2012년 딥러닝의 발전히 급격하게 이루어지면서, CNN을 기반으로 한 정교화된 분류 시스템을 향한 연구가 많이 이루어졌습니다.
특히 ImageNet 분류 대회(ILSVRC)를 통해 다양한 CNN 기반 모델들이 제시되었습니다
이번 chatper에서는 다양한 CNN 모델을 직접 scratch부터 만들면서 데이터셋에 훈련시키며 살펴보도록 하겠습니다
1. LeNet-5
1998년 LeCun에 의해 소개된 LeNet-5는 5개의 layer로 구성되어 있습니다.
5X5 Conv filter(stride 1) 가 적용되었습니다. 또한 Pooling layer는 2X2 size이며, stride 2가 적용되었습니다. LeNet-5의 구조는 아래와 같습니다.

Keras를 이용하여 직접 LeNet-5를 구현해 보겠습니다.
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, AveragePooling2D, Flatten, Dense, Input
from tensorflow.keras.models import Model, Sequential
class LeNet5(Sequential):
def __init__(self, input_shape, num_classes):
super().__init__()
# 1st Block(Input + Conv2D + Avg_pooling)
self.add(Conv2D(6, kernel_size=(5,5), strides=(1,1), padding='same',
activation='relu', # 원래의 제시에서는 tanh로 제시되었으나, 모델의 성능을 위해 제가 relu로 바꿨습니다.
input_shape=input_shape))
self.add(AveragePooling2D(pool_size=(2,2)))
# 2nd Block(Conv2D + Avg_pooling)
self.add(Conv2D(16, kernel_size=(5,5), strides=(1,1), padding='same',
activation='relu',
input_shape=input_shape))
self.add(AveragePooling2D(pool_size=(2,2)))
# FC layer
self.add(Flatten()) # 2D -> 1D vectors
self.add(Dense(120, activation='relu'))
self.add(Dense(84, activation='relu'))
self.add(Dense(num_classes, activation='softmax')) LeNet-5 모델을 인스턴스화 하고, 모델의 정보를 출력해보겠습니다
# 논문에 제안된 img width, height은 32 X 32이나, 아래의 fashion_MNIST의 img는 28 X 28 사이즈이므로, 조정해주었습니다.
img_height = 28
img_width = 28
img_channels = 1
input_shape = (img_height, img_width, img_channels)
num_classes = 10 # 10개의 의류 class
# Build model
model = LeNet5(input_shape=input_shape, num_classes=num_classes)
# Print model Info
print(model.summary())Model: "le_net5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 28, 28, 6) 156
_________________________________________________________________
average_pooling2d (AveragePo (None, 14, 14, 6) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 14, 14, 16) 2416
_________________________________________________________________
average_pooling2d_1 (Average (None, 7, 7, 16) 0
_________________________________________________________________
flatten (Flatten) (None, 784) 0
_________________________________________________________________
dense (Dense) (None, 120) 94200
_________________________________________________________________
dense_1 (Dense) (None, 84) 10164
_________________________________________________________________
dense_2 (Dense) (None, 10) 850
=================================================================
Total params: 107,786
Trainable params: 107,786
Non-trainable params: 0
_________________________________________________________________
None이제 모델을 compile한 이후, fashion-mnist 데이터에 대해 훈련시켜보겠습니다.
# load data
import tensorflow as tf
import numpy as np
from tensorflow.keras.datasets import fashion_mnist
from tensorflow.keras.utils import to_categorical
(X_train, y_train), (X_test, y_test) = fashion_mnist.load_data()
# normalize data
X_train, X_test = X_train.astype('float32')/255.0, X_test.astype('float32')/255.0
X_train, X_test = X_train.reshape(-1,*input_shape), X_test.reshape(-1, *input_shape)
# Make labels to one-hot encoding labels
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
print('X_train shape:', X_train.shape)
print('X_test shape:', X_test.shape)
print('y_train shape:', y_train.shape)
print('y_test shape:', y_test.shape)X_train shape: (60000, 28, 28, 1)
X_test shape: (10000, 28, 28, 1)
y_train shape: (60000, 10)
y_test shape: (10000, 10)# build model
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# Train
model.fit(X_train, y_train, batch_size=32, epochs=20, validation_data=(X_test, y_test))Epoch 1/20
1875/1875 [==============================] - 11s 5ms/step - loss: 0.5266 - accuracy: 0.8071 - val_loss: 0.4031 - val_accuracy: 0.8547
Epoch 2/20
1875/1875 [==============================] - 9s 5ms/step - loss: 0.3585 - accuracy: 0.8673 - val_loss: 0.3681 - val_accuracy: 0.8646
Epoch 3/20
1875/1875 [==============================] - 9s 5ms/step - loss: 0.3085 - accuracy: 0.8876 - val_loss: 0.3219 - val_accuracy: 0.8857
Epoch 4/20
1875/1875 [==============================] - 9s 5ms/step - loss: 0.2766 - accuracy: 0.8969 - val_loss: 0.3072 - val_accuracy: 0.8909
Epoch 5/20
1875/1875 [==============================] - 8s 5ms/step - loss: 0.2535 - accuracy: 0.9062 - val_loss: 0.2816 - val_accuracy: 0.8979
Epoch 6/20
1875/1875 [==============================] - 8s 5ms/step - loss: 0.2335 - accuracy: 0.9124 - val_loss: 0.2892 - val_accuracy: 0.8982
Epoch 7/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.2173 - accuracy: 0.9178 - val_loss: 0.2716 - val_accuracy: 0.9020
Epoch 8/20
1875/1875 [==============================] - 9s 5ms/step - loss: 0.2031 - accuracy: 0.9226 - val_loss: 0.2752 - val_accuracy: 0.9056
Epoch 9/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.1896 - accuracy: 0.9280 - val_loss: 0.2742 - val_accuracy: 0.9053
Epoch 10/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.1776 - accuracy: 0.9334 - val_loss: 0.2690 - val_accuracy: 0.9081
Epoch 11/20
1875/1875 [==============================] - 9s 5ms/step - loss: 0.1668 - accuracy: 0.9367 - val_loss: 0.2685 - val_accuracy: 0.9074
Epoch 12/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.1564 - accuracy: 0.9406 - val_loss: 0.2756 - val_accuracy: 0.9119
Epoch 13/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.1469 - accuracy: 0.9447 - val_loss: 0.2817 - val_accuracy: 0.9129
Epoch 14/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.1376 - accuracy: 0.9480 - val_loss: 0.2900 - val_accuracy: 0.9144
Epoch 15/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.1297 - accuracy: 0.9507 - val_loss: 0.3166 - val_accuracy: 0.9052
Epoch 16/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.1220 - accuracy: 0.9540 - val_loss: 0.3011 - val_accuracy: 0.9086
Epoch 17/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.1167 - accuracy: 0.9548 - val_loss: 0.3351 - val_accuracy: 0.9033
Epoch 18/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.1078 - accuracy: 0.9590 - val_loss: 0.3120 - val_accuracy: 0.9102
Epoch 19/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.1018 - accuracy: 0.9604 - val_loss: 0.3401 - val_accuracy: 0.9123
Epoch 20/20
1875/1875 [==============================] - 8s 4ms/step - loss: 0.0985 - accuracy: 0.9628 - val_loss: 0.3513 - val_accuracy: 0.9136위에서 훈련 시킨 모델을 토대로, 모델의 분류 결과를 시각화 해보겠습니다!
import matplotlib.pyplot as plt
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
# Prediction
prediction_values = model.predict_classes(X_test)
# figure(그리기) 위한 set up
fig = plt.figure(figsize=(15, 7))
fig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.05, wspace=0.05)
# Plot 50 images with prediction
for i in range(50):
ax = fig.add_subplot(5, 10, i + 1, xticks=[], yticks=[])
ax.imshow(X_test[i,:].reshape((28,28)),cmap=plt.cm.gray_r, interpolation='nearest')
# If correct, label the image with the blue text
if prediction_values[i] == np.argmax(y_test[i]):
ax.text(0, 7, class_names[prediction_values[i]], color='blue')
# If wrong, label the image with the red text
else:
ax.text(0, 7, class_names[prediction_values[i]], color='red') 위의 결과를 살펴보면은 50개의 이미지에서 2개의 잘못 분류된 것을 확인할 수 있었습니다.
다음과 같이 LeNet-5를 이용하여 이미지 분류를 해보았습니다.
위의 결과를 살펴보면은 50개의 이미지에서 2개의 잘못 분류된 것을 확인할 수 있었습니다.
다음과 같이 LeNet-5를 이용하여 이미지 분류를 해보았습니다.
2. AlexNet
AlexNet은 2012년 ImageNet challenge에서 제시된 모델입니다.
첫 CNN based의 우승작이었습니다.
AlexNet의 구조는 아래와 같습니다.
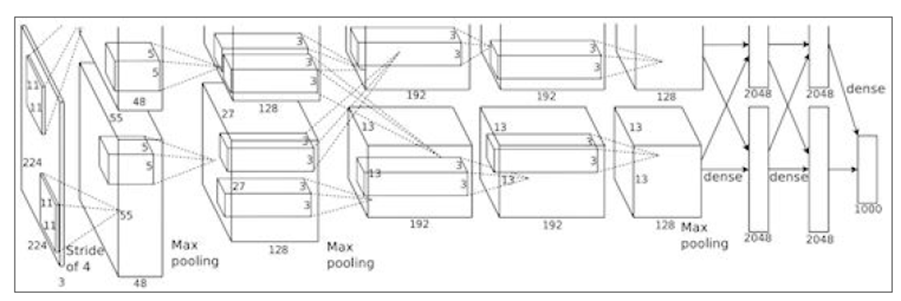

이 역시 마찬가지로 Keras를 이용하여 직접 구현하여 보겠습니다.
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Input, BatchNormalization, Dropout
from tensorflow.keras.models import Model, Sequential
class AlexNet(Sequential):
def __init__(self, input_shape=(227,227,3), num_classes):
super().__init__()
# 1st Block(Input + Conv2D + MaxPooling + Normalization)
self.add(Conv2D(96, kernel_size=(11,11), strides=4, activation='relu', input_shape=input_shape))
self.add(MaxPooling2D(pool_size=(3,3)), strides=(2,2))
self.add(BatchNormalization())
# 2nd Block(Input + Conv2D + MaxPooling + Normalization)
self.add(Conv2D(256, kernel_size=(5,5), strides=(1,1), padding='same', activation='relu'))
self.add(MaxPooling2D(pool_size=(3,3)), strides=(2,2))
self.add(BatchNormalization())
# 3rd Block(Conv2D)
self.add(Conv2D(384, kernel_size=(3,3), strides=(1,1), padding='same', activation='relu'))
self.add(Conv2D(384, kernel_size=(3,3), strides=(1,1), padding='same', activation='relu'))
self.add(Conv2D(256, kernel_size=(3,3), strides=(1,1), padding='same', activation='relu'))
self.add(MaxPooling2D(pool_size=(3,3)), strides=(2,2))
# FC layer
self.add(Flatten()) # 2D -> 1D vectors
self.add(Dense(4096, activation='relu'))
self.add(Dropout(0.5))
self.add(Dense(4096, activation='relu'))처음 제시된 AlexNet의 구현은 위와 같습니다.
cifar-10의 image 크기는 32 X 32이므로 AlexNet8을 축소시켜서 훈련시켜 보겠습니다.
