Kubernetes
컨테이너 개발 시대: 컨테이너는 VM과 유사하지만 격리 속성을 완화하여 애플리케이션 간에 운영체제(OS)를 공유한다. 그러므로 컨테이너는 가볍다고 여겨진다. VM과 마찬가지로 컨테이너에는 자체 파일 시스템, CPU 점유율, 메모리, 프로세스 공간 등이 있다. 기본 인프라와의 종속성을 끊었기 때문에, 클라우드나 OS 배포본에 모두 이식할 수 있다.
컨테이너는 다음과 같은 추가적인 혜택을 제공하기 때문에 인기가 있다.
1 기민한 애플리케이션 생성과 배포: VM 이미지를 사용하는 것에 비해 컨테이너 이미지 생성이 보다 쉽고 효율적임.
->[서버 구성 과정]https://ikcoo.tistory.com/31
서버 주문 -> 서버 설치 -> CPU, 메모리, 하드 디스크 조립 ->
네트워크 연결 -> OS 설치 -> 계정 설정 -> 방화벽 설정 -> ...
지속적인 개발, 통합 및 배포: 안정적이고 주기적으로 컨테이너 이미지를 빌드해서 배포할 수 있고 (이미지의 불변성 덕에 = 한번 만들어지면 이미지내의 정보는 절대 변하지 않고) 빠르고 효율적으로 롤백할 수 있다.
개발과 운영의 관심사 분리: 배포 시점이 아닌 빌드/릴리스 시점에 애플리케이션 컨테이너 이미지를 만들기 때문에, 애플리케이션이 인프라스트럭처에서 분리된다.
클라우드 및 OS 배포판 간 이식성: Ubuntu, RHEL, CoreOS, 온-프레미스, 주요 퍼블릭 클라우드와 어디에서든 구동된다.
애플리케이션 중심 관리: 가상 하드웨어 상에서 OS를 실행하는 수준에서 논리적인 리소스를 사용하는 OS 상에서 애플리케이션을 실행하는 수준으로 추상화 수준이 높아진다.
느슨하게 커플되고, 분산되고, 유연하며, 자유로운 마이크로서비스: 애플리케이션은 단일 목적의 머신에서 모놀리식 스택으로 구동되지 않고 보다 작고 독립적인 단위로 쪼개져서 동적으로 배포되고 관리될 수 있다.
리소스 격리: 애플리케이션 성능을 예측할 수 있다.
리소스 사용량: 고효율 고집적.
쿠버네티스 사용 이유
:쿠버네티스는 분산 시스템을 탄력적으로 실행하기 위한 프레임 워크를 제공한다. 애플리케이션의 확장과 장애 조치를 처리하고, 배포 패턴 등을 제공한다.
서비스 디스커버리와 로드 밸런싱 쿠버네티스는 DNS 이름을 사용하거나 자체 IP 주소를 사용하여 컨테이너를 노출할 수 있다. 컨테이너에 대한 트래픽이 많으면, 쿠버네티스는 네트워크 트래픽을 로드밸런싱하고 배포하여 배포가 안정적으로 이루어질 수 있다.
스토리지 오케스트레이션 쿠버네티스를 사용하면 로컬 저장소, 공용 클라우드 공급자 등과 같이 원하는 저장소 시스템을 자동으로 탑재 할 수 있다.
자동화된 롤아웃과 롤백 쿠버네티스를 사용하여 배포된 컨테이너의 원하는 상태를 서술할 수 있으며 현재 상태를 원하는 상태로 설정한 속도에 따라 변경할 수 있다. 예를 들어 쿠버네티스를 자동화해서 배포용 새 컨테이너를 만들고, 기존 컨테이너를 제거하고, 모든 리소스를 새 컨테이너에 적용할 수 있다.
자동화된 빈 패킹(bin packing) 컨테이너화된 작업을 실행하는데 사용할 수 있는 쿠버네티스 클러스터 노드를 제공한다. 각 컨테이너가 필요로 하는 CPU와 메모리(RAM)를 쿠버네티스에게 지시한다. 쿠버네티스는 컨테이너를 노드에 맞추어서 리소스를 가장 잘 사용할 수 있도록 해준다.
