[번역] 더 강력해진 React Query 셀렉터
이 글은 tkdodo의 블로그 30번째 글을 번역했습니다.
select. React Query에서 내가 특히 좋아하는 기능 중 하나다. 가능하면 쓸 일이 없길 바라지만, 막상 필요할 땐 그 어떤 도구보다 효과적일 수 있다.
select는 소규모 앱에서 React Query를 처음 시작할 때는 거의 필요 없는 최적화입니다. 특히 여기서 보여줄 예제처럼 단순한 상황에서는 굳이 사용할 이유가 없을 수 있습니다. 항상 그렇듯, 단 몇 줄의 코드로 고급 개념을 보여주는 것과 실제 상황에서 적용하는 것 사이에는 균형이 필요합니다.
글로벌 상태와 구독
이전에 #18: Inside React Query에서 설명했듯이, React Query는 QueryCache라는 하나의 전역 상태로 구성되어 있으며, 여기에 모든 Query에 대한 정보가 저장됩니다.
어떤 Query에서 변화가 발생하면, 우리는 해당 변화를 모든 QueryObserver(즉, useQuery로 생성되는 것들)에게 알려야 합니다.
이상적으로는, 모든 컴포넌트가 모든 것에 구독(subscribe)하는 상황은 피해야 합니다.
예를 들어 todos Query에 변화가 생겼다고 해서, profile Query에만 관심 있는 컴포넌트가 리렌더링될 이유는 없습니다.
그럴 거라면, 차라리 애플리케이션 전체에 React Context로 배포되는 최상위 useState를 쓰는 게 낫겠죠.
구독을 제어하고, 이를 세밀하게 조정하는 것이 바로 상태 관리 도구들이 존재하는 이유입니다.
QueryHash
아시다시피, React Query에는 앞서 언급한 기능이 기본적으로 내장되어 있습니다.
물론, useQuery가 전체 QueryCache를 구독하는 것은 아닙니다.
useQuery에 전달한 QueryKey는 결정론적으로(hash 함수에 의해) QueryHash로 변환되고, useQuery는 해당 Query에 변화가 있을 때만 알림을 받습니다.
본질적으로, 이것은 관심 있는 Query로 미리 필터링하는 것과 같습니다.
대부분의 경우, 이것만으로 충분합니다. 하나의 엔드포인트 데이터가 변경되면 컴포넌트가 리렌더링되고, 다른 엔드포인트 데이터가 변경되면 리렌더링되지 않습니다.
그렇다면, 더 이상 무엇이 필요할까요?
세밀한 구독(Fine-grained Subscriptions)
가끔은 엔드포인트가 매우 많은 데이터를 반환하지만, 우리가 그 모든 데이터에 관심 있는 것은 아닙니다.
특히 자주 변경되는 필드와 거의 변경되지 않는 필드가 함께 있을 때, 전체 응답을 캐시에 저장하더라도 더 세밀한 수준의 구독이 필요할 수 있습니다.
이럴 때 사용할 수 있는 것이 바로 select입니다.
select란 무엇인가?
select는 useQuery에 전달할 수 있는 옵션으로, 컴포넌트가 구독할 데이터를 선택(pick), 변환(transform), 또는 계산(compute)하는 데 사용됩니다.
이는 Redux에서 셀렉터(selector)를 사용해 파생 상태(derived state)를 얻는 방식과 매우 유사합니다.
셀렉터는
Redux에만 국한된 개념이 아닙니다. 다만, Flux 아키텍처와 잘 맞아 떨어지고 React 환경에서 널리 알려진 덕분에 Redux와 함께 자주 언급될 뿐입니다. 예를 들어Zustand같은 다른 상태 관리 라이브러리에도 셀렉터가 존재합니다.
제 개인적인 생각으로는, 셀렉터는 어떤 데이터에 접근하고 싶은지 가장 명확하게 표현하는 방법입니다. React는 useSyncExternalStoreWithSelector를 통해서도 이를 제공합니다.
예를 들어, 우리가 API에서 상품 데이터를 가져온다고 해봅시다.

그리고 상품 제목만 렌더링하는 컴포넌트를 만들고 싶다고 가정해 보겠습니다.
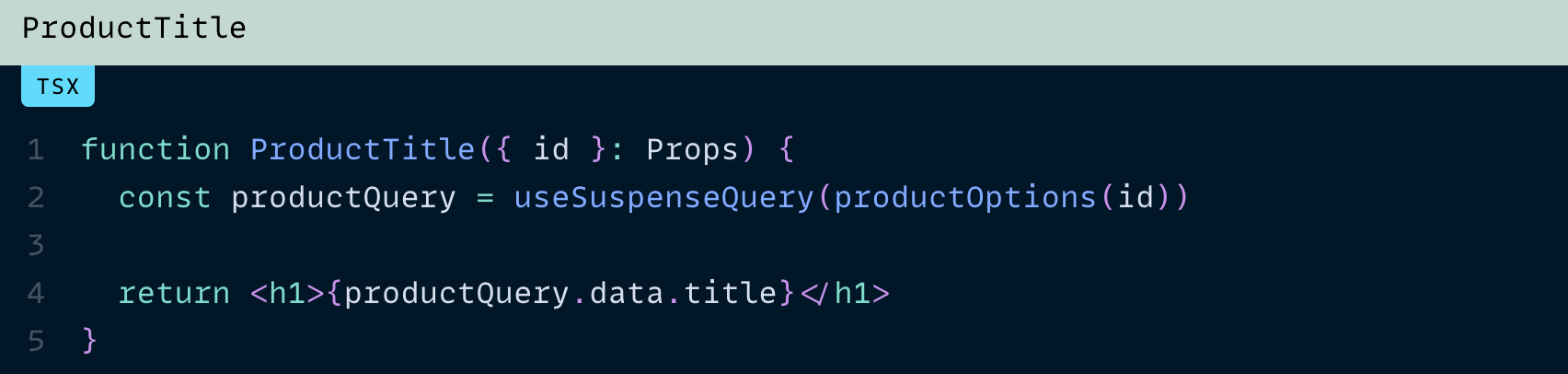
이 방식은 대부분의 상황에서 문제없을 가능성이 큽니다.