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Input, BatchNormalization, Dropout
from tensorflow.keras.models import Model, Sequential
class AlexNet8(Sequential):
def __init__(self, input_shape, num_classes):
super().__init__()
# 1st Block(Input + Conv2D + MaxPooling + Normalization)
self.add(Conv2D(96, kernel_size=(3,3), activation='relu', padding='same', input_shape=input_shape))
self.add(BatchNormalization())
self.add(MaxPooling2D(pool_size=(3,3), strides=(2,2)))
# 2nd Block(Input + Conv2D + MaxPooling + Normalization)
self.add(Conv2D(256, kernel_size=(3,3), padding='same', activation='relu'))
self.add(BatchNormalization())
self.add(MaxPooling2D(pool_size=(3,3), strides=(2,2)))
# 3rd Block(Conv2D)
self.add(Conv2D(384, kernel_size=(3,3), padding='same', activation='relu'))
self.add(Conv2D(384, kernel_size=(3,3), padding='same', activation='relu'))
self.add(Conv2D(256, kernel_size=(3,3), padding='same', activation='relu'))
self.add(MaxPooling2D(pool_size=(3,3), strides=(2,2)))
# FC layer
self.add(Flatten()) # 2D -> 1D vectors
self.add(Dense(2048, activation='relu'))
self.add(Dropout(0.5))
self.add(Dense(2048, activation='relu'))
self.add(Dropout(0.5))
self.add(Dense(num_classes, activation='softmax'))이번에는 cifar-10 dataset을 이용하여 모델을 훈련시켜보겠습니다
# load data
import tensorflow as tf
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.utils import to_categorical
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
# normalize data
X_train, X_test = X_train/255.0, X_test/255.0
# Make labels to one-hot encoding labels
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
print('X_train shape:', X_train.shape)
print('X_test shape:', X_test.shape)
print('y_train shape:', y_train.shape)
print('y_test shape:', y_test.shape)X_train shape: (50000, 32, 32, 3)
X_test shape: (10000, 32, 32, 3)
y_train shape: (50000, 10)
y_test shape: (10000, 10)Model을 compile하고 모델 정보를 출력해 보겠습니다.
img_height = 32
img_width = 32
img_channels = 3
input_shape = (img_height, img_width, img_channels)
num_classes = 10
# Build model
model = AlexNet8(input_shape=input_shape, num_classes=num_classes)
# Print model Info
print(model.summary())Model: "alex_net8"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_2 (Conv2D) (None, 32, 32, 96) 2688
_________________________________________________________________
batch_normalization (BatchNo (None, 32, 32, 96) 384
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 15, 15, 96) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 15, 15, 256) 221440
_________________________________________________________________
batch_normalization_1 (Batch (None, 15, 15, 256) 1024
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 7, 7, 256) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 7, 7, 384) 885120
_________________________________________________________________
conv2d_5 (Conv2D) (None, 7, 7, 384) 1327488
_________________________________________________________________
conv2d_6 (Conv2D) (None, 7, 7, 256) 884992
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 3, 3, 256) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 2304) 0
_________________________________________________________________
dense_3 (Dense) (None, 2048) 4720640
_________________________________________________________________
dropout (Dropout) (None, 2048) 0
_________________________________________________________________
dense_4 (Dense) (None, 2048) 4196352
_________________________________________________________________
dropout_1 (Dropout) (None, 2048) 0
_________________________________________________________________
dense_5 (Dense) (None, 10) 20490
=================================================================
Total params: 12,260,618
Trainable params: 12,259,914
Non-trainable params: 704
_________________________________________________________________
None이제 모델을 훈련시켜보겠습니다!
# build model
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# Train
model.fit(X_train, y_train, batch_size=32, epochs=50, validation_data=(X_test,y_test))Epoch 1/50
1563/1563 [==============================] - 14s 9ms/step - loss: 1.5807 - accuracy: 0.4243 - val_loss: 1.5269 - val_accuracy: 0.4793
Epoch 2/50
1563/1563 [==============================] - 13s 9ms/step - loss: 1.2556 - accuracy: 0.5559 - val_loss: 1.4653 - val_accuracy: 0.5012
Epoch 3/50
1563/1563 [==============================] - 13s 9ms/step - loss: 1.1266 - accuracy: 0.6064 - val_loss: 1.3713 - val_accuracy: 0.5320
Epoch 4/50
1563/1563 [==============================] - 13s 8ms/step - loss: 1.0463 - accuracy: 0.6398 - val_loss: 1.3903 - val_accuracy: 0.5312
Epoch 5/50
1563/1563 [==============================] - 14s 9ms/step - loss: 0.9916 - accuracy: 0.6609 - val_loss: 1.2358 - val_accuracy: 0.5657
Epoch 6/50
1563/1563 [==============================] - 13s 9ms/step - loss: 0.9255 - accuracy: 0.6820 - val_loss: 1.1037 - val_accuracy: 0.6266
Epoch 7/50
1563/1563 [==============================] - 14s 9ms/step - loss: 0.9031 - accuracy: 0.6934 - val_loss: 0.9475 - val_accuracy: 0.6742
Epoch 8/50
1563/1563 [==============================] - 13s 9ms/step - loss: 0.8696 - accuracy: 0.7062 - val_loss: 0.9173 - val_accuracy: 0.6927
Epoch 9/50
1563/1563 [==============================] - 13s 9ms/step - loss: 0.8294 - accuracy: 0.7192 - val_loss: 0.9155 - val_accuracy: 0.6946
Epoch 10/50
1563/1563 [==============================] - 13s 9ms/step - loss: 0.8154 - accuracy: 0.7239 - val_loss: 0.9536 - val_accuracy: 0.6813
Epoch 11/50
1563/1563 [==============================] - 13s 8ms/step - loss: 0.7841 - accuracy: 0.7386 - val_loss: 1.0169 - val_accuracy: 0.6551
Epoch 12/50
1563/1563 [==============================] - 13s 8ms/step - loss: 0.7670 - accuracy: 0.7432 - val_loss: 1.0089 - val_accuracy: 0.6676
Epoch 13/50
1563/1563 [==============================] - 13s 8ms/step - loss: 0.7294 - accuracy: 0.7581 - val_loss: 0.9086 - val_accuracy: 0.6961
Epoch 14/50
1563/1563 [==============================] - 13s 8ms/step - loss: 0.7086 - accuracy: 0.7656 - val_loss: 0.8976 - val_accuracy: 0.7011
Epoch 15/50
1563/1563 [==============================] - 13s 8ms/step - loss: 0.6851 - accuracy: 0.7721 - val_loss: 0.9349 - val_accuracy: 0.6975
Epoch 16/50
1563/1563 [==============================] - 13s 9ms/step - loss: 0.6709 - accuracy: 0.7790 - val_loss: 0.9015 - val_accuracy: 0.6941
Epoch 17/50
1563/1563 [==============================] - 13s 8ms/step - loss: 0.6413 - accuracy: 0.7890 - val_loss: 0.8818 - val_accuracy: 0.7064
Epoch 18/50
1563/1563 [==============================] - 13s 9ms/step - loss: 0.6315 - accuracy: 0.7944 - val_loss: 1.1729 - val_accuracy: 0.5960
Epoch 19/50
1563/1563 [==============================] - 13s 9ms/step - loss: 0.6058 - accuracy: 0.8026 - val_loss: 0.9324 - val_accuracy: 0.7038
Epoch 20/50
1563/1563 [==============================] - 13s 8ms/step - loss: 0.5883 - accuracy: 0.8089 - val_loss: 0.8515 - val_accuracy: 0.7241
Epoch 21/50
1563/1563 [==============================] - 13s 9ms/step - loss: 0.5618 - accuracy: 0.8164 - val_loss: 0.8143 - val_accuracy: 0.7395
Epoch 22/50
1563/1563 [==============================] - 13s 8ms/step - loss: 0.5643 - accuracy: 0.8189 - val_loss: 0.9171 - val_accuracy: 0.7169
Epoch 23/50
1563/1563 [==============================] - 13s 9ms/step - loss: 0.5235 - accuracy: 0.8305 - val_loss: 1.0290 - val_accuracy: 0.6712
Epoch 24/50
1563/1563 [==============================] - 13s 9ms/step - loss: 0.5214 - accuracy: 0.8312 - val_loss: 0.8062 - val_accuracy: 0.7588
Epoch 25/50
1563/1563 [==============================] - 13s 9ms/step - loss: 0.4972 - accuracy: 0.8393 - val_loss: 0.8252 - val_accuracy: 0.7296
Epoch 26/50
1563/1563 [==============================] - 13s 9ms/step - loss: 0.4907 - accuracy: 0.8419 - val_loss: 0.8190 - val_accuracy: 0.7358
Epoch 27/50
1563/1563 [==============================] - 13s 8ms/step - loss: 0.4576 - accuracy: 0.8533 - val_loss: 0.8330 - val_accuracy: 0.7491
Epoch 28/50
1563/1563 [==============================] - 13s 9ms/step - loss: 0.4705 - accuracy: 0.8505 - val_loss: 0.7978 - val_accuracy: 0.7541
Epoch 29/50
1563/1563 [==============================] - 13s 8ms/step - loss: 0.4467 - accuracy: 0.8581 - val_loss: 0.9988 - val_accuracy: 0.7135
Epoch 30/50
1563/1563 [==============================] - 13s 9ms/step - loss: 0.4189 - accuracy: 0.8673 - val_loss: 0.9121 - val_accuracy: 0.7237
Epoch 31/50
1563/1563 [==============================] - 13s 8ms/step - loss: 0.4112 - accuracy: 0.8700 - val_loss: 0.8344 - val_accuracy: 0.7439
Epoch 32/50
1563/1563 [==============================] - 13s 9ms/step - loss: 0.4218 - accuracy: 0.8680 - val_loss: 0.8552 - val_accuracy: 0.7344
Epoch 33/50
1563/1563 [==============================] - 13s 9ms/step - loss: 0.4126 - accuracy: 0.8717 - val_loss: 0.9581 - val_accuracy: 0.7406
Epoch 34/50
1563/1563 [==============================] - 13s 8ms/step - loss: 0.3781 - accuracy: 0.8813 - val_loss: 0.8410 - val_accuracy: 0.7487
Epoch 35/50
1563/1563 [==============================] - 13s 8ms/step - loss: 0.3721 - accuracy: 0.8834 - val_loss: 0.9500 - val_accuracy: 0.7443
Epoch 36/50
1563/1563 [==============================] - 13s 9ms/step - loss: 0.4450 - accuracy: 0.8625 - val_loss: 0.8621 - val_accuracy: 0.7417
Epoch 37/50
1563/1563 [==============================] - 13s 9ms/step - loss: 0.4047 - accuracy: 0.8766 - val_loss: 0.8978 - val_accuracy: 0.7062
Epoch 38/50
1563/1563 [==============================] - 13s 9ms/step - loss: 0.4170 - accuracy: 0.8731 - val_loss: 0.8555 - val_accuracy: 0.7463
Epoch 39/50
1563/1563 [==============================] - 13s 9ms/step - loss: 0.3480 - accuracy: 0.8942 - val_loss: 0.9049 - val_accuracy: 0.7334
Epoch 40/50
1563/1563 [==============================] - 13s 9ms/step - loss: 0.3411 - accuracy: 0.8963 - val_loss: 0.8682 - val_accuracy: 0.7444
Epoch 41/50
1563/1563 [==============================] - 13s 9ms/step - loss: 0.3424 - accuracy: 0.8959 - val_loss: 1.0855 - val_accuracy: 0.7106
Epoch 42/50
1563/1563 [==============================] - 13s 8ms/step - loss: 0.3578 - accuracy: 0.8929 - val_loss: 0.8307 - val_accuracy: 0.7408
Epoch 43/50
1563/1563 [==============================] - 13s 8ms/step - loss: 0.3360 - accuracy: 0.8975 - val_loss: 0.8995 - val_accuracy: 0.7546
Epoch 44/50
1563/1563 [==============================] - 13s 9ms/step - loss: 0.3221 - accuracy: 0.9034 - val_loss: 1.0236 - val_accuracy: 0.7078
Epoch 45/50
1563/1563 [==============================] - 13s 8ms/step - loss: 0.3297 - accuracy: 0.9016 - val_loss: 0.8877 - val_accuracy: 0.7476
Epoch 46/50
1563/1563 [==============================] - 13s 8ms/step - loss: 0.2986 - accuracy: 0.9103 - val_loss: 0.9974 - val_accuracy: 0.7431
Epoch 47/50
1563/1563 [==============================] - 13s 8ms/step - loss: 0.4386 - accuracy: 0.8740 - val_loss: 0.9088 - val_accuracy: 0.7584
Epoch 48/50
1563/1563 [==============================] - 13s 8ms/step - loss: 0.3015 - accuracy: 0.9116 - val_loss: 0.9738 - val_accuracy: 0.7574
Epoch 49/50
1563/1563 [==============================] - 13s 8ms/step - loss: 0.3247 - accuracy: 0.9062 - val_loss: 0.9421 - val_accuracy: 0.7454
Epoch 50/50
1563/1563 [==============================] - 13s 8ms/step - loss: 0.3210 - accuracy: 0.9075 - val_loss: 0.9764 - val_accuracy: 0.7539위에서 훈련 시킨 모델을 토대로, 모델의 분류 결과를 시각화 해보겠습니다!
