- 논문 링크 : Natural Adversarial Examples
- 데이터셋, 코드 링크 : Github

Abstract
본 논문에서는 크게 2가지의 adversarial examples을 소개하고 있습니다. 이들의 특징으로는 기존의 adversarial examples처럼 계산된 perturbation값을 더하여 만드는 방법이 아니라, clean하고 natural 상태의 이미지 데이터들로 구성되었다는 점입니다. 저자들은 각각의 데이터셋들을 ImageNet-A, ImageNet-O라 명명하였는데, ImageNet-A는 ImageNet test set과 비슷한 distribution을 갖는 데이터셋이며, ImageNet-O는 ImageNet의 distribution을 벗어난(Out-Of-Distribution) 데이터셋입니다. 위 2가지의 데이터셋의 실험 결과 DenseNet에서는 기존 ImageNet의 정확성이 92%였지만, ImageNet-A에 대해서는 2%의 정확성만을 가진다고 합니다. ImageNet-O 역시 마찬가지로 거의 random choice 단계밖에 되지 않는 성능으로 떨어진다고 합니다. 또한 기존의 성능 향상 기법으로 잘 알려진 Data Augmentation, More labeled data, Architectural changes도 큰 개선을 주지 못하였다고 합니다.
따라서 본 논문의 기존 ImageNet기반으로 발전하였던 모델들의 취약성과 한계점을 지적하며, Robustness한 모델의 필요성을 역설하고 있습니다.
Research Background
ImageNet classification을 바탕으로 컴퓨터 비전 분야의 많은 발전이 이루어졌습니다. 특히 진보된 여러 모델들이 등장하였습니다. 하지만 이러한 모델들은 data-distribution이 맞지 않을 때 성능이 좋지 않다는 단점을 저자들은 지적하고, 이와 관련한 연구들을 소개하고 있습니다. Recht et al.은 ImageNet test이미지 샘플들이 simple, clear, close-up한 이미지들로 구성되는 경향이 있어서, 매우 쉬우며 real world의 더 어려운 이미지를 대표하기에는 부적절하다고 지적합니다. Geirhos et al.은 Image classfication datasets이 "spurious cues(가짜 단서)" 혹은 "shortcut"을 포함하고 있어서, 모델들이 그것들을 이용하여 일종의 치팅을 사용한다고 주장하였다고 합니다. 예를 들어, 모델들이 이미지들의 backgrounds를 이용하여 foreground의 object class를 예측할 수 있다고 합니다. 따라서 데이터셋에 이러한 spurious cues가 포함되면, 이것은 ImageNet에 대해서는 optimistic 하지만 real-world에서는 inaccurate하다고 합니다.
저자들은 위에서 언급한 취약점을 드러내기 위해서 "suprious cues"나 "shortcuts"이 없는 데이터셋들을 만들었다고 합니다. 이 데이터셋들은 사람에게는 쉬우나 모델들에게는 매우 어려우며, ImageNet과 동일한 class를 가진다고 합니다. 또한 clean(natural) examples로 구성된 것이 큰 특징이며, 이들은 transferabiltiy를 가져서 unseen classfier들에서도 성능을 크게 저하시킨다고 합니다.
Related work
저자들은 관련 연구로 아래와 같이 4가지 주제를 소개하고 있습니다
-
Adversarial examples : 기존의 대부분의 연구에서 다룬 adversarial examples은 norm-limit을 주어 생성한 perturbation을 더해주어 생성하게 됩니다. 이렇게 생성된 adversarial examples은 같은 계열의 models에게 tranferred될 수 있습니다. 반면에, 본 논문서 소개하는 ImageNet-A, ImageNet-O는 모든 모델들에 transfer될 수 있으며, norm-limit에 제약받지 않는다고 합니다
-
Out-of-Distribution Detection(OOD) : Out-of-Distribution Dataset은 pre-trained된 모델의 학습 데이터셋의 분포를 벗어난 데이터셋을 말합니다. 보통 얼마나 벗어나 있는지 척도를 구하기 위해, Softmax probability의 maximum에 negative값을 붙인 것을 사용한다고 합니다. 본 논문서 소개한 ImageNet-O는 기존의 OOD dataset과는 달리 훨씬 더 사실적이며 미세한 이상함을 가진다고 하며, 이는 label distribution을 바꾸면서도 non-semantic한 요소들은 기존과 같이 유지하여 만들었다고 합니다.
