Pandas 기본 문법
pandas를 이용해 제목처럼 할 것이다. 제목처럼 하기 전에 기본 문법을 알아보자.
데이터프레임 만들기
import numpy as np
import pandas as pd
columns = ['축구', '맛집', '피파', '노래', '연애']
index = [2024, 2023, 2022, 2021]
seokjin = np.array([
[10, 60, 100, 60, 100],
[100, 50, 100, 40, 100],
[100, 70, 100, 10, 0],
[100, 75, 100, 0, 0],
])
seokjin_table = pd.DataFrame(seokjin, index=index, columns=columns)
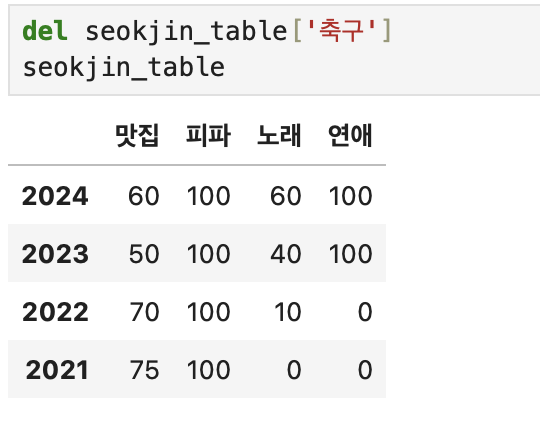
김석진 씨의 도파민 테이블이다.
데이터 접근
seokjin_table.축구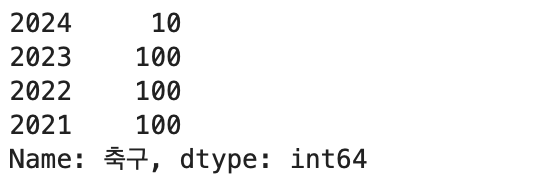
데이터 합치기
concat을 이용해 합칠 수 있다.
pd.concat([df1,df2])
열 삭제하기
제목 하기
- 데이터 불러오기
https://oracleselixir.com/stats/players/byTournament/LCK%2F2024%20Season%2FSpring%20Season
위 사이트에서 데이터를 다운받았다.
import pandas as pd
df = pd.read_csv('./LCK 2024 Spring - Player Stats - OraclesElixir.csv')- dataframe.describe()로 값 확인하기
df.describe()
3. 포지션 기준으로 테이블 분리하기
포지션을 기준으로 정렬한 후 분리했다.
grouped_df = {pos: group for pos, group in df.groupby('Pos')}
top = grouped_df['Top']
jungle = grouped_df['Jungle']
mid = grouped_df['Middle']
adc = grouped_df['ADC']
sup = grouped_df['Support']원딜 그룹만 가져왔다.
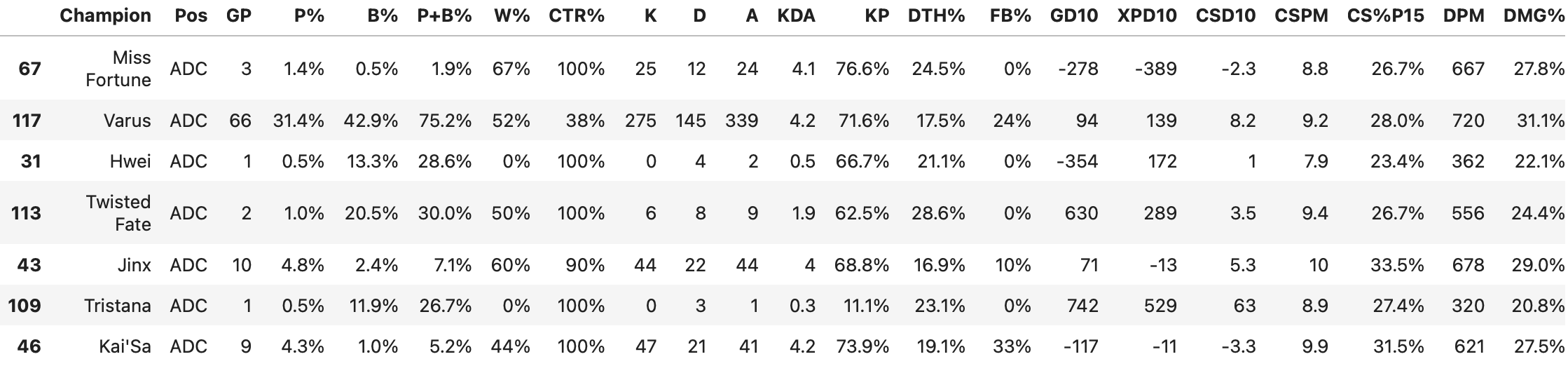
잘 나옴.