import matplotlib.pyplot as plt
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
# Prediction
prediction_values = model.predict_classes(X_test)
# figure(그리기) 위한 set up
fig = plt.figure(figsize=(15, 7))
fig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.05, wspace=0.05)
# Plot 50 images with prediction
for i in range(50):
ax = fig.add_subplot(5, 10, i + 1, xticks=[], yticks=[])
ax.imshow(X_test[i,:].reshape((32,32,3)),cmap=plt.cm.gray_r, interpolation='nearest')
# If correct, label the image with the blue text
if prediction_values[i] == np.argmax(y_test[i]):
ax.text(0, 7, class_names[prediction_values[i]], color='blue')
# If wrong, label the image with the red text
else:
ax.text(0, 7, class_names[prediction_values[i]], color='red')
위의 결과를 살펴보면 기대만큼은 많이 못 맞춘것 같습니다
성능을 더욱 높이기 위해서는 image augmentaion을 통해 원본 샘플을 무작위로 변형시켜, 훈련 이미지를 확대해야 합니다
AlexNet이 남긴 의미는 다음과 같이 설명할 수 있습니다
1. 활성화 함수에서 처음으로 ReLU 함수를 도입하였습니다. 이를 통해 기존 sigmoid, tanh에서 발생하는 vanishing gradient 문제를 해결하였습니다
2. CNN에 Dropout을 적용하였습니다
3. 합성곱(convolution layer)과 Pooling layer, Dense layer, Flatten layer를 도입한 전형적인 CNN 계층구조를 갖습니다
3. VGG
VGG는 2014년 Imagenet 분류대회에서 2등을 차지하였습니다만, 이 모델이 제시한 기법은 수많은 후속 연구에 영향을 끼쳤습니다
VGG는 AlexNet이 달성했던 16.4%의 오차율을 7.3%로 획기적으로 개선하였습니다.
VGG의 아키텍쳐는 아래와 같습니다.


지금까지 가장 성능이 우수해 지금도 보편적으로 사용되는 아키텍쳐는 VGG-16, VGG-19입니다.
16과 19는 아키텍의 깊이(훈련 가능한 layer 갯수)를 의미합니다.
그럼 VGG가 남긴 의미는 무엇일까요? 지금부터 자세하게 설명드리겠습니다
1. 규모가 큰 합성곱을 여러 작은 합성곱으로 대체
3X3 커널을 갖는 두 합성곱 계층은 5X5 커널의 합성곱 계층 1개와 같은 Receptive Field(수용 영역)을 갖습니다
이를 확장시켜보면, 3x3 계층을 3개 연속으로 배치하면 7x7 1개, 3x3를 4개 연속으로 배치하면 9x9 1개와 같은 수용영역을 갖습니다
즉, 큰 거 1개를 작은 3x3로 쪼개는 것입니다. 일종의 divide & conquer 개념입니다
이렇게 잘게 쪼개면 2가지의 이점이 있습니다
첫 번째로, 매개변수를 줄이는 것입니다. 실제로 11x11의 매개변수 갯수는 121개이지만, 3x3 5개의 변수는 3x3x5 = 45개 밖에 되지 않습니다. 매개변수가 적을수록 최적화가 용이하고, 학습도 적게 시킬 수 있으며, 무엇보다 overfitting 억제가 가능합니다
두 번째로는 비선형성을 증가시키는 것입니다. 합성곱 layer수가 많아질수록, ReLu 같은 '비선형' 활성화 함수가 많아지게 되어서, 비선형 연산이 많아져, 네트워크가 복잡한 특징을 학습할 수 있는 능력이 증대됩니다.
2. 특징 맵 깊이를 증가
합성곱 연산층에서 커널의 갯수를 늘림으로써, output의 depth(커널 연산 결과)가 깊어지게 됩니다. 이를 통해 더 복잡하고 차별적인 특징을 활용하는 인코더를 사용할 수 있습니다.
3. 척도 변경을 통한 데이터 보강
원본 이미지를 아래와 같이 다양하게 resizing, cropping, flipping하면서 여러개의 이미지를 추가로 만듭니다
이를 통해서 모델이 학습할 데이터 수가 증가하면서, 모델은 다양한 이미지 척도에 대해 분류하는 방법을 학습하게 됩니다. 그 결과, 더욱 더 견고한 모델을 만들 수 있습니다

4. 완전 연결 계층(FC layer)을 합성곱 계층으로 대체
전통적인 VGG 아키텍쳐는 마지막에 여러 개의 완전 연결 계층을 둡니다
하지만 이후에 제안된 VGG 아키텍쳐는 밀집 계층을 합성곱 계층으로 대체합니다
이러한 밀집 계층을 두지 않는 네트워크를 완전 합성곱 계층(Fully convolutional network)라 부릅니다.
또한 다양한 크기의 이미지에 적용될 수 있습니다.
이제 Keras를 이용하여 직접 구현해 보겠습니다.
class VGG_16(Sequential):
def __init__(self, input_shape, num_classes):
super().__init__()
# 1st Block(Input + Conv2D + Conv2D + MaxPooling)
self.add(Conv2D(64, kernel_size=(3,3), activation='relu', padding='same', input_shape=input_shape))
self.add(Conv2D(64, kernel_size=(3,3), activation='relu', padding='same'))
self.add(MaxPooling2D(pool_size=(2,2), strides=(2,2)))
# 2nd Block(Conv2D + Conv2D + MaxPooling)
self.add(Conv2D(128, kernel_size=(3,3), padding='same', activation='relu'))
self.add(Conv2D(128, kernel_size=(3,3), padding='same', activation='relu'))
self.add(MaxPooling2D(pool_size=(2,2), strides=(2,2)))
# 3rd Block(Conv2D + Conv2D + Conv2D + MaxPooling)
self.add(Conv2D(256, kernel_size=(3,3), padding='same', activation='relu'))
self.add(Conv2D(256, kernel_size=(3,3), padding='same', activation='relu'))
self.add(Conv2D(256, kernel_size=(3,3), padding='same', activation='relu'))
self.add(MaxPooling2D(pool_size=(2,2), strides=(2,2)))
# 4th Block(Conv2D + Conv2D + Conv2D + MaxPooling)
self.add(Conv2D(512, kernel_size=(3,3), padding='same', activation='relu'))
self.add(Conv2D(512, kernel_size=(3,3), padding='same', activation='relu'))
self.add(Conv2D(512, kernel_size=(3,3), padding='same', activation='relu'))
self.add(MaxPooling2D(pool_size=(2,2), strides=(2,2)))
# 5th Block(Conv2D + Conv2D + Conv2D + MaxPooling)
self.add(Conv2D(512, kernel_size=(3,3), padding='same', activation='relu'))
self.add(Conv2D(512, kernel_size=(3,3), padding='same', activation='relu'))
self.add(Conv2D(512, kernel_size=(3,3), padding='same', activation='relu'))
self.add(MaxPooling2D(pool_size=(2,2), strides=(2,2)))
# 6th Block(FC layer
self.add(Flatten())
self.add(Dense(4096, activation='relu'))
self.add(Dense(4096, activation='relu'))
self.add(Dense(num_classes, activation='softmax'))실제 논문에서 제시된 VGG16의 구조는 위와 같습니다.
Tensorflow에서는 라이브러리에 직접 VGG16을 구현하였습니다.