자동화된 복구(self-healing) 쿠버네티스는 실패한 컨테이너를 다시 시작하고, 컨테이너를 교체하며, '사용자 정의 상태 검사'에 응답하지 않는 컨테이너를 죽이고, 서비스 준비가 끝날 때까지 그러한 과정을 클라이언트에 보여주지 않는다.
시크릿과 구성 관리 쿠버네티스를 사용하면 암호, OAuth 토큰 및 SSH 키와 같은 중요한 정보를 저장하고 관리 할 수 있다. 컨테이너 이미지를 재구성하지 않고 스택 구성에 시크릿을 노출하지 않고도 시크릿 및 애플리케이션 구성을 배포 및 업데이트 할 수 있다.
쿠버네티스 구성요소
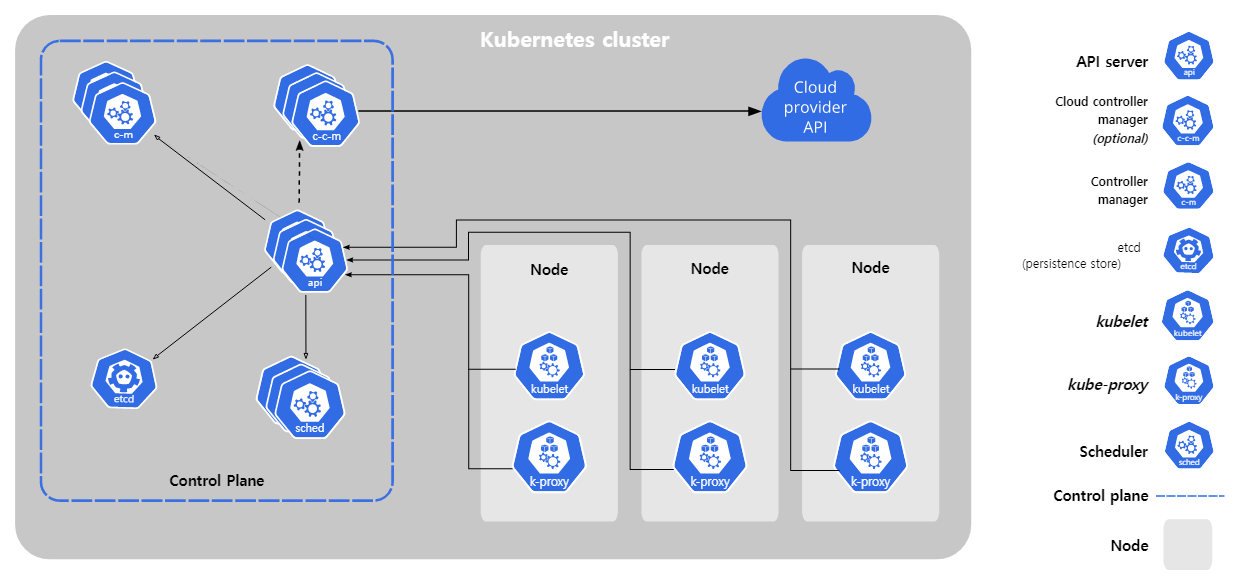
-
쿠버네티스 클러스터란?
쿠버네티스를 배포하면 클러스터를 얻는다. 즉, 쿠버네티스를 실행 중이라는 건 클러스터를 실행하고 있다는 얘기와 같다.
쿠버네티스 클러스터는 컨테이너화된 애플리케이션을 실행하는 노드(워커 머신)의 집합이다.
모든 클러스터는 최소 한 개 이상의 마스터 노드 및 워커 노드를 가진다. -
쿠버네티스 클러스터는 크게 컨트롤 플레인(Control Plane)과 노드(Node)라고 하는 2가지 영역으로 구성되어 있다.
컨트롤 플레인: 제어 영역이라고 할 수 있으며, Master Node라고 부르기도 한다.
