Pod
쿠버네티스에서 파드(Pod)는 1개 이상의 컨테이너가 캡슐화 되어 클러스터 안에서 배포되는 가장 작은 단위의 객체를 의미한다.
Pod의 특징
-
기본적으로 하나의 파드에는 하나 이상의 컨테이너가 포함된다.
-
파드는 노드 IP와 별개로 고유 IP를 할당 받으며, 파드 안의 컨테이너들은 그 IP를 공유한다.
-
파드 자체는 일반적으로 1개의 IP만 가진다. (단, Multus CNI 이용 등 특정 조건에 한해 2개의 IP를 가질 수도 있다.)
-
파드 안의 컨테이너들은 동일한 볼륨과 연결이 가능하다.
-
파드는 클러스터에서 배포의 최소 단위이고, 특정 네임스페이스(Namespace) 안에서 실행된다.
-
파드는 기본적으로 반영속적(ephemeral)이다.
동일한 역할을 하는 파드라도 환경에 따라 다른 노드들에 각각 배치될 수 있고, 특정 노드가 죽으면 해당 노드의 파드들이 건강한 상태의 다른 노드로 옮겨지기도 한다.
또는 필요에 따라 파드 숫자의 구성도 수시로 달라질 수 있다. 쿠버네티스에서의 파드는 무언가가 구동 중인 상태를 유지하기 위해 동원되는 일회성 자원이며, 필요에 따라 언제든 삭제될 수 있다.
파드의 생명 주기
Pod phase
Pod의 status상태는 필드가 있는 PodStatus object에 phase 필드에 저장되며 아래와 같은 순서대로 생명주기를 가진다.
Pending -> Running -> Succeeded or Failed
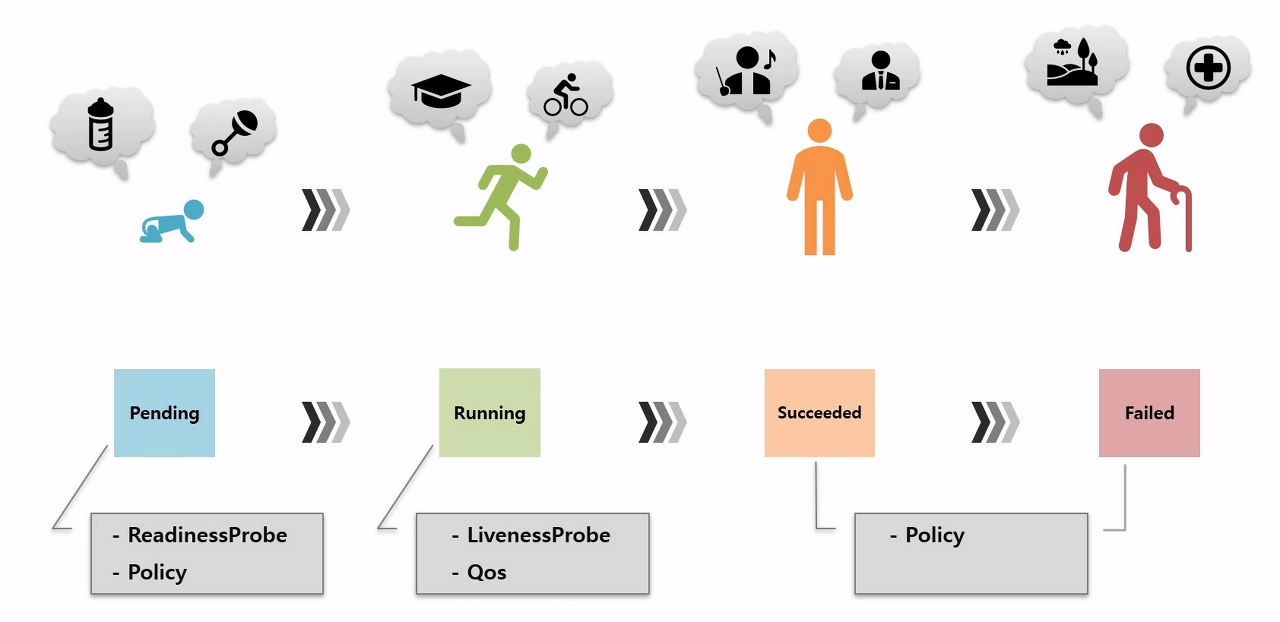
Pod의 생명 주기와 현재 상태는 kubelet이 주기적으로 모니터링한다. 이렇게 모니터링된 상태 정보는 kubectl get pods의 출력 결과 중 STATUS 필드에서 볼 수 있다. 해당 파드 오브젝트의 .status.phase 필드에서도 확인 가능하며, 이때 필요한 명령어는 다음과 같다.