하지만, 해당 엔드포인트는 구매 수나 댓글 수처럼 제목보다 자주 변하는 정보도 함께 반환할 수 있습니다.
이 단순한 컴포넌트가 관련 없는 변경 때문에 가끔 리렌더링되는것을 최적화하고 싶다고 가정해 봅시다.
그럴 때 select가 도움이 됩니다. 전체 상품 데이터에 컴포넌트를 구독시키는 대신, 관심 있는 필드(또는 필드들)만 선택할 수 있습니다.
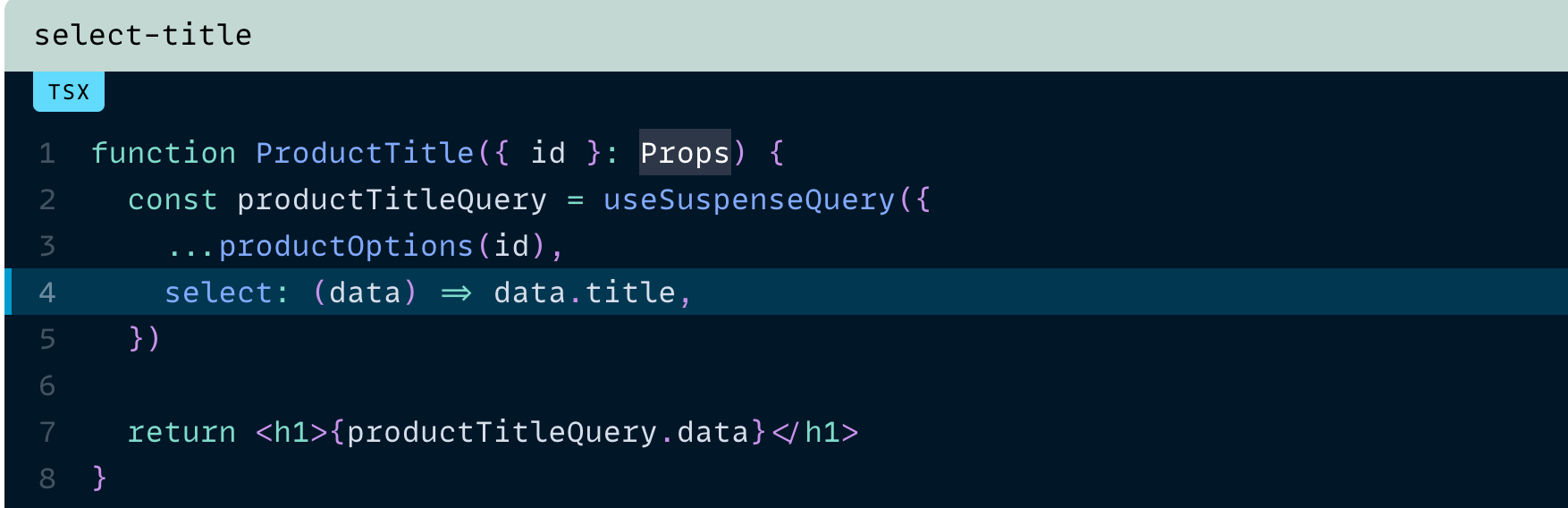
select를 사용하는 컴포넌트는 select 함수의 반환 값에만 구독됩니다. 따라서 그 결과가 변경될 때만 리렌더링됩니다.
이 예시에서는 제목(title)이 자주 변하지 않을 가능성이 크기 때문에, 다른 상품 데이터 속성이 자주 변경되더라도 컴포넌트가 리렌더링될 일은 거의 없습니다.
더 좋은 점은, 원한다면 여러 속성을 한 번에 "선택"할 수도 있다는 것입니다. 또한 참조 안정성(referential stability)에 대해 걱정할 필요도 없습니다.
왜냐하면 React Query는 select 결과에 구조적 공유(structural sharing)를 적용하기 때문입니다.
이는 원자적 셀렉터(atomic selector) 사용을 선호하는 Zustand 같은 다른 라이브러리와는 다른 점입니다.
즉, 이런 코드도 예상대로 동작한다는 뜻입니다.
