방학 동안 3개의 프로젝트를 진행했었고, 다양한 인재분들의 코드리뷰를 통해 공통적으로 내 코드가 가지고 있던 문제점을 깨달아서, 학기가 시작되고 정신없어지기 전에 따로 정리하고자 한다.
크게 다음과 같은 계층별 순서로 목차를 구성하였다.
Domain(JPA Entity) -> Dto -> Repository -> Service -> Controller
Domain(JPA Entity)
생성메서드
먼저 생성자보다 생성메서드를 프로젝트에서 채택한 이유는 아래를 참고하였다.
https://tecoble.techcourse.co.kr/post/2020-05-26-static-factory-method/
위에서 언급했듯이, 생성의 목적을 이름에 담을 수 있기에 정적 팩토리 메서드를 프로젝트 내부 Domain Model에 도입하였다.
일반적으로 정적 팩토리 메서드의 대표적인 네이밍 2개는 아래와 같다.
from : 하나의 매개 변수를 받아서 객체를 생성
of : 여러개의 매개 변수를 받아서 객체를 생성
다만 JPA Entity에서 생성메서드를 도입하려면, 생성자의 접근제어자를 protected 혹은 private로 변경해주어야 한다.
예를 들어, 게시물에 작성할 댓글(Comment) Entity를 구성한다면,
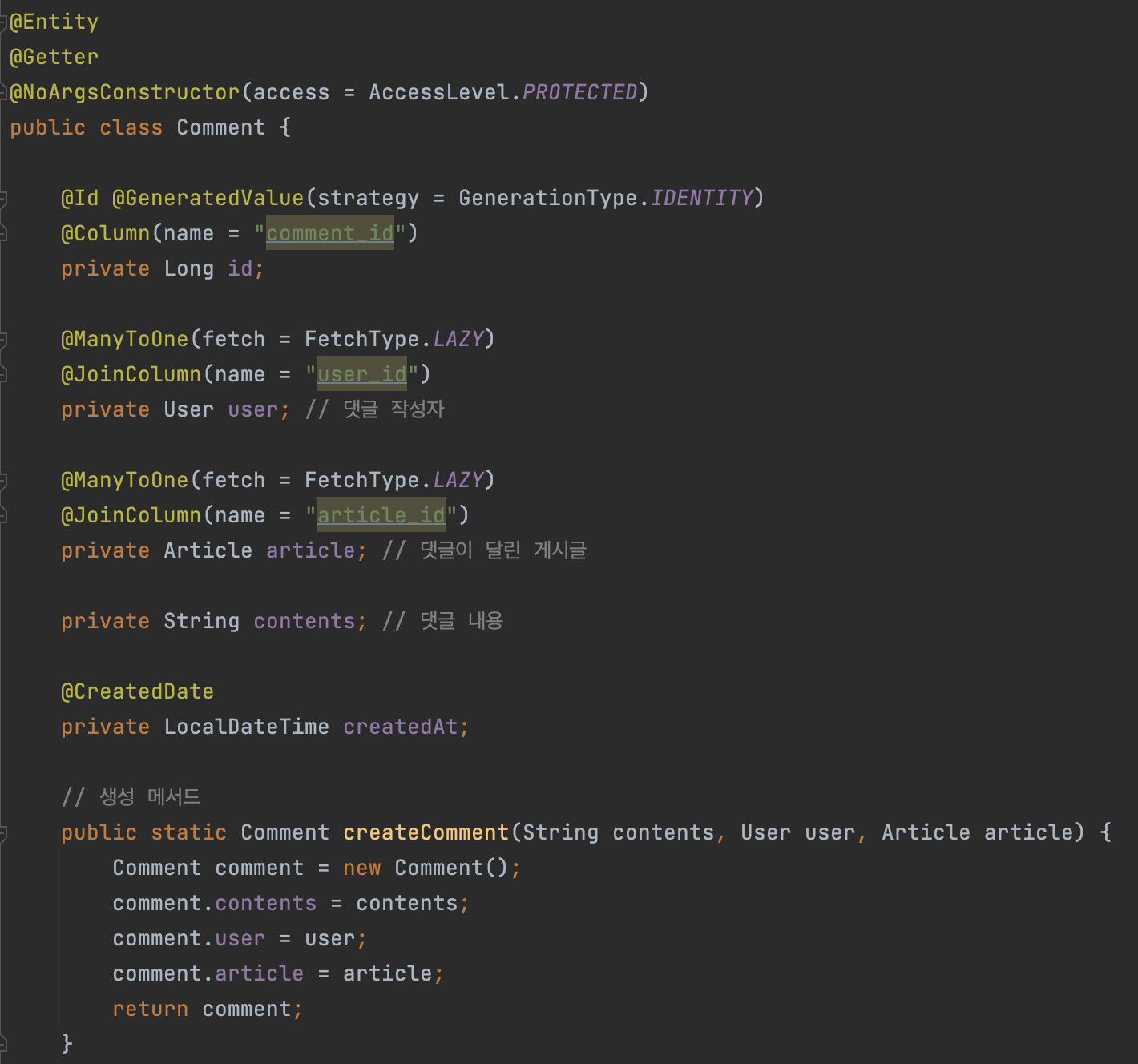 위와 같이 @NoArgsConstructor(access = AccessLevel.PROTECTED)를 통해
위와 같이 @NoArgsConstructor(access = AccessLevel.PROTECTED)를 통해
기본 생성자의 접근제어를 protected로 처리해주어야 한다.