위와 같이 일일이 정의해 주지 않아도 다음과 같이 사용할 수 있습니다.
vgg_net = tf.keras.applications.VGG16(
include_top=True, # 구현되어있는 VGG의 Dense layer를 포함한다는 뜻입니다. False의 경우 새로운 Dense layer를 추가해줘야합니다
weights='imagenet', # imagenet으로 사전 훈련된 weight값을 초기 weight로 갖는다는 뜻입니다
input_tensor=None, # 입력으로 받는 tensor
input_shpae=None, # 입력으로 받는 input의 shape(구조)를 의미합니다
poooling=None, # pooling의 종류를 의미합니다. 'max', 'avg'...
classes=1000 # 분류할 class의 숫자를 의미합니다
)아래의 모델은 작은 이미지 사이즈로 인하여 축소한 VGG16입니다.
import tensorflow as tf
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Input, BatchNormalization, Dropout
from tensorflow.keras.models import Model, Sequential
class cifar10_VGG16(Sequential):
def __init__(self, input_shape, num_classes):
super().__init__()
# 1st Block(Input + Conv2D + Conv2D + MaxPooling)
self.add(Conv2D(64, kernel_size=(3,3), activation='relu', padding='same', input_shape=input_shape))
self.add(Conv2D(64, kernel_size=(3,3), activation='relu', padding='same'))
self.add(BatchNormalization())
self.add(MaxPooling2D(pool_size=(2,2), strides=(2,2)))
self.add(Dropout(0.4))
# 2nd Block(Conv2D + Conv2D + MaxPooling)
self.add(Conv2D(128, kernel_size=(3,3), padding='same', activation='relu'))
self.add(Conv2D(128, kernel_size=(3,3), padding='same', activation='relu'))
self.add(BatchNormalization())
self.add(MaxPooling2D(pool_size=(2,2), strides=(2,2)))
self.add(Dropout(0.4))
# 3rd Block(Conv2D + Conv2D + MaxPooling)
self.add(Conv2D(256, kernel_size=(3,3), padding='same', activation='relu'))
self.add(Conv2D(256, kernel_size=(3,3), padding='same', activation='relu'))
self.add(MaxPooling2D(pool_size=(2,2), strides=(2,2)))
self.add(BatchNormalization())
self.add(Dropout(0.5))
# 6th Block(FC layer
self.add(Flatten())
self.add(Dense(256, activation='relu'))
self.add(Dropout(0.5))
self.add(Dense(256, activation='relu'))
self.add(Dropout(0.5))
self.add(Dense(num_classes, activation='softmax'))만든 모델의 정보를 출력해보겠습니다.
# cifar-10 info
img_height = 32
img_width = 32
img_channels = 3
input_shape = (img_height, img_width, img_channels)
num_classes = 10
# Build model
model = cifar10_VGG16(input_shape=input_shape, num_classes=num_classes)
# Print model Info
print(model.summary())Model: "cifar10_vg_g16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_7 (Conv2D) (None, 32, 32, 64) 1792
_________________________________________________________________
conv2d_8 (Conv2D) (None, 32, 32, 64) 36928
_________________________________________________________________
batch_normalization_2 (Batch (None, 32, 32, 64) 256
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 16, 16, 64) 0
_________________________________________________________________
dropout_2 (Dropout) (None, 16, 16, 64) 0
_________________________________________________________________
conv2d_9 (Conv2D) (None, 16, 16, 128) 73856
_________________________________________________________________
conv2d_10 (Conv2D) (None, 16, 16, 128) 147584
_________________________________________________________________
batch_normalization_3 (Batch (None, 16, 16, 128) 512
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 8, 8, 128) 0
_________________________________________________________________
dropout_3 (Dropout) (None, 8, 8, 128) 0
_________________________________________________________________
conv2d_11 (Conv2D) (None, 8, 8, 256) 295168
_________________________________________________________________
conv2d_12 (Conv2D) (None, 8, 8, 256) 590080
_________________________________________________________________
max_pooling2d_5 (MaxPooling2 (None, 4, 4, 256) 0
_________________________________________________________________
batch_normalization_4 (Batch (None, 4, 4, 256) 1024
_________________________________________________________________
dropout_4 (Dropout) (None, 4, 4, 256) 0
_________________________________________________________________
flatten_2 (Flatten) (None, 4096) 0
_________________________________________________________________
dense_6 (Dense) (None, 256) 1048832
_________________________________________________________________
dropout_5 (Dropout) (None, 256) 0
_________________________________________________________________
dense_7 (Dense) (None, 256) 65792
_________________________________________________________________
dropout_6 (Dropout) (None, 256) 0
_________________________________________________________________
dense_8 (Dense) (None, 10) 2570
=================================================================
Total params: 2,264,394
Trainable params: 2,263,498
Non-trainable params: 896
_________________________________________________________________
None이제 모델을 compile한 이후에, 훈련시켜 보겠습니다!
# load data
import tensorflow as tf
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.preprocessing.image import ImageDataGenerator
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
# normalize data
X_train, X_test = X_train/255.0, X_test/255.0
# Make labels to one-hot encoding labels
y_train = to_categorical(y_train)
y_test = to_categorical(y_test)
print('X_train shape:', X_train.shape)
print('X_test shape:', X_test.shape)
print('y_train shape:', y_train.shape)
print('y_test shape:', y_test.shape)X_train shape: (50000, 32, 32, 3)
X_test shape: (10000, 32, 32, 3)
y_train shape: (50000, 10)
y_test shape: (10000, 10)이제 모델을 훈련시켜보겠습니다!
# build model
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# Train
model.fit(X_train, y_train, batch_size=32, epochs=20, validation_data=(X_test,y_test))Epoch 1/20
1563/1563 [==============================] - 17s 11ms/step - loss: 2.0115 - accuracy: 0.2565 - val_loss: 1.6287 - val_accuracy: 0.4236
Epoch 2/20
1563/1563 [==============================] - 16s 10ms/step - loss: 1.5805 - accuracy: 0.4187 - val_loss: 1.3583 - val_accuracy: 0.5221
Epoch 3/20
1563/1563 [==============================] - 16s 10ms/step - loss: 1.3508 - accuracy: 0.5252 - val_loss: 1.1185 - val_accuracy: 0.6043
Epoch 4/20
1563/1563 [==============================] - 16s 10ms/step - loss: 1.1764 - accuracy: 0.5925 - val_loss: 1.1919 - val_accuracy: 0.5865
Epoch 5/20
1563/1563 [==============================] - 17s 11ms/step - loss: 1.0594 - accuracy: 0.6426 - val_loss: 0.9553 - val_accuracy: 0.6766
Epoch 6/20
1563/1563 [==============================] - 18s 11ms/step - loss: 0.9787 - accuracy: 0.6699 - val_loss: 0.9157 - val_accuracy: 0.6966
Epoch 7/20
1563/1563 [==============================] - 16s 10ms/step - loss: 0.9169 - accuracy: 0.6937 - val_loss: 0.8518 - val_accuracy: 0.7173
Epoch 8/20
1563/1563 [==============================] - 16s 10ms/step - loss: 0.8735 - accuracy: 0.7104 - val_loss: 0.8310 - val_accuracy: 0.7215
Epoch 9/20
1563/1563 [==============================] - 16s 10ms/step - loss: 0.8177 - accuracy: 0.7280 - val_loss: 0.7096 - val_accuracy: 0.7645
Epoch 10/20
1563/1563 [==============================] - 16s 10ms/step - loss: 0.7853 - accuracy: 0.7412 - val_loss: 0.6894 - val_accuracy: 0.7734
Epoch 11/20
1563/1563 [==============================] - 16s 10ms/step - loss: 0.7514 - accuracy: 0.7524 - val_loss: 0.6560 - val_accuracy: 0.7795
Epoch 12/20
1563/1563 [==============================] - 16s 10ms/step - loss: 0.7177 - accuracy: 0.7622 - val_loss: 0.6946 - val_accuracy: 0.7681
Epoch 13/20
1563/1563 [==============================] - 16s 10ms/step - loss: 0.6808 - accuracy: 0.7754 - val_loss: 0.6324 - val_accuracy: 0.7826
Epoch 14/20
1563/1563 [==============================] - 16s 10ms/step - loss: 0.6568 - accuracy: 0.7814 - val_loss: 0.5859 - val_accuracy: 0.8074
Epoch 15/20
1563/1563 [==============================] - 16s 10ms/step - loss: 0.6370 - accuracy: 0.7884 - val_loss: 0.6063 - val_accuracy: 0.7895
Epoch 16/20
1563/1563 [==============================] - 16s 10ms/step - loss: 0.6164 - accuracy: 0.7965 - val_loss: 0.6344 - val_accuracy: 0.7878
Epoch 17/20
1563/1563 [==============================] - 16s 10ms/step - loss: 0.5891 - accuracy: 0.8070 - val_loss: 0.6074 - val_accuracy: 0.7956
Epoch 18/20
1563/1563 [==============================] - 16s 10ms/step - loss: 0.5723 - accuracy: 0.8130 - val_loss: 0.5436 - val_accuracy: 0.8163
Epoch 19/20
1563/1563 [==============================] - 16s 10ms/step - loss: 0.5494 - accuracy: 0.8200 - val_loss: 0.5481 - val_accuracy: 0.8230
Epoch 20/20
1563/1563 [==============================] - 16s 10ms/step - loss: 0.5364 - accuracy: 0.8232 - val_loss: 0.5313 - val_accuracy: 0.8252모델의 분류 결과를 시각해 보겠습니다
import matplotlib.pyplot as plt
import numpy as np
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
# Prediction
prediction_values = model.predict_classes(X_test)
# figure(그리기) 위한 set up
fig = plt.figure(figsize=(15, 7))
fig.subplots_adjust(left=0, right=1, bottom=0, top=1, hspace=0.05, wspace=0.05)
# Plot 50 images with prediction
for i in range(50):
ax = fig.add_subplot(5, 10, i + 1, xticks=[], yticks=[])
ax.imshow(X_test[i,:].reshape((32,32,3)),cmap=plt.cm.gray_r, interpolation='nearest')
# If correct, label the image with the blue text
if prediction_values[i] == np.argmax(y_test[i]):
ax.text(0, 7, class_names[prediction_values[i]], color='blue')
# If wrong, label the image with the red text
else:
ax.text(0, 7, class_names[prediction_values[i]], color='red')
앞선 AlexNet보다 개선된 성능을 보여줍니다.
그러나 VGG 역시 network가 깊어질수록, backpropagation에 필요한 gradient값이 뒤에서 앞으로 갈수록 감소한다는 문제(Vanishing gradient)가 발생합니다
이로 인하여 overfitting과 같은 문제가 발생합니다.
4. GoogLeNet (Inception module)
GoogLeNet은 2014년 ILSVRC에서 1위를 하였던 모델입니다
GoogLeNet은 Google과 LeNet에서 따온 이름으로, Inception block을 담고 있다는 점에서 매우 중요합니다. 특히 Inception block을 통해 위의 VGG에서 발생한 vanishing graident를 해결하였습니다
이제 GoogLeNet의 아키텍쳐를 자세하게 살펴보겠습니다.