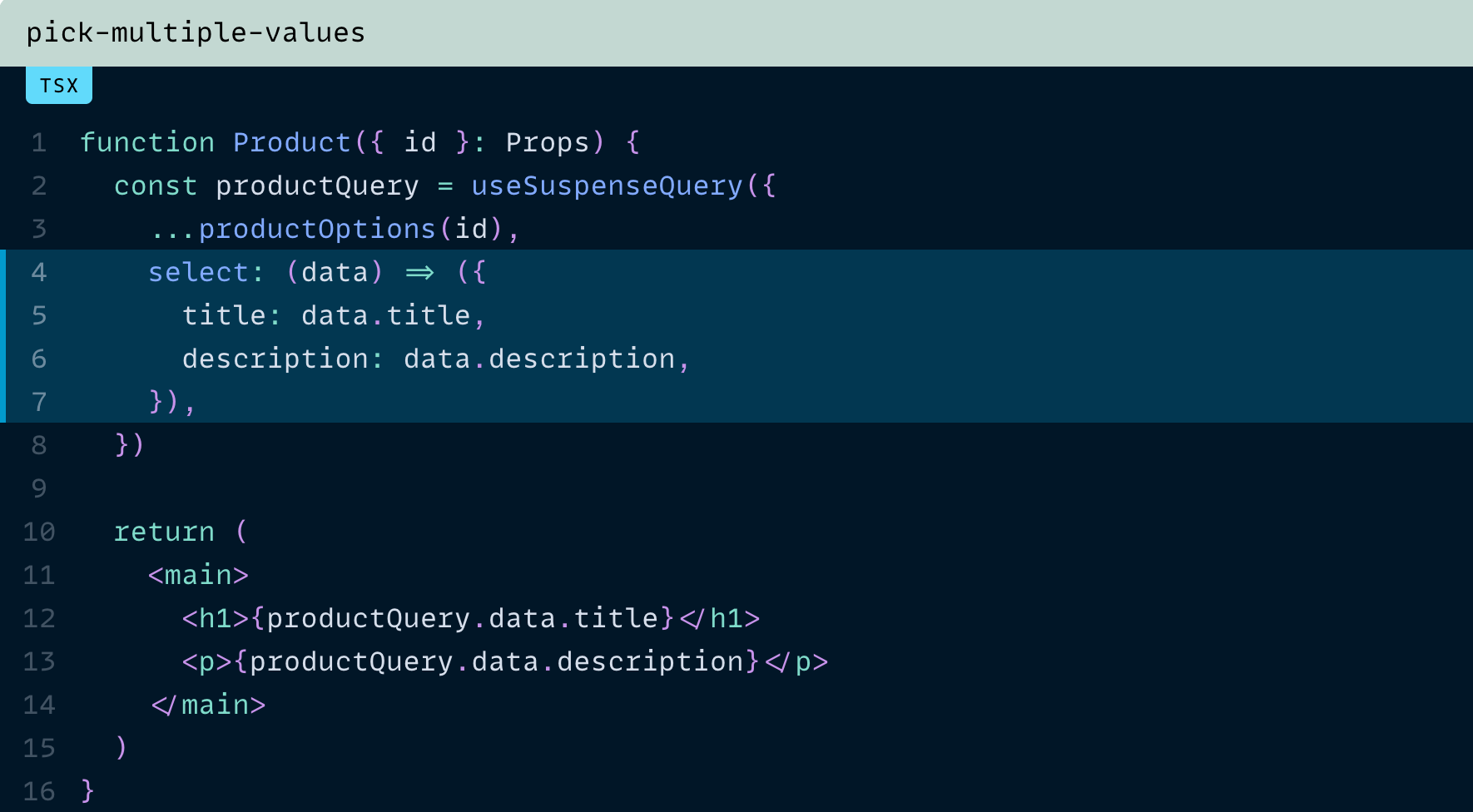
title이나 description 중 하나라도 변경되면 리렌더링이 발생하고, 그렇지 않으면 발생하지 않습니다. 꽤 멋지죠?
select 추상화의 타입 지정(Typing Select Abstractions)
아마 위의 예시들에서 눈치채지 못했을 수도 있지만, 그 모든 코드는 유효한 TypeScript 코드입니다.
사실 단순히 유효할 뿐만 아니라, 타입 안전(type-safe)하고 타입 추론(type inference)이 적용됩니다. 즉, useQuery에서 반환되는 객체의 data 필드는 select가 반환하는 타입으로 지정됩니다.
하지만, 이는 타입 추론에 맡길 때만 작동합니다. 즉, useQuery에 제네릭 타입 파라미터를 직접 지정하지 않는 것이 중요합니다.
아직 안 읽어보셨다면, [#6: React Query와 TypeScript]를 참고해 주세요.
이 원칙을 지키는 건 비교적 쉽지만, 이런 의문이 생길 수 있습니다:
그렇다면 select를 포함한 재사용 가능한 추상화를 TypeScript에서 어떻게 작성할 수 있지?
예를 들어, select를 인자로 받는 productOptions를 만들려면 어떤 타입 매직이 필요할까요?
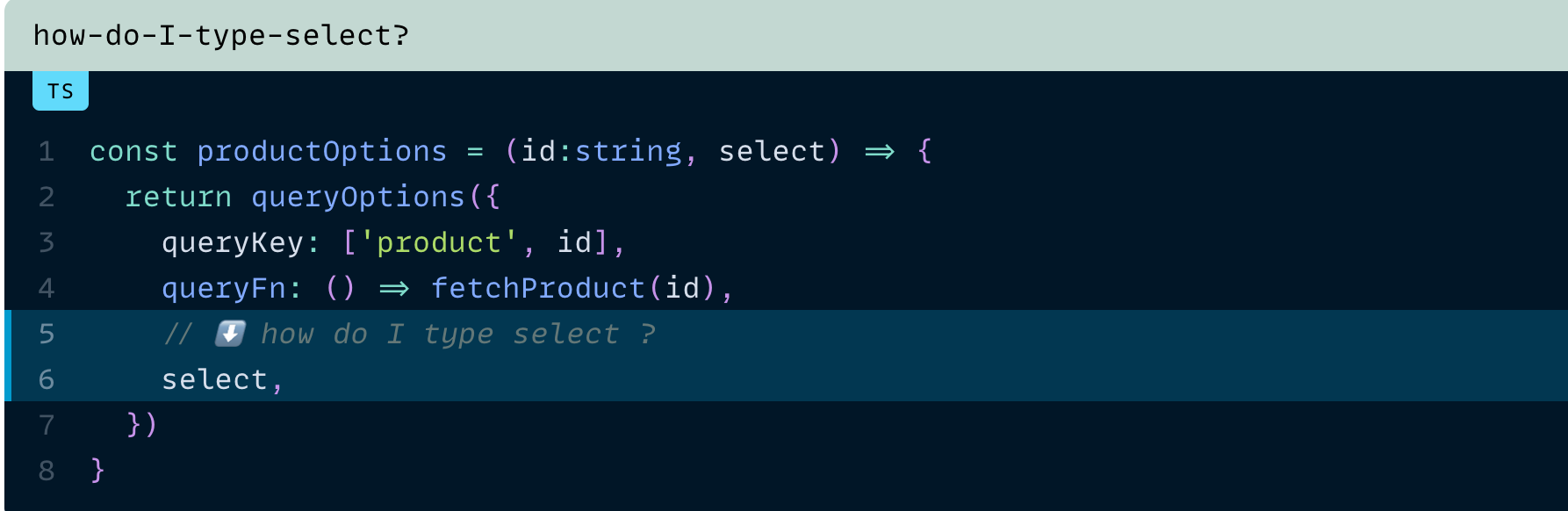
저는 그렇게 하지 마세요!라고 말하고 싶어요.