지연로딩(FetchType.LAZY)
댓글과 게시물이 다대일의 관계를 구성하고 있다.
다대일 관계, 즉 @xxxToOne에 해당하는 관계에는 반드시 지연로딩을 걸어준다.
- FetchType.EAGER: 댓글 조회 시 게시물까지 불러오는 쿼리까지 날린다.
- FetchType.LAZY: 댓글 조회 시 연관관계에 해당하는 객체에 실제로 접근할 때에만(getArticle() 등) 쿼리가 나간다.
EAGER일 때 게시물이 수천 개가 넘어가면 그만큼 DB에 가해지는 부담이 커질 것이다.
참고로 @xxxToOne에는 EAGER, @xxxToMany에는 LAZY가 default로 설정된다.
중간 테이블
테이블 간의 다대다 관계는 중간 테이블을 두어 해소하는 것이 바람직하다.
왜 @ManyToMany가 존재하는데 사용을 기피하는지는 아래의 링크를 참고하자.
(https://codeung.tistory.com/254)
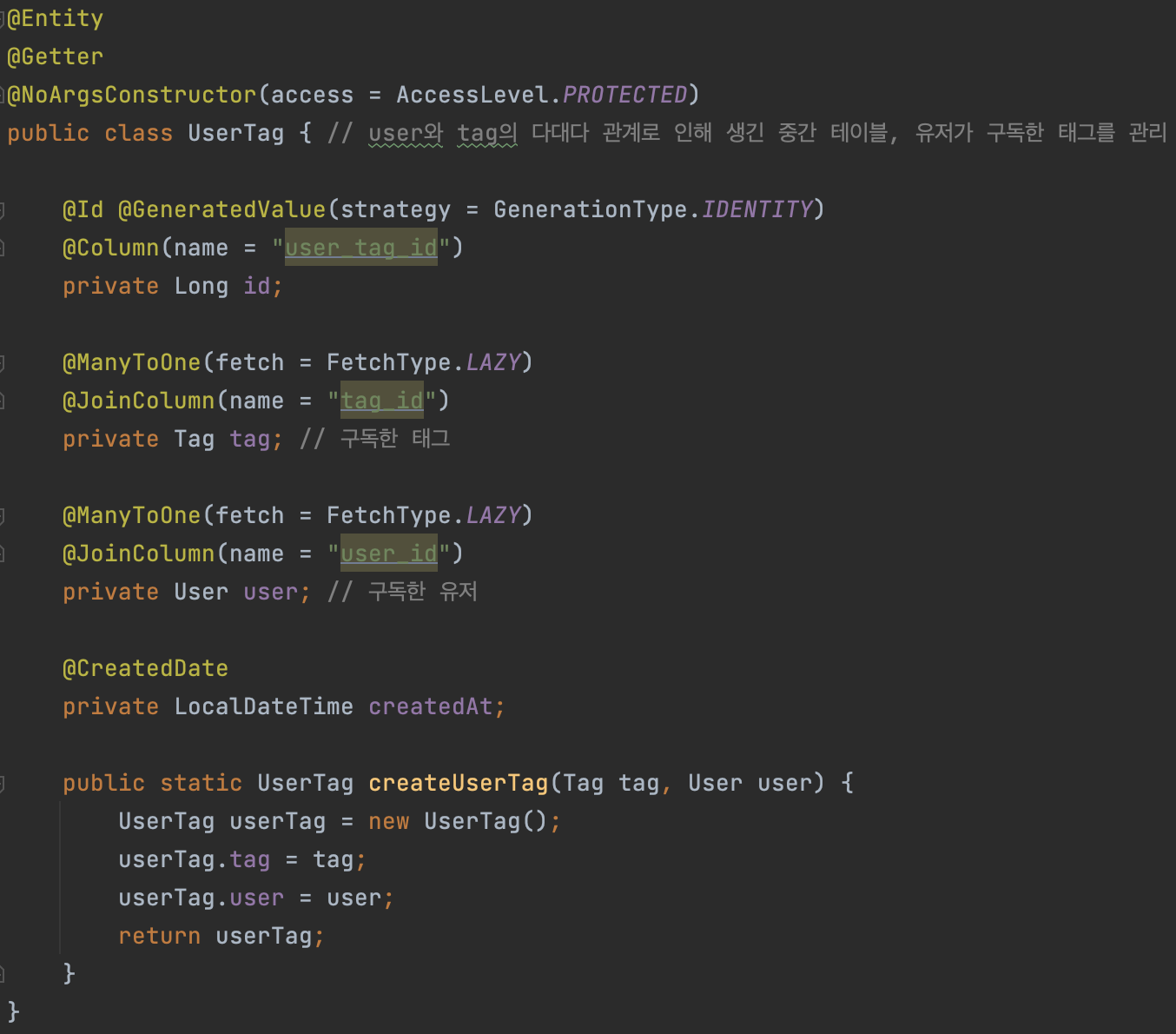 나같은 경우에는 프로젝트 요구사항에 user는 여러 tag를 구독하고, tag는 여러 user에게 구독받을 수 있기에, usertag라는 중간 테이블 역할을 해주는 JPA Entity를 새로 만들었다. 이때 앞에서 언급한대로 @xxxToOne의 관계는 항상 LAZY 로딩으로 처리해야 하며, 따로 이 객체가 생성된 일시 등을 기록하고 싶다면 @CreatedDate로 간단하게 바로 설정할 수 있다.
