Abstract
본 논문에서는 VGG 스타일의 ConvNet을 제시하는데요, training time시에는 multi-branch topology로 구성되지만, inference time시에는 re-parameterization 기법을 사용하여 구조를 바꿔서 오직 3x3 convolution과 ReLU로 구성된 single-branch로 바꾸는 것이 가장 큰 특징입니다. 이러한 모델은 다른 ResNet계열보다도 높은 정확성과 빠른 속도를 달성했다고 하며, EfficientNet이나 RegNet과 같은 SOTA모델에 뒤쳐지지 않는 성능을 보였다고 합니다.
연구 배경 및 관련 연구
Multi-branch model들의 단점과 그에 대한 해결책 : RepVGG
VGG이후 ResNet과 같은 multi-branch 모델들이 등장하였고, 좋은 성능을 보였습니다. 하지만 multi-branch 모델들의 단점으로는 먼저 복잡한 구조를 가지기 때문에 customize나 구현이 까다로우며, 메모리 효율성과 inference 시간이 길어진다는 단점이 있습니다.
또 다른 문제로는 multi-branch의 몇몇 요소들이 메모리 접근 cost를 증가시키며, 다양한 기기에 지원되지 않는다는 점입니다.
필자는 이러한 문제들에 반해 RepVGG는 다음과 같은 이점을 갖는다고 합니다.
RepVGG 장점
1) VGG style이므로 braches가 없어서 layer에 입력후 바로 출력을 합니다
2) 3X3 CONV와 ReLU로 구성되어 있습니다
3) no automatic search, manual refinement, compound scaling, heavy designs 없이 concrete한 아키텍쳐를 만들 수 있습니다.
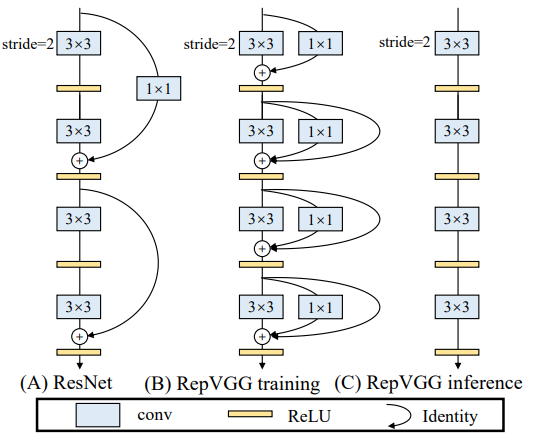
그럼 필자들은 어떻게 이러한 문제들을 해결했을까요?? 먼저 그들은 multi-branch의 장점들이 training시에만 적용될 수 있다고 하여서, inference-time시에는 structural re-parameterization을 통해서 branch가 없게 만들었습니다. 즉 training time시에는 아래와 그림처럼 ResNet과 같은 3x3 conv, 1x1 conv, Identity로 구성된 multi-branch를 두었다면, Inference time에서는 3x3 kernel하나로 이것을 통합하였다고 합니다. Identity branch를 degraded된 1x1 conv로 간주하고, 1x1 conv를 다시 degraded된 3x3 conv로 간주하였다고 합니다. 마찬가지로 batch-normalization 역시 3x3로 간주할 수 있어서, branch의 모든 요소들을 3x3로 간주하여 하나로 만들었다는 것이 이 논문의 핵심입니다.
Why 3x3 Conv?
RepVGG는 오직 3x3 Conv를 사용하는데, 이는 NVIDIA-GPU에서 3x3 conv의 성능이 다른 커널 사이즈보다 훨씬 빠르기 때문이라 합니다.  실제로 위의 표처럼 연산 속도 지표인 TFLOPS가 3x3 kernel size에서 가장 빠르다고 합니다. 이러하기에 저자들은 오직 3x3 conv를 사용하려 하였으며, Winograd와 같은 3x3 conv를 accelerating하는 알고리즘도 존재한다고 합니다.
실제로 위의 표처럼 연산 속도 지표인 TFLOPS가 3x3 kernel size에서 가장 빠르다고 합니다. 이러하기에 저자들은 오직 3x3 conv를 사용하려 하였으며, Winograd와 같은 3x3 conv를 accelerating하는 알고리즘도 존재한다고 합니다.