kubectl get pod <파드명> -o jsonpath='{.status.phase}'status를 좀더 자세히 보면
-
Pending : 클러스터 내 파드 생성이 승인되었지만 아직 내부의 컨테이너가 완전히 시작되기 전이며, 아직 노드에 배치되지 않은 상태다.
-
Running : 파드가 클러스터의 특정 노드에 배치되었으며 내부의 모든 컨테이너가 생성 완료된 상태다. 하나 이상의 컨테이너가 구동되기 시작했거나 시작되는 중이다.
-
Succeeded : 파드 안의 컨테이너가 유한한 수의 작업을 실행한 후 종료되도록 설계되었을 때에만 볼 수 있다. 이 경우는 파드에 있는 모든 컨테이너가 해당 작업을 정상적으로 마치고 종료된 것이다.
-
Failed : 역시 파드 안의 컨테이너가 유한한 수의 작업을 실행한 후 종료되도록 설계되었을 때에만 볼 수 있다. 이 경우는 파드에 있는 컨테이너 중 하나 이상이 비정상 종료되었을 때 발생한다.
이 외에도 특수한 경우에만 파드에 부여되는 상태 정보(.status.phase)가 추가로 존재한다.
-
unknown : 파드의 상태 확인이 불가한 경우다. 대개 해당 노드의 네트워크 문제로 발생한다.
-
terminating : 파드를 삭제시켰을 때 볼 수 있다. 일반적으로 파드는 30초의 유예 시간 후에 완전히 삭제되며, 즉시 삭제를 원한다면 kubectl delete 명령에 --force 옵션을 더하면 된다.
컨테이너 상태
스케줄러가 파드를 특정 노드에 할당하면, kubelet은 컨테이너 런타임을 이용하여 컨테이너를 생성하며, kubelet은 컨테이너의 상태를 주기적으로 모니터링한다.
컨테이너의 상태는 kubectl describe pod 명령의 결과 중 Containers 항목이나, 파드 오브젝트의 .status.containerStatuses[*].state 필드에서 확인
kubectl get pod myapp-pod -o jsonpath=컨테이너 상태 종류
Waiting
컨테이너가 Running 또는 Terminated 상태가 아닌 상태
컨테이너 시작 전 필요한 작업 중(이미지 풀링, 스토리지 연결 등) Reason 필드에 이유가 표시됩니다.
-
Running
- 실행 중
- 해당 상태가 된 시각 표시
-
Terminated
- 컨테이너 실행이 완료됨
- 실패
-
Reason 필드에 이유가 표시됨
- 해당 상태가 된 시각 표시
컨테이너의 재시작 정책
Pod의spec에명시된 restartPolicy를 통해 컨테이너 재시작 정책을 결정한다. Always, OnFailure, Never 를 값으로 쓰며 기본값은 Always 이다.
.spec.restartPolicy 재시작 정책:
- Always: (기본값) 종료/실패 시 항상 재시작
- Onfailure: 실패 시 재시작 (정상 종료 시 재시작하지 않음)
- Never: 재시작 하지 않음
apiVersion: v1
kind: Pod
metadata:
name: always-pod
spec:
restartPolicy: Always
containers:
- image: ghcr.io/c1t1d0s7/go-myweb
name: myapp
ports:
- containerPort: 8080
protocol: TCPrestartPolicy는 Pod의 모든 컨테이너에 적용되며, 동일한 노드에서만kubelet에 의한 컨테이너 재시작된다.