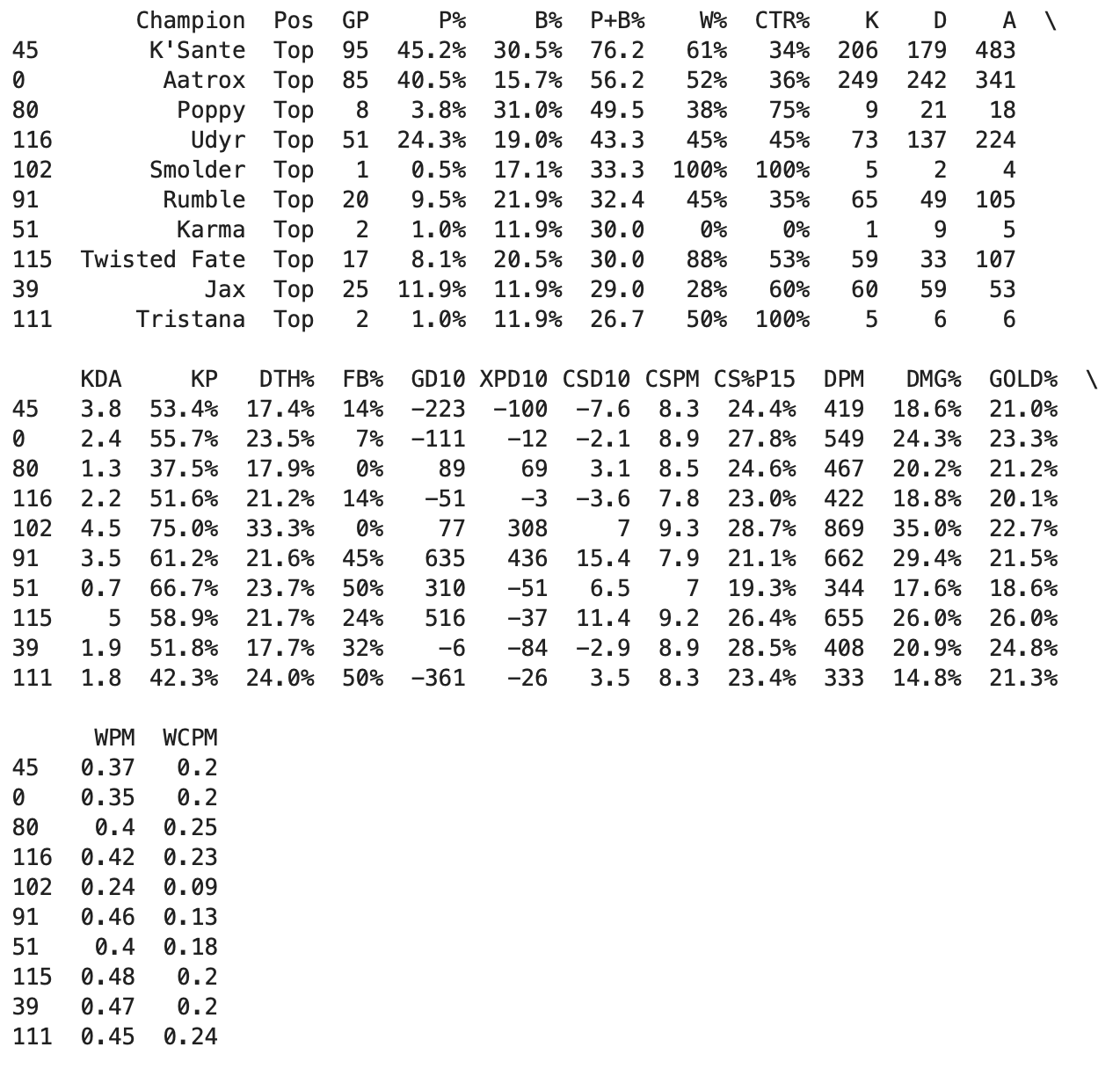
4. TOP 10 챔피언을 표시하자
top['P+B%'] = top['P+B%'].str.rstrip('%').astype(float)
jungle['P+B%'] = jungle['P+B%'].str.rstrip('%').astype(float)
mid['P+B%'] = mid['P+B%'].str.rstrip('%').astype(float)
adc['P+B%'] = adc['P+B%'].str.rstrip('%').astype(float)
sup['P+B%'] = sup['P+B%'].str.rstrip('%').astype(float)
top_top10 = top.nlargest(10, 'P+B%')
jungle_top10 = jungle.nlargest(10, 'P+B%')
mid_top10 = mid.nlargest(10, 'P+B%')
adc_top10 = adc.nlargest(10, 'P+B%')
sup_top10 = sup.nlargest(10, 'P+B%')
print(top_top10)이상하게 데이터 타입 변환을 안 하면 에러가 뜬다.
아무튼 잘 된다.