노드: 애플리케이션 컨테이너를 실행하는 역할을 한다고 하여 Worker Node라고 부르기도 한다.(like vm)
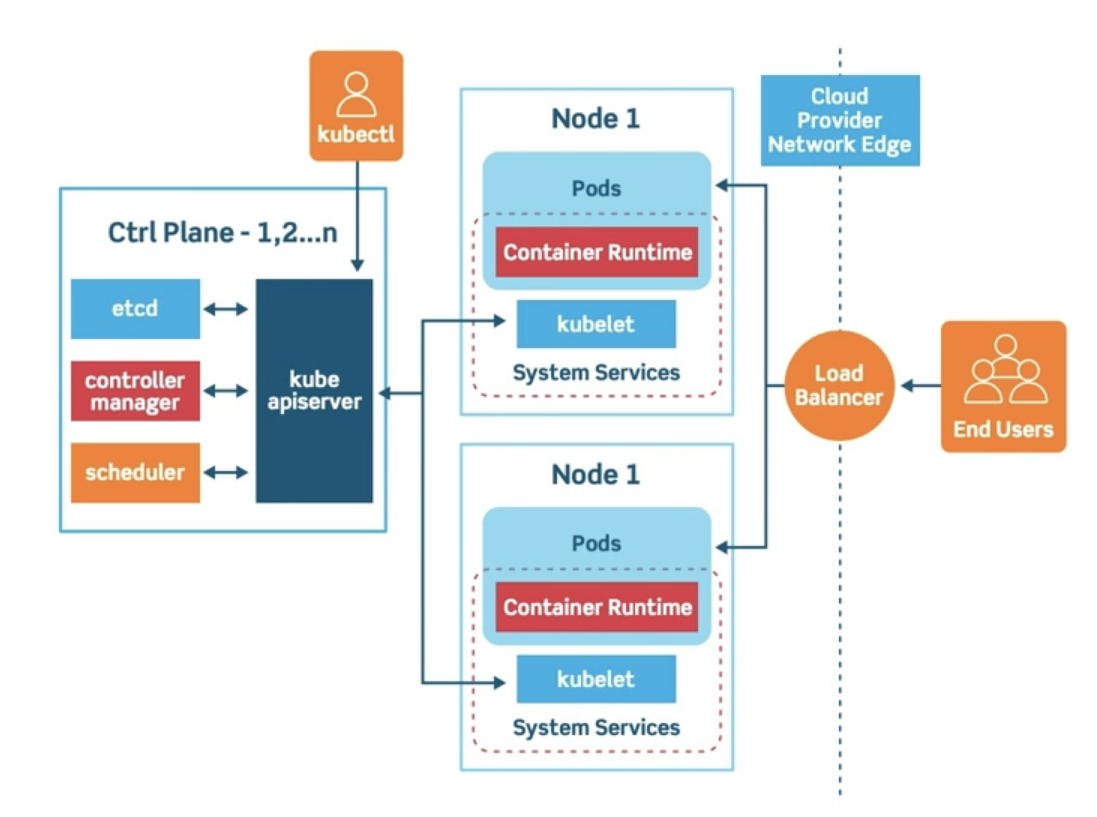
1) 컨트롤 플레인 : 마스터 노드
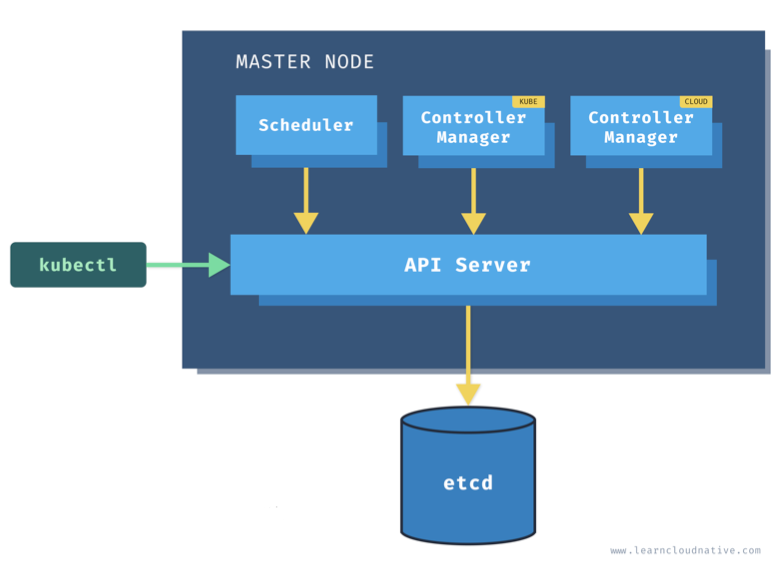
(1) 설명
Master Node라 불리는 컨트롤 플레인은 보통 1개~n개(홀수개)가 존재한다.