포드의 컨테이너가 종료된 후 kubelet은 5분으로 제한되는 기하급수적 백오프 지연(10초, 20초, 40초, …)으로 컨테이너를 다시 시작합니다. 컨테이너가 아무 문제 없이 10분 동안 실행되면 kubelet은 해당 컨테이너의 다시 시작 백오프 타이머를 재설정합니다.. => 재조사
컨테이너 프로브
컨테이너 프로브는 kubelet이 컨테이너를 주기적으로 진단하는 프로브 핸들러를 호출합니다.
프로브의 핸들러는 네 가지 메커니즘을 가지고 이중 하나만을 정의하여 컨테이너의 상태를 진단합니다.
- HTTPGetAction
특정 경로에 HTTP GET 요청
HTTP 응답 코드가 2XX 또는 3XX 인지 확인함
- TCPSocketAction
특정 TCP 포트 연결
포트가 활성화되어 있는지 확인
-
ExecAction
컨테이너 내의 지정된 바이너리를 실행
명령의 종료 코드가 0인지 확인 -
grpc
gRPC를 사용하여 원격 프로시저 호출을 수행한다. 체크 대상이 gRPC 헬스 체크를 구현해야 한다. 응답의 status 가 SERVING 이면 진단이 성공했다고 간주한다.
이러한 진단 결과는 크게 Success(성공), Failure(실패), Unknown(진단 실패)의 세 가지로 구분된다. 만약 진단 결과가 Failure로 나온다면, kubelet이 이를 감지하여 필요한 작업을 수행한다.
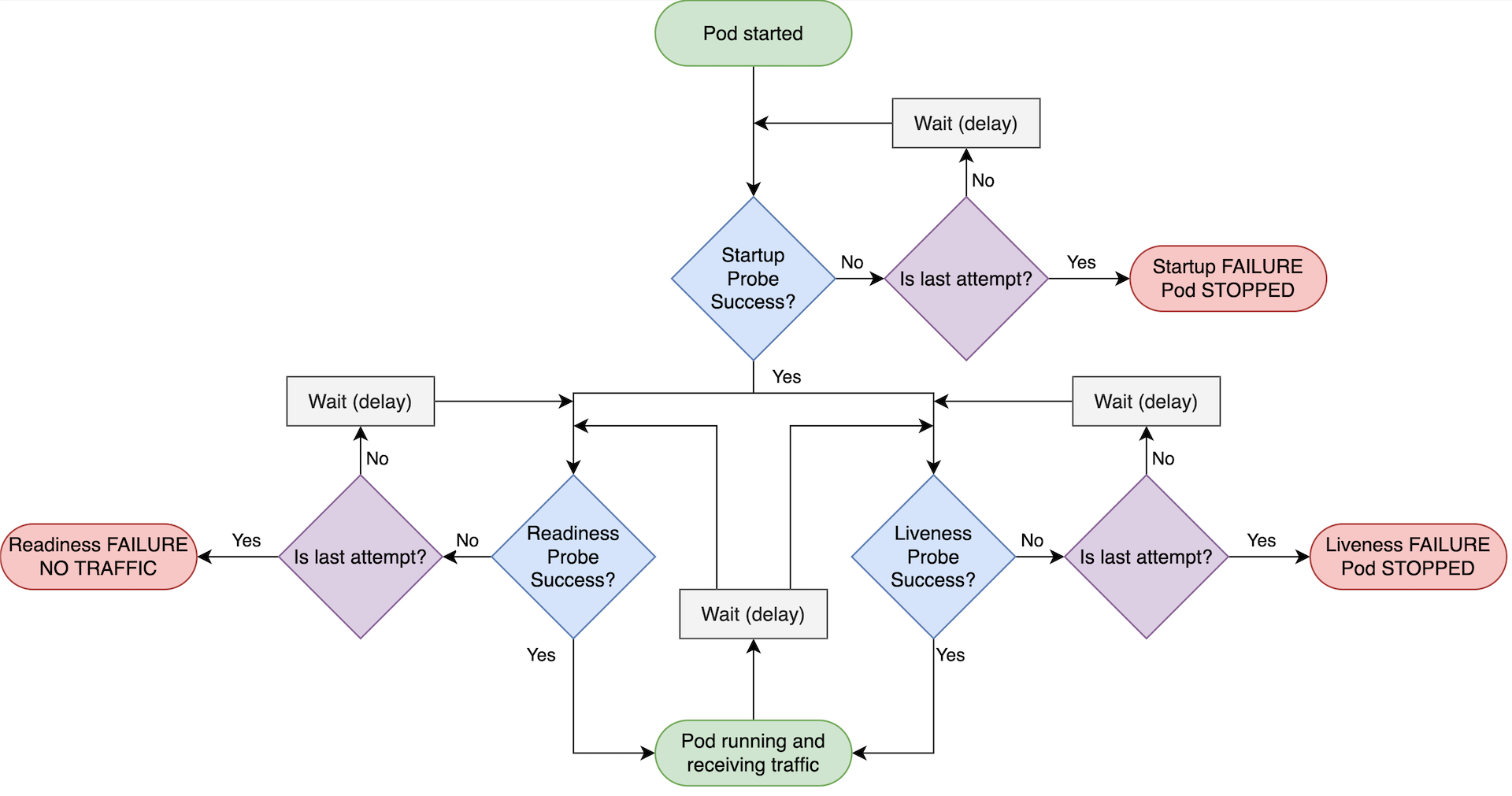
컨테이너 상태 진단을 위한 프로브는 크게 Liveness, Readiness, Startup의 세 종류로 구분되며 정의된 프로브핸들러 방식에 의해 실행된다.
-
Liveness Probe : 컨테이너가 동작 중인지 여부를 나타낸다. 만약 활성 프로브(liveness probe)에 실패한다면, kubelet은 컨테이너를 죽이고, 해당 컨테이너는 재시작 정책의 대상이 된다. 만약 컨테이너가 활성 프로브를 제공하지 않는 경우, 기본 상태는 Success 이다.
-
Readiness Probe : 컨테이너가 요청(Request)을 처리할 수 없는 상황이 감지되면 해당 파드로의 로드밸런싱을 중단시킨다. 단, 파드 자체는 건드리지 않는다.
-