-
Spurious Cues and Unintended Shortcuts : 모델들은 여러 suprious cues를 통해 학습하여서, 높은 accuracy를 달성할 수 있지만, 이는 잘못된 추론이라 합니다. Suprious cues의 예로는 만약 초원에 있는 소를 classfication하는 경우, trainset에 소 이미지들이 주로 초원에 있는 것이 많아서 소를 보고 소로 분류하는 것이 아니라, backgroud인 초원을 보고 소로 분류한다는 점을 언급하고 있습니다. ImageNet-A/O는 이러한 가짜 단서들을 없애서 모델들이 더는 이를 사용하지 못하게 한다고 합니다.
-
Robustness to Shifted Input Distribution: Brendel et al.은 classifiers이 이미지 regions의 공간적인 순서를 모르는 점을 지적하고 있습니다. ImageNet test set은 difficulty가 부족하기 때문에, 이것을 가지고 성능을 측정하는 것은 shortcomming을 이용한다는 사실을 가려버릴 수 있다고 언급하고 있습니다. Geirhos et al.은 classifiers이 textural cues에 의존적이며, obeject의 shape 정보를 잘 사용하지 않는다는 점을 언급하고 있습니다.
Design of Datasets
ImageNet-A

ImageNet-A는 ImageNet training distribution과는 다른 분포의 이미지들을 가지지만, ImageNet과 같은 class를 가지도록 구성되어 있습니다. 즉, Input data distribution을 shift하여 만든 것입니다.
이를 만들기 위해서는 아래와 같은 절차를 따른다고 합니다.
1.ImageNet class에 해당하는 여러 이미지들을 다른 데이터셋에서 수집합니다
2.ResNet-50 classifier가 올바르게 예측한 이미지들은 삭제합니다.
3.부정확하게 분류된 이미지들 가운데서 low confidence를 가지며, visually clear한 이미지들만을 선택합니다.
ImageNet-A class restrictions
1.
ImageNet-O

ImageNet-O는 Semantic한 요소들의 data distribution을 shift함으로써, ImageNet-1K와 다른 concept의 이미지들을 포함하게 됩니다. 즉, 기존 IamgeNet-1K label의 distribution이 바뀐 데이터셋이라 할 수 있습니다
ImageNet-O를 만들기 위해서는 다음과 같은 절차를 따릅니다.
1. 먼저 ImageNet-22k 데이터셋을 다운받고, ImageNet-1k와 중복된 것을 삭제합니다
2. ResNet-50에 의해 high confidence를 가지거나 적은 anomaly score(negative of the maximum of softmax probability)를 가지는 이미지들을 keep합니다.
3. 이중에서 visually clear한 이미지들을 선택한다고 합니다. 대략적으로 2000장의 이미지가 남는다고 하는데, 이는 anomalies가 rarer하기 때문이라 합니다.
Illustrative Failure Modes
저자들은 신경망이 오분류하는 경우들을 설명하고 있습니다. 먼저 신경망이 아래처럼 visual concepts을 overgeneralize하는 점이 있습니다. 또한 모델이 너무 color, texture에 의존하여, object class를 전체 이미지와 연관되어 학습된다는 점이 있는것을 소개합니다. 
Experiments
본 논문서는 최근의 CNN기반의 모델들에 대해서 그들이 서로 weakness와 failure modes를 공유하고 있다고 하며, 이를 입증하는 실험의 결과를 제시합니다. 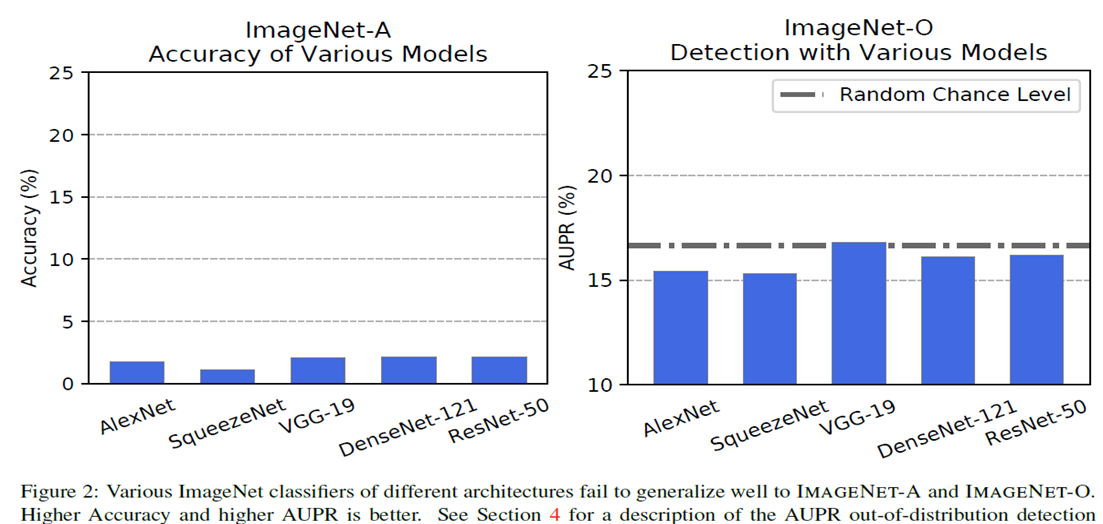 여기서 사용된 척도로는 ImageNet-A의 경우에는 흔히 사용되는 Top-1 accuracy를 사용하며, out-of-Distribution detection의 척도 model로 부터 예측된 softmax probabilities의 최댓값의 negative인 anomaly-score를 사용합니다.
