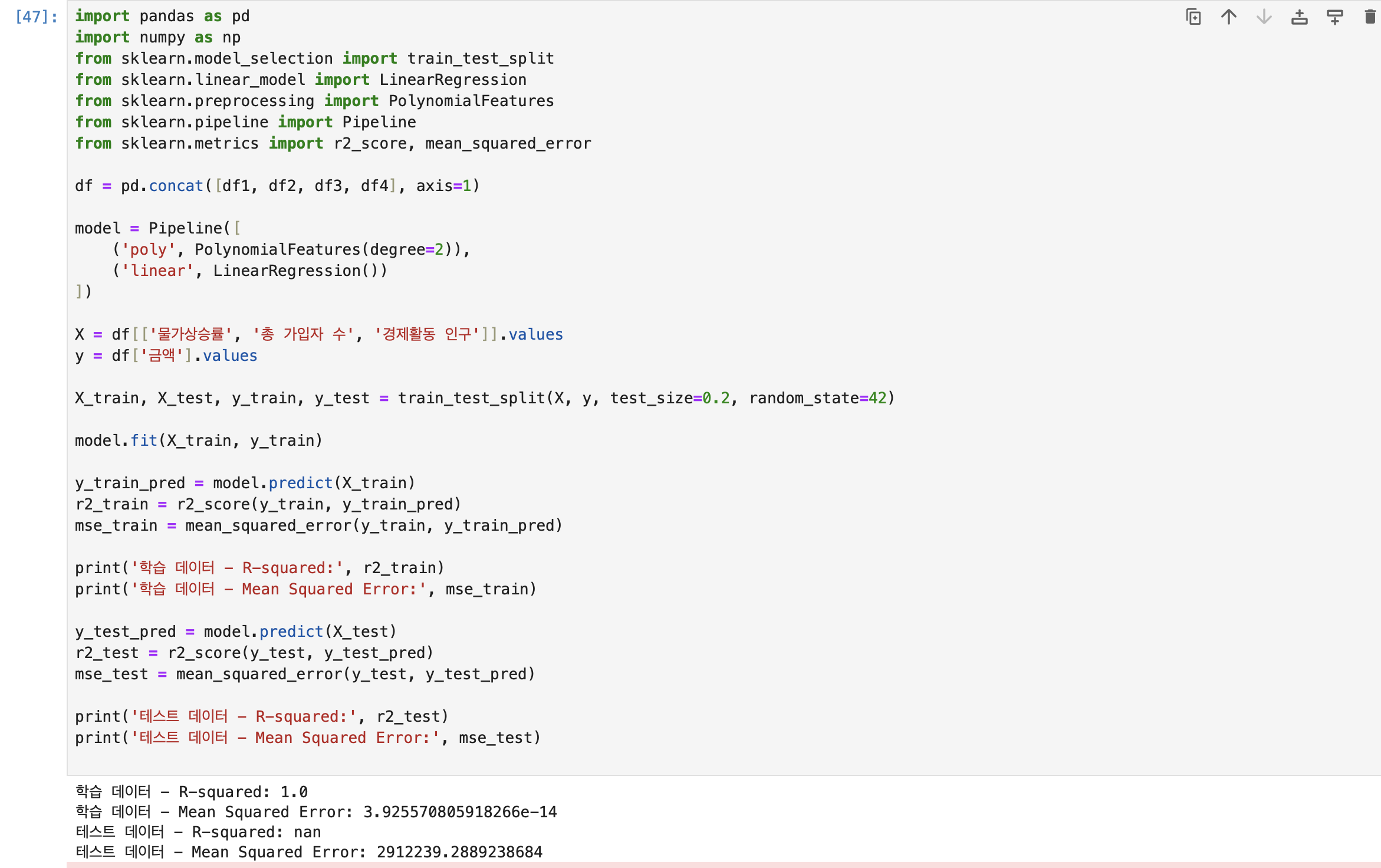
회귀분석 모델 학습
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import PolynomialFeatures
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
X = df[['물가상승률', '경제활동인구']]
Y = df['금액']
imputer = IterativeImputer()
X_imputed = imputer.fit_transform(X)
poly = PolynomialFeatures(degree=3)
X_poly = poly.fit_transform(X_imputed)
x_train, x_test, y_train, y_test = train_test_split(X_poly, Y, test_size=0.2, random_state=5)
lrmodel = LinearRegression()
lrmodel.fit(x_train, y_train)
predicted_y_train = lrmodel.predict(x_train)
mse_train = mean_squared_error(y_train, predicted_y_train)
r2_train = r2_score(y_train, predicted_y_train)
print("MSE on train data: %f" % mse_train)
print("train의 결정계수:%f" % r2_train)
predicted_y_test = lrmodel.predict(x_test)
mse_test = mean_squared_error(y_test, predicted_y_test)
r2_test = r2_score(y_test, predicted_y_test)
print("MSE on test data: %f" % mse_test)
print("test의 결정계수:%f" % r2_test)
실행 결과