우리는 Query Options API를, 공유 옵션을 쉽게 추상화하면서도 동시에 사용하는 곳에서 직접 추가 옵션을 지정할 수 있도록 만들었습니다.
그래서 지금까지 봤던 코드들을 보면, TypeScript가 쓰이고 있다는 흔적이 거의 없죠.
하지만, 저는 정말 이걸 하고 싶은데요?
좋아요, 꼭 해야 한다면 조금 더 복잡해집니다. 특히 select를 선택적(optional)으로 만들고 싶다면요:
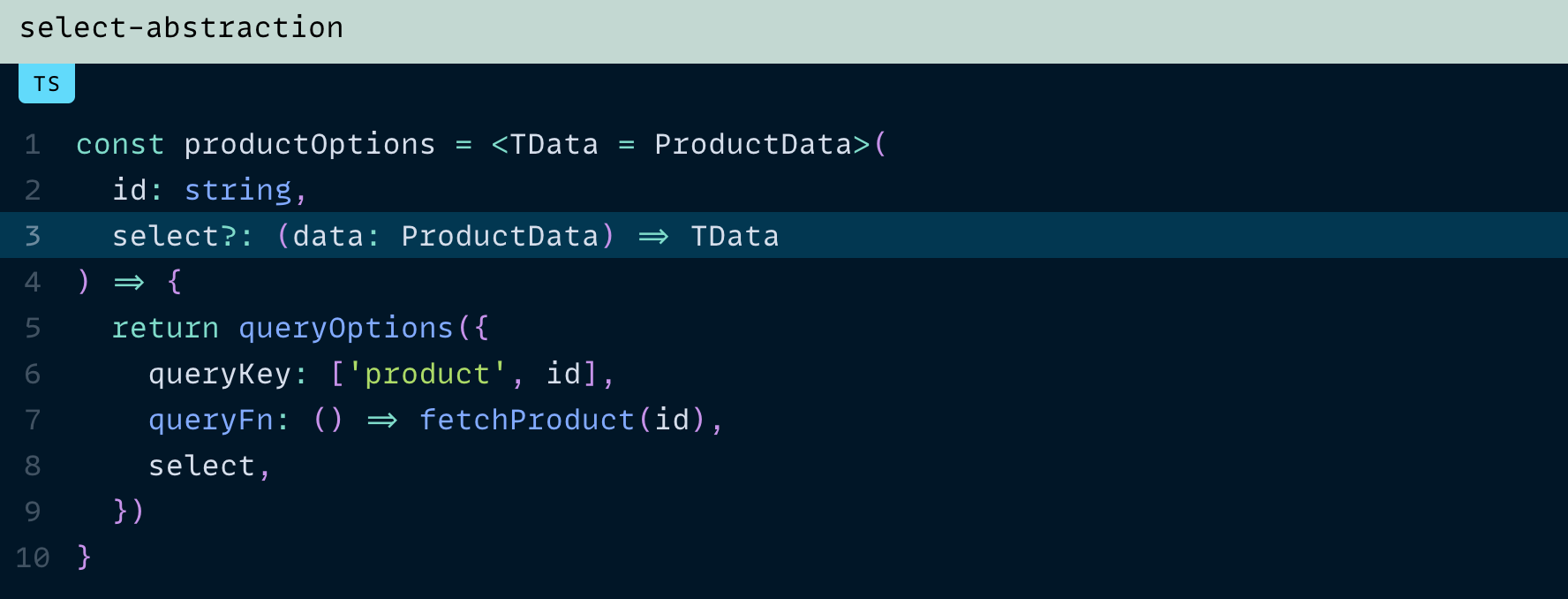
여기서 핵심은, TData라는 타입 매개변수(type parameter)를 추가하고, 그 기본값을 queryFn이 반환하는 타입(ProductData)으로 설정하는 것입니다.
그다음, select를 ProductData → TData로 변환하는 함수 타입으로 정의합니다.
- select를 제공하지 않을 경우 → data의 타입은 ProductData
- select를 제공할 경우 → data의 타입은 해당 함수의 반환 타입
메모이제이션(Memoization)으로 select 강화하기
이미 최적화를 하고 있는 김에 한 발 더 나아가서,
select에서 실행되는 함수가 정말 비용이 큰 작업이라고 가정해 봅시다.
예를 들어, 다음 작업을 한 번에 처리한다고 해보겠습니다.
- 아주 큰 상품 목록을 순회
- 수천 개의 사용자 리뷰를 기반으로 각 상품의 평균 평점을 계산
- 잘못된 데이터를 필터링한 뒤 평점 상위 상품을 정렬
이 함수를 앞으로 expensiveSuperTransformation이라고 부르겠습니다.