나같은 경우에는 프로젝트 요구사항에 user는 여러 tag를 구독하고, tag는 여러 user에게 구독받을 수 있기에, usertag라는 중간 테이블 역할을 해주는 JPA Entity를 새로 만들었다. 이때 앞에서 언급한대로 @xxxToOne의 관계는 항상 LAZY 로딩으로 처리해야 하며, 따로 이 객체가 생성된 일시 등을 기록하고 싶다면 @CreatedDate로 간단하게 바로 설정할 수 있다.
Domain의 Dto 의존 문제
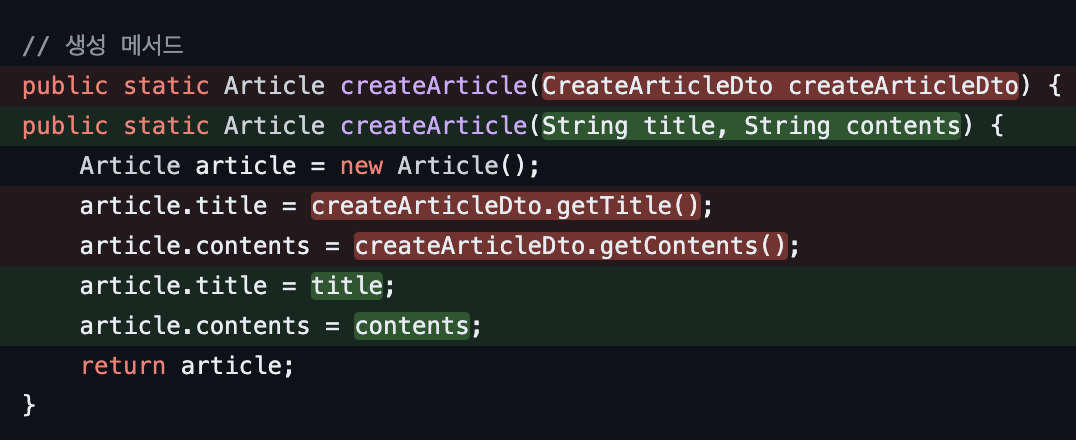
코드리뷰를 받아보니 Domain Model의 생성메서드가 Dto에 의존하는 문제가 있었다.
Dto는 Client-Controller-Service 사이에서 활용된다. 따라서 Domain Model이 Dto에 의존하고 있는 것은 불필요한 의존관계이므로 이를 해소해주었다.
(물론 Dto의 getter를 통해 편리하게 데이터를 가져올 수 있다는 이점이 있기도 하다. 실제로 그 이점 때문에 아무 생각 없이 사용하기도 했으니.
다만 솔로 프로젝트가 아닌 경우는 이런 상황을 피해야 할 것이다.)
Cascade
Cascade 옵션은 JPA Entity 간 관계에서 부모 Entity의 상태 변화가 자식 Entity에도 전이되는 기능이다.
다시말해 부모 Entity의 상태 변경(추가, 수정, 삭제)이 자식 Entity에 자동으로 적용된다.