Building RepVGG via Stuructual Re-param
먼저 simpel convNet들을 사용하는 이유로는 그들이 빠르고, 메모리 경제적이며, flexible하기 때문이라고 합니다. Residual block의 경우 아래처럼 addtion전까지 가지고 이썽야 하므로, 메모리 사용량이 많아지게 됩니다. 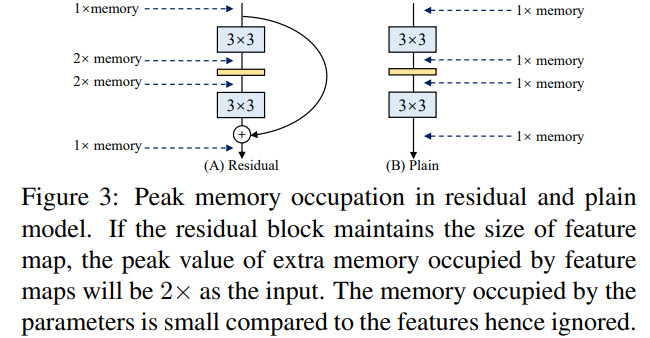
Training-time Multi-branch Architecture
Plain한 ConvNets의 단점으로는 안좋은 성능을 뽑을 수 있습니다. 논문 저자들을 ResNet을 참고하여, shortcut branch를 추가하는 방식으로 훈련시켜서 성능 개선을 하였다고 합니다. ResNEt-like의 identity Multi-branch은 inference에는 안좋지만, training에서는 이점이 있으므로, 필자들은 훈련시에만 multiple branches를 사용하였다고 합니다.
Re-param for Plain Inference-time Model
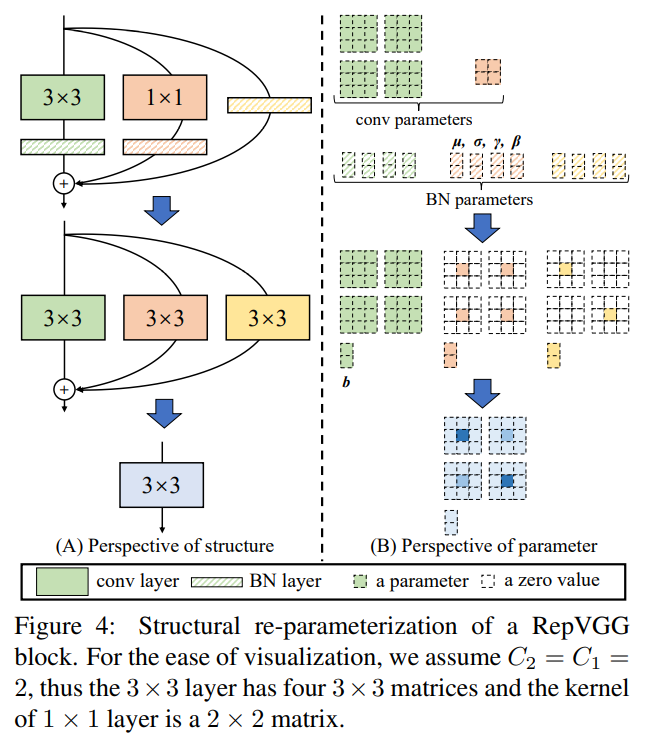
< Batch Normalization >
- µ : accumalated mean
- σ : standard deviation
- γ : scale factor
- β : bias
- : Convolution operator
M(1) ∈ R(N×C1×H1×W1), M(2) ∈ R(N×C2×H2×W2) be the input and output.
- : Convolution operator
BN의 구성요소들을 위처럼 표기하고, 3x3 conv, 1x1 conv, identity를 지난 output(M(2))는 다음과 같이 표기할 수 있습니다. 