GoogLeNet은 AlexNet이나 VGG보다 훨씬 적은 매개변수를 가지고 있습니다.
훨씬 가벼운 모델이며, 성능역시 우수하여 인기가 시들지 않고 있습니다.
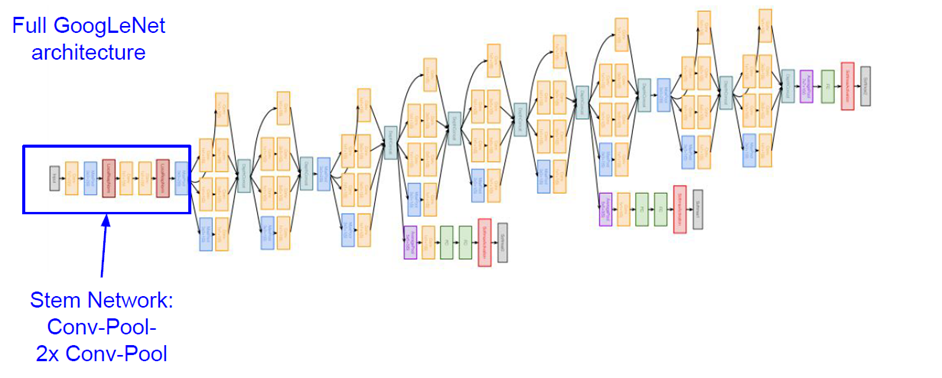
- Inception module
아래 그림과 같이 네트워크 중간중간 인셉션 모듈을 둡니다.(아래 그림서는 9개의 인셉션 모듈이 존재합니다) 각 인셉션 모듈은 다음과 같이 병렬구조로 여거개의 계층 블록으로 되어있습니다.
- No FC-layers
GoogLeNet은 마지막에 FC layer가 없는 대신에, average pooling layer를 사용합니다
이제 GoogLeNet의 중요한 특징들에 관하여 상세히 설명드리겠습니다
1. 인셉션 모듈로 세부 특징 잡아내기
기본 인셉션 모듈은 3개의 합성곱 계층과 1개의 maxPooling으로 구성됩니다.
각 계층의 결과를 하나로 연결해 최종 결과를 만드는 이 병렬 처리의 이점은 여러가지가 있습니다
먼저 다양한 데이터의 처리를 가능하게 해줍니다
각 인셉션 모듈의 결과는 다양한 척도의 특징을 결합하여 광범위한 정보를 잡아냅니다
이 경우 최선의 커널 크기를 정해주지 않아도 된다는 장점이 있습니다
즉, 네트워크가 각 모듈에 대해 어느 합성곱 계층에 의존하였는지를 학습합니다
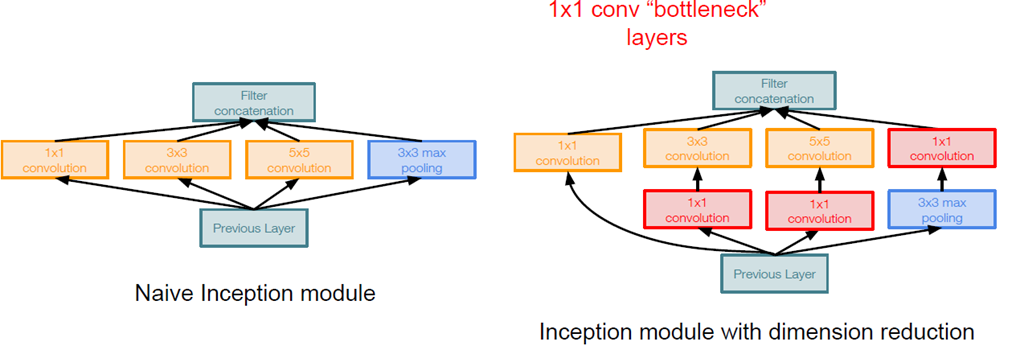
2. 병목 계층으로 1x1 합성곱 계층을 사용
1x1 합성곱 계층은 모델의 구조에 영향을 주지 않고 깊이를 변경하기 위해 사용됩니다
예를 들어 N개의 1x1필터를 갖는 계층은 입력이 HxWxD인 경우 HxWxN을 결과로 반환합니다
이 속성을 잘 사용하면은, N<D인 경우 특징 깊이를 줄임으로써 매개변수의 갯수를 줄일 수 있습니다.
3. 완전 연결 계층 대신 풀링 계층의 사용
앞서 위에서 설명드렸다 싶이, 완전 연결 계층(FC layer)대신 average Pooling을 이용하여 매개변수의 수를 줄였습니다. 물론 pooling을 이용하면 네트워크가 표현력을 약간 잃게 되지만, 줄어드는 계산량의 이익이 더 큽니다
4. 중간 손실로 경사 소실 문제 해결하기
GoogLeNet은 auxiliary classifier를 중간에 두어서 Vanishing gradient의 문제를 해결합니다 각각의 auxiliary classifier에서 분류한 결과를 이용하여 gradient값을 이용하여 각각 update를 해줍니다. 즉,깊은 구조를 여러개의 auxiliary classifier의 도입을 통해 divide & conquer 한다고 생각하면 될 것 같습니다**
아래에서는 처음 논문에 제시된 GoogLeNet을 직접 구현해보겠습니다
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, Flatten, Input
def Inception_block(input_layer, f1, f2_conv1, f2_conv3, f3_conv1, f3_conv5, f4):
# Input:
# - f1: number of filters of the 1x1 convolutional layer in the first path
# - f2_conv1, f2_conv3 are number of filters corresponding to the 1x1 and 3x3 convolutional layers in the second path
# - f3_conv1, f3_conv5 are the number of filters corresponding to the 1x1 and 5x5 convolutional layer in the third path
# - f4: number of filters of the 1x1 convolutional layer in the fourth path
# 1st path:
path1 = Conv2D(filters=f1, kernel_size = (1,1), padding = 'same', activation = 'relu')(input_layer)
# 2nd path
path2 = Conv2D(filters = f2_conv1, kernel_size = (1,1), padding = 'same', activation = 'relu')(input_layer)
path2 = Conv2D(filters = f2_conv3, kernel_size = (3,3), padding = 'same', activation = 'relu')(path2)
# 3rd path
path3 = Conv2D(filters = f3_conv1, kernel_size = (1,1), padding = 'same', activation = 'relu')(input_layer)
path3 = Conv2D(filters = f3_conv5, kernel_size = (5,5), padding = 'same', activation = 'relu')(path3)
# 4th path
path4 = MaxPooling2D((3,3), strides= (1,1), padding = 'same')(input_layer)
path4 = Conv2D(filters = f4, kernel_size = (1,1), padding = 'same', activation = 'relu')(path4)
output_layer = concatenate([path1, path2, path3, path4], axis = -1)
return output_layer
def GoogLeNet():
# input layer
input_layer = Input(shape = (224, 224, 3))
# convolutional layer: filters = 64, kernel_size = (7,7), strides = 2
X = Conv2D(filters = 64, kernel_size = (7,7), strides = 2, padding = 'valid', activation = 'relu')(input_layer)
# max-pooling layer: pool_size = (3,3), strides = 2
X = MaxPooling2D(pool_size = (3,3), strides = 2)(X)
# convolutional layer: filters = 64, strides = 1
X = Conv2D(filters = 64, kernel_size = (1,1), strides = 1, padding = 'same', activation = 'relu')(X)
# convolutional layer: filters = 192, kernel_size = (3,3)
X = Conv2D(filters = 192, kernel_size = (3,3), padding = 'same', activation = 'relu')(X)
# max-pooling layer: pool_size = (3,3), strides = 2
X = MaxPooling2D(pool_size= (3,3), strides = 2)(X)
# 1st Inception block
X = Inception_block(X, f1 = 64, f2_conv1 = 96, f2_conv3 = 128, f3_conv1 = 16, f3_conv5 = 32, f4 = 32)
# 2nd Inception block
X = Inception_block(X, f1 = 128, f2_conv1 = 128, f2_conv3 = 192, f3_conv1 = 32, f3_conv5 = 96, f4 = 64)
# max-pooling layer: pool_size = (3,3), strides = 2
X = MaxPooling2D(pool_size= (3,3), strides = 2)(X)
# 3rd Inception block
X = Inception_block(X, f1 = 192, f2_conv1 = 96, f2_conv3 = 208, f3_conv1 = 16, f3_conv5 = 48, f4 = 64)
# Extra network 1:
X1 = AveragePooling2D(pool_size = (5,5), strides = 3)(X)
X1 = Conv2D(filters = 128, kernel_size = (1,1), padding = 'same', activation = 'relu')(X1)
X1 = Flatten()(X1)
X1 = Dense(1024, activation = 'relu')(X1)
X1 = Dropout(0.7)(X1)
X1 = Dense(5, activation = 'softmax')(X1)
# 4th Inception block
X = Inception_block(X, f1 = 160, f2_conv1 = 112, f2_conv3 = 224, f3_conv1 = 24, f3_conv5 = 64, f4 = 64)
# 5th Inception block
X = Inception_block(X, f1 = 128, f2_conv1 = 128, f2_conv3 = 256, f3_conv1 = 24, f3_conv5 = 64, f4 = 64)
# 6th Inception block
X = Inception_block(X, f1 = 112, f2_conv1 = 144, f2_conv3 = 288, f3_conv1 = 32, f3_conv5 = 64, f4 = 64)
# Extra network 2:
X2 = AveragePooling2D(pool_size = (5,5), strides = 3)(X)
X2 = Conv2D(filters = 128, kernel_size = (1,1), padding = 'same', activation = 'relu')(X2)
X2 = Flatten()(X2)
X2 = Dense(1024, activation = 'relu')(X2)
X2 = Dropout(0.7)(X2)
X2 = Dense(1000, activation = 'softmax')(X2)
# 7th Inception block
X = Inception_block(X, f1 = 256, f2_conv1 = 160, f2_conv3 = 320, f3_conv1 = 32,
f3_conv5 = 128, f4 = 128)
# max-pooling layer: pool_size = (3,3), strides = 2
X = MaxPooling2D(pool_size = (3,3), strides = 2)(X)
# 8th Inception block
X = Inception_block(X, f1 = 256, f2_conv1 = 160, f2_conv3 = 320, f3_conv1 = 32, f3_conv5 = 128, f4 = 128)
# 9th Inception block
X = Inception_block(X, f1 = 384, f2_conv1 = 192, f2_conv3 = 384, f3_conv1 = 48, f3_conv5 = 128, f4 = 128)
# Global Average pooling layer
X = GlobalAveragePooling2D(name = 'GAPL')(X)
# Dropoutlayer
X = Dropout(0.4)(X)
# output layer
X = Dense(1000, activation = 'softmax')(X)
# model
model = Model(input_layer, [X, X1, X2], name = 'GoogLeNet')
return modelKeras에서는 VGG와 마찬가지로 모듈로 개선된 GoogLeNet을 제공하고 있습니다.
import tensorflow as tf
model = tf.keras.applications.InceptionV3()
print(model.summary())Model: "inception_v3"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_2 (InputLayer) [(None, 299, 299, 3) 0
__________________________________________________________________________________________________
conv2d_94 (Conv2D) (None, 149, 149, 32) 864 input_2[0][0]
__________________________________________________________________________________________________
batch_normalization_94 (BatchNo (None, 149, 149, 32) 96 conv2d_94[0][0]
__________________________________________________________________________________________________
activation_94 (Activation) (None, 149, 149, 32) 0 batch_normalization_94[0][0]
__________________________________________________________________________________________________
conv2d_95 (Conv2D) (None, 147, 147, 32) 9216 activation_94[0][0]
__________________________________________________________________________________________________
batch_normalization_95 (BatchNo (None, 147, 147, 32) 96 conv2d_95[0][0]
__________________________________________________________________________________________________
activation_95 (Activation) (None, 147, 147, 32) 0 batch_normalization_95[0][0]
__________________________________________________________________________________________________
conv2d_96 (Conv2D) (None, 147, 147, 64) 18432 activation_95[0][0]
...