주요 3가지 CascadeType은 다음과 같다.
- CascadeType.PERSIST: 부모 Entity가 영속성 컨텍스트에 진입할 때 자식 Entity도 함께 진입한다. 즉 부모 Entity가 저장/수정되면 자식 Entity도 함께 수정된다. 예를 들어 1대 다 관계의 두 Domain에서, 한 쪽 Domain에 내부 비즈니스 로직을 통해 다 관계에 해당하는 자식 Domain을 제어해야 하는 상황에서 필요한 옵션이다.
- CascadeType.REMOVE: 부모 Entity가 데이터베이스에서 소멸하면 연관된 자식 Entity도 함께 소멸한다.
- 그 외 MERGE, DETACH, REFRESH 등이 있다.
- CascadeType.ALL: 위 5개 Cascade를 적용한다. ALL을 남용하면 중요한 순간 의도치 않은 DB 제어로 인해 치명적인 결과를 발생시킬 수 있으므로 사용을 되도록이면 자제해야 한다. (코드리뷰 할 때 반복적으로 지적된 부분이다.)
그러므로 Cascade의 구체적인 타입을 명시적으로, 한정적으로 결정해 주는 것이 바람직하다. 예를 들어 부모가 삭제되면 자식이 삭제되는 기능만 활성화되는 것을 원한다면, 아래와 같이 지정해줄 수 있을 것이다.
 자식 Entity에서 부모를 REMOVE로 지정하는 실수는 하지 않도록 하자. (당해보면 참 슬프다)
자식 Entity에서 부모를 REMOVE로 지정하는 실수는 하지 않도록 하자. (당해보면 참 슬프다)