컨트롤 플레인 컴포넌트는 클러스터 내 어떠한 머신에서든지 동작할 수 있다. 그러나 간결성을 위하여, 구성 스크립트는 보통 동일 머신 상에 모든 컨트롤 플레인 컴포넌트를 구동시키고, 사용자 컨테이너는 해당 머신 상에 동작시키지 않는다.
컨트롤 플레인은 클러스터의 상태를 관리하고, 명령어를 처리하는 역할을 한다.
각각의 컨트롤 플레인은 etcd, controller-manager, scheduler, kube api server라고 하는 여러 컴포넌트(구성요소)를 가진다.
https://coffeewhale.com/apiserver
일전에 배운 kubectl 커맨드는 여기의 구성요소인 kube apiserver와 커뮤니케이션하는 용도라고 할 수 있다.
마치 전통적인 3 tier 아키텍쳐 관계처럼, 클라이언트 - 백엔드 서버 - 데이터 서버의 역할을 하는 방식으로 마스터 노드가 돌아간다고 볼 수 있다.
클라이언트의 요청을 처리하는 API 서버가 있고, 그 API가 클러스터의 상태 데이터를 저장하는 데 활용하는 db가 있다. (scheduler, controller-manager가 클라이언트, kube api server가 백엔드, etcd가 데이터 서버에 해당된다고 볼 수 있다.)
(2) 컴포넌트 분석
kube api server:
kubclet을 이용하여 api 서버에 클라이언트가 명령어 전달
쿠버네티스 리소스와 클러스터의 상태 관리 및 동기화를 위한 API를 제공한다.
etcd를 데이터 저장소로 사용한다.
etcd:
분산 key-value 저장소로 클러스터의 상태를 저장한다.
만약 클러스터 상태를 백업하고 복구하고 싶다면 etcd만 건드리면 된다.
컨트롤 플레인(마스터 노드) 영역 밖에 따로 떼서 관리하기도 하는데, 일반적으로는 컨트롤 플레인 내부에 각각 할당된다.
scheduler:
Api 서버와 통신하는 컴포넌트로써, 각각의 노드(워커 노드)의 자원(cpu, memory, gpu 등) 사용 상태를 관리한다. 동시에 아직 노드가 배정되지 않은 새로 생성된 pod를 감지하고 새로운 워크로드를 띄우는 역할을 한다. 이 때, 클러스터내 자원할당이 가능한 노드중 알맞은 노드를 선택하여 해당 노드에 워크로드를 배포하는(== pod를 띄우는) 역할을 한다.
controller-manager:
여러 컨트롤러 프로세스를 관리한다. (이전에는 컨트롤러로가 각각 다 나누어져 있었는데, 하나로 통합되면서 매니저라는 이름이 붙은 것)
크게 두가지 매니저로 나뉘는데, Kube 컨트롤러 매니저와 Cloud 컨트롤러 매니저이다.
Cloud 컨트롤러 매니저는 대표적인 클라우드 provider들(aws, gcp, azure 등)과 통신한다. 각각의 클라우드 환경에 맞춘 컨트롤러가 배정되어, provider들의 종속적인 기능들을 클러스터에서 수행하는 역할을 한다.
kube 컨트롤러 매니저도 여러 컨트롤러로 이루어져있다. Api 서버에는 다양한 api 리소스들(pod, deployment, service, secret 등)이 있고 각각의 리소스들을 관리하는 컨트롤러가 배정된다. 이들은 Api 서버를 주기적으로 찌르면서 현재 클러스터 상태와, etcd에 저장된 리소스의 상태를 비교한다. 만약 etcd 리소스 상태에 변화가 있다면 이를 현재 클러스터 리소스에 반영함으로써 동기화 시켜준다. 이러한 변화를 감지하고 동기화시키는 반복된 과정을 reconcile 이라고 부른다.