여기서 사용된 척도로는 ImageNet-A의 경우에는 흔히 사용되는 Top-1 accuracy를 사용하며, out-of-Distribution detection의 척도 model로 부터 예측된 softmax probabilities의 최댓값의 negative인 anomaly-score를 사용합니다.
위와 같이 모두 성능이 매우 안좋은 것을 확인할 수 있으며, 여러 모델들에게도 transfer되는 것을 확인할 수 있다고 합니다.
Efforts to Improve performance
본 논문서는 안좋아진 성능을 개선시키기 위한 실험으로, 널리 사용되는 Data-Augmentation, More Labeled data, Achitectural changes를 실험해보았다고 합니다.
Data Augmentation
Popular한 data augmentation 기법을 적용해 보았으나, 최대 10%정도의 향상만 보였다고 합니다. 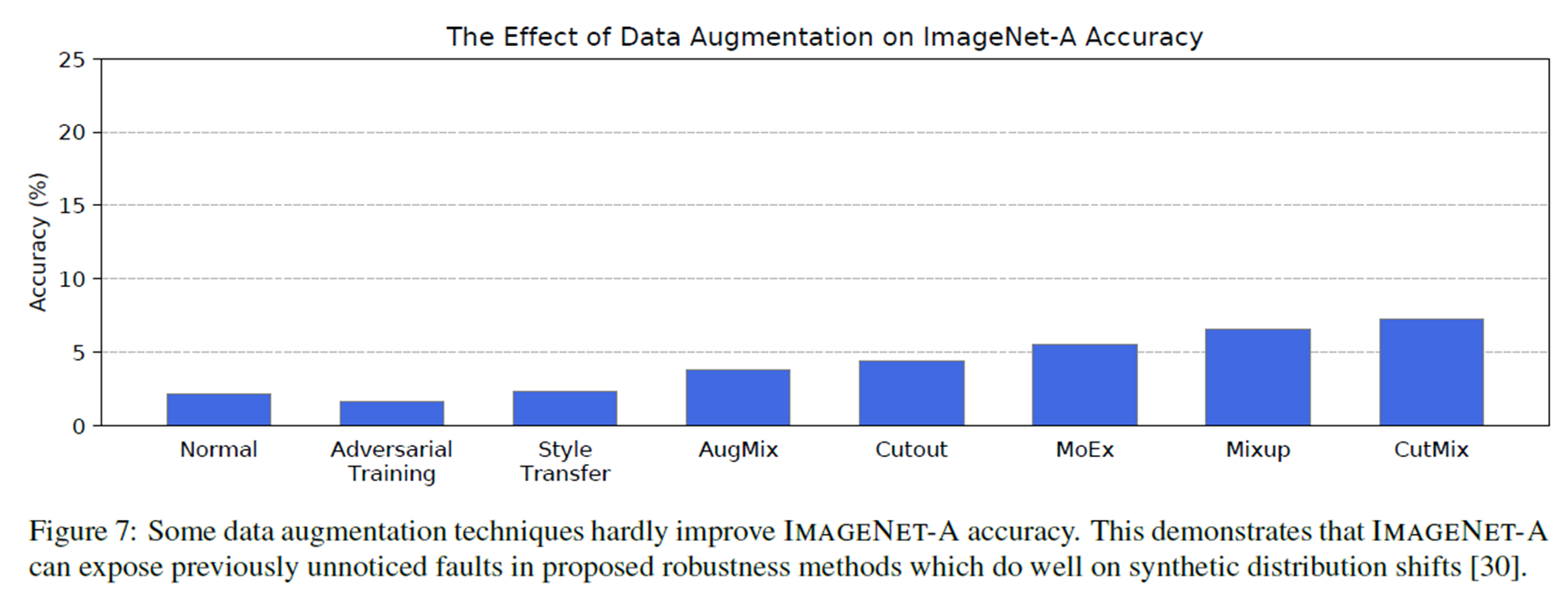
More labeled Data
ImageNet-1K로 pre-trained된 모델에 추가적인 데이터셋을 학습시켜서 성능향상을 기대할 수 있는지 실험해 보았다고 합니다. Pre-trained ResNet-50에 Place365 데이터셋을 추가적으로 학습시킨후, ImageNet-1k로 fine-tuned한 모델의 결과는 고작 1.56%의 향상밖에 보이지 못하였다고 합니다.