orphanRemoval
orphanRemoval = true 옵션은 부모-자식으로 연결된 관계에서 자식이 부모를 잃는, 즉 고아 객체가 감지될 때 이를 DB에서 삭제해주는 기능이다. 따라서 부모 Entity 삭제 상황 시 REMOVE 옵션과 동일한 기능을 해낸다. (부모가 소멸되면 자식은 부모를 잃은 것이므로)
만약 부모 Entity 내부 비즈니스 로직을 통해 특정 값을 통해 특정 자식을 찾아 삭제하는 로직을 추가하고자 한다면, PERSIST와 orphanRemoval = true을 모두 설정해주어야 한다.
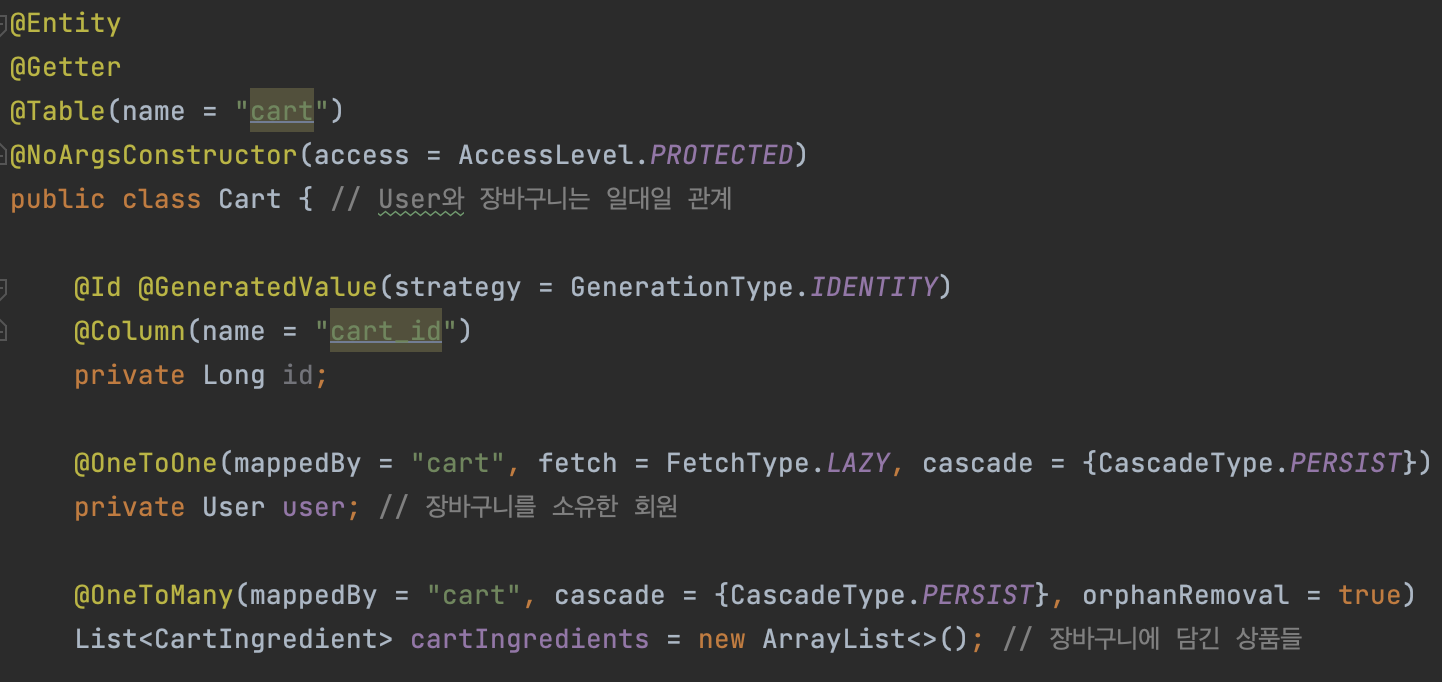
장바구니 기능을 구현하기 위한 Cart와 CartIngredient 엔티티가 1대 다 관계로 존재한다. 이때 장바구니에서 특정 상품, 혹은 전체 상품을 삭제하는 비즈니스 로직을 구현하여 실행해보면, orphanRemoval = true를 설정해주지 않았을 때 자식 Entity는 실제 DB 상에서 소멸하지 않는다. orphanRemoval = true를 설정해주어야 부모가 제거할 자식 Entity를 고아객체로 만들어 실제 DB에서도 소멸시킬 수 있다.
이 옵션은 자식이 오직 하나의 부모에만 연결되어 있을 때 사용해야 한다. 여러 부모 Entity와 연관되어 있다면 의도치 않은 결과가 나올 수 있다.
Dto
RequestDto & ResponseDto