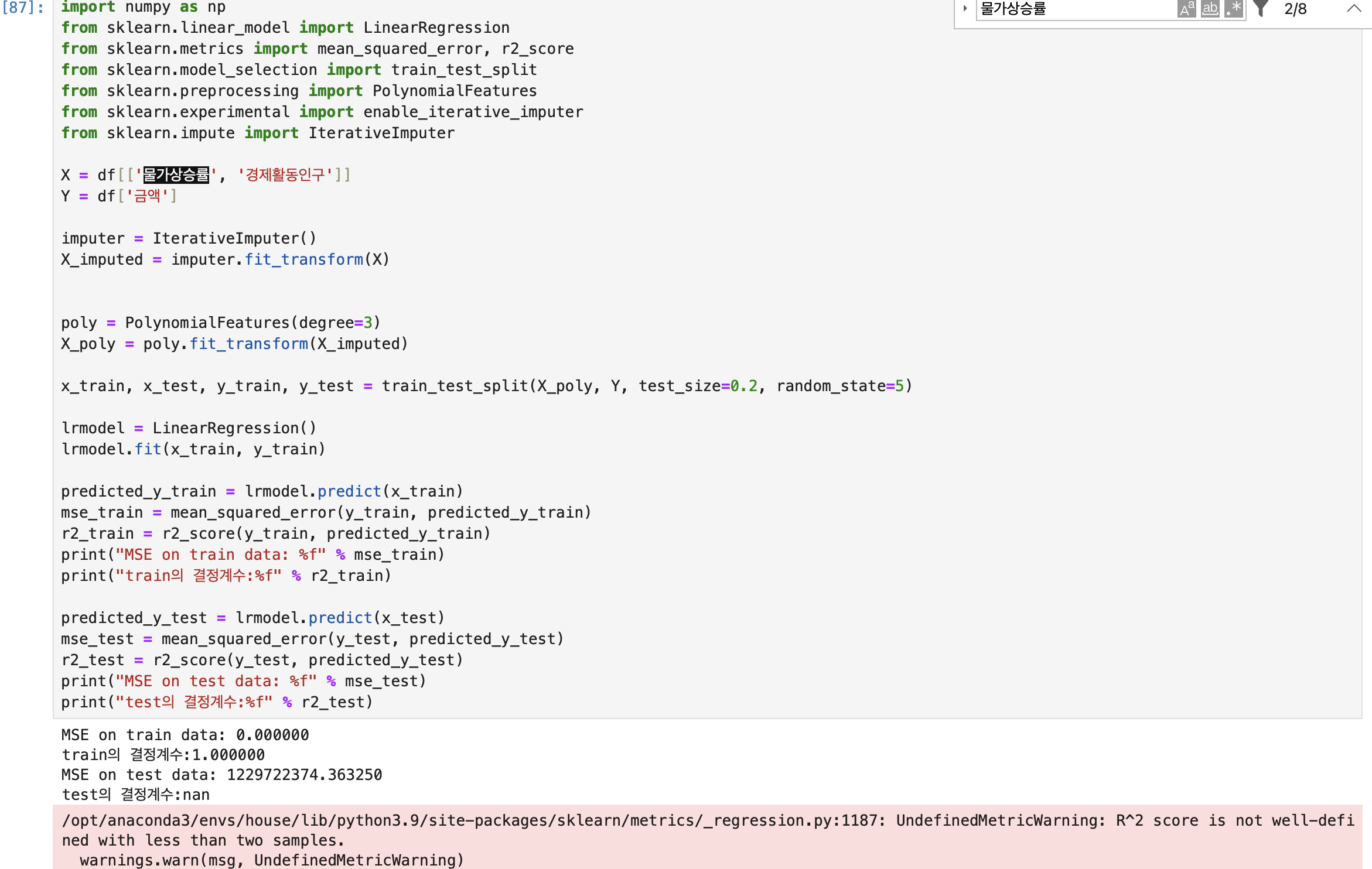
테스트 데이터 성능에서는
MSE가 1229722374.363250으로 매우 높고, 결정계수(R-squared)가 NaN(Not a Number)입니다. 이는 모델이 테스트 데이터에 대해 매우 좋지 않은 성능을 보인다는 것을 의미합니다. 즉, 모델이 훈련 데이터에 과도하게 적합되어 일반화 능력이 떨어지는 것으로 보입니다.
사실 결과는 그리 중요하지 않습니다.
테스트 데이터셋의 샘플 수가 2개 미만이고, 학습했다고 하기엔 데이터도 없기 때문입니다.
사용 코드
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import PolynomialFeatures
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
while True:
try:
물가상승률 = float(input("물가상승률을 입력하세요: "))
경제활동인구 = float(input("경제활동인구를 입력하세요: "))
break
except ValueError:
print("유효한 숫자를 입력하세요.")
new_data = pd.DataFrame({'물가상승률': [물가상승률], '경제활동인구': [경제활동인구]})
new_data_imputed = imputer.transform(new_data)
new_data_poly = poly.transform(new_data_imputed)
predicted_y_new = lrmodel.predict(new_data_poly)
print(f"입력한 데이터에 대한 예측 금액: {predicted_y_new[0]}")
실행 결과

데이터를 찾아 보기도 하고, 주제를 바꾸려는 생각도 했지만 시간이 부족해 그냥 했습니다. 연도별 기금적립 현황 데이터가 2019년~2024년, 5개밖에 없어서 이런 결과가 나왔습니다.
데이터를 먼저 찾고 주제를 정할 걸 그랬습니다.