추가적으로 ImageNet-A 자체로 훈련시켰을 때도(80%학습, 20% Test), Top-1과 Top-5 accuracy가 각각 2%, 5%미만였다고 합니다. ImageNet-21k를 추가적으로 학습시켰을 때는 ImageNEt-A는 9.24% accuracy 향상이, ImageNEt-O는 5% AUPR향상이 있었는데, 이는 ImageNet-O가 ImageNet-21k와 중복되는 것이 있으므로, 당연히 개선된다는 점을 언급하고 있습니다.
Architectural Changes
저자들은 모델의 구조적인 변화가 ImageNet-A의 정확도와 ImageNet-O detection의 큰 변화를 줄 수 있다고 언급하고 있습니다. 저자들은 모델의 layer의 수를 늘려보기도 하고, self-attention, ResNet-50의 residual block을 Res2Net v1b block으로 대체해 보는 실험을 진행하였고 다음과 같은 결과를 제시합니다. 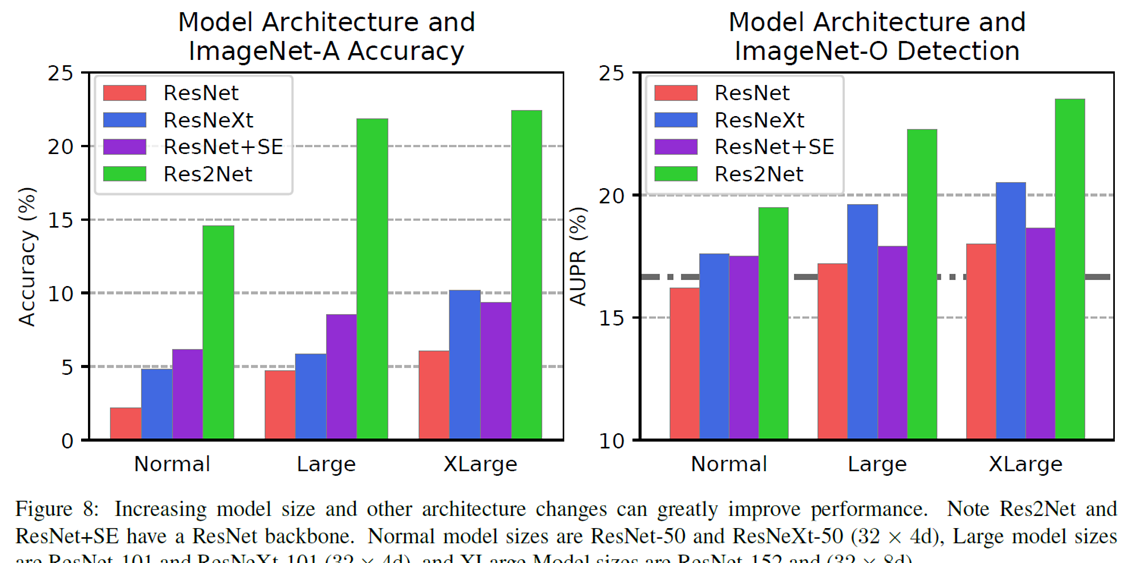 또한 Convolution연산을 사용하지 않은 vision transformer(DeiT)도 좋지 않은 결과 (ImageNet-A 28.2% accuracy, ImageNet-O 24.8% AUPR)을 보여준다고 합니다.
또한 Convolution연산을 사용하지 않은 vision transformer(DeiT)도 좋지 않은 결과 (ImageNet-A 28.2% accuracy, ImageNet-O 24.8% AUPR)을 보여준다고 합니다.
Conclusion
본 논문에서는 natural한 adversarial examples로 구성된 dataset 2가지를 소개하고 있습니다. 이 데이터셋들은 data augmentation, more pre-training data, architectural changes을 적용해봤을 때 개선이 어렵다는 특징을 가집니다. 특히 이 데이터셋들은 모든 모델(vision Transformer포함)에 대해 낮은 성능을 보이는 transferability를 가집니다. 즉, 본 논문을 통해 ImageNet 기반으로 발전된 모델들의 한계를 보이기도 하면서, real world을 위한 보다 더 robust한 모델에 대한 필요성을 역설하고 있다고 생각합니다.