- RequestDto는 Client가 서버에 전송하는 데이터 양식이며, 직렬화 및 역직렬화를 위해 @Getter와 @NoArgsConstructor가 필수적으로 존재해야 한다.
- ResponseDto는 서버가 클라이언트에게 전송하는 데이터 양식이며, @Getter가 필수적이다.
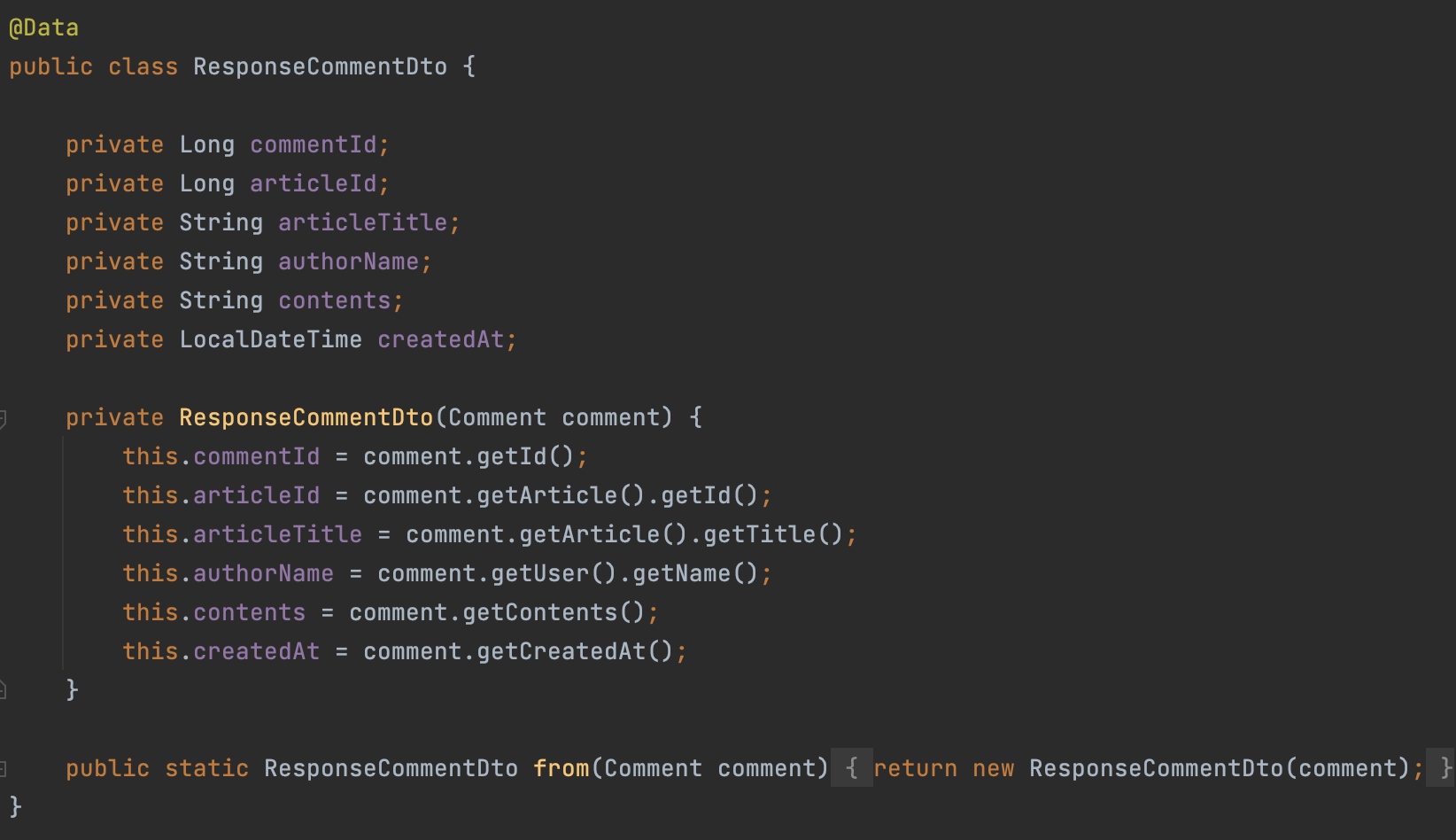 ResponseCommentDto는 서버가 클라이언트에게 댓글에 대한 정보를 보내주는 데이터 양식이다. 초기에 @Data를 사용했는데, @Data는 무엇을 의미할까?
ResponseCommentDto는 서버가 클라이언트에게 댓글에 대한 정보를 보내주는 데이터 양식이다. 초기에 @Data를 사용했는데, @Data는 무엇을 의미할까?
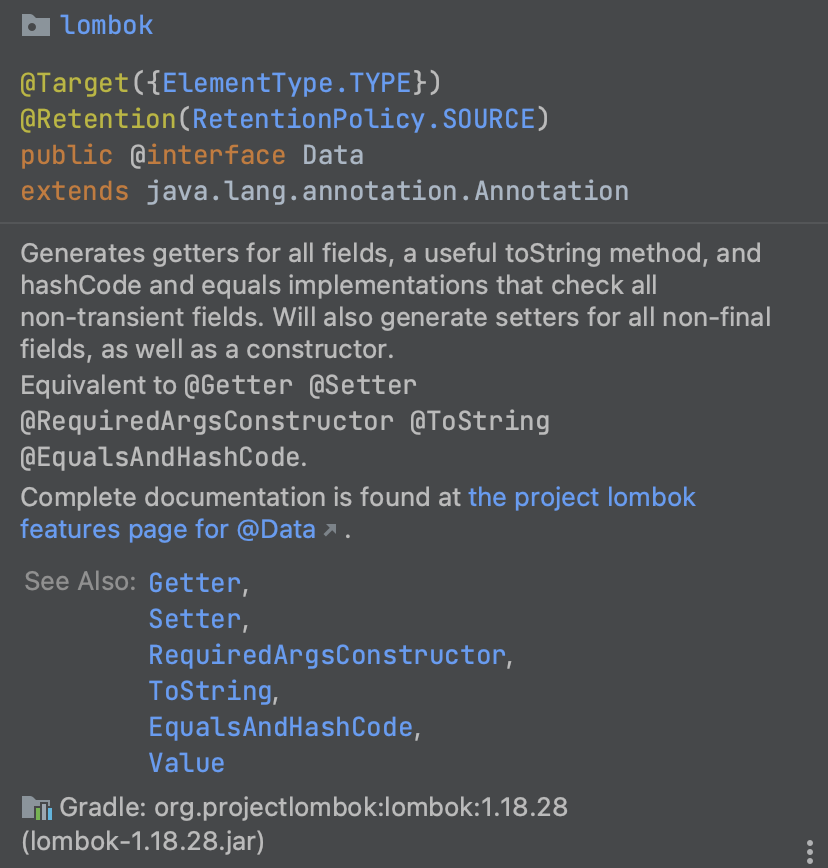 @Data는 Lombok의 라이브러리이며, 다음과 같은 어노테이션의 모음이라고 한다.
@Data는 Lombok의 라이브러리이며, 다음과 같은 어노테이션의 모음이라고 한다.
@Getter
@Setter
@RequiredArgsConstructor
@ToString
@EqualsAndHashCode
여기서 ResponseDto에 필수적으로 요구되는 건 @Getter뿐이다.(RequestDto면 @NoArgsConstructor도 필요) @Setter는 필수적인 경우가 아니라면 피해야 하기에, @Data는 @Getter로 수정해주는 것이 바람직할 것이다.