일반적으로 select에 이렇게 작성할 수 있습니다:
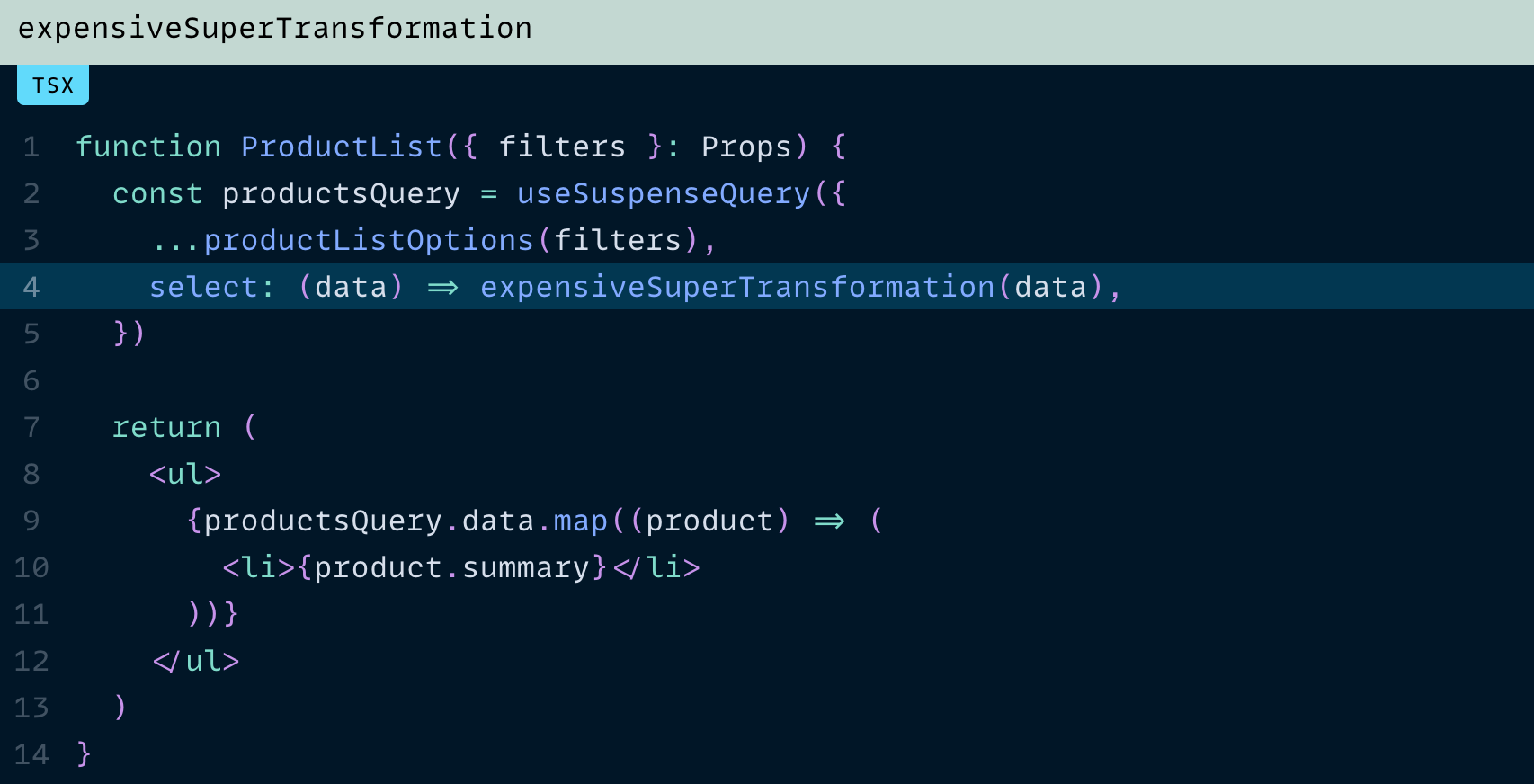
이 코드는 잘 동작하겠지만, 한 가지 함정이 있습니다.
expensiveSuperTransformation이 매 렌더링마다 실행된다는 점입니다.
그 이유를 이해하려면 React Query가 select 함수를 다시 실행하는 두 가지 경우를 알아야 합니다.
데이터가 변경될 때
이건 당연합니다. 새로운 데이터를 받으면 변환 결과가 달라질 수 있으니, 변환 함수를 다시 실행해야 합니다.
select 함수 자체가 변경될 때
React Query는 성능 최적화의 일환으로 select 함수의 참조 동일성(referential identity)을 추적합니다. 동일한 함수가 전달되면 같은 결과를 생성한다고 판단해 재실행을 건너뛸 수 있습니다.
하지만 인라인 함수는 매 렌더마다 새로 생성되기 때문에, 방금 말한 최적화가 적용되지 않습니다.