https://ko.javascript.info/
https://blog.eunsukim.me/posts/understanding-how-kubernetes-works
https://fe-developers.kakaoent.com/2022/220519-garbage-collection/
api 리소스와 오브젝트
리소스와 오브젝트간의 관계는 자바에서 클래스Class와 오브젝트(객체)의 관계와 정확히 동일 합니다.
쿠버네티스 리소스는 클래스와 동일하게 쿠버네티스 오브젝트를 생성할 때 사용하는 틀입니다.
예를 들어 ‘k get po’라고 했을 때 apple, banana와 같은 결과가 나왔다면
이때 apple과 banana는 쿠버네티스 오브젝트이고
파드가 쿠버네티스 리소스입니다.
그래서 쿠버네티스에서 스케일링 한다는 것은 이 파드수를 늘이거나 줄인다는 의미입니다.
파드는 실제 서비스 시 장애 대응을 위해 최소한 2개 이상을 실행
지금까지 서버인 Pod, Pod 로드밸런서 Service, Service 로드밸런서 ingress, 환경변수 ConfigMap과 Secret, 데이터 저장소 사용을 위한 PVC와 PV를 설명했습니다.
마지막으로 파드를 배포하고 통제하는 리소스들인 워크로드 컨트롤러Workload Controller까지만 설명 하겠습니다.
파드에 담긴 어플리케이션의 성격에 따라 워크로드 컨트롤러는 아래 5종류가 있습니다.
디플로이먼트Deployment: 보통 어플리케이션 배포 시 사용. 파드이름이 랜덤숫자로 만들어짐
스테이트풀셋StatefulSet: 보통 DB 배포 시 사용. Pod 이름이 일련번호가 붙어서 만들어짐
데몬셋DaemonSet: 항상 실행되어 무언가를 감시하거나 처리하는 데몬 성격의 어플리케이션 배포 시 사용. 한 노드(물리머신 또는 VM)에 항상 한개의 파드만 실행됨.
잡Job: 1회성으로 무언가 처리를 하고 종료되는 어플리케이션을 배포할 때 사용. 예를 들어 데이터 마이그레이션(이관) 작업을 하는 어플리케이션이나 어떤 작업의 사전 준비 상태를 체크하는 어플리케이션 같은 것을 배포할 때 사용
크론잡CronJob: 1회성이 아닌 주기적으로 무언가 처리를 하는 어플리케이션을 배포할 때 사용
OpenAPI V2 API 스펙 문서
일반적으로 API는 API 스펙 문서를 제공합니다. 쿠버네티스도 OpenAPI V2 형식의 API 스펙 문서를 제공합니다. 그래서 이론상 kubectl 툴이 없다하더라도 이 API 스펙 문서만으로도 kube-apiserver를 전부 다룰 수 있습니다. (물론 간단하지는 않겠지만요.)
파드와 디플로이먼트 리플리카셋
API 서버는 리소스를 etcd에 저장 후 클라이언트에 응답을 반환함과 동시에 관련된 클라이언트(ex. 컨트롤러 매니저의 컨트롤러)들에 통보해줍니다.
그리하여 오브젝트가 갱신될 때마다 API 서버는 오브젝트를 감시하고 있는 연결된 모든 클라이언트에게 오브젝트의 새로운 버전을 보내줍니다.
스케줄러 ==>만약 동점인 노드가 여러개라면 라운드로빈 적용
그러나 watch=true 를 전달 하면 동작이 크게 바뀝니다.
이제 응답은 수정 유형 및 영향을 받는 개체를 포함하는 일련의 수정 이벤트로 구성됩니다.
긴 폴링이라는 기술을 사용하여 이벤트의 초기 배치를 보낸 후 연결이 열린 상태로 유지됩니다.
긴 폴링 : https://lannstark.tistory.com/88