Entity to Dto
처음 Service에서 repository를 통해 가져온 Entity를 클라이언트에게 전달할 Dto로 전환하는 로직은 아래와 같았다.
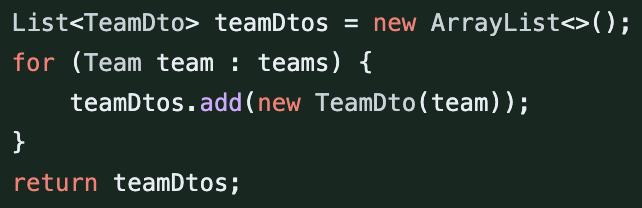 (다시 보니까 굉장히 부끄럽다.)
(다시 보니까 굉장히 부끄럽다.)
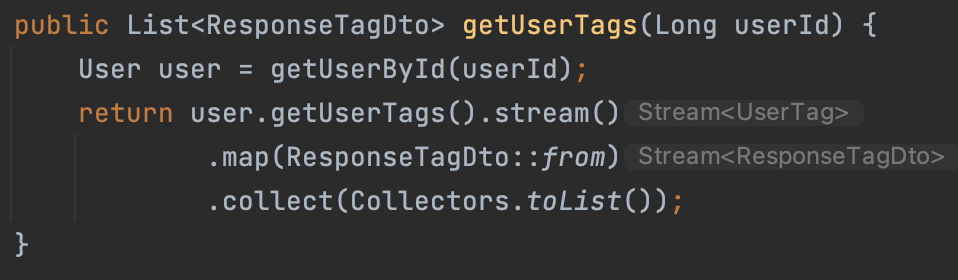 Java 8의 stream() 메서드를 사용하면 위와 같이 굉장히 간결하게 코드를 바꿀 수 있다. 위 코드는 유저가 구독 중인 태그의 정보를 조회하는 메서드이다.
Java 8의 stream() 메서드를 사용하면 위와 같이 굉장히 간결하게 코드를 바꿀 수 있다. 위 코드는 유저가 구독 중인 태그의 정보를 조회하는 메서드이다.
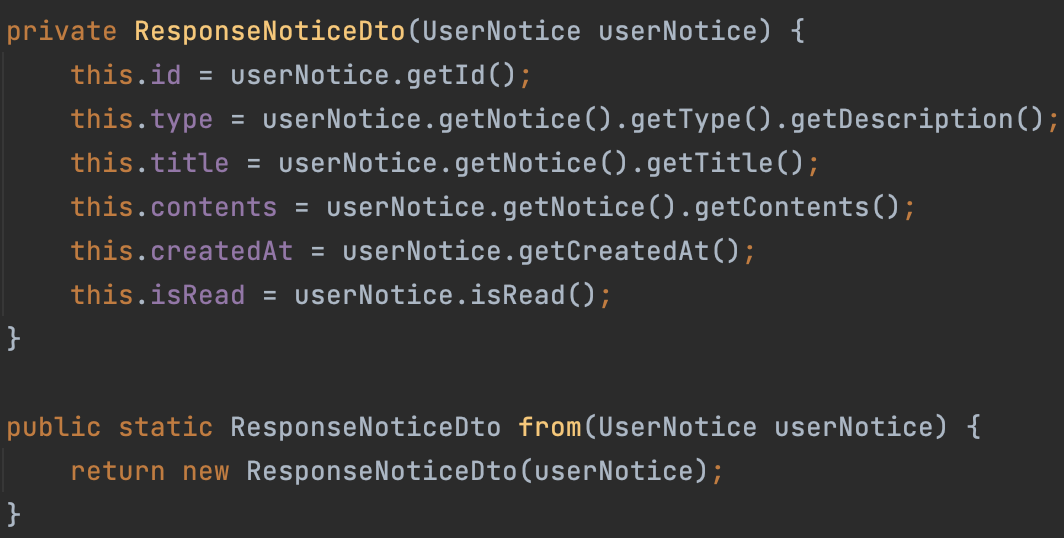 또한 Dto에도 정적 팩토리 메서드를 도입할 수 있다.
또한 Dto에도 정적 팩토리 메서드를 도입할 수 있다.
Repository
JpaRepository 주요 메서드
- existsById: 주어진 Id에 해당하는 엔티티가 존재하는 여부를 확인하며 true/false를 반환한다.
- findById: 주어진 Id에 해당하는 엔티티를 가져온다. 만약 존재하지 않으면 Optional.empty()를 반환하고, Service에서 이와 관련된 예외처리 로직을 orElseThrow() 등을 사용하여 작성한다.