사실 이것은 좋은 특성이기도 합니다. 추가 props를 클로저로 캡처할 수 있어 오래된(stale) 결과를 걱정하지 않아도 되거든요
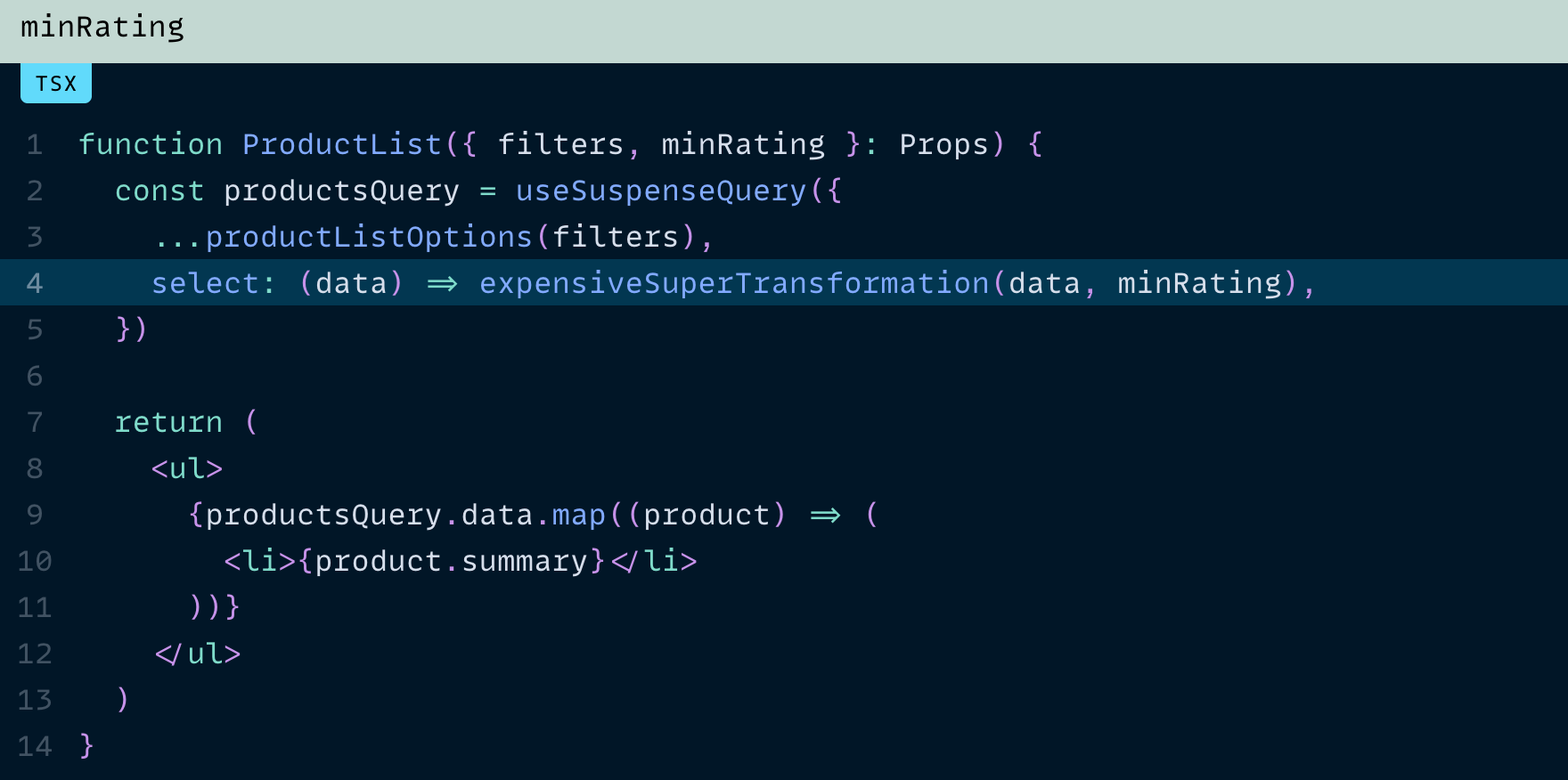
이제 minRating이 바뀐다면, 최신 계산 결과를 얻기 위해 select 함수가 다시 실행되는 게 오히려 반갑습니다.
그렇다면 첫 번째 예제에서는 계산을 건너뛰어도 괜찮다고 React Query에 알리고, 두 번째 예제에서는 그러면 안 된다고 어떻게 구분해서 알려줄 수 있을까요?
select 안정화하기(Stabilizing select)
핵심은 select에 안정적인 참조(stable reference)를 전달하는 것이고,
React에는 이를 구현할 수 있는 좋은 내장 방법이 있습니다
유용한 useCallback
아이러니하게도, 제가 얼마 전 "쓸모없는 useCallback"이라는 글을 썼다는 점을 생각하면 아이러니하지만, 이번 경우에는 정말 잘 맞습니다.
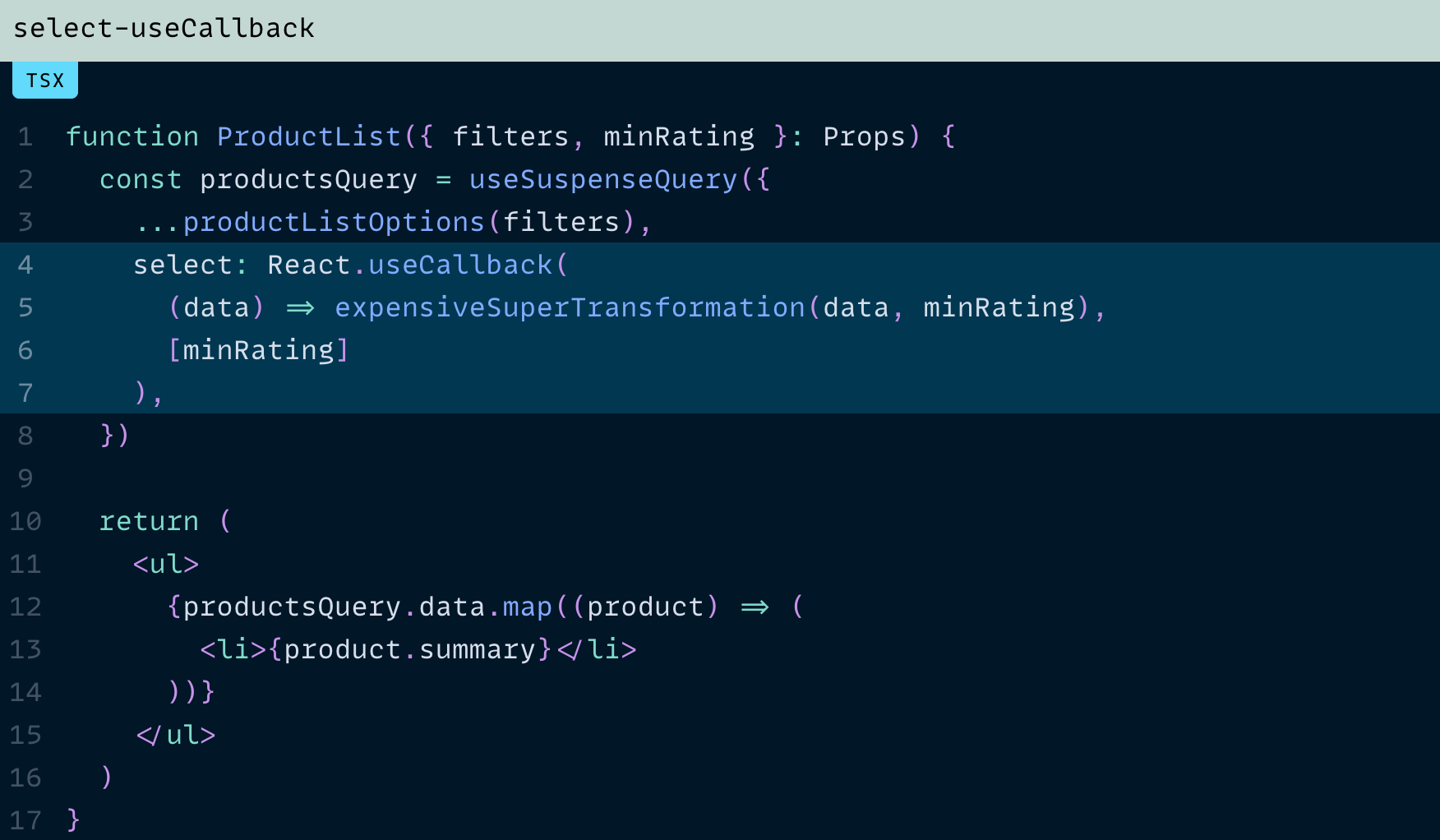
이제 minRating이 변경되지 않는 한, select에는 안정적인 참조가 전달됩니다.