...
...
concatenate_3 (Concatenate) (None, 8, 8, 768) 0 activation_185[0][0]
activation_186[0][0]
__________________________________________________________________________________________________
activation_187 (Activation) (None, 8, 8, 192) 0 batch_normalization_187[0][0]
__________________________________________________________________________________________________
mixed10 (Concatenate) (None, 8, 8, 2048) 0 activation_179[0][0]
mixed9_1[0][0]
concatenate_3[0][0]
activation_187[0][0]
__________________________________________________________________________________________________
avg_pool (GlobalAveragePooling2 (None, 2048) 0 mixed10[0][0]
__________________________________________________________________________________________________
predictions (Dense) (None, 1000) 2049000 avg_pool[0][0]
==================================================================================================
Total params: 23,851,784
Trainable params: 23,817,352
Non-trainable params: 34,432
__________________________________________________________________________________________________
None다음은 tensorflow dataset에 있는 flower data를 이용하여 모델을 학습시켜보겠습니다.
# Load data
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow.keras.utils import to_categorical
(training, validation), dataset_info = tfds.load(
'tf_flowers',
split=['train[:70%]','train[70%:]'],
with_info=True,
as_supervised=True,
shuffle_files=True,
)
# print dataset Info
# dataset_info
# Print number of classes, Training images, Validation Images
num_classes = dataset_info.features['label'].num_classes
print('classes:',num_classes)
num_train = 0
num_val = 0
for elem in training:
num_train += 1
for elem in validation:
num_val += 1
print('Training:',num_train)
print('Validation:',num_val)classes: 5
Training: 2569
Validation: 1101# Resizing images
import numpy as np
IMAGE_RES = 299
Batch_size = 32
def format_image(image, label):
image = tf.image.resize(image,(IMAGE_RES, IMAGE_RES))/255.0 # normalize
return image, label
train = training.shuffle(num_train//4).map(format_image).batch(Batch_size).prefetch(1) # mapping을 이용하여 shuffle 해준다
validation = validation.map(format_image).batch(Batch_size).prefetch(1)이제 모델을 훈련시켜보겠습니다
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Train
model.fit(train, batch_size=Batch_size, epochs=20, validation_data=validation)Epoch 1/20
81/81 [==============================] - 17s 157ms/step - loss: 0.8240 - accuracy: 0.7641 - val_loss: 1.9465 - val_accuracy: 0.5604
Epoch 2/20
81/81 [==============================] - 11s 131ms/step - loss: 0.4616 - accuracy: 0.8431 - val_loss: 14.6742 - val_accuracy: 0.2461
Epoch 3/20
81/81 [==============================] - 11s 130ms/step - loss: 0.3368 - accuracy: 0.8789 - val_loss: 0.9251 - val_accuracy: 0.7375
Epoch 4/20
81/81 [==============================] - 11s 130ms/step - loss: 0.2586 - accuracy: 0.9136 - val_loss: 1.1546 - val_accuracy: 0.7530
Epoch 5/20
81/81 [==============================] - 11s 130ms/step - loss: 0.2096 - accuracy: 0.9311 - val_loss: 1.3947 - val_accuracy: 0.6585
Epoch 6/20
81/81 [==============================] - 11s 131ms/step - loss: 0.2436 - accuracy: 0.9214 - val_loss: 1.3072 - val_accuracy: 0.7684
Epoch 7/20
81/81 [==============================] - 11s 128ms/step - loss: 0.1480 - accuracy: 0.9510 - val_loss: 4.4865 - val_accuracy: 0.4968
Epoch 8/20
81/81 [==============================] - 11s 131ms/step - loss: 0.1266 - accuracy: 0.9564 - val_loss: 1.5832 - val_accuracy: 0.7021
Epoch 9/20
81/81 [==============================] - 11s 130ms/step - loss: 0.1667 - accuracy: 0.9447 - val_loss: 2.1813 - val_accuracy: 0.7184
Epoch 10/20
81/81 [==============================] - 11s 130ms/step - loss: 0.1655 - accuracy: 0.9463 - val_loss: 0.9540 - val_accuracy: 0.7611
Epoch 11/20
81/81 [==============================] - 11s 129ms/step - loss: 0.1882 - accuracy: 0.9366 - val_loss: 1.0167 - val_accuracy: 0.7257
Epoch 12/20
81/81 [==============================] - 11s 131ms/step - loss: 0.0853 - accuracy: 0.9708 - val_loss: 0.4935 - val_accuracy: 0.8411
Epoch 13/20
81/81 [==============================] - 11s 130ms/step - loss: 0.0562 - accuracy: 0.9829 - val_loss: 2.0963 - val_accuracy: 0.7094
Epoch 14/20
81/81 [==============================] - 11s 130ms/step - loss: 0.0307 - accuracy: 0.9910 - val_loss: 0.6281 - val_accuracy: 0.8256
Epoch 15/20
81/81 [==============================] - 11s 130ms/step - loss: 0.1589 - accuracy: 0.9502 - val_loss: 8.4738 - val_accuracy: 0.3760
Epoch 16/20
81/81 [==============================] - 11s 132ms/step - loss: 0.1274 - accuracy: 0.9572 - val_loss: 1.2884 - val_accuracy: 0.7393
Epoch 17/20
81/81 [==============================] - 11s 130ms/step - loss: 0.0858 - accuracy: 0.9716 - val_loss: 0.4300 - val_accuracy: 0.8847
Epoch 18/20
81/81 [==============================] - 11s 130ms/step - loss: 0.0802 - accuracy: 0.9731 - val_loss: 0.9894 - val_accuracy: 0.8038
Epoch 19/20
81/81 [==============================] - 11s 130ms/step - loss: 0.0944 - accuracy: 0.9724 - val_loss: 1.4304 - val_accuracy: 0.7257
Epoch 20/20
81/81 [==============================] - 11s 132ms/step - loss: 0.1000 - accuracy: 0.9661 - val_loss: 0.4190 - val_accuracy: 0.8629모델의 예측 결과를 시각화 해보겠습니다! 정답인 경우에는 파란색, 오답인 경우는 빨간색으로 표시하였습니다
import matplotlib.pyplot as plt
class_names = np.array(dataset_info.features['label'].names)
image_batch, label_batch = next(iter(train))
image_batch = image_batch.numpy()
label_batch = label_batch.numpy()
predicted_batch = model.predict(image_batch)
predicted_batch = tf.squeeze(predicted_batch).numpy()
predicted_ids = np.argmax(predicted_batch, axis=-1)
predicted_class_names = class_names[predicted_ids]
plt.figure(figsize=(10,10))
for n in range(30):
plt.subplot(6,5,n+1)
plt.subplots_adjust(hspace = 0.3)
plt.imshow(image_batch[n])
color = "blue" if predicted_ids[n] == label_batch[n] else "red"
plt.title(predicted_class_names[n].title(), color=color)
plt.axis('off')
_ = plt.suptitle("Model predictions (blue: correct, red: incorrect)")
위의 결과를 보면 25개중 3개를 틀렸는데요, 꽤 정확하게 훈련된 것 같습니다!