먼저 모든 BN과 conv layer들을 bias vector를 가지는 conv로 다음과 같이 바꿀 수 있습니다. (W', b'은 각각 {W, µ,σ, γ, β}에서 변환된 Kernel과 bias를 의미합니다) 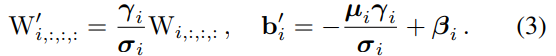
 즉 위와 같이 BN layer를 conv로 표현 가능하며, 이는 identity branch에서도 마찬가지로 적용가능합니다. 따라서 위의 그림을 다시 참고하면, 결국에는 BN parameters는 bias로, 3x3 Conv는 3x3 kernel로, 1x1과 identity는 1x1 conv로 표현할 수 있으며, 이것을 다 더해서 하나의 W'(kernel)과 b'(bias)로 나타내었다는 얘기인 것 같습니다
즉 위와 같이 BN layer를 conv로 표현 가능하며, 이는 identity branch에서도 마찬가지로 적용가능합니다. 따라서 위의 그림을 다시 참고하면, 결국에는 BN parameters는 bias로, 3x3 Conv는 3x3 kernel로, 1x1과 identity는 1x1 conv로 표현할 수 있으며, 이것을 다 더해서 하나의 W'(kernel)과 b'(bias)로 나타내었다는 얘기인 것 같습니다
Architectural Specification
RepVGG는 3x3 Conv를 사용하지만, 최소한의 operator를 사용하기 위해서 max pooling은 사용하지 않습니다. 필자들은 3x3 conv를 5개 단계로 두고, 첫단계서는 stride=2로 주어서 down-sampling을 하였다고 합니다. 뒤따르는 fully-connected layer head부분에서는 global average pooling을 하였다고 합니다. 또한 paremeters 수를 줄이기 위해서 group wise 3x3 conv를 사용하였다고 합니다
Experiments
본 논문서는 먼저 ImageNet image-classification에 대한 결과를 보여주고 있습니다. 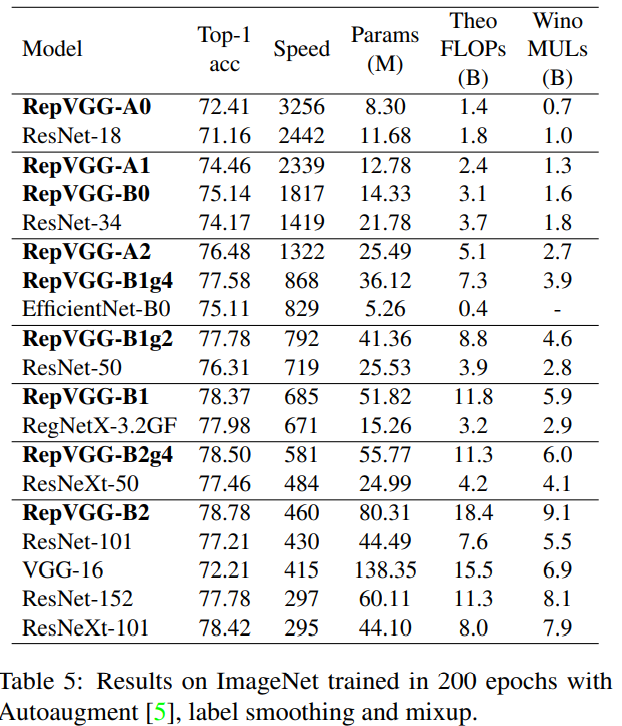 위의 표처럼 RepVGG는 빠른 성능과 정확도를 보여주고 있으며, 성능 향상 기법을 더했을 때 다음과 같이 SOTA 모델과 견줄만한 결과를 보인다고 합니다.
위의 표처럼 RepVGG는 빠른 성능과 정확도를 보여주고 있으며, 성능 향상 기법을 더했을 때 다음과 같이 SOTA 모델과 견줄만한 결과를 보인다고 합니다. 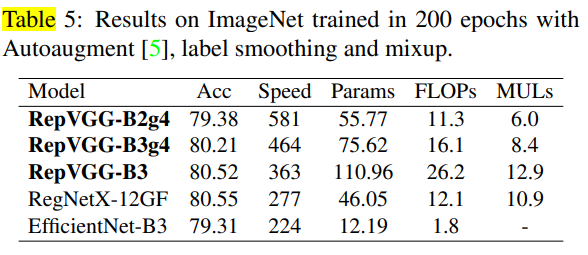
또한 Re-param의 중요성을 알아보기 위해서, 아래와 같이 각각에 대해 적용해 보았을때의 결과도 제시하고 있습니다

마지막으로는 Semantic segmentation에 대해서도 실험을 해봤을 때, RepVGG가 잘 된다고 합니다. 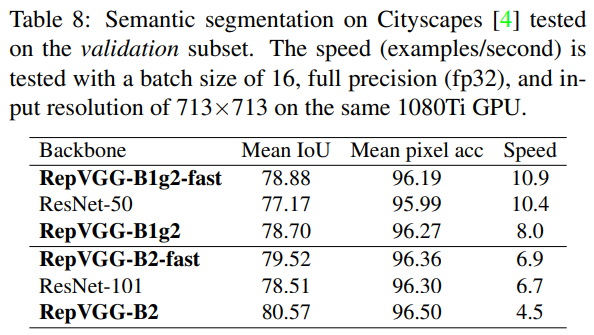
저자들은 RepVGG의 한계로 GPU에서는 잘되지만, lower-power device에 사용되는 MobileNets, ShuffleNets 등에서는 덜 선호된다고 합니다.
Conclusion
본 놈누에서는 3x3 conv와 ReLU만을 사용하여 GPU 연산과 inference에 특화된 VGG-style의 RepVGG모델을 소개하고 있습니다. Re-parameterization을 통해서, SOTA모델들과 견줄만한 정확성과 속도를 가진다고 합니다.