그리고 의존성(dependency)이 전혀 없다면,
아예 컴포넌트 바깥으로 함수를 옮겨서 안정성을 확보할 수도 있습니다.
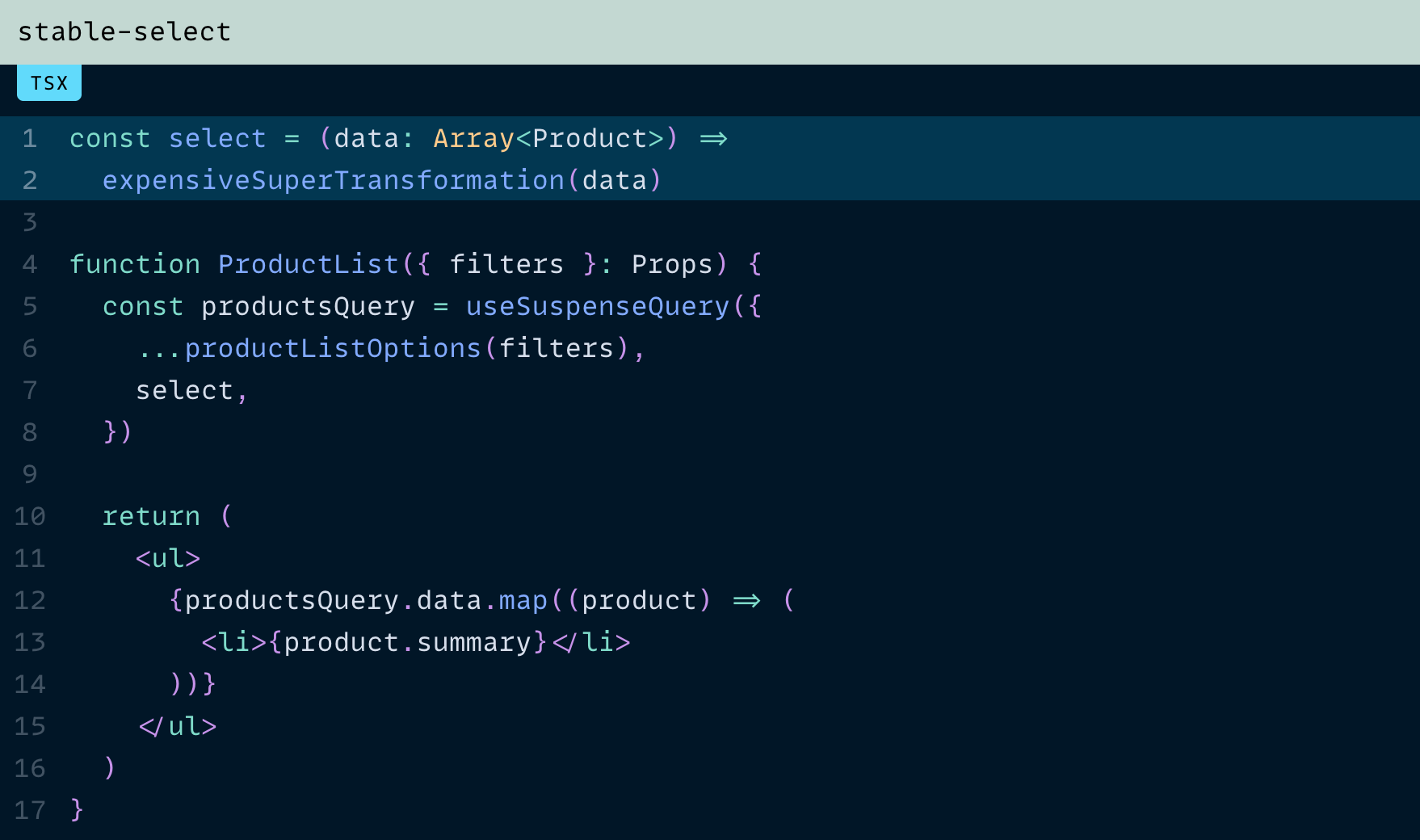
최종 보스(The Final Boss)
지금까지는 아주 잘 작동하지만, 아직 끝이 아닙니다.