5. ResNet
ResNet은 2015년 ILSVRC에서 우승한 아키텍쳐입니다
특히 ResNet은 새로운 유형의 residual connection을 통해 상당히 깊은 네트워크를 효율적으로 생성할 수 있는 방법을 제공하여 성능을 높였습니다
특히 아래와 같이 Residual block을 통한 skip connection을 통해 기존보다 계산해야 할 연산량을 줄였습니다
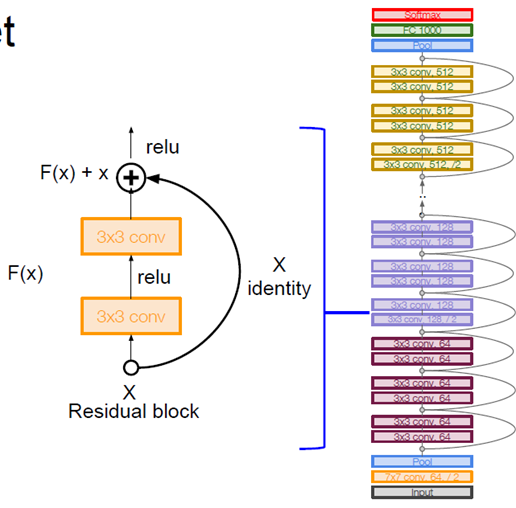
지금부터는 ResNet이 왜 깊은 network에서도 학습이 되는지에 대해서 알아보겠습니다
기존의 Deep한 Network의 문제점은 바로 Vanishing gradient였습니다
앞쪽 layer로 갈수록 back propagation에서, weight 갱신 값이 줄어들어 0이 되어 학습이 안되는 현상이 발생하는 것입니다
ResNet은 이 문제를 이전 layer를 skip connection으로 다음 layer에 연결시켜서, gradient vanishing을 해결합니다 ResNet은 각 layer의 입력이 다른 구조의 network의 출력이 됩니다. 모든 layer들이 연결되어 깊은 신경망을 형성할 수 있는 것이지요
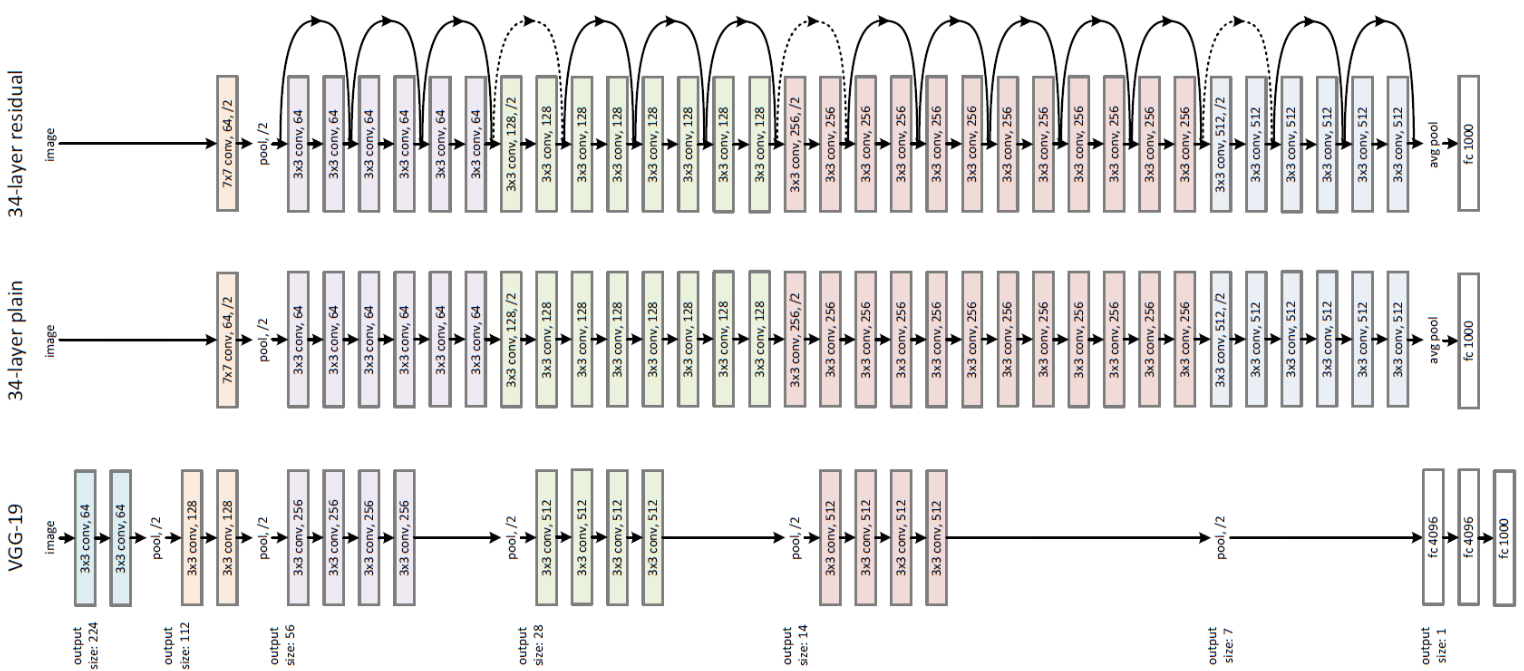
하지만 ResNet이 vanishing gradient를 완전히 해결한 것은 아니며, 많은 논문들이 이를 다루고 있습니다
또한 ResNet-50+ 이상의 모델들은 GoogLeNet과 마찬가지로 'bottleneck'을 사용하여서, efficiency를 높입니다
이제 keras을 이용하여 ResNet-50을 직접 구현해 보도록 하겠습니다
from keras import models, layers
from keras import Input
from keras.models import Model, load_model
from keras.preprocessing.image import ImageDataGenerator
from keras import optimizers, initializers, regularizers, metrics
from keras.callbacks import ModelCheckpoint, EarlyStopping
from keras.layers import BatchNormalization, Conv2D, Activation, Dense, GlobalAveragePooling2D, MaxPooling2D, ZeroPadding2D, Add
import os
import matplotlib.pyplot as plt
import numpy as np
import math
# number of classes
K = 4
input_tensor = Input(shape=(224, 224, 3), dtype='float32', name='input')
def conv1_layer(x):
x = ZeroPadding2D(padding=(3, 3))(x)
x = Conv2D(64, (7, 7), strides=(2, 2))(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = ZeroPadding2D(padding=(1,1))(x)
return x
def conv2_layer(x):
x = MaxPooling2D((3, 3), 2)(x)
shortcut = x
for i in range(3):
if (i == 0):
x = Conv2D(64, (1, 1), strides=(1, 1), padding='valid')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(64, (3, 3), strides=(1, 1), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(256, (1, 1), strides=(1, 1), padding='valid')(x)
shortcut = Conv2D(256, (1, 1), strides=(1, 1), padding='valid')(shortcut)
x = BatchNormalization()(x)
shortcut = BatchNormalization()(shortcut)
x = Add()([x, shortcut])
x = Activation('relu')(x)
shortcut = x
else:
x = Conv2D(64, (1, 1), strides=(1, 1), padding='valid')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(64, (3, 3), strides=(1, 1), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(256, (1, 1), strides=(1, 1), padding='valid')(x)
x = BatchNormalization()(x)
x = Add()([x, shortcut])
x = Activation('relu')(x)
shortcut = x
return x
def conv3_layer(x):
shortcut = x
for i in range(4):
if(i == 0):
x = Conv2D(128, (1, 1), strides=(2, 2), padding='valid')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(128, (3, 3), strides=(1, 1), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(512, (1, 1), strides=(1, 1), padding='valid')(x)
shortcut = Conv2D(512, (1, 1), strides=(2, 2), padding='valid')(shortcut)
x = BatchNormalization()(x)
shortcut = BatchNormalization()(shortcut)
x = Add()([x, shortcut])
x = Activation('relu')(x)
shortcut = x
else:
x = Conv2D(128, (1, 1), strides=(1, 1), padding='valid')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(128, (3, 3), strides=(1, 1), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(512, (1, 1), strides=(1, 1), padding='valid')(x)
x = BatchNormalization()(x)
x = Add()([x, shortcut])
x = Activation('relu')(x)
shortcut = x
return x
def conv4_layer(x):
shortcut = x
for i in range(6):
if(i == 0):
x = Conv2D(256, (1, 1), strides=(2, 2), padding='valid')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(256, (3, 3), strides=(1, 1), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(1024, (1, 1), strides=(1, 1), padding='valid')(x)
shortcut = Conv2D(1024, (1, 1), strides=(2, 2), padding='valid')(shortcut)
x = BatchNormalization()(x)
shortcut = BatchNormalization()(shortcut)
x = Add()([x, shortcut])
x = Activation('relu')(x)
shortcut = x
else:
x = Conv2D(256, (1, 1), strides=(1, 1), padding='valid')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(256, (3, 3), strides=(1, 1), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(1024, (1, 1), strides=(1, 1), padding='valid')(x)
x = BatchNormalization()(x)
x = Add()([x, shortcut])
x = Activation('relu')(x)
shortcut = x
return x
def conv5_layer(x):
shortcut = x
for i in range(3):
if(i == 0):
x = Conv2D(512, (1, 1), strides=(2, 2), padding='valid')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(512, (3, 3), strides=(1, 1), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(2048, (1, 1), strides=(1, 1), padding='valid')(x)
shortcut = Conv2D(2048, (1, 1), strides=(2, 2), padding='valid')(shortcut)
x = BatchNormalization()(x)
shortcut = BatchNormalization()(shortcut)
x = Add()([x, shortcut])
x = Activation('relu')(x)
shortcut = x
else:
x = Conv2D(512, (1, 1), strides=(1, 1), padding='valid')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(512, (3, 3), strides=(1, 1), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(2048, (1, 1), strides=(1, 1), padding='valid')(x)
x = BatchNormalization()(x)
x = Add()([x, shortcut])
x = Activation('relu')(x)
shortcut = x
return x
x = conv1_layer(input_tensor)
x = conv2_layer(x)
x = conv3_layer(x)
x = conv4_layer(x)
x = conv5_layer(x)
x = GlobalAveragePooling2D()(x)
output_tensor = Dense(K, activation='softmax')(x)
resnet50 = Model(input_tensor, output_tensor)
resnet50.summary()Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input (InputLayer) [(None, 224, 224, 3) 0
__________________________________________________________________________________________________
zero_padding2d (ZeroPadding2D) (None, 230, 230, 3) 0 input[0][0]
__________________________________________________________________________________________________
conv2d (Conv2D) (None, 112, 112, 64) 9472 zero_padding2d[0][0]
__________________________________________________________________________________________________
batch_normalization (BatchNorma (None, 112, 112, 64) 256 conv2d[0][0]
__________________________________________________________________________________________________
activation (Activation) (None, 112, 112, 64) 0 batch_normalization[0][0]
__________________________________________________________________________________________________
zero_padding2d_1 (ZeroPadding2D (None, 114, 114, 64) 0 activation[0][0]
__________________________________________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 56, 56, 64) 0 zero_padding2d_1[0][0]
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, 56, 56, 64) 4160 max_pooling2d[0][0]
...
...
...
conv2d_52 (Conv2D) (None, 7, 7, 2048) 1050624 activation_47[0][0]
__________________________________________________________________________________________________
batch_normalization_52 (BatchNo (None, 7, 7, 2048) 8192 conv2d_52[0][0]
__________________________________________________________________________________________________
add_15 (Add) (None, 7, 7, 2048) 0 batch_normalization_52[0][0]
activation_45[0][0]
__________________________________________________________________________________________________
activation_48 (Activation) (None, 7, 7, 2048) 0 add_15[0][0]
__________________________________________________________________________________________________
global_average_pooling2d (Globa (None, 2048) 0 activation_48[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, 4) 8196 global_average_pooling2d[0][0]
==================================================================================================
Total params: 23,595,908
Trainable params: 23,542,788
Non-trainable params: 53,120또한, tensorflow 모듈을 통해서 ResNet50을 불러올 수 있습니다
import tensorflow as tf
Resnet50 = tf.keras.applications.resnet50.ResNet50(
include_top=True,
weights='imagenet', # imagnet을 통해 사전학습시킨 가중치를 초기값으로 사용
input_shape=None,
input_tensor=None,
pooling=None,
classes=1000
)
print(Resnet50.summary())Model: "resnet50"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_3 (InputLayer) [(None, 224, 224, 3) 0
__________________________________________________________________________________________________
conv1_pad (ZeroPadding2D) (None, 230, 230, 3) 0 input_3[0][0]
__________________________________________________________________________________________________
conv1_conv (Conv2D) (None, 112, 112, 64) 9472 conv1_pad[0][0]
__________________________________________________________________________________________________
conv1_bn (BatchNormalization) (None, 112, 112, 64) 256 conv1_conv[0][0]
__________________________________________________________________________________________________
conv1_relu (Activation) (None, 112, 112, 64) 0 conv1_bn[0][0]
__________________________________________________________________________________________________
pool1_pad (ZeroPadding2D) (None, 114, 114, 64) 0 conv1_relu[0][0]
__________________________________________________________________________________________________
pool1_pool (MaxPooling2D) (None, 56, 56, 64) 0 pool1_pad[0][0]
__________________________________________________________________________________________________
conv2_block1_1_conv (Conv2D) (None, 56, 56, 64) 4160 pool1_pool[0][0]
__________________________________________________________________________________________________
...