- findAll(By): 모든 엔티티를 가져온다. 기본적으로 List 형태로 반환되나 아래처럼 Page 형태로도 가능하다.

- count(): Entity의 총 개수를 반환한다.
- deleteById: 주어진 Id에 해당하는 엔티티를 삭제한다.
- delete: 주어진 엔티티를 삭제한다.
- deleteAll: 모든 엔티티를 삭제한다.
- save: 주어진 엔티티를 저장한다. 이미 엔티티의 id가 존재한다면 저장이 아닌 수정이 이루어진다.
- flush(): 영속성 컨텍스트의 변경 내용을 DB에 즉시 반영한다.
N+1 문제에 대처하기 위한 @BatchSize
JPA를 쓰면 항상 면접장에서 듣는 단골 질문이라고 한다.
N+1 문제란, 1개의 쿼리를 사용할 목적으로 작성했으나 실제로는 N개의 쿼리가 추가적으로 생성되는 문제이다. 당연히 N이 커지면 시간이 오래 걸릴 것이고 서버의 부담이 가중될 것이다.
예를 들어, 유저가 작성한 게시물 조회 기능을 구현한다면 우리는 데이터베이스 쿼리의 JOIN 연산을 사용하여 하나의 쿼리로 처리하기를 기대하지만, 실제로는 N개의 게시글을 추가로 조회하는 쿼리가 발생하는 문제가 대표적이다.
지연로딩을 도입하면 첫 쿼리를 사용하는 순간에는 추가적인 N개의 쿼리가 발생하진 않지만, 마찬가지로 게시물에 접근하는 순간에는 N개의 쿼리가 필연적으로 발생한다.
내가 진행한 프로젝트는 페이징이 적용되어 있어서, @BatchSize를 통해 이를 해결하고자 했다. @BatchSize를 통해 컬렉션이나 프록시 객체를 한꺼번에 설정한 size만큼 in query로 조회할 수 있고, 이는 지연 로딩의 성능을 향상시킨다.
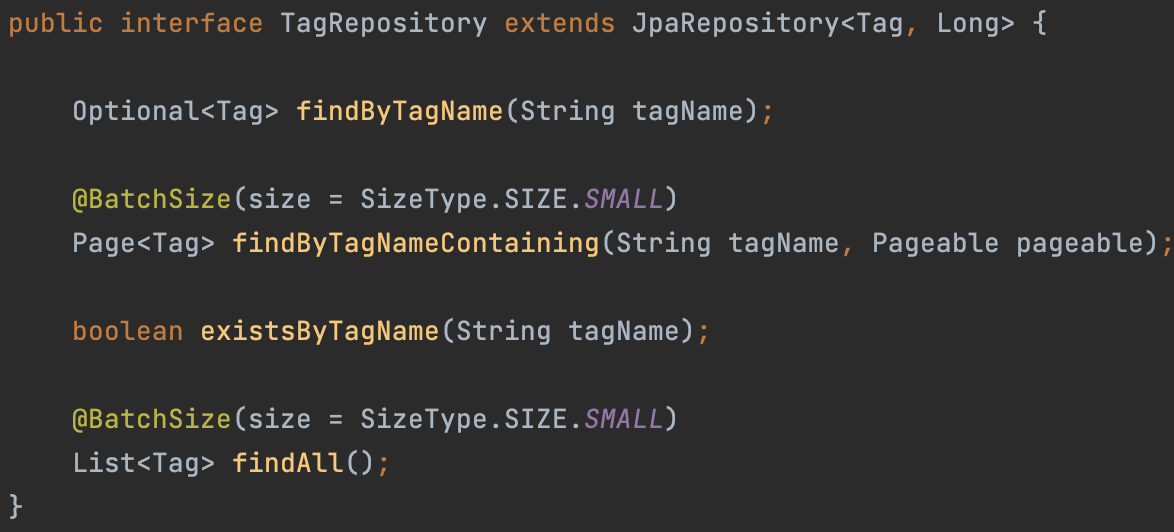 위와 같이 repository 내부메서드에 @BatchSize를 적용할 수도 있고, Entity 클래스 내부 Collection에 직접 @BatchSize를 적용할 수 있다. size는 보통 100~1000으로 구성되며, 적절한 배치 크기를 선택하는 것이 중요하다.
위와 같이 repository 내부메서드에 @BatchSize를 적용할 수도 있고, Entity 클래스 내부 Collection에 직접 @BatchSize를 적용할 수 있다. size는 보통 100~1000으로 구성되며, 적절한 배치 크기를 선택하는 것이 중요하다.
Service와 Controller 계층은 다음 게시물에서 다루도록 하겠다.
(잘못된 부분 지적은 언제나 환영하고 감사드립니다)