같은 컴포넌트를 여러 번 렌더링하면 어떻게 될까요? select는 얼마나 자주 실행될까요?
정답은: 컴포넌트마다 한 번씩입니다.
정확히는 QueryObserver마다 한 번인데, select의 결과가 거기에 캐시되기 때문이죠.
useQuery를 호출할 때마다 새로운 QueryObserver가 만들어지므로, 각 호출마다 최소 한 번은 select가 실행됩니다.
이건 좀 아쉽습니다. 여전히 하나의 데이터에 대해 expensiveSuperTransformation이 여러 번 실행될 수 있다는 뜻이니까요.
이런 상황을 막기 위해선 어떻게 하는게 좋을까요?
정답은 메모이제이션을 더하는 것입니다.
더 많은 메모이제이션(More Memoization)
우리가 정말 원하는 건 expensiveSuperTransformation을 입력값 기준으로 메모이제이션하는 것입니다.
하지만 이 작업은 React Query 바깥에서 이뤄져야 합니다.
왜냐하면 React Query는 옵저버(Observer) 단위로 결과를 캐시하기 때문이죠.
그래서 fast-memoize 같은 라이브러리를 도입해 이렇게 할 수 있습니다
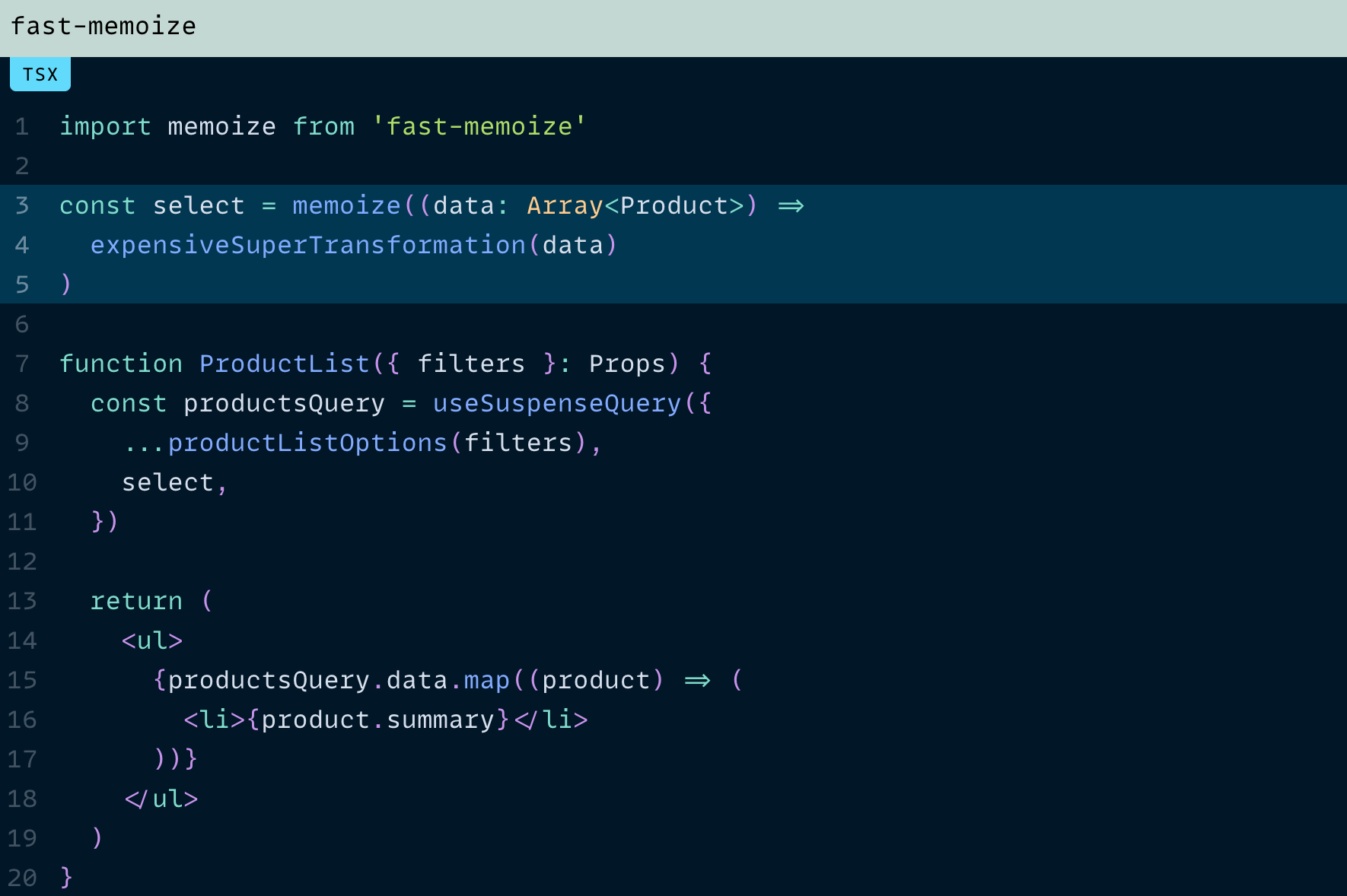
이제 ProductList를 세 번 렌더링한다고 가정해 봅시다.
발생하는 일은 이렇습니다
-
select는 세 번 실행됩니다(각
QueryObserver마다 한 번씩 — 이것은 피할 수 없습니다). -
하지만
expensiveSuperTransformation은 한 번만 실행됩니다. 동일한 data로 실행되기 때문에fast-memoize의 캐시를 두 번 맞고 지나가거든요.
데이터가 변경되더라도 마찬가지입니다.
select는 세 번 실행되지만,
expensiveSuperTransformation은 새로운 data에 대해 한 번만 실행됩니다.
이 정도면 우리가 할 수 있는 최상의 최적화입니다.