...
...
conv5_block3_3_bn (BatchNormali (None, 7, 7, 2048) 8192 conv5_block3_3_conv[0][0]
__________________________________________________________________________________________________
conv5_block3_add (Add) (None, 7, 7, 2048) 0 conv5_block2_out[0][0]
conv5_block3_3_bn[0][0]
__________________________________________________________________________________________________
conv5_block3_out (Activation) (None, 7, 7, 2048) 0 conv5_block3_add[0][0]
__________________________________________________________________________________________________
avg_pool (GlobalAveragePooling2 (None, 2048) 0 conv5_block3_out[0][0]
__________________________________________________________________________________________________
predictions (Dense) (None, 1000) 2049000 avg_pool[0][0]
==================================================================================================
Total params: 25,636,712
Trainable params: 25,583,592
Non-trainable params: 53,120
__________________________________________________________________________________________________
None이제 위에서 사용한 flower데이터를 이용하여 ResNet을 훈련시켜보겠습니다
# Load data
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow.keras.utils import to_categorical
import numpy as np
(training, validation), dataset_info = tfds.load(
'tf_flowers',
split=['train[:70%]','train[70%:]'],
with_info=True,
as_supervised=True,
shuffle_files=True,
)
# Print number of classes, Training images, Validation Images
num_classes = dataset_info.features['label'].num_classes
num_train = 0
num_val = 0
for elem in training:
num_train += 1
for elem in validation:
num_val += 1
IMAGE_RES = 224
Batch_size = 32
def format_image(image, label):
image = tf.image.resize(image,(IMAGE_RES, IMAGE_RES))/255.0 # normalize
return image, label
train = training.shuffle(num_train//4).map(format_image).batch(Batch_size).prefetch(1) # mapping을 이용하여 shuffle 해준다
validation = validation.map(format_image).batch(Batch_size).prefetch(1)
# Compile & train model
Resnet50.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# Train
Resnet50.fit(train, batch_size=Batch_size, epochs=40, validation_data=validation)Epoch 1/40
81/81 [==============================] - 13s 114ms/step - loss: 1.2391 - accuracy: 0.6816 - val_loss: 2.1079 - val_accuracy: 0.2352
Epoch 2/40
81/81 [==============================] - 8s 100ms/step - loss: 0.4924 - accuracy: 0.8307 - val_loss: 2.5324 - val_accuracy: 0.2352
Epoch 3/40
81/81 [==============================] - 8s 100ms/step - loss: 0.3286 - accuracy: 0.8906 - val_loss: 3.9270 - val_accuracy: 0.2352
Epoch 4/40
81/81 [==============================] - 8s 100ms/step - loss: 0.2089 - accuracy: 0.9249 - val_loss: 2.6711 - val_accuracy: 0.2352
Epoch 5/40
81/81 [==============================] - 8s 100ms/step - loss: 0.1750 - accuracy: 0.9408 - val_loss: 4.3946 - val_accuracy: 0.2352
Epoch 6/40
81/81 [==============================] - 8s 101ms/step - loss: 0.2218 - accuracy: 0.9233 - val_loss: 2.5345 - val_accuracy: 0.2352
Epoch 7/40
81/81 [==============================] - 8s 100ms/step - loss: 0.1413 - accuracy: 0.9498 - val_loss: 2.2298 - val_accuracy: 0.1390
Epoch 8/40
81/81 [==============================] - 8s 100ms/step - loss: 0.0846 - accuracy: 0.9728 - val_loss: 1.4481 - val_accuracy: 0.4968
Epoch 9/40
81/81 [==============================] - 8s 101ms/step - loss: 0.0863 - accuracy: 0.9751 - val_loss: 2.1628 - val_accuracy: 0.5232
Epoch 10/40
81/81 [==============================] - 8s 100ms/step - loss: 0.1704 - accuracy: 0.9436 - val_loss: 1.2840 - val_accuracy: 0.6222
Epoch 11/40
81/81 [==============================] - 8s 101ms/step - loss: 0.1062 - accuracy: 0.9615 - val_loss: 0.8423 - val_accuracy: 0.7421
Epoch 12/40
81/81 [==============================] - 8s 100ms/step - loss: 0.0959 - accuracy: 0.9665 - val_loss: 0.6714 - val_accuracy: 0.8156
Epoch 13/40
81/81 [==============================] - 8s 99ms/step - loss: 0.0862 - accuracy: 0.9731 - val_loss: 0.8677 - val_accuracy: 0.7811
Epoch 14/40
81/81 [==============================] - 8s 100ms/step - loss: 0.0307 - accuracy: 0.9903 - val_loss: 0.5419 - val_accuracy: 0.8329
Epoch 15/40
81/81 [==============================] - 8s 100ms/step - loss: 0.0241 - accuracy: 0.9910 - val_loss: 0.5301 - val_accuracy: 0.8547
Epoch 16/40
81/81 [==============================] - 8s 100ms/step - loss: 0.0287 - accuracy: 0.9910 - val_loss: 0.5812 - val_accuracy: 0.8302
Epoch 17/40
81/81 [==============================] - 8s 100ms/step - loss: 0.0280 - accuracy: 0.9926 - val_loss: 0.7899 - val_accuracy: 0.8084
Epoch 18/40
81/81 [==============================] - 8s 100ms/step - loss: 0.0969 - accuracy: 0.9685 - val_loss: 1.1199 - val_accuracy: 0.7566
Epoch 19/40
81/81 [==============================] - 8s 100ms/step - loss: 0.1015 - accuracy: 0.9677 - val_loss: 1.2726 - val_accuracy: 0.7284
Epoch 20/40
81/81 [==============================] - 8s 100ms/step - loss: 0.0424 - accuracy: 0.9848 - val_loss: 0.7804 - val_accuracy: 0.8247
Epoch 21/40
81/81 [==============================] - 8s 101ms/step - loss: 0.0509 - accuracy: 0.9837 - val_loss: 2.2831 - val_accuracy: 0.6540
Epoch 22/40
81/81 [==============================] - 8s 100ms/step - loss: 0.0728 - accuracy: 0.9763 - val_loss: 1.7499 - val_accuracy: 0.6521
Epoch 23/40
81/81 [==============================] - 8s 100ms/step - loss: 0.1139 - accuracy: 0.9650 - val_loss: 1.8594 - val_accuracy: 0.6921
Epoch 24/40
81/81 [==============================] - 8s 101ms/step - loss: 0.0648 - accuracy: 0.9786 - val_loss: 0.5513 - val_accuracy: 0.8411
Epoch 25/40
81/81 [==============================] - 8s 100ms/step - loss: 0.0437 - accuracy: 0.9864 - val_loss: 1.0012 - val_accuracy: 0.7675
Epoch 26/40
81/81 [==============================] - 8s 101ms/step - loss: 0.0322 - accuracy: 0.9903 - val_loss: 0.8119 - val_accuracy: 0.8365
Epoch 27/40
81/81 [==============================] - 8s 101ms/step - loss: 0.0185 - accuracy: 0.9957 - val_loss: 0.5238 - val_accuracy: 0.8728
Epoch 28/40
81/81 [==============================] - 8s 100ms/step - loss: 0.0124 - accuracy: 0.9953 - val_loss: 0.5409 - val_accuracy: 0.8683
Epoch 29/40
81/81 [==============================] - 8s 100ms/step - loss: 0.0775 - accuracy: 0.9770 - val_loss: 0.8802 - val_accuracy: 0.7838
Epoch 30/40
81/81 [==============================] - 8s 101ms/step - loss: 0.0203 - accuracy: 0.9934 - val_loss: 1.1730 - val_accuracy: 0.7738
Epoch 31/40
81/81 [==============================] - 8s 100ms/step - loss: 0.0361 - accuracy: 0.9879 - val_loss: 2.0849 - val_accuracy: 0.6358
Epoch 32/40
81/81 [==============================] - 8s 101ms/step - loss: 0.0709 - accuracy: 0.9778 - val_loss: 1.1464 - val_accuracy: 0.7548
Epoch 33/40
81/81 [==============================] - 8s 100ms/step - loss: 0.0353 - accuracy: 0.9895 - val_loss: 0.8874 - val_accuracy: 0.7602
Epoch 34/40
81/81 [==============================] - 8s 101ms/step - loss: 0.0222 - accuracy: 0.9934 - val_loss: 1.3508 - val_accuracy: 0.7166
Epoch 35/40
81/81 [==============================] - 8s 101ms/step - loss: 0.0254 - accuracy: 0.9914 - val_loss: 0.9432 - val_accuracy: 0.8002
Epoch 36/40
81/81 [==============================] - 8s 100ms/step - loss: 0.0564 - accuracy: 0.9833 - val_loss: 1.1578 - val_accuracy: 0.7221
Epoch 37/40
81/81 [==============================] - 8s 100ms/step - loss: 0.0629 - accuracy: 0.9778 - val_loss: 0.7517 - val_accuracy: 0.8120
Epoch 38/40
81/81 [==============================] - 8s 100ms/step - loss: 0.0296 - accuracy: 0.9895 - val_loss: 2.1037 - val_accuracy: 0.7003
Epoch 39/40
81/81 [==============================] - 8s 100ms/step - loss: 0.0502 - accuracy: 0.9860 - val_loss: 1.1215 - val_accuracy: 0.7430
Epoch 40/40
81/81 [==============================] - 8s 100ms/step - loss: 0.0979 - accuracy: 0.9689 - val_loss: 1.0381 - val_accuracy: 0.7657이제 모델의 예측결과를 시각화 해보겠습니다!
class_names = np.array(dataset_info.features['label'].names)
image_batch, label_batch = next(iter(train))
image_batch = image_batch.numpy()
label_batch = label_batch.numpy()
predicted_batch = Resnet50.predict(image_batch)
predicted_batch = tf.squeeze(predicted_batch).numpy()
predicted_ids = np.argmax(predicted_batch, axis=-1)
predicted_class_names = class_names[predicted_ids]
plt.figure(figsize=(10,10))
for n in range(30):
plt.subplot(6,5,n+1)
plt.subplots_adjust(hspace = 0.3)
plt.imshow(image_batch[n])
color = "blue" if predicted_ids[n] == label_batch[n] else "red"
plt.title(predicted_class_names[n].title(), color=color)
plt.axis('off')
_ = plt.suptitle("Model predictions (blue: correct, red: incorrect)")
ResNet을 이용하여 잘 분류되는 것을 확인 할 수 있었습니다
Reference
- 실전! 텐서플로 2로 배우는 컴퓨터 비전 딥러닝 chapter 03
- 경희대학교 소프트웨어융합학과 로봇센서데이터 수업 lecture note