Startup Probe : 컨테이너 내의 애플리케이션이 시작되었는지를 나타낸다. 스타트업 프로브(startup probe)가 주어진 경우, 성공할 때까지 다른 나머지 프로브는 활성화되지 않는다. 만약 스타트업 프로브가 실패하면, kubelet이 컨테이너를 죽이고, 컨테이너는 재시작 정책에 따라 처리된다.
시작 프로브는 deployment.yaml 매니페스트에서 정의됩니다. 예를 들어 다음은 시작 프로브를 포함하는 deployment.yamlspec:template: 에 대한 섹션을 보여줍니다. 프로브는 에 정의되어 있으며 포트 80 에서 URL 을 호출합니다. 또한 프로브는 실패하기 전에 30번 시도해야 하며 확인 사이에 10초의 대기 시간이 있어야 한다고 명시되어 있습니다.startupProbe/health/startup
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-app-api-deployment
spec:
template:
metadata:
labels:
app: test-app-api
spec:
containers:
- name: test-app-api
image: andrewlock/my-test-api:0.1.1
startupProbe:
httpGet:
path: /health/startup
port: 80
failureThreshold: 30
periodSeconds: 10프로브 결과
각 probe는 다음 세 가지 결과 중 하나를 가진다.
- Success
컨테이너가 진단을 통과함. - Failure
컨테이너가 진단에 실패함. - Unknown
진단 자체가 실패함(아무런 조치를 수행해서는 안 되며, kubelet이 추가 체크를 수행할 것이다)
https://nearhome.tistory.com/89
https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/
https://seongjin.me/kubernetes-pods/
https://andrewlock.net/deploying-asp-net-core-applications-to-kubernetes-part-6-adding-health-checks-with-liveness-readiness-and-startup-probes/
https://kdeon.tistory.com/48
https://tech.scatterlab.co.kr/kubernetes-event-alarm/